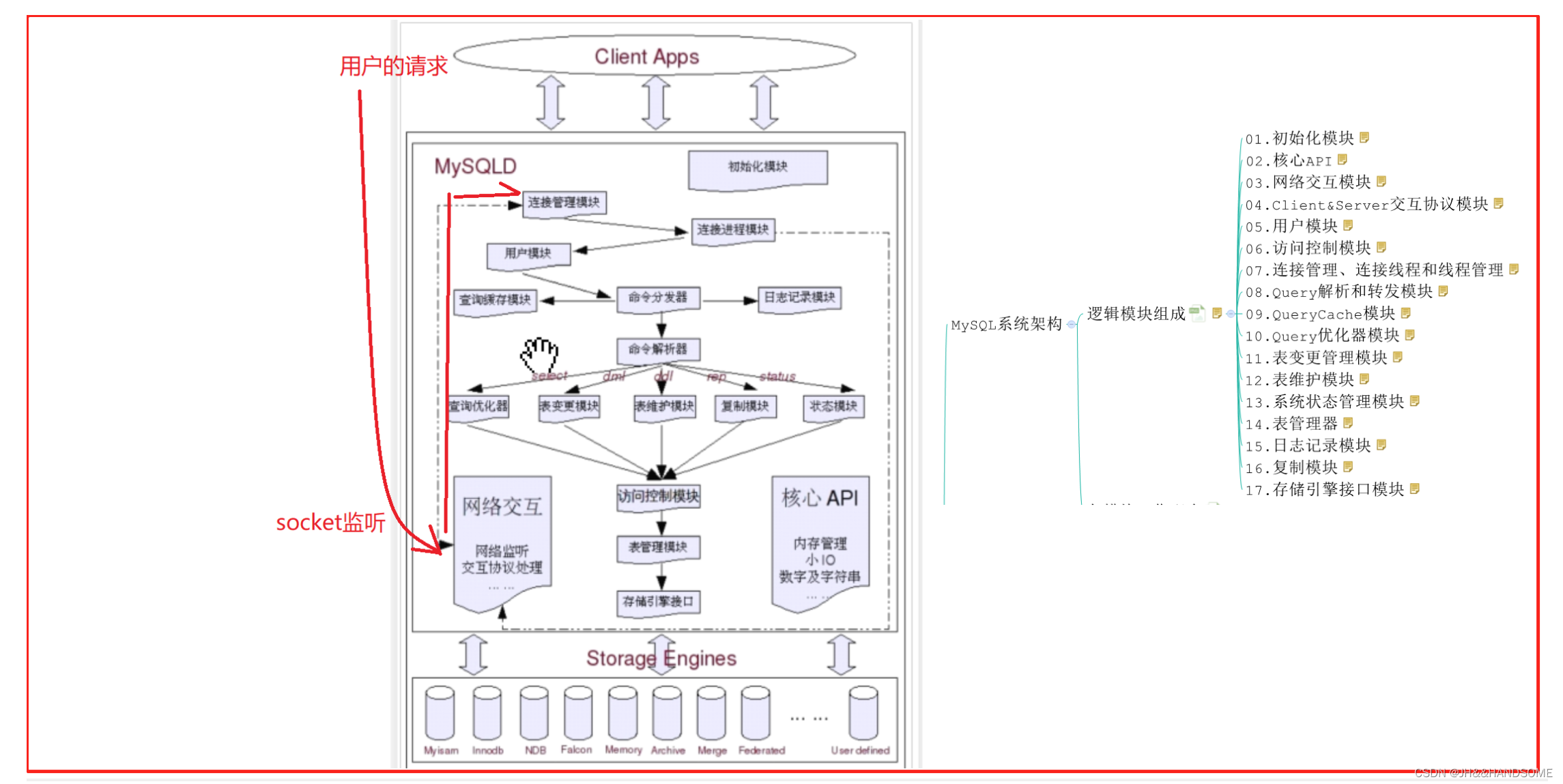
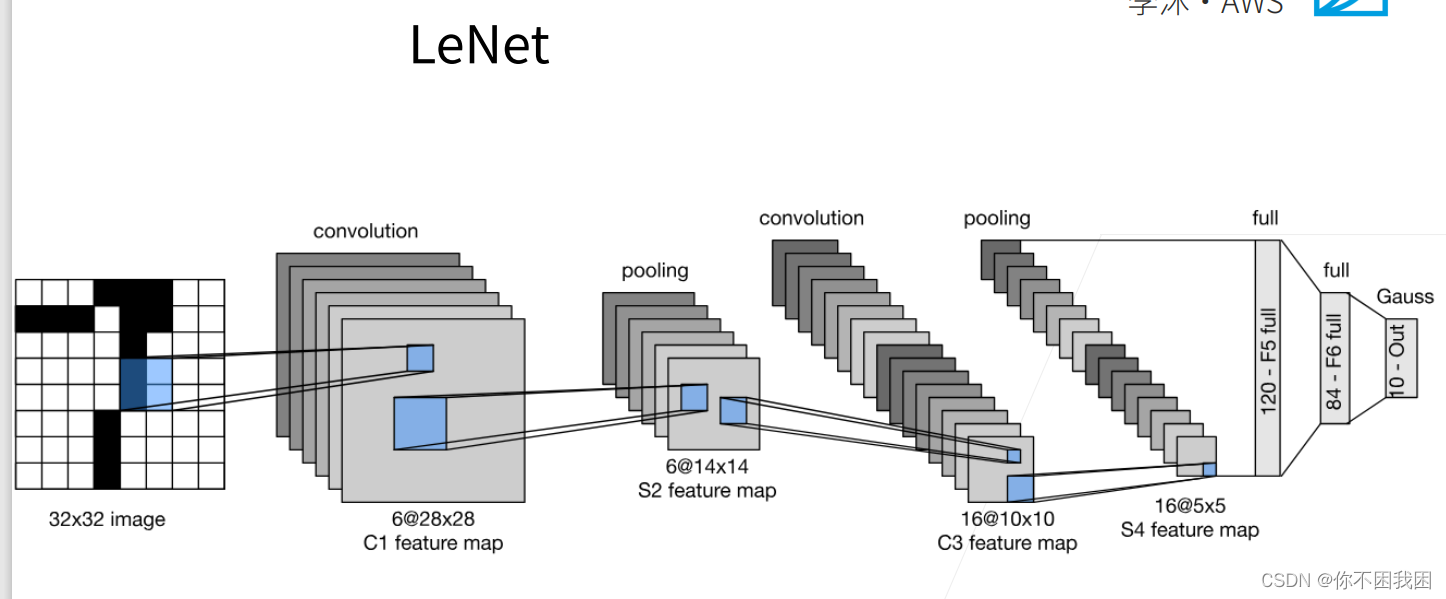
1. 经典神经网络(LeNet)
LeNet是早期成功的神经网络;
先使用卷积层来学习图片空间信息
然后使用全连接层来转到到类别空间
【通过在卷积层后加入激活函数,可以引入非线性、增加模型的表达能力、增强稀疏性和解决梯度消失等问题,从而提高卷积神经网络的性能和效果】
LeNet由两部分组成:卷积编码器和全连接层密集块
import torch
from torch import nn
from d2l import torch as d2lclass Reshape(torch.nn.Module):def forward(self, x):return x.view(-1, 1, 28, 28) # 批量数不变,通道数=1,h=28, w=28net = torch.nn.Sequential(Reshape(), nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(), # 在卷积后加激活函数,填充是因为原始处理数据是32*32nn.AvgPool2d(kernel_size=2, stride=2), # 池化层nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), # 将4D结果拉成向量# 相当于两个隐藏层的MLPnn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(), nn.Linear(84, 10))
检查模型
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:X = layer(X) """对神经网络 net 中的每一层进行迭代,并打印每一层的输出形状layer.__class__.__name__ 是获取当前层的类名,即层的类型"""print(layer.__class__.__name__, 'output shape: \t', X.shape)
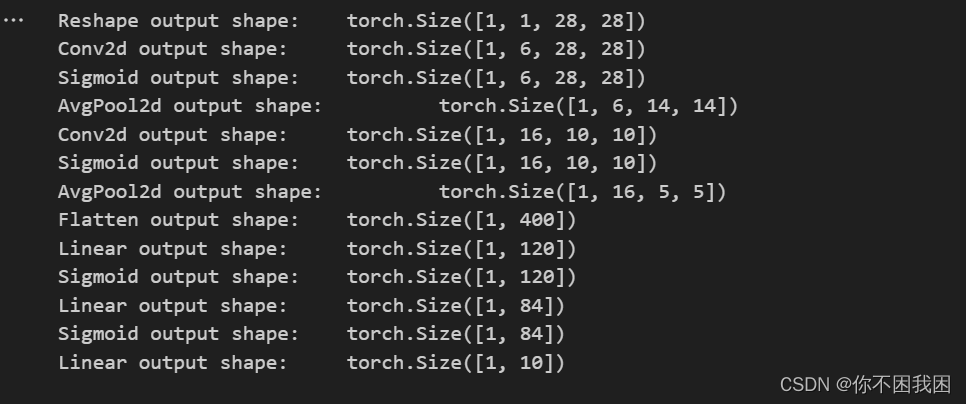
LeNet在Fashion-MNIST数据集上的表现
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)# 对evaluate_accuarcy函数进行轻微的修改
def evaluate_accuracy_gpu(net, data_iter, device=None): """使用GPU计算模型在数据集上的精度。"""if isinstance(net, torch.nn.Module):net.eval()if not device:device = next(iter(net.parameters())).devicemetric = d2l.Accumulator(2)for X, y in data_iter:if isinstance(X, list):X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1] # 分类正确的个数 / 总个数
【
net.to(device) 是将神经网络 net 中的所有参数和缓冲区移动到指定的设备上进行计算的操作。
net 是一个神经网络模型。device 是指定的设备,可以是 torch.device 对象,如 torch.device(‘cuda’) 表示将模型移动到 GPU 上进行计算,或者是字符串,如 ‘cuda:0’ 表示将模型移动到指定编号的 GPU 上进行计算,也可以是 ‘cpu’ 表示将模型移动到 CPU 上进行计算。
通过调用 net.to(device),模型中的所有参数和缓冲区将被复制到指定的设备上,并且之后的计算将在该设备上进行。这样可以利用 GPU 的并行计算能力来加速模型训练和推断过程。
注意,仅仅调用 net.to(device) 并不会对输入数据进行迁移,需要手动将输入数据也移动到相同的设备上才能与模型进行计算。例如,可以使用 input = input.to(device) 将输入数据 input 移动到指定设备上。】
# 为了使用 GPU,我们还需要一点小改动
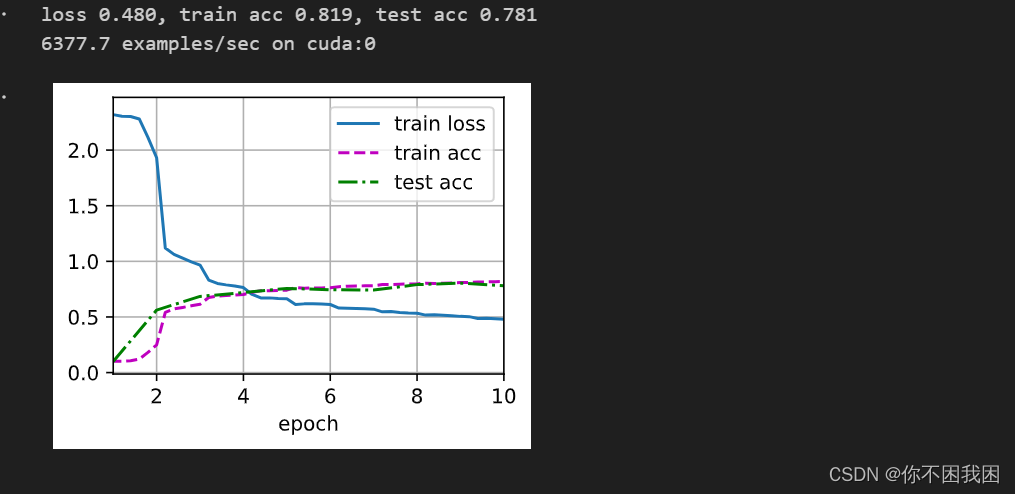
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU训练模型(在第六章定义)。"""def init_weights(m): # 初始化权重if type(m) == nn.Linear or type(m) == nn.Conv2d: nn.init.xavier_uniform_(m.weight)net.apply(init_weights) # 对整个网络应用初始化print('training on', device)net.to(device) # 将神经网络 net 中的所有参数和缓冲区移动到指定的设备上进行计算的操作optimizer = torch.optim.SGD(net.parameters(), lr=lr) # 定义优化器loss = nn.CrossEntropyLoss() # 定义损失函数# 动画效果animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):metric = d2l.Accumulator(3) # metric被初始化为存储3个指标值的累加器net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()# 将输入输出数据也移动到相同的设备X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]# 动画效果if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
训练和评估LeNet-5模型
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
2. 深度卷积神经网络(AlexNet)
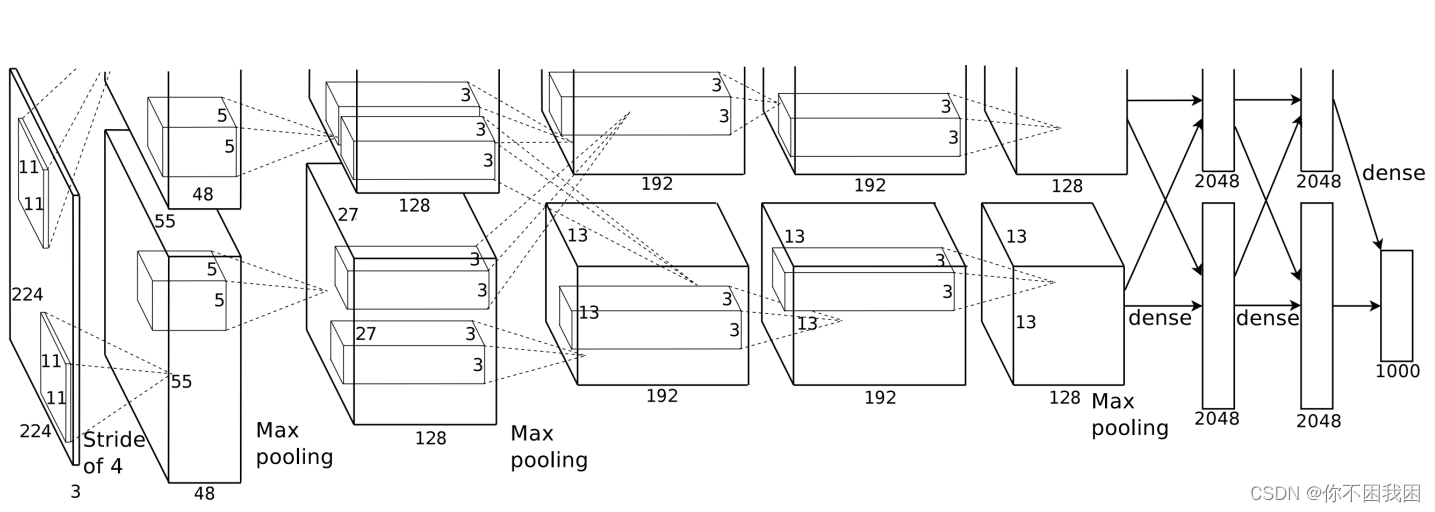
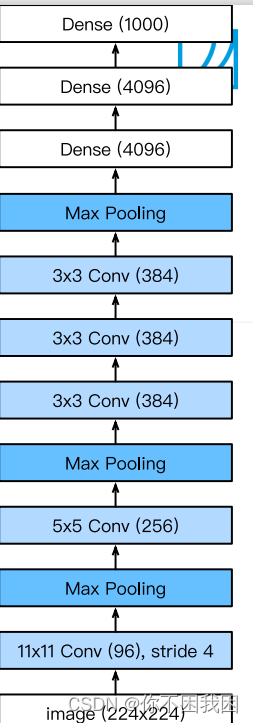
AlexNet架构 VS LeNet:
更大的核窗口和步长,因为图片更大了
更大的池化窗口,使用maxpooling
更多的输出通道
添加了3层卷积层
更多的输出
更多细节:
- 激活函数从sigmod变成了Rel(减缓梯度消失)
- 隐藏全连接层后加入了丢弃层dropout
- 数据增强
总结:
- AlexNet是更大更深的LeNet,处理的参数个数和计算复杂度大幅度提升
- 新加入了丢弃法,ReLU激活函数,最大池化层和数据增强
代码实现:
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(), # 在MNIST输入通道是1,在ImageNet测试集上输入为3nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(), # 相比于LeNet将激活函数改为ReLUnn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2), nn.Flatten(), # 将4D->2Dnn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5), # 添加丢弃nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5),nn.Linear(4096, 10)) # 在Fashion-MNIST上做测试所以输出为10
# 构造一个单通道数据,来观察每一层输出的形状
X = torch.randn(1, 1, 224, 224)
for layer in net:X = layer(X)print(layer.__class__.__name__, 'Output shape:\t', X.shape)
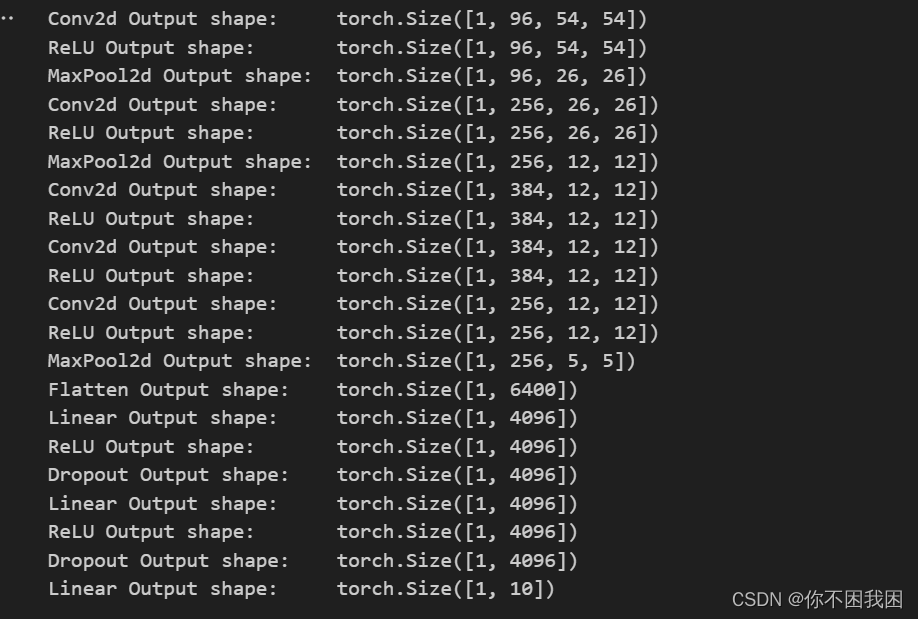
# Fashion-MNIST图像的分辨率低于ImageNet图像,所以将其增加到224x224
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
# 训练AlexNet
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
3. 使用块的网络(VGG)
3.1 VGG相关

VGG的引出:
- AlexNet比LeNet更深更大,取得了更好的精度
- 能不能更深更大?
- 更多的全连接层(太贵)
- 更多的卷积层
- 将卷积层组合成块 -> VGG
VGG块:
-
深VS宽
- 在同样的计算开销下,堆多一点的3x3的卷积层(模型更深但是窗口更窄)相比于5x5的Conv效果更好
-
3x3卷积(填充1【保持输入输出大小不变】)(n层【Conv层数】,m通道【Conv输入输出通道数】)
-
2x2 Maxpooling(步幅2)
核心:用大量3x3conv+池化 -> 堆成块,大量的块 -> 网络
VGG架构:
- 多个VGG块后连接全连接层
- 不同次数的重复块得到不同的架构:VGG-16, VGG-19
- 实际上就是把AlexNet的卷积层架构替换成了VGG块的串联

网络发展的进度:
-
LeNet(1995)
- 2卷积 + 池化
- 2 全连接层
-
AlexNet
- 更大更深
- ReLU,Dropout,数据增强
- 快 / 精度不高
-
VGG
- 更大更深更规整的AlexNet(重复的VGG块)
- 慢 / 精度高 / 占用内存高 / 可通过调节块的数量改变
VGG总结:
- VGG使用可重复使用的卷积块来构建深度卷积神经网络
- 不同的卷积块个数和超参数可以得到不同复杂度的变种
3.2 代码实现
【layers = [] 是创建一个空的列表 layers。
layers 是一个列表对象,用于存储神经网络的层。
通过 layers = [],我们创建了一个空的列表,可以在后续的代码中向其中添加层。这种方式通常用于构建神经网络模型,可以方便地按顺序添加和管理不同层的参数和计算过程。
示例用法如下:
layers = []# 添加层到列表中
layers.append(nn.Linear(10, 20))
layers.append(nn.ReLU())
layers.append(nn.Linear(20, 1))# 使用列表构建神经网络模型
model = nn.Sequential(*layers)
在这个例子中,我们先创建一个空的列表 layers,然后按顺序向其中添加线性层、ReLU激活函数层和线性层。最后,我们使用 nn.Sequential 将列表中的层按顺序组合成一个神经网络模型 model。这种方式可以灵活地扩展和管理模型中的不同层。】
vgg块:通道加倍, 高宽减半
import torch
from torch import nn
from d2l import torch as d2ldef vgg_block(num_convs, in_channels, out_channels): # 超参数:卷积层数,输入输出通道数layers = [] # 创建一个空的列表 layersfor _ in range(num_convs):layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))layers.append(nn.ReLU())in_channels = out_channelslayers.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 经过一次池化, 高宽减半return nn.Sequential(*layers)
vgg-11 它有5个卷积块,前2块使用单卷积层,而后3块使用双卷积层
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512)) # 给出不同块的结构def vgg(conv_arch):conv_blks = []in_channels = 1for (num_convs, out_channels) in conv_arch: # 构造出每一块conv_blks.append(vgg_block(num_convs, in_channels, out_channels))in_channels = out_channelsreturn nn.Sequential(*conv_blks, nn.Flatten(),nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), # 输入宽度= 通道数 * 最后输出矩阵的大小是7 * 7, 因为之前经过5次块的池化,224 - 112 - 56- 28 - 15 - 7 nn.Dropout(0.5), nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(0.5), nn.Linear(4096, 10) )net = vgg(conv_arch)
# 观察每个层输出的形状
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:X = blk(X)print(blk.__class__.__name__, 'output shape:\t', X.shape)
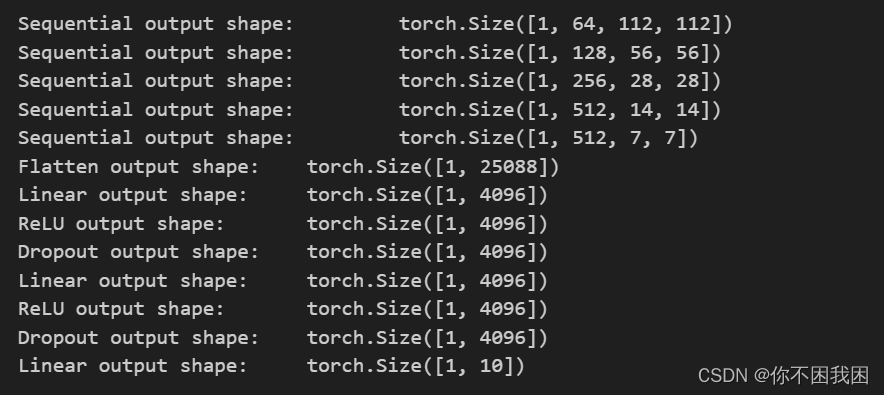
由于后续模型太深,GPU跑不动哈,有点尴尬,但不多
还是给出测试过程:
# 由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
4. 网络中的网络(NiN)
4.1 NiN相关
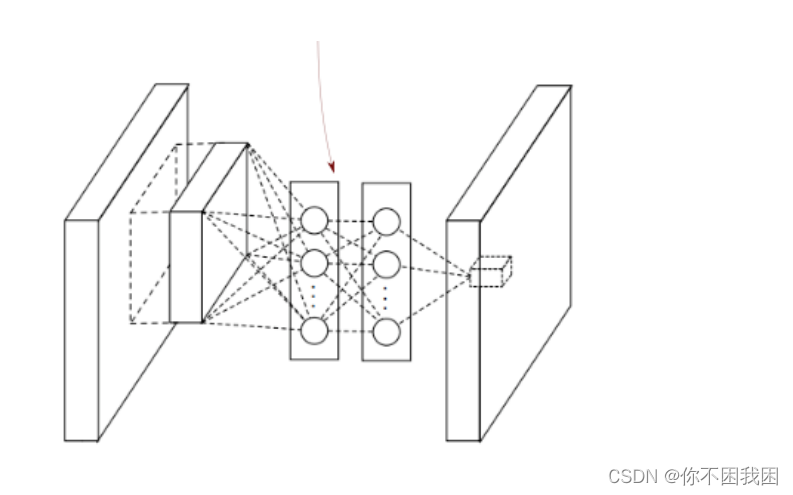
问题引出:LeNet、AlexNet、VGG都存在问题—全连接层参数过多
- 全连接层的参数过多:占用参数空间\占用内存大\占用带宽,容易过拟合
- 于此对比,卷积层需要较少的参数:输入通道数x输出通道数x h x w
思路:
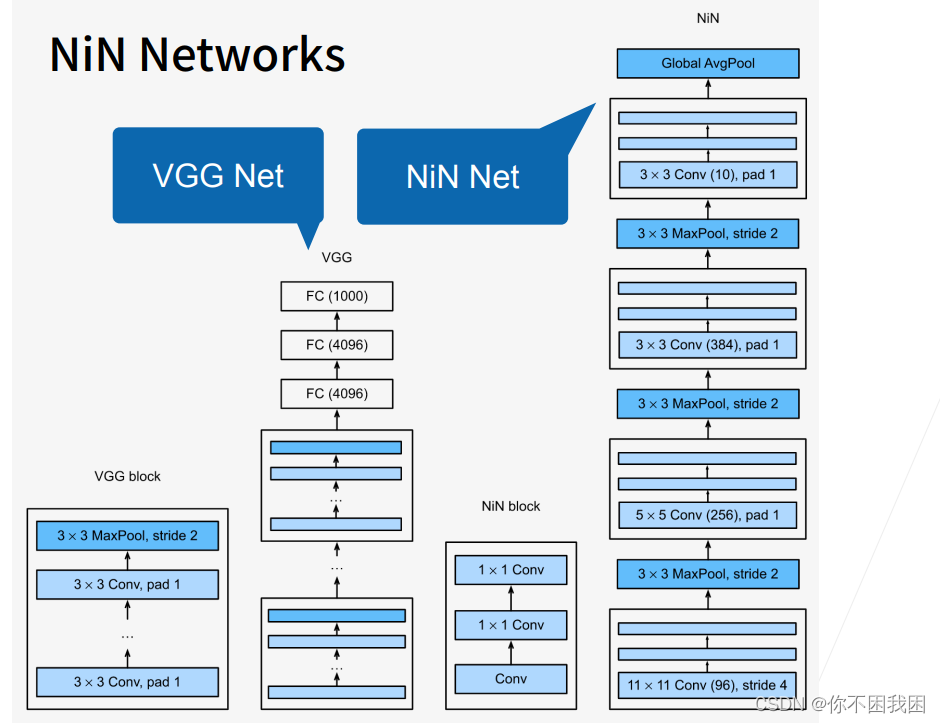
NiN块:
- 一个卷积层后跟着两个’全连接层‘【用1x1卷积层代替全连接层】
- 步幅1,无填充,输出形状和卷积层输出一样
- 1x1卷积层起到全连接层的作用
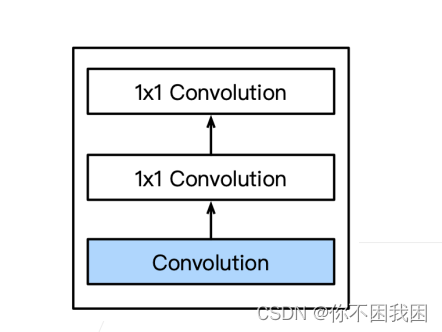
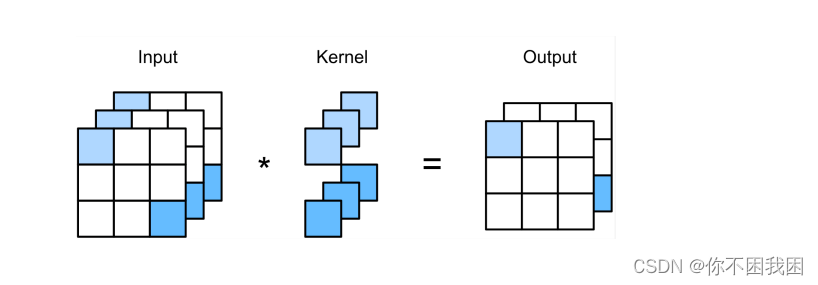
1x1 Convolution:
NiN架构:
- 无全连接层
- 交替使用NiN块和步幅为2的最大池化层(高宽减半)
- 逐步减小高宽和增大通道数
- 最后使用全局平均池化层【全局平均化在每个通道上】得到输出
- 其输入通道数是类别数
- 最后使用softmax返回概率
总结:
- NiN块使用卷积层后加两个1x1卷积层【充当全连接层】
- 对每个像素增加了非线性
- NiN使用全局平均池化层来替代VGG和AlexNet中的全连接层【最后输出类别的那层】
- 不容易过拟合,同时卷积层有更少的参数个数
4.2 NiN实现
NiN块:
import torch
from torch import nn
from d2l import torch as d2ldef nin_block(in_channels, out_channels, kernel_size, strides, padding):return nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=strides,padding=padding),nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1), # 1x1卷积层相当于Linear,不改变通道数,输入输出通道数相同nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1),nn.ReLU())
NiN模型 ->基于AlexNet架构
net = nn.Sequential(nin_block(1, 96, kernel_size=11, strides=4, padding=0), # 使用的是灰度图,所以输入通道数是1(使用Fashion-MNSIT数据集测试),后面参数继承自AlexNetnn.MaxPool2d(3, stride=2),nin_block(96, 256, kernel_size=5, strides=1, padding=2),nn.MaxPool2d(3, stride=2),nin_block(256, 384, kernel_size=3, strides=1, padding=1),nn.MaxPool2d(3, stride=2), nn.Dropout(0.5),nin_block(384, 10, kernel_size=3, strides=1, padding=1), # 把通道数降到10,因为输出类别是10,如果使用别的数据集要修改输出通道数nn.AdaptiveAvgPool2d((1, 1)), # 做全局平均池化层,把每个通道的平均值拿出来-> 替代原来的输出类别的全连接层nn.Flatten() # 消除最后两个维度,将4D->2D, 方便后期Softmax)
查看每个块的输出形状:
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:X = layer(X)print(layer.__class__.__name__, 'output shape:\t', X.shape)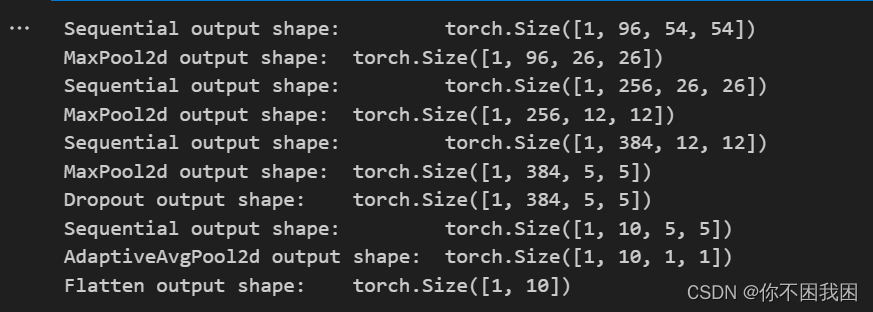
训练模型:
训练时间过长,中断了哈,总体的准确率比VGG低,且处理图片数较少
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())