前言
为了节省内存,Redis 推出了 ziplist 数据类型,采用一种更加紧凑的方式来存储 hash、zset 元素。因为查找的时间复杂度是 O(N),且写入需要重新分配内存,所以它仅适用于小数据量的存储,而且它还存在 连锁更新 的风险。
为了降低 ziplist 内存分配和连锁更新带来的影响,Redis 又推出了 quicklist 数据结构,我们来一睹它的风采。
注意:quicklist只是降低了 ziplist 内存分配和连锁更新带来的影响,没有从根本上解决这些问题。
quicklist
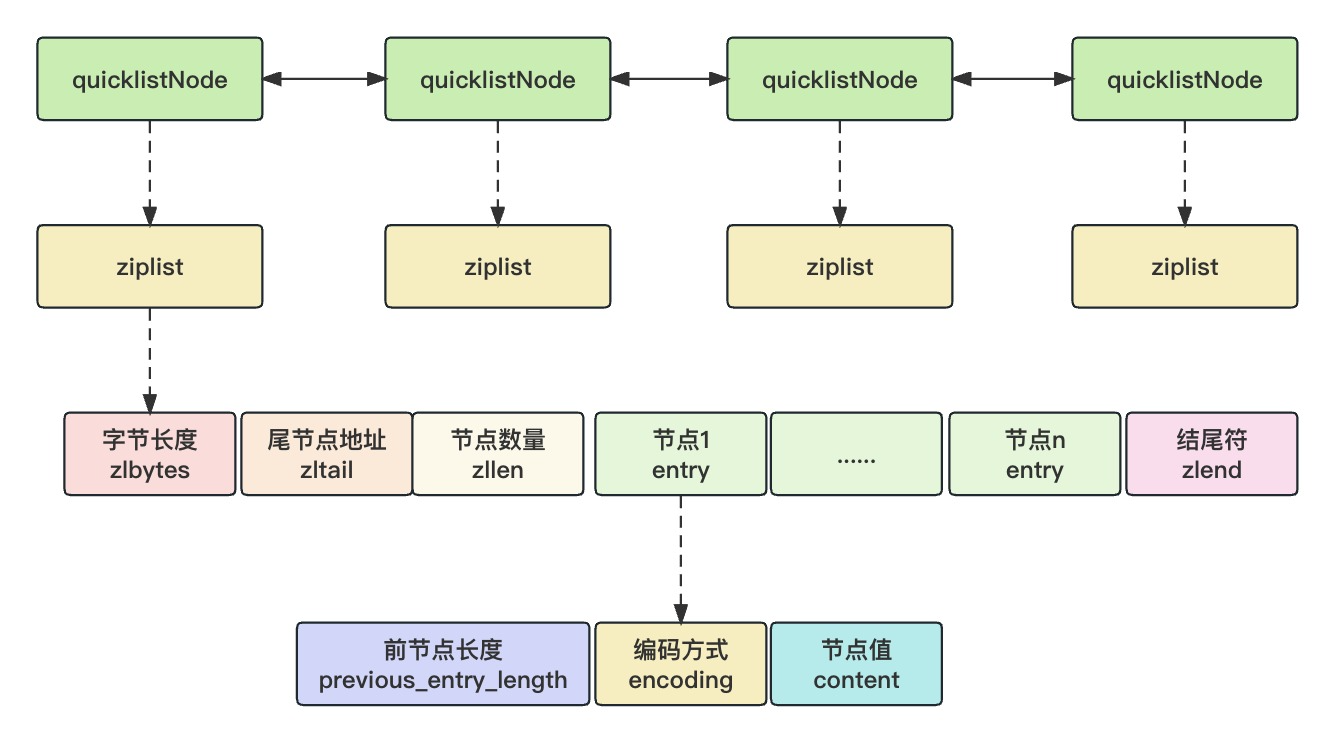
quicklist 是由若干个 ziplist 节点组成的一条双向链表,quicklist 的核心在于控制好每个 ziplist 的大小,因为 ziplist 越大,内存分配的开销越大,连锁更新带来的影响也就越大。
Redis 提供了list-max-ziplist-size参数来限制 ziplist 大小,值为负数时,限制的是 ziplist 的内存空间;值为正数时,限制的是 ziplist 元素数量。默认值是 -2,代表每个 ziplist 不超过 8KB。
- -1:最大 4KB
- -2:最大 8KB,默认值
- -3:最大 16KB
- -4:最大 32KB
- -5:最大 64KB,不推荐
-
0:限制元素数量
另外 Redis 还支持对 quicklist 中的 ziplist 节点做压缩,节点一旦压缩,就意味着每次访问都必须先解压缩,这势必会带来额外的开销。又因为两端的节点是访问频率较高的,特别是头尾节点是最常访问的节点。因此,为了兼顾访问性能和内存占用,Redis 提供了list-compress-depth参数配置 quicklist 两端不压缩的节点数,默认不压缩。
源码
- quicklist
quicklist 是一条由若干个 ziplist 组成的双向链表,为了快速访问两端节点,quicklist 用两个指针分别指向了首尾节点,同时记录下链表里的节点数,以及所有的总元素数量,这样就不必每次都再统计一遍。
fill限制单个 ziplsit 长度,可以是内存空间也可以是元素数量;compress限制了两端不被压缩的节点数量。
typedef struct quicklist {quicklistNode *head; // 头节点quicklistNode *tail; // 尾节点unsigned long count; // 总元素数量unsigned long len; // 节点数int fill : QL_FILL_BITS; // 限制ziplist长度 正数代表限制元素数量 负数代表限制内存大小unsigned int compress : QL_COMP_BITS; // 链表两端不压缩的节点数 因为两端会被频繁访问unsigned int bookmark_count: QL_BM_BITS;quicklistBookmark bookmarks[];
} quicklist;
- quicklistNode
quicklist 里的每个节点用 quicklistNode 表示,每个节点都都有两个指针分别指向前驱节点和后继节点。
每个节点都是一个单独的 ziplist,所以还有一个zl指针指向 ziplist。同时还会记录一些额外的数据,比如元素数量,ziplist 是否被压缩,能否被压缩等等。
typedef struct quicklistNode {struct quicklistNode *prev; // 前驱节点struct quicklistNode *next; // 后继节点unsigned char *zl; // ziplist指针unsigned int sz; // ziplist大小unsigned int count : 16; // ziplist元素数量unsigned int encoding : 2; // 编码方式 ziplist/quicklistLZFunsigned int container : 2; // 存储方式unsigned int recompress : 1; // 是否压缩unsigned int attempted_compress : 1; // 数据能否被压缩 太小就没压缩的必要unsigned int extra : 10; // 预留位
} quicklistNode;
- quicklistLZF
ziplist 采用 LZF 压缩算法,压缩后的结构是 quicklistLZF。sz 记录压缩后的数据长度,compressed 是压缩后的字节数组。
typedef struct quicklistLZF {unsigned int sz; // 压缩后的长度char compressed[]; // 压缩后的数据
} quicklistLZF;
- quicklistEntry
quicklistEntry 代表 quicklist 里的一个 ziplist 节点里的一个元素。
typedef struct quicklistEntry {const quicklist *quicklist; // quicklist指针quicklistNode *node; // 所属node节点unsigned char *zi; // ziplist指针unsigned char *value; // 节点值指针long long longval; // 整形值unsigned int sz; // 节点长度int offset; // 偏移量
} quicklistEntry;
- quicklistCreate
创建一个空的 quicklist。
quicklist *quicklistCreate(void) {struct quicklist *quicklist;quicklist = zmalloc(sizeof(*quicklist));quicklist->head = quicklist->tail = NULL;quicklist->len = 0;quicklist->count = 0;quicklist->compress = 0;quicklist->fill = -2; // 默认每个ziplist不超过8KBquicklist->bookmark_count = 0;return quicklist;
}
- quicklistPush
插入元素,根据 where 判断是插入到头部还是尾部。
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,int where) {// 插入到头结点还是尾节点if (where == QUICKLIST_HEAD) {quicklistPushHead(quicklist, value, sz);} else if (where == QUICKLIST_TAIL) {quicklistPushTail(quicklist, value, sz);}
}
- quicklistPushTail
以插入到尾部为例,quicklist 在插入前都会先判断目标 ziplist 是否能容纳新的元素,如果能容纳则直接插入;否则会创建新的 ziplist 节点再插入元素,这样就可以限制每个 ziplist 大小。
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {quicklistNode *orig_tail = quicklist->tail;assert(sz < UINT32_MAX); // 判断插入的目标node是否能容纳新元素if (likely(_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {quicklist->tail->zl =ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);quicklistNodeUpdateSz(quicklist->tail);} else {// 不能容纳,则创建新的节点插入quicklistNode *node = quicklistCreateNode();node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);quicklistNodeUpdateSz(node);_quicklistInsertNodeAfter(quicklist, quicklist->tail, node);}quicklist->count++;quicklist->tail->count++;return (orig_tail != quicklist->tail);
}
尾巴
为了降低 ziplist 内存分配的开销和连锁更新带来的影响,Redis 推出了 quicklist 数据结构,它可以看作是 ziplist 的一个升级版本,核心是限制每个 ziplist 的大小,然后把它们串联成一条双向链表,这样就可以把内存分配和连锁更新的开销分摊到每个节点上,影响就不会那么大了,同时又能利用 ziplist 节省内存的优点。
需要注意的是,quicklist 不是银弹,虽然可以降低 ziplist 的一些额外开销,但它的查找效率依然是 O(N)。