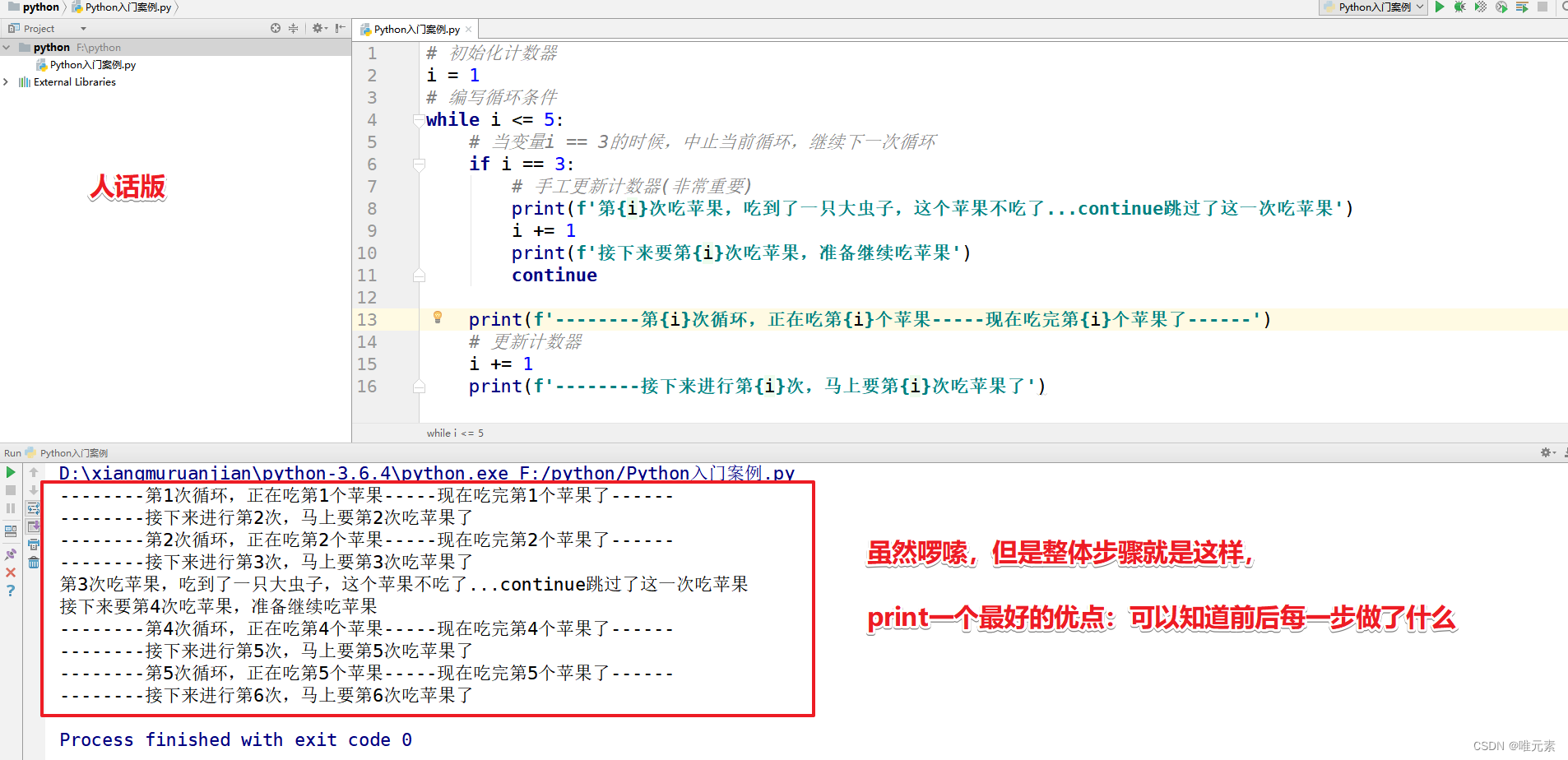
input_t = input_t.squeeze(1) 这行代码用于从 input_t 中去除尺寸为1的维度。在深度学习中,经常会出现具有额外尺寸为1的维度,这些维度通常是为了匹配模型的期望输入维度而添加的。
在这里,input_t可能具有形状 (batch_size, 1, feature_dim),其中 1 表示时间步维度。在某些情况下,模型可能要求输入不包含时间步维度,而只包含 (batch_size, feature_dim) 的形状。为了适应模型的输入要求,squeeze(1) 被用来删除时间步维度,将 input_t 转换为 (batch_size, feature_dim) 的形状。
输入 (354, 32, 541, 1)
keras.layers.InputLayer(input_shape=(None, N, channels)),
TimeDistributed(Conv1D(18, 5, strides=3, activation=“relu”)), (354, 32, 179, 18) 108
TimeDistributed(Conv1D(20, 5, strides=2, activation=“relu”)), (354, 32, 88, 20) 1820
TimeDistributed(MaxPool1D()) (354, 32, 44, 20) 0
TimeDistributed(Conv1D(22, 5, activation=“relu”)) (354, 32, 40, 22) 2222
TimeDistributed(MaxPool1D()) (354, 32, 20, 22) 0
TimeDistributed(Conv1D(24, 5, activation=“relu”)) (354, 32, 16, 24) 2664
TimeDistributed(Flatten()) (354, 32, 384) 0
卷积层本质上是对一条数据进行各种特征变换(channel),最后经过Flatten降维,从二维的空间变回序列数据,交给RNN处理
TimeDistributed(Dense(32, activation=“relu”) (354, 32, 32) 12320
SimpleRNN(19, return_sequences=True) (354, 32, 19) 988
TimeDistributed(Dense(1)) (354, 32, 1) 20
为什么输入一定是四维的,后面都是四维,why?
这里我把T和channel弄混了,平常所说的Conv1d这种是没有T这个维度的,但是有channel这个维度。即,原本的Conv1d是三维的,现在加上时间T这个维度,一共四维
TimeDistributed输入至少为 3D(bs, time, feature),其中index = 1应该是时间所表示的维度

所以解释了,这里的None指的是T维度,因为input_shape是不包含batch维度的


对于RNN:如果 return_sequences:返回 3D 张量, 尺寸为 (batch_size, timesteps, units)。
否则,返回尺寸为 (batch_size, units) 的 2D 张量
Conv1D的输入输出,pytorch和tf有何区别,维度分别是多少?
卷积是没有时间维度的!即seq_len(T)维度(纵向的),这里的L准确来说是input_size(横向的)
Pytorch Conv1d:
Input:( N , C i n , L ) N, C_{in},L) N,Cin,L) L是指sequence length, C指channel数量
Output: ( N , C o u t , L o u t ) (N, C_{out}, L_{out}) (N,Cout,Lout)
like Conv2d:
Input: ( N , C i n , H , W ) (N, C_{in}, H, W) (N,Cin,H,W)
Onput: ( N , C o u t , H o u t , W o u t ) (N, C_{out}, H_{out}, W_{out}) (N,Cout,Hout,Wout)
TensorFlow:
Conv1d:(batch_size, seq_len, channels) 受data_format = “channels_last (默认) / first” 参数控制
tf的设计理念是,除了第一个inputlayer,其他层都不需要给出输入的维度,模型会自动算出。且input layer给出的维度是不包含 batch 轴的。
首先在写模型的时候,keras.layers.Conv1D(filters, kernel_size)第一个参数就是outchannel,tf中是缺省了输入维度的,会自动匹配。其中filters的数量你可以想象成你想提取多少个“特征”
RNN和RNNCELL输入
在PyTorch中可以使用下面两种方式去调用,分别是torch.nn.RNNCell()和torch.nn.RNN(),这两种方式的区别在于RNNCell()只能接受序列中单步的输入,且必须传入隐藏状态,而RNN()可以接受一个序列的输入,默认会传入全0的隐藏状态,也可以自己申明隐藏状态传入。
如果用RNNCell()就相当于要必须在外面加个for循环,进行seq_len次forward,显式地将hidden传入给下一次forward。
batch的理解:
大多数情况可以直接忽略batch,因为他就是数据处理的一种并行化方式。但需要知道几个基础知识,比如模型参数是共享的,但是hidden state [bs, hidden state],这种有bs的肯定不是共享的,hidden state就是记录状态用的。
总结:
RNN关心序列维度,缺省为单通道RNN,[bs, seq_len, input_size, 1]—>[bs,seq_len,input_size]
所以在把数据给RNN之前,都要把数据处理成上述样子。
CNN才关心Channel,而不关心seq_len,所以是[bs, channel, …]
最大的问题在于忽略了Channel这一维度,其实称之为特征维度:无论是1d,2d,3d都是在描述数据的多少,比如一个序列长度为12,比如一个图片的像素点有12 * 12个。
但是如果一个序列被三个传感器x,y,z检测记录,合起来组成这一个数据点,那么描述这一个数据点需要三个“特征”,channel = 3;同样,对于每个像素点的特征数量是3,所以channel = 3.
无论batchsize还是seq_len都是用来方便处理数据的,要区分于数据本身的特征:特征维度,共有多少个特征,每个特征几维
为什么需要TimeDistributed?
首先对于卷积操作来说维度是固定的,就像函数传参一样,不是任意长度的。
![【LeetCode】145. 二叉树的后序遍历 [ 左子树 右子树 根结点]](https://img-blog.csdnimg.cn/88587c23768a40c8be2df9f79e6b8235.png)
![[SQL | MyBatis] MyBatis 简介](https://img-blog.csdnimg.cn/b8551321cd504535bbc61a2e3f5c4234.png)







![【LeetCode】94. 二叉树的中序遍历 [ 左子树 根结点 右子树 ]](https://img-blog.csdnimg.cn/a0dd44bb339a48828b562c80b25b3fe2.png)