最近在跑深度学习模型,发现Embedding随机性太强导致模型结果有出入,因此考虑固定初始随机向量,既提前训练好词/字向量,不多说上代码!!
1、利用gensim训练字向量(词向量自行修改)
# 得到每一行的数据 []
datas = open('data/word.txt', 'r', encoding='gbk').read().split("\n")
# 得到一行的单个字 [[],...,[]]
word_datas = [[i for i in data if i != " "] for data in datas]
model = Word2Vec(word_datas, # 需要训练的文本vector_size=10, # 词向量的维度window=2, # 句子中当前单词和预测单词之间的最大距离min_count=1, # 忽略总频率低于此的所有单词 出现的频率小于 min_count 不用作词向量workers=8, # 使用这些工作线程来训练模型(使用多核机器进行更快的训练)sg=0, # 训练方法 1:skip-gram 0;CBOW。epochs=10 # 语料库上的迭代次数)
2、保存模型或者字向量
#字向量保存
model.wv.save_word2vec_format('word_data.vector', # 保存路径binary=False # 如果为 True,则数据将以二进制 word2vec 格式保存,否则将以纯文本格式保存)
#模型保存
model.save('word.model')
3、nn.Embedding读取gensim模型
model = gensim.models.Word2Vec.load('./word.model')
weights = torch.FloatTensor(model.wv.vectors)
embedding = nn.Embedding.from_pretrained(weights)
embedding.requires_grad = False
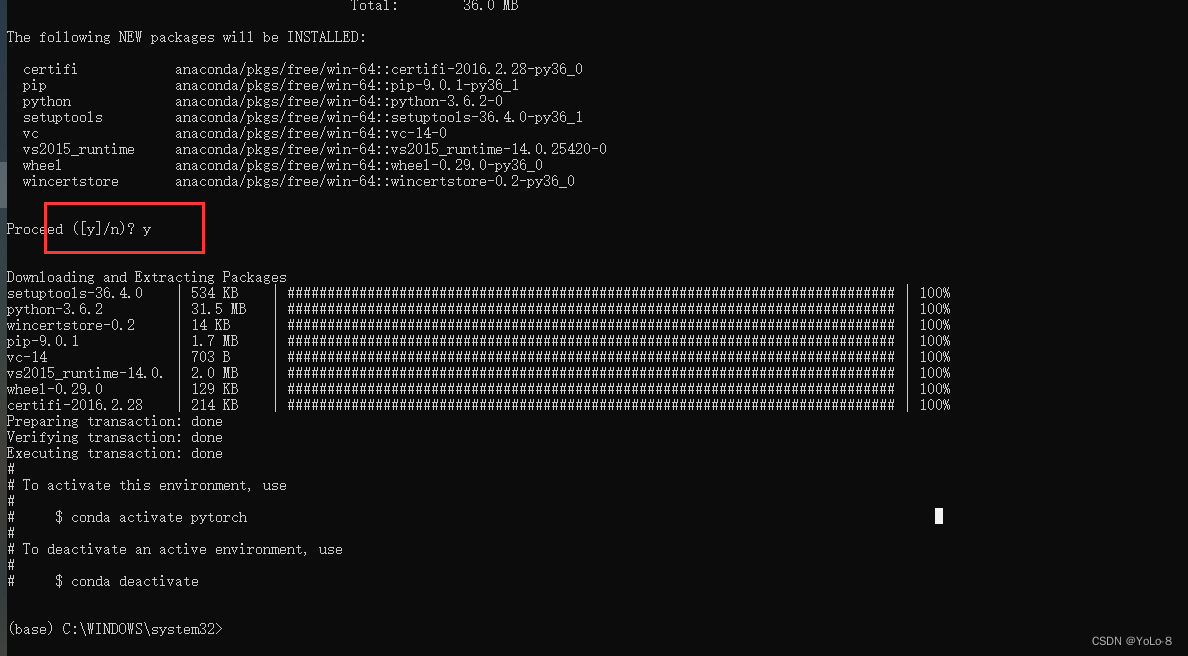
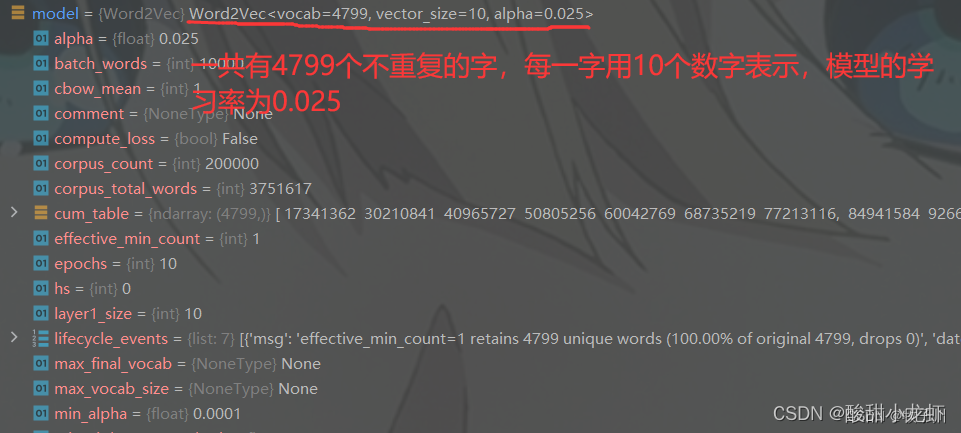
这里懒了,拷贝别人的图,debug就可以看看,简单理解下就是有X个字,就有X行,然后每个字用Y个数字表示,就是Y列,上图X=4799,Y=10。
*也许看了上面你依然会一脸懵(别着急,下面给你举个例子)
4、案例
import gensim
import torch
import torch.nn as nnmodel = gensim.models.Word2Vec.load('./word.model')
weights = torch.FloatTensor(model.wv.vectors)embedding = nn.Embedding.from_pretrained(weights)
embedding.requires_grad = False #训练时候不训练向量query = '天氣'
query_id = torch.tensor(model.wv.vocab['天氣'].index)#下面只是查询,具体的根据你自己的训练即可
gensim_vector = torch.tensor(model[query])
embedding_vector = embedding(query_id)print(gensim_vector==embedding_vector)#首先將 Gensim 的預訓練模型讀取進來,並將其向量轉換成 PyTorch 所需要的資料格式 Tensor,當作 nn.Embedding() 的初始值。
#這裡有個小細節:如果並不打算在模型訓練過程中一併訓練 nn.Emedding(),要記得將其設定為 requires_grad = False。