文章目录
- 📚数据质量评估的五个维度
- 📚口袋妖怪数据质量分析
- 🐇导入库和数据
- 🐇检查数据
- 🐇缺失值分析
- 🐇重复值检测
- 🐇异常值检测
📚数据质量评估的五个维度
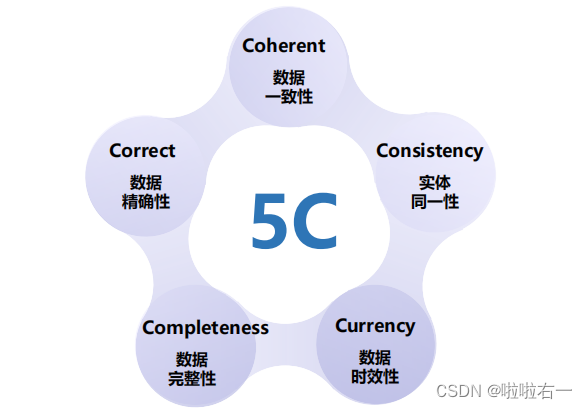
- Coherent: without semantic errors or contradictory data between attributes of an object
- Correct: the extent to which data correctly portrays reality
- Completeness: without missing (null) values in table fields
- Currency: the degree to which data is up-to-date
- Consistency: consistent data values for an entity between different tables
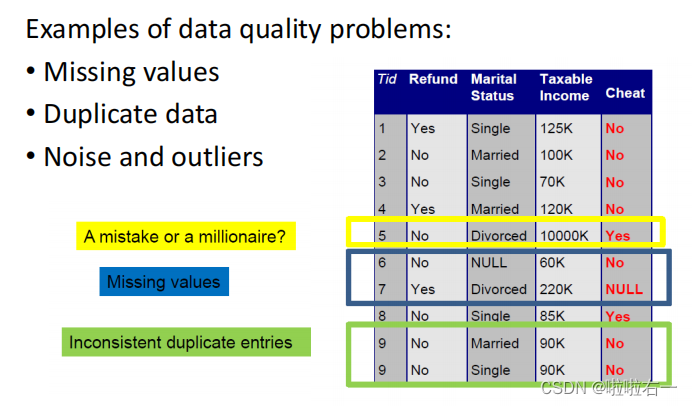
📚口袋妖怪数据质量分析
🐇导入库和数据
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') #忽略警告
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
url = r'./data/Pokemon.csv'
data = pd.DataFrame(pd.read_csv(url)) #打开文件,读取数据
🐇检查数据
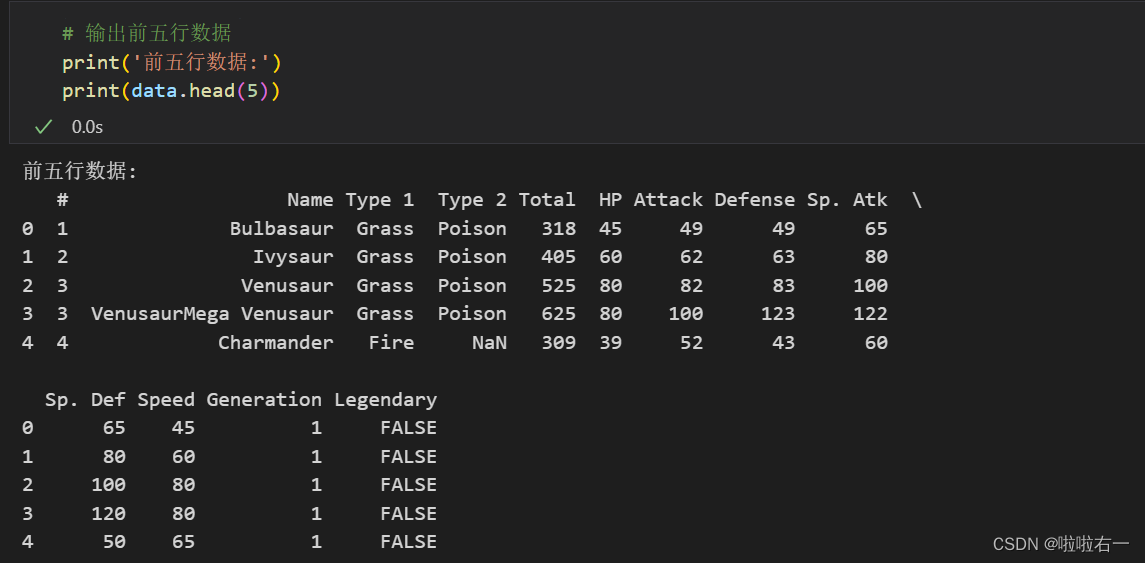
# 输出前五行数据
print('前五行数据:')
print(data.head(5))
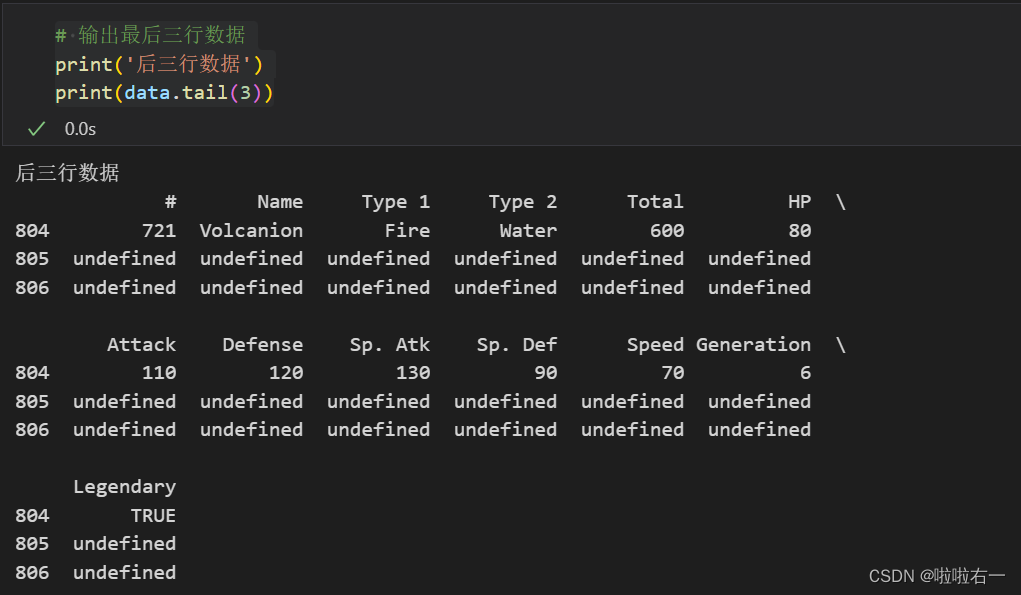
# 输出最后三行数据
print('后三行数据')
print(data.tail(3))
- 删除后两行 :
data = data.iloc[:-2]
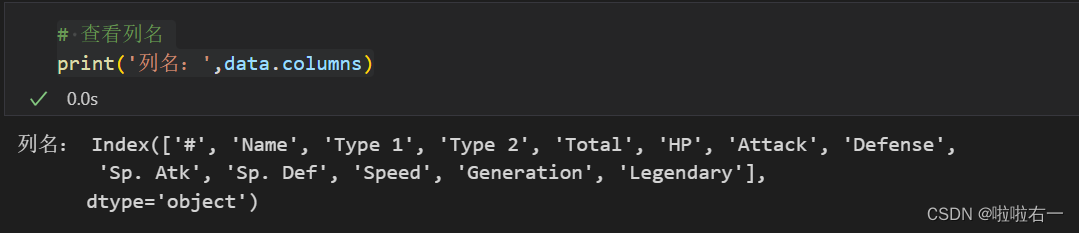
# 查看列名
print('列名:',data.columns)
# 查看行数与列数
print('行数与列数:',data.shape)

# 展示index,datatype和memory相关信息
print(data.info())

🐇缺失值分析
raw, column = data.shape
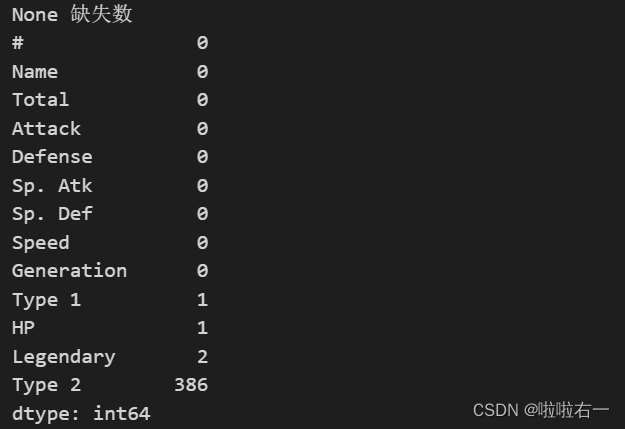
if None:num = data[col].isnull().sum().sort_values()
else:num = data.isnull().sum().sort_values()
print(None, r'缺失数')
print(num)
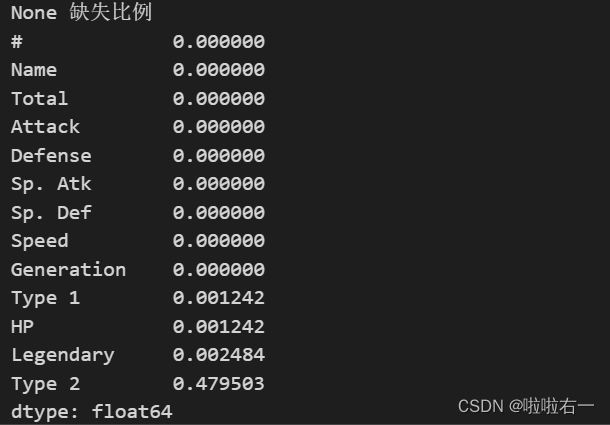
print(None, r'缺失比例')
print(num/raw)
- 将所有缺失值填充为“null”:
data = data.fillna("null")
🐇重复值检测
主要针对#列
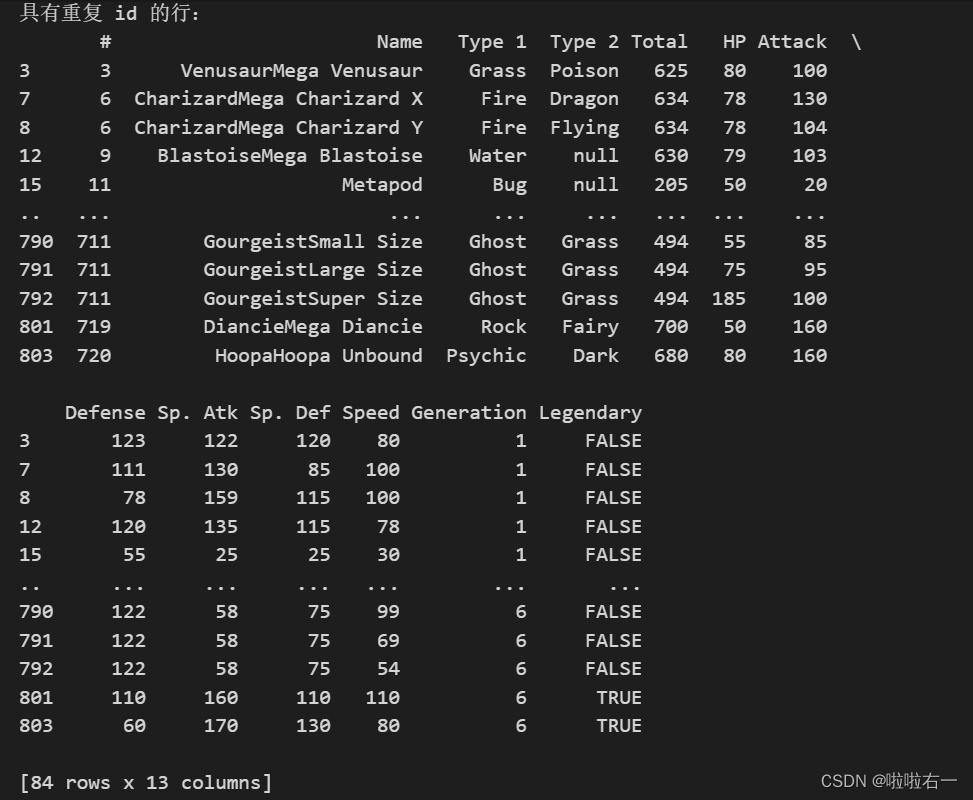
# 检查 'id' 列是否有重复值
duplicate_ids = data.duplicated('#')
# 获取所有具有重复 id 的行
duplicate_rows = data[duplicate_ids]
# 打印具有重复 id 的行
print("具有重复 id 的行:")
print(duplicate_rows)
- 对于
#重复的妖怪只保留第一条记录:data = data.drop_duplicates(['#'],keep='first')
🐇异常值检测
- 离群值
data['Attack'] = data['Attack'].astype(float) data['Defense'] = data['Defense'].astype(float) data['Sp. Atk'] = data['Sp. Atk'].astype(float) data['Sp. Def'] = data['Sp. Def'].astype(float) data['Speed'] = data['Speed'].astype(float) data.boxplot(column=['Attack','Defense','Sp. Atk','Sp. Def','Speed']) plt.show()
-
检查
Generation列是否存在非数字值non_numeric_generation = pd.to_numeric(data['Generation'], errors='coerce').isna() print(data[non_numeric_generation])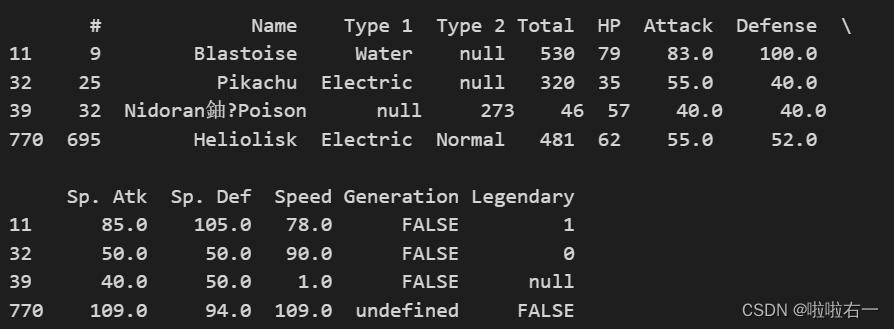
data = data[~non_numeric_generation]
-
检查
Legendary列除了TRUE和FALSE之外的值filtered_data = data[~data['Legendary'].isin(['TRUE', 'FALSE'])] print(filtered_data)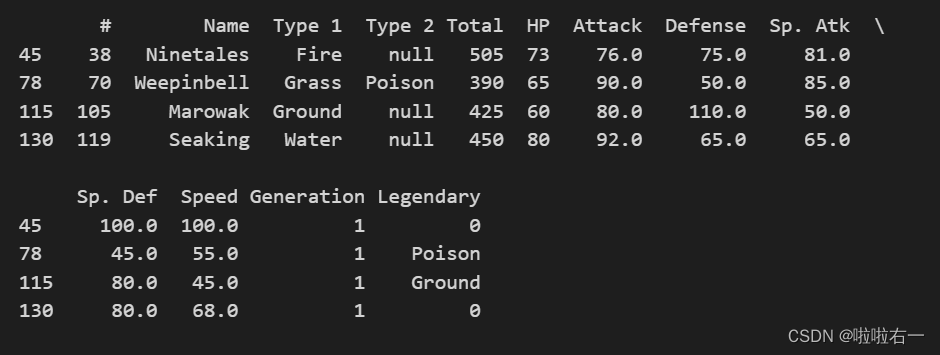
data = data.drop(filtered_data.index)