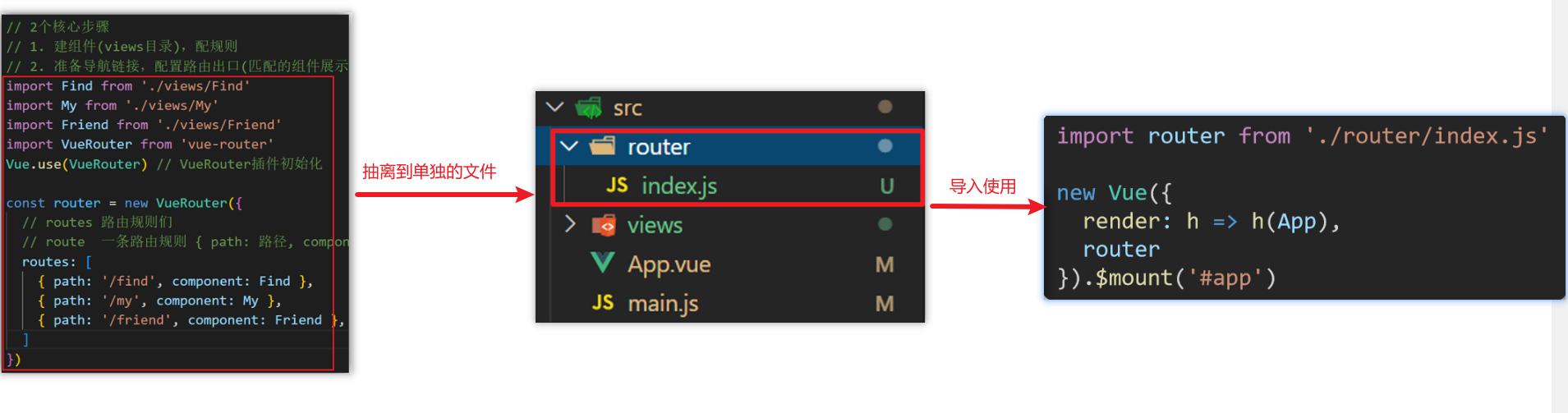
使用过“框架”的同学都能感受到“框架”带来的方便。所谓”框架“本质上就是一系列代码安排帮助我们完成脏活累活,或者复杂的工作流程后,把处理结果交给我们提供的代码。本节我们要完成的 c 语言模板也是一个框架,它也需要做一系列脏活累活,例如读取代码文件里面的内容,然后交给词法识别模块进行处理。其中还有一部分“复杂工作流程”,那就是识别语言对应的正则表达式,将其构建成 DFA 状态机,形成跳转表,将跳转表转换为基于 C 语言的二维数组和对应的调用代码,这些工作则是我们前面在 GoLex 工作中完成的内容,我们需要将对应的二维数组拷贝到本节要创建的 c 语言模板中,当状态机针对输入的字符串完成识别工作后,需要把结果提交给我们提供的处理代码,这些代码就是 input.lex 文件中定义在正则表达式后面的 action 代码。
我们要完成的 c 语言模板代码,首先需要具备的功能是将字符串从文件中读取,然后将其提交给状态机识别,因此我们的第一步工作就是完成一个基于 c 语言的输入缓存模块,由于词法解析需要频繁的将字符串从文件中进行读取,因此输入缓存模块的设计对整个词法解析的应用效率有很大影响,我们希望输入缓存模块能实现如下几点要求:
1,模块对应的函数执行速度要尽可能快,这就需要尽可能少的去对字符串进行拷贝操作。
2,要能支持多个字符的预读取和回退
3,要能支持一定长度的字符串读入
4,要能随时访问当前识别的字符串和上次已经识别好的字符串。
5,尽可能减少磁盘文件读取
为了实现上面约束,我们把缓冲区的设置如下:
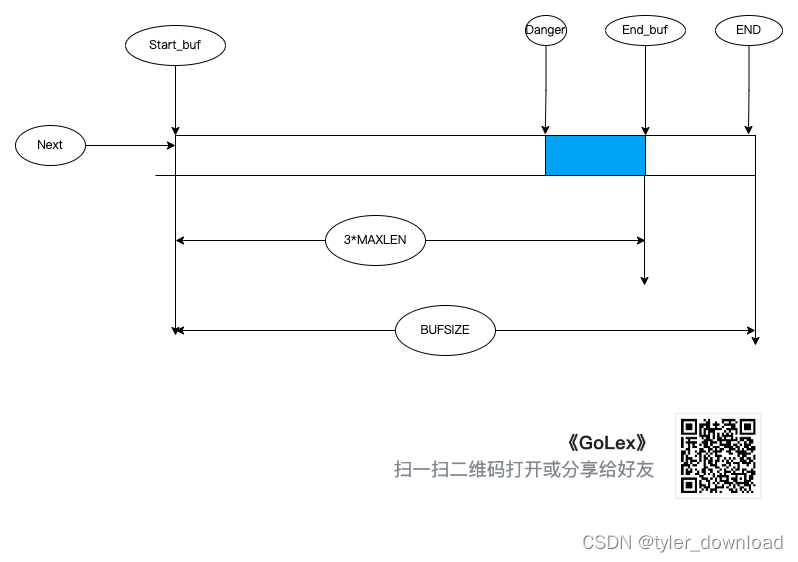
如上图所示,Start_buf 是指向缓冲区开头的指针, END 是指向缓冲区末尾的指针。我们在缓存数据时,不能将整个缓冲区全部用完,其中 Start_buf 到 End_buf 这段区域用来存储数据,End_buf 到 END 这段区域没有使用,也就是这段区域会浪费掉。整个缓冲区的大小用 BUFSIZE 表示,用于存储数据的部分大小为 3*MAXLEN,其中 MAXLEN 表示我们一次能识别的字符串长度,Next 指向下一个要读取字符在缓冲区中的位置。Danger 是一个特定标志位,如果 Next 越过了 Danger,那意味着缓冲区中的有效数据已经很少,此时我们需要从磁盘中读取新的数据放入缓冲区。
输入系统的复杂在于,我们需要很多指针来指向不同特定部位,除了上面已经设置的指针外,我们还需要几个指针,他们分别指向上次读取的字符串起始地址和结束地址,当前正在读取的字符串的起始地址,具体情况如下图所示:
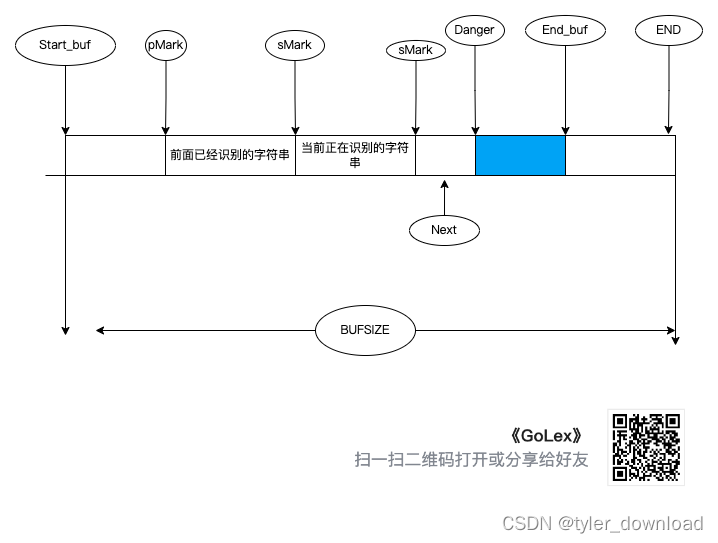
如上图所示,pMark 指向上次已经识别的字符串的开始,sMark 指向上次已经识别的字符串的末尾,它同时也是当前正在识别字符串的开始,eMark(对应上图第二个 sMark,我画错了) 指向当前识别字符串的末尾。你可能有疑问为何 Next 指针会在 e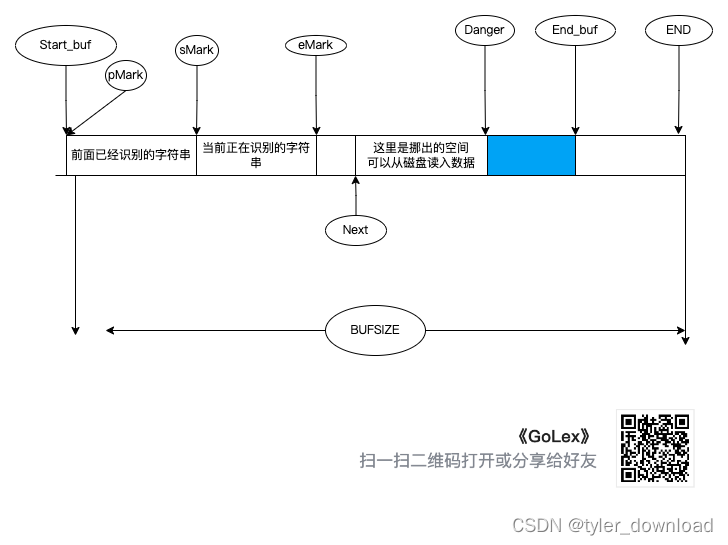
Mark 后面呢,那是因为我们会预读取若干字符,如果这些预读取的字符需要重新放回缓冲区,那么我们直接将 Next 指针调整到 sMark 所在位置即可。
如果 Next 指针所在位置越过了 Danger,那么我们就需要从磁盘读入新的数据。首先我们需要把 pMark 到 End_buf 这段区间的数据往前挪动,直到到 pMark 抵达 Start_buf 所在位置,挪动所产生的新区间就可以让磁盘读入的数据进行填充,具体操作如下图所示:

通常情况下,磁盘读取和数据挪动的开销比较大,一般情况下这种情况出现次数很少,因此不会对程序运行效率产生太大影响。下面我们进入到实现细节,首先我们启动一个空的 c 语言工程,然后在里面创建一个新文件名为 input.c,输入代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <string.h>
#include "debug.h"
#include <unistd.h>#define COPY(d, s, a) memcpy(d, s, a)
//默认情况下字符串从控制台读入
#define STDIN 0//最大运行程序预读取 16 个字符
#define MAXLOOK 16
//允许识别的最大字符串长度
#define MAXLEX 1024//定义缓冲区长度
#define BUFSIZE ((MAXLEX * 3) + (2 * MAXLOOK))
//缓冲区不足标志位
#define DANGER (End_buf - MAXLOOK)
//缓冲区末尾指针
#define END (&Start_buf[BUFSIZE])
//没有可读的字符
#define NO_MORE_CHARS() (Eof_read && Next >= End_buf)typedef unsigned char uchar;
//存储读入数据的缓冲区
PRIVATE uchar Start_buf[BUFSIZE];
//缓冲区结尾
PRIVATE uchar *End_buf = END;
//当前读入字符位置
PRIVATE uchar *Next = END;
//当前识别字符串的起始位置
PRIVATE uchar *sMark = END;
//当前识别字符串的结束位置
PRIVATE uchar *eMark = END;
//上次已经识别字符串的起始位置
PRIVATE uchar *pMark = NULL;
//上次识别字符串所在的起始行号
PRIVATE int pLineno = 0;
//上次识别字符串的长度
PRIVATE int pLength = 0;
//读入的文件急病号
PRIVATE int Inp_file = STDIN;
//当前读取字符串的行号
PRIVATE int Lineno = 1;
//函数 mark_end()调用时所在行号
PRIVATE int Mline = 1;
//我们会使用字符'\0'去替换当前字符,下面变量用来存储被替换的字符
PRIVATE int Termchar = 0;
//读取到文件末尾的标志符
PRIVATE int Eof_read = 0;/*
后面Openp 等函数直接使用文件打开,读取和关闭函数
*/int ii_newfile(char* name) {/*打开输入文件,在这里指定要进行词法解析的代码文件。如果该函数没有被调用,那么系统默认从控制台读取输入。他将返回-1 如果指定文件打开失败,要不然就会返回被打开的文件句柄。在调用该接口打开新文件时,他会自动关闭上次由该接口打开的文件。*/int fd = STDIN; //打开的文件句柄if (!name) {fd = open(name, O_RDONLY);}if (fd != -1) {//打开新文件成功后关闭原先打开的文件if (Inp_file != STDIN) {close(Inp_file);}Inp_file = fd;Eof_read = 0;Next = END;sMark = END;pMark = END;End_buf = END;Lineno = 1;Mline = 1;}return fd;
}//PUBLIC 在 debug.h 中定义为空,这里使用它只是为了代码上说明,函数可以被其他外部模块调用
PUBLIC uchar* ii_text() {//返回当前读取字符串的起始位置return sMark;
}PUBLIC int ii_length() {//返回当前读取字符串的长度return (eMark - sMark);
}PUBLIC int ii_lineno() {//返回当前读取字符串所在的行号return Lineno;
}PUBLIC uchar* ii_ptext() {//返回上次读取的字符串起始位置return pMark;
}PUBLIC int ii_plength() {//返回上次读取字符串的长度return pLength;
}PUBLIC int ii_plineno() {//返回上次读取字符串所在行号return pLineno;
}PUBLIC uchar* ii_mark_start() {//将当前 Next 所指的位置作为当前读取字符串的开始Mline = Lineno;eMark = sMark = Next;return sMark;
}PUBLIC uchar* ii_mark_end() {//将当前 Next 所指位置作为当前读取字符串的结尾Mline = Lineno;eMark = Next;return eMark;
}PUBLIC uchar* ii_move_start() {/*将当前识别字符串的起始地址向右挪动一位,这意味着丢弃当前读取字符串的第一个字符*/if (sMark >= eMark) {/*需要确保当前识别的字符串起始指针不能越过其末尾指针*/return NULL;} else {sMark += 1;return sMark;}
}PUBLIC uchar* ii_to_mark() {/** 将 Next 指针挪动 eMark 所在位置,这意味着我们放弃预读取的字符*/Lineno = Mline;Next = eMark;return Next;
}PUBLIC uchar* ii_mark_prev() {/** 把当前读取的字符串设置为已经读取完成,将其转换成“上一个”已经识别的字符串,* 注意这个函数要再 ii_mark_start 调用前调用,因为 ii_mark_start 会更改 sMark 的值*/pLineno = Lineno;pLength = eMark - sMark;pMark = sMark;return pMark;
}
以上代码实现了输入系统的变量和常量定义,同时提供了各种情况下指针变化的辅助函数实现,函数的具体逻辑请参考 B 站上我的视频讲解和演示,(搜索 coding 迪斯尼)。上面使用到的一些宏定义实现在 debug.h 中,其内容如下:
#ifndef __DEBUG_H
#define __DEBUG_H#ifdef DEBUG#define PRIVATE#define D(x) x#define ND(x)#else#define PRIVATE static#define D(x)#define ND(x) x#endif#define PUBLIC
#endif
下面我们看看输入系统中最复杂的两个操作,一个是从缓冲区中读取字符,其实现如下:
int ii_advance() {/**该函数返回当前 Next 指向的字符,然后将 Next 后移一位,如果Next 越过了 Danger 所在位置,、* 那么我们将促发缓冲区当前数据的移动,然后从文件中读入数据,将数据写入移动后空出来的位置*/static int been_called = 0;if (!been_called) {/** 该函数还没有被调用过,走到这里是第一次调用。我们在这里首先插入一个回车符。其目的在于,如果当前* 正则表达式需要开头匹配,那么就需要字符串起始时以回车开头*/Next = sMark = eMark = END - 1;//开头先插入一个回车符,以便匹配正则表达式要求的开头匹配*Next = '\n';--Lineno;--Mline;been_called = 1;}if (NO_MORE_CHARS()) {//缓冲区没有数据可读取,而且文件也已经全部读取return 0;}if (!Eof_read && ii_flush(0) < 0) {/** ii_flush 负责将缓冲区的数据进行迁移,然后从文件中读取数据,再把数据填入迁移空出来的空间* 如果当前缓冲区的数据已经读取完毕,但是从文件读取数据到缓冲区没有成功,那么直接返回-1*/return -1;}if (*Next == '\n') {/** 在函数第一次调用时,也就是 been_called 取值为 0 时,我们把 Lineno--设置成-1,* 这里将其重新设置为 0*/Lineno++;}int c = *Next;Next++;return c;
}
在整个输入系统的实现中,最不好理解的就是缓冲区的刷新,当 Next 指针越过 DANGER 指针所在位置时,我们就需要读取新数据放入缓冲区,在执行缓冲区刷新时,有一些变量和指针需要预先说明,如下图所示:
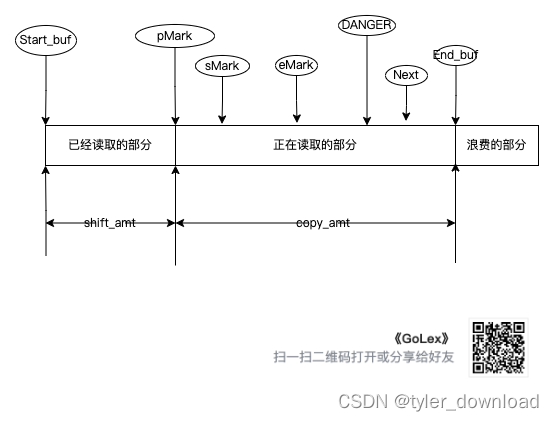
如上图所示,当 Next 指针越过 DANGER 所指位置后,我们就需要刷新缓冲区。此时 pMark如果他不是 NULL 的话,那么它前面的数据都可以丢弃,如果他是 NULL,那么 sMark 前面的数据都可以丢弃,shift_amt 是 Start_buf 到 pMark的距离,如过 pMark 是 NULL,那么就是 Start_buf 到 sMark 的距离,同时 copy_amt 是 pMark 到 End_buf 的距离,如果 pMark 是 NULL,那么就是 sMark 到 End_buf 的距离。
缓冲区刷新的目的就是将 copy_amt 这段区间的数据向前挪动 shift_amt 的长度,挪动后就空出了 shift_amt 长度的空间,此时我们从文件中读取 shift_amt 长度的字符,写入挪动后空出来的空间,对应代码实现如下:
int ii_fillbuf(uchar* starting_at) {/** 从文件读取数据然后写入 starting_at 起始的位置。一次从磁盘读入的字符数量必须是 MAXLEX 的倍数。* 如果从磁盘读取的数据不足 MAXLEX,那意味着我们已经读完整个文件*/int need, got;need = ((END - starting_at) / MAXLEX) * MAXLEX;//如果处于调试模式则输出相关内容D(printf("Reading %d bytes\n", need);)if (need < 0) {//starting_at 的地址越过了缓冲区末尾return 0;}if (need == 0) {return 0;}got = read(Inp_file, starting_at, need);if (got == -1) {//文件读取出错return 0;}End_buf = starting_at + got;if (got < need) {//已经读完整个文件Eof_read = 1;}return got;
}int ii_flush(int force) {/** 如果 force 不是 0,那么强制刷新缓冲区*/int copy_amt, shift_amt;uchar* left_edge;if (NO_MORE_CHARS()) {//没有多余数据可以读取则直接返回return 1;}if (Next >= DANGER || force) {left_edge = pMark? min(sMark, pMark) : sMark;shift_amt = left_edge - Start_buf;if (shift_amt < MAXLEX) {//一次读入的数据要求至少是 MAXLEXif (!force) {return -1;}/** 如果要强制刷新,那么把 Next 前面的数据全部丢弃*/left_edge = ii_mark_start();ii_mark_prev();shift_amt = left_edge - Start_buf;}copy_amt = End_buf - left_edge;//将 left_edge 后面的数据挪动到起始位置memmove(Start_buf, left_edge, copy_amt);if (!ii_fillbuf(Start_buf+copy_amt)) {return -1;}if (pMark) {pMark -= shift_amt;}sMark -= shift_amt;eMark -= shift_amt;Next -= shift_amt;}return 1;
}
在上面代码实现中,ii_flush 用于确定缓存中数据的移动,ii_filbuf 负责从文件中读入数据,如果读入的数据量少于指定的需求量,也就是 got 对应的数值少于 need,那意味着文件中所有数据都已经读取完成,于是代码将标志位 Read_Eof 设置为 1.
最后我们再添加一些用于字符读取和操作的相关函数,其实现如下:
int ii_look(int n) {/** 在基于 Next 的基础上获取前或后 n 个位置的字符,如果n=0,那么返回当前正在被读取的字符,* 由于每读取一个字符后,Next 会向前一个单位,因此当 n=0时,函数返回 Next-1 位置处的* 字符,因此它返回当前正在读取的字符*/uchar* p;p = Next + (n-1);if (Eof_read && p >= End_buf) {//越过了缓冲区末尾直接返回-1return EOF;}return (p < Start_buf || p >= End_buf) ? 0 : *p;
}int ii_pushback(int n) {/** 将当前已经读取的字符进行回退,回退时位置不能越过 sMark,* 成功返回 1,失败返回 0*/while (--n >= 0 && Next >= sMark) {Next -= 1;if (*Next == '\n' || !*Next) {--Lineno;}}if (Next < eMark) {eMark = Next;Mline = Lineno;}return (Next > sMark);
}void ii_term() {/** 为当前识别的字符串设置'\0'作为结尾,c 语言字符串都需要这个字符作为结尾*/Termchar = *Next;*Next = '\0';
}void ii_unterm() {/** 恢复'\0'原来对应的字符,是函数 ii_term 的逆操作*/if (Termchar) {*Next = Termchar;Termchar = 0;}
}int ii_input() {/** 该函数是对 ii_advance 的封装,ii_advance 没有考虑到调用了 ii_term 的情况。* 如果调用了 ii_term,那么 ii_advance 就有可能返回字符'\0',该函数会先调用* ii_unterm 然后再调用 ii_advance*/int rval;if (Termchar) {ii_unterm();rval = ii_advance();ii_mark_end();ii_term();} else {rval = ii_advance();ii_mark_end();}return rval;
}void ii_unput(int c) {/** 将字符 c 替换掉当前所读取字符*/if (Termchar) {ii_unterm();if (ii_pushback(1)) {*Next = c;}ii_term();} else {if (ii_pushback(1)) {*Next = c;}}
}int ii_lookahead(int n) {if (n == 1 && Termchar) {return Termchar;} else {return ii_look(n);}
}int ii_flushbuf() {if (Termchar) {ii_unterm();}return ii_flush(1);
}
上面函数中,需要主要的是 ii_term,它的作用是将 Next 指向的字符替换成’\0’,在 c 语言中,字符串的结尾标志为’\0’,例如’abc\0’在 c 语言中其长度为 3,编译器正是依靠末尾的’\0’来确定字符串的长度。ii_unterm 的作用是取消 ii_term的操作。ii_look 的目的是从 Next 指向位置开始,读取n 个字节之后的字符,注意这里 n 可以是负数,也就是我们能依靠该函数读取 位于 Next 前面或后面 n 个字节之后的字符。
ii_input 是对 ii_advance 的封装调用,它也是用来获取 Next 指针指向的字符,只不过它先判断当前字符是否被’\0’替换过,如果是那么它将返回被替换之前的字符。ii_lookahead 也是对 ii_look 的封装,它主要是在读取字符时,预先考虑是否调用过 ii_term,如果调用过,那么就需要返回被’\0’替换的字符。
以上就是 Lex 词法解析程序输入系统的设置,虽然目前我们仅仅给出了代码设计并对代码逻辑做了一些简单的说明,在下一节我们将对这些代码调用起来,在具体的调用和运行情景下,我们会对当前的实现逻辑有更好的理解,更多详细的讲解和调试演示,请在 B 站搜索 coding 迪斯尼,当前代码下载地址:
链接: https://pan.baidu.com/s/1zGAtP1A-d8CZhqDSIeAtXQ 提取码: p5nk