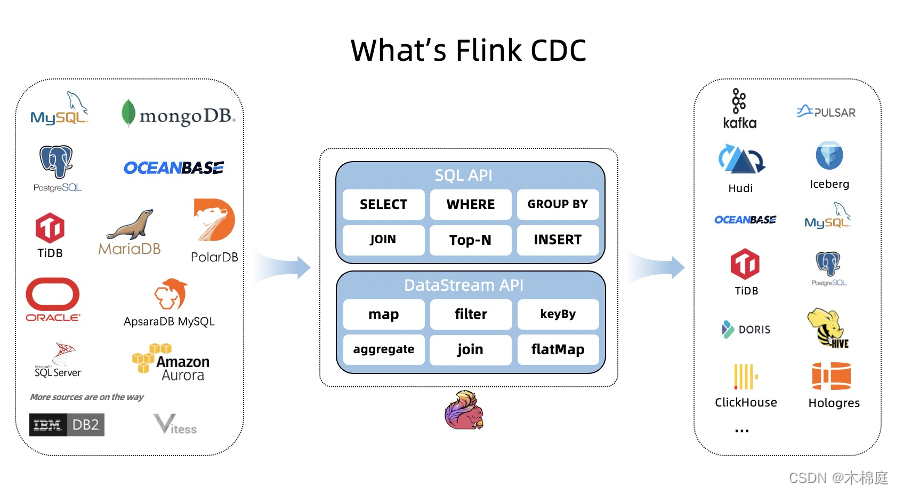
何为FLINK-CDC?
CDC是Change Data Capture的缩写,中文意思是变更数据获取,flink-cdc的作用是,通过flink捕获数据源的事务变动操作记录,包括数据的增删改操作等,根据这些记录可作用于对目标端进行实时数据同步。
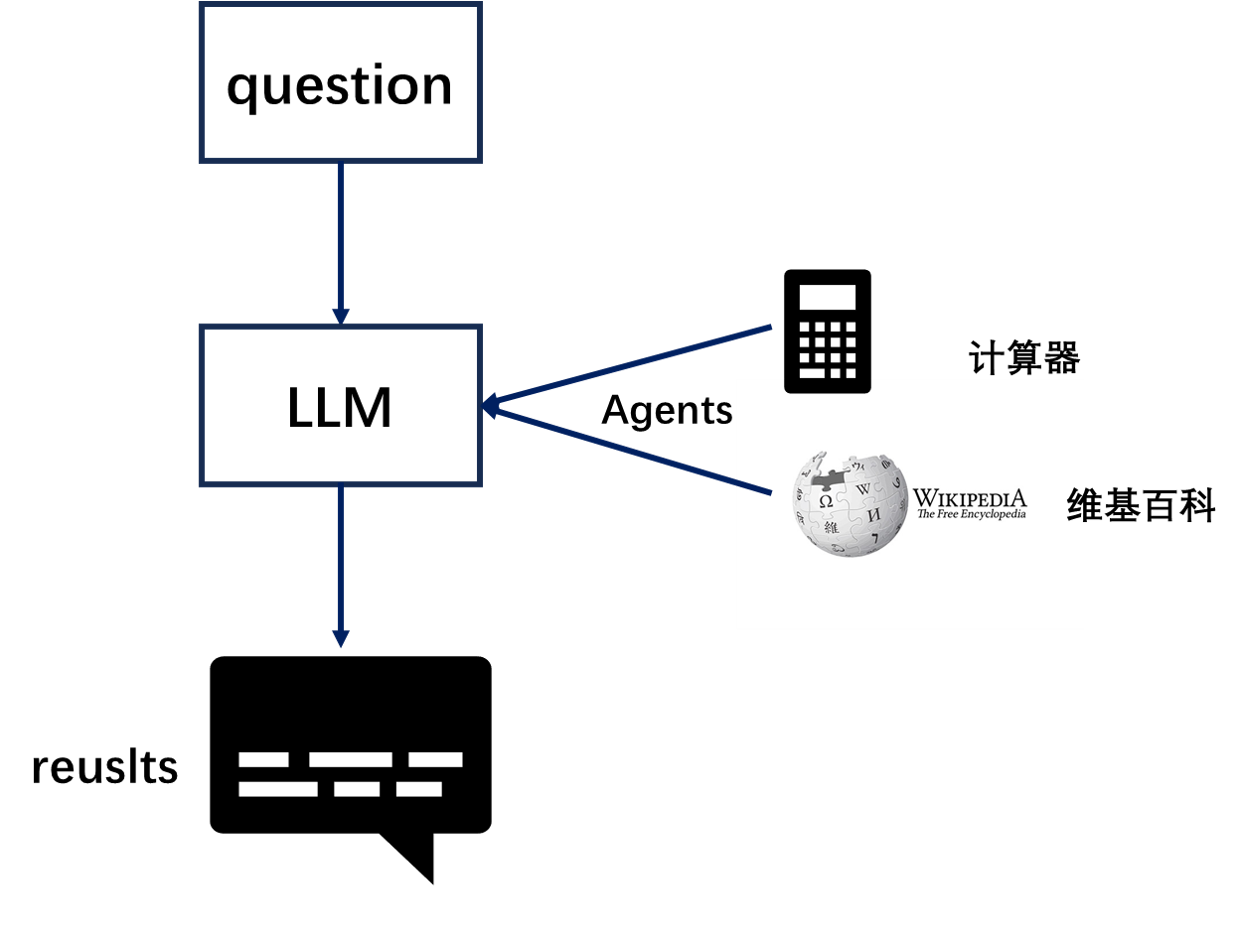
下图是flink-cdc最新支持的数据源类型:
对有记录事务操作的kafka数据源通过flink-cdc实现实时数据同步
kafka的数据源要通过flink-cdc进行实时数据同步,并更新到目标数据库:例如mysql、postgres、oracle等传统关系型数据库,或者是clickhouse、TiDb等关系型数据库,或者是其他,首先要符合以下条件:
- kafka的数据记录了事务操作。
- kakfa的数据描述了主键。
- kafka的数据有严格的更新时间先后顺序,即源端先更新(增、删、改)的数据会先进入kafka。
符合以下几点的kafka数据即可以作为flink-cdc采集的数据源,并实时同步到目标库。
如何通过具体编程来实现以上思路(例子:kafka数据源通过flink-cdc实时入库mysql)
本文不掺杂任何代码,只提供思路,思路大致可按以下步骤实现:
- 新建一个kafka的topic,用于接收kafka格式转换后的数据,topic只设置一个分区(原因是保证cdc读取数据时是顺序读取)。
- 编写一个map函数,用于转换kafka的数据为debezium格式的json,或者转换为canal格式的json,flink的官网分别有这两种格式的样例
debezium:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/formats/debezium/
canal:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/formats/canal/
函数的输入是源kafka-topic的一条数据,格式为字符串,函数的输出为经过转换后的kafka-topic的一条数据,格式为字符串。 - 将2的数据,即map输出的rdd,写入1中的kafka,控制写入的线程数为单线程(原因是保证数据顺序写入)。
- 编写flink-sql建表语句,使用flink的table api,选取kafka connector 和 jdbc connector作为转换后的kafka源端和mysql目标端的连接方式,如果kafka数据源转换为debezium格式则’value.format’ = ‘debezium-json’,如果kafka的数据源转换为canal格式则’value.format’ = ‘canal-json’。
- 编写flink-sql数据插入语句(由kafka数据源的flink表数据插入到mysql也就是jdbc数据源的数据库),再提交flink任务。
思路总结
以上思路使用了kafka数据源转换成flink-cdc可识别的kafka数据源的思想,再利用flink的table api,实现程序内数据源的指定,通过flink-sql,实现数据源之间(源端与目标端之间的数据同步),flink就会对目标端数据源进行实时增删改。