一、为什么要扒一下底层技术
首先我是一个解决方案工程师,为什么要看redis底层的设计呢?总结下来分几点:
1. 让系统跑起来更放心
2. 面试中可以对跟对面的牛马侃大山、吹🐮
3. 虚一点,举一反三,学习一下底层的优秀设计(毕竟是沉淀出来的产物)
二、怎么快速掌握它的底层设计
这里也就是考虑一下怎么科学高效的掌握一门计算,当然每个人的学习方式、接收程度是有区别的,那么只分享一下我的阅读方式。
拿到源码后不要无从下手,可以先看目录可以掌握该篇技术的核心功能模块(当然,排除那些分包不好的),比如拿Redis举例,它的分包结构:
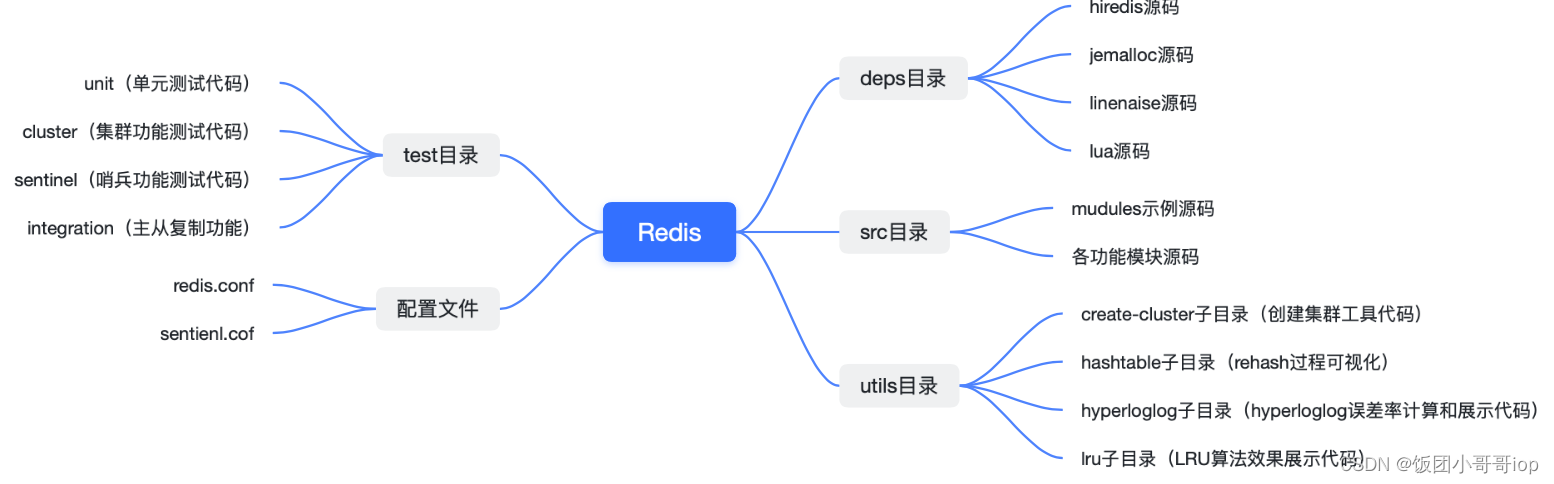 有了总体的分包结构,我们可以根据需求、重要程度有针对性的学习功能模块,再去探索每个功能特性涉及的核心技术能力。
有了总体的分包结构,我们可以根据需求、重要程度有针对性的学习功能模块,再去探索每个功能特性涉及的核心技术能力。
第二点:也是每个培训老师都会讲到的一个事情,抓主线、不要陷入分支漩涡,容易太纠结里面的细节出不来。
第三点:就是要对相应的原理有所了解,然后再开始阅读源码。这是因为源码是原理的体现,如果对 Redis 功能的基本原理不了解,直接阅读源码,就难于理解代码逻辑,增加了代码阅读的难度。
最后一个,也是个人认为最最要的,每学习一个功能模块一定要带着问题,带着目标去阅读,比如:学习sds时,可以给自己提两个问题 : sds是什么? 为什么redis要使用sds 这个类型?
Redis 目录结构
上面已经聊到了为什么要先看目标结构,这里在啰嗦两句:可以想一下,我们在做大型系统设计的时候对于包命名模块都是经过精心设计的,而设计的基本原则大概就是能划归到同一个目录下的代码文件,一般都是具有相近功能目标的。
看下第三方代码库

依赖呗,Redis 作为C语言的生态,底层功能依赖于标准的 glibc 库提供的,比如内存分配、行读写(readline)、文件读写、子进程 / 线程创建等。(但是,性能、内存分配不理想)
另一方面是有些功能是 Redis 运行所需要的,但是这部分功能又会独立于 Redis 进行开发和演进。 Client-Server 架构的系统,访问 Redis 离不开客户端的支撑。
src目录,也就是源码库
 src 目录下只有一个 modules 子目录,其中包含了一个实现 Redis module 的示例代码。剩余的源码文件都是在 src 目录下,没有再分下一级子目录。(纯C语言风格,不同功能模块之间不再设置目录分隔,而是通过头文件包含来相互调用)
src 目录下只有一个 modules 子目录,其中包含了一个实现 Redis module 的示例代码。剩余的源码文件都是在 src 目录下,没有再分下一级子目录。(纯C语言风格,不同功能模块之间不再设置目录分隔,而是通过头文件包含来相互调用)
tests 目录
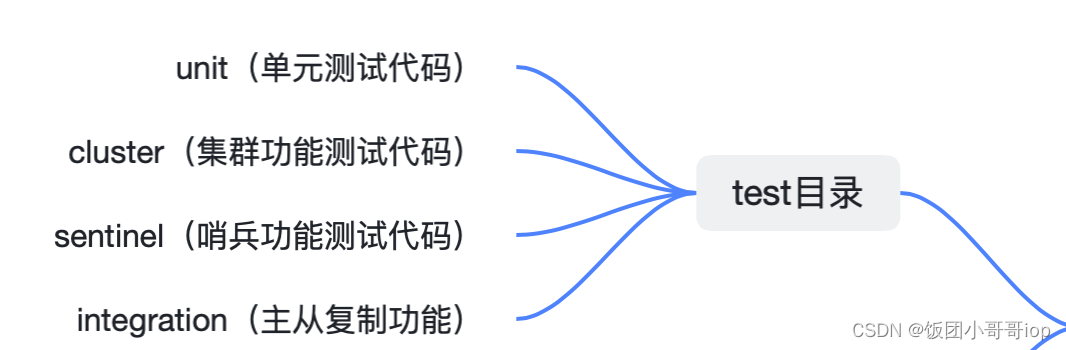
用于功能模块测试和单元测试的代码。而在 Redis 的代码目录中,就将这部分代码用一个 tests 目录统一管理了起来。 Redis 实现的测试代码可以分成四部分,分别是单元测试 (对应 unit 子目录),Redis Cluster 功能测试 (对应 cluster 子目录)、哨兵功能测试 (对应 sentinel 子目录)、主从复制功能测试(对应 integration 子目录)。
utils 目录

这部分主要提供一些工具的支持,做一些主流成的辅助工作,包括:用于创建 Redis Cluster 的脚本、用于测试 LRU 算法效果的程序,以及可视化 rehash 过程的程序
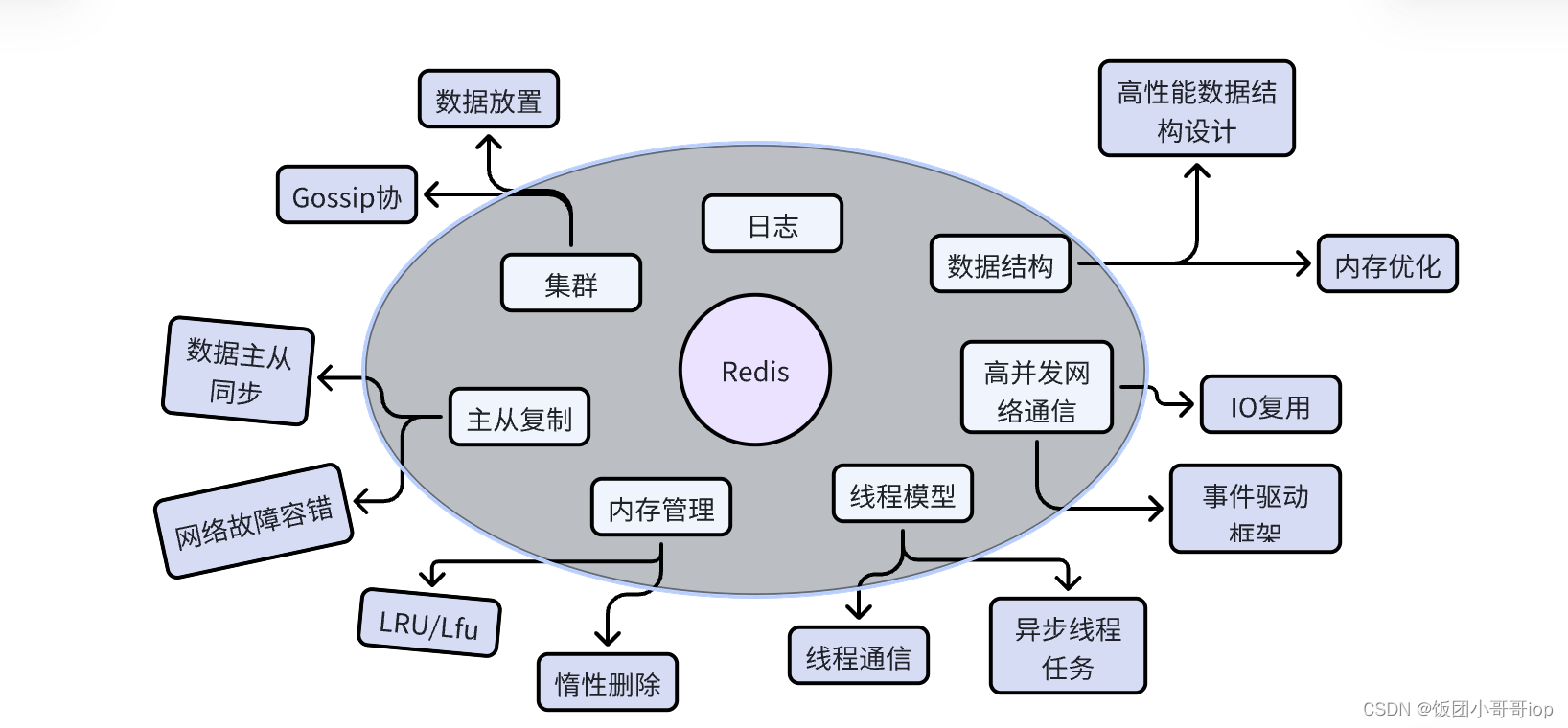
功能汇总
最后一张图,我们来看看读完Redis后,我们应该学到哪些东西?