Scapy 是一款使用纯Python编写的跨平台网络数据包操控工具,它能够处理和嗅探各种网络数据包。能够很容易的创建,发送,捕获,分析和操作网络数据包,包括TCP,UDP,ICMP等协议,此外它还提供了许多有用的功能,例如嗅探网络流量,创建自定义协议和攻击网络的安全测试工具。使用Scapy可以通过Python脚本编写自定义网络协议和攻击工具,这使得网络安全测试变得更加高效和精确。
读者可自行安装Scapy第三方库,其次该工具依赖于PCAP接口,读者可自行安装npcap驱动工具包,具体的安装细节此处就不再赘述。
- 安装Scapy工具:pip install PyX matplotlib scapy
- 安装Npcap驱动:https://npcap.com/dist/
21.2.1 端口扫描基础
网络端口扫描用于检测目标主机上开放的网络端口。端口扫描可以帮助安全专业人员识别存在的网络漏洞,以及识别网络上的服务和应用程序。在进行端口扫描时,扫描程序会发送特定的网络数据包,尝试与目标主机的每个端口进行通信。如果端口处于打开状态,则扫描程序将能够成功建立连接。否则,扫描程序将收到一条错误消息,表明目标主机上的该端口未开放。
常见的端口扫描技术包括TCP连接扫描、SYN扫描、UDP扫描和FIN扫描等。其中,TCP连接扫描是最常用的一种技术,它通过建立TCP连接来识别开放的端口。SYN扫描则利用TCP协议的三次握手过程来判断端口是否开放,而UDP扫描则用于识别UDP端口是否开放。FIN扫描则是利用TCP FIN数据包来探测目标主机上的端口是否处于开放状态。
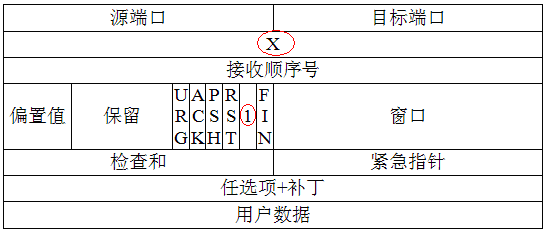
在动手开发扫描软件之前,我们还是要重点复习一下协议相关的内容,这样才能真正理解不同端口扫描方式的原理,首先是TCP协议,TCP(Transmission Control Protocol)传输控制协议是一种面向连接的、可靠的、基于字节流的传输层协议。下图是TCP报文格式:

TCP报文分为头部和数据两部分,其中头部包含以下字段:
-
源端口(Source Port):占用2个字节,表示发送端使用的端口号,范围是0-65535。
-
目的端口(Destination Port):占用2个字节,表示接收端使用的端口号,范围是0-65535。
-
序列号(Sequence Number):占用4个字节,表示数据段中第一个字节的序号。TCP协议中采用序号对数据进行分段,从而实现可靠传输。
-
确认号(Acknowledgement Number):占用4个字节,表示期望收到的下一个字节的序号。TCP协议中采用确认号对接收到的数据进行确认,从而实现可靠传输。
-
数据偏移(Data Offset):占用4个位,表示TCP头部的长度。由于TCP头部长度是可变的,该字段用于指示数据段从哪里开始。
-
保留位(Reserved):占用6个位,保留用于将来的扩展。
-
控制位(Flags):占用6个位,共有6个标志位,分别为URG、ACK、PSH、RST、SYN和FIN。其中,URG、ACK、PSH和RST标志的长度均为1位,SYN和FIN标志的长度为1位。
-
窗口大小(Window Size):占用2个字节,表示发送方可接受的字节数量,用于流量控制。
-
校验和(Checksum):占用2个字节,用于检验数据的完整性。
-
紧急指针(Urgent Pointer):占用2个字节,表示该报文的紧急数据在数据段中的偏移量。
-
选项(Options):可变长度,用于协商TCP参数,如最大报文长度、时间戳等。
对于端口扫描来说我们需要重点关注控制位中所提到的6个标志位,这些标志是我们实现扫描的关键,如下是这些标志位的说明;
- URG:紧急指针标志位,当URG=1时,表明紧急指针字段有效。它告诉系统中有紧急数据,应当尽快传送,这时不会按照原来的排队序列来传送,而会将紧急数据插入到本报文段数据的最前面。
- ACK:当ACK=1时,我们的确认序列号ack才有效,当ACK=0时,确认序号ack无效,在TCP协议中规定所有建立连接的ACK必须全部置为1。
- PSH:当该标志位被设置时,表示TCP数据包需要立即发送给接收方,而无需等待缓冲区填满。这个操作被称为推送操作,即将缓冲区的数据立即推送给接收方。
- RST:当RST=1时,表明TCP连接出现严重错误,此时必须释放连接,之后重新连接,该标志又叫重置位。
- SYN:同步序列号标志位,tcp三次握手中,第一次会将SYN=1,ACK=0,此时表示这是一个连接请求报文段,对方会将SYN=1,ACK=1,表示同意连接,连接完成之后将SYN=0。
- FIN:在tcp四次挥手时第一次将FIN=1,表示此报文段的发送方数据已经发送完毕,这是一个释放链接的标志。
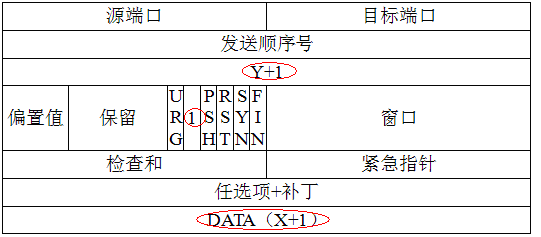
接着我们来具体看一下在TCP/IP协议中,TCP是如何采用三次握手四次挥手实现数据包的通信功能的,如下是一个简单的通信流程图;
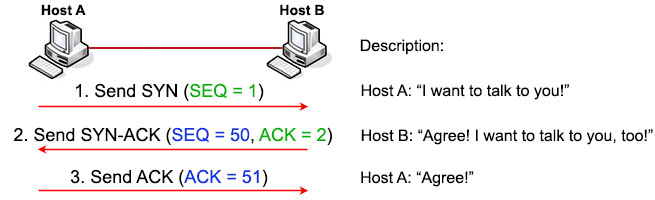
(1) 第一次握手:建立连接时,客户端A发送SYN包(SYN=j)到服务器B,以及初始序号X,保存在包头的序列号(Sequence Number)字段里,并进入SYN_SEND状态,等待服务器B确认。
(2)第二次握手:服务器B收到SYN包,必须确认客户A的SYN(ACK=j+1),同时自己也发送一个SYN包(SYN=k),即SYN+ACK包,此时服务器B进入SYN_RECV状态。
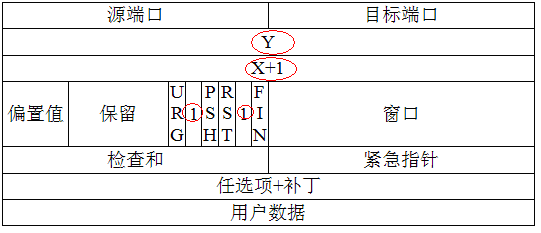
(3) 第三次握手:客户端A收到服务器B的SYN+ACK包,向服务器B发送确认包ACK(ACK=k+1),此包发送完毕,客户端A和服务器B进入ESTABLISHED状态,完成三次握手。至此服务端与客户端之间就可以传输数据了。
21.2.2 ICMP构建与发送
首先我们先来构建并实现一个ICMP数据包,在之前的文章中笔者已经通过C语言实现了数据包的构建,当然使用C语言构建数据包是一件非常繁琐的实现,通过运用Scapy则可以使数据包的构建变得很容易,ICMP数据包上层是IP头部,所以在构造数据包时应先构造IP包头,然后再构造ICMP包头,如下我们先使用ls(IP)查询一下IP包头的结构定义,然后再分别构造参数。
>>> from scapy.all import *
>>> from random import randint
>>> import time
>>>
>>> uuid = randint(1,65534)
>>> ls(IP) # 查询IP头部定义
version : BitField (4 bits) = (4)
ihl : BitField (4 bits) = (None)
tos : XByteField = (0)
len : ShortField = (None)
id : ShortField = (1)
flags : FlagsField (3 bits) = (<Flag 0 ()>)
frag : BitField (13 bits) = (0)
ttl : ByteField = (64)
proto : ByteEnumField = (0)
chksum : XShortField = (None)
src : SourceIPField = (None)
dst : DestIPField = (None)
options : PacketListField = ([])
>>>
>>> ip_header = IP(dst="192.168.1.1",ttl=64,id=uuid) # 构造IP数据包头
>>> ip_header.show() # 输出构造好的包头
###[ IP ]###version = 4ihl = Nonetos = 0x0len = Noneid = 64541flags =frag = 0ttl = 64proto = ipchksum = Nonesrc = 192.168.1.101dst = 192.168.1.1\options \>>> ip_header.summary()
'192.168.1.101 > 192.168.1.1 ip'
上述代码中我们已经构造了一个IP包头,接着我们还需要构造一个ICMP包头,该包头的构造可以使用ICMP()并传入两个参数,如下则是构造好的一个ICMP包头。
>>> ICMP()
<ICMP |>
>>>
>>> icmp_header = ICMP(id=uuid, seq=uuid)
>>>
>>> icmp_header
<ICMP id=0xfc1d seq=0xfc1d |>
>>> icmp_header.show()
###[ ICMP ]###type = echo-requestcode = 0chksum = Noneid = 0xfc1dseq = 0xfc1d
接着我们需要将上述两个包头粘贴在一起,通过使用/将来给你这进行拼接,并在icmp_header后面增加我们所有发送的数据包字符串,最终将构造好的数据包存储至packet变量内,此时输入packet.summary()即可查看构造的数据包字符串。
>>> packet = ip_header / icmp_header / "hello lyshark"
>>>
>>> packet
<IP id=64541 frag=0 ttl=64 proto=icmp dst=192.168.1.1 |<ICMP id=0xfc1d seq=0xfc1d |<Raw load='hello lyshark' |>>>
>>>
>>> packet.summary()
'IP / ICMP 192.168.1.101 > 192.168.1.1 echo-request 0 / Raw'
>>>
当我们构造好一个数据包后,下一步则是需要将该数据包发送出去,对于发送数据包Scapy中提供了多种发送函数,如下则是不同的几种发包方式,当我们呢最常用的还是sr1()该函数用于发送数据包并只接受回显数据。
- send(pkt):发送三层数据包,但不会受到返回的结果
- sr(pkt):发送三层数据包,返回两个结果,分别是接收到响应的数据包和未收到响应的数据包
- sr1(pkt):发送三层数据包,仅仅返回接收到响应的数据包
- sendp(pkt):发送二层数据包
- srp(pkt):发送二层数据包,并等待响应
- srp1(pkt):发送第二层数据包,并返回响应的数据包
此处我们就以sr1()函数作为演示目标,通过构造数据包并调用sr1()将该数据包发送出去,并等待返回响应数据到respon变量内,此时通过对该变量进行解析即可得到当前ICMP的状态。
>>> respon = sr1(packet,timeout=3,verbose=0)
>>> respon
<IP version=4 ihl=5 tos=0x0 len=41 id=26086 flags= frag=0 ttl=64 proto=icmp chksum=0x9137 src=192.168.1.1 dst=192.168.1.101 |<ICMP type=echo-reply code=0 chksum=0x177d id=0xfc1d seq=0xfc1d |<Raw load='hello lyshark' |<Padding load='\x00\x00\x00\x00\x00' |>>>>
>>>
>>> respon[IP].src
'192.168.1.1'
>>>
>>> respon[IP].ttl
64
>>> respon.fields
{'options': [], 'version': 4, 'ihl': 5, 'tos': 0, 'len': 41, 'id': 26086, 'flags': <Flag 0 ()>, 'frag': 0, 'ttl': 64, 'proto': 1, 'chksum': 37175, 'src': '192.168.1.1', 'dst': '192.168.1.101'}
上述流程就是一个简单的ICMP的探测过程,我们可以将这段代码进行组合封装实现ICMP_Ping函数,该函数只需要传入一个IP地址即可返回特定地址是否在线,同时我们使用ipaddress.ip_network则可生成一整个C段中的地址信息,并配合threading启用多线程,则可实现一个简单的主机存活探测工具,完整代码如下所示;
from scapy.all import *
from random import randint
import time,ipaddress,threading
import argparse
import loggingdef ICMP_Ping(addr):RandomID=randint(1,65534)packet = IP(dst=addr, ttl=64, id=RandomID) / ICMP(id=RandomID, seq=RandomID) / "hello lyshark"respon = sr1(packet,timeout=3,verbose=0)if respon:print("[+] 存活地址: {}".format(str(respon[IP].src)))if __name__== "__main__":logging.getLogger("scapy.runtime").setLevel(logging.ERROR)#net = ipaddress.ip_network("192.168.1.0/24")parser = argparse.ArgumentParser()parser.add_argument("-a","--addr",dest="addr",help="指定一个IP地址或范围")args = parser.parse_args()if args.addr:net = ipaddress.ip_network(str(args.addr))for item in net:t = threading.Thread(target=ICMP_Ping,args=(str(item),))t.start()else:parser.print_help()
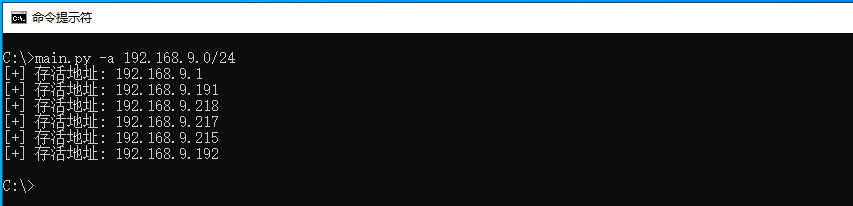
读者可自行运行上述程序片段,并传入main.py -a 192.168.9.0/24表示扫描整个C段,并输出存活主机列表,其中logging模块则用于指定只有错误提示才会输出,其他的警告忽略。扫描结果如下图所示;
接着我们继续实现路由追踪功能,跟踪路由原理是IP路由每经过一个路由节点TTL值会减一,假设TTL值为0时数据包还没有到达目标主机,那么该路由则会回复给目标主机一个数据包不可达,由此我们就可以获取到目标主机的IP地址,我们首先构造一个数据包,并设置TTL值为1,将该数据包发送出去即可看到回显主机的IP信息。
>>> from scapy.all import *
>>> from random import randint
>>> import time
>>>
>>> RandomID=randint(1,65534)
>>> packet = IP(dst="104.193.88.77", ttl=1, id=RandomID) / ICMP(id=RandomID, seq=RandomID) / "hello"
>>> respon = sr1(packet,timeout=3,verbose=0)
>>>
>>> respon
<IP version=4 ihl=5 tos=0xc0 len=61 id=14866 flags= frag=0 ttl=64 proto=icmp chksum=0xbc9a src=192.168.1.1 dst=192.168.1.2 |<ICMP type=time-exceeded code=ttl-zero-during-transit chksum=0xf4ff reserved=0 length=0 unused=None |<IPerror version=4 ihl=5 tos=0x0 len=33 id=49588 flags= frag=0 ttl=1 proto=icmp chksum=0x4f79 src=192.168.1.2 dst=104.193.88.77 |<ICMPerror type=echo-request code=0 chksum=0x30c4 id=0xc1b4 seq=0xc1b4 |<Raw load='hello' |>>>>>
关于如何实现路由跟踪,具体来说一开始发送一个TTL为1的数据包,这样到达第一个路由器的时候就已经超时了,第一个路由器就会返回一个ICMP通知,该通知包含了对端的IP地址,这样就能够记录下所经过的第一个路由器的地址。接着将TTL值加1,让其能够安全的通过第一个路由器,而第二个路由器的的处理过程会自动丢包,发通包超时通知,这样记录下第二个路由器IP,由此能够一直进行下去,直到这个数据包到达目标主机,由此打印出全部经过的路由器。
将上述跟踪过程自动化,就可以完成数据包的跟踪,其Python代码如下所示。
from scapy.all import *
from random import randint
import time,ipaddress,threading
from optparse import OptionParser
import loggingdef TraceRouteTTL(addr):for item in range(1,128):RandomID=randint(1,65534)packet = IP(dst=addr, ttl=item, id=RandomID) / ICMP(id=RandomID, seq=RandomID)respon = sr1(packet,timeout=3,verbose=0)if respon != None:ip_src = str(respon[IP].src)if ip_src != addr:print("[+] --> {}".format(str(respon[IP].src)))else:print("[+] --> {}".format(str(respon[IP].src)))return 1else:print("[-] --> TimeOut")time.sleep(1)if __name__== "__main__":logging.getLogger("scapy.runtime").setLevel(logging.ERROR)parser = OptionParser()parser.add_option("-a","--addr",dest="addr",help="指定一个地址或范围")(options,args) = parser.parse_args()if options.addr:TraceRouteTTL(str(options.addr))else:parser.print_help()
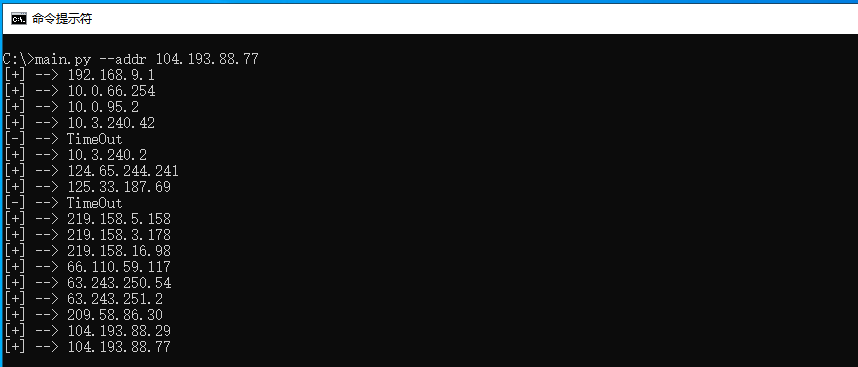
读者可自行运行上述程序片段,并传入main.py --addr 104.193.88.77表示跟踪从本机到目标104.193.88.77主机所经过的路由器地址信息,并将扫描结果输出如下图所示;
21.2.3 TCP全连接扫描
TCP Connect 扫描又叫做全连接扫描,它是一种常用的端口扫描技术。在这种扫描中,扫描程序向目标主机发送TCP连接请求包(SYN包),如果目标主机回应了一个TCP连接确认包(SYN-ACK包),则说明该端口处于开放状态。否则,如果目标主机回应了一个TCP复位包(RST包)或者没有任何响应,则说明该端口处于关闭状态。这种扫描技术的优点是准确性高,因为它可以在不建立实际连接的情况下确定目标主机的端口状态。但是,缺点是这种扫描技术很容易被目标主机的防火墙或入侵检测系统检测到。
全连接扫描需要客户端与服务器之间直接建立一次完整的握手,该方式扫描速度慢效率低,我们需要使用Scapy构造完整的全连接来实现一次探测,在使用该工具包时读者应该注意工具包针对flags所代指的标识符RA/AR/SA含义,这些标志是Scapy框架中各种数据包的简写,此外针对数据包的定义有以下几种;
- F:FIN 结束,结束会话
- S:SYN 同步,表示开始会话请求
- R:RST 复位,中断一个连接
- P:PUSH 推送,数据包立即发送
- A:ACK 应答
- U:URG 紧急
- E:ECE 显式拥塞提醒回应
- W:CWR 拥塞窗口减少
实现全链接扫描我们封装并实现一个tcpScan()函数,该函数接收两个参数一个扫描目标地址,一个扫描端口列表,通过对数据包的收发判断即可获取特定主机开放状态;
from scapy.all import *
import argparse
import loggingdef tcpScan(target,ports):for port in ports:# S 代表发送SYN报文send=sr1(IP(dst=target)/TCP(dport=port,flags="S"),timeout=2,verbose=0)if (send is None):continue# 如果是TCP数据包elif send.haslayer("TCP"):# 是否是 SYN+ACK 应答if send["TCP"].flags == "SA":# 发送ACK+RST数据包完成三次握手send_1 = sr1(IP(dst=target) / TCP(dport=port, flags="AR"), timeout=2, verbose=0)print("[+] 扫描主机: %-13s 端口: %-5s 开放" %(target,port))elif send["TCP"].flags == "RA":print("[+] 扫描主机: %-13s 端口: %-5s 关闭" %(target,port))if __name__ == "__main__":logging.getLogger("scapy.runtime").setLevel(logging.ERROR)# 使用方式: main.py -H 192.168.1.10 -p 80,8080,443,445parser = argparse.ArgumentParser()parser.add_argument("-H","--host",dest="host",help="输入一个被攻击主机IP地址")parser.add_argument("-p","--port",dest="port",help="输入端口列表 [80,443,135]")args = parser.parse_args()if args.host and args.port:tcpScan(args.host,eval(args.port))else:parser.print_help()
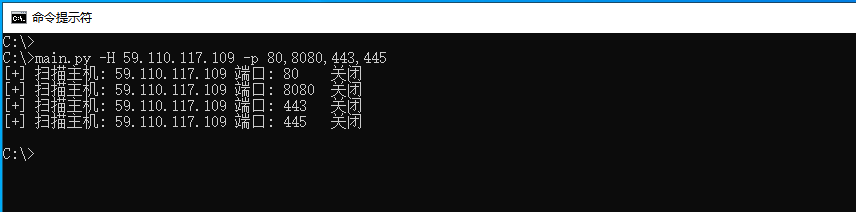
运行上述代码片段,并传入59.110.117.109地址以及,端口80,8080,443,445程序将依次扫描这些端口,并输出如下图所示;

21.2.4 SYN半开放扫描
TCP SYN扫描又称半开式扫描,该过程不会和服务端建立完整的连接,其原理是利用了TCP协议中的一个机制,即在TCP三次握手过程中,客户端发送SYN包到服务端,服务端回应SYN+ACK包给客户端,最后客户端回应ACK包给服务端。如果服务端回应了SYN+ACK包,说明该端口是开放的;如果服务端回应了RST包,说明该端口是关闭的。
TCP SYN扫描的优点是不会像TCP Connect扫描那样建立完整的连接,因此不会留下大量的日志,可以有效地隐藏扫描行为。缺点是在扫描过程中会产生大量的半连接,容易被IDS/IPS等安全设备检测到,而且可能会对目标主机造成负担。
SYN扫描不会和服务端建立完整的连接,从而能够在一定程度上提高扫描器的效率,该扫描方式在代码实现上和全连接扫描区别不大,只是在结束到服务端响应数据包之后直接发送RST包结束连接,上述代码只需要进行简单修改,将send_1处改为R标志即可;
from scapy.all import *
import argparse
import loggingdef tcpSynScan(target,ports):for port in ports:# S 代表发送SYN报文send=sr1(IP(dst=target)/TCP(dport=port,flags="S"),timeout=2,verbose=0)if (send is None):continue# 如果是TCP数据包elif send.haslayer("TCP"):# 是否是 SYN+ACK 应答if send["TCP"].flags == "SA":# 发送ACK+RST数据包完成三次握手send_1 = sr1(IP(dst=target) / TCP(dport=port, flags="AR"), timeout=2, verbose=0)print("[+] 扫描主机: %-13s 端口: %-5s 开放" %(target,port))elif send["TCP"].flags == "RA":print("[+] 扫描主机: %-13s 端口: %-5s 关闭" %(target,port))else:print("[+] 扫描主机: %-13s 端口: %-5s 关闭" %(target,port))if __name__ == "__main__":logging.getLogger("scapy.runtime").setLevel(logging.ERROR)# 使用方式: main.py -H 192.168.1.10 -p 80,8080,443,445parser = argparse.ArgumentParser()parser.add_argument("-H","--host",dest="host",help="输入一个被攻击主机IP地址")parser.add_argument("-p","--port",dest="port",help="输入端口列表 [80,443,135]")args = parser.parse_args()if args.host and args.port:tcpSynScan(args.host,eval(args.port))else:parser.print_help()
同理,我们分别传入被扫描主机IP地址以及需要扫描的端口号列表,当扫描结束后即可输出如下图所示的结果;

21.2.5 UDP无状态扫描
UDP 无状态扫描是一种常见的网络扫描技术,其基本原理与TCP SYN扫描类似。不同之处在于UDP协议是无连接的、无状态的,因此无法像TCP一样建立连接并进行三次握手。
UDP 无状态扫描的基本流程如下:
- 客户端向服务器发送带有端口号的
UDP数据包,如果服务器回复了UDP数据包,则目标端口是开放的。 - 如果服务器返回了一个
ICMP目标不可达的错误和代码3,则意味着目标端口处于关闭状态。 - 如果服务器返回一个
ICMP错误类型3且代码为1,2,3,9,10或13的数据包,则说明目标端口被服务器过滤了。 - 如果服务器没有任何相应客户端的
UDP请求,则可以断定目标端口可能是开放或被过滤的,无法判断端口的最终状态。
读者需要注意,UDP 无状态扫描可能会出现误报或漏报的情况。由于UDP协议是无连接的、无状态的,因此UDP端口不可达错误消息可能会被目标主机过滤掉或者由于网络延迟等原因无法到达扫描主机,从而导致扫描结果不准确。
from scapy.all import *
import argparse
import loggingdef udpScan(target,ports):for port in ports:udp_scan_resp = sr1(IP(dst=target)/UDP(dport=port),timeout=5,verbose=0)if (str(type(udp_scan_resp))=="<class 'NoneType'>"):print("[+] 扫描主机: %-13s 端口: %-5s 关闭" %(target,port))elif(udp_scan_resp.haslayer(UDP)):if(udp_scan_resp.getlayer(TCP).flags == "R"):print("[+] 扫描主机: %-13s 端口: %-5s 开放" %(target,port))elif(udp_scan_resp.haslayer(ICMP)):if(int(udp_scan_resp.getlayer(ICMP).type)==3 and int(udp_scan_resp.getlayer(ICMP).code) in [1,2,3,9,10,13]):print("[+] 扫描主机: %-13s 端口: %-5s 关闭" %(target,port))if __name__ == "__main__":logging.getLogger("scapy.runtime").setLevel(logging.ERROR)parser = argparse.ArgumentParser()parser.add_argument("-H","--host",dest="host",help="")parser.add_argument("-p","--port",dest="port",help="")args = parser.parse_args()if args.host and args.port:udpScan(args.host,eval(args.port))else:parser.print_help()
运行上述代码,并传入不同的参数,即可看到如下图所示的扫描结果,读者需要注意因为UDP的特殊性导致端口扫描无法更精确的判定;
本文作者: 王瑞
本文链接: https://www.lyshark.com/post/1a03a021.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!