目录
一、R的基础
1.1、R的安装
1.2、牛刀小试
1.3、线性关系实例
1.4、工作空间
1.5、R包的使用
包的安装
结果的重用
二、R数据集
2.1、向量
2.2、矩阵
2.3、数组
2.4、数据框
2.5、列表
三、R的常用命令
四、list列表详解
五、数据源导入方法
5.1、键盘输入
5.2、从文本文件导入
5.3、导入Excel数据
六、访问MYSQL数据库
一、R的基础
1.1、R的安装
提示:想要R语言和RStudio安装包的私信我。
第一步:双击安装包

第二步:一直下一步,选择安装路径
这里最好不要放到C盘,也不要有中文路径,空格路径。
第三步:一直无脑下一步,等待安装即可
第四步:双击桌面R图标

1.2、牛刀小试
我们来编写一段代码:
x <- rnorm(3)
x
第一句代码表示随机生成3个数字赋值给变量x。
第二句代码表示获取变量x。
1.3、线性关系实例
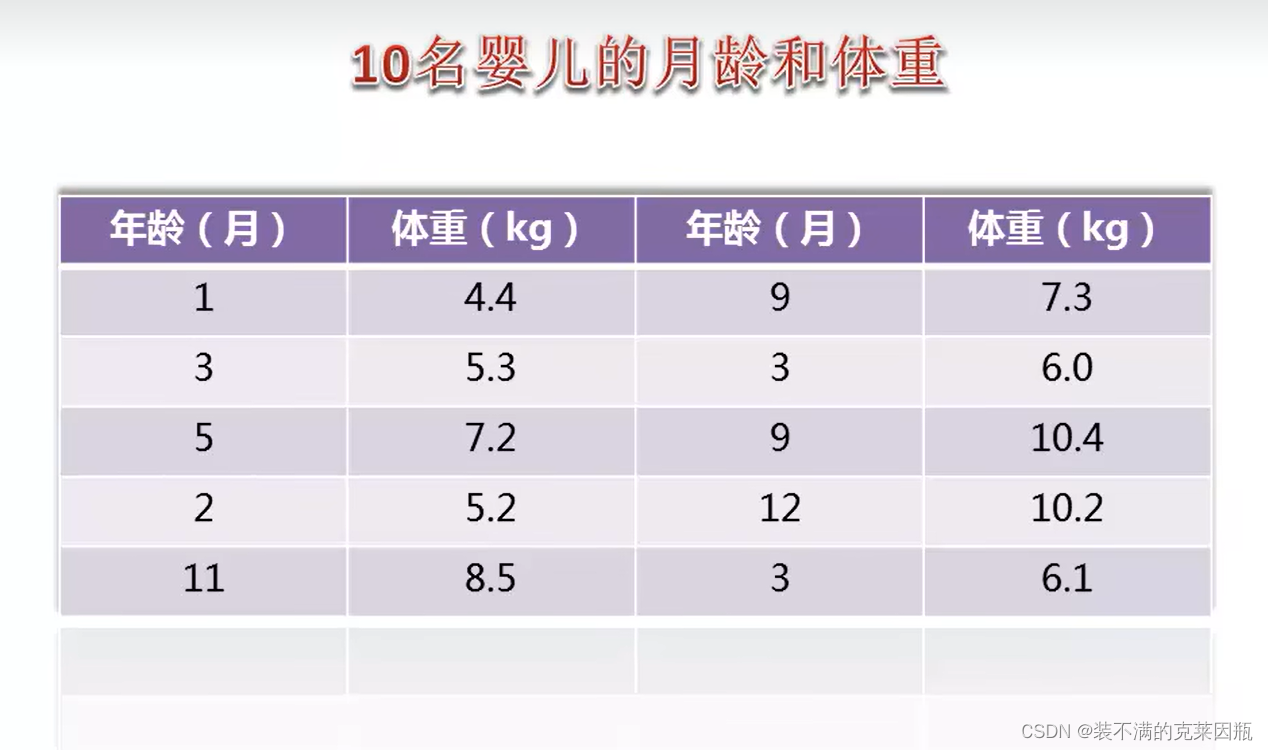
> age <- c(1,3,5,2,11,9,3,9,12,3) # 年龄数据集
> weight <- c(4.4,5.3,7.2,5.2,8.5,7.3,6.0,10.4,10.2,6.1) # 体重数据集
>
> mean(weight) # 体重平均数
[1] 7.06
> sd(weight) # 体重标准差
[1] 2.077498
> cor(age,weight) # 年龄和体重的线性关系
[1] 0.9075655
> plot(age,weight) # 画图表示关系
> 
1.4、工作空间
就是代码和文档都放在哪个目录下了,最好一个项目一个工作空间。
> getwd() # 获取你所在的工作空间
[1] "C:/Users/DELL/Documents"如果你不喜欢这个目录,你可以通过setwd("c:/Users/')去修改。
1.5、R包的使用
R自带了一系列默认包(包括base、datasets、graphics、methods等等),它们提供了种类繁多的默认函数和数据集。
包的安装
比如我想安装名为car的包,使用如下命令:
install.packages("car")这时他会提示你使用哪个镜像来下载,我们当然要选国内的镜像了,这样下载速度会快。
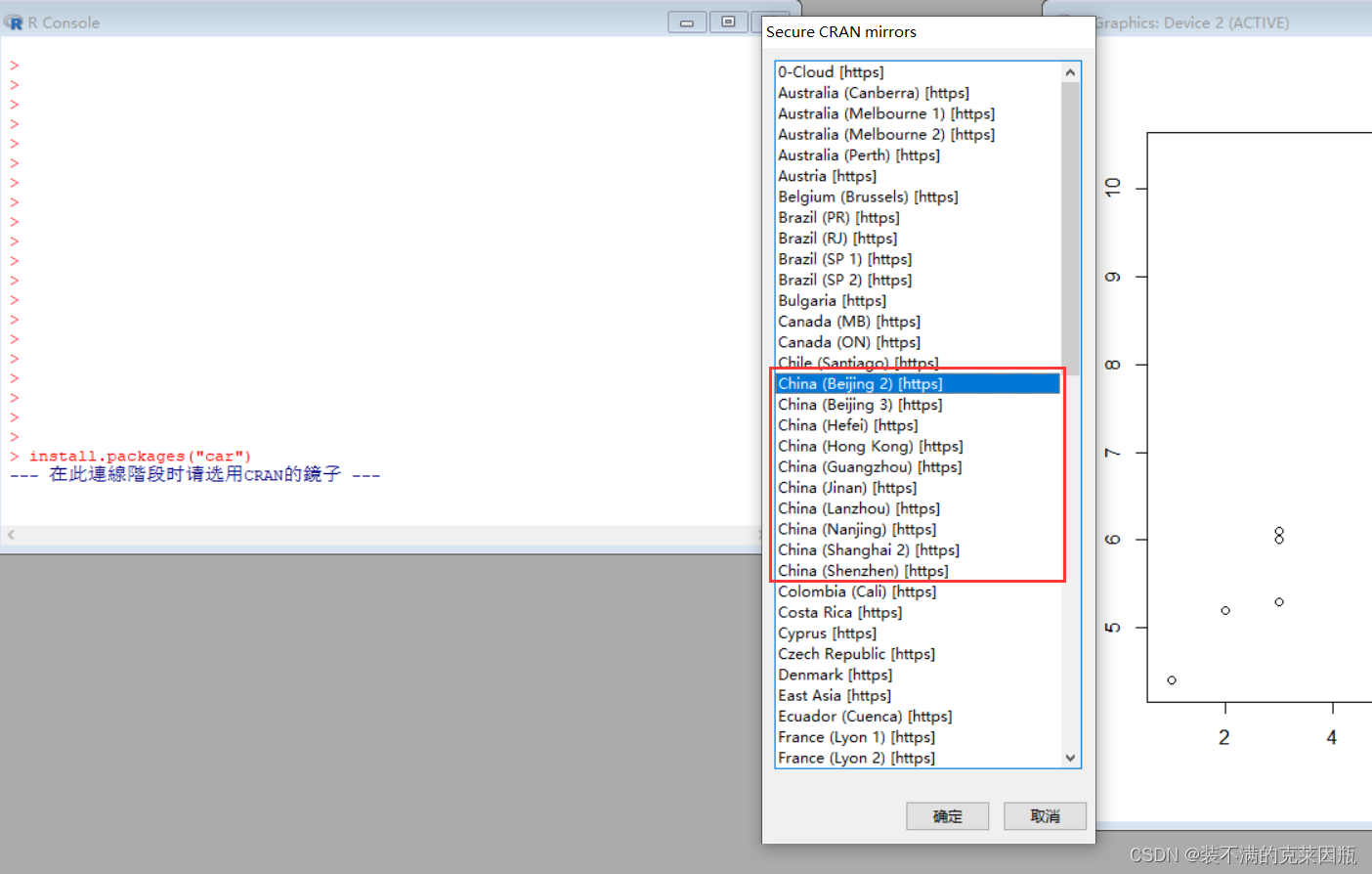
下载完需要把car包绑定到我们的环境下:
library(car)我们输入一行命令测试一下:
> head(mtcars)
出现这个结果就代表安装car包成功了。
结果的重用
R语言的结果可以很好的保存,并且可以作为下一次使用的参数传进去。
比如:
> result <- lm(mpg~wt, data=mtcars) # 做线性拟合
> plot(result)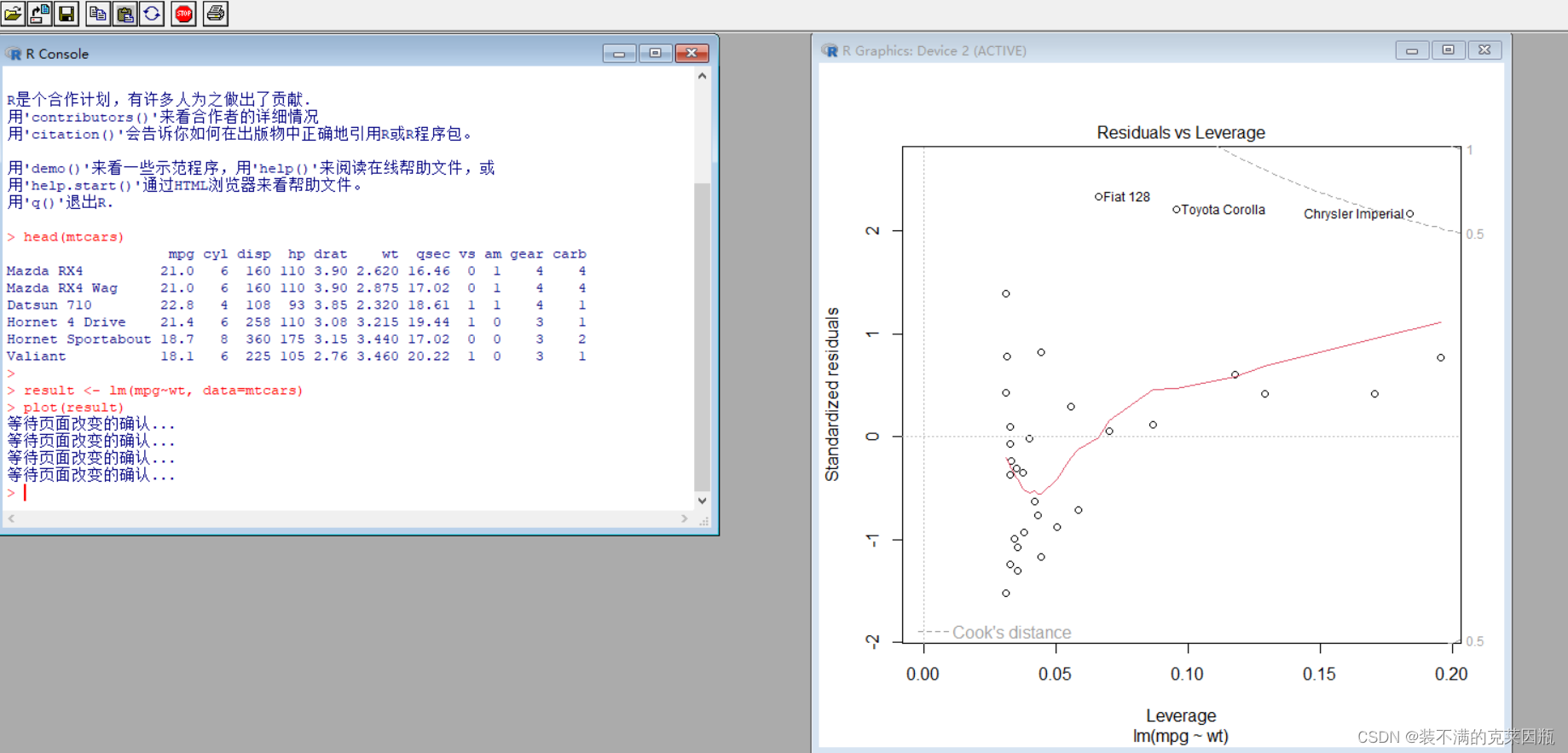
二、R数据集
按照某种格式来创建数据集,是任何数据分析的第一步。
(1)选择一种数据结构来存储。
(2)将数据输入或导入到这个数据结构中。
R拥有许多用于存储数据的对象类型,包括向量、矩阵、数组、数据框和列表。

2.1、向量
其实就是一个一维数组,而且里面的元素必须是相同类型的。
比如:
> a <- c(1,2,3,4,5,6) # 创建一个向量数据集,里面都是相同类型的
> a
[1] 1 2 3 4 5 6
>
> a[2] # 通过下标取出相应的元素
[1] 2
> a[5]
[1] 5
> 2.2、矩阵
是二维数据,并且元素类型必须一致。
比如:
> y <- matrix(5:24, nrow=4, ncol=5) #创建5-24位数字,4行5列的矩阵数据集
> y[,1] [,2] [,3] [,4] [,5]
[1,] 5 9 13 17 21
[2,] 6 10 14 18 22
[3,] 7 11 15 19 23
[4,] 8 12 16 20 24
> > x <- c(2,45,68,94)
> rnames <- c("R1","R2") # 创建矩阵行名
> cnames <- c("C1","C2") # 创建矩阵列名
> newMatrix <- matrix(x, nrow=2, ncol=2, byrow=TRUE, dimnames=list(rnames,cnames))
> newMatrixC1 C2
R1 2 45
R2 68 94
> 2.3、数组
与矩阵相似,但它的维度是大于2的。
比如:
> dim1 <- c("A1","A2","A3")
> dim2 <- c("B1","B2")
> dim3 <- c("C1","C2","C3","C4")
> d <- array(1:24, c(3,2,4), dimnames=list(dim1,dim2,dim3)) # 生成4个矩阵,每一个都是3*2的格式
> d
, , C1B1 B2
A1 1 4
A2 2 5
A3 3 6, , C2B1 B2
A1 7 10
A2 8 11
A3 9 12, , C3B1 B2
A1 13 16
A2 14 17
A3 15 18, , C4B1 B2
A1 19 22
A2 20 23
A3 21 24> 获取数组里的元素:
> d[1,2,3] # 取第3个矩阵里的第1行,第二列的数据
[1] 16
> 2.4、数据框
数据框中,可以存在不同类型的数据,比如下面的列表:
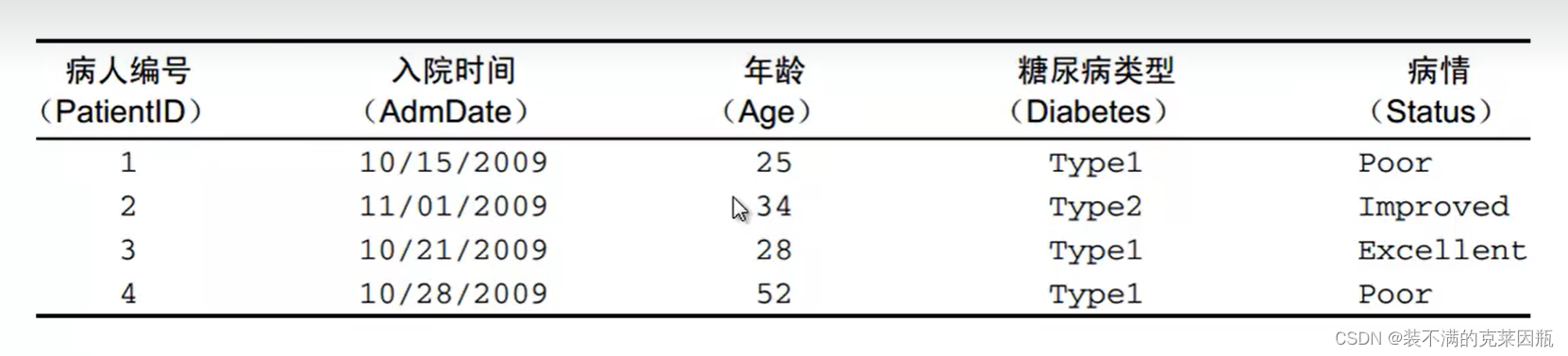
病人编号、入院时间、年龄都是数值类型的,后面糖尿病类型和病情都是字符串类型。
比如:
> patientID <- c(1,2,3,4) # 创建病人编号(第一列数据)
> age <- c(25,34,28,52) # 创建年龄(第二列数据)
> diabetes <- c("Type1", "Type2", "Type3", "Type2") # 创建糖尿病类型(第三列数据)
> status <- c("poor", "Improved", "Excllent", "poor") # 创建病情(第四列数据)
> patientsData <- data.frame(patientID, age, diabetes, status) # 创建数据框数据集
> patientsData # 打印patientID age diabetes status
1 1 25 Type1 poor
2 2 34 Type2 Improved
3 3 28 Type3 Excllent
4 4 52 Type2 poor
>
> patientsData[1:2] # 获取patientsData变量的第一列到第二列数据patientID age
1 1 25
2 2 34
3 3 28
4 4 52
>
> patientsData[c("age")] # 获取patientsData变量的age那列数据age
1 25
2 34
3 28
4 52
>
> patientsData$age # 获取patientsData变量的age那列数据
[1] 25 34 28 52
>
> attach(patientsData) # 将变量绑定,以后就可以直接使用列名打印了,就不用$符号了
The following objects are masked _by_ .GlobalEnv:age, diabetes, patientID, status> age
[1] 25 34 28 52
> 2.5、列表
创建列表:
> g <- "My first list" # 创建字符串
> h <- c(12, 45, 43, 90) #创建向量数据集,里面是数值类型
> j <- matrix(1:10, nrow=2) # 创建矩阵数据集,1-10,两行
> k <- c("A", "B", "C") # 创建向量数据集,里面是字符串类型
> mylist <- list(g, h, j, k) # 创建列表数据集
> mylist
[[1]]
[1] "My first list"[[2]]
[1] 12 45 43 90[[3]][,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10[[4]]
[1] "A" "B" "C">
> mylist[[2]] # 获取列表里第二个元素
[1] 12 45 43 90
>
> mylist[[3]] # 获取列表里第三个元素[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> 三、R的常用命令
(1)查询所有的变量
ls()> ls()
character(0)
> data <- c(1,2,3)
> ls()
[1] "data"(2)移除某个变量
rm(变量名)> rm(data)
> ls()
character(0)(3)获取向量长度
length(变量名)> v <- c(1, 2, 3)
> length(v)
[1] 3(4)获取变量所属类型
mode(变量名)> v <- c(1, 2, 3)
> mode(v)
[1] "numeric"(5)各种方式形成向量
seq(1, 10, 2) # 生成一个从1开始到10结束,步长为2的向量> x <- seq(1, 10, 2)
> x
[1] 1 3 5 7 9rep(5, 10) # 生成10个5的向量> x <- rep(5, 10)
> x[1] 5 5 5 5 5 5 5 5 5 5> x <- rep(1:3, 3)
> x
[1] 1 2 3 1 2 3 1 2 3> x <- c(1, 20, 50, -5, -35, -80)
> x
[1] 1 20 50 -5 -35 -80
> x[x > 0] # 获取大于0的向量
[1] 1 20 50
> x[x < -10 | x > 0] # 获取小于-10或者大于0的向量
[1] 1 20 50 -35 -80
> 四、list列表详解
> mylist <- list(stud.id=1234, stud.name="Tom", stud.marks=c(12, 3, 14, 25, 19)) # 创建一个列表
> mylist # 打印列表
$stud.id
[1] 1234$stud.name
[1] "Tom"$stud.marks
[1] 12 3 14 25 19> mylist[[1]] # 获取列表mylist的第一个元素值
[1] 1234
> mylist[[3]] # 获取列表mylist的第三个元素值
[1] 12 3 14 25 19
> mylist[1] # 获取列表mylist的第一个整元素值
$stud.id
[1] 1234> mode(mylist[[1]]) # 获取列表mylist第一个元素的类型
[1] "numeric"
> mode(mylist[1]) # 获取列表mylist第一个整元素的类型
[1] "list"
> mylist$stud.id # 和mylist[[1]]同理
[1] 1234
> names(mylist) # 获取列表mylist的所有元素名
[1] "stud.id" "stud.name" "stud.marks"
> names(mylist) <- c("id", "name", "marks") # 列表mylist里的元素改名
> mylist
$id
[1] 1234$name
[1] "Tom"$marks
[1] 12 3 14 25 19> mylist$parents <- c("Mna", "Jutice") # 为列表mylist增加新元素parents
> mylist
$id
[1] 1234$name
[1] "Tom"$marks
[1] 12 3 14 25 19$parents
[1] "Mna" "Jutice"> mylist <- mylist[-4] # 列表mylist删除第四个元素
> mylist
$id
[1] 1234$name
[1] "Tom"$marks
[1] 12 3 14 25 19> other <- list(age=19, sex="male") # 创建列表赋值给other变量
> lst <- c(mylist, other) # 将列表mylist和列表other合并成一个列表赋值给lst
> lst
$id
[1] 1234$name
[1] "Tom"$marks
[1] 12 3 14 25 19$age
[1] 19$sex
[1] "male"> unlist(lst) # 将列表转为向量形式,方便循环遍历id name marks1 marks2 marks3 marks4 marks5 age sex
"1234" "Tom" "12" "3" "14" "25" "19" "19" "male"
解释一下unlist()函数:
比如向量我们很容易遍历,就是从1遍历到100,但是list的元素是可以多类型的,比如说list列表中第一个元素是向量,向量里又有1,2,3,4,5元素,那list列表第二个元素是矩阵,矩阵又包含二维数据,那么我们遍历就很麻烦,所以使用unlist函数先转为向量模式,再遍历就方便多了。
五、数据源导入方法
5.1、键盘输入
> mydata <- data.frame(age=numeric(0), gender=character(0), weight=numeric(0)) # 创建数据框,但里面元素只是定义了名字和类型,却没有数据
> mydata <- edit(mydata) # edit的意思是我们要手动键盘录入数据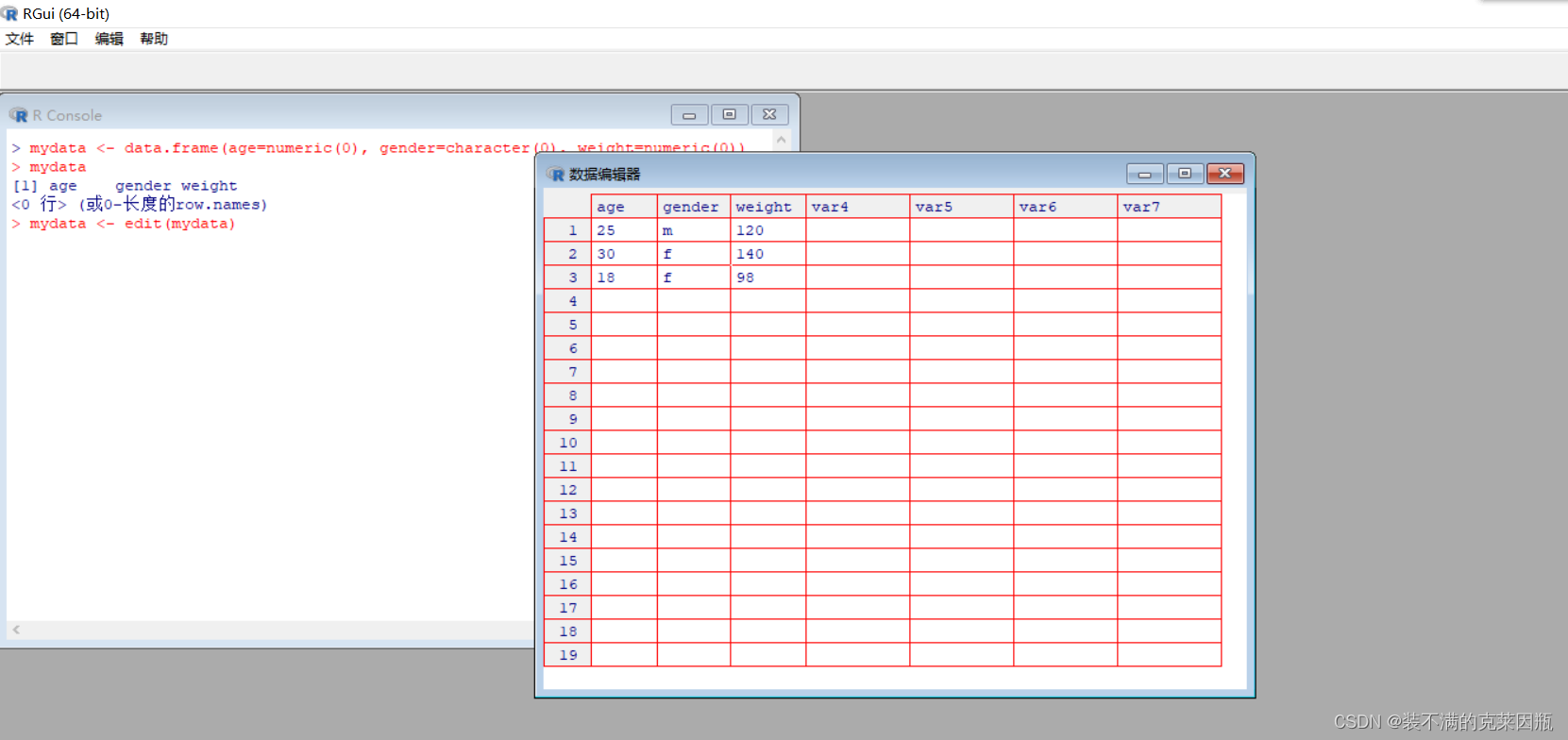
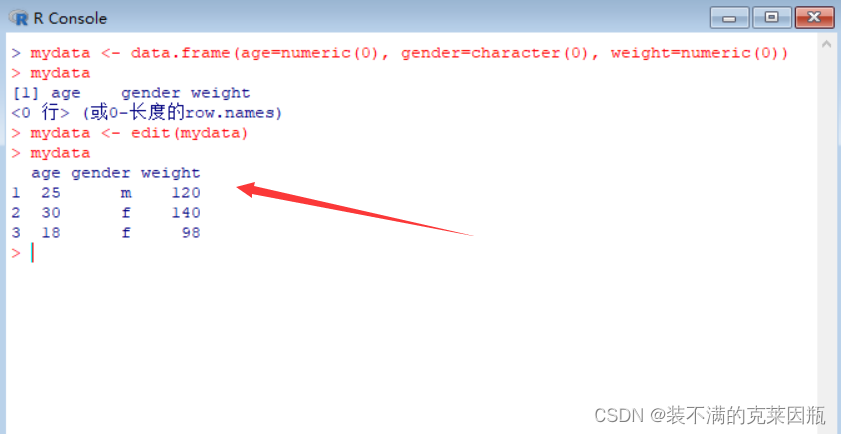
fix(mydata)和mydata <- edit(mydata)是等价的。
5.2、从文本文件导入
先看看数据,是一个叫person.txt的文件,内容是:
id,name,age,school
1,李白,20,哈尔滨工业大学
2,杜甫,30,哈尔滨工程大学
3,白居易,19,哈尔滨理工大学
4,杜牧,23,东北林业大学
5,李清照,27,东北农业大学> mydata <- read.table("D:/Java/R/resources/person.txt", header=TRUE, sep=",", encoding="UTF-8")
> mydataid name age school
1 1 李白 20 哈尔滨工业大学
2 2 杜甫 30 哈尔滨工程大学
3 3 白居易 19 哈尔滨理工大学
4 4 杜牧 23 东北林业大学
5 5 李清照 27 东北农业大学5.3、导入Excel数据
这个不能直接用read.table去读取Excel文件,得先把我们的Excel文件先另存为csv格式,这样就可以读取了。
我们的数据是这样的:
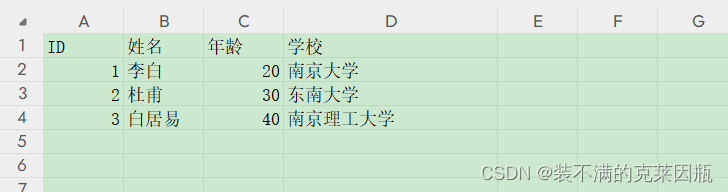
> mydata <- read.table("D:/Java/R/resources/student.csv", header=TRUE, sep=",", encoding="UTF-8")
> mydataID 姓名 年龄 学校
1 1 李白 20 南京大学
2 2 杜甫 30 东南大学
3 3 白居易 40 南京理工大学六、访问MYSQL数据库
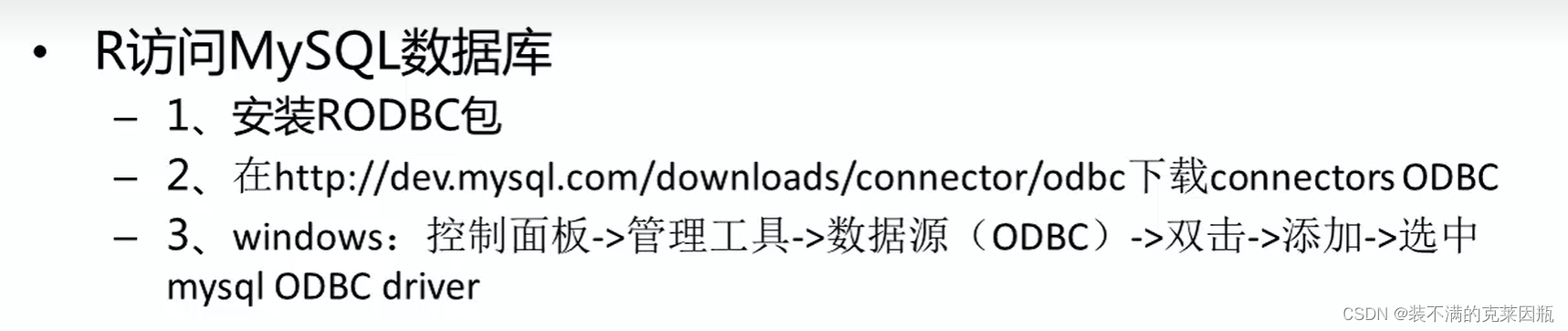
install.packages("RODBC")




![[RISC-V]verilog](https://img-blog.csdnimg.cn/419ffc5d349e4f949c65d5a0a0884d62.png)