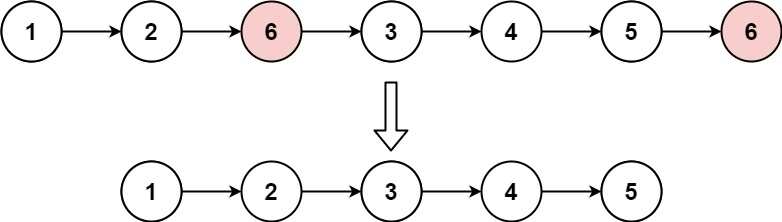
目录
1、数据库分库分表是什么
2、为什么要对数据库分库分表
3、何时选择分库分表
4、⭐分库分表遵循的原则
5、分库分表的方式
6、数据存放在表和库中的规则(算法)
7、分库分表的架构模式
8、分库分表的问题
小结
1、数据库分库分表是什么
数据库分库分表是一种常见的数据库设计和优化策略,用于解决大规模数据存储和查询的性能、容量和扩展性问题。数据库的性能优化有参数优化、缓存及索引、读写分离、分库分表等方案。通过分库分表,将原本存储在单一数据库中的数据,拆分到多个数据库或者多个数据表中。这是为了提高数据库的扩展性和读写性能,解决单一数据库在数据量和并发访问上的瓶颈。
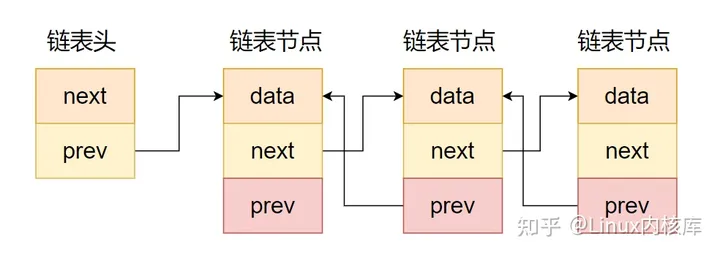
【分库】:将数据按照某种规则或策略划分到多个独立的数据库中。分库可以实现数据的隔离和负载均衡,提高系统的并发处理能力和扩展性。
【分表】:将单个表中的数据按照某种规则或策略划分到多个表中。分表可以降低单个表的数据量,加快查询速度,并且便于管理和维护。
分库分表图示:
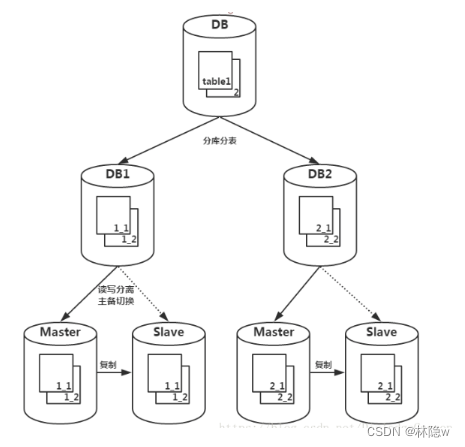
图片来源:分库、分表、分区的区别,傻傻分不清?-阿里云开发者社区
2、为什么要对数据库分库分表
-
提高性能:随着数据量的增加,单个数据库可能无法满足高并发和大规模数据处理的需求。造成数据库慢的根本原因是InnoDB存储引擎,聚簇索引结构的 B+tree 层级变高,磁盘IO变多查询性能变慢。通过将数据分散到多个表和多个数据库中,可以提高系统的读写性能和响应速度。每个表和数据库只需要处理部分数据,减轻了单个数据库的负载压力。
-
扩展性:数据库分表分库提供了水平扩展的能力,可以支持系统的持续增长和负载的均衡分布。当数据量逐渐增加时,可以通过增加更多的表和数据库来分担负载,而不是依赖于垂直扩展(增加服务器的计算和存储能力)。
-
数据隔离:某些业务场景需要对数据进行隔离,例如多租户系统或多个独立的业务模块。通过分表分库,可以将不同租户或业务模块的数据存储在不同的表或数据库中,实现数据的逻辑隔离和安全性。
-
灵活性:分表分库可以根据实际需求进行灵活的数据管理。例如,可以根据数据的访问模式、生命周期或其他特定因素,将数据分散到不同的表或数据库中,以便更好地管理和查询数据。
-
故障隔离:当数据库出现故障或需要进行维护时,分表分库可以减少对整个系统的影响。如果某个表或数据库发生故障,其他表或数据库仍然可以正常运行,从而保证系统的可用性。
3、何时选择分库分表
需要注意的是,数据库分库分表并非适用于所有场景。它引入了额外的复杂性和管理成本,并可能导致跨表查询的开销增加。在决定是否进行分库分表时,需要综合考虑系统的规模、性能需求、维护成本以及未来的扩展计划。在实际应用中,可以根据具体情况选择适合的分库分表策略,并进行性能测试和评估,以确保系统能够满足需求并具备良好的扩展性。
分库分表的主要针对的是现存海量数据访问的性能瓶颈,和对持续激增的数据量所做出的反应。因此,分库分表的关键是看数据量。这个标准因不同公司不同业务等等因素影响,例如:存储占用100G+ ,数据增量每天200w+ ,单表条数1亿条+ ......

图片来源:好好的系统,为什么要分库分表?
4、⭐分库分表遵循的原则
1. 根据业务需求和场景切分
例如,将商品信息和订单信息划分到不同的数据库中。如果数据量较小且性能满足要求,可能不需要进行分表分库。
2. 避免跨库事务
例如商品下单时需要同时操作商品库存和订单表,可以将商品库存信息冗余到订单表中,避免跨库事务的开销。如果业务需要支持跨库事务,就需要选择支持分布式事务的分库方案。
3. 避免跨库Join操作
在订单查询时,应当尽量避免使用多个表之间的跨库Join操作,多表关联查询不易实现性能优化,可以通过字段冗余或表分组等方式来降低跨库Join的可能性。
4. 合理划分数据范围
将相关性较高的数据放在同一个表或同一个库中,可以减少跨表查询的开销。例如,订单表和订单明细表通常会被放在同一个库中,以便更高效地查询订单及其相关的明细信息。
5. 合理选择分片键
分片键的选择很关键,需要根据数据的特点和查询模式进行选择,在进行分表分库时,应该尽量保持数据的均衡分布,避免某个表或库成为热点。这可以通过合理的分片策略和负载均衡机制来实现。
6. 合理规划索引
根据查询场景和数据分布规律,选择合适的索引策略,提高查询效率。
7. 合理配置硬件资源
分库分表会增加系统的硬件资源消耗,需要根据实际情况进行合理配置,保证系统的性能和稳定性。
8. 定期维护和监控
分库分表后会增加系统的复杂性,需要定期进行维护和监控,及时发现和解决问题,确保系统的稳定运行。
9. 灵活扩展和迁移
根据业务的发展,需要灵活地扩展和迁移数据库和数据表,保证系统的可扩展性。例如,选择合适的分片键、设计良好的数据迁移方案以及建立监控和管理机制等都是提高可维护性和可管理性的重要因素。
10. 备份和恢复策略
分库分表后,备份和恢复的策略也需要进行相应调整,确保数据的安全性和可靠性。
5、分库分表的方式
分库分表的核心就是对数据的分片(Sharding)并相对均匀的路由在不同的库、表中,以及分片后对数据的快速定位与检索结果的整合。因此,分库与分表可以从:垂直(纵向)和 水平(横向)两种纬度进行拆分。
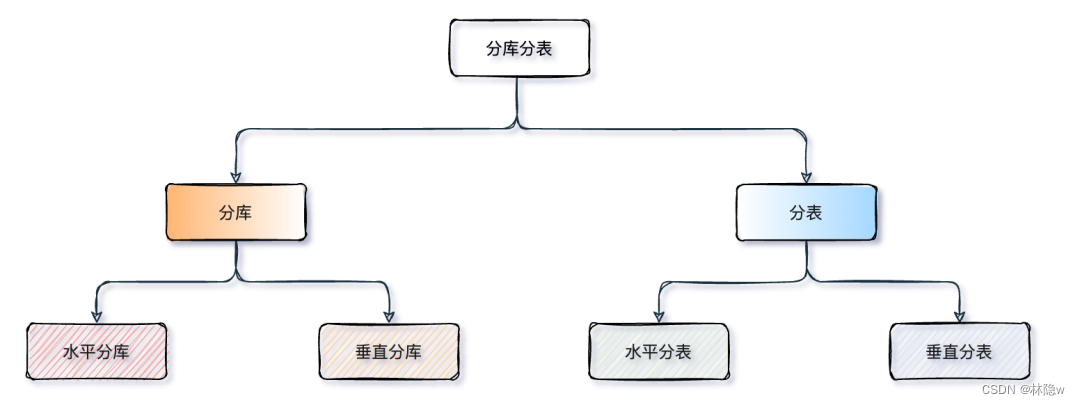
图片来源:好好的系统,为什么要分库分表?
垂直拆分
1. 垂直分库
垂直分库一般来说按照业务和功能进行拆分,将不同业务数据分别放到不同的数据库中,核心理念 专库专用。
但是有些时候业务之间的划分不一定都是清晰明了的,例如电商中订单数据的拆分,其他很多业务也都依赖于订单数据,有时候业务界限不是很好划分。
垂直分库把一个库的压力分摊到多个库,提升了一些数据库性能,但并没有解决由于单表数据量过大导致的性能问题,所以就需要配合后边的分表来解决。
2. 垂直分表
垂直分表针对业务上字段比较多的大表进行的,一般是把业务宽表中比较独立的字段,或者不常用的字段拆分到单独的数据表中,是一种大表拆小表的模式。
例如:一张t_order订单表上有几十个字段,其中订单金额相关字段计算频繁,为了不影响订单表t_order的性能,就可以把订单金额相关字段拆出来单独维护一个t_order_price_expansion扩展表,这样每张表只存储原表的一部分字段,通过订单号order_no做关联,再将拆分出来的表路由到不同的库中。
由于数据库它是以行为单位将数据加载到内存中,拆分后的核心表大多是访问频率较高的字段,而且字段长度也都较短,因而可以加载更多数据到内存中,减少磁盘IO,增加索引查询的命中率,进一步提升数据库性能。
水平拆分
1. 水平分库
水平分库是把同一个表按一定规则拆分到多个不同的数据库中,每个库可以位于不同的服务器上,以此实现水平扩展,是一种常见的提升数据库性能的方式,以实现数据的分流和负载均衡。
对比:垂直分库是不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构。
这种方案往往能解决单库存储量及性能瓶颈问题,但由于同一个表被分配在不同的数据库中,数据的访问需要额外的路由工作,因此也加大了系统的复杂度。
2. 水平分表
水平分表是在同一个数据库内,把一张大数据量的表按一定规则,切分成多个结构完全相同表,而每个表只存原表的一部分数据。
例如:一张t_order订单表有900万数据,经过水平拆分出来三个表,t_order_1、t_order_2、t_order_3,每张表存有数据300万,以此类推。
但由于子表还是在同一个数据库实例中,只是解决了单一表数据量过大的问题,并没有将拆分后的表分散到不同的机器上,还在竞争同一个物理机的CPU、内存、网络IO等。要想进一步提升性能,就需要将拆分后的表分散到不同的数据库中,达到分布式的效果。
6、数据存放在表和库中的规则(算法)
分库分表以后会出现一个问题,那就是:一张表会出现在多个数据库里,那么如何知道数据该往哪个库的哪个表里存呢? 这就需要一些规则来实现,它是一种路由算法,决定了一条数据具体应该存在哪个数据库的哪张表里。 常见的有取模算法 、范围限定算法、范围+取模算法 、预定义算法。
1、取模算法
关键字段取模(对hash结果取余数 hash(XXX) mod N),N为数据库实例数或子表数量)是最为常见的一种路由方式。
2、范围限定算法
范围限定算法以某些范围字段,如时间或ID区拆分。
3、范围 + 取模算法
为了避免热点数据的问题,我们可以对上范围算法优化一下
4、预定义算法
预定义算法是事先已经明确知道分库和分表的数量,可以直接将某类数据路由到指定库或表中,查询的时候亦是如此。
以上部分内容引自:好好的系统,为什么要分库分表?
7、分库分表的架构模式
分布式数据库中间件分为两种,proxy代理和client客户端式架构。proxy模式有MyCat、DBProxy等,客户端式架构有TDDL、Sharding-JDBC等。
二者对比图示:

图片来源:分库、分表、分区的区别,傻傻分不清?-阿里云开发者社区
【代理模式】:是将select、update等sql语句发送给代理,由这个代理来操作具体的底层数据库。所以必须要求代理本身需要保证高可用,否则即使数据库没有宕机,proxy代理操作有问题,那也无法操作数据。
【客户端模式】:通常在连接池上做了一层封装,内部与不同的库连接,sql交给smart-client进行处理。通常仅支持一种语言,如果其他语言要使用,需要开发多语言客户端。

图片来源:分库、分表、分区的区别,傻傻分不清?-阿里云开发者社区
8、分库分表的问题
相比于单库单表,拆分后的多库多表的数据存储架构会变得十分复杂,因此,会出现以下几个主要的问题:
1. 分页、排序、跨节点联合查询
这是开发中使用频率较高的操作,在分库分表后却是让人非常头疼的问题。把分散在不同库中表的数据查询出来,再将所有结果进行汇总合并整理后提供给用户。
举例图示:
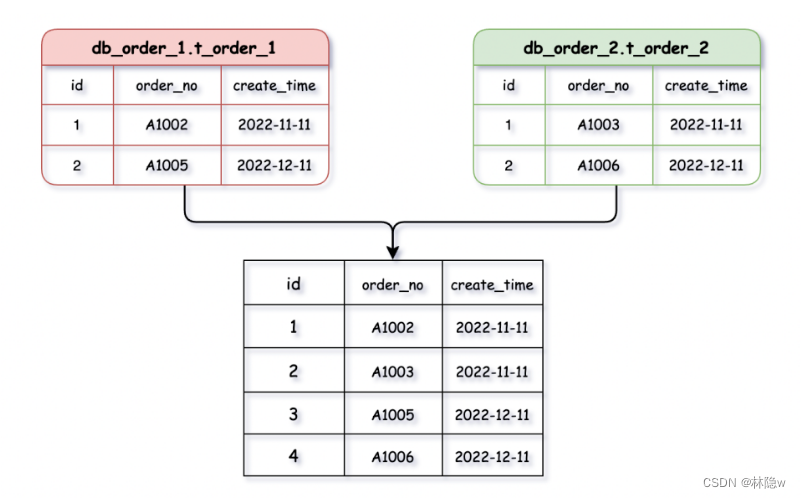
图片来源:好好的系统,为什么要分库分表?
2. 事务一致性
分布式事务下,该如何保证插入到不同库的多条记录能够要么同时成功,要么同时失败呢?
MySQL的XA协议,主要定义了事务协调者(Transaction Manager)和资源管理器(Resource Manager)之间的接口。当前主流的方案是柔性事务,TCC模式就属于柔性事务。
对于分布式事务问题每家公司有自己的实现,华为用saga,阿里用TXC,蚂蚁用DTX,支持FMT模式和TCC模式。
TCC模式图示:

图片来源:分库、分表、分区的区别,傻傻分不清?-阿里云开发者社区
3. 全局唯一主键
分库分表后数据库表的主键ID的业务意义就不大了,因为无法在标识唯一一条记录,例如:多张表t_order_1、t_order_2的主键ID全部从1开始会重复,此时我们需要主动为一条记录分配一个ID,这个全局唯一的ID就叫分布式ID,发放这个ID的系统通常被叫发号器。
4. 海量数据治理
对于多个数据库以及这些库内大量分片表的高效治理是非常必要的,因为双十一大促等业务,其产生的订单表可能会被拆分成成千上万个t_order_n表,如果没有高效的管理方案,手动建表、排查问题是一件很可怕和严重的事情。
5. 数据迁移
当设计好分库分表的架构以后,首要的问题就是如何能够平滑而完整的迁移历史数据,增量数据和全量数据迁移,这也是一个复杂的问题。
小结
总之,数据库的分库分表首先可以将数据分散到多个数据库和表中,从而减轻了单个数据库和表的负载压力,提高系统的读写性能和响应速度(性能提升);其次,提供了水平扩展的能力,可以支持系统的持续增长和负载的均衡分布。随着数据量的增加,可以通过增加更多的数据库和表来分担负载,而不是依赖于垂直扩展(扩展性)。然后,可以将不同业务模块或租户的数据进行隔离,实现数据的逻辑隔离和安全性。每个数据库或表只包含特定的数据,提高了数据的安全性和可控性;最后,分库分表可以根据实际需求进行灵活的数据管理。需要权衡系统规模、性能需求、维护成本等因素来决定是否采用分库分表策略。在实际应用中,需要根据具体情况选择合适的分库分表方案,并进行性能测试和评估,以确保系统能够满足需求并具备良好的扩展性。可以根据数据的访问模式、生命周期或其他特定因素,将数据分散到不同的数据库和表中,以便更好地管理和查询数据。
参考:
分库、分表、分区的区别,傻傻分不清?-阿里云开发者社区
好好的系统,为什么要分库分表?
分库分表的 21 条法则,hold 住! - 知乎
https://baijiahao.baidu.com/s?id=1708707864255381575&wfr=spider&for=pc
分库分表是什么,为什么要分库分表? - 知乎
MySQL分库分表全攻略:从小白到大神的进阶指南! - 哔哩哔哩
感谢阅读,码字不易,多谢点赞!如有不当之处,欢迎反馈指出,感谢!