文章目录
- 关于Unity性能优化
- 一、资源部分:
- 1、图片
- 1.1、 图片尺寸越小越好
- 1.2、使用2N次幂大小
- 1.3、取消勾选Read/Write Enabled
- 1.4、图片压缩
- 1.5、禁用多余的Mip Map
- 1.6、合并图集
- 2、模型
- 2.1.限制模型面数
- 2.2.限制贴图的大小
- 2.3.禁用Read/Write Enables
- 2.4.不勾选其他辅助功能
- 2.5.调整网格压缩
- 2.6.使用LOD技术
- 3、字体
- 3.1.区分字何功能
- 3.2.制作字体
- 二、代码部分
- 1.AssetBundle文件
- 2.建立对象池管理资源
- 3.留意装箱拆箱
- 4.事件注册移除
- 5.物体寻找
- 6.可见性设置
- 7.静态类
- 8.避免重复
- 9.数据类型
- 10.字串操作
- 11.使用枚举和常量
- 12.反射和动态
- 13.避免try catch
- 14.避免Camera.main找摄像机
- 三、托管部分:
- 1、什么是托管
- 1.1、托管介绍
- 1.2、什么内存碎片和扩展
- 2、如何处理
- 2.1、减少临时分配
- 2.2、内存复用
- 2.3、避免拆箱装箱
- 2.4、避免闭包和匿名函数
- 总结:
想拿《1024达人勋章》,帮忙点个赞,谢谢。
关于Unity性能优化
总结内存的优化主要分为以下三部分,资源,代码和托管。资源部分往往是大头,很多情况下都能占据工程的内存70%~80以上的大小,所以这一部分的优化至关重要。

一、资源部分:
1、图片
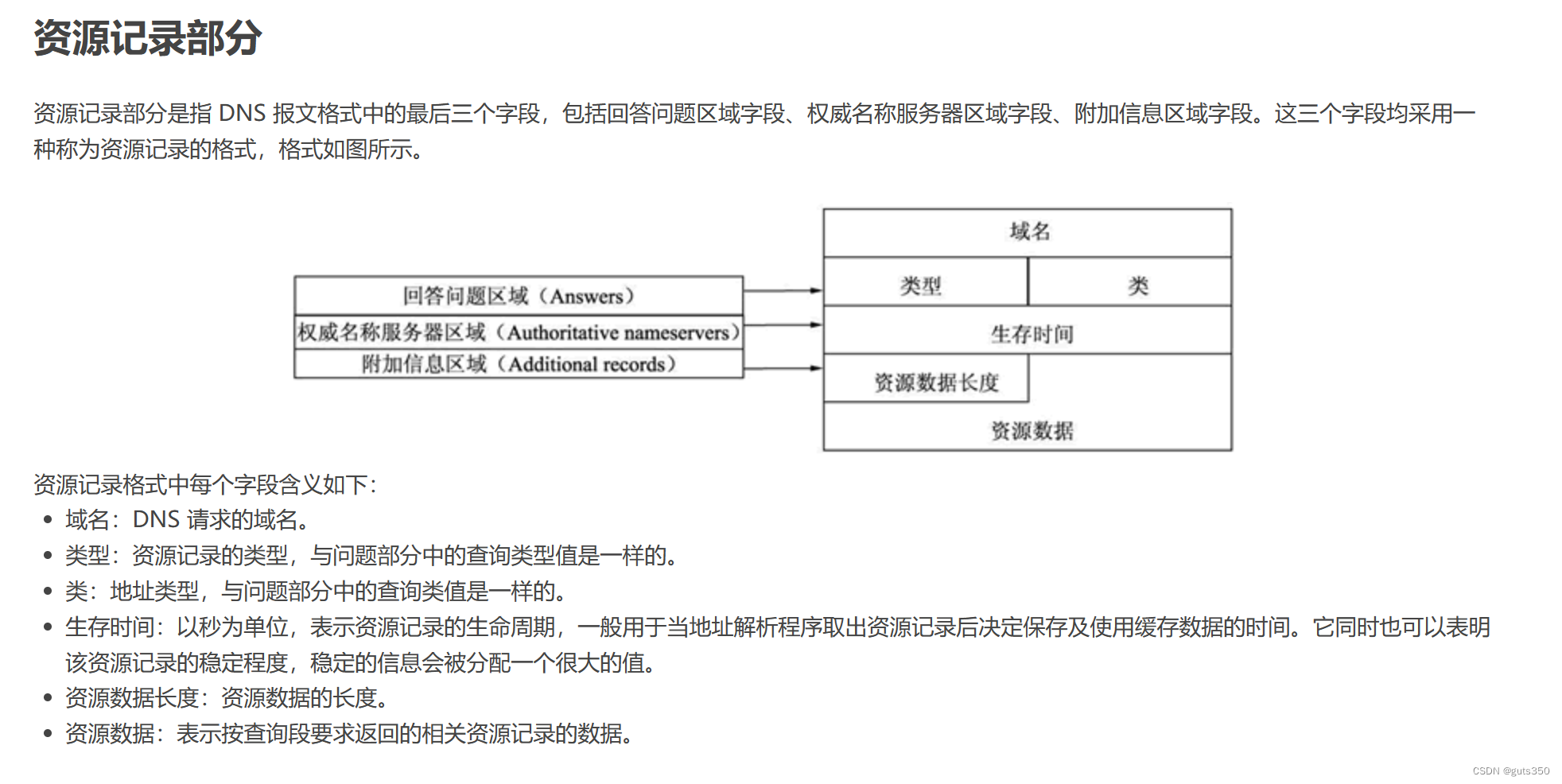
关于纹理主要检查以下几个部分:
-图片大小
-压缩格式
-导入设置
从性能优化的角度上看,图片的处理有以下几个事需要做:
1.1、 图片尺寸越小越好
按需求而定,在够用的情况下,越小越好。需要知道的是1024X1024的图片大小将是512X512的四倍,而不是二倍。如下图是1024大小3m,而512只有0.8m.


而然这只是图片大小,当使用时放到内存中将会进一步增大。
1.2、使用2N次幂大小
由于Unity对2的N次幂大小的图片处理更为友好,尽量使用此尺寸大小。
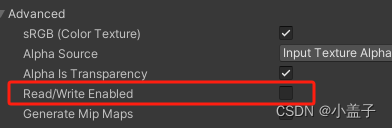
1.3、取消勾选Read/Write Enabled
当勾选此选项时,该图片将会在CPU中多存一份备份让CPU访问,如果没有读写需求可以请关闭此选项。
1.4、图片压缩
在你选压缩格式以前,Unity本身会对图片有一部分处理,转换为我们工程中使用的Texture 2D。
为什么转换好了格式还需要我们选择压缩的方式呢?因为Unity有个明显的优势即平台的通用与适配性。
因而对单一平台的处理会相对薄弱,而平台的性能优势又不尽相同。所以我们需要根据平台的来选择。
| 格式 | 内存占用 | 质量 | 透明 | 二次方大小 | 建议使用场景 |
|---|---|---|---|---|---|
| RGBA32 | 1 | 100% | 有 | 无需要 | 清晰度要求极高 |
| RGBA16+Dithering | 1/2 | 80% | 有 | 无需要 | UI、头像、不带渐变、颜色不丰富 |
| RGBA16 | 1/2 | 60% | 有 | 无需要 | UI、头像、不带渐变、颜色不丰富、不拉伸放大 |
| RGB16+Dithering | 1/2 | 80% | 无 | 无需要 | UI、头像、不透明、不拉伸放大 |
| RGB16 | 1/2 | 60% | 无 | 无需要 | UI、头像、不透明、不渐变、不拉伸放大 |
| RGB(ETC1)+Alpha(ETC1) | 1/4 | 60% | 有 | 需要,可长宽不同 | 尽可能使用,不满足要求再考虑上列格式 |
| RGB(ETC1) | 1/8 | 60% | 无 | 需要,可长宽不同 | 尽可能使用,不满足要求再考虑上列格式 |
| PVRTC4 | 1/8 | 40% | 无 | 需要,长宽相同 | 尽可能使用,不满足要求再考虑上列格式 |
RGBA32通常作为一种高保真的压缩格式,质量好性能消耗大。
而RBGA16+Dithering可以理解为RBGA32的阉割版,色彩分级大,过度也不够顺滑。
最后ETC1+Alpha/PVRTC4则是移动端常用的压缩格式,性能上有明显的优势。
1.5、禁用多余的Mip Map
类似于模型的Lod(Level of Detail)技术,会根据距离远近来展示图片的精度。
可以节省部分性能,但Mip map会增大部分内存,因而UI则没有必要开启功能。
当一张Texture开启Mipmap后,占用的内存将会是原来的4/3.
1.6、合并图集
合并图集优化的是图片渲染中Draw Call数量,基本原理即是将会经常一起出现的图片合并成一张图,当需要渲染的时候就一起发送给GPU去渲染。
由于DrawCall是由CPU调用GPU的命令,从而可以提升CPU的性能表现。
通过Edit > Project Setting > Editor > Sprite Packer > Mode > Always Enabled(Legacy Sprite Packer)
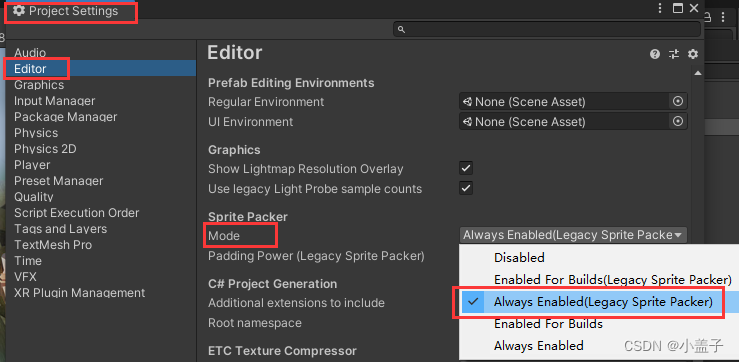
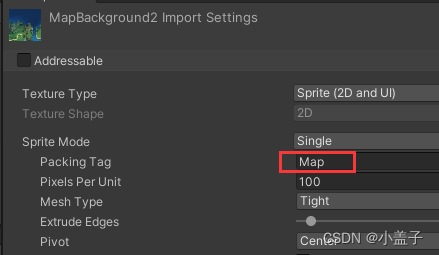
然后图片上就可以通过Packing Tag命名来区分合并的包了
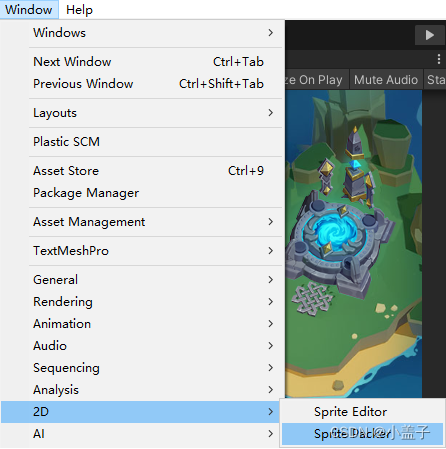
通过Windows > 2D > Sprite Packer 可以打开图集窗口 点击Pack即可合并
2、模型
模型的优化更多的是建模人员的内容,模型的规范等。
2.1.限制模型面数
我们知道模型的构成即是由一个个点连成三角面,再由一个个三角面堆叠而成的。
所以面数的多少在一定程度上会影响模型文件的大小,所以不能无限制的添加。
2.2.限制贴图的大小
贴图会影响到模型的精细度,因而也会一定程序上影响大小。具体原理参照上面的图片部分讲解。
这部分也是容易被忽略的部分。
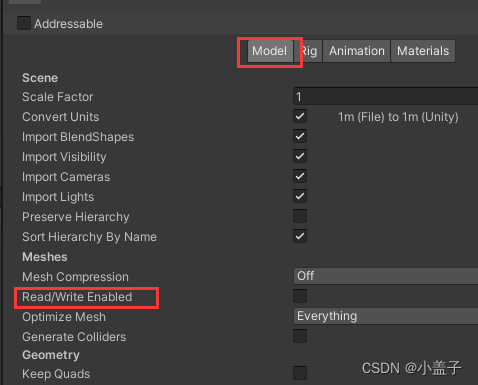
2.3.禁用Read/Write Enables
这个和图片的有点类似,打开后也会在CPU中保留一份Mesh数据让脚本访问,
在游戏当不需要对模型进行操作的时候则关闭此选项。
默认是禁用的,优化时可以排查一下。
2.4.不勾选其他辅助功能
与Reader/Write Enables类似,基本上在Unity中都是需要消耗一定资源去维护的。
因为未明确功能及需求不要点开。
2.5.调整网格压缩
调整Mesh Compression,此选项可以调整模型网格的压缩率,降低精度,从而获得性能的提升。
调整Optimize Mesh: 默认勾选的,确定三角形的网格中列出的顺序,获得更好的性能。
调整Normal:是否导入法线数据,默认导入,如果不需要做光照处理可以关闭。

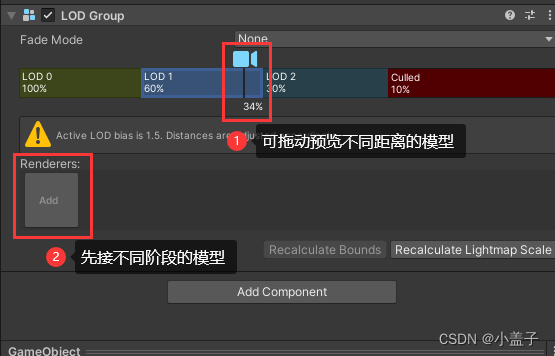
2.6.使用LOD技术
这个是Unity提供的一个基于距离来决定展示精细度的功能,模型需要准备好指定内容的高、中、低模。
距离近的时候展示高模型,远一些时候使用中模,最远使用低模。
但这个技术也有个缺点,会大大增加模型工作量,同时也会让工程的包体变的巨大。
3、字体
3.1.区分字何功能
字体包有的含有中、英文,而有的则只是有英文。这点也非常容易被忽略,
如果一个字体我们只需要用到英文部分则,则应当优先考虑使用只有英文字体的包。
3.2.制作字体
此外如果字体我们只需要用到其中的小部分字符,我们可以考虑使用BMFont等字体
制作插件,制作自己独有的字体,以减少资源的大小。
字体少则1m,大的有数十兆,个人认为这点非常重要。可以考虑和美术同学协同优化。
总体而言,资源部分在满足效果需求的情况下,应该越小越好。
二、代码部分
1.AssetBundle文件
AssetBundle加载后要使用Unload卸载镜像文件
AssetBundle文件下载后可以考虑存本地作为缓存
2.建立对象池管理资源
什么是对象池资源太多了,自行查阅吧 Y(^ _ ^)Y,这里不坠述了。
3.留意装箱拆箱
避免装箱拆箱操作比如yield返回值、Foreach、ArrayList等…
4.事件注册移除
-比方说,Button.onClick.AddListener()加载的按钮事件,使用后则需要使用:Button.onClick.RemoveListener()来移除。-Evnet中的+=事件,需要使用-=来移除
否则将因为内容一直被引用而点用,可能造成内存泄露。
5.物体寻找
避免 频繁大量 Find()或GetComponent()函数.因为他会在当前全场景中搜索,产生较高开销。
可以考虑使用MonoBehaviour脚本下挂载引导,以减少搜索次数。
6.可见性设置
在非静态类中,全局变量会在该类补实例化过程中占用资料,而非局部变量则会在方便使用过程中占用资源。
7.静态类
非静态类会在实例化后占用资料,而静态类则会在首次补调用后,在程序中一直存在。
因而不要过多的使用静态类。
8.避免重复
需要注意在Update或for等循环、递归结构中的资源使用。在这些结果中通常重复次数较多,则容易产生大量的资源使用。比如就不要在Update中不断的实例化、销毁物体,而因考虑使用对像池。
9.数据类型
刚开始学习的时候我也很不理解,既然int和float都能存放数字,为什么需要区分开?
后面才知道他们占用的空间是不同的。在够用的情况下,我们应当使用更清量级的数据类型。
同理,选择数组时也当如此。
10.字串操作
避免大量的String操作,因为会产生大量的内存分配。实在有需要,则可以考虑使用StringBuffer进行优化。
11.使用枚举和常量
有时候我们在代码中有些莫名奇妙的数字,开发者自己当时知道是什么含义,时间长了可能会忘记,也不利于别人阅读。
因而推荐使用数字和常量,因为它们可以命名,从而提高代码的可读性。
12.反射和动态
避免过多使用发射和动态代码,因为他们的性能消耗会更大。
13.避免try catch
增经小白的我也想过,既然这个可以放置报错,我所有地方都不做空判断,直接使try catch不就好了。
其实这个语句结构体内有大量性能消耗。
14.避免Camera.main找摄像机
没想到吧,这个也消耗性能。不过细想每次都去找,当然会有消耗。找个变量存起来就好了。
三、托管部分:
1、什么是托管
1.1、托管介绍
Unity的托管内存系统是基于Mono或Il2CPP虚拟机之上的C#环境。所有托管代码中被创建的对像都会被分配到托管堆上,所有不为空的引用对象和值类型对象都将放置在托管堆上。当在脚本中不包含对像的任何引用时,系统将自动释放这部分内存。
个人推荐脑袋里要有下面一个图,内存的占用像是是一箱箱货物,需要有足够的空间来存放。废弃后的清理也有延迟,那么如何合理的分配和使用空间?我们来探讨一下。
1.2、什么内存碎片和扩展
内存空间类似于一个个小格子,有的数据类型需要占用2格,有的则是4格、8格,紧密排列在一起。
当有数据补释放时,这些格子会重新被空出来。这时这些格子只能存放小于等于这中间格子大小的
数据。这样就有可能有些空格子并没存到数据,这种情况称为 内容碎片 ,而当新的数据托管不足
矣存放时,则会申请更大的托管空间来存放。
2、如何处理
2.1、减少临时分配
部分项目中会出现每帧分配上百kb的临时数据,这非常影响性能。因为这些临时数据无法马上被释放
有可能导致堆长度不够而申请更大的长度。而托管堆申请的内存长度是不会反还的,会导致占用内存过大。
2.2、内存复用
尽量复用数组、集合、对象等。尽量避免新分配内存空间。
比如在Update中New一个List进行计算,就不如将List放在循环体外,每次Update使用Clear()清空后复用。
2.3、避免拆箱装箱
这是C#语言用于临时分配较小内存会被分代垃圾收集器和分配大小的而被开发出来的。
但由于不能有效处理小的、频繁产生的临时垃圾,所以我们要避免装箱拆箱操作比如:
yield返回值、Foreach、ArrayList等…
2.4、避免闭包和匿名函数
因为在编译IL代码时,闭包和匿名函数装会被New成一个Class
总结:
性能优化往往就是在了解程序与资源的运行规则后,根据具体项目合理分配资源。有时间也难免做出一些取舍拆东墙补西墙不善尽美。 希望大家可以活学活用。文章整理出来的是我上一篇文章的延伸,更细化一点的内容,希望对大家有帮助。谢谢观看。