文章目录
- 前言
- 排序算法的基本概念
- 内部排序
- 插入排序
- 直接插入排序
- 折半插入排序
- 希尔排序
- 交换排序
- 冒泡排序
- 快速排序
- 选择排序
- 简单选择排序
- 堆排序
- 归并排序
- 基数排序
- 外部排序
- 多路归并
- 败者树
- 置换——选择排序
- 最佳归并树
前言
本文所有代码均在仓库中,这是一个完整的由纯C语言实现的可以存储任意类型元素的数据结构的工程项目。

- 首先是极好的工程意识,该项目是一个中大型的CMake项目,结构目录清晰,通过这个项目可以遇见许多工程问题并且可以培养自己的工程意识。
- 其次是优秀的封装性(每个数据结构的头文件中只暴漏少量的信息),以及优秀的代码风格和全面的注释,通过这个项目可以提升自己的封装技巧:
- 异常处理功能:在使用C语言编写代码的时候不能使用类似Java的异常处理机制是非常难受的,所以我也简单实现了一下。详情可看在C语言中实现类似面向对象语言的异常处理机制
最后也是最重要的一点,数据结构的通用性和舒适的体验感,下面以平衡二叉树为例:
- 第一步:要想使用平衡二叉树,只需要引入其的头文件:
#include "tree-structure/balanced-binary-tree/BalancedBinaryTree.h"
- 第二步:定义自己任意类型的数据,并构造插入数据(以一个自定义的结构体为例):
#include "tree-structure/balanced-binary-tree/BalancedBinaryTree.h"int dataCompare(void *, void *);typedef struct People {char *name;int age;
} *People;int main(int argc, char **argv) {struct People dataList[] = {{"张三", 15},{"李四", 3},{"王五", 7},{"赵六", 10},{"田七", 9},{"周八", 8},};BalancedBinaryTree tree = balancedBinaryTreeConstructor(NULL, 0, dataCompare);for (int i = 0; i < 6; ++i) {balancedBinaryTreeInsert(&tree, dataList + i, dataCompare);}return 0;
}/*** 根据人的年龄比较*/
int dataCompare(void *data1, void *data2) {int sub = ((People) data1)->age - ((People) data2)->age;if (sub > 0) {return 1;} else if (sub < 0) {return -1;} else {return 0;}
}
- 第三步:打印一下平衡二叉树:
#include "tree-structure/balanced-binary-tree/BalancedBinaryTree.h"int dataCompare(void *, void *);void dataPrint(void *);typedef struct People {char *name;int age;
} *People;int main(int argc, char **argv) {struct People dataList[] = {{"张三", 15},{"李四", 3},{"王五", 7},{"赵六", 10},{"田七", 9},{"周八", 8},};BalancedBinaryTree tree = balancedBinaryTreeConstructor(NULL, 0, dataCompare);for (int i = 0; i < 6; ++i) {balancedBinaryTreeInsert(&tree, dataList + i, dataCompare);balancedBinaryTreePrint(tree, dataPrint);printf("-------------\n");}return 0;
}/*** 根据人的年龄比较*/
int dataCompare(void *data1, void *data2) {int sub = ((People) data1)->age - ((People) data2)->age;if (sub > 0) {return 1;} else if (sub < 0) {return -1;} else {return 0;}
}/*** 打印人的年龄* @param data*/
void dataPrint(void *data) {People people = (People) data;printf("%d", people->age);
}
打印的结果如下:

最后期待大佬们的点赞。
排序算法的基本概念
排序算法就是将结构中所有数据按照关键字有序的过程。排序的分类如下:

评价一个排序算法的指标通常有以下三种:
- 时间复杂度
- 空间复杂度
- 稳定性
其中稳定性是指关键字相同的元素在排序前后相对位置是否改变,如果不变则称该排序算法是稳定的,否则就是不稳定的。
内部排序
插入排序
算法思想:是每次将一个待排序的记录按其关键字大小插入前面已排好序的子序列,直到全部记录插入完成。
直接插入排序
- 算法思想:边寻找无序元素插入的位置边向后移动有序序列。
- 时间复杂度: O ( n ) ∼ O ( n 2 ) O(n)\thicksim O(n²) O(n)∼O(n2)
- 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性:稳定
/*** 直接插入排序* @param dataList* @param length*/
void directInsert(void *dataList[], int length, int (*compare)(void *, void *)) {for (int i = 2; i <= length; ++i) {void *data = dataList[i];int j;for (j = i - 1; j > 0 && compare(data, dataList[j - 1]) < 0; --j) {dataList[j + 1 - 1] = dataList[j - 1];}dataList[j + 1 - 1] = data;}
}
折半插入排序
- 算法思想:先用二分查找寻找无序元素的位置再向后移动有序序列。
- 时间复杂度: O ( n l o g 2 n ) ∼ O ( n 2 ) O(nlog₂n)\thicksim O(n²) O(nlog2n)∼O(n2)
- 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性:稳定
/*** 折半插入排序* @param dataList* @param length*/
void binaryInsertSort(void *dataList[], int length, int (*compare)(void *, void *)) {for (int i = 2; i <= length; ++i) {void *data = dataList[i];int mid, high = i - 1, low = 1;while (low <= high) {mid = (high + low) / 2;if (compare(dataList[mid - 1], data) > 0) {high = mid - 1;} else {low = mid + 1;}}for (int j = i; j > low; j--) {dataList[j - 1] = dataList[j - 1 - 1];}dataList[low - 1] = data;}
}
希尔排序
- 算法思想:先将待排序列表分割成若干形如 L [ i , i + d , i + 2 d , … , i + k d ] L[i,i+d,i+2d,\dots,i+kd] L[i,i+d,i+2d,…,i+kd]的子表,然后对各个子表分别进行直接插入排序,之后缩小增量 d d d,重复上述过程,直到 d = 1 d=1 d=1。
- 时间复杂度:无法用数学方法准确表示,当 n n n在某一范围内时间复杂度为 O ( n 1.3 ) O(n^{1.3}) O(n1.3),最坏的时间复杂度为 O ( n 2 ) O(n²) O(n2)
- 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性:不稳定
/*** 希尔排序* @param dataList* @param length* @param compare*/
void shellSort(void *dataList[], int length, int (*compare)(void *, void *)) {for (int p = length / 2; p >= 1; p /= 2) {for (int i = p + 1; i <= length; ++i) {void *data = dataList[i - 1];int j;for (j = i - p; j > 0 && compare(data, dataList[j - 1]) < 0; j -= p) {dataList[j + p - 1] = dataList[j - 1];}dataList[j + p - 1] = dataList[j - 1];}}
}
交换排序
算法思想:根据序列中两个元素关键字的比较结果来对换这两个元素在序列中的位置。
冒泡排序
- 算法思想:从前往后或从后往前两两比较相邻两元素的关键字,若为逆序则交换它们,直到序列比较完。
- 时间复杂度: O ( n ) ∼ O ( n 2 ) O(n)\thicksim O(n²) O(n)∼O(n2)
- 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性:稳定
/*** 冒泡排序* @param dataList* @param length* @param compare*/
void bubbleSort(void *dataList[], int length, int (*compare)(void *, void *)) {for (int i = 1; i <= length - 1; i++) {bool flag = false;for (int j = length; j > i; j--) {if (compare(dataList[j - 1], dataList[j - 1 - 1]) < 0) {swap(dataList + j - 1, dataList + j - 1 - 1);flag = true;}}if (!flag) {break;}}
}
快速排序
快速排序算法的平均时间复杂度接近最好时间复杂度,是最好的内部排序。
- 算法思想:在待排序列中选择一个元素 p i v o t pivot pivot作为基准,通过一趟排序将序列划分为两部分 L [ 1 , … , k − 1 ] L[1,\dots,k-1] L[1,…,k−1]和 L [ k + 1 , … , n ] L[k+1,\dots,n] L[k+1,…,n],使得 L [ 1 , … , k − 1 ] L[1,\dots,k-1] L[1,…,k−1]中所有元素小于 p i v o t pivot pivot, L [ k + 1 , … , n ] L[k+1,\dots,n] L[k+1,…,n]中所有元素大于等于 p i v o t pivot pivot。 p i o v t piovt piovt则放在了其最终的位置 L [ k ] L[k] L[k]上,这个过程为一趟快速排序。然后分别递归的对两个部分重复上述过程,直到每部分只有一个元素或空为止。
- 时间复杂度: O ( n l o g 2 n ) ∼ O ( n 2 ) O(nlog₂n)\thicksim O(n²) O(nlog2n)∼O(n2),具体为 O ( n × 递归层数 ) O(n\times 递归层数) O(n×递归层数)
- 空间复杂度: O ( l o g 2 n ) ∼ O ( n ) O(log₂n)\thicksim O(n) O(log2n)∼O(n),具体为 O ( 递归层数 ) O(递归层数) O(递归层数)
- 稳定性:不稳定
static int partition(void *dataList[], int low, int high, int (*compare)(void *, void *)) {void *pivot = dataList[low - 1];while (low < high) {while (low < high && compare(dataList[high - 1], pivot) > 0) {high--;}dataList[low - 1] = dataList[high - 1];while (low < high && compare(dataList[low - 1], pivot) <= 0) {low++;}dataList[high - 1] = dataList[low - 1];}dataList[low - 1] = pivot;return low;
}/*** 快速排序* @param dataList * @param low * @param high * @param compare */
void quickSort(void *dataList[], int low, int high, int (*compare)(void *, void *)) {if (low < high) {int pivotPos = partition(dataList, low, high, compare);quickSort(dataList, low, pivotPos - 1, compare);quickSort(dataList, pivotPos + 1, high, compare);}
}
选择排序
算法思想:每一趟在待排序元素中选择关键字最小或最大的元素加入有序子序列。
简单选择排序
- 算法思想:第 i i i趟从 L ( i . . . n ) L(i...n) L(i...n)中选择关键字最小的元素与 L ( i ) L(i) L(i)交换,每一趟排序都可以确定一个元素的最终位置。
- 时间复杂度: O ( n 2 ) O(n²) O(n2)
- 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性:不稳定
/*** 简单选择排序* @param dataList * @param length * @param compare */
void SimpleSelectSort(void *dataList[], int length, int (*compare)(void *, void *)) {for (int i = 1; i < length; ++i) {int minIndex = i;for (int j = i + 1; j <= length; ++j) {if (compare(dataList[j], dataList[minIndex]) < 0) {minIndex = j;}}if (minIndex != i) {swap(dataList[i], dataList[minIndex]);}}
}
堆排序
当一个序列 L [ 1 , … , n ] L[1,\dots,n] L[1,…,n]满足:
- L ( i ) > = L ( 2 i ) L(i)>=L(2i) L(i)>=L(2i)且 L ( i ) > = L ( 2 i + 1 ) L(i)>=L(2i+1) L(i)>=L(2i+1)时,称该序列为大顶堆
- L ( i ) < = L ( 2 i ) L(i)<=L(2i) L(i)<=L(2i)且 L ( i ) < = L ( 2 i + 1 ) L(i)<=L(2i+1) L(i)<=L(2i+1)时,称该序列为小顶堆
可以将堆看成一棵线性存储的完全二叉树:
- 大顶堆的最大元素存放在根结点,且其任一非根结点的值小于等于其双亲结点的值。
- 小顶堆的最小元素存放在根结点,且其任一非根结点的值大于等于其双亲结点的值。
- 在完全二叉树中:
- 若 i < = ⌊ n / 2 ⌋ i<=⌊n/2⌋ i<=⌊n/2⌋,那么结点 i i i为分支结点,否则为叶子结点。
- i i i的左孩子 2 i 2i 2i
- i i i的右孩子 2 i + 1 2i+1 2i+1
- i i i的父结点 ⌊ i / 2 ⌋ ⌊i/2⌋ ⌊i/2⌋
堆排序首要任务就是先构建一个堆(以大顶堆为例):
- 检查所有分支结点的关键字是否满足大顶堆的性质,如果不满足,则用最大孩子的关键字和分支结点的关键字交换,使该分支子树成为大顶堆。之后依次对 ⌊ n / 2 ⌋ − 1 ∼ 1 ⌊n/2⌋-1\thicksim1 ⌊n/2⌋−1∼1位置的分支结点重复以上检查。
- 若关键字交换破坏了下一级的堆,则采用相同的方式继续往下调整。
堆构建完后就可以进行堆排序了,堆排序的算法思想如下:
- 每一趟将堆顶元素加入有序子序列(与待排序列中的最后一个元素交换),并将待排元素序列再次调整为大顶堆。
- 时间复杂度:
- 建立堆时: O ( n ) O(n) O(n)
- 排序时: O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)
- 整体: O ( n l o g 2 n ) O(nlog₂n) O(nlog2n)
- 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性:不稳定
如果要在堆中插入或删除元素(以小顶堆为例),那么思想为:
- 插入元素时,首先将新元素放到堆尾,然后与父结点对比,若新元素比父结点更小,则将两者互换,一直重复此步骤直至新元素无法上升。
- 删除元素时,首先用堆底元素代替被删除的元素,然后让该元素不断的下坠,直到无法下坠为止。
static void heapAdjust(void **dataList, int rootIndex, int length, int (*compare)(void *, void *)) {void *root = dataList[rootIndex - 1];//i指向左孩子for (int i = 2 * rootIndex; i <= length; i *= 2) {//如果右孩子>左孩子,则让i指向右孩子if (i < length && compare(dataList[i + 1 - 1], dataList[i - 1]) > 0) {i++;}if (compare(root, dataList[i - 1]) > 0) {break;} else {dataList[rootIndex - 1] = dataList[i - 1];rootIndex = i;}}dataList[rootIndex - 1] = root;
}static void buildMaxHeap(void **dataList, int length, int (*compare)(void *, void *)) {for (int i = length / 2; i > 0; i--) {heapAdjust(dataList, i, length, compare);}
}/*** 堆排序* @param dataList* @param length* @param compare*/
void heapSort(void **dataList, int length, int (*compare)(void *, void *)) {buildMaxHeap(dataList, length, compare);for (int i = length; i > 1; i--) {swap(dataList[i - 1], dataList[1 - 1]);heapAdjust(dataList, 1 - 1, i - 1, compare);}
}
归并排序
- 算法思想:将待排序列视为 n n n个有序的子序列,然后两两(或两个以上)归并,得到 ⌈ n / 2 ⌉ ⌈n/2⌉ ⌈n/2⌉个长度为 2 2 2或为 1 1 1的有序序列,然后继续归并,直到合成一个长度为 n n n的有序序列为止。
- 时间复杂度: O ( n l o g 2 n ) O(nlog₂n) O(nlog2n)
- 空间复杂度: O ( n ) O(n) O(n)
- 稳定性:稳定
static void merge(void *dataList[], int length, int low, int mid, int high, int (*compare)(void *, void *)) {void *temp[length];int i, j, k;for (k = low; k <= high; ++k) {temp[k] = dataList[k];}for (i = low, j = mid + 1, k = i; i <= mid && j <= high; k++) {if (compare(temp[i - 1], temp[j - 1]) < 0) {dataList[k - 1] = temp[i - 1];i--;} else {dataList[k - 1] = temp[j - 1];j++;}}while (i <= mid) {dataList[k - 1] = temp[i - 1];k++;i++;}for (; j <= high;) {dataList[k - 1] = temp[j - 1];k++;j++;}
}/*** 归并排序* @param dataList * @param length * @param low * @param high * @param compare */
void mergeSort(void *dataList[], int length, int low, int high, int (*compare)(void *, void *)) {if (low < high) {int mid = (low + high) / 2;mergeSort(dataList, length, low, mid, compare);mergeSort(dataList, length, mid + 1, high, compare);merge(dataList, length, low, mid, high, compare);}
}
基数排序
假设长度为 n n n的排序列表中每个结点 a j a_j aj的关键字由 d d d元组 ( k j d − 1 , k j d − 2 , … , k j 1 , k j 0 ) (k_j^{d-1},k_j^{d-2},\dots,k_j^1,k_j^0) (kjd−1,kjd−2,…,kj1,kj0)组成,其中 0 ≤ k j i ≤ r − 1 , ( 0 ≤ j < n , 0 ≤ i ≤ d − 1 ) 0\leq k_j^i\leq r-1,(0\leq j<n,0\leq i\leq d-1) 0≤kji≤r−1,(0≤j<n,0≤i≤d−1), r r r称为基数。那么基数排序的算法思想为:
- 初始化:设置 r r r个空队列, Q 0 , Q 1 , … , Q r − 1 Q_0,Q_1,\dots,Q_{r-1} Q0,Q1,…,Qr−1
- 按照各个关键字位权重递增的次数对 d d d个关键字位分别进行分配和收集
- 分配:顺序扫描各个元素,若当前处理的关键字位 = x =x =x,则将元素插入 Q x Q_x Qx队尾
- 收集:把 Q 0 , Q 1 , … , Q r − 1 Q_0,Q_1,\dots,Q_{r-1} Q0,Q1,…,Qr−1各个队列中的结点依次出队链接
- 时间复杂度: O ( d ( n + r ) ) O(d(n+r)) O(d(n+r))
- 空间复杂度: O ( r ) O(r) O(r)
- 稳定性:稳定
以int dataList[] = {278, 109, 63, 930, 589, 184, 505, 269, 8, 83}为例:
/*** 基数排序* @param dataList* @param length* @param maxLength*/
void radixSort(int dataList[], int length, int maxLength) {LinkedQueue queue = linkedQueueConstructor();for (int i = 0; i < length; ++i) {linkedQueueEnQueue(queue, dataList + i);}LinkedQueue queue0 = linkedQueueConstructor();LinkedQueue queue1 = linkedQueueConstructor();LinkedQueue queue2 = linkedQueueConstructor();LinkedQueue queue3 = linkedQueueConstructor();LinkedQueue queue4 = linkedQueueConstructor();LinkedQueue queue5 = linkedQueueConstructor();LinkedQueue queue6 = linkedQueueConstructor();LinkedQueue queue7 = linkedQueueConstructor();LinkedQueue queue8 = linkedQueueConstructor();LinkedQueue queue9 = linkedQueueConstructor();LinkedQueue queueList[] = {queue0, queue1, queue2, queue3, queue4, queue5, queue6, queue7, queue8, queue9};for (int i = 1; i <= maxLength; ++i) {while (!linkedQueueIsEmpty(queue)) {void *data = linkedQueueDeQueue(queue);int key = *(int *) data / (int) pow(10, i - 1) % 10;linkedQueueEnQueue(queueList[key], data);}for (int j = 0; j < 10; ++j) {LinkedQueue keyQueue = queueList[j];while (!linkedQueueIsEmpty(keyQueue)) {linkedQueueEnQueue(queue, linkedQueueDeQueue(keyQueue));}}}while (!linkedQueueIsEmpty(queue)) {void *data = linkedQueueDeQueue(queue);printf("%d,", *(int *) data);}
}

外部排序
多路归并
操作系统以块为单位对磁盘存储空间进行管理,如果要修改磁盘块中的数据,就需要把对应磁盘块的内容读到内存中,在内存中修改后再写回磁盘。在对磁盘数据进行排序时,如果磁盘中的数据过多,那么无法一次将数据全部读到内存中,此时就应该使用外部排序。实现外部排序的思想是使用归并排序的的方法,最少只需要在内存中分配三块大小的缓冲区即可对任意一个大文件进行排序。
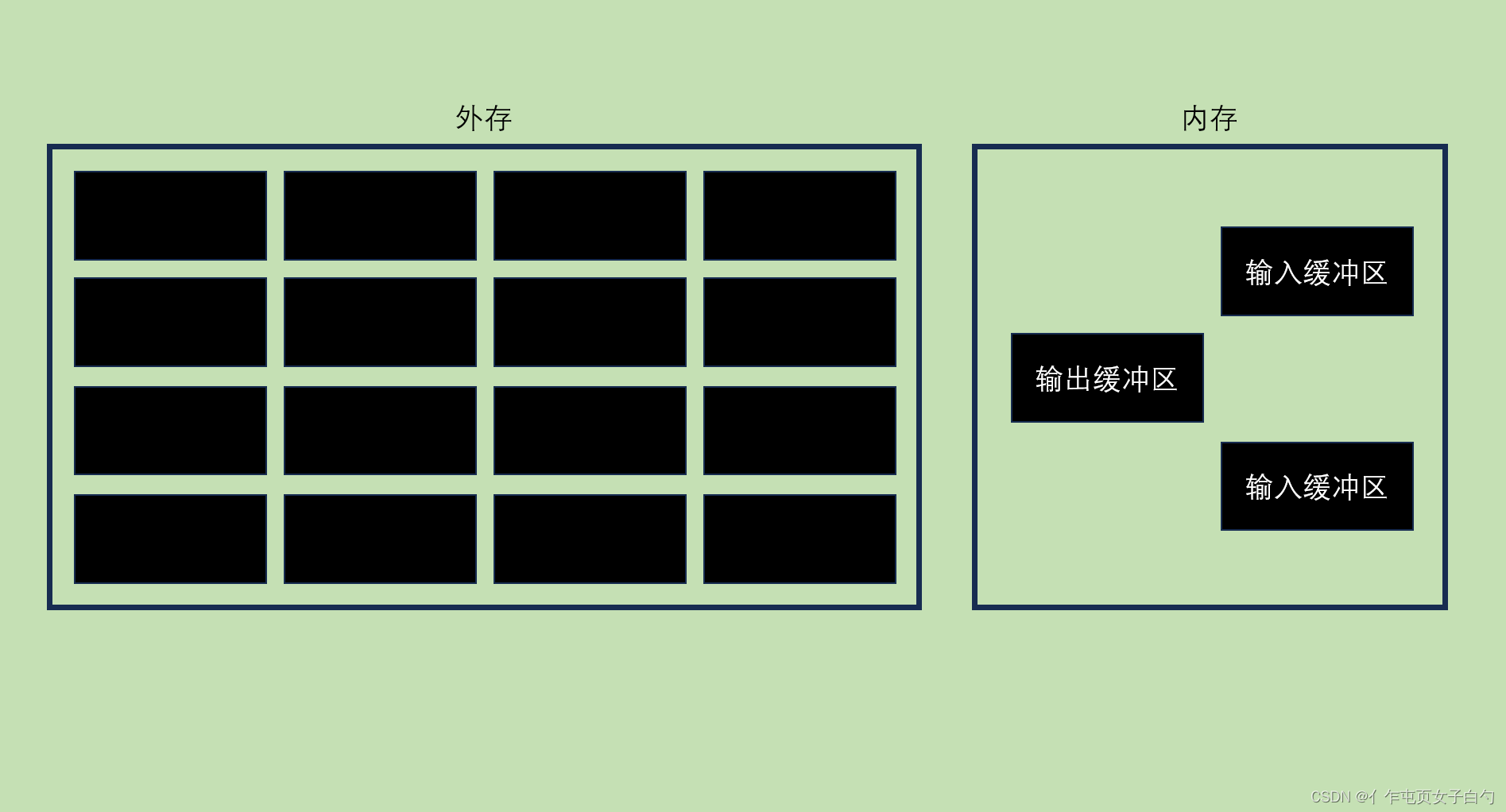
外部排序的步骤如下:
- 构造归并段:每次将磁盘中两个块的内容读入输入缓冲区中,进行内部排序写到输出缓冲区,当某个输入缓冲区为空时就立即读入磁盘中的下一个段,当输出缓冲区已满时就写入到磁盘中。16个块都排序完后就构造了8个两块长度的初始归并段。
- 接着继续构造4个4块长度的归并段。
- 以此类推当只有一个归并段时整个磁盘就变得有序了。
在每次构造归并段时都需要把所有的磁盘块读写一遍,并且还要进行内部排序,因此外部排序的时间开销由以下几部分构成:
外部排序的时间开销 = 读写外存的时间 + 内部排序所需时间 + 内部归并所需的时间 外部排序的时间开销=读写外存的时间+内部排序所需时间+内部归并所需的时间 外部排序的时间开销=读写外存的时间+内部排序所需时间+内部归并所需的时间
其中读写外存的时间是外部排序的主要开销,因此可以使用多路归并的方式来减少归并的趟数从而减少读写外存的次数。若对 r r r个初始归并段做 k k k路归并,则归并树可用 k k k叉树表示,若树高为 h h h,则归并趟数 n n n为:
n = h − 1 = ⌈ l o g k r ⌉ n=h-1=⌈log_kr⌉ n=h−1=⌈logkr⌉
因此归并路数(增加缓冲区的个数)越多,初始归并段(增加缓冲区的长度)越少,读写磁盘的次数就越少。但多路归并同样存在着问题:
- 问题一: k k k路归并时,需要开辟 k k k个输入缓冲区,内存开销增大。
- 问题二:每挑选一个关键字需要对比关键字 k − 1 k-1 k−1次,内部归并所需要的时间增加。
败者树
败者树可视为多一个根结点的完全二叉树, k k k个叶结点分别是当前参加比较的元素,非叶子结点用来记忆左右子树中的失败者,而让胜者往上继续进行比较,一直到根结点。
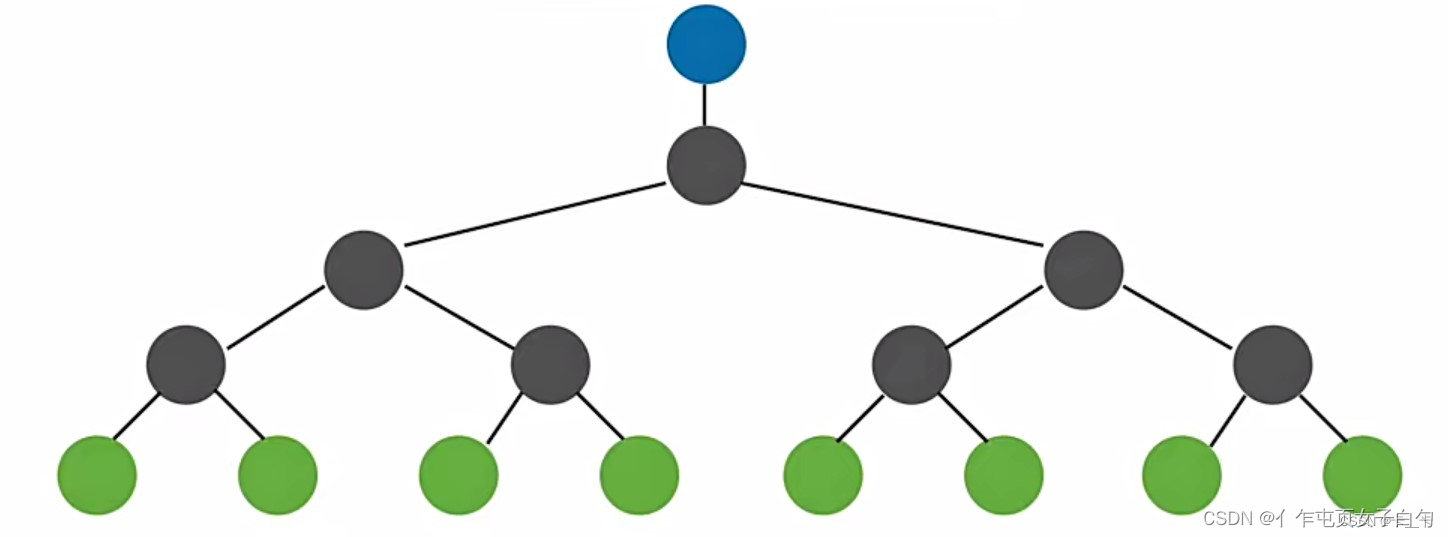
可以将败者树用于多路归并从而减少关键字的对比,从而解决问题二。对于 k k k路归并,第一次构造败者树需要对比关键字 k − 1 k-1 k−1次,有了败者树,选出最小元素,只需要对比关键字 ⌈ l o g 2 k ⌉ ⌈log_2k⌉ ⌈log2k⌉次。
置换——选择排序
对于传统归并段构造的方法,如果用于内部排序的输入缓冲区可容纳 l l l个记录,则每个初始归并段也只能包含 l l l个记录,若文件共有 n n n个记录,则初始归并段的数量为 r = n l r=\frac{n}{l} r=ln。而置换——选择排序可以构造比内存缓冲区长度长的归并段。置换——选择排序的思想为:
- 假设输入缓冲区的大小为三,读入代排文件中的三个记录。
- 每次将缓冲区的最小记录放到归并段一的末尾(并在内存中记录这个最小记录
miniMax),接着读入待排文件的下一记录填充输入缓冲区。 - 若当前缓冲区的最小记录小于
miniMax,那么就不可能将其放到归并段一的末尾,此时找到第二小且大于miniMax的记录放到归并段。 - 当某一时刻输入缓冲区的所有记录都小于
miniMax时,第一个初始归并段就构造结束。 - 接着以同样的方式构造初始归并段二,依次类推直到待排文件为空。
最佳归并树
如果采用置换——选择排序构造初始归并段,并将每一个初始归并段看作一个叶子结点,归并段的长度作为结点的权值,则归并树的带权路径长度 W S L WSL WSL有以下公式成立:
W S L = 读磁盘的次数 = 写磁盘的次数 WSL=读磁盘的次数=写磁盘的次数 WSL=读磁盘的次数=写磁盘的次数
那么 W S L WSL WSL最小的树就是一棵哈夫曼树,从而可以通过构造一棵哈夫曼树以使存盘存取次数最小。在构造哈夫曼树树的过程中,如果初始归并段的数量无法构成严格的 k k k叉哈夫曼树,那么就需要补充长度为0的虚段,再进行构造。对于一棵 k k k叉归并树:
- 如果 ( 初始归并段的数量 − 1 ) % ( k − 1 ) = 0 (初始归并段的数量-1)\%(k-1)=0 (初始归并段的数量−1)%(k−1)=0,则说明刚好可以构成严格 k k k叉哈夫曼树,此时不需要添加虚段。
- 如果 ( 初始归并段的数量 − 1 ) % ( k − 1 ) = u ≠ 0 (初始归并段的数量-1)\%(k-1)=u\neq0 (初始归并段的数量−1)%(k−1)=u=0,则需要补充 ( k − 1 ) − u (k-1)-u (k−1)−u个虚段。