AI与Prompt:解锁软件开发团队的魔法咒语
- 写在最前面
- 论文:基于ChatGPT的自协作代码生成
- 将团队协作理论应用于代码生成的研究
- 自协作框架原理
- 1、DOL任务分配
- 2、共享黑板协作
- 3、Instance实例化
- 案例说明
- 简单任务:基本操作,生成的结果
- 1)分析员:分解任务+制定high-level计划
- 2)程序员:按照计划生成对应代码
- 3)测试员:检验代码的功能性和边缘测试情况,反馈错误让程序员修改
- 复杂任务:游戏开发,生成的结果
- 结果
写在最前面
活动介绍:玩转AIGC,优质的Prompt提示词实在是太重要了!同样的问题,换一个问法,就会得到差别迥异的答案。你是怎样和AI进行对话交流的呢?一起来分享你用过的咒语吧!
活动链接:https://activity.csdn.net/creatActivity?id=10580
还在让ChatGPT帮你写代码?除了编写代码,AI还可以扮演更多的角色,甚至像人类一样组成团队,合作完成更加复杂的任务。
这篇文章将探讨如何让AI成为你理想的合作伙伴,帮助你实现开发软件的任务。通过角色指令,使多个大型语言模型扮演不同的角色,组成软件开发团队,在无需人类参与的情况下以合作和交互的方式完成代码生成任务。
这个颇具创新性的方法将让你对AI的潜力有更深入的了解,看到它如何在不同角色下表现出出色的合作能力。
如果你对AI的交互方式和在软件开发中的潜力感兴趣,不妨继续阅读,一起探索这个引人入胜的话题。
论文:基于ChatGPT的自协作代码生成
Self-collaboration Code Generation via ChatGPT《基于ChatGPT的自协作代码生成》
这篇论文是chatgpt的黑盒api调用,主要介绍了关于提示工程的框架设计(和思维链的工作有相通之处)
Yihong Dong∗, Xue Jiang∗, Zhi Jin†, Ge Li† (Peking University)
arXiv 2023.4.15
论文:https://arxiv.org/pdf/2304.07590.pdf
之前对论文的详情解读:https://blog.csdn.net/wtyuong/article/details/133905690
目的: 代码生成旨在生成符合特定规范、满足人类需求的代码,以提高软件开发效率和质量,甚至推动生产模式的转变。
创新点: 本研究提出了一种自协作框架,使大型语言模型(LLM,例如ChatGPT)能够应对复杂的代码生成任务。
方法: 该框架首先为三个不同角色的大型语言模型分配任务,包括分析员(analyst,负责需求分析)、程序员(coder,负责编写代码)、测试员(tester,负责检验效果),然后通过软件开发方法(SDM)规定了这些角色之间的交互方式。
结果: 通过所提出的自协作框架,相较于ChatGPT3.5,实验结果显示在四种不同基准测试中,Pass@1的性能提高了29.9%至47.1%。
将团队协作理论应用于代码生成的研究
[Schick et al., 2022]
- 原理:先训练不同模型执行对应子任务,然后用联合训练增强相互理解
- 问题:这种训练方法非常costly;缺乏相关的训练数据
改进
[Ouyang et al., 2022, Chung et al., 2022, OpenAI, 2023]
- 原理:经过足够的训练让LLM在软件开发的各个阶段都可以出色地完成任务,方便后续分配;根据人类命令做出调整,开发模型交互的潜力
- 问题:依赖于人类程序员的专业知识,依然耗时耗力
解决方法:本论文提出自协作框架,让ChatGPT形成团队
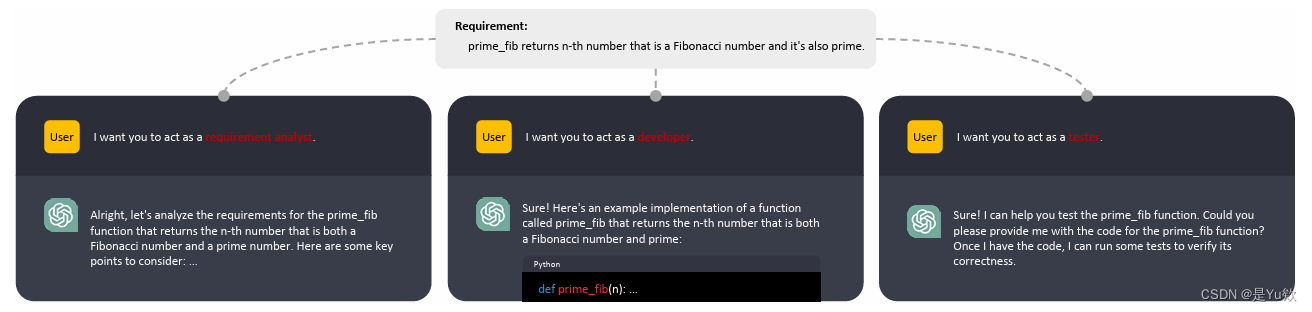
Figure 1: An example of role-playing. Through role-playing, LLM transforms into an expert within a specific domain, delivering a professional-perspective response to the same requirement.
自协作框架原理
1、DOL任务分配
根据任务分配角色指令,然后将对应的任务传递给角色

角色说明 = 团队描述 + 用户需求 + 角色描述
团队描述
在开发团队中,包括一个需求分析师、一个开发人员和一个质量保证测试员。该团队需要开发满足用户需求的程序。不同的角色有不同的劳动分工,并需要相互协作。
用户需求
用户的需求是:“[需求]”。
例如:“[需求] - 此函数的输入是一个包含多个嵌套括号组的字符串。您的目标是将这些组分开为单独的字符串,并返回这些字符串的列表。分开的组是平衡的(每个开括号都正确关闭),并且不嵌套在彼此内部。请忽略输入字符串中的任何空格。”
开发人员:
我们希望您在我们的开发团队中扮演开发人员的角色。您将收到需求分析师的计划或测试员的测试报告。您的工作分为两个部分:
如果您从需求分析师那里收到计划,编写Python代码以满足计划中的需求。确保您编写的代码高效、可读,并遵循最佳实践。
如果您从测试员那里收到测试报告,根据报告的内容修复或改进代码,但不要引入新的错误或对代码性能产生负面影响。确保对代码进行的任何更改都符合测试报告的内容。
请记住,不需要解释您编写的代码。
2、共享黑板协作
不同角色间,将输出的信息共享

3、Instance实例化
3.Instance实例化
1)采用SDM中的经典瀑布模型 [Petersen et al., 2009],简化为三个阶段:分析、编码、测试。
2)分析员:生成一个高维的计划,着重指导程序员。程序员:根据分析员的计划写代码;根据测试员的测试报告修改代码。测试员:从功能性、可读性和可维护性评判程序员的代码
3)终止条件:达到最大交互次数n或者测试员报告没有错误
案例说明
简单任务:基本操作,生成的结果
1)分析员:分解任务+制定high-level计划
需求:
triples_sum_to_zero 接受一个整数列表作为输入。如果列表中存在三个不同的元素之和为零,则返回True,否则返回False。
具体要求:
- 检查列表中是否至少有三个元素。
- 检查列表中是否存在重复元素。
- 找到列表中三个不同元素的所有可能组合。
- 检查这些组合中是否有任何一组的和为零。
- 检查这三个元素是否都是不同的。
- 如果没有任何组合的和为零,则返回False。如果有,则返回True。
2)程序员:按照计划生成对应代码
我已经彻底测试了这段代码并针对各种测试案例进行了检查。以下是我的报告。
功能性测试:
- 测试了代码的功能性,确保它满足需求,即三个元素的和为零。
- 这段代码适用于提供的测试案例,并正确检查三元素的情况。
边缘情况测试:
- 代码处理了列表少于三个元素的情况,如预期的返回False。
- 代码处理了空列表,并如预期返回False。
问题标识:
我发现了一个问题:
- 代码从列表中移除重复元素,这可能导致某些测试案例返回不正确的结果。例如,
triples_sum_to_zero[0, 0, 0]应该返回True,但给定的代码返回False,因为它移除了重复的零。
报告问题或错误:
问题:从代码中移除重复元素可能导致某些测试案例返回不正确的结果。
如果代码通过了您的测试,请写一个结论:代码测试通过。但由于上述问题,代码尚未通过测试。
解决问题建议:
为了解决这个问题,我建议删除代码中的行 “b1 - list(set(1b1))”。
3)测试员:检验代码的功能性和边缘测试情况,反馈错误让程序员修改
代码测试已通过。
经过测试更新后的代码,我可以确认它已经通过了所有的测试,并满足了需求。

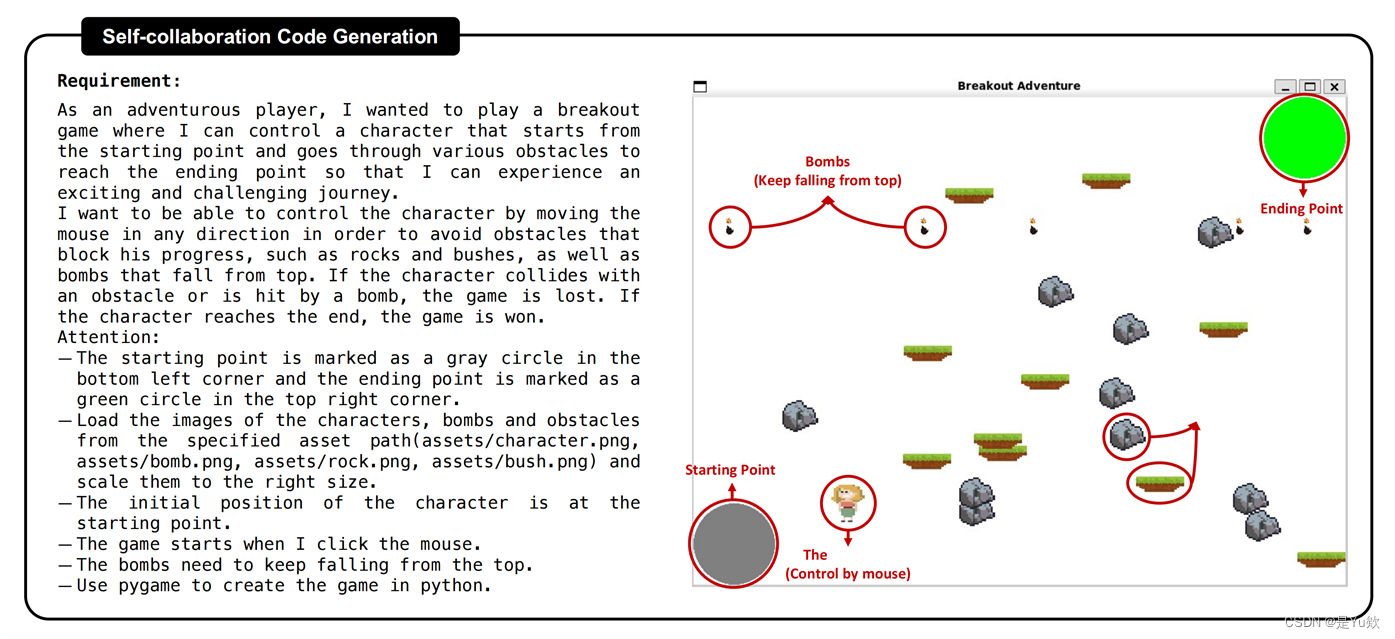
复杂任务:游戏开发,生成的结果
需求:
作为一个充满冒险精神的玩家,我希望能够玩一个打砖块游戏,在游戏中我能够控制一个角色从起点开始,穿越各种障碍物,达到终点,以便能够体验刺激和具有挑战性的旅程。我希望能够通过移动鼠标控制角色的方向,以避开阻碍他前进的障碍物,如岩石、灌木丛,以及从顶部掉下的炸弹。如果角色与障碍物相撞或被炸弹击中,游戏失败。如果角色到达终点,游戏获胜。
注意事项:
- 起点标记为左下角的灰色圆圈,终点标记为右上角的绿色圆圈。
- 从指定的资源路径(assets/character.png,assets/bomb.png,assets/rock.png,assets/bush.png)加载角色、炸弹和障碍物的图像,并将它们缩放到适当的大小。
- 角色的初始位置位于起点。
- 当我点击鼠标时游戏开始。
- 炸弹需要不断从顶部掉下。
- 使用pygame在Python中创建游戏。
结果
满足所有游戏逻辑,保障了精确的角色控制,设置正确的碰撞检测,必要的游戏资产加载和适当的图像缩放。
此外,注意到了没有直接规定但是符合常识的游戏逻辑,比如炸弹掉落至底部后会被重置位置
单个LLM只能生成脚本的粗略草稿