文章目录
- 引言
- 特征工程
- 1.特征类型
- 1.1 结构化 vs 非结构化数据
- 1.2 定量 vs 定性数据
- 2.数据清洗
- 2.1 数据对齐
- 2.2 缺失值处理
原文链接:https://www.showmeai.tech/article-detail/208
作者:showmeAI
引言
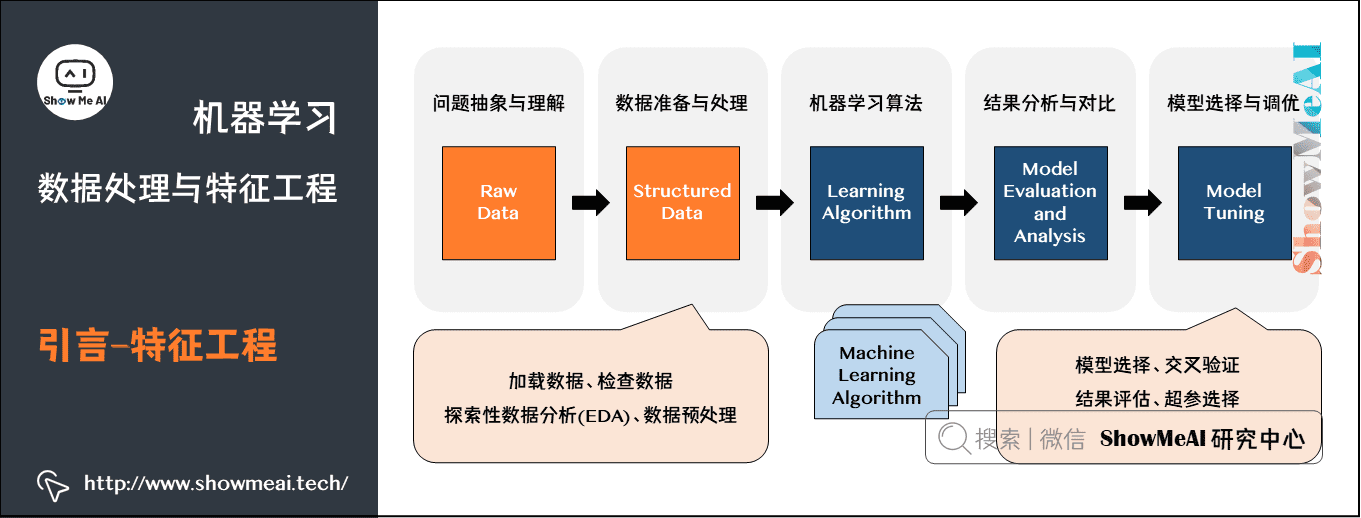
上图为大家熟悉的机器学习建模流程图,ShowMeAI在前序机器学习实战文章 Python机器学习算法应用实践中和大家讲到了整个建模流程非常重要的一步,是对于数据的预处理和特征工程,它很大程度决定了最后建模效果的好坏,在本篇内容汇总,我们给大家展开对数据预处理和特征工程的实战应用细节做一个全面的解读。
特征工程
首先我们来了解一下「特征工程」,事实上大家在ShowMeAI的实战系列文章 Python机器学习综合项目-电商销量预估 和 Python机器学习综合项目-电商销量预估<进阶> 中已经看到了我们做了特征工程的处理。
如果我们对特征工程(feature engineering)做一个定义,那它指的是:利用领域知识和现有数据,创造出新的特征,用于机器学习算法;可以手动(manual)或自动(automated)。
- 特征:数据中抽取出来的对结果预测有用的信息。
- 特征工程:使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
在业界有一个很流行的说法:
数据与特征工程决定了模型的上限,改进算法只不过是逼近这个上限而已。

这是因为,在数据建模上,「理想状态」和「真实场景」是有差别的,很多时候原始数据并不是规矩干净含义明确充分的形态:
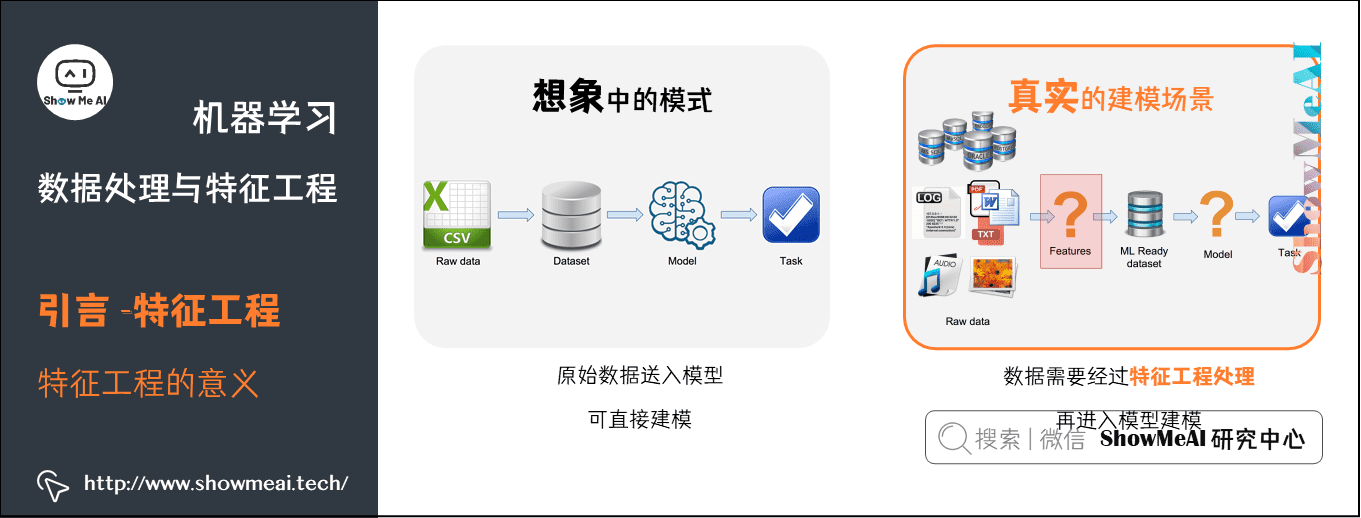
而特征工程处理,相当于对数据做一个梳理,结合业务提取有意义的信息,以干净整齐地形态进行组织:

特征工程有着非常重要的意义:
- 特征越好,灵活性越强。只要特征选得好,即使是一般的模型(或算法)也能获得很好的性能,好特征的灵活性在于它允许你选择不复杂的模型,同时运行速度也更快,也更容易理解和维护。
- 特征越好,构建的模型越简单。有了好的特征,即便你的参数不是最优的,你的模型性能也能仍然会表现的很好,所以你就不需要花太多的时间去寻找最优参数,这大大的降低了模型的复杂度,使模型趋于简单。
- 特征越好,模型的性能越出色。显然,这一点是毫无争议的,我们进行特征工程的最终目的就是提升模型的性能。
本篇内容,ShowMeAI带大家一起来系统学习一下特征工程,包括「特征类型」「数据清洗」「特征构建」「特征变换」「特征选择」等板块内容。
我们这里用最简单和常用的Titanic数据集给大家讲解。
Titanic数据集是非常适合数据科学和机器学习新手入门练习的数据集,数据集为1912年泰坦尼克号沉船事件中一些船员的个人信息以及存活状况。我们可以根据数据集训练出合适的模型并预测新数据(测试集)中的存活状况。
Titanic数据集可以通过 seaborn 工具库直接加载,如下代码所示:
import pandas as pd
import numpy as np
import seaborn as snsdf_titanic = sns.load_dataset('titanic')
其中数据集的数据字段描述如下图所示:

1.特征类型
在具体演示Titanic的数据预处理与特征工程之前,ShowMeAI再给大家构建一些关于数据的基础知识。
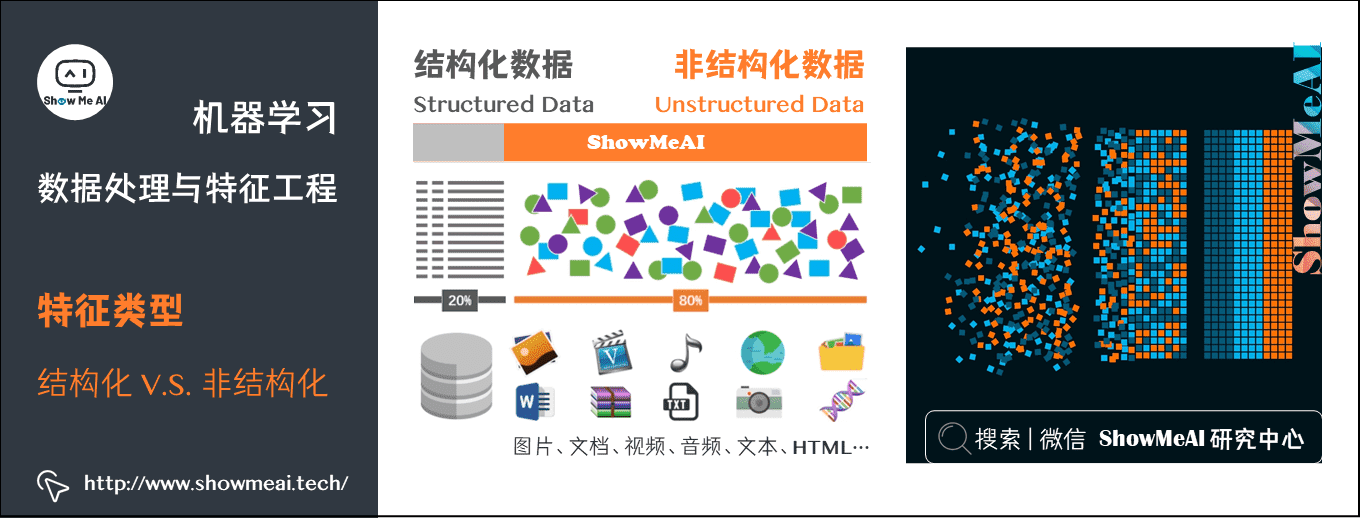
1.1 结构化 vs 非结构化数据
数据可以分为「结构化数据」和「非结构化数据」,比如在互联网领域,大部分存储在数据库内的表格态业务数据,都是结构化数据;而文本、语音、图像视频等就属于非结构化数据。
1.2 定量 vs 定性数据
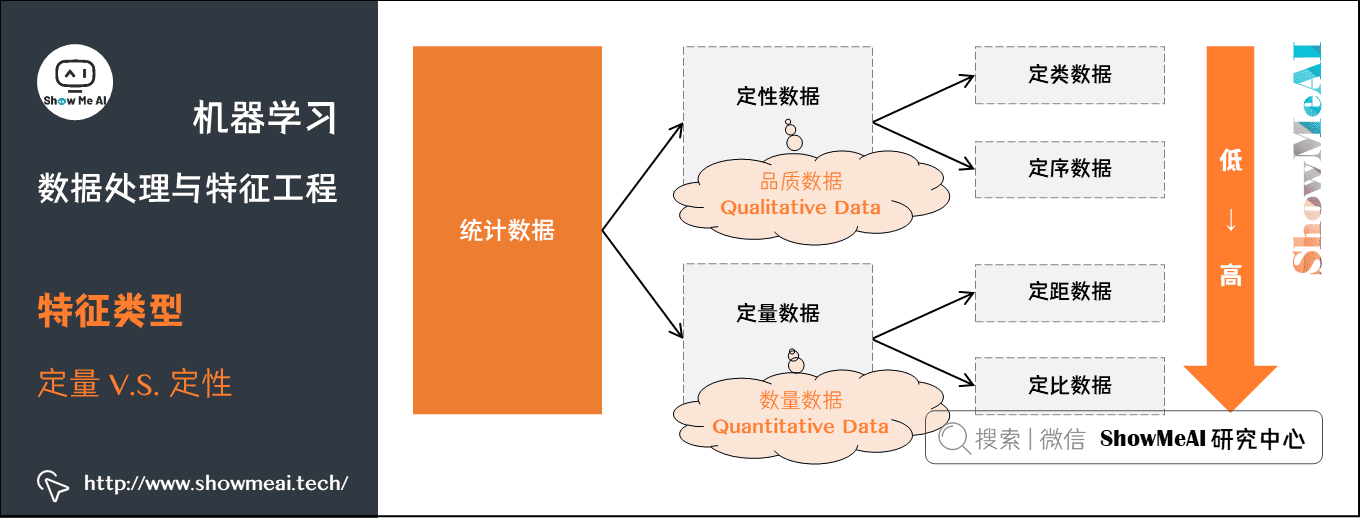
对于我们记录到的数据,我们通常又可以以「定量数据」和「定性数据」对齐进行区分,其中:
- 定量数据:指的是一些数值,用于衡量数量与大小。
例如高度,长度,体积,面积,湿度,温度等测量值。 - 定性数据:指的是一些类别,用于描述物品性质。
例如纹理,味道,气味,颜色等。
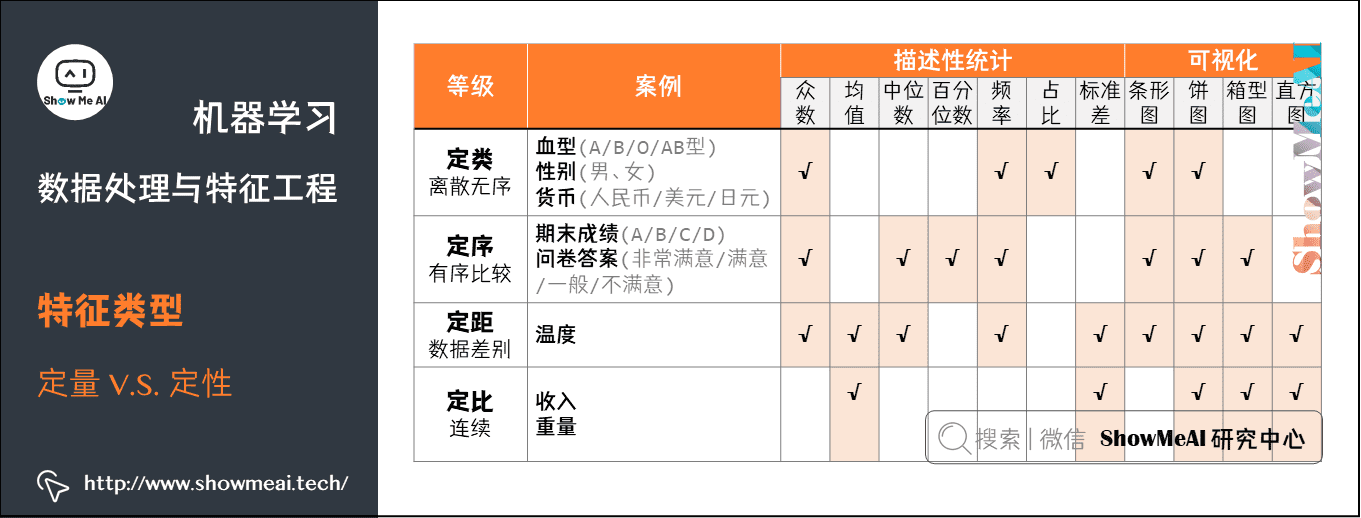
如下图是两类数据示例以及它们常见的处理分析方法的总结:
2.数据清洗
实际数据挖掘或者建模之前,我们会有「数据预处理」环节,对原始态的数据进行数据清洗等操作处理。因为现实世界中数据大体上都是不完整、不一致的「脏数据」,无法直接进行数据挖掘,或者挖掘结果差强人意。
「脏数据」产生的主要成因包括:
- 篡改数据
- 数据不完整
- 数据不一致
- 数据重复
- 异常数据
数据清洗过程包括数据对齐、缺失值处理、异常值处理、数据转化等数据处理方法,如下图所示:

下面我们注意对上述提到的处理方法做一个讲解。
2.1 数据对齐
采集到的原始数据,格式形态不一,我们会对时间、字段以及相关量纲等进行数据对齐处理,数据对齐和规整化之后的数据整齐一致,更加适合建模。如下图为一些处理示例:

(1) 时间
- 日期格式不一致【2022-02-20、20220220、2022/02/20、20/02/2022】。
- 时间戳单位不一致,有的用秒表示,有的用毫秒表示。
- 使用无效时间表示,时间戳使用0表示,结束时间戳使用FFFF表示。
(2) 字段 - 姓名写了性别,身份证号写了手机号等。
(3) 量纲 - 数值类型统一【如1、2.0、3.21E3、四】。
- 单位统一【如180cm、1.80m】。
2.2 缺失值处理
数据缺失是真实数据中常见的问题,因为种种原因我们采集到的数据并不一定是完整的,我们有一些缺失值的常见处理方式:
- 不处理(部分模型如XGBoost/LightGBM等可以处理缺失值)。
- 删除缺失数据(按照样本维度或者字段维度)。
- 采用均值、中位数、众数、同类均值或预估值填充。
具体的处理方式可以展开成下图:

下面回到我们的Titanic数据集,我们演示一下各种方法:
我们先对数据集的缺失值情况做一个了解(汇总分布):
df_titanic.isnull().sum()
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
(1) 删除
最直接粗暴的处理是剔除缺失值,即将存在遗漏信息属性值的对象 (字段,样本/记录) 删除,从而得到一个完备的信息表。优缺点如下:
- 优点:简单易行,在对象有多个属性缺失值、被删除的含缺失值的对象与初始数据集的数据量相比非常小的情况下有效;
- 不足:当缺失数据所占比例较大,特别当遗漏数据非随机分布时,这种方法可能导致数据发生偏离,从而引出错误的结论。
在我们当前Titanic的案例中,embark_town字段有 2 个空值,考虑删除缺失处理下。
df_titanic[df_titanic["embark_town"].isnull()]
df_titanic.dropna(axis=0,how='any',subset=['embark_town'],inplace=True)

(2) 数据填充
第2大类是我们可以通过一些方法去填充缺失值。比如基于统计方法、模型方法、结合业务的方法等进行填充。

① 手动填充
根据业务知识来进行人工手动填充。
② 特殊值填充
将空值作为一种特殊的属性值来处理,它不同于其他的任何属性值。如所有的空值都用unknown填充。一般作为临时填充或中间过程。
代码实现
df_titanic['embark_town'].fillna('unknown', inplace=True)
③ 统计量填充
若缺失率较低,可以根据数据分布的情况进行填充。常用填充统计量如下:
- 中位数:对于数据存在倾斜分布的情况,采用中位数填补缺失值。
- 众数:离散特征可使用众数进行填充缺失值。
- 平均值:对于数据符合均匀分布,用该变量的均值填补缺失值。
中位数填充——fare:缺失值较多,使用中位数填充
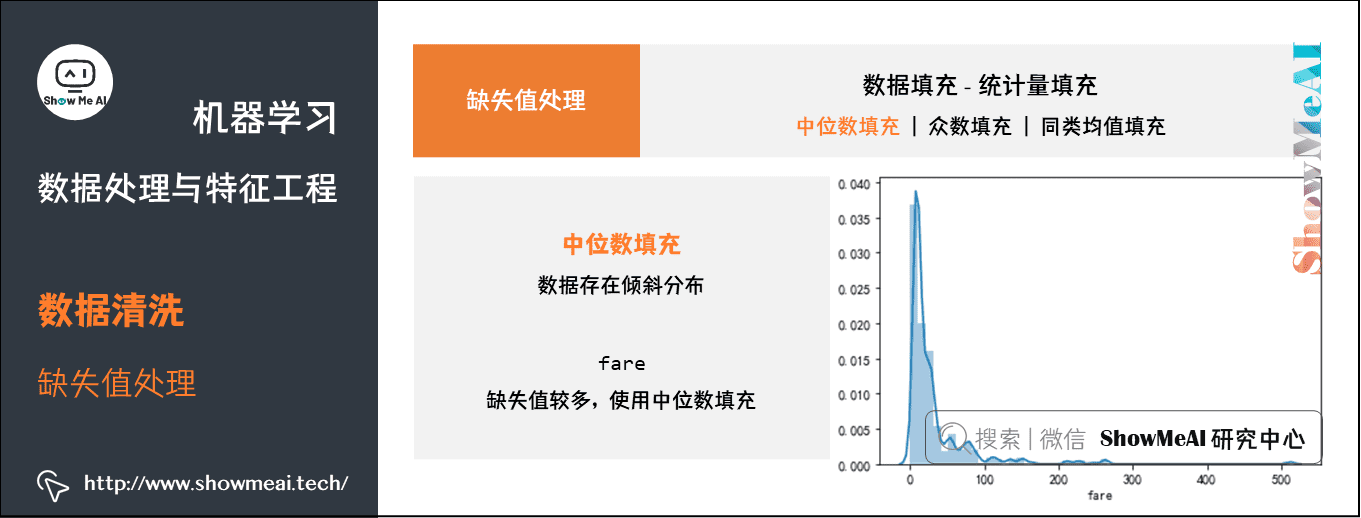
df_titanic['fare'].fillna(df_titanic['fare'].median(), inplace=True)
众数填充——embarked:只有两个缺失值,使用众数填充
df_titanic['embarked'].isnull().sum()
#执行结果:2
df_titanic['embarked'].fillna(df_titanic['embarked'].mode(), inplace=True)
df_titanic['embarked'].value_counts()
#执行结果:
#S 64
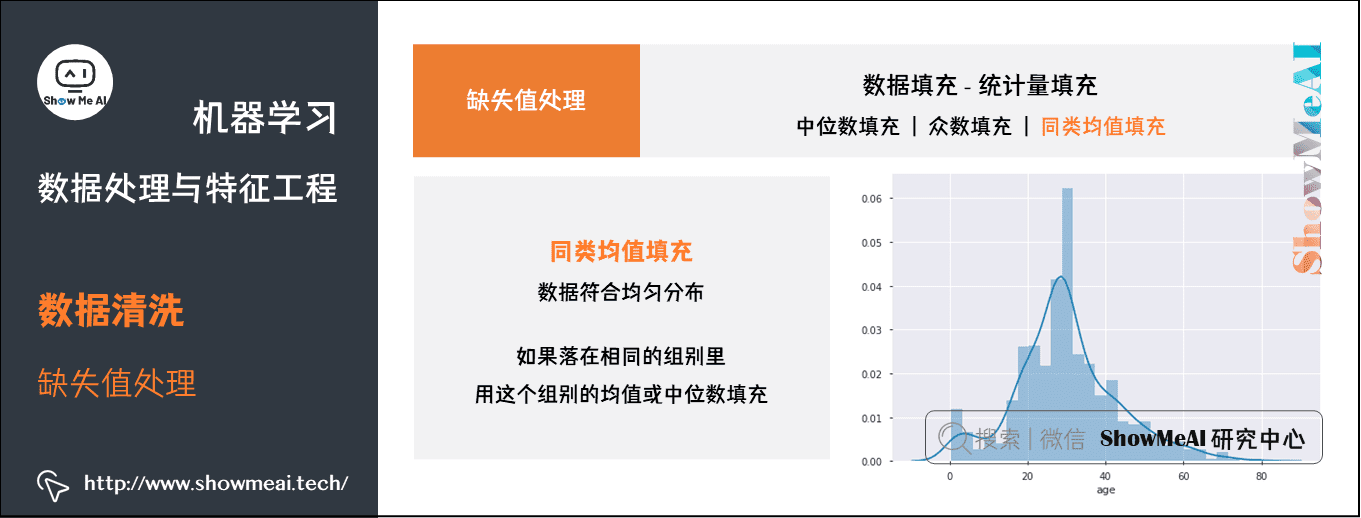
同类均值填充
age:根据 sex、pclass 和 who 分组,如果落在相同的组别里,就用这个组别的均值或中位数填充。
df_titanic.groupby(['sex', 'pclass', 'who'])['age'].mean()
age_group_mean = df_titanic.groupby(['sex', 'pclass', 'who'])['age'].mean().reset_index()
def select_group_age_median(row):condition = ((row['sex'] == age_group_mean['sex']) &(row['pclass'] == age_group_mean['pclass']) &(row['who'] == age_group_mean['who']))return age_group_mean[condition]['age'].values[0]
df_titanic['age'] =df_titanic.apply(lambda x: select_group_age_median(x) if np.isnan(x['age']) else x['age'],axis=1)
④ 模型预测填充
如果其他无缺失字段丰富,我们也可以借助于模型进行建模预测填充,将待填充字段作为Label,没有缺失的数据作为训练数据,建立分类/回归模型,对待填充的缺失字段进行预测并进行填充。
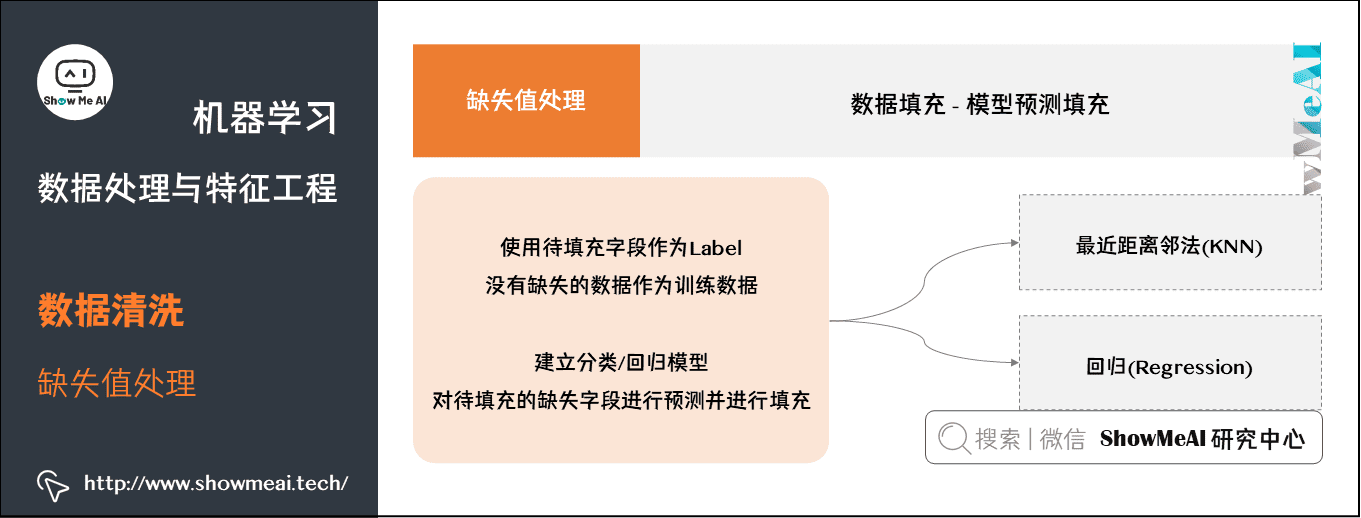
最近距离邻法(KNN)
- 先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的 公式 个样本,将这 公式 个值加权平均/投票来估计该样本的缺失数据。
回归(Regression)
- 基于完整的数据集,建立回归方程。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。当变量不是线性相关时会导致有偏差的估计,常用线性回归。
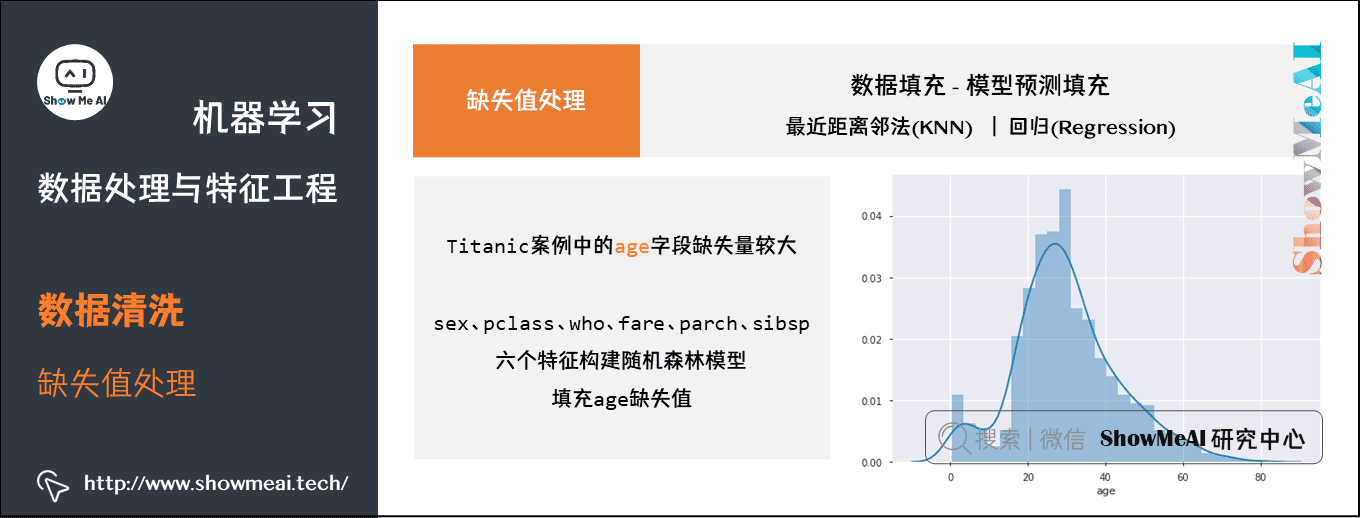
我们以 Titanic 案例中的 age 字段为例,讲解一下:
- age 缺失量较大,这里我们用 sex、pclass、who、fare、parch、sibsp 六个特征构建随机森林模型,填充年龄缺失值。
df_titanic_age = df_titanic[['age', 'pclass', 'sex', 'who','fare', 'parch', 'sibsp']] df_titanic_age = pd.get_dummies(df_titanic_age) df_titanic_age.head()# 乘客分成已知年龄和未知年龄两部分 known_age = df_titanic_age[df_titanic_age.age.notnull()] unknown_age = df_titanic_age[df_titanic_age.age.isnull()] # y 即目标年龄 y_for_age = known_age['age'] # X 即特征属性值 X_train_for_age = known_age.drop(['age'], axis=1) X_test_for_age = unknown_age.drop(['age'], axis=1) from sklearn.ensemble import RandomForestRegressor rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1) rfr.fit(X_train_for_age, y_for_age) # 用得到的模型进行未知年龄结果预测 y_pred_age = rfr.predict(X_test_for_age) # 用得到的预测结果填补原缺失数据 df_titanic.loc[df_titanic.age.isnull(), 'age'] = y_pred_agesns.distplot(df_titanic.age)