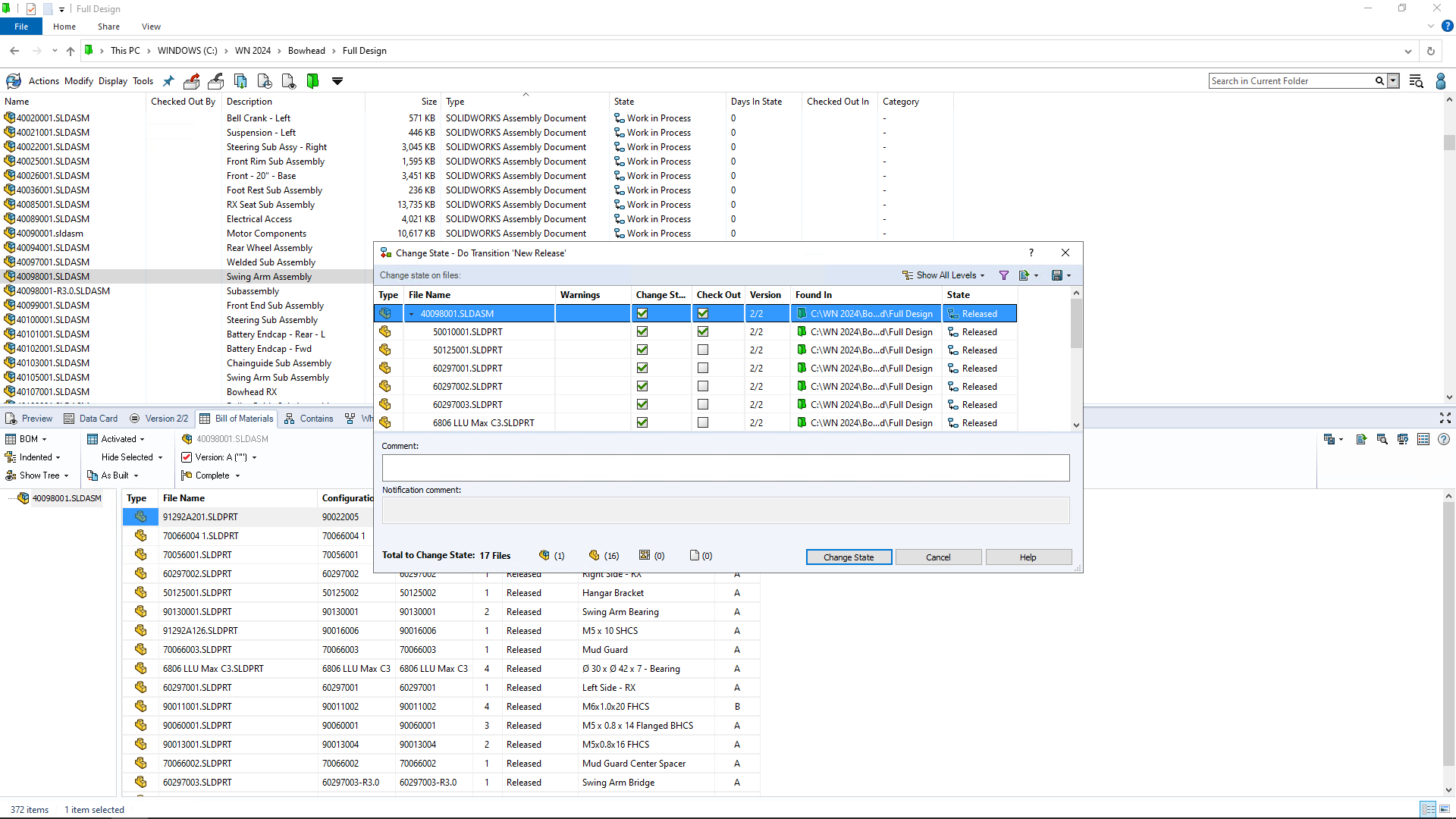
二进制搭建 Kubernetes v1.20
k8s集群master01:20.0.0.50 kube-apiserver kube-controller-manager kube-scheduler etcd
k8s集群master02:20.0.0.100k8s集群node01:20.0.0.110 kubelet kube-proxy docker etcd
k8s集群node02:20.0.0.120 kubelet kube-proxy docker etcdetcd集群节点1:20.0.0.50 etcd
etcd集群节点2:20.0.0.110 etcd
etcd集群节点3:20.0.0.110 etcd负载均衡nginx+keepalive01(master):20.0.0.31
负载均衡nginx+keepalive02(backup):20.0.0.32VIP 20.0.0.200
操作系统初始化配置
#所有主机操作
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalldiptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X#关闭selinux
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config#关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab #根据规划设置主机名
#20.0.0.50
hostnamectl set-hostname master01
#20.0.0.110
hostnamectl set-hostname node01
#20.0.0.120
hostnamectl set-hostname node02在master添加hosts
cat >> /etc/hosts << EOF
20.0.0.50 master01
20.0.0.110 node01
20.0.0.120 node02
EOF

调整内核参数(master)
cat > /etc/sysctl.d/k8s.conf << EOF
#开启网桥模式,可将网桥的流量传递给iptables链
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
#关闭ipv6协议
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
EOFsysctl --system
配置时间同步(所有主机节点)
#时间同步
yum install ntpdate -y
ntpdate time.windows.com部署 docker引擎
#所有 node 节点部署docker引擎yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum install -y docker-ce docker-ce-cli containerd.iosystemctl start docker.service
systemctl enable docker.service
部署 etcd 集群
etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd是go语言编写的。
etcd 作为服务发现系统,有以下的特点:
简单:安装配置简单,而且提供了HTTP API进行交互,使用也很简单
安全:支持SSL证书验证
快速:单实例支持每秒2k+读操作
可靠:采用raft算法,实现分布式系统数据的可用性和一致性
etcd 目前默认使用2379端口提供HTTP API服务, 2380端口和peer通信(这两个端口已经被IANA(互联网数字分配机构)官方预留给etcd)。 即etcd默认使用2379端口对外为客户端提供通讯,使用端口2380来进行服务器间内部通讯。
etcd 在生产环境中一般推荐集群方式部署。由于etcd 的leader选举机制,要求至少为3台或以上的奇数台。
---------- 准备签发证书环境 ----------
CFSSL 是 CloudFlare 公司开源的一款 PKI/TLS 工具。
CFSSL 包含一个命令行工具和一个用于签名、验证和捆绑 TLS 证书的 HTTP API 服务。使用Go语言编写。
CFSSL 使用配置文件生成证书,因此自签之前,需要生成它识别的 json 格式的配置文件,CFSSL 提供了方便的命令行生成配置文件。
CFSSL 用来为 etcd 提供 TLS 证书,它支持签三种类型的证书:
1、client 证书,服务端连接客户端时携带的证书,用于客户端验证服务端身份,如 kube-apiserver 访问 etcd;
2、server 证书,客户端连接服务端时携带的证书,用于服务端验证客户端身份,如 etcd 对外提供服务;
3、peer 证书,相互之间连接时使用的证书,如 etcd 节点之间进行验证和通信。
这里全部都使用同一套证书认证。在 master01 节点上操作
#准备cfssl证书生成工具
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -O /usr/local/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -O /usr/local/bin/cfssljson
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -O /usr/local/bin/cfssl-certinfochmod +x /usr/local/bin/cfssl*-------------------------------------------------------------------------
cfssl:证书签发的工具命令
cfssljson:将 cfssl 生成的证书(json格式)变为文件承载式证书
cfssl-certinfo:验证证书的信息
cfssl-certinfo -cert <证书名称> #查看证书的信息
-------------------------------------------------------------------------
生成Etcd证书
mkdir /opt/k8s
cd /opt/k8s/#上传 etcd-cert.sh 和 etcd.sh 到 /opt/k8s/ 目录中
chmod +x etcd-cert.sh etcd.sh#创建用于生成CA证书、etcd 服务器证书以及私钥的目录
mkdir /opt/k8s/etcd-cert
mv etcd-cert.sh etcd-cert/
cd /opt/k8s/etcd-cert/
./etcd-cert.sh #生成CA证书、etcd 服务器证书以及私钥ls
ca-config.json ca-csr.json ca.pem server.csr server-key.pem
ca.csr ca-key.pem etcd-cert.sh server-csr.json server.pem


#上传 etcd-v3.4.9-linux-amd64.tar.gz 到 /opt/k8s 目录中,启动etcd服务
https://github.com/etcd-io/etcd/releases/download/v3.4.9/etcd-v3.4.9-linux-amd64.tar.gzcd /opt/k8s/
tar zxvf etcd-v3.4.9-linux-amd64.tar.gz
ls etcd-v3.4.9-linux-amd64
Documentation etcd etcdctl README-etcdctl.md README.md READMEv2-etcdctl.md
------------------------------------------------------------------------------------------
etcd就是etcd 服务的启动命令,后面可跟各种启动参数
etcdctl主要为etcd 服务提供了命令行操作
------------------------------------------------------------------------------------------#创建用于存放 etcd 配置文件,命令文件,证书的目录
mkdir -p /opt/etcd/{cfg,bin,ssl}cd /opt/k8s/etcd-v3.4.9-linux-amd64/
mv etcd etcdctl /opt/etcd/bin/
cp /opt/k8s/etcd-cert/*.pem /opt/etcd/ssl/cd /opt/k8s/
./etcd.sh etcd01 20.0.0.50 etcd02=https://20.0.0.110:2380,etcd03=https://20.0.0.120:2380#进入卡住状态等待其他节点加入,这里需要三台etcd服务同时启动,如果只启动其中一台后,服务会卡在那里,直到集群中所有etcd节点都已启动,可忽略这个情况#可另外打开一个窗口查看etcd进程是否正常
ps -ef | grep etcd
#把etcd相关证书文件、命令文件和服务管理文件全部拷贝到另外两个etcd集群节点
scp -r /opt/etcd/ root@20.0.0.110:/opt/
scp -r /opt/etcd/ root@20.0.0.120:/opt/
scp /usr/lib/systemd/system/etcd.service root@20.0.0.110:/usr/lib/systemd/system/
scp /usr/lib/systemd/system/etcd.service root@20.0.0.120:/usr/lib/systemd/system/在 node01 节点上操作(20.0.0.110)
vim /opt/etcd/cfg/etcd
#[Member]
ETCD_NAME="etcd02" #修改
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://20.0.0.110:2380" #修改
ETCD_LISTEN_CLIENT_URLS="https://20.0.0.110:2379" #修改#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://20.0.0.110:2380" #修改
ETCD_ADVERTISE_CLIENT_URLS="https://20.0.0.110:2379" #修改
ETCD_INITIAL_CLUSTER="etcd01=https://20.0.0.50:2380,etcd02=https://20.0.0.110:2380,etcd03=https://20.0.0.120:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"#启动etcd服务
systemctl start etcd
systemctl enable etcd ##systemctl enable --now etcd
systemctl在enable、disable、mask子命令里面增加了--now选项,可以激活同时启动服务,激活同时停止服务等。systemctl status etcd

在 node02 节点上操作(20.0.0.120)
vim /opt/etcd/cfg/etcd
#[Member]
ETCD_NAME="etcd03"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://20.0.0.120:2380"
ETCD_LISTEN_CLIENT_URLS="https://20.0.0.120:2379"#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://20.0.0.120:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://20.0.0.120:2379"
ETCD_INITIAL_CLUSTER="etcd01=https://20.0.0.50:2380,etcd02=https://20.0.0.110:2380,etcd03=https://20.0.0.120:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"#启动etcd服务
systemctl start etcd
systemctl enable etcd
systemctl status etcd
#检查etcd群集状态(任意节点均可查看)ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://20.0.0.50:2379,https://20.0.0.110:2379,https://20.0.0.120:2379" endpoint health --write-out=table------------------------------------------------------------------------------------------
--cert-file:识别HTTPS端使用SSL证书文件
--key-file:使用此SSL密钥文件标识HTTPS客户端
--ca-file:使用此CA证书验证启用https的服务器的证书
--endpoints:集群中以逗号分隔的机器地址列表
cluster-health:检查etcd集群的运行状况
------------------------------------------------------------------------------------------

#查看etcd集群成员列表
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://20.0.0.50:2379,https://20.0.0.110:2379,https://20.0.0.120:2379" --write-out=table member list
部署 Master 组件
在 master01 节点上操作
#上传 master.zip 和 k8s-cert.sh 到 /opt/k8s 目录中,解压 master.zip 压缩包
cd /opt/k8s/
unzip master.zip
chmod +x *.sh#创建kubernetes工作目录
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}#创建用于生成CA证书、相关组件的证书和私钥的目录
mkdir /opt/k8s/k8s-cert
mv /opt/k8s/k8s-cert.sh /opt/k8s/k8s-cert
cd /opt/k8s/k8s-cert/
./k8s-cert.sh #生成CA证书、相关组件的证书和私钥ls *pem
admin-key.pem apiserver-key.pem ca-key.pem kube-proxy-key.pem
admin.pem apiserver.pem ca.pem kube-proxy.pem#复制CA证书、apiserver相关证书和私钥到 kubernetes工作目录的 ssl 子目录中
cp ca*pem apiserver*pem /opt/kubernetes/ssl/
注意k8s-cert.sh 文件中 要确保IP指定正确
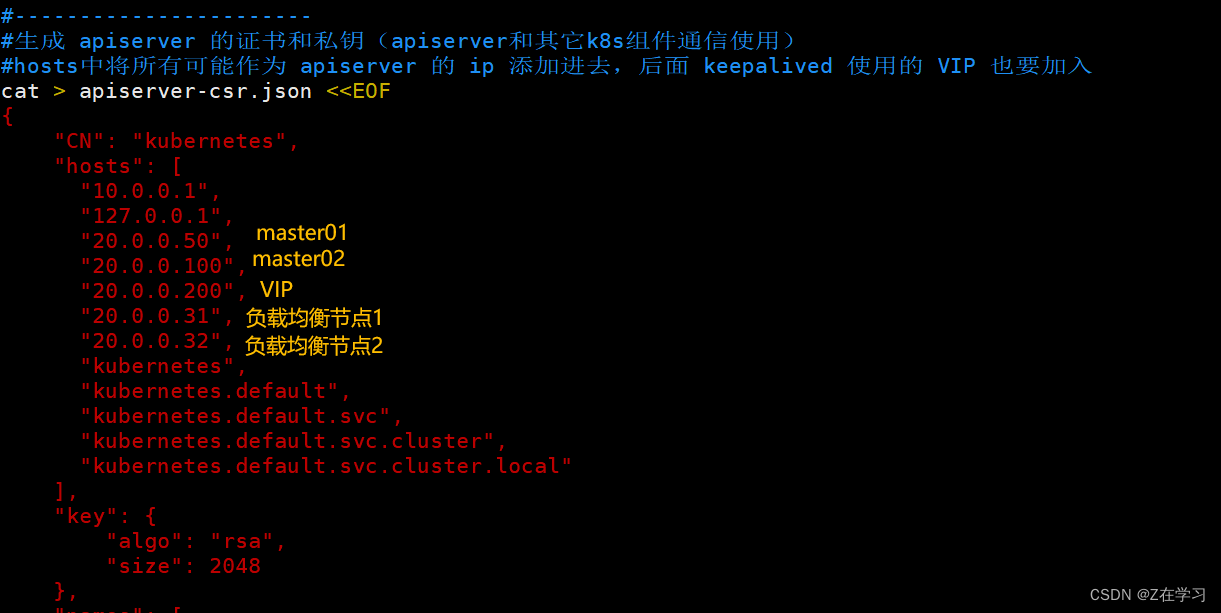
同样master.zip解压后的文件中IP也要修改正确

#上传 kubernetes-server-linux-amd64.tar.gz 到 /opt/k8s/ 目录中,解压 kubernetes 压缩包
#下载地址:https://github.com/kubernetes/kubernetes/blob/release-1.20/CHANGELOG/CHANGELOG-1.20.md
#注:打开链接你会发现里面有很多包,下载一个server包就够了,包含了Master和Worker Node二进制文件。cd /opt/k8s/
tar zxvf kubernetes-server-linux-amd64.tar.gz#复制master组件的关键命令文件到 kubernetes工作目录的 bin 子目录中cd /opt/k8s/kubernetes/server/bin
cp kube-apiserver kubectl kube-controller-manager kube-scheduler /opt/kubernetes/bin/
ln -s /opt/kubernetes/bin/* /usr/local/bin/#创建 bootstrap token 认证文件,apiserver 启动时会调用,
然后就相当于在集群内创建了一个这个用户,接下来就可以用 RBAC 给他授权cd /opt/k8s/vim token.sh
#!/bin/bash
#获取随机数前16个字节内容,以十六进制格式输出,并删除其中空格
BOOTSTRAP_TOKEN=$(head -c 16 /dev/urandom | od -An -t x | tr -d ' ')
#生成 token.csv 文件,按照 Token序列号,用户名,UID,用户组 的格式生成
cat > /opt/kubernetes/cfg/token.csv <<EOF
${BOOTSTRAP_TOKEN},kubelet-bootstrap,10001,"system:kubelet-bootstrap"
EOFchmod +x token.sh
./token.shcat /opt/kubernetes/cfg/token.csv
![]()


#二进制文件、token、证书都准备好后,开启 apiserver 服务
cd /opt/k8s/./apiserver.sh 20.0.0.50 https://20.0.0.50:2379,https://20.0.0.110:2379,https://20.0.0.120:2379#检查进程是否启动成功
ps aux | grep kube-apiservernetstat -natp | grep 6443 #安全端口6443用于接收HTTPS请求,用于基于Token文件或客户端证书等认证


#启动 scheduler 服务
cd /opt/k8s/
./scheduler.sh
ps aux | grep kube-scheduler
#启动 controller-manager 服务
./controller-manager.sh
ps aux | grep kube-controller-manager
#生成kubectl连接集群的kubeconfig文件
./admin.sh#通过kubectl工具查看当前集群组件状态
kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-2 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"} #查看版本信息
kubectl version
部署 Worker Node 组件
在所有 node 节点上操作(20.0.0.110、20.0.0.120)
#创建kubernetes工作目录
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}#上传 node.zip 到 /opt 目录中,解压 node.zip 压缩包,获得kubelet.sh、proxy.sh
cd /opt/
unzip node.zip
chmod +x kubelet.sh proxy.sh
在 master01 节点上操作
#把 kubelet、kube-proxy 拷贝到 node 节点
cd /opt/k8s/kubernetes/server/bin
scp kubelet kube-proxy root@20.0.0.110:/opt/kubernetes/bin/
scp kubelet kube-proxy root@20.0.0.120:/opt/kubernetes/bin/
#上传kubeconfig.sh文件到/opt/k8s/kubeconfig目录中,生成kubelet初次加入集群引导kubeconfig文件和kube-proxy.kubeconfig文件
#kubeconfig 文件包含集群参数(CA 证书、API Server 地址),客户端参数(上面生成的证书和私钥),集群 context 上下文参数(集群名称、用户名)。Kubenetes 组件(如 kubelet、kube-proxy)通过启动时指定不同的 kubeconfig 文件可以切换到不同的集群,连接到 apiserver。mkdir /opt/k8s/kubeconfigcd /opt/k8s/kubeconfig
chmod +x kubeconfig.sh
./kubeconfig.sh 20.0.0.50 /opt/k8s/k8s-cert/
#把配置文件 bootstrap.kubeconfig、kube-proxy.kubeconfig 拷贝到 node 节点
scp bootstrap.kubeconfig kube-proxy.kubeconfig root@20.0.0.110:/opt/kubernetes/cfg/
scp bootstrap.kubeconfig kube-proxy.kubeconfig root@20.0.0.120:/opt/kubernetes/cfg/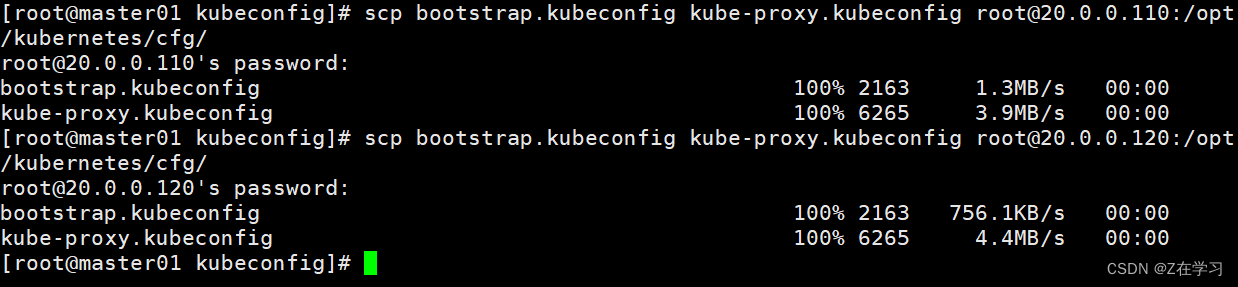
#RBAC授权,使用户 kubelet-bootstrap 能够有权限发起 CSR 请求证书
kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap若执行失败,可先给kubectl绑定默认cluster-admin管理员集群角色,授权集群操作权限
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous

kubelet 采用 TLS Bootstrapping 机制,自动完成到 kube-apiserver 的注册,在 node 节点量较大或者后期自动扩容时非常有用。
Master apiserver 启用 TLS 认证后,node 节点 kubelet 组件想要加入集群,必须使用CA签发的有效证书才能与 apiserver 通信,当 node 节点很多时,
签署证书是一件很繁琐的事情。因此 Kubernetes 引入了 TLS bootstraping 机制来自动颁发客户端证书,
kubelet 会以一个低权限用户自动向 apiserver 申请证书,kubelet 的证书由 apiserver 动态签署。kubelet 首次启动通过加载 bootstrap.kubeconfig 中的用户 Token 和 apiserver CA 证书发起首次 CSR 请求,
这个 Token 被预先内置在 apiserver 节点的 token.csv 中,其身份为 kubelet-bootstrap 用户和 system:kubelet-bootstrap 用户组;
想要首次 CSR 请求能成功(即不会被 apiserver 401 拒绝),则需要先创建一个 ClusterRoleBinding,
将 kubelet-bootstrap 用户和 system:node-bootstrapper 内置 ClusterRole 绑定(通过 kubectl get clusterroles 可查询),使其能够发起 CSR 认证请求。TLS bootstrapping 时的证书实际是由 kube-controller-manager 组件来签署的,也就是说证书有效期是 kube-controller-manager 组件控制的;
kube-controller-manager 组件提供了一个 --experimental-cluster-signing-duration 参数来设置签署的证书有效时间;
默认为 8760h0m0s,将其改为 87600h0m0s,即 10 年后再进行 TLS bootstrapping 签署证书即可。也就是说 kubelet 首次访问 API Server 时,是使用 token 做认证,通过后,Controller Manager 会为 kubelet 生成一个证书,以后的访问都是用证书做认证了。在 node01 节点上操作
#启动 kubelet 服务
cd /opt/
./kubelet.sh 20.0.0.110
ps aux | grep kubelet
在 master01 节点上操作,通过 CSR 请求
#检查到 node01 节点的 kubelet 发起的 CSR 请求,Pending 表示等待集群给该节点签发证书
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-BOIYGMMLKt3jjGVa7CKCL-24mcdeLbU3uUBp8cnYJLk 25s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending

#通过 CSR 请求kubectl certificate approve node-csr-BOIYGMMLKt3jjGVa7CKCL-24mcdeLbU3uUBp8cnYJLk
#Approved,Issued 表示已授权 CSR 请求并签发证书
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-BOIYGMMLKt3jjGVa7CKCL-24mcdeLbU3uUBp8cnYJLk 12m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued

#查看节点,由于网络插件还没有部署,节点会没有准备就绪 NotReady
kubectl get nodeNAME STATUS ROLES AGE VERSION
20.0.0.110 NotReady <none> 5m9s v1.20.11

在 node01 节点上操作
#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done

#启动proxy服务
cd /opt/
./proxy.sh 20.0.0.110
ps aux | grep kube-proxy
部署网络组件
#k8s 组网方案对比:
●flannel方案
需要在每个节点上把发向容器的数据包进行封装后,再用隧道将封装后的数据包发送到运行着目标Pod的node节点上。目标node节点再负责去掉封装,将去除封装的数据包发送到目标Pod上。数据通信性能则大受影响。
●calico方案
Calico不使用隧道或NAT来实现转发,而是把Host当作Internet中的路由器,使用BGP同步路由,并使用iptables来做安全访问策略,完成跨Host转发。
采用直接路由的方式,这种方式性能损耗最低,不需要修改报文数据,但是如果网络比较复杂场景下,路由表会很复杂,对运维同事提出了较高的要求。
#Calico 主要由三个部分组成:
Calico CNI插件:主要负责与kubernetes对接,供kubelet调用使用。
Felix:负责维护宿主机上的路由规则、FIB转发信息库等。
BIRD:负责分发路由规则,类似路由器。
Confd:配置管理组件。#Calico 工作原理:
Calico 是通过路由表来维护每个 pod 的通信。Calico 的 CNI 插件会为每个容器设置一个 veth pair 设备, 然后把另一端接入到宿主机网络空间,由于没有网桥,CNI 插件还需要在宿主机上为每个容器的 veth pair 设备配置一条路由规则, 用于接收传入的 IP 包。
有了这样的 veth pair 设备以后,容器发出的 IP 包就会通过 veth pair 设备到达宿主机,然后宿主机根据路由规则的下一跳地址, 发送给正确的网关,然后到达目标宿主机,再到达目标容器。
这些路由规则都是 Felix 维护配置的,而路由信息则是 Calico BIRD 组件基于 BGP 分发而来。
calico 实际上是将集群里所有的节点都当做边界路由器来处理,他们一起组成了一个全互联的网络,彼此之间通过 BGP 交换路由, 这些节点我们叫做 BGP Peer。
目前比较常用的CNI网络组件是flannel和calico,flannel的功能比较简单,不具备复杂的网络策略配置能力,calico是比较出色的网络管理插件,但具备复杂网络配置能力的同时,往往意味着本身的配置比较复杂,所以相对而言,比较小而简单的集群使用flannel,考虑到日后扩容,未来网络可能需要加入更多设备,配置更多网络策略,则使用calico更好。
部署 flannel
#在 node01 节点上操作
#上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
cd /opt/
docker load -i flannel.tarmkdir /opt/cni/bin
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
#在 master01 节点上操作
#上传 kube-flannel.yml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
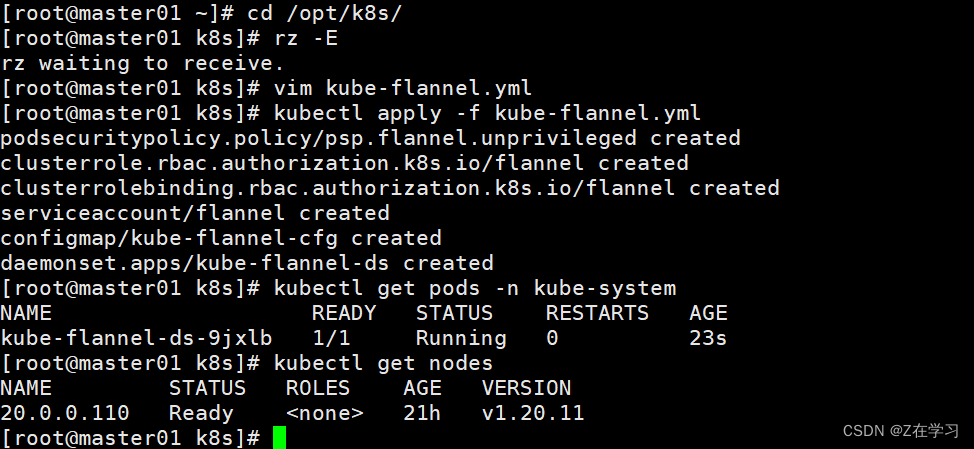
kubectl apply -f kube-flannel.yml kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-9jxlb 1/1 Running 0 23skubectl get nodes
NAME STATUS ROLES AGE VERSION
20.0.0.110 Ready <none> 21h v1.20.11
部署 Calico
在 master01 节点上操作
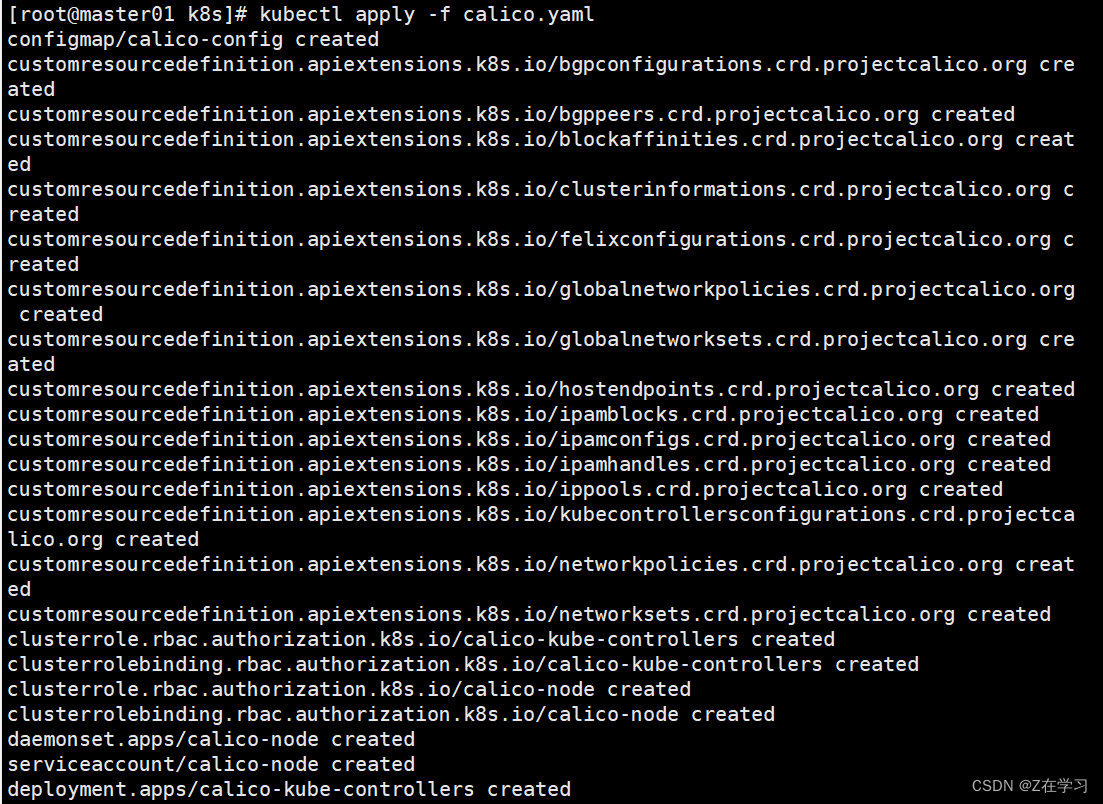
#上传 calico.yaml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
vim calico.yaml
#修改里面定义Pod网络(CALICO_IPV4POOL_CIDR),与前面kube-controller-manager配置文件指定的cluster-cidr网段一样- name: CALICO_IPV4POOL_CIDRvalue: "10.244.0.0/16"kubectl apply -f calico.yamlkubectl get pods -n kube-system
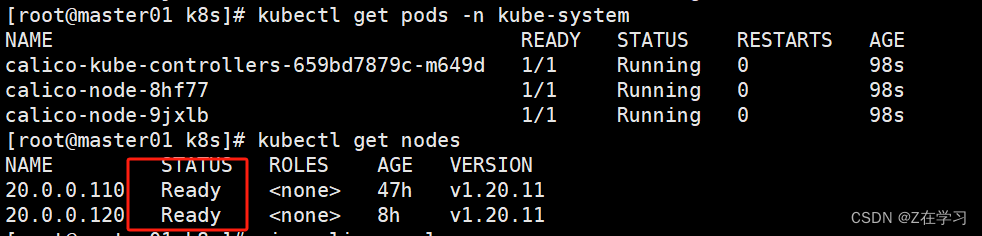
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-659bd7879c-4h8vk 1/1 Running 0 58s
calico-node-nsm6b 1/1 Running 0 58s
calico-node-tdt8v 1/1 Running 0 58s#等 Calico Pod 都 Running,节点也会准备就绪
kubectl get nodes
部署 CoreDNS
CoreDNS:可以为集群中的 service 资源创建一个域名 与 IP 的对应关系解析
在所有 node 节点上操作
#上传 coredns.tar 到 /opt 目录中
cd /opt
docker load -i coredns.tar


在 master01 节点上操作
#上传 coredns.yaml 文件到 /opt/k8s 目录中,部署 CoreDNS
cd /opt/k8s
kubectl apply -f coredns.yamlkubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-6954c77b9b-pbxkv 1/1 Running 0 19s
#DNS 解析测试
kubectl run -it --rm dns-test --image=busybox:1.28.4 sh
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.localName: kubernetes
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
注:
如果出现以下报错
[root@master01 k8s]# kubectl run -it --image=busybox:1.28.4 sh
If you don't see a command prompt, try pressing enter.
Error attaching, falling back to logs: unable to upgrade connection: Forbidden (user=system:anonymous, verb=create, resource=nodes, subresource=proxy)
Error from server (Forbidden): Forbidden (user=system:anonymous, verb=get, resource=nodes, subresource=proxy) ( pods/log sh)需要添加 rbac的权限 直接使用kubectl绑定 clusteradmin 管理员集群角色 授权操作权限[root@master01 k8s]# kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
clusterrolebinding.rbac.authorization.k8s.io/cluster-system-anonymous created


master02 节点部署
//从 master01 节点上拷贝证书文件、各master组件的配置文件和服务管理文件到 master02 节点
scp -r /opt/etcd/ root@20.0.0.100:/opt/
scp -r /opt/kubernetes/ root@20.0.0.100:/opt
scp -r /root/.kube root@20.0.0.100:/root
scp /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service root@20.0.0.100:/usr/lib/systemd/system///修改配置文件kube-apiserver中的IP
vim /opt/kubernetes/cfg/kube-apiserver
KUBE_APISERVER_OPTS="--logtostderr=true \
--v=4 \
--etcd-servers=https://192.168.10.80:2379,https://192.168.10.18:2379,https://192.168.10.19:2379 \
--bind-address=20.0.0.100 \ #修改
--secure-port=6443 \
--advertise-address=20.0.0.100 \ #修改
......//在 master02 节点上启动各服务并设置开机自启
systemctl start kube-apiserver.service
systemctl enable kube-apiserver.service
systemctl start kube-controller-manager.service
systemctl enable kube-controller-manager.service
systemctl start kube-scheduler.service
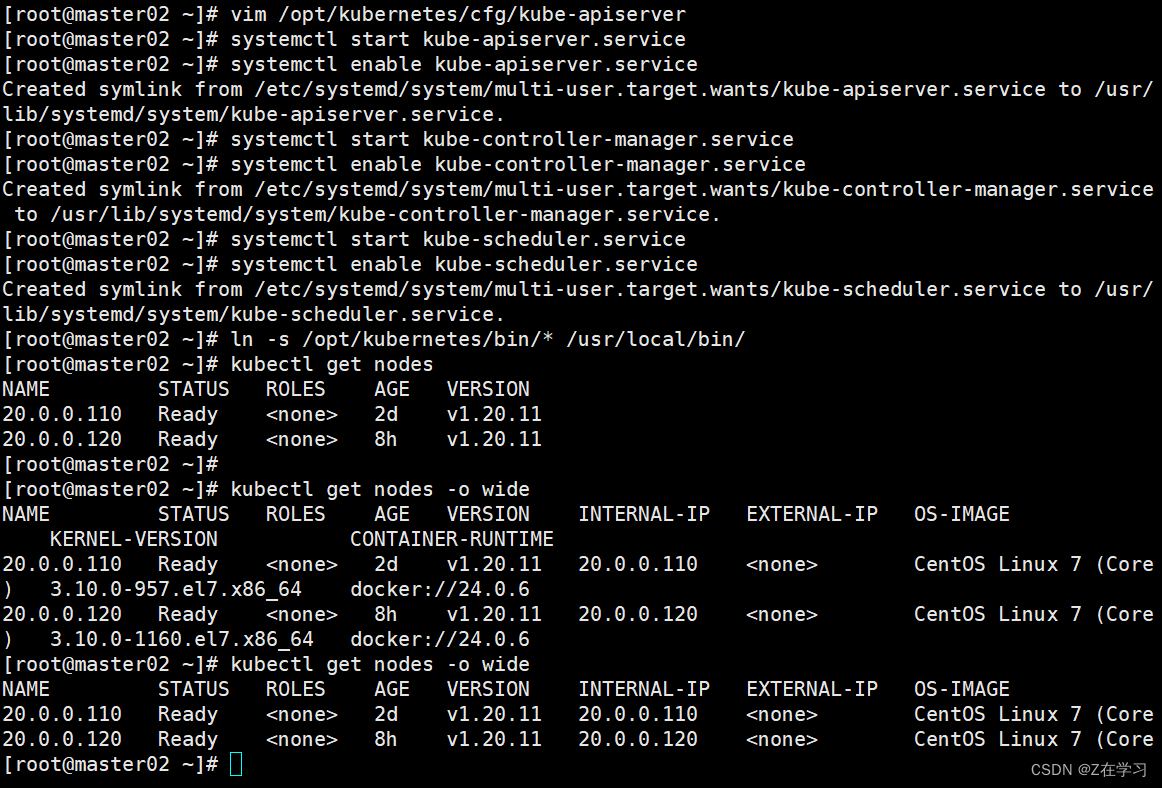
systemctl enable kube-scheduler.service//查看node节点状态
ln -s /opt/kubernetes/bin/* /usr/local/bin/
kubectl get nodes
kubectl get nodes -o wide #-o=wide:输出额外信息;对于Pod,将输出Pod所在的Node名
//此时在master02节点查到的node节点状态仅是从etcd查询到的信息,而此时node节点实际上并未与master02节点建立通信连接,因此需要使用一个VIP把node节点与master节点都关联起来
负载均衡部署
#配置load balancer集群双机热备负载均衡(nginx实现负载均衡,keepalived实现双机热备)
##### 在lb01、lb02节点上操作 #####
#配置nginx的官方在线yum源,配置本地nginx的yum源
cat > /etc/yum.repos.d/nginx.repo << 'EOF'
[nginx]
name=nginx repo
baseurl=http:#nginx.org/packages/centos/7/$basearch/
gpgcheck=0
EOFyum install nginx -y#修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台master的节点ip和6443端口
vim /etc/nginx/nginx.conf
events {worker_connections 1024;
}#添加
stream {log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';access_log /var/log/nginx/k8s-access.log main;upstream k8s-apiserver {server 20.0.0.50:6443;server 20.0.0.100:6443;}server {listen 6443;proxy_pass k8s-apiserver;}
}http {
......#检查配置文件语法
nginx -t #启动nginx服务,查看已监听6443端口
systemctl start nginx
systemctl enable nginx
netstat -natp | grep nginx #部署keepalived服务
yum install keepalived -y#修改keepalived配置文件
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalivedglobal_defs {# 接收邮件地址notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}# 邮件发送地址notification_email_from Alexandre.Cassen@firewall.locsmtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_MASTER #lb01节点的为 NGINX_MASTER,lb02节点的为 NGINX_BACKUP
}#添加一个周期性执行的脚本
vrrp_script check_nginx {script "/etc/nginx/check_nginx.sh" #指定检查nginx存活的脚本路径
}vrrp_instance VI_1 {state MASTER #lb01节点的为 MASTER,lb02节点的为 BACKUPinterface ens33 #指定网卡名称 ens33virtual_router_id 51 #指定vrid,两个节点要一致priority 100 #lb01节点的为 100,lb02节点的为 90advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {20.0.0.200/24 #指定 VIP}track_script {check_nginx #指定vrrp_script配置的脚本}
}#创建nginx状态检查脚本
vim /etc/nginx/check_nginx.sh
#!/bin/bash
#egrep -cv "grep|$$" 用于过滤掉包含grep 或者 $$ 表示的当前Shell进程ID,即脚本运行的当前进程ID号
count=$(ps -ef | grep nginx | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thensystemctl stop keepalived
fichmod +x /etc/nginx/check_nginx.sh#启动keepalived服务(一定要先启动了nginx服务,再启动keepalived服务)
systemctl start keepalived
systemctl enable keepalived
ip a #查看VIP是否生成#修改node节点上的bootstrap.kubeconfig,kubelet.kubeconfig配置文件为VIP
cd /opt/kubernetes/cfg/
vim bootstrap.kubeconfig
server: https:#20.0.0.200:6443vim kubelet.kubeconfig
server: https:#20.0.0.200:6443vim kube-proxy.kubeconfig
server: https:#20.0.0.200:6443#重启kubelet和kube-proxy服务
systemctl restart kubelet.service
systemctl restart kube-proxy.service#在 lb01 上查看 nginx 和 node 、 master 节点的连接状态
netstat -natp | grep nginx
tcp 0 0 0.0.0.0:6443 0.0.0.0:* LISTEN 84739/nginx: master
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 84739/nginx: master
tcp 0 0 20.0.0.31:60382 20.0.0.100:6443 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.200:6443 20.0.0.110:41650 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.200:6443 20.0.0.120:49726 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.31:35234 20.0.0.50:6443 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.200:6443 20.0.0.110:41648 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.200:6443 20.0.0.120:49728 ESTABLISHED 84742/nginx: worker
tcp 0 0 20.0.0.200:6443 20.0.0.110:41646 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.31:32786 20.0.0.100:6443 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.200:6443 20.0.0.110:41656 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.31:60378 20.0.0.100:6443 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.31:32794 20.0.0.100:6443 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.200:6443 20.0.0.120:49724 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.31:35886 20.0.0.50:6443 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.200:6443 20.0.0.120:51372 ESTABLISHED 84742/nginx: worker
tcp 0 0 20.0.0.200:6443 20.0.0.120:49722 ESTABLISHED 84741/nginx: worker
tcp 0 0 20.0.0.200:6443 20.0.0.120:49702 ESTABLISHED 84741/nginx: worker##### 在 master01 节点上操作 #####
#测试创建pod
kubectl run nginx --image=nginx#查看Pod的状态信息
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-dbddb74b8-nf9sk 0/1 ContainerCreating 0 33s #正在创建中kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-dbddb74b8-nf9sk 1/1 Running 0 80s #创建完成,运行中kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
nginx-dbddb74b8-26r9l 1/1 Running 0 10m 172.17.36.2 192.168.80.15 <none>
#READY为1/1,表示这个Pod中有1个容器#在对应网段的node节点上操作,可以直接使用浏览器或者curl命令访问
curl 172.17.36.2#这时在master01节点上查看nginx日志
kubectl logs nginx-dbddb74b8-nf9sk
部署 Dashboard
Dashboard 介绍
仪表板是基于Web的Kubernetes用户界面。您可以使用仪表板将容器化应用程序部署到Kubernetes集群,对容器化应用程序进行故障排除,并管理集群本身及其伴随资源。您可以使用仪表板来概述群集上运行的应用程序,以及创建或修改单个Kubernetes资源(例如deployment,job,daemonset等)。例如,您可以使用部署向导扩展部署,启动滚动更新,重新启动Pod或部署新应用程序。仪表板还提供有关群集中Kubernetes资源状态以及可能发生的任何错误的信息。
#在 master01 节点上操作
#上传 recommended.yaml 文件到 /opt/k8s 目录中
cd /opt/k8s
vim recommended.yaml
#默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部:
kind: Service
apiVersion: v1
metadata:labels:k8s-app: kubernetes-dashboardname: kubernetes-dashboardnamespace: kubernetes-dashboard
spec:ports:- port: 443targetPort: 8443nodePort: 30001 #添加type: NodePort #添加selector:k8s-app: kubernetes-dashboardkubectl apply -f recommended.yaml#创建service account并绑定默认cluster-admin管理员集群角色
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')#使用输出的token登录Dashboard
https://NodeIP:30001