中国移动项目部署文档
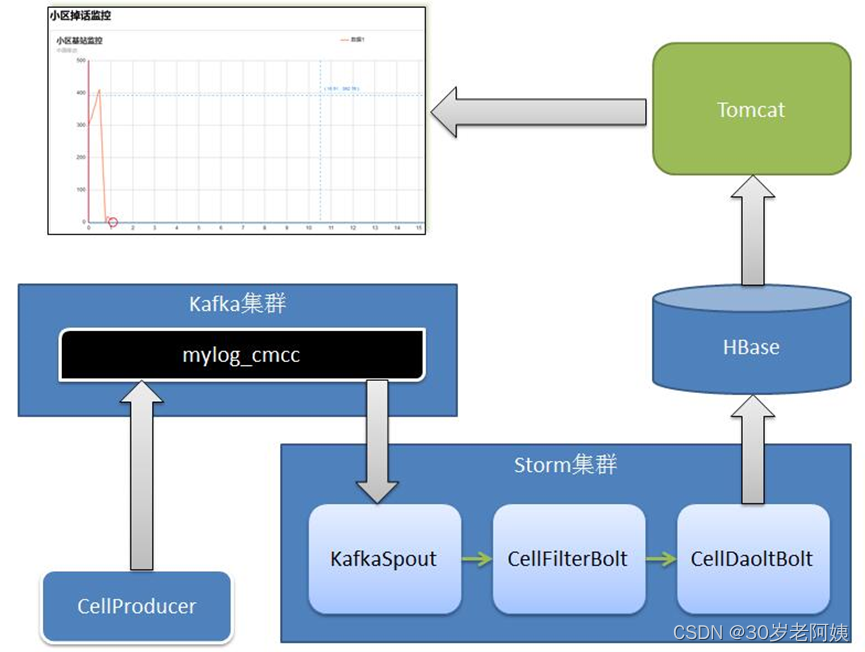
一、项目架构
二、启动集群
1、启动Zookeeper集群
2、启动Hbase(完全分布式需要先启动Hadoop集群)
在conf/hbase-env.sh中设置JAVA_HOME
在conf/hbase-site.xml中,仅需要指定hbase和zookeeper写数据的本地路径。默认情况下会在/tmp下创建新的目录。
<configuration><property><name>hbase.rootdir</name><value>file:///root/hbase</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>/root/zookeeper</value></property>
</configuration>
我们不需要创建任何目录,hbase会创建。如果手动创建了,hbase会做一个迁移,这不是我们想要的。
bin/start-hbase.sh脚本用于启动hbase。启动成功,hbase会在标准输出打印成功启动的信息。使用jps查看进程,会只有一个HMaster进程。这个进程中包含了一个HMaster、一个HRegionServer以及一个zookeeper的daemon。它们在同一个进程中。
1、连接HBase:shell> ./bin/hbase shell
2、在hbase的shell中输入help并回车,获取帮助:hbase(main):001:0> help
3、创建表使用create命令创建表,必须指定表名和列族的名称hbase(main):001:0> create 'test', 'cf'
0 row(s) in 0.4170 seconds=> Hbase::Table - test4、列出表的信息使用list命令列出信息。hbase(main):002:0> list 'test'
TABLE
test
1 row(s) in 0.0180 seconds=> ["test"]5、向table插入数据使用put命令。hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0850 secondshbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0110 secondshbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0100 seconds以上,插入了三个值,每次一个。第一次在row1的位置,cf:a列插入值value1。hbase中的列由列族前缀cf跟一个冒号,再跟一个列标识符后缀比如a。6、一次性扫描表中的所有数据要查询表中的数据,可以使用scan命令。可以在该命令中使用限定条件,下面获取了表中的所有数据:hbase(main):016:0> scan 'test'
ROW COLUMN+CELL row1 column=cf:a, timestamp=1568514191889, value=value1 row2 column=cf:b, timestamp=1568514198429, value=value2
row3 column=cf:c, timestamp=1568514205341, value=value3
3 row(s) in 0.0350 seconds7、查询一行记录使用get命令一次获取一行记录hbase(main):017:0> get 'test', 'row1'
COLUMN CELL cf:a timestamp=1568514191889, value=value1
1 row(s) in 0.0140 seconds8、禁用一张表如果要删除表或更改表的设置,需要先使用disable命令禁用该表,之后也可以使用enable命令重新使用该表。hbase(main):018:0> disable 'test'
0 row(s) in 1.3350 secondshbase(main):019:0> enable 'test'
0 row(s) in 0.2520 seconds再次使用disable命令禁用该表:hbase(main):020:0> disable 'test'
0 row(s) in 1.2580 seconds9、删除表在表已经禁用的情况下,使用drop命令删除表hbase(main):021:0> drop 'test'
0 row(s) in 0.1550 seconds10、退出HBase的shell退出shell断开到集群的连接,可以使用quit命令。但是hbase服务进程仍然在后台运行。hbase(main):022:0> quit
[root@node1 hbase-0.98.12.1-hadoop2]#11、停止hbase服务进程bin/start-hbase.sh开启hbase的所有进程,bin/stop-hbase.sh用于停止所有hbase进程。[root@node1 hbase-0.98.12.1-hadoop2]# bin/stop-hbase.sh
stopping hbase..................
[root@node1 hbase-0.98.12.1-hadoop2]#
12、使用jps查看进程信息,确保hbase的HMaster和HRegionServer进程成功关闭:[root@node1 hbase-0.98.12.1-hadoop2]# jps
2831 Jps
[root@node1 hbase-0.98.12.1-hadoop2]#start-hbase.sh
3、启动Kafka集群bin/kafka-server-start.sh config/server.properties三、项目部署
1、在Hbase中创建如下表:
start-hbase.sh
hbase shell
create 'cell_monitor_table','cf'
- 修改项目配置
A、cmccstorm项目
-
- 修改cmcc.constant.Constants中对应各配置项。
如:HBASE_ZOOKEEPER_LIST、KAFKA_ZOOKEEPER_LIST、BROKER_LIST、ZOOKEEPERS
B、cmccweb项目
- 修改cmcc.hbase.dao.impl.HBaseDAOImp中Hbase的Zookeeper集群配置
- 启动生成测试数据的方法 -- cmccstorm
运行kafka.productor. CellProducer,随机生成模拟数据,并将数据写入到Kafka中。
此时,可查看Kafka中topic列表:
bin/kafka-topics.sh --zookeeper node2:2181,node3:2181,node4:2181 --list
bin/kafka-topics.sh --zookeeper node2:2181,node3:2181,node4:2181 --create --replication-factor 2 --partitions 1 --topic mylog_cmcc
bin/kafka-console-consumer.sh --zookeeper node2:2181,node3:2181,node4:2181 --from-beginning --topic mylog_cmcc
![]()
mylog_cmcc为模拟数据发送至Kafka中的topic
查看数据:
bin/kafka-console-consumer.sh --zookeeper node2:2181,node3:2181,node4:2181 --topic mylog_cmcc
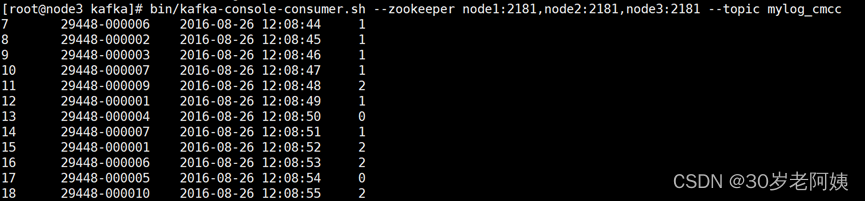
- 启动storm分析-- cmccstorm
(当前项目以本地测试为例)
运行topo.KafkaOneCellMonintorTopology,从Kafka中读取数据,Storm分析之后,结果写入Hbase中存放。
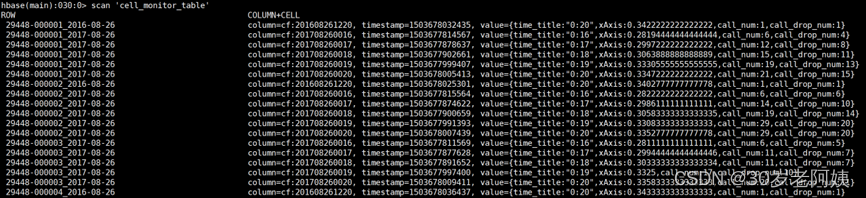
此时,若已经产生“掉话”情况,分析结果在Hbase当中可以查看到:
- 启动web展示项目 -- cmccweb
将cmccweb添加到Tomcat中,启动Tomcat服务,浏览器通过访问以下地址查看:
http://localhost:8080/cmcc/onecellmonitor.jsp