前言:
本文章旨在从例题中加深对整型在数据中的存储的相关知识的理解。
首先我们需要明确整型在内存中都是以补码的形式进行计算
例1:

解析:
首先我们需要明确整型在内存中都是以补码的形式进行计算。
接着将一个整型类型的数据存储在char类型,需要进行截断(直接截断整型的后8位)。
所以存储在a中的补码就是8个1。同理目前在a,b,c中存储的都是8个1.
然后是以%d十进制的形式打印,然而a是一个char类型的变量,所以需要整型提升。
TIP:
char类型不能确定是有符号还是无符号,根据编译器自己。
如何进行整型提升?
有符号位的整型提升就是根据符号位进行提升,而无符号位的直接补0。
综上所述,signed char b,b此时内存中补码存储就是全1,又因为-1的补码就是全1,即b的打印结果就是-1.
而无符号的char整型提升后有8个1,又因为无符号数的原码反码补码相同,所以c的十进制打印结果就是255.
综上,a,b的打印结果都是-1,c的打印结果是255
总结:
因为将整形数据存储在char类型中,所以先进行截断,接着%d打印又需要整型提升!
例2

解析:
-128的原码:
10000000000000000000000010000000//原码
11111111111111111111111101111111//反码
11111111111111111111111110000000//补码
存储在char类型中,进行截断,只留后面8位。
所以此时存储在a中的补码就是
10000000
又因为%u打印,所以需要整型提升,char类型没有unsigned表明,默认都是有符号的,所以此时10000000整型提升就按符号位。
11111111111111111111111110000000//整型提升完毕。
又因为无符号数,所以原码反码补码相同,即二进制位的表达形式就是上述式子,然后再转换为十进制即可。
总结:
最后整型提升打印函数中%d和%u的区别:
因为我们都是对补码进行操作,最后一步如果%u那么原码反码补码相同,不用转换,如果是%d,还需要将补码转换为原码进行打印输出。
例3

解析:
00000000000000000000000010000000//128的原码
01111111111111111111111101111111//128的反码
01111111111111111111111110000000//128的补码
又因为存储在char类型中,所以进行截断。
10000000//阶段之后的a
接下来的步骤跟上一道题一模一样,所以结果也一样。(因为存在内存中的值都是一样的)
例4:

解析:
首先将两个数的补码表示出来,然后利用补码计算。
10000000000000000000000000010100//i的原码
11111111111111111111111111101011//i的反码
11111111111111111111111111101100//i的补码 -------(1)
00000000000000000000000000001010// j的原码反码补码-------(2)
(1)+(2)得到
11111111111111111111111111110110//i+j的补码
11111111111111111111111111110101//i+j的反码
10000000000000000000000000001010//i+j的原码
所以最终屏幕上的输出结果就是-10
总结:
无符号和有符号是可以相加的,他们都是存储在内存中,所以需要补码计算,最后打印函数输出是原码的形式。
例5:

解析:
首先是死循环打印,因为i是一个无符号整型是恒大于0的,当i变成-1时,无符号整型补码形式就是全1,一个非常大的数,接着再-1.
TIP:
如果把i变量的类型改为int,则输出结果就是9~0.因为循环语句的判断条件卡住了。
例6:

解析:
首先我们从数学的角度理解在数组a里面存储的应该是-1~-1000,但是又因为a是一个char类型的数组,而一个char类型的数组只能存的下-128~127,所以在数组真实的存储情况是这样
-1,-2,…………,-128,127,126……1,0,-1进行一个循环。

注意上图的10000000表示-128,是因为10000000是负数的补码,需要再变成原码
又因为strlen计算字符串长度到‘\0’之前出现字符的个数,而\0的ASCII码值就是0,因此当遇到0就结束,所以最终的输出结果就是128+127=255
例7
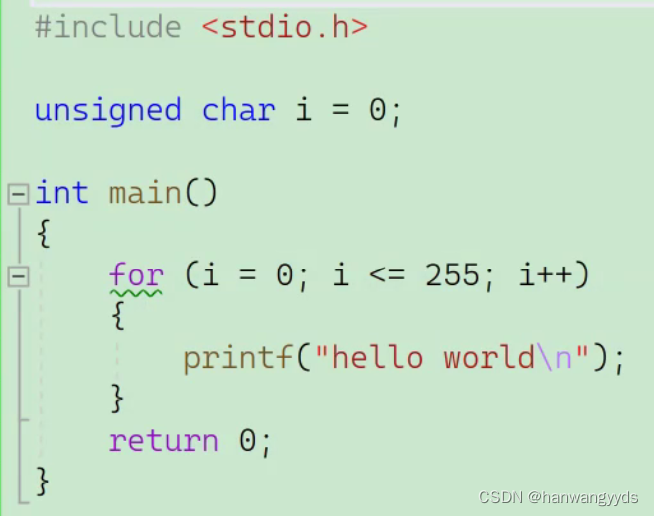
解析:
输出结果是死循环打印hello world
因为unsigned char取值范围是0~255(11111111),而循环判断条件是小于等于255,所以恒成立。