本文是向大家介绍Hologres是一款实时HSAP产品,隶属阿里自研大数据品牌MaxCompute,兼容 PostgreSQL 生态、支持MaxCompute数据直接查询,支持实时写入实时查询,实时离线联邦分析,低成本、高时效、快速构筑企业实时数据仓库(Real-Time Data Warehouse)。
1. HSAP理念与产品
首先介绍下大数据相关实时业务场景,一般有实时大屏、实时BI报表、用户画像和监控预警等。
- 实时大屏业务,一般用作公司领导层做决策的辅助工具,以及对外成果展示。比如双11实时成交额大屏等场景
- 实时BI报表,是运营和产品经理最常用到的业务场景,适用于大部分的报表分析场景
- 用户画像,常用在广告推荐场景中,通过更详细的算法给用户贴上标签,使营销活动更加 有针对性,更有效地投放给目标人群
- 预警监控大屏,比如对网站、APP进行流量监控,在达到一定阈值的时候可以进行告警
针对上述大数据业务场景,业界在很早之前就开始通过数据仓库的建设来满足这些场景的需求。
1.1. 传统数仓建设与痛点
传统上,我们是如何做数据加工以及数据服务的呢?最常见的方式就是下图所示,数据链路也左向右发展,有加工平台负责加工,结果数据导出到服务平台对外提供服务。离线数据仓库数据流程如下:
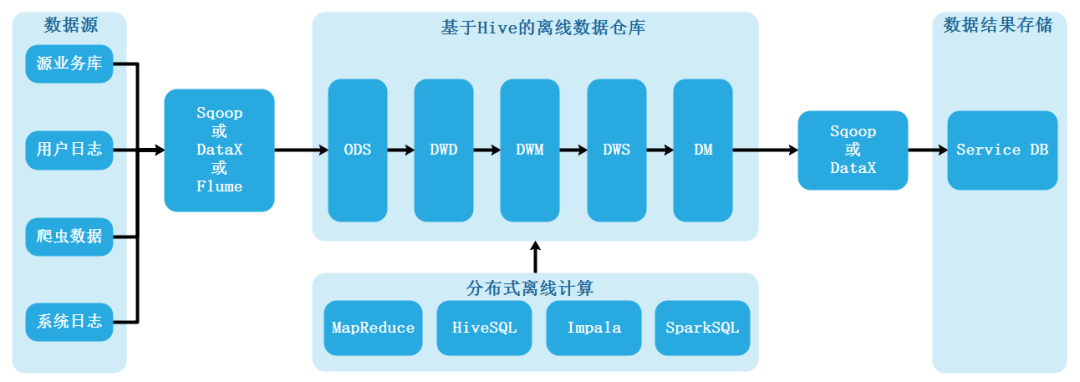
这个架构在最开始应用的时候还是比较顺利的,大部分公司里面 90%的场景下是这个架构。但是随着业务越来越多,越来越复杂,每天都有新的报表,每天都有新的业务场景,就会发现每一个业务调整的时候,都要从源头一步步调整,包括表结构,加工脚本,历史数据重刷等等,最后造成整个数据加工的链路会变得数据冗余、成本高、开发周期长、甚至数据不一致。痛点整理如下:
- ETL逻辑复杂,存储、时间成本过高
- 数据处理链路非常长
- 无法支持实时/近实时的数据,只能处理T+1的数据
为了满足大数据实时化需求,从传统数仓上演进出Lambda架构,其思路,在传统离线数仓的基础上再加上一个处理实时数据的层,然后将离线数仓和实时链路产生的数据在Serving层进行Merge,以此实现对离线产生的数据和实时产生的数据进行查询。
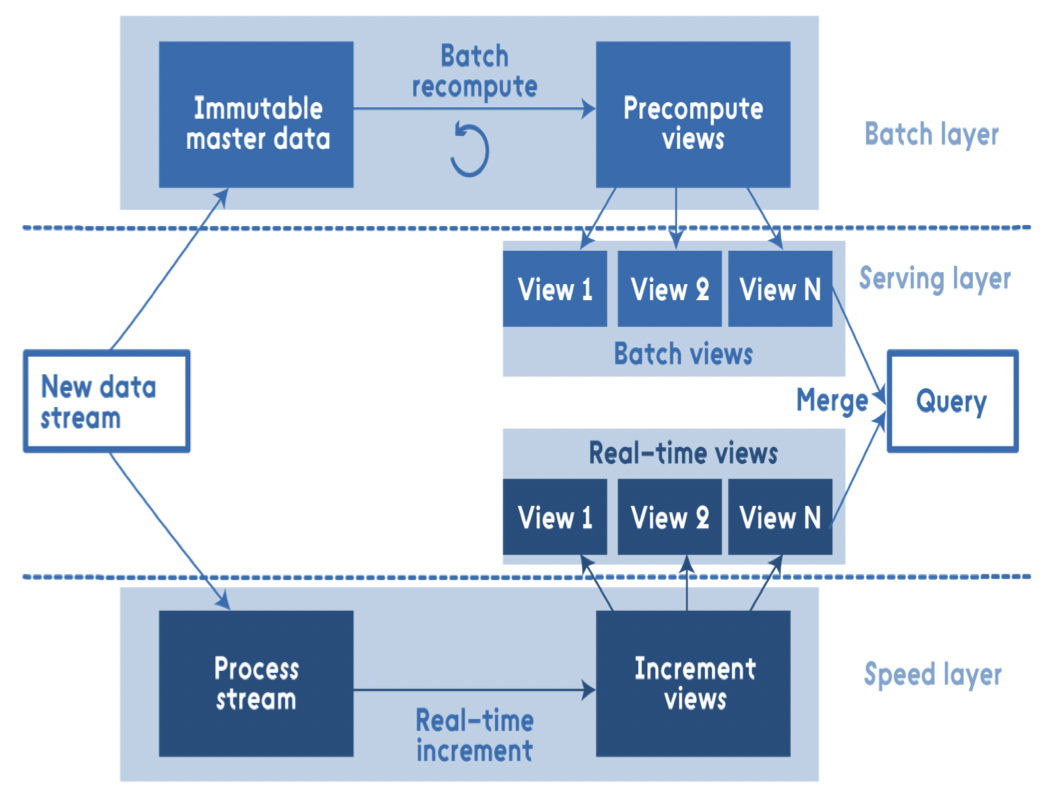
典型架构如下:
Lambda架构的问题:
- 一致性难题:2套语义、2套逻辑、2份数据
- 成本高问题:环环相扣、多套系统、运维复杂
- 开发周期长:错误难以诊断和修订、补数周期长
- 业务不敏捷:无法自助实时分析、分析到服务转化周期长
总结:传统大数据开发链路,数据冗余、成本高、开发周期长。
1.2. HSAP与Hologres
参考:《基于Hologres和Flink的实时数据分析方案》
1.2.1. 阿里的HSAP:服务分析一体化方案
基于上述背景,阿里提出了HSAP(Hybrid Serving and Analytical Processing)理念,目标做到服务分析一体化,它既能支持很高QPS场景的查询写入,又能将复杂的分析场景在一套体系里面完成。
1、统一存储:同时存储实时数据和离线数据
2、统一接口:在统一个接口下(比如SQL),支持高QPS的查询、支持复杂的分析以及联邦查询和分析
3、统一数据服务:系统能够直接对接前端应用,例如报表和在线服务等,不需要再额外的导入导出就能即席分析
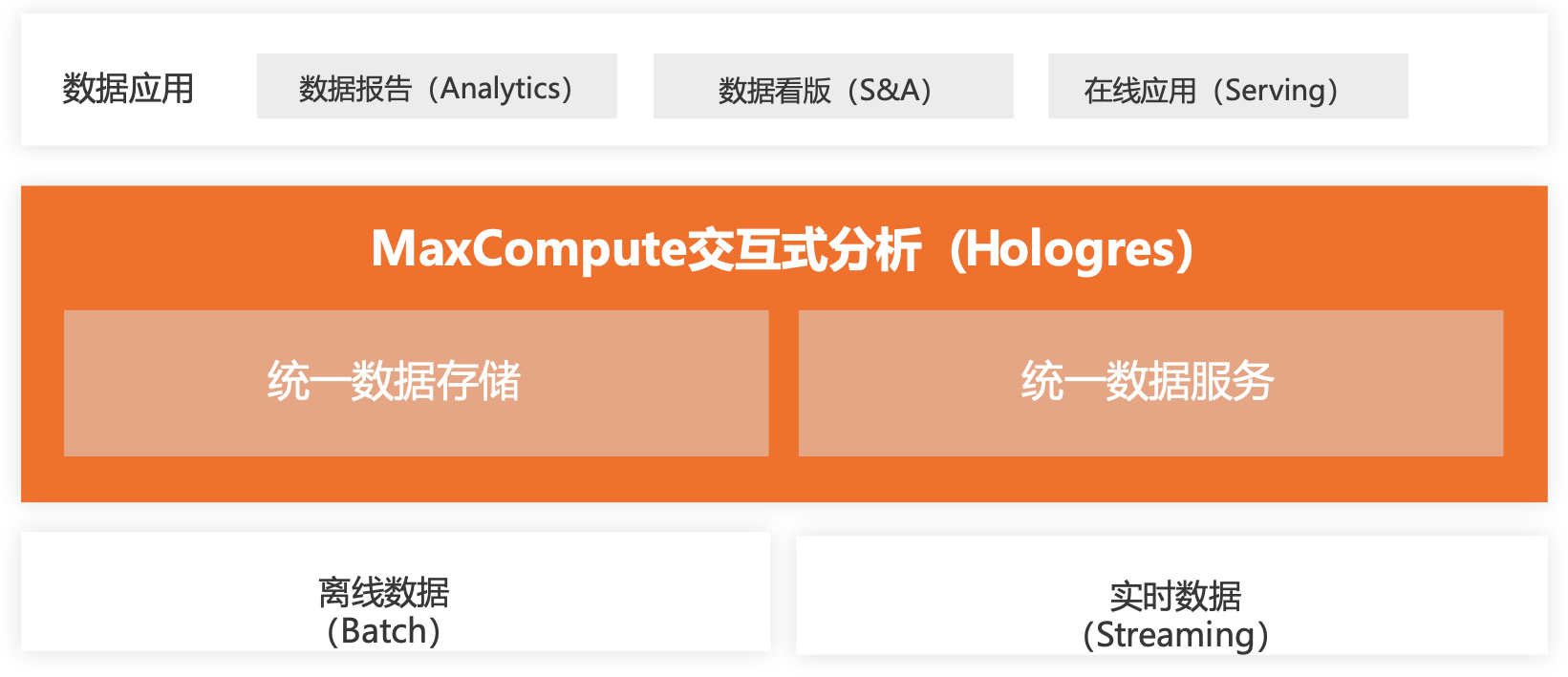
1.2.2. 基于HSAP的实现:Hologres
基于HSAP的设计理念,诞生了Hologres。
Hologres:Better OLAP+ Better Serving +Cost Reduced
Hologres是一款实时HSAP产品,隶属阿里自研大数据品牌MaxCompute,兼容 PostgreSQL 生态、支持MaxCompute数据直接查询,支持实时写入实时查询,实时离线联邦分析,低成本、高时效、快速构筑企业实时数据仓库(Real-Time Data Warehouse)。具备如下优势:
| 说明 | |
| 分析服务一体化 |
|
| 以实时为中心设计 |
|
| 计算存储分离 |
|
| 丰富生态 |
|
1.2.3. 基于HSAP的架构诉求
根据对传统数仓的痛点,阿里对精细化运营平台提出了如下诉求:架构简化、成本优化、数据统一、学习门槛低、适应业务敏捷、自助式分析趋势,如下:
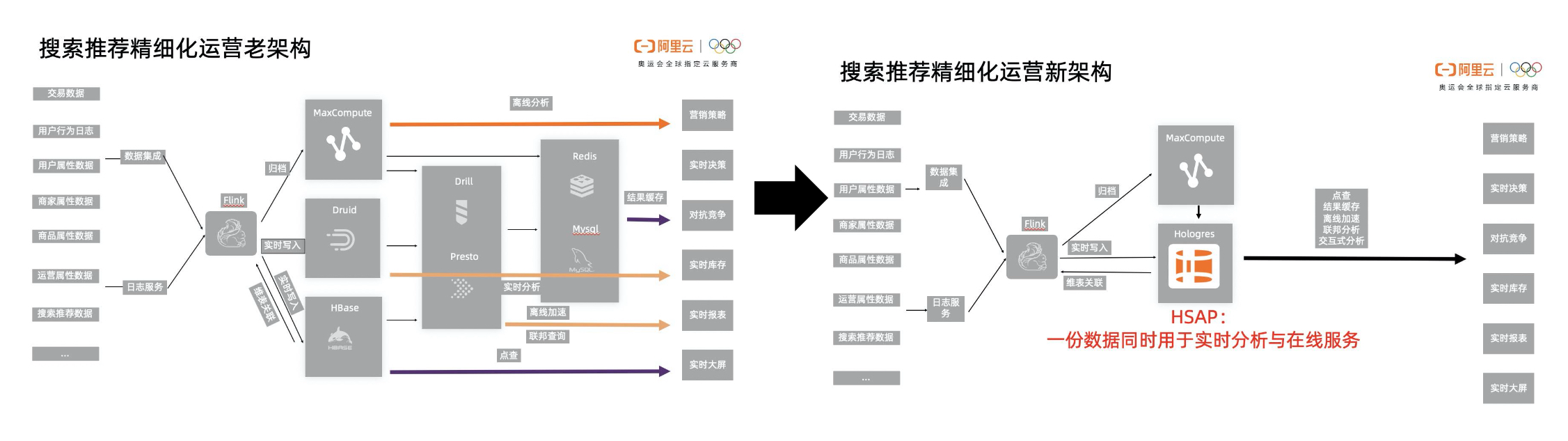
即将原有复杂的架构简化为以HSAP核心思想的数仓架构。
1.3. Hologres功能特性

1.4. Hologres 生态介绍
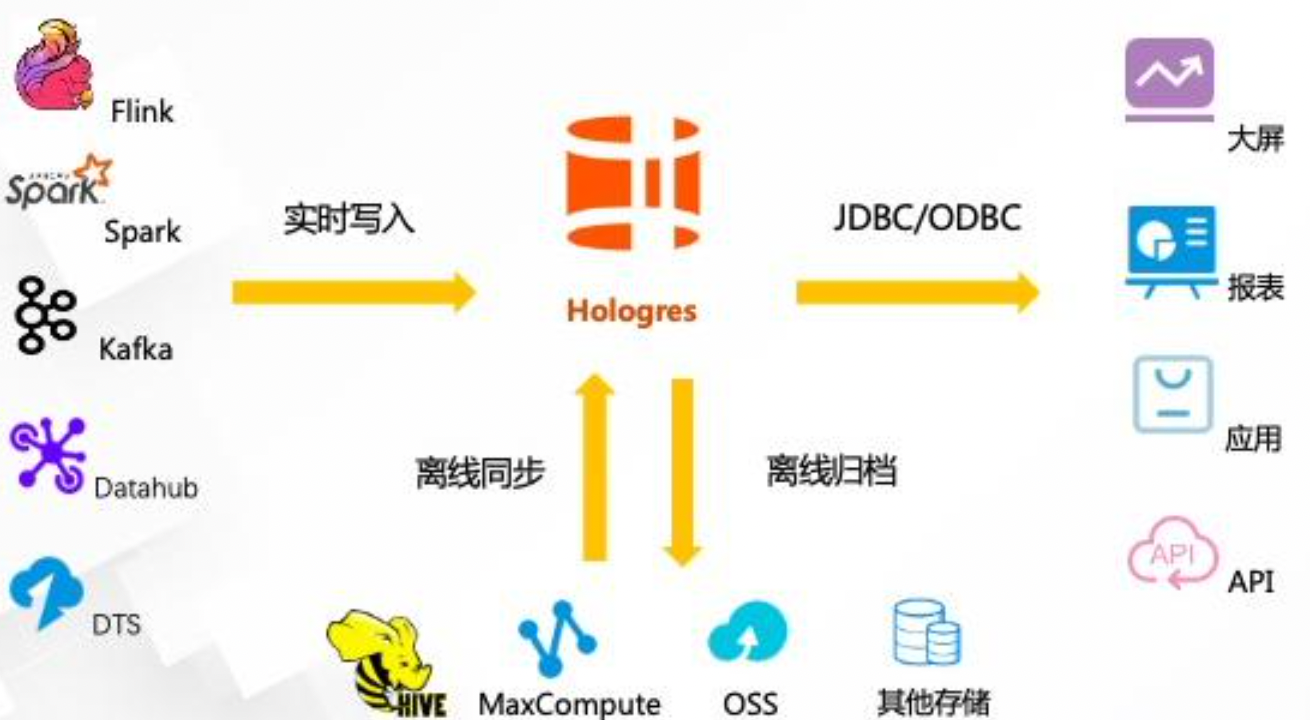
到目前为止,相信大家已经了解到 Hologres 是一款兼容 PostgreSQL 协议的实时交互式 分析产品。在生态的兼容性上,Hologres 有着非常庞大的生态家族。
1.5. 基于Holo应用场景
Hologres兼容PostgreSQL生态,是新一代的阿里云实时数仓产品,与大数据生态无缝连接,支持实时与离线数据,对接第三方BI工具,实现可视化分析业务。

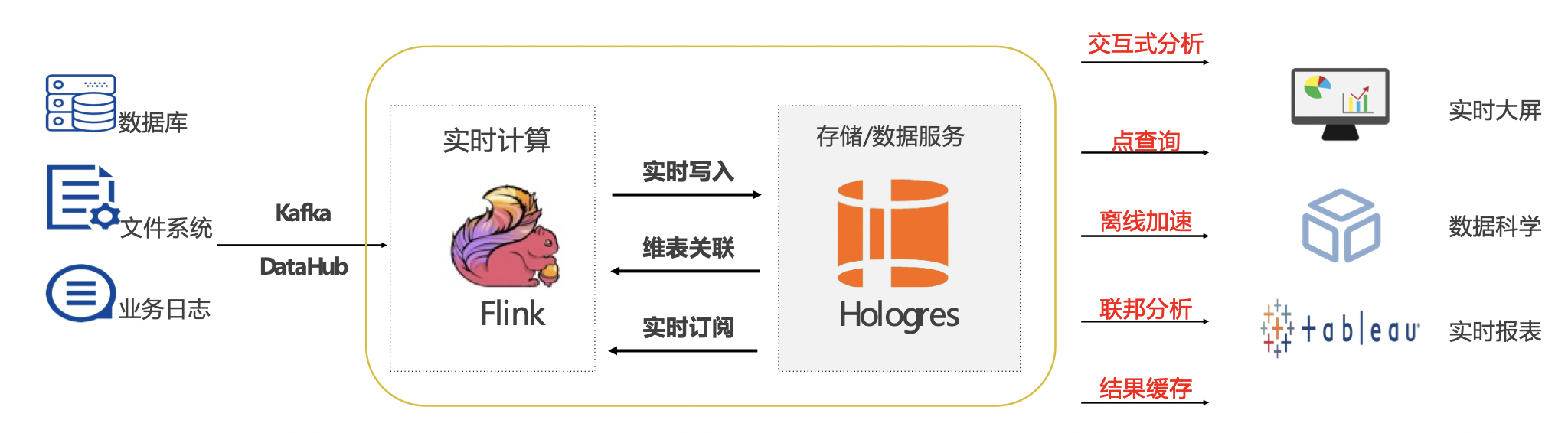
1.5.1. 解决方案:Flink+ Hologres实时数仓
Flink流批一体计算,Hologres实时离线统一存储、分析服务统一数据服务
1.5.2. 解决方案:实时、离线、分析、服务一体化实时数仓
MaxCompute+Hologres+Flink,实时离线联合分析,冷热温三大维度数据全洞察

1.5.3. 解决方案:MaxCompute秒级交互式分析
MaxCompute+Hologres,外表:成本优化、吞吐量大;内表:索引优化、低延迟查询

1.5.4. 个性化推荐:PAl+Hologres向量检索、API as Service
实时推荐依赖特征查询、实时指标计算、向量检索召回,提高广告留存率,Flink+PAl+Hologres with Proxima

2. Hologres的架构
Hologres架构简单,是存储计算分离的架构,数据全部存在一个分布式文件系统里面,在阿里内部指的是盘古分布式文件系统;服务节点叫做 Backend,也叫Worker Node,真正去接收数据,存储和查询,并且能够支持数据的计算;Frontend 接收路由分发过来的SQL,然后生成真正的物理执行计划,发布到 Backend 做分布式的执行;在接入端由LBS 来做相应的负载均衡任务。
下图中黄色部分均部署在容器中,整个分布式系统可以做到高度容错。同时,因为兼容 PostgreSQL 生态,所以一些开源或者商业化的 BI 工具可以直接跟Hologres 进行对接。
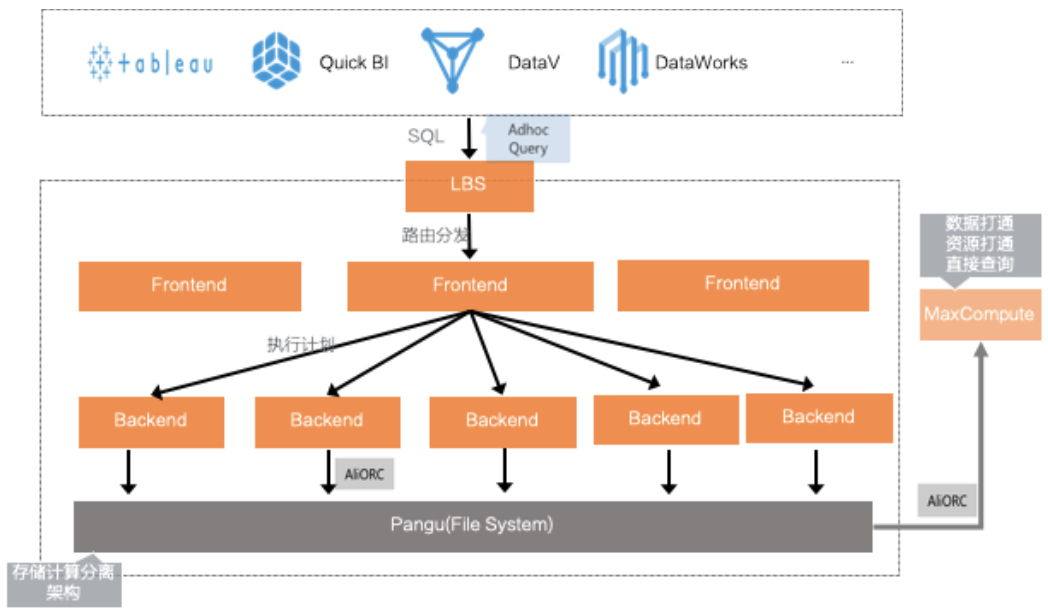
详细组件图如下:

组件介绍:
| 组件 | 用途 | 说明 | |
| 计算层 | 接入节点(Frontend,FE) | 用于SQL的认证、解析、优化 | 兼容Postgres 11(语法、连接工具、BI) |
| 计算HoloWorker | 分为执行引擎、存储引擎、调度等组件,主要负责用户任务的计算、调度。 | Hologres揭秘:深度解析高效率分布式查询引擎 | |
| Meta Service | 主要用于管理元数据Meta信息 | ||
| Holo Master | 负责每个组件的可用性,故障时快速重新拉起组件 | 技术揭秘:从双11看实时数仓Hologres高可用设计与实践 | |
| 存储层 | Pangu File System | 数据存储 | 1、与MaxCompute在存储层打通,可快速访问 2、支持直接访问OSS、DLF数据 |
3. Hologres架构原理
3.1. (一)存储计算分离
在传统的分布式系统中,常用的存储计算架构有如下三种:
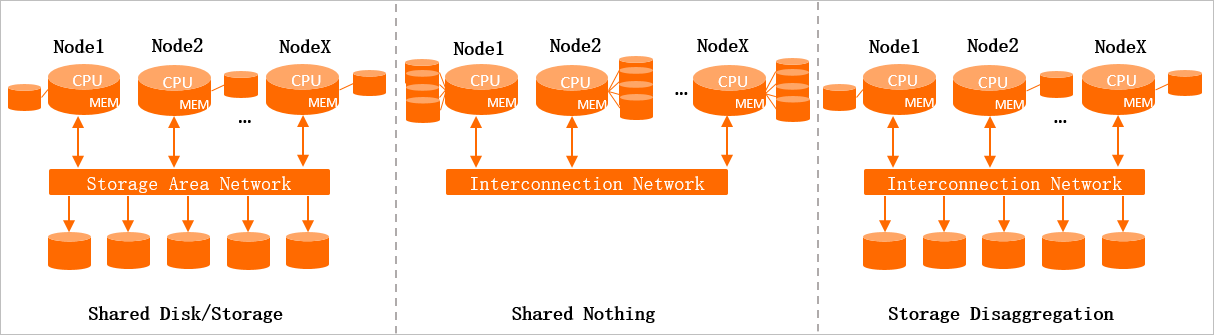
- Shared Disk/Storage (共享存储):存储集群上挂载了很多盘,每个计算节点都可以访问这些盘;
-
- 计算节点需要引入分布式协调机制保证数据同步和一致性
- Shared Nothing :每个计算节点自己挂载存储,节点之间可以通信,存储不共享
-
- Failover:节点Failover需要等待数据加载完成之后才能提供服务;
- 扩容:需要数据Rebalance过程
- Storage Disaggregation:存储集群作为一个大磁盘,每个计算节点都可以访问,共享存储集群,且每个计算节点都有一定的缓存空间,可以对缓存数据进行访问
-
- 一致性问题处理简单:计算层只需要保证同一时刻有一个计算节点写入同一分片的数据。
- 扩展更灵活:计算和存储可以分开扩展,计算不够扩计算节点,存储不够扩存储节点。不需要Rebalance
- 计算节点故障恢复快:计算节点发生Failover,可快速从共享存储异步拉取。
Hologres采用的是第三种存储计算分离架构,Hologres的存储使用的是阿里自研的Pangu分布式文件系统(类似HDFS)。
3.2. (二)流批统一的存储
Hologres 定位是能够做离线数据和实时数据的存储。
- 典型的 Lambda 架构:是将实时数据通过实时数据的链路写入到实时数据存储中,离线数据通过离线数据的链路写入到离线存储中,然后将不同的 Query 放到不同的存储中,再做一个 Merge。
- Hologres:数据收集之后可以走不同的处理链路,但是处理完成之后的结果都可以写入Hologres 中

优点:Hologres解决了数据的一致性问题,也不需要去区分离线表和实时表,降低了复杂度,也大大降低了使用者的学习成本。
3.3. (三)存储引擎
每个分片(Table Group Shard, 简称 shard)构成了一个存储管理和恢复的单元 (Recovery Unit)。上图显示了一个分片的基本架构。
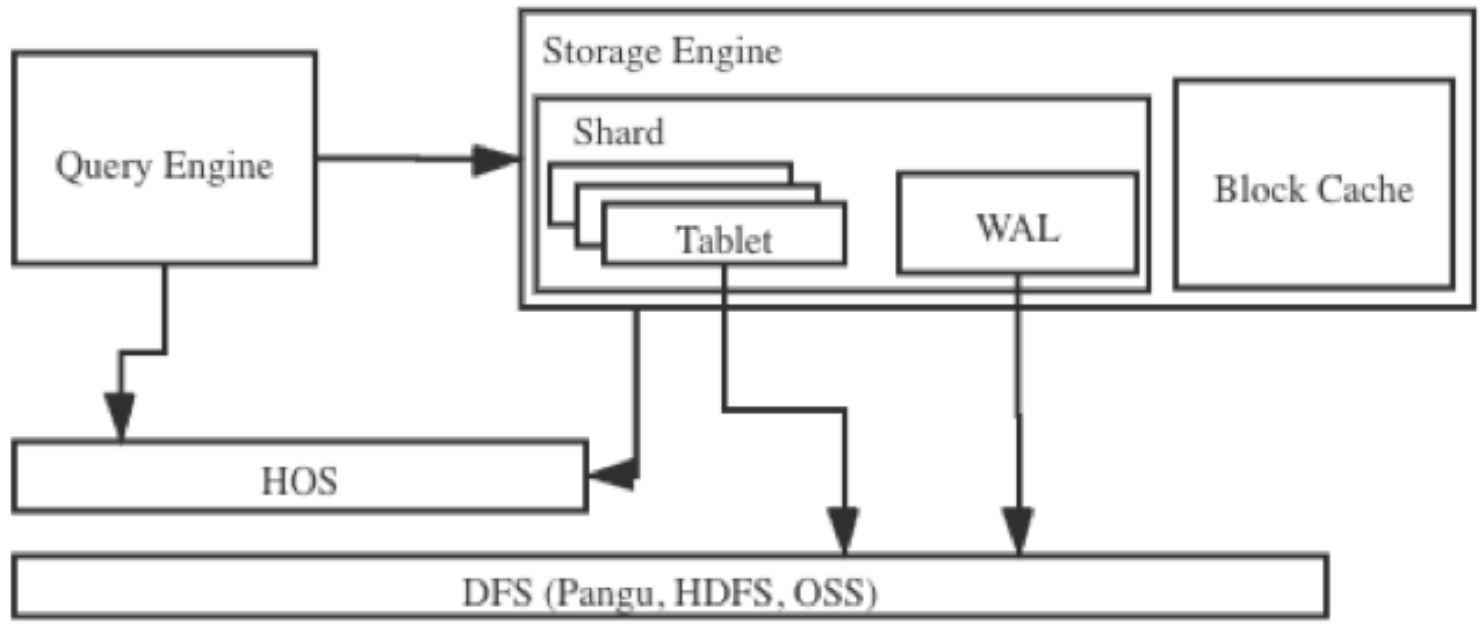
- 一个分片由多个tablet组成,这些 tablet会共享一个日志(Write-Ahead Log,WAL)。
- 存储引擎用了Log-Structured Merge (LSM)的技术,所有的新数据都是以append-only的形式插入的。数据先写到 tablet所在的内存表 (MemTable),积累到一定规模后写入到文件中。当一个数据文件关闭后,里面的内容就不会变了。新的数据以及后续的更新都会写到新的文件。与传统数据库的 B+-tree数据结构相比,LSM减少了随机IO,大幅的提高了写的性能。
- 当写操作不断进来,每个tablet里会积累出很多文件。当一个tablet里小文件积累到一定数量时,存储引擎会在后台把小文件合并起来 (compaction),这样系统就不需要同时打 开很多文件,能减少使用系统资源,更重要的是合并后, 文件减少了,提高了读的性能。
- 在DML的功能上,存储引擎提供了单条或者批量的创建,查询,更新,和删除(CRUD操 作)访问方法的接口,查询引擎可以通过这些接口访问存储的数据。
3.3.1. 存储引擎组件介绍
下面是存储引擎几个重要的的组件:
1、WAL和WAL Manager
WAL Manager是来管理日志文件的。存储引擎用预写式日志(WAL) 来保证数据的原子性 和持久性。
- 当CUD操作发生时,存储引擎先写WAL,再写到对应tablet的MemTable中等到MemTable积累到一定的规模或者到了一定的时间,就会把这个MemTable切换为不可更改的flushing MemTable, 并新开一个 MemTable接收新的写入请求。而这个不可更改的 flushing MemTable就可以刷磁盘,变成不可更改的文件; 当不可更改的文件生成后,数据就可以算持久化。
- 当系统发生错误崩溃后,系统重启时会去WAL读日志,恢复还没有持久化的数据。
- 只有当一个日志文件对应的数据都持久化后,WAL Manager才会把这个日志文件 删除。
2、文件存储
每个tablet会把数据存在一组文件中,这些文件是存在DFS里 (阿里巴巴盘古或者 Apache HDFS )。
- 行存文件的存储方式是Sorted String Table(SST) 格式。
- 列存文件支持两种存储格式:
-
- 一种是类似PAX的自研格式
- 另外一种是改进版的Apache ORC格式 (在 AliORC的基础上针对Hologres的场景做了很多优化)。
这两种列存格式都针对文件扫描的场景做了优化。
3、Block Cache (Read Cache)
为了避免每次读数据都用IO到文件中取,存储引擎通过BlockCache把常用和最近用的数据放在内存中,减少不必要的IO,加快读的性能。
- 在同一个节点内,所有的shard共享一个 Block Cache。
- Block Cache有两种淘汰策略:
-
- LRU (Least recently used,最近最少使 用)
- LFU (Least Frequently Used, 最近不常用)。
顾名思义,LRU算法是首先淘汰最 长时间未被使用的block,而LFU是先淘汰一定时间内被访问次数最少的block。
3.3.2. 存储格式--行、列
第一节提到 Hologres 既能支持分析,又能支持服务。这是因为 Hologres 底层会有两种不同的存储模式:行存和列存,这也就意味着我们既能支持查询的量大,又能支持查的快。
下图是 Hologres 行存和列存两种模式下的对比:

Hologres 底层支持行存储和列存储两种文件格式,新版本也支持了行列共存格式,对于两者的处理也有略微不同,具体如下图所示。

数据写入过程:
- 数据写入的时候先写 WAL(Write Ahead Log),WAL是存储在分布式文件系统中的,保证整个服务的数据不会丢失,因为即便服务器挂掉也可以从分布式系统中恢复。
- WAL 写完之后再写 MemTable,就是内存表,这样子才认为是数据写入成功。
- MemTable 有一定的大小,写满了之后会将其中的数据逐渐 flush 到文件中,文件是存储在分布式系统中的。
而对于行存储和列存储的区别就在Flash 到文件的这个过程中,这个过程会将行存表 flush 成行存储的文件,列存表会 Flash 成列存文件。在 Flash 的过程中会产生很多小文件,后台会将这些小文件合并成一个大文件(Compaction)。
3.3.3. 读写原理
Hologres支持两种类型的写入:单分片写入和分布式批量写入。
两种类型的写入都是原子的(Atomic Write),即写入或回滚。单分片写入一次更新一个shard,但是需要支持极高的写入频率。另一方面,分布式批写用于将大量数据作为单个事务写到多个shard中的场景, 并且通常以低得多的频率执行。

单分片写入 :
如上图所示,WAL管理器在接收到单分片写请求后,
(1)为写请求分配一条Log Sequence Number (LSN),这个LSN是由时间戳和递增的序号组成,并且
(2)创建一条新的日志,并在文件系统中的持久化这条日志。这条日志包含了恢复写操作所需的信息。在完全保留这条日志后,才向tablet提交写入。之后,
(3)我们会在相应tablet的内存表 (MemTable) 中执行这个写操作,并使其对新的读请求可见。值得注意的是,不同tablet上 的更新可以并行化。当一个MemTable满了以后,
(4)将其刷新到文件系统中,并初始化一 个新的MemTable。
(5)最后,将多个分片文件在后台异步合并(compaction)。在合并或MemTable刷新结束时,管理tablet的元数据文件将相应更新。
分布式批量写入
接收到写入请求的前台节点会将写请求分发到所有相关的分片。这些分片通过两阶段提 交机制(Two Phase Commit) 来保证分布式批量写入的写入原子性。
多版本读
Hologres支持在tablet中多版本读取数据。读请求的一致性是read-your-writes,即客户端始终能看到自己最新提交的写操作。每个读取请求都包含一个读取时间戳,用于构造读的snapshot LSN。如果有一行数据的LSN大于snapshot LSN的记录, 这行数据就会被过滤掉, 因为它是在读的snapshot产生后才被插入到这个tablet的。
3.3.4. 存储引擎技术亮点总结
1. 存储计算分离
存储引擎采用存储计算分离的架构,所有的数据文件存在一个分布式文件系统(DFS, 例如阿里巴巴盘古或者Apache HDFS)的里面。当查询负载变大需要更多的计算资源的时 候可以单独扩展计算资源; 当数据量快速增长的时候可以快速单独扩展存储资源。计算节点 和存储节点可以独立扩展的架构保证了不需要等待数据的拷贝或者移动就能快速扩展资源; 而且,可以利用DFS存多副本的机制保证数据的高可用性。 这种架构不但极大地简化了运 维,而且为系统的稳定性提供了很大的保障。
2. 异步执行流程
存储引擎采用了基于事件触发, 非阻塞的纯异步执行架构, 这样能够充分发挥现代CPU多 core的处理能力,提高了吞吐量, 支持高并发的写入和查询。这种架构得益于HOS (HoloOS) 框架,HOS在提供高效的异步执行和并发能力的同时,还能自动地做CPU的负载 均衡提升系统的利用率。
3. 统一的存储
在HSAP场景下,有两类查询模式,一类是简单的点查询(数据服务Serving类场景), 另一类是扫描大量数据的复杂查询(分析Analytical类场景)。 当然,也有很多查询是介于两者之间的。这两种查询模式对数据存储提出了不同的要求。行存能够比较高效地支持点查询,而列存在支持大量扫描的查询上有明显的优势。
为了能够支持各种查询模式,统一的实时存储是非常重要的。存储引擎支持行存和列存 的存储格式。根据用户的需求,一个tablet可以是行存的存储格式 (适用于Serving的场景); 也可以是列存的存储格式(适用于Analytical的场景)。 比如,在一个典型HSAP的 场景,很多用户会把数据存在列存的存储格式下,便于大规模扫描做分析;与此同时,数据的索引存在行存的存储格式下,便于点查。并通过定义primary key constraint (我们是用 行存来实现的)用来防止数据重复。不管底层用的是行存还是列存,读写的接口是一样的, 用户没有感知,只在建表的时候指定即可。
4. 读写隔离
存储引擎采用了snapshot read的语意,读数据时采用读开始时的数据状态,不需要数据锁,读操作不会被写操作block住; 当有新的写操作进来的时候,因为写操作是appendonly,所有写操作也不会被读操作block住。这样可以很好的支持HSAP的高并发混合工作负 载场景。
5. 丰富的索引
存储引擎提供了多种索引类型,用于提升查询的效率。一个表可以支持clustered index 和 non-clustered index这两类索引。一个表只能有一个clustered index, 它包含表里所有的列。一个表可以有多个non-clustered indices。在non-clustered indexes里,除了排序用的non-clustered index key外,还有用来找到全行数据的Row Identifier ( RID)。 如果 clustered index存在, 而且是独特的,clustered index key就是RID; 否则存储引擎会产生一个独特的RID。 为了提高查询的效率,在non-clustered index中还可以有其他的列, 这样在某些查询时,扫一个索引就可以拿到所有的列的值了 (covering index)。
在数据文件内部,存储引擎支持了字典和位图索引。字典可以用来提高处理字符串的效率和提高数据的压缩比,位图索引可以帮助高效地过滤掉不需要的记录。
3.4. (四)执行引擎
Hologres的执行引擎(主要以HQE为主)是自研的执行引擎,具备分布式执行、全异步执行、向量化和列处理、自适应增量处理等优势。
Query执行过程
当客户端发起一个SQL后,Frontend(FE)节点对SQL进行解析和认证,并分发至执行引擎(Query Engine)的不同执行模块。

1、如果是点查/点写的场景,会跳过优化器(Query Optimizer,QO),直接分发至后端获取数据,减少数据传送链路,从而实现更优的性能。整个执行链路也叫Fixed Plan,点查(与HBase的KV查询)、点写场景会直接走Fixed Plan。
2、如果是OLAP查询和写入场景:首先会由优化器(Query Optimizer,QO)对SQL进行解析,生成执行计划,在执行计划中会预估出算子执行Cost、统计信息、空间裁剪等。QO会通过生成的执行计划,决定使用HQE、PQE、SQE或者Hive QE对算子进行真正的计算。
- HQE(Hologres Query Engine):Hologres自研执行引擎,采用可扩展的MPP架构全并行计算,向量化算子发挥CPU极致算力,从而实现极致的查询性能。
- PQE(Postgres Query Engine):用于兼容Postgres提供扩展能力,支持PG生态的各种扩展组件
- SQE(Seahawks Query Engine):无缝对接MaxCompute(ODPS)的执行引擎,--> Hologres揭秘:高性能原生加速MaxCompute核心原理
3、执行引擎决定正确的执行计划,然后会通过存储引擎(Storage Engine,SE)进行数据获取,最后对每个Shard上的数据进行合并,返回至客户端。
3.5. (五)数据模型
1、分片与表组
Hologres存储引擎的基本抽象是分布式的表,为了让系统可扩展,我们需要把表切分为分片(shard)。
为了更高效地支持Join以及多表更新等场景,用户可能需要把几个相关的表存放在一起,为此Hologres引入了表组(Table Group)的概念。
分片策略完全一样的一组表就构成了一个表组,同一个表组的所有表有同样数量的分片。用户可以通过 “shard_count”来指定表的分片数,通过“distribution_key”来指定分片列。目前我们只支持Hash的分片方式。
2、表的数据存储格式
表的数据存储格式分为两类,一类是行存表,一类是列存表,格式可以通过 “orientation”来指定。
3、记录存储顺序
每张表里的记录都有一定的存储顺序,用户可以通过“clustering_key”来指定。如果没有指定排序列,存储引擎会按照插入的顺序自动排序。选择合适的排序列能够大大优化一些查询的性能。
4、索引
表还可以支持多种索引,如字典索引和位图索引。通过 “dictionary_encoding_columns”和“bitmap_columns”来指定需要索引的列。
4. 计算组实例架构
在Hologres V2.0版本推出了全新的弹性高可用实例形态,将计算资源分解为不同的计算组(Virtual Warehouse),更好的服务于高可用部署。具备优点如下:
- 计算组独立弹性可扩展(弹性分配、按需创建)
- 计算组之间共享数据、元数据
- 使用一个Endpoint,无需切换Endpoint即可实现流量切换。
- 计算组实例可同时完美支撑读写分离、资源隔离、业务隔离等诸多场景,对用户提供资源隔离、弹性等核心能力
使用限制:
- 计算组实例仍处于公测(Beta)状态,开启计算组模式需要后台配置,且仅Hologres V2.0.4及以上版本支持开启并使用计算组模式
- 一个计算组实例最多创建10个计算组,单个计算组资源最小32CU,最大512CU。
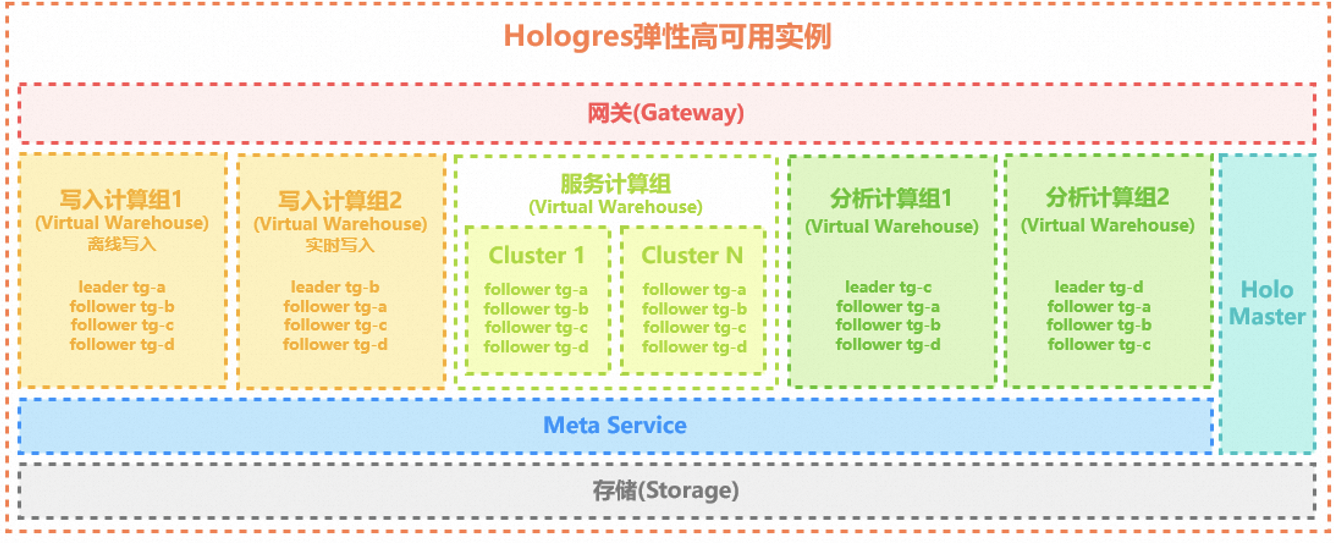
4.1. 计算组实例核心组件
计算组实例的核心组件主要有分为三个层面:
- 数据存储:Hologres数据存储是构建在Alibaba Pangu存储服务上,提供高性能、高可靠、高可用、低成本、弹性存储空间、强大稳定安全等核心服务。
- 计算组(Virtual Warehouse):计算组是独立弹性可扩展的计算资源,负责执行用户的查询请求。
- 云服务组件:云服务组件包括网关、Meta Service、Holo Master等,主要有元数据管理、安全认证管理、统一接入管理以及节点管理等能力。其中网关(Gateway)主要用于转发请求,负责将不同的查询负载转发到各个计算组,用户的查询、写入等相关流量都会经过Gateway。
举例:一个Hologres弹性高可用实例如下:
4.2. 单实例多计算组实现读写分离
通过如下架构可以做到:
1、读写分离:使用init_warehouse写入计算组用于写入数据;使用read_warehouse_1查询计算组用于服务查询
2、计算组流量切换:若发现计算组read_warehouse_1有故障,可以将ram_test的流量切换到init_warehouse计算组

5. Hologres的高可用架构
Hologres提供了2种高可用方式,即使在单实例的情况下,也能保障服务可靠:
- 单实例自动恢复的高可用
- 共享存储的多实例高可用方案
5.1. 单实例自动恢复的高可用方案
Hologres计算节点均为容器调度(即下图中的Worker Node),资源管理器(Resource Manager)负责周期性健康检查。
当出现1分钟容器响应超时(可能是内存溢出、硬件故障、软件Bug等原因导致),Resource Manager会自动拉起新的计算节点,并迁移Shard职责到新的节点上(例如Worker Node3响应超时,Resource Manager拉起Worker Node4取代Worker Node3),实现系统状态的快速恢复。

该方案为当前每个实例内部默认启用,当系统发生故障时,无需手工运维介入,系统可以自动恢复。在恢复期间,如果查询算子需要访问恢复中的节点,则查询会立即失败。
缺陷:在单实例方案中,采用的是故障实时监测、节点替换的方案,在节点恢复时存在一定的服务不可用周期
5.2. 共享存储的多实例高可用
对于关键业务场景,需要更高级别的高可用方案,支持故障隔离、负载隔离,可以采用共享存储的多实例方案。该方案主实例具备完整能力,数据可读可写,权限、系统参数可配置,而只读从实例处于只读状态,所有的变更都通过主实例完成,如下图所示。

主从实例之间计算资源不共享,负载隔离,故障隔离。所有实例共享同一份数据和访问控制,仅有一份存储费用。
建议将主实例作为数据写入和数据加工实例,只读从实例作为数据分析实例,保障读写分离。
- 对于在线服务类的查询业务,由于对于查询的P99稳定性要求较高,建议单独使用一个只读从实例,有效保障线上服务高可用。
- 对于OLAP查询类,可与在线服务从实例分开,单独使用一个数据分析从实例,保证两种读分离,避免大Query对线上服务查询的影响。
5.3. 单实例Shard级多副本
具体参考:单实例Shard级多副本
我们可以通过设置Table Group副本数的方式来提高某个Table Group查询并发能力和可用性。
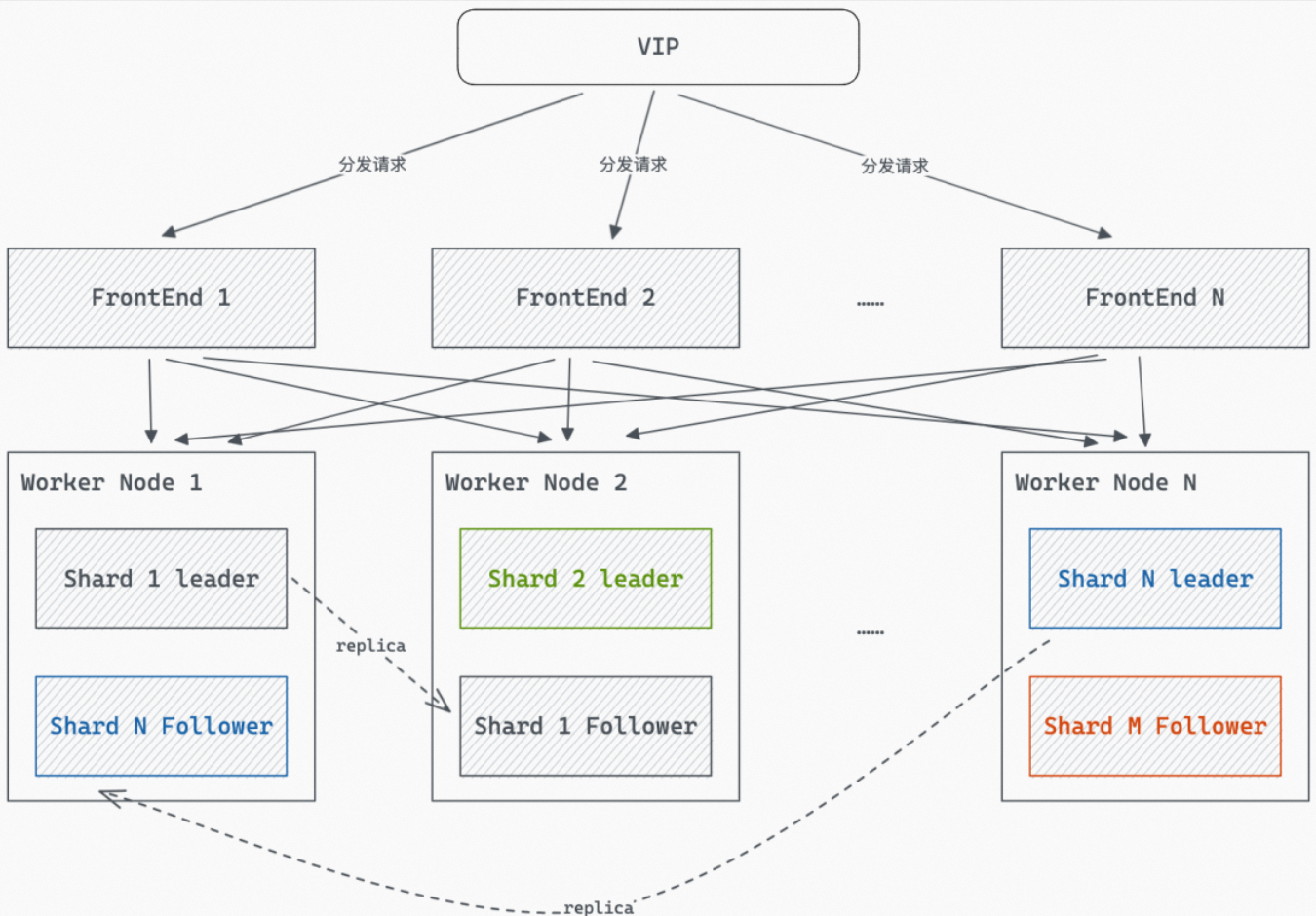
说明:
- 新增的副本属于内存级别的运行时副本,不会增加额外存储成本。replica count数字越大,对资源的消耗也越大,replica count参数应小于等于计算节点数
- shard_count * replica count = 默认实例推荐shard数时,具备最好的性能。
使用说明:
1、数据是按Shard分布的,不同Shard管理不同的数据,不同Shard之间的数据没有重复,所有的Shard在一起是一份完整的数据。
2、默认情况下每一个Shard只有一个副本,即replica count = 1,其对应的属性为leader。您可以通过调整replica count的值,使相同的数据有多个副本,其他副本的属性为follower。
3、写请求由Leader Shard负责,读请求会均衡由多个Follower Shard(也包含leader Shard)共同服务。当使用Follower Shard查询时,数据可能会出现10~20ms级别延迟。
参考资料:产品概述_实时数仓Hologres-阿里云帮助中心

![[已解决]大数据集群CPU告警问题解决](https://img-blog.csdnimg.cn/img_convert/983f11cb7cc3df73a145f5546fb6f014.png)