1.9构建机器学习模型
我们使用机器学习预测模型的工作流程讲解机器学习系统整套处理过程。
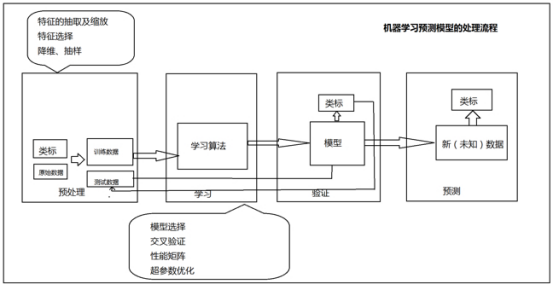
整个过程包括了数据预处理、模型学习、模型验证及模型预测。其中数据预处理包含了对数据的基本处理,包括特征抽取及缩放、特征选择、特征降维和特征抽样;我们将带有类标的原始数据划按照82原则分为训练数据集和测试集。使用训练数据集用于模型学习算法中学习出适合数据集的模型,再用测试数据集用于验证最终得到的模型,将模型得到的类标签和原始数据的类标签进行对比,得到分类的错误率或正确率。
当有新数据来的时候,我们可以代入模型进行预测分类。
注:特征缩放、降维等步骤中所需的参数,只可以从训练数据中获取,并能够应用于测试数据集及新的样本,但仅仅在测试集上对模型进行性能评估或许无法监测模型是否被过度优化(后面模型选择中会提到这个概念)。
1.9.1数据预处理(特征工程)
数据预处理是机器学习应用的必不可少的重要步骤之一,以提到的Iris Dataset为例,将花朵的图像看做原始数据,从中提取有用的特征,其中根据常识我们可以知道这些特征可以是花的颜色、饱和度、色彩、花朵整体长度以及花冠的长度和宽度等。首先了解一下几个数据预处理方法:
l **(数据归一化与标准化,缺失值处理)**大部分机器学习算法为达到性能最优的目的,将属性映射到[0,1]区间,或者使其满足方差为1、均值为0的标准正态分布,从而提取出的特征具有相同的度量标准。
l **(数据降维)**当源数据的某些属性间可能存在较高的关联,存在一定的数据冗余。此时,我们使用机器学习算法中的降维技术将数据压缩到相对低纬度的子空间中是非常有用的。数据降维算法不仅可以能够使得所需的存储空间更小,而且还能够使得学习算法运行的更快。
l **(数据集切分)**为了保证算法不仅在训练集上有效,同时还能很好地应用于新数据,我们通常会随机地将数据集划分为训练数据集和测试数据集,使用训练数据集来训练及优化我们的机器学习模型,完成后使用测试数据集对最终模型进行评估。
数据预处理也称作特征工程,所谓的特征工程就是为机器学习算法选择更为合适的特征。当然,数据预处理不仅仅还有上述的三种。
1.9.2选择预测模型进行模型训练
任何分类算法都有其内在的局限性,如果不对分类任务预先做一些设定,没有任何一个分类模型会比其他模型更有优势。因此在实际的工作处理问题过程中,必不可少的一个环节就是选择不同的几种算法来训练模型,并比较它们的性能,从中选择最优的一个。
(1)如何选择最优的模型呢?我们可以借助一些指标,如分类准确率(测量值和真实值之间的接近程度)、错误率等指标衡量算法性能。
(2)疑问:选择训练模型的时候没有使用测试数据集,却将这些数据应用于最终的模型评估,那么判断究竟哪一个模型会在测试数据集有更好的表现?
针对该问题,我们采用了交叉验证技术,如10折交叉验证,将训练数据集进一步分为了训练子集和测试子集,从而对模型的泛化能力进行评估。
(3)不同机器学习算法的默认参数对于特定类型的任务来说,一般都不是最优的,所以我们在模型训练的过程中会涉及到参数和超参数的调整。
什么是超参数呢?超参数是在模型训练之前已经设定的参数,一般是由人工设定的。
什么是参数呢?参数一般是在模型训练过程中训练得出的参数。
1.9.3模型验证与使用未知数据进行预测
使用训练数据集构建一个模型之后可以采用测试数据集对模型进行测试,预测该模型在未知数据上的表现并对模型的泛化误差进行评估。如果对模型的评估结果表示满意,就可以使用此模型对以后新的未知数据进行预测。(模型评估部分会专门在下节讲解~)
但什么是泛化误差呢?我们带着这个问题分别对模型验证这块涉及到的基础概念做一个深入理解:
【基础概念】通常我们把分类错误的样本数占样本总数的比例称为“错误率(error rate)”,如果在m个样本中有a个样本分类错误,则错误率为E=a/m;从另一个角度,1-a/m则称为“分类精度(accurary)”,也就是“精度+错误率=1”。
我们将模型(或学习器)的实际输出与样本的真实值之间的差异称为“误差(error)”,学习器在训练集上的误差称为“训练误差(training error)”或经验误差(empirical error),在新的样本上的误差称为“泛化误差(generalization error)”。
我们在模型验证的时候期望得到泛化误差小的学习器。
1.9.4模型验证与使用未知数据进行预测
使用训练数据集构建一个模型之后可以采用测试数据集对模型进行测试,预测该模型在未知数据上的表现并对模型的泛化误差进行评估。如果对模型的评估结果表示满意,就可以使用此模型对以后新的未知数据进行预测。(模型评估部分会专门在下节讲解~)
但什么是泛化误差呢?我们带着这个问题分别对模型验证这块涉及到的基础概念做一个深入理解:
【基础概念】通常我们把分类错误的样本数占样本总数的比例称为“错误率(error rate)”,如果在m个样本中有a个样本分类错误,则错误率为E=a/m;从另一个角度,1-a/m则称为“分类精度(accurary)”,也就是“精度+错误率=1”。
我们将模型(或学习器)的实际输出与样本的真实值之间的差异称为“误差(error)”,学习器在训练集上的误差称为“训练误差(training error)”或经验误差(empirical error),在新的样本上的误差称为“泛化误差(generalization error)”。
我们在模型验证的时候期望得到泛化误差小的学习器。
1.9.5准确率和召回率、F1分数
预测误差(error,ERR)和准确率(accurary,ACC)都提供了误分类样本数量的相关信息。误差可以理解为预测错误样本与所有被预测样本数量量的比值,而准确率计算方法则是正确预测样本的数量与所有被预测样本数量的比值。
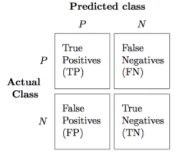
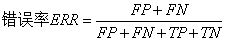
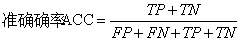
对类别数量不均衡的分类问题来说,真正率TPR与假正率FPR是更重要的指标:
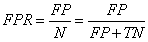 ,
,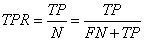
比如在肿瘤诊断中,我们更为关注是正确检测出的恶性肿瘤,使得病人得到治疗。然而降低良性肿瘤(假负FN)错误被划分为恶性肿瘤,但对患者影响并不大。与FPR相反,真正率提供了有关正确识别出来的恶性肿瘤样本(或相关样本)的有用信息。
由此提出了准确率(persoon,PRE)和召回率(recall,REC),是与真正率、真负率相关的性能评价指标,召回率实际上与真正率含义相同,定义如下:
(真正率是看矩阵的行,即实际情况)
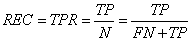
准确率(模型的预测情况,看矩阵的列)定义:
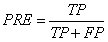
实际中,常采用准确率与召回率的组合,称为F1-Score
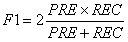
1.9.6Khold评估模型性能
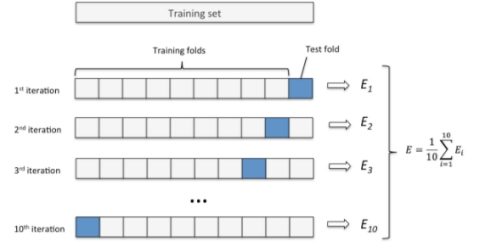
验证模型准确率是非常重要的内容,我们可以将数据手工切分成两份,一份做训练,一份做测试,这种方法也叫“留一法”交叉验证。这种方法很有局限,因为只对数据进行一次测试,并不一定能代表模型的真实准确率。因为模型的准确率和数据的切分是有关系的,在数据量不大的情况下,影响比较大。因此我们提出了K折交叉验证,K-Fold交叉验证。
K-Fold交叉验证,将数据随机且均匀地分成k分,常用的k为10,数据预先分好并保持不动。假设每份数据的标号为0-9,第一次使用标号为0-8的共9份数据来做训练,而使用标号为9的这一份数据来进行测试,得到一个准确率。第二次使用标记为1-9的共9份数据进行训练,而使用标号为0的这份数据进行测试,得到第二个准确率,以此类推,每次使用9份数据作为训练,而使用剩下的一份数据进行测试,这样共进行10次,最后模型的准确率为10次准确率的平均值。这样就避免了数据划分而造成的评估不准确的问题。
如下图:
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢不能老盯着手机屏幕,要不时地抬起头,看看老板的位置⭐
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12468207.html