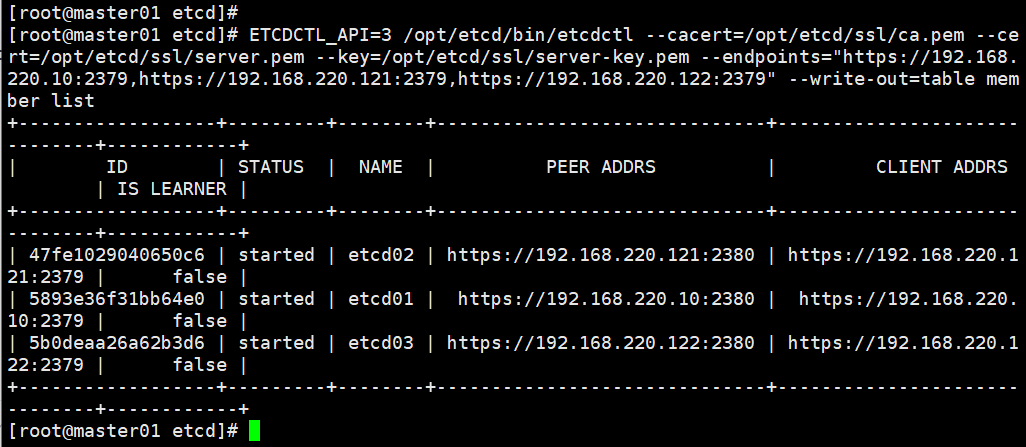
Mysql实战-为什么索引要建立在被驱动表上
前面我们讲解了B+Tree的索引结构,也详细讲解下 left Join的底层驱动表 选择原理,那么今天我们来看看到底如何用以及如何建立索引和索引优化
开始之前我们先提一个问题, 为什么索引要建立在被驱动表上 ?
文章目录
- Mysql实战-为什么索引要建立在被驱动表上
- 1.建表及测试数据
- 2. 不用连接查询 笛卡尔积
- 3.带条件的查询过程即被驱动表的查询过程
1.建表及测试数据
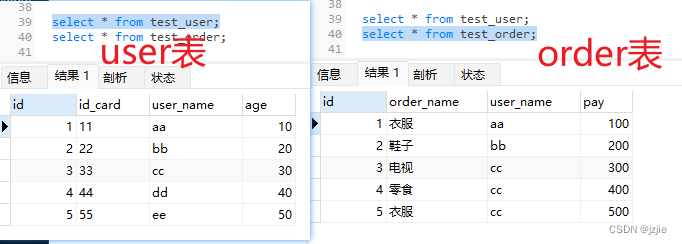
我们先创建两个表 test_user 和 test_order 这两个表作为我们的测试表及测试数据
- test_user 5条数据, 索引只有主键id
- test_order 5条数据,索引同样也只有主键id
#创建表 test_user
CREATE TABLE `test_user` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',`id_card` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '身份证ID',`user_name` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '用户名字',`age` int DEFAULT NULL COMMENT '年龄',PRIMARY KEY (`id`),KEY `idx_age` (`age`),KEY `idx_name` (`user_name`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'
#创建表 test_order
CREATE TABLE `test_order` (`id` int NOT NULL AUTO_INCREMENT,`order_name` varchar(32) NOT NULL DEFAULT '',`user_name` varchar(32) NOT NULL,`pay` int NOT NULL DEFAULT '0',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8插入数据
#插入 user 用户数据
INSERT INTO `test`.`test_user` (`id`, `id_card`, `user_name`, `age`) VALUES (1, '11', 'aa', 10);
INSERT INTO `test`.`test_user` (`id`, `id_card`, `user_name`, `age`) VALUES (2, '22', 'bb', 20);
INSERT INTO `test`.`test_user` (`id`, `id_card`, `user_name`, `age`) VALUES (3, '33', 'cc', 30);
INSERT INTO `test`.`test_user` (`id`, `id_card`, `user_name`, `age`) VALUES (4, '44', 'dd', 40);
INSERT INTO `test`.`test_user` (`id`, `id_card`, `user_name`, `age`) VALUES (5, '55', 'ee', 50);#插入 order 订单数据
INSERT INTO `test`.`test_order` (`id`, `order_name`, `user_name`, `pay`) VALUES (1, '衣服', 'aa', 100);
INSERT INTO `test`.`test_order` (`id`, `order_name`, `user_name`, `pay`) VALUES (2, '鞋子', 'bb', 200);
INSERT INTO `test`.`test_order` (`id`, `order_name`, `user_name`, `pay`) VALUES (3, '电视', 'cc', 300);
INSERT INTO `test`.`test_order` (`id`, `order_name`, `user_name`, `pay`) VALUES (4, '零食', 'cc', 400);
INSERT INTO `test`.`test_order` (`id`, `order_name`, `user_name`, `pay`) VALUES (5, '衣服', 'cc', 500);
查询结果
2. 不用连接查询 笛卡尔积
我们先不用 join语句, 直接查询2个表,看下效果
#直接查询2个表
select * from test_user,test_order;
得到的解雇i就是 笛卡尔积
- user表中的每一条记录,都与order表的一条记录形成组合
- user中有5条数据,order表中也有5条数据
- user 的 第一条,分别和 order 5条对应
- 从而俩个表连接后就有 5 * 5 =25条记录
查询结果笛卡尔积, 25条结果

3.带条件的查询过程即被驱动表的查询过程
上面我们见识到了 如果没有任何条件,我们连接的2个表会形成笛卡尔积,数量膨胀很大,所以 我们在连接的时候一般都需要过滤条件,我们加一些条件,看下效果
#带条件的 笛卡尔积查询
select * from test_user,test_order where test_user.id > 1 and test_user.id = test_order.id and test_order.pay >200 ;
执行结果如下, 只有3条
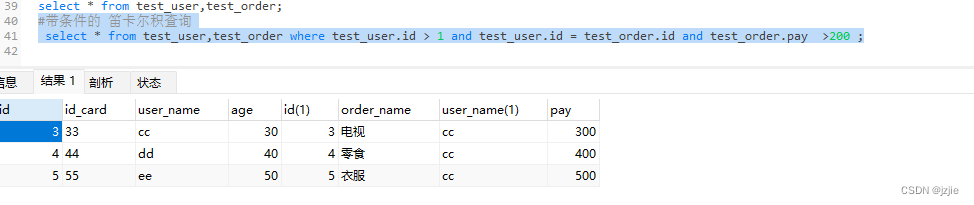
查询条件如下
- test_user.id > 1
- test_user.id = test_order.id
- test_order.pay > 200
- 首先 id > 1, 就只剩下 user2,3,4,5
- 然后test_user.id = test.order.id 这样子就会把很多笛卡尔积 全部去掉, 只保留 两个表 id相同的记录, 还是user的 2,3,4,5
- 最后还有个 pay>200, 这样就通过掉了 user=2这一条 pay=200, 只保留 3,4,5
- 也就是我们要的查询结果
我们来分析下执行过程
- 确定驱动表,我们先假设 user表是驱动表,然后分析下执行过程
- 根据查询条件 test_user.id >1 ,如果 id不是主键, 而且也没索引, 那就是全表扫描ALL, 找到4条记录 user_id = 2,3,4,5
- 根据上面驱动表的数据(前面假设是 user), 然后从被驱动表 test_order中寻找匹配的记录,也就是 user_id =2,3,4,5 和 test_user.id = test_order.id匹配的记录
- 此时开始查询 test_order,当匹配第一条 test_user.id = 2时, 简化查询条件 test_user.id = test_order.id 就变成了 test_order.id = 2 并且还剩余 一个查询条件 test_order.pay > 200
- 所以 test_order 的表就变成了单表查询, 两个查询条件 test_order.id = 2 and test_order.pay >200, 执行test_order的单表查询,查询结果不满足,因为 test_order.id =2 的 pay=200,不pay >200的条件, 本次结束, 继续
- 开始下一次 当 user_id =3时, test_order的单表查询变成了 test_order.id =3 and test_order.pay > 200,进行查询, 满足条件,返回结果
- 依次类推,直到 user_id 的记录3,4,5匹配完毕 ,最终得到 3条记录
- 这就是查询过程
从上面的过程中,我们可以知道,驱动表 只访问了一次
但是被驱动表 要匹配记录,需要不停的去查询,匹配,被动表访问了很多很多次
所以 这就是为什么要把索引建立在被驱动表上的原因
至此,我们通过Mysql的执行查询过程,分析了解到了索引要建立在被驱动表上的原理,这对于我们后期进行SQL分析,有着重要的作用