[Personalized Federated Recommendation via Joint Representation Learning, User Clustering, and Model Adaptation]
(https://dl.acm.org/doi/abs/10.1145/3511808.3557668)
CIKM2022(CCF-B)
论文精读
文章主要创新点(消融实验分析的三个点):
-
联合表示学习
联合表示学习是指通过将用户的协作信息和属性信息结合起来,使用图神经网络(GNN)等方法来学习用户的表示。它能够捕捉用户之间的相似性和特征之间的关联,为个性化推荐提供基础。
注意力机制的使用
注意力机制在这篇论文中的主要作用是用于将用户的属性信息和协同信息进行融合,从而生成用户和物品的原始嵌入向量。通过注意力机制,可以有效地将不同维度的信息进行交叉和整合,从而提取出更有代表性和丰富的特征表示。这样可以帮助模型更好地理解用户和物品之间的关系,进而提高个性化推荐系统的性能。 -
用户聚类
用户聚类是将相似的用户分组,形成用户群体。通过聚类分析,可以将具有相似兴趣和行为模式的用户聚集在一起,从而更好地进行个性化推荐。用户聚类可以帮助减轻通信负担,提高模型训练效率。 -
个性化推荐
模型适应是指根据用户的属性和本地数据的异质性,为每个用户群体学习个性化模型。通过将全局联邦模型、群体级联邦模型和用户的本地模型相结合,可以为不同用户群体提供个性化的推荐模型。模型适应可以提高联邦推荐系统的性能和个性化程度。
Abstract

- 联邦推荐的背景:联邦推荐使用联邦学习技术在推荐系统中来保护用户隐私。它通过在用户设备和中央服务器之间交换模型,而不是原始用户数据,来实现这一点。
- 用户属性和数据的异构性:由于每个用户的属性和本地数据可能都有所不同,因此为了提高联邦推荐的性能,获得针对每个用户的个性化模型是关键。
- PerFedRec框架:文章提出了一个基于图神经网络的个性化联邦推荐框架(PerFedRec)。这个框架通过联合表示学习、用户聚类和模型适应来实现其目的。
- 构建协同图并整合属性信息:具体来说,框架首先构建一个协同图,然后融合属性信息,以通过联邦GNN联合学习表示。
- 基于表示的用户聚类:一旦学到了这些表示,就可以将用户聚类到不同的用户组中,并为每个聚类学习个性化模型。
- 用户的个性化学习:每个用户会通过结合全局联邦模型、集群级联邦模型和用户的微调本地模型来学习一个个性化模型。
- 减轻通信负担:为了减少沉重的通信负担,系统聪明地选择了每个集群中的一些代表性用户(而不是随机选择的用户)来参与训练。
- 实验结果:在真实世界的数据集上的实验结果表明,提出的方法在性能上超过了现有的方法
总之,这篇文章提出了一个新的联邦推荐框架,该框架结合了图神经网络、用户聚类和模型适应技术,旨在提高推荐的性能,同时也注重保护用户隐私。
Introduction


- 联邦推荐的目标:联邦推荐旨在帮助用户筛选有用的信息,同时保护用户的个人数据隐私。
- 联邦推荐的工作原理:根据联邦学习的原则,联邦推荐在用户设备和中央服务器之间交换模型,而不是原始的用户数据。
- 联邦推荐的应用:这种分布式学习范式已经被应用于内容推荐、移动众包任务推荐和自动驾驶策略推荐等领域。
- 现有方法的限制:尽管有一些经典的推荐算法已经被扩展到联邦设置中(如联邦协同过滤、联邦矩阵分解和联邦图神经网络),但这些方法有两个主要缺点:
- 一是它们为所有用户提供相同的推荐,忽略了
用户的异构性(例如数据分布的非独立同分布性和不同的计算资源水平)。(本文提出的个性化推荐解决这个问题) - 二是它们需要与
众多用户进行频繁杂的模型交换,导致高通信成本。(本文提出的用户聚类,选择特定客户端通信解决这个问题)
- 一是它们为所有用户提供相同的推荐,忽略了
PerFedRec框架:为了解决上述问题,文章提出了一个基于图神经网络的联邦推荐框架 - PerFedRec。该框架从用户/项目的属性和协同信息中学习表示,并通过GNN将用户划分为不同的簇。每个簇都有一个簇级联邦推荐模型,而中央服务器有一个全局模型。通过结合簇级模型和全局模型,可以为每个用户提供个性化的推荐。减轻通信负担:此外,为了减轻通信负担,PerFedRec框架通过在每个簇中选择一部分代表性用户来更新全局模型,而不是所有用户。这种"用户退出"策略在通信受限的场景中(如自动驾驶策略推荐)非常有用。
总结和贡献:总的来说,文章的贡献可以归结为三点:表示学习、用户聚类和模型适应(个性化推荐),这三者都是为了提供个性化的推荐。
所提出的框架主要做了以下三点工作:
-
联合表示学习、用户聚类和模型适应:- 提出了一个框架,它在联邦推荐中结合了表示学习、用户聚类和模型适应。这是为了实现个性化的推荐,同时考虑到用户的本地数据和资源的多样性。
- 通过使用图神经网络(GNN)学习用户的合作和属性信息,可以有效地聚类相似的用户,并学习个性化的模型。
-
选取代表性用户:为了训练,从每个聚类中仔细挑选了一些代表性的用户。
这种方法减少了与服务器之间的通信成本,特别适合带宽有限、延迟要求低的应用场景。 -
改进现有基线的性能: 该提议的方法在多个真实世界的数据集上都提高了与现有技术基线相比的性能。

Problem Formultion
系统构成: -
该系统包括一个中央服务器和N个分布式用户。 每个用户具有一个由dua维度组成的属性uₙ。
系统中有M个项目,每个项目具有一个由dia维度组成的属性vₘ。 -
用户与项目的交互:
每个用户都有与项目的历史交互记录,例如给项目打分。 但由于隐私关注,中央服务器不能观察到用户的历史交互和属性。 -
数据交换:
由于上述隐私问题,与服务器之间的数据交换不包括用户数据。相反,只有推荐模型可以在服务器和用户设备之间交换。
我们提出的方案
- 系统目标:在这些约束条件下,系统的目标是为不同的用户训练个性化的推荐模型。


这段论文描述了一个名为PerFedRec的推荐框架。以下是主要的点和组成部分:
- PerFedRec框架概述:
- 框架由两部分组成:
- 用户端的端到端本地推荐网络
- 服务器端的聚类聚合器
- 框架由两部分组成:
- 用户端本地推荐网络:
- 这个网络由三个主要模块组成:
- a. 原始嵌入模块 (Raw Embedding Module):
- 此模块预处理用户和项目的属性。 使用注意力机制,它结合属性信息与合作信息(即用户与项目的交互)。
- 形式上,用户n和项目m的合作信息表示为一个d维的嵌入 E i d u , n E_{idu,n} Eidu,n 和 E i d , i , m E_{id,i,m} Eid,i,m。
- 这些嵌入是随机初始化的,并在基于用户-项目交互的训练过程中进行更新。
- 用户n和项目m的属性通过一个线性层和一个特征交叉层传递,以生成属性嵌入 E f u , n E_{fu,n} Efu,n和 E f i , m E_{fi,m} Efi,m。
- 数学上,属性嵌入的生成可以由以下公式表示:




- b.局部GNN模块:
- 当获取所有商品的嵌入和用户自己的嵌入后,系统需要用户-商品交互矩阵来训练局部GNN模型。- 但是,存在一个问题:用户-商品交互信息是私有的本地数据,不应被与服务器或其他用户分享。
-
解决隐私问题:
-
为了解决上述隐私问题,作者采用了一个与文献[17]类似的方法:
- 每个用户上传受保护的嵌入和经过加密的商品ID(使用对所有用户相同的加密方式)。
- 然后服务器将加密的商品ID和用户嵌入发送给所有用户。
- 为了进一步减少通信成本,服务器
只将加密的商品ID和与该商品交互过的其他用户的嵌入发送给某个用户。
-
因此,每个用户能够得到多个用户的嵌入信息以及对应的商品,而不暴露这些用户的身份。这样,每个用户可以探索其周围的用户和商品,从而扩展其本地交互图。 -
GNN模块的输出:

-
应用嵌入:
这些嵌入将被输入到一个个性化预测网络中,用于进行评分或偏好预测。这种策略提供了插件,并使用了GNN模块,如PinSage[18]、NCF[16]和LightGCN[8]。


- C.个性化预测模块

这段文本描述了一个推荐系统中的个性化预测模块。这个模块结合了用户特定的模型、集群级模型和全局模型,以实现更为个性化的推荐。
服务器端基于聚类的联邦模块


这部分论文详细描述了“Server-Side Clustering Based Federation”模块,即服务器端基于聚类的联邦模块。以下是对该部分的解读:
-
主要功能:这个服务器端的联邦模块有三个主要功能:用户聚类、用户选择和参数聚合。
-
用户聚类(User Clustering):
- 基于用户嵌入 E u , n E_{u,n} Eu,n,服务器将用户聚类成 K 个组。
- 用户 n 归属于某个特定的集群 C ( n ) C(n) C(n)。
- 聚类方法可以是任何常用的方法,如K-means。
- 由于节点表示 E u , n E_{u,n} Eu,n是基于每个用户的属性和协作信息共同学习得到的,因此表示更加丰富。
-
用户选择(User Selection):
- 为了降低在关键情况下的通信成本,该框架提供了一个基于集群的用户选择功能。
- 在每个集群内,可以根据集群大小适应性地选择一些随机用户参与每次迭代中的模型聚合。
-
参数聚合(Parameter Aggregation):
- 框架同时进行网络模型聚合和嵌入聚合。
用户嵌入存储在本地设备上,但可以通过服务器交换,而不会泄露用户身份。商品的嵌入则由所有客户端共享和更新。- 对于网络模型,服务器会根据所有参与用户的加权总和来聚合一个全局模型 以及针对每个集群 C(n)的集群级模型,后者则根据该集群中所有参与用户的加权总和来聚合。
-
个性化推荐:全局模型和集群级模型将提供给用户 n,以实现个性化的推荐。
-
总结:这部分描述了一个服务器端的联邦学习框架,该框架通过用户聚类、用户选择和参数聚合,以实现个性化推荐。
实验部分
实验设置

 数
数
- 数据集:
- 研究使用三个真实世界的数据集进行实验:MovieLens-100K、Yelp和Amazon-Kindle。
- MovieLens-100K 是一个电影评分数据集,包含100,000个用户评分。
- Yelp 和 Amazon-Kindle分别是其他常用的基准数据集,其中 Yelp是关于商业评论的,而 Amazon-Kindle 用于推荐电子书。
- 基线方法:
研究比较了提议的 PerFedRec 方法和现有的 FedGNN 方法。此外,PerFedRec 旨在通过对用户进行聚类以改进FedAvg算法来提供更加个性化的推荐。
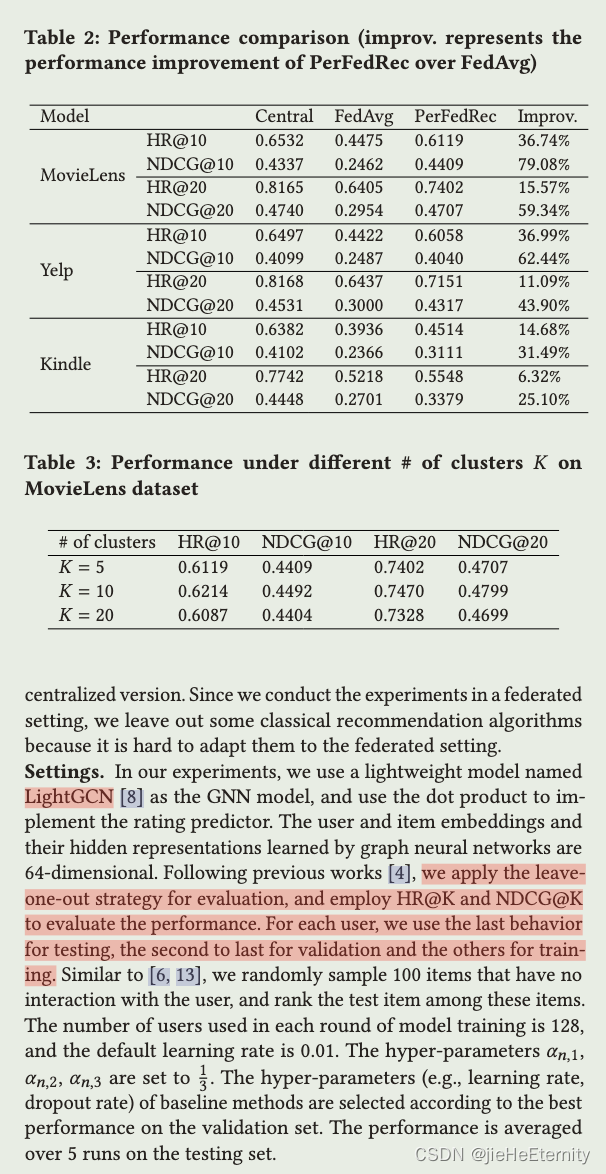
- 性能比较:
- 表格2显示了在三个数据集上的性能比较。用两种指标衡量性能:HR@K 和
NDCG@K。从结果可以看出,对于大多数数据集和评估指标,PerFedRec 都优于 FedAvg。
- 表格2显示了在三个数据集上的性能比较。用两种指标衡量性能:HR@K 和
- 不同聚类数量的性能:
- 表格3展示了在MovieLens数据集上使用不同数量的聚类(K=5, 10,
20)时的性能。这有助于了解在该数据集上聚类数量对性能的影响。
- 表格3展示了在MovieLens数据集上使用不同数量的聚类(K=5, 10,
- 实验设置:
- 实验使用了名为 LightGCN 的轻量级模型,并采用点乘来实现评分预测。用户和项目的嵌入向量都隐藏在表示中,维度为64。
- 为了评估,研究使用了留一法,并使用了HR@K和NDCG@K进行评估。
在测试时,每位用户的最后一次行为用于测试,倒数第二次用于验证,其他的用于训练。
表现分析

- 总体性能比较:
- Table 2 展示了三种方法在三个数据集上的性能。
- 中心化方法(Centralized method)在几乎所有场景中都取得了最好的结果。
- FedAvg 表现最差,因为它忽略了特征信息并且不提供个 性化的推荐。
- PerFedRec vs. Centralized & FedAvg:
- 提议的 PerFedRec 性能接近于中心化方法。
- 与 FedAvg 相比,PerFedRec 在所有三个数据集上的平均 HR@10 提高了 29.47%,而 NDCG@10 提高了57.67%。
- 数据集稀疏性的影响:
- MovieLens 数据集上的性能提升最为显著。
- 稀疏的数据集(如 Kindle)上的改进较小,但仍然达到了平均 19.40% 的提升。
- 尤其在 Kindle 数据集上,尽管它没有外部特征信息,但仍然取得了改进,这显示了个性化推荐的重要性。
- 总结:这段文本主要对比了不同推荐系统方法的性能,并强调了PerFedRec方法相对于其他方法的优越性,尤其是在稀疏数据集上。
模型分析和消融实验

- 模型分析
- 关键超参数的影响:
文章讨论了一个关键的超参数:模型训练中的簇数量(clusters K)。
Table 3显示,当改变超参数时,性能保持相对稳定,这减少了调整超参数的困难
- 关键超参数的影响:
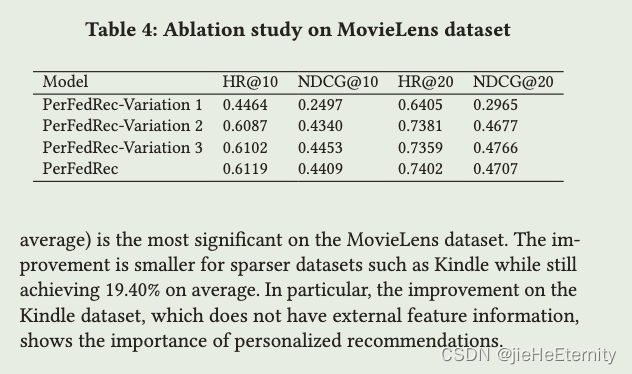
- 在MovieLens数据集上的消融实验。
- 比较了 PerFedRec 和它的三个变种(Variation 1, 2, 3)。
- 原始的 PerFedRec 在 HR@10、NDCG@10、HR@20 和 NDCG@20 的指标上都取得了相对较好的性能。
- 研究提议的框架中每个模块对性能的贡献。
- PerFedRec-Variation 1:
不使用个性化推荐。 - PerFedRec-Variation 2:
不使用特征信息。 - PerFedRec-Variation 3:
不使用用户聚类。
- PerFedRec-Variation 1:
- 主要发现:
- 从Table 4可以看出,性能的最大提升来自个性化推荐。
- 加入特征信息显著提高了性能。
- 与没有用户聚类的 Variation 3 相比,PerFedRec 的性能下降很小,但通过用户聚类减少了通信成本。
文章总结
- 用户聚类的重要性:
- 文章强调了在分布式推荐中用户聚类的重要性,并提出了一个新的个性化分布式推荐框架。
- 框架的工作原理:
- 该框架通过合作性和属性信息的 GNNs 学习用户表示,对相似的用户进行聚类,并通过结合用户级别、簇级别和全局模型来获取个性化推荐模型。
- 通信成本的减少:
- 为了减少与选定的代表性客户的通信成本,从每个簇中选择客户进行模型联合。
- 实验结果:
在三个真实世界的数据集上的实验表明,提议的框架性能优越,与传统的联邦推荐相比。
代码链接
代码解析
代码主要分为两个部分,utility文件下封装的一些工具类代码和其余的针对这个模型的代码,其中utility文件夹下的代码和NGCF这篇论文中的工具类代码一摸一样,应该是直接在这个基础上修改的,这里主要讨论下图中的几个代码:
Central.py,FedAvg.py,PerFedRed.py,GNN.py
其余的几个代码主要是:
其中Central.py表示不采用联邦学习,直接使用主服务器训练。
FedAvg.py表示采用联邦学习中的平均聚合方式,PerFedRec.py是本文提出的框架:基于联合表示学习、用户聚类和模型自适应的个性化联合推荐。
model_ini = copy.deepcopy(model.state_dict())这行代码执行后的效果,model_ini变量。这里有什么取决于GNN模型中网络结构如何定义:
def init_weight(self):initializer = nn.init.xavier_uniform_embedding_dict = nn.ParameterDict({'user_emb': nn.Parameter(initializer(torch.empty(self.n_user,self.emb_size))),'item_emb': nn.Parameter(initializer(torch.empty(self.n_item,self.emb_size)))})weight_dict = nn.ParameterDict()return embedding_dict, weight_dict

detach()方法在PyTorch中是用来将一个张量从计算图中分离出来的,确保该张量不再参与自动梯度计算。
当我们在PyTorch中进行张量操作时,PyTorch构建了一个计算图来跟踪这些操作,从而可以在后续执行反向传播计算梯度。在某些情况下,我们可能希望阻止PyTorch跟踪某些特定的张量操作,使它们不参与反向传播。在这种情况下,我们可以使用detach()方法。
看到的本文在代码上相对于FedAvg的创新。
PerFedRec.py如下所示,其中的idxs_users变量,初始化的时候随机选取128个客户端,在后面,对所有的用户进行聚类后,按照每个元素所属类的元素数量在每个聚类中按照元素数量大小来决定选取客户端数量的多少。
n_rdm = int(n_fed_client_each_round/2)#客户端的一半是随机选择n_choice = int(n_fed_client_each_round/2)#客户端的另一半是在聚类中加权选择idxs_users_rdm = random.sample(range(0, n_client), n_rdm)#随机选择idxs_users_choice = random.choices(range(0, n_client), weights=(clu_result_weight), k=n_choice)#在聚类中加权选择,n_client和clu_result_weight的长度一样。聚类中元素数量越多,被选中的概率越大。idxs_users_ = idxs_users_rdm + idxs_users_choiceidxs_users_ = list(set(idxs_users_))while len(idxs_users_) < n_fed_client_each_round:r_= random.sample(range(0, n_client), 1)[0]if not r_ in idxs_users_:idxs_users_.append(r_)idxs_users = idxs_users_
下面是带注释的PerFedRec.py全部代码
import copy
import pickle
import random
import sys
import math
from statistics import mean
import numpy as np
import torch
import torch.optim as optim
from numpy import array
from GNN import GNN
from utility.helper import *
from utility.batch_test import *
import warnings
# warnings.filterwarnings('ignore')
from time import time
from sklearn.cluster import KMeansdef FedWeiAvg(w,w_):w_avg = copy.deepcopy(w[0])for k in w_avg.keys():w_avg[k] = torch.mul(w_avg[k], w_[0])for i in range(1, len(w)):w_avg[k] += (w[i][k] * w_[i])return w_avgdef FedAvg(w):w_avg = copy.deepcopy(w[0])#深度拷贝以后,修改w_avg不对更改w的值。for k in w_avg.keys():#对于模型中一个客户端的所有不同的权重(一个客户端可能有几种不同类型的权重。for i in range(1, len(w)):#len(w)是有多少个客户端。w_avg[k] += w[i][k] #计算一个类型权重的所有客户端的和。w_avg[k] = torch.div(w_avg[k], len(w))#计算一个类型权重的平均值。return w_avg#返回的是所有客户端每一类型权重的均值。if __name__ == '__main__':n_fed_client_each_round = 128 #每次随机选择的客户端的数量n_cluster = 5 #所有客户端分为5类if torch.cuda.is_available():args.device = torch.device('cuda')plain_adj, norm_adj, mean_adj = data_generator.get_adj_mat()#这三个矩阵的维度都是(9746,9746)args.node_dropout = eval(args.node_dropout)#[0.1]args.mess_dropout = eval(args.mess_dropout)#[0.1,0.1,0.1]args.mode = 'fed'args.include_feature = Falsen_client = data_generator.n_usersmodel = GNN(data_generator.n_users,data_generator.n_items,norm_adj,args).to(args.device)t0 = time()cur_best_pre_0, stopping_step = 0, 0optimizer = optim.Adam(model.parameters(), lr=args.lr)loss_loger, pre_loger, rec_loger, ndcg_loger, hit_loger = [], [], [], [], []idxs_users = random.sample(range(0, n_client), n_fed_client_each_round)#从n_client个客户端中随机挑选n_fed_client_each_round个客户端组成的列表#idxs_users在后面的更新中,每次随机选取一半的客户,其余一半客户按照用户聚类中的元素数量的加权选择。wei_usrs = [1./n_fed_client_each_round] * n_fed_client_each_round#初始化了一个权重列表,这些权重用于加权客户端模型的融合。best_hr_10, best_hr_20, best_ndcg_10, best_ndcg_20 = 0, 0, 0, 0training_time = 0.0,begin_time = time()for epoch in range(args.epoch):t1 = time()loss, mf_loss, emb_loss = 0., 0., 0.n_batch = data_generator.n_train // args.batch_size + 1model_para_list = []#存储每个模型的参数user_ini_state = copy.deepcopy(model.state_dict())['embedding_dict.user_emb']#初始化客户端向量print(model.state_dict().keys())user_emb_list = {}local_test = []w_cluster = {i:[] for i in range(n_cluster)}#创建一个键值对,键是聚类索引,值是每个聚类中的列表。local_model_test_res = {} #创建一个字典存储本地模型的测试结果def LocalTestNeg(data_generator,test_idx,model):#本地测试函数test_positive, test_nagetive = data_generator.sample_test_nagative(test_idx)#为test_idx这个用户生成一个正样本和100个负样本(从未交互的样本中随机挑选)u_g_embeddings, pos_i_g_embeddings = model.get_u_i_embedding([test_idx], test_positive)#得到这个测试用户和正样本的嵌入向量rate_batch = model.rating(u_g_embeddings, pos_i_g_embeddings).detach().cpu()[0]u_g_embeddings, pos_i_g_embeddings = model.get_u_i_embedding([test_idx] * len(test_nagetive),test_nagetive)rate_batch_nagetive = torch.matmul(u_g_embeddings.unsqueeze(1),pos_i_g_embeddings.unsqueeze(2)).squeeze().detach().cpu()#这个函数为每一个测试用户生成了一个正样本,生成了100个负样本,分别计算这个正样本和前面101个样本的的向量内积。torch_cat = torch.cat((rate_batch, rate_batch_nagetive), 0).numpy()return torch_catfor idx in (idxs_users):if epoch>1:#clu_result[idx]获取与用户idx相应的聚类标签model.load_state_dict(copy.deepcopy(w_cluster_avg[clu_result[idx]]))#w_cluster_avg存储各个聚类的平均模型参数,提取该用户对应聚类的平均参数user_ini_state = copy.deepcopy(model.state_dict())['embedding_dict.user_emb']model_ini = copy.deepcopy(model.state_dict())users, pos_items, neg_items = data_generator.sample(idx)u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings = model(users,pos_items,neg_items,drop_flag=args.node_dropout_flag)#执行模型的前向传递。batch_loss, batch_mf_loss, batch_emb_loss = model.create_bpr_loss(u_g_embeddings,pos_i_g_embeddings,neg_i_g_embeddings)#使用前面生成的嵌入来计算bpr损失值。optimizer.zero_grad()batch_loss.backward()optimizer.step()local_model_test_res[idx] = LocalTestNeg(data_generator,idx,model)#哈希映射,键是用户,值是用户和1个正样本向量和100个负样本向量做内积得到的loss += batch_lossmf_loss += batch_mf_lossemb_loss += batch_emb_lossmodel_aft = copy.deepcopy(model.state_dict())# 这段代码对当前模型的某些项目嵌入进行扰动,将扰动后的模型参数保存到一个列表中for _ in range(100):ran_idx = random.randint(0, data_generator.n_items-1)#随机选择一个项目的索引loc, scale = 0., 0.02 #拉普拉斯分布参数,loc是均值,scale是拉普拉斯分布的尺度参数s = torch.Tensor(np.random.laplace(loc, scale, args.embed_size)).to(args.device)# 扰动参数model_aft['embedding_dict.item_emb'][ran_idx] = model_aft['embedding_dict.item_emb'][ran_idx] + s#实行扰动model_para_list += [model_aft]user_emb_list[idx] = model_aft['embedding_dict.user_emb'][idx]if epoch >= 1:w_cluster[clu_result[idx] ].append(model_aft)model.load_state_dict(model_ini)w_ = FedAvg(model_para_list)#得到全局联邦模型for j in user_emb_list:user_ini_state[j] = user_emb_list[j]#训练后的模型向量w_['embedding_dict.user_emb'] = copy.deepcopy(user_ini_state)if epoch>=1 :w_cluster_avg = []for i in range(len(w_cluster)):try:w_cluster_avg.append(FedAvg(w_cluster[i]))#得到每一个聚类的联邦平均权重except Exception:w_cluster_avg.append(w_)res_list = []if epoch > 1:print('Cluster test')hr_list = []ndcg_list = []hr_list_20 = []ndcg_list_20 = []for i in range(len(w_cluster)):users_to_test = [x for x in range(n_client) if clu_result[x]==i]for test_idx in (users_to_test):model.load_state_dict(w_cluster_avg[i])torch_cat = LocalTestNeg(data_generator, test_idx, model)model.load_state_dict(w_)torch_cat2 = LocalTestNeg(data_generator, test_idx, model)if local_model_test_res.get(test_idx) is not None:torch_cat = np.mean( np.array([ torch_cat2,torch_cat, local_model_test_res[test_idx] ]), axis=0 )else:torch_cat = np.mean(np.array([torch_cat2,torch_cat]), axis=0)ranking = list(np.argsort(torch_cat))[::-1].index(0) + 1ndcg = 0hr = 0if ranking <= 10:hr = 1ndcg = math.log(2) / math.log(1 + ranking)hr_list.append(hr), ndcg_list.append(ndcg)ndcg = 0hr = 0if ranking <= 20:hr = 1ndcg = math.log(2) / math.log(1 + ranking)hr_list_20.append(hr), ndcg_list_20.append(ndcg)print(f'HR@10={mean(hr_list)},NDCG@10={mean(ndcg_list)}')if mean(hr_list) > best_hr_10 or mean(ndcg_list) > best_ndcg_10 or mean(hr_list_20) > best_hr_20 or mean(ndcg_list_20) > best_ndcg_20:best_hr_10 = max(best_hr_10, mean(hr_list))best_ndcg_10 = max(best_ndcg_10, mean(ndcg_list))best_hr_20 = max(best_hr_10, mean(hr_list_20))best_ndcg_20 = max(best_ndcg_20, mean(ndcg_list_20))training_time = time() - begin_timemodel.load_state_dict(w_)users_emb = w_['embedding_dict.user_emb']users_emb = users_emb.cpu().detach().numpy()kmeans = KMeans(n_clusters=n_cluster, random_state=0).fit(users_emb)clu_result = list(kmeans.labels_)clu_result_dict = dict((x, clu_result.count(x)) for x in set(clu_result))#统计clu_result中每个元素的出现次数clu_result_weight = [clu_result_dict[i] for i in clu_result]#每个位置的元素是这个元素所属于聚类的元素数量n_rdm = int(n_fed_client_each_round/2)#客户端的一半是随机选择n_choice = int(n_fed_client_each_round/2)#客户端的另一半是在聚类中加权选择idxs_users_rdm = random.sample(range(0, n_client), n_rdm)#随机选择idxs_users_choice = random.choices(range(0, n_client), weights=(clu_result_weight), k=n_choice)#在聚类中加权选择,n_client和clu_result_weight的长度一样。聚类中元素数量越多,被选中的概率越大。idxs_users_ = idxs_users_rdm + idxs_users_choiceidxs_users_ = list(set(idxs_users_))while len(idxs_users_) < n_fed_client_each_round:r_= random.sample(range(0, n_client), 1)[0]if not r_ in idxs_users_:idxs_users_.append(r_)idxs_users = idxs_users_random.shuffle(idxs_users)wei_usrs = [clu_result_weight[i] for i in idxs_users]#选择中的用户所属聚类的元素数量wei_usrs = [i/sum(wei_usrs) for i in wei_usrs]#每一个聚类的元素数量占比# w_ = FedWeiAvg(model_para_list,wei_usrs)if epoch % 10 == 0:print(f"Best Result:{'%.4f' % best_hr_10},{'%.4f' % best_ndcg_10},{'%.4f' % best_hr_20},{'%.4f' % best_ndcg_20}")print(f'Trainig time:{training_time}')if (epoch + 1) % 50 != 0:if args.verbose > 0 and epoch % args.verbose == 0:perf_str = 'Epoch %d [%.1fs]: train==[%.5f=%.5f + %.5f]' % (epoch, time() - t1, loss, mf_loss, emb_loss)print(perf_str)continuet2 = time()users_to_test = list(data_generator.test_set.keys())ret = test(model, users_to_test, drop_flag=True)t3 = time()loss_loger.append(loss)rec_loger.append(ret['recall'])pre_loger.append(ret['precision'])ndcg_loger.append(ret['ndcg'])hit_loger.append(ret['hit_ratio'])if args.verbose > 0:perf_str = 'Epoch %d [%.1fs + %.1fs]: train==[%.5f=%.5f + %.5f], recall=[%.5f, %.5f], ' \'precision=[%.5f, %.5f], hit=[%.5f, %.5f], ndcg=[%.5f, %.5f]' % \(epoch, t2 - t1, t3 - t2, loss, mf_loss, emb_loss, ret['recall'][0], ret['recall'][-1],ret['precision'][0], ret['precision'][-1], ret['hit_ratio'][0], ret['hit_ratio'][-1],ret['ndcg'][0], ret['ndcg'][-1])print(perf_str)cur_best_pre_0, stopping_step, should_stop = early_stopping(ret['recall'][0], cur_best_pre_0,stopping_step, expected_order='acc', flag_step=5)if should_stop == True:breakif ret['recall'][0] == cur_best_pre_0 and args.save_flag == 1:torch.save(model.state_dict(), args.weights_path + str(epoch) + '.pkl')print('save the weights in path: ', args.weights_path + str(epoch) + '.pkl')recs = np.array(rec_loger)pres = np.array(pre_loger)ndcgs = np.array(ndcg_loger)hit = np.array(hit_loger)best_rec_0 = max(recs[:, 0])idx = list(recs[:, 0]).index(best_rec_0)final_perf = "Best Iter=[%d]@[%.1f]\trecall=[%s], precision=[%s], hit=[%s], ndcg=[%s]" % \(idx, time() - t0, '\t'.join(['%.5f' % r for r in recs[idx]]),'\t'.join(['%.5f' % r for r in pres[idx]]),'\t'.join(['%.5f' % r for r in hit[idx]]),'\t'.join(['%.5f' % r for r in ndcgs[idx]]))print(final_perf)emd_dict = model.get_weight()论文中的个性化推荐主要分为三部分
每个客户端利用自己本地的数据进行训练(对应下面这部分代码)
users, pos_items, neg_items = data_generator.sample(idx)u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings = model(users,pos_items,neg_items,drop_flag=args.node_dropout_flag)#执行模型的前向传递。batch_loss, batch_mf_loss, batch_emb_loss = model.create_bpr_loss(u_g_embeddings,pos_i_g_embeddings,neg_i_g_embeddings)#使用前面生成的嵌入来计算bpr损失值。optimizer.zero_grad()batch_loss.backward()optimizer.step()
利用客户端的所属于的聚类中的参数来对客户端中的参数进行更新。
if epoch>1:#clu_result[idx]获取与用户idx相应的聚类标签model.load_state_dict(copy.deepcopy(w_cluster_avg[clu_result[idx]]))#w_cluster_avg存储各个聚类的平均模型参数,提取该用户对应聚类的平均参数user_ini_state = copy.deepcopy(model.state_dict())['embedding_dict.user_emb']
在一个epoch内,每次和所有的客户端通信完后就会得到全局的联邦模型参数,使用联邦平均的方式得到全局联邦模型参数,代码如下:
w_ = FedAvg(model_para_list)#得到全局联邦模型
这个加上前面提到的idx_users构成了用户的个性化推荐。
虽然我们模拟多客户端和server的过程中一直在使用model.load_dict()函数来更新model参数,这样每次都会覆盖掉前面的参数,但是这样对于联邦学习来说是有益的。





![[推荐]SpringBoot,邮件发送附件含Excel文件(含源码)。](https://img-blog.csdnimg.cn/e042371eadb9418c9f7e3195067cf0dc.png)