一、Filebeat介绍
1、Filebeat是什么?
-
Filebeat适用于转发和集中数据的轻量级传送工具,Filebeat监视了指定的日志文件或位置,收集日志事件,并将他们转发到Elasticsearch或Logstash进行索引。
-
**Filebeat的工作方式:**启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找,对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到位Filebeat配置的输出。
Filebeat由两个主要组成部分:Prospector(探勘者)和Harvesters(矿车)。这些组件一起工作来读取文件并将时间数据发送到指定的output。
- **prospector: ** 负责找到所有需要进行读取的数据源。
- harvesters : 负责读取单个文件的内容,并将内容发送到output,负责文件的打开和关闭。
2、Filebeat的工作原理
-
Filebeat可以保持每个文件的状态,并且频繁的把文件状态从注册表里更新到磁盘,这里所说的文件状态是用来记录上一次Harvaster读取文件时,读取到的位置,以保证能把全部的日志都读取出来,然后发给output。
-
如果在某一时刻,作为output的Elasticsearch或则Logstash变成了不可用,Filebeat将会把最后的文件读取位置保存下来,直到output重新可用的时候,快速地恢复文件数据的读取。
-
在Filebeat运行过程中,每个Prospector的状态信息都会保存在内存里,如果Filebeat出现了重启,完成重启之后,会从注册表文件里恢复重启之间的状态信息,让Filebeat继续从之间已知的位置开始进行读取数据。
理解
Filbeat可以实现保持读取时的文件状态。将文件状态频繁保存在磁盘中。
1、这样可以保证能把全部的日志读取出来。
2、在output的ES或logsatsh出现故障,Filebeat也会把文件读取位置保存下来,方便下次快速恢复。
3、当Filebeat出现故障重启时,也可以恢复到之前的读取位置。
3、Filebeat用途
适用于集群环境下,服务多,且部署在不同机器。
1、为什么要用filebeat来收集日志?为什么不直接使用lohstash收集日志?
- 因为logstash是jvm跑的,资源消耗比较大,启动一个logstash就需要消耗500M左右的内存(这就是为什么logstash启动特别慢的原因)。
- 而filebeat只需要10M左右的内存资源。
- 常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat发送到logstash,lostash根据配置文件进行过滤,然后将过滤之后的文件传输到elasticsearch中,最后通过kibana展示。
2、filebeat结合logstash带来的好处?
1、通过logstash,具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻Elasticsearch持续写入数据的压力。
2、从其它数据源(例如数据库,s3对象存储或消息传递队列)中提取
3、将数据发送到多个目的地,例如S3,HDFS(hadoop分部署文件系统)或写入文件
4、使用数据流逻辑组成更复杂的处理管道。
3、Filebeat和Logstash的区别
| logstash | filebeat | |
| 内存 | 大 | 小 |
| CPU | 大 | 小 |
| 插件 | 多 | 多 |
| 功能 | 从多中输入端采集并实时解析和转换数据并输出到多中输出端 | 传输 |
| 轻重 | 相对较重 | 轻量级的二进制文件 |
| 过滤能力 | 强大的过滤能力 | 轻微的过滤能力 |
| 进程 | 一台服务器只允许一个logstash进程,挂掉之后需要手动拉起 | |
| 原理 | logstash使用管道的方式进行日志的收集和输出,分为输入input、输出output,每个阶段都有不同的替代方式 | 开启进程后悔启动一个或多个探测器(prospectors)去检测指定的日志文件,对于探测器找到的每一个日志文件,filebeat启动收个进程(harvester),没一个收个进程读取一个日志文件的新内容,并发现这些新的数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定地点。 |
| 集群 | 单节点 | 单节点 |
| 输出多个接收方 | 支持 | 6.0之前支持 |
| 二次开发或者扩展开发 | 难 | 易 |
二、部署ELFK
1、环境搭建
再ELK的的服务基础上,增加一台filebeat服务器。
| 主机名 | IP地址 | 部署软件 | 系统 |
|---|---|---|---|
| node1 | 20.0.0.55 | Elasticsearch、Kibana | centos7 |
| node2 | 20.0.0.56 | Elasticsearch | centos7 |
| apache | 20.0.0.57 | logstash、apache | centos7 |
| filebeat | 20.0.0.58 | filebeat | centos7 |
关闭防护墙、修改主机名。
systemctl disable --now firewalldhostnamectl set-hostname filebeat

2、安装filebeat
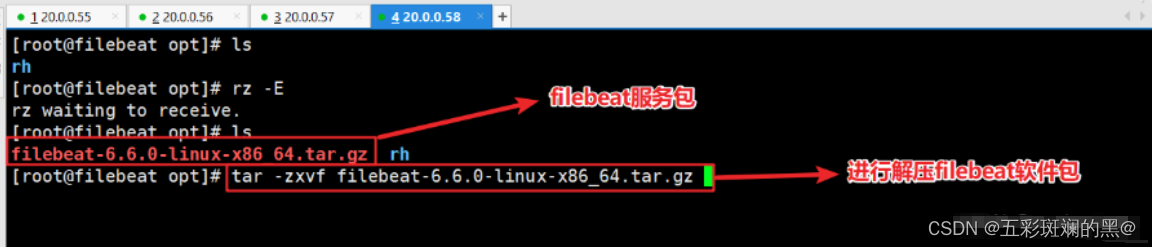
#上filebeat包上传到/opt目录下cd /opt
tar -zxvf filebeat-6.6.0-linux-x86_64.tar.gzmv filebeat-6.2.4-linux-x86_64 /usr/local/filebeatcd /usr/local/filebeat
vim filebeat.ymlfilebeat.prospectors:
##21行,指定log类型,从日志文件中读取消息
- type: log
##24行,开启日志收集功能,默认为falseenabled: true
##28行,指定监控的日志文件- /var/log/ *.log
##29行,添加收集/var/log/messages- /var/log/messages
##31行,添加以下内容,注意格式fields: service_name: filebeatlog_type: logservice_id: 20.0.0.58
#-------------------------- Elasticsearch output -------------------------
该区域内容全部注释
#----------------------------- Logstash output ---------------------------
##165行,取消注释
output.logstash:
##167行,取消注释,指定logstash的IP和端口号hosts: ["20.0.0.57:5044"]./filebeat -e -c filebeat.yml
#启动filebeat,-e记录到stderr并禁用syslog /文件输出,-c指定配置文件




3、在logstash组件所在的节点(apache节点)上新建一个logstash配置文件
cd /etc/logstash/conf.d
vim logstash.conf
input {beats {port => "5044"}
}
output {elasticsearch {hosts => ["20.0.0.55:9200", "20.0.0.56:9200"]index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}/usr/share/logstash/bin/logstash -f logstash.conf 

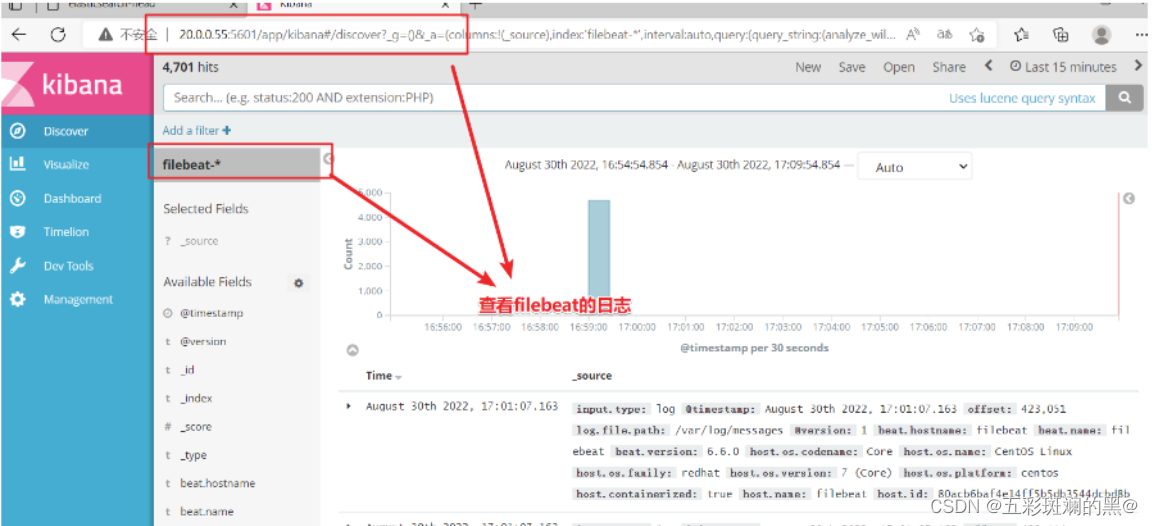
4、验证查看
网页访问20.0.0.55:9100查看能否查看到

网页访问20.0.0.55:5601查看能否查看到