目录
一、“不会开发游戏的AI工具制作者不是好博士”
二、ControlNet出现的背景
三、什么是ControlNet?
四、「神采 Prome AI」的诞生
五、总结
去年DALLE2,Stable Diffusion等文-图底层大模型发布带动了应用层的发展,出现了一大批爆款产品,被认为是”AI绘画元年“。目光再转到今年,在隔壁ChatGPT风头一时无二的时候,ControlNet的出现再次把大家的注意力移到了AI绘画生成上面。
一、“不会开发游戏的AI工具制作者不是好博士”
在科普ControlNet之前,有必要先介绍一下他的作者。目前正在斯坦福读博的中国人张吕敏(Lvmin Zhang),2021年才毕业于苏州大学,并且在本科期间就发表了多篇ICCV,CVPR,ECCV等顶会著作。这些论文高度与绘画相关,他的Style2Paints甚至已经更新到第五版了。
很少人知道,他还在Unity上做了一款名为 YGOPro2 的TCG游戏,可见每一个学霸都是时间管理大师。

二、ControlNet出现的背景
时间再回到去年各种模型诞生初期,那时候图像生成只需要用户简单地输入文本(Prompts)就可以实现,这让普通人操作的难度大大降低。尤其是Stable Diffusion的出现,直接部署在家用电脑的同时又很快生成高质量图片。
但是伴随着普通用户的尝试,种种问题也随之暴露出来。首先由于扩散模型本身diversity很强,导致生成的图像往往不受控制(可控性低),常常无法满足需求,需要用户在三四十张生成的图片中挑选一张可用的(废片率高)。
提示词:一张精美的图片需要通过大量的关键词拼凑(多达四五十个单词),才呈现出一个相对比较好的表现形式:

对于刚接触AI绘画的普通人来说找到合适的关键词是面临的首要问题,其次很多我们常见的关键词如:建筑,宏大/精美等远远不如渲染配置参数词:“4K超清”,“高质量”,“阴影效果”表现效果好。可见单纯的关键词控制无法满足用户对精美细节的需要。而在成图的时候原生Stable-Diffusion 模型的瑕疵则更明显,比如著名的“AI不会画手”,“美少女吃面梗”都反映出大模型在手脚方面的细节表现不好。针对这些问题除了避免出现手脚,进行二次AI创作/手动修改似乎也没什么好的办法(加入数据集针对性训练当然也是一种办法,但是一方面对于数据量的要求会很大大提升,另一方面还是没有很好地解决黑盒问题)。
幸运的,就在不久之前,ControlNet发布了。
三、什么是ControlNet?
ControlNet是一种神经网络结构,通过添加额外的条件来控制扩散模型。
ControlNet将网络结构划分为:1. 不可训练(locked)部分保留了stable-diffusion模型的原始数据和模型自身的学习能力。2. 可训练(trainable)部分通过额外的输入针对可控的部分进行学习,本质是端对端的训练。简单来说就是通过一些额外条件生成受控图像-在Stable Diffusion模型中添加与UNet结构类似的ControlNet额外条件信息,映射进参数固定的模型中,完成可控条件生成。
众所周知,AIGC的可控性是它进入实际生产最关键的一环。有了ControlNet的帮助我们可以直接提取建筑的构图,人物的姿势,画面的深度和语义信息等等。在很大程度上我们不需要频繁更换提示词来碰运气,尝试一次次开盲盒的操作了。

ControlNet把每一种不同类别的输入分别训练了模型,目前有8个:Canny,Depth,HED,MLSD,Normal,Openpose,Scribble,Seg。这些可控条件大致可以分为三类,下面我们将一一展开介绍:
- 姿势识别
姿势识别,用于人物动作,提取人体姿势的骨架特征(posture skeleton)。姿势提取的效果图很像小时候flash上的小游戏“火柴人打斗”,有了这个就不用去网上寻找各种英语姿势tag,而是可以直接输入一张姿势图。并且这个模型还可以生成多人姿势(偶尔会翻车,但是之前靠提示词是完全无法生成多人动作的)
这个功能对于人物设计和动画非常有用,可能会用于影视和游戏行业,比如动作捕捉和捏脸系统。

边缘检测,通过从原始图片中提取线稿,来生成同样构图的画面
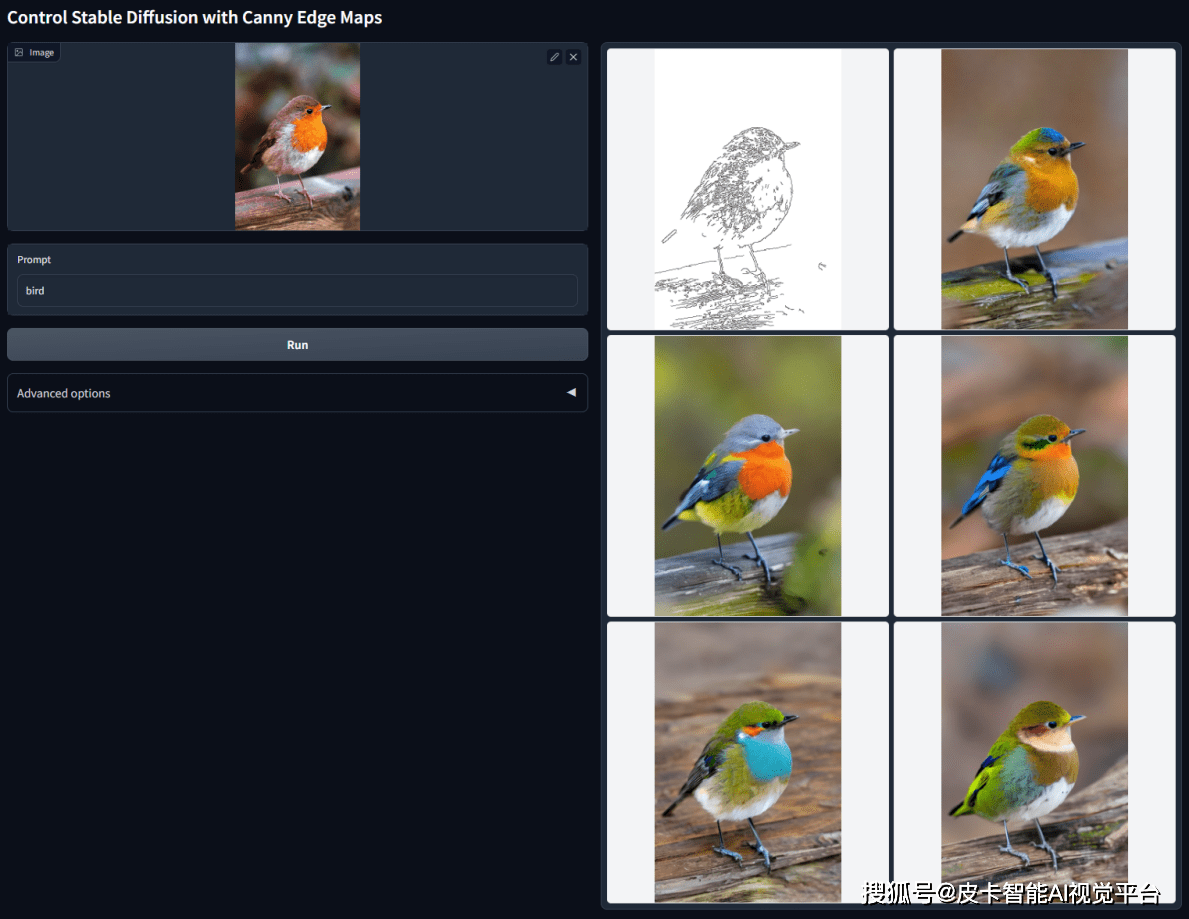
跟canny类似,适合重新上色和风格化
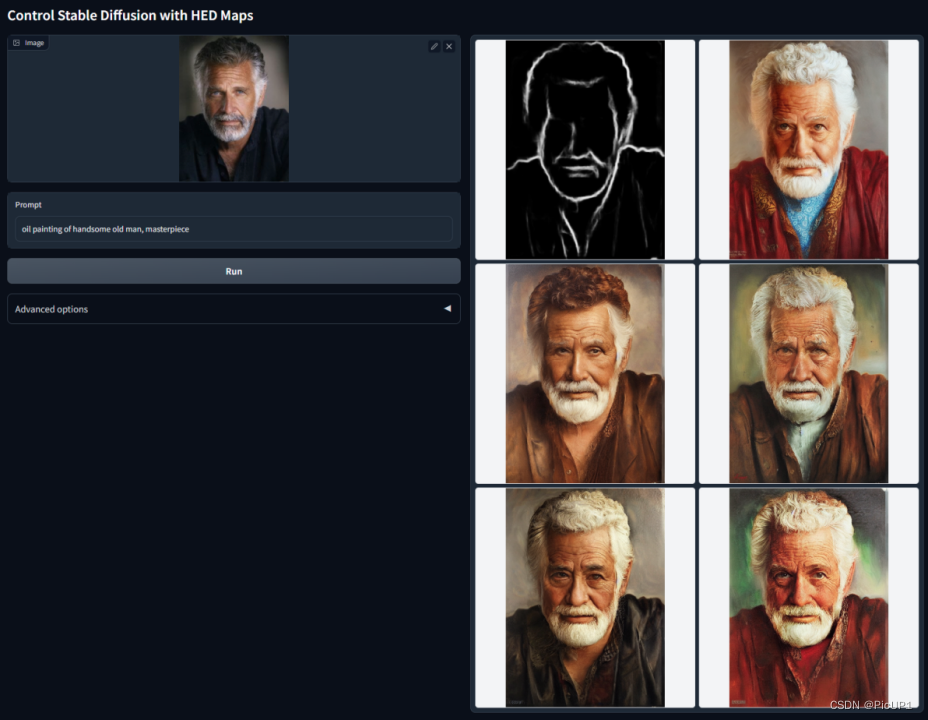
针对涂鸦

语义分割识别(区块标注,适合大片块状草图上色)
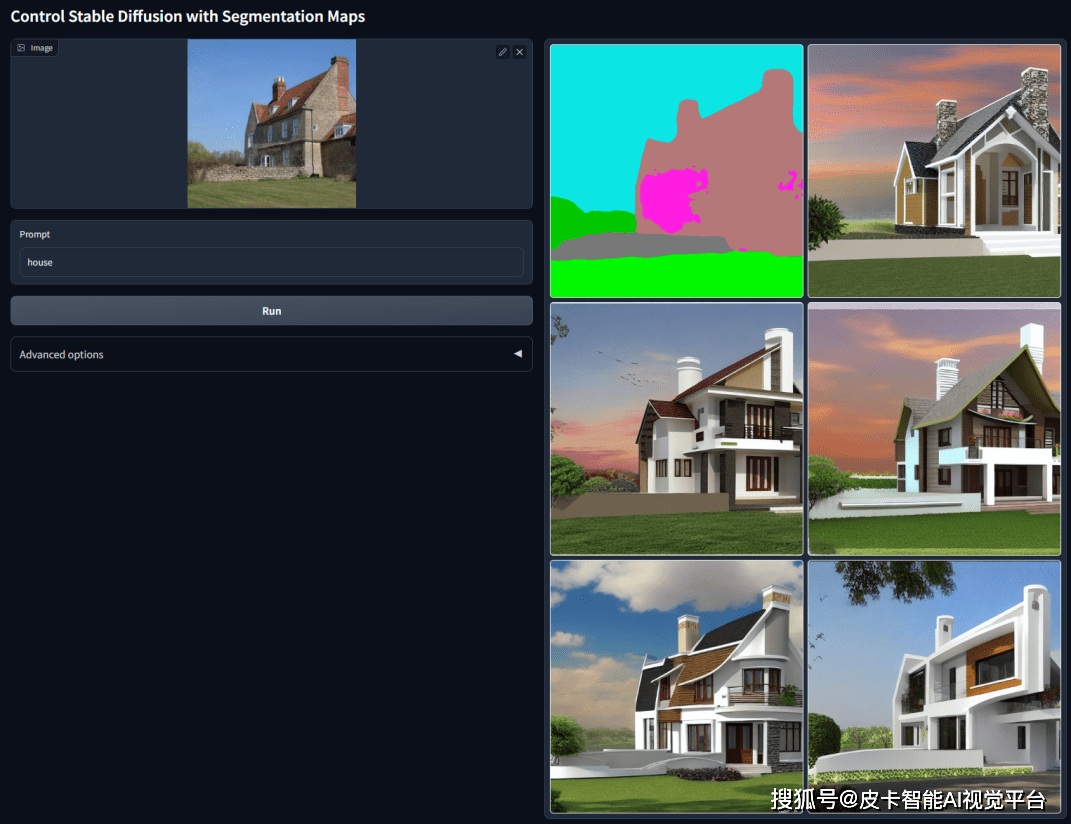
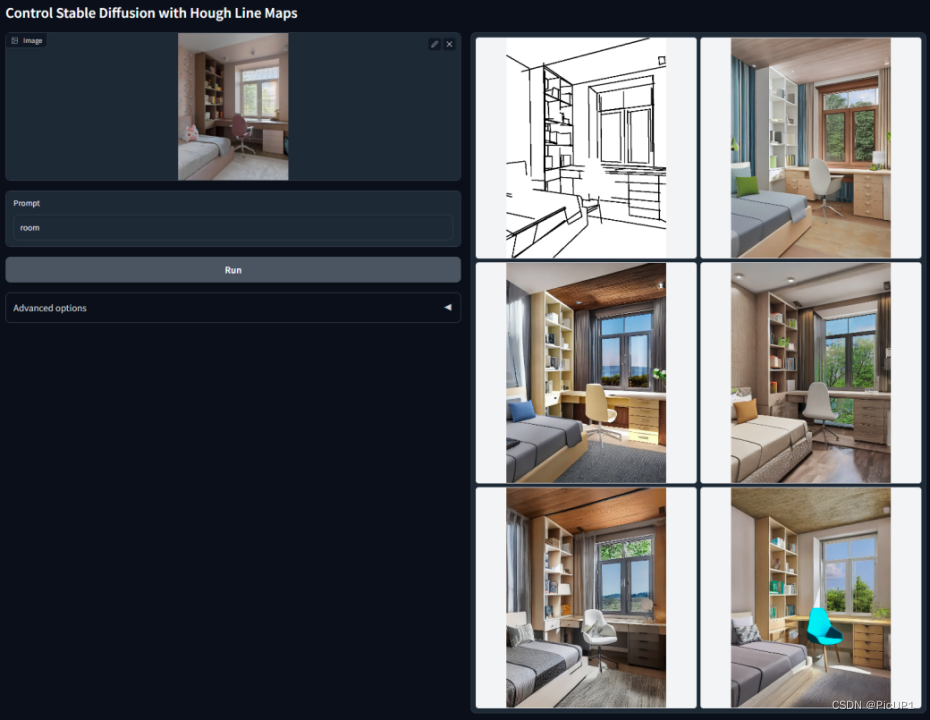
- 线段识别,适用于建筑场景
深度检测,提取深度图
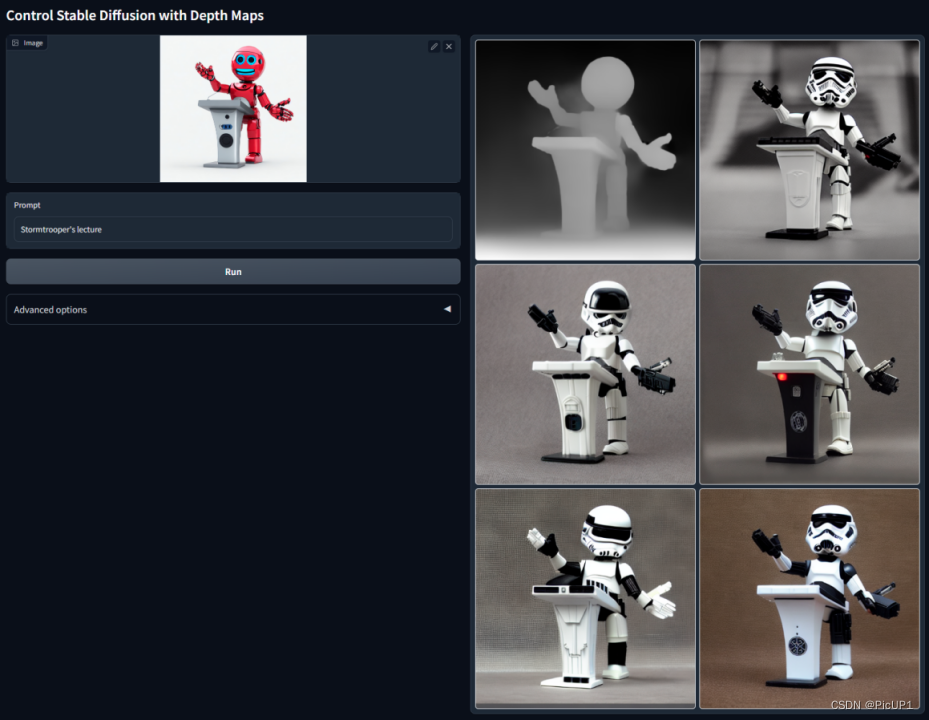
通过提取原始图片中的深度信息,生成具有深度图,再生成具有同样表面几何形状的图片。甚至可以利用3D建模软件搭建简单的场景,再交给ControlNet去渲染。
模型识别,适用于建模,类似深度图,比深度模型对于细节的保留更加精确,用于法线贴图。
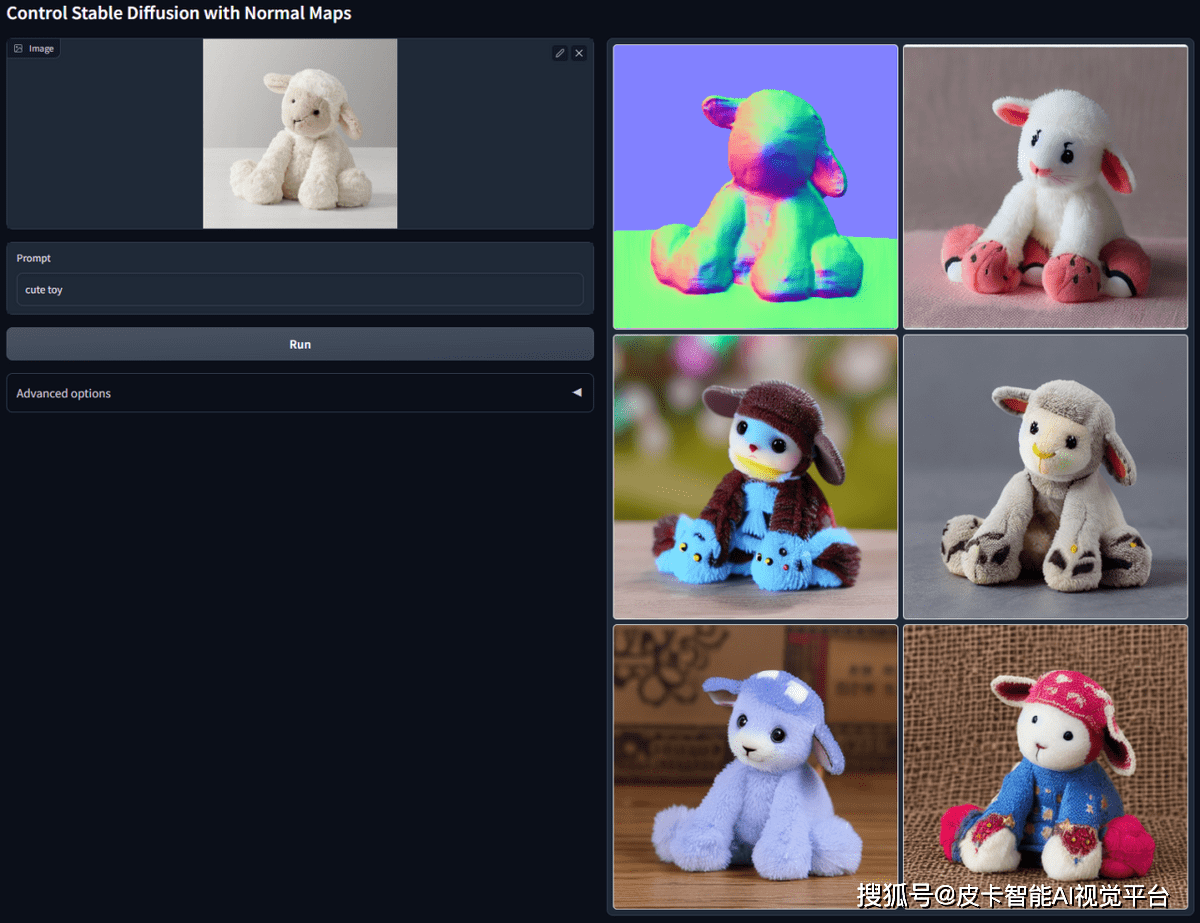
靠着以上八种模型就可以用其他Input Condition(语义图,关键点图,深度图等单一维度的特征)来辅助文字提示词来生成可控的输出图片了。比起仅仅依靠提示词的方法,ControlNet虽然多花了点时间,但要知道有些图片靠直接点击按钮的方式的话,不论roll多少次都是搞不出来的。
四、「神采 Prome AI」的诞生
皮卡智能一直在AIGC的应用中无限探索,去年AI绘画爆火时,我们创造了「AI艺术创作」平台,用户可以用中文生成AI绘画和使用「图生图」的功能。

与去年上线的「AI艺术创作」不同,这款新产品主要面向B端用户,ControlNet的出现,让我们将AI绘画从玩具变成工具。神采PromeAI拥有强大的人工智能驱动设计助手和广泛可控的AIGC(C-AIGC)模型风格库,使你能够轻松地创造出令人惊叹的图形、视频和动画。例如边缘和人物姿态,甚至可以通过线稿控制来完美解决AIGC经常受到诟病的“手指”问题。

该产品具有以下功能:可以直接将涂鸦和照片转化为插画,自动识别人物姿势并生成插画;将线稿转化为完整的上色稿,并提供多种配色方案;自动识别图片景深信息以生成具有相同景深结构的图片,识别建筑及室内图片线段并生成新的设计方案;读取图片法线信息以辅助快速建模,利用图片语义分割识别生成具有相同构图和内容的不同风格图片。

五、总结
就在AI绘画刚出来那会儿,就有人说ai无法生成不同图层,或者是线稿/中间图,不会取代人工绘画。不提后者,就说现在,不管是文生图(直接生成线稿),还是图生图(ControlNet,从图片提取线稿),哪怕把渲染过程制作成视频也是轻而易举的。每个技术问题都会变成下一次的突破,在大模型解决画风,Lora解决角色,ControlNet解决了输出内容之后,手脚以及其他关键点优化很快也会解决了。
从模型本身上看,不难想象下一次技术的迭代一定会在可控性上有更大的提升,因为一张图像能提取的特征无非就是画风、深度,光照,姿势,语义等。从应用方面看,既然ControlNet能标记骨骼来画人体,说不定之后也可以用于医学,建筑,也能标记车站画轨道。


 在各个细分领域的公司带着他们的ai工具“下沉”之后,他们已经发现了越来越多可以做的事情。今年才过了三个月,无法想象在接下来的九个月AIGC这条赛道还会带给我们哪些更惊奇的变化。
在各个细分领域的公司带着他们的ai工具“下沉”之后,他们已经发现了越来越多可以做的事情。今年才过了三个月,无法想象在接下来的九个月AIGC这条赛道还会带给我们哪些更惊奇的变化。