1.梯度下降法的原理
1.1确定一个小目标:预测函数
机器学习中一个常见的任务是通过学习算法,自动发现数据背后的规律,不断改进模型,做出预测。
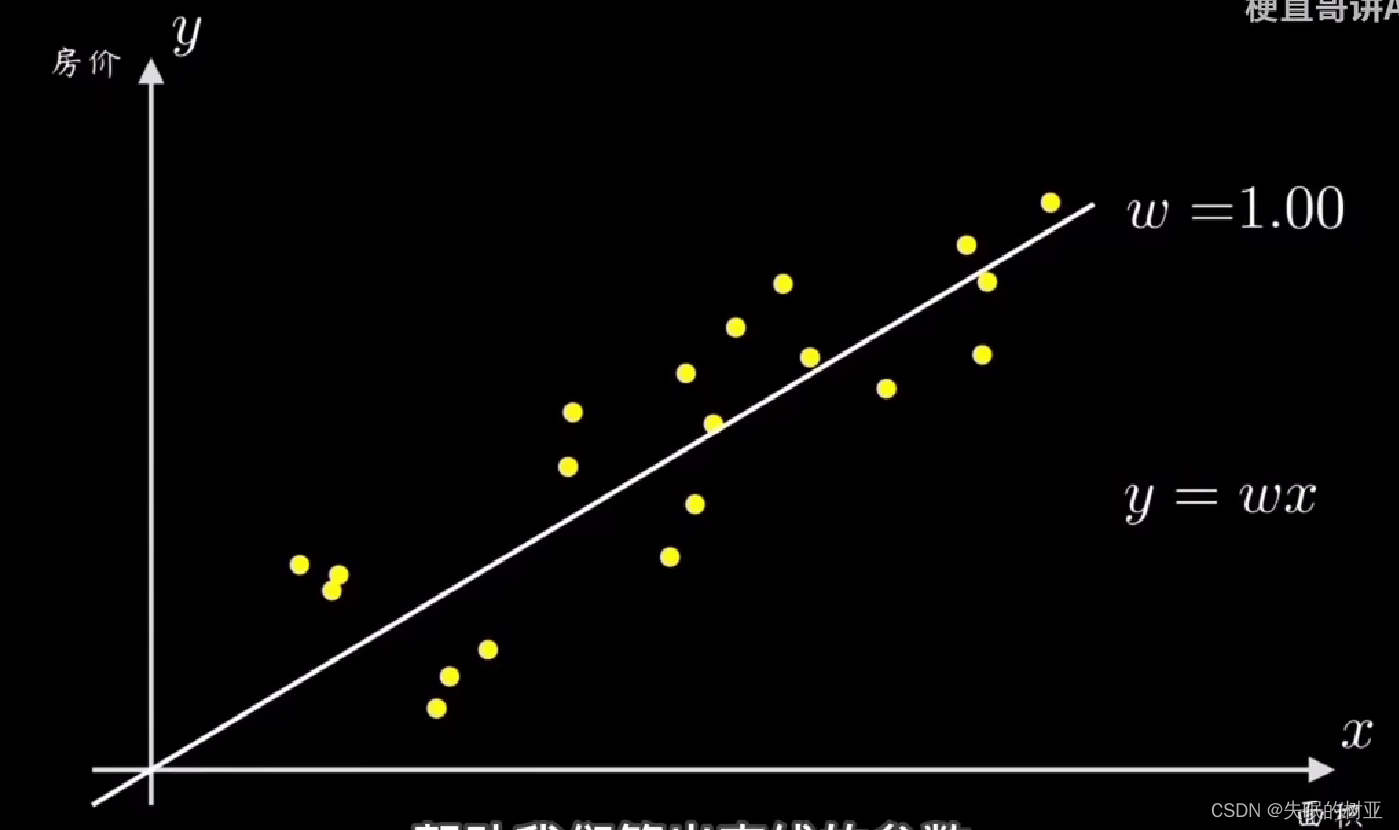
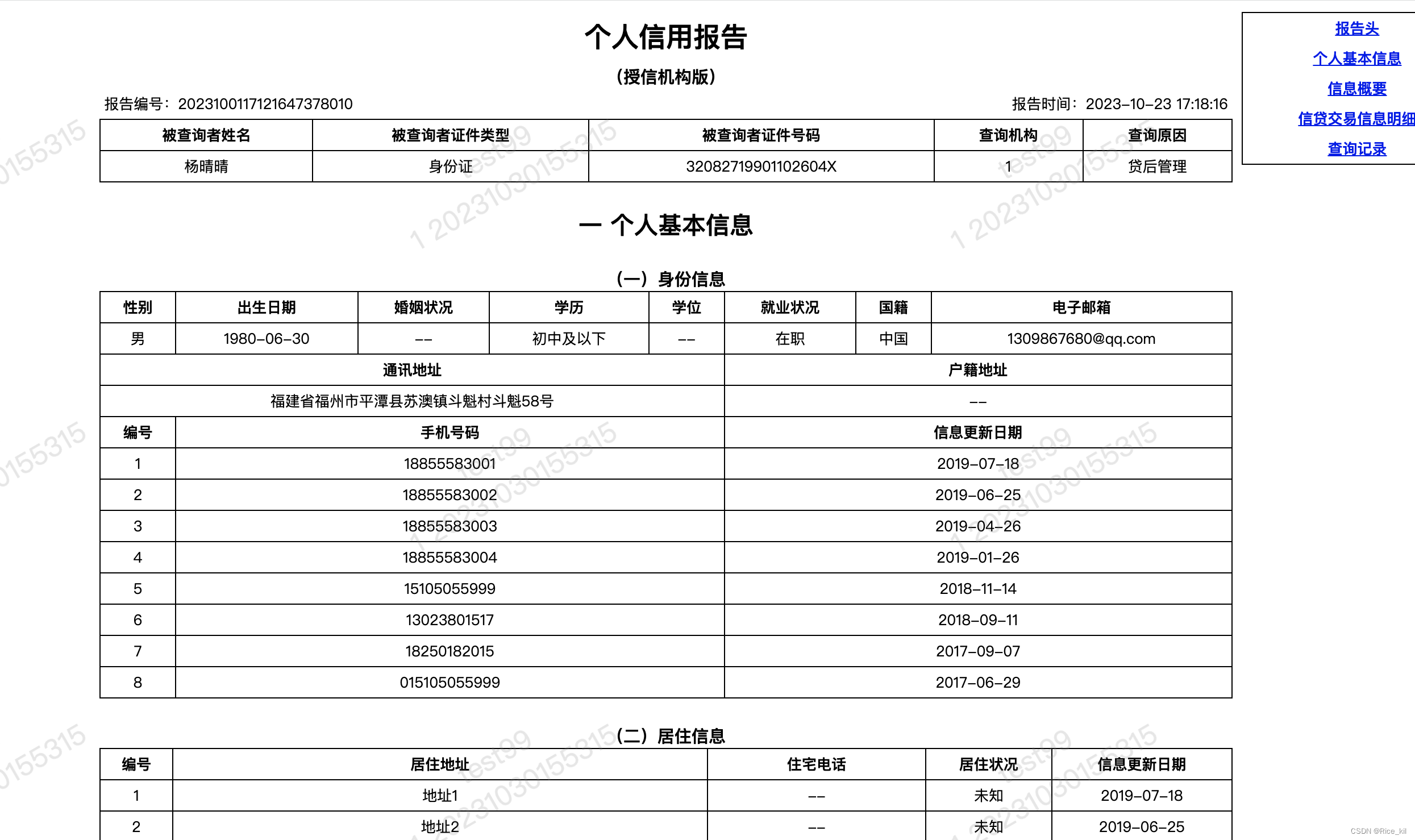
上图的坐标系,横轴表示房子面积,纵轴表示房价,图中的点就是给出的数据。
任务是,设计一个算法,让机器能够拟合这些数据,算出直线的参数w
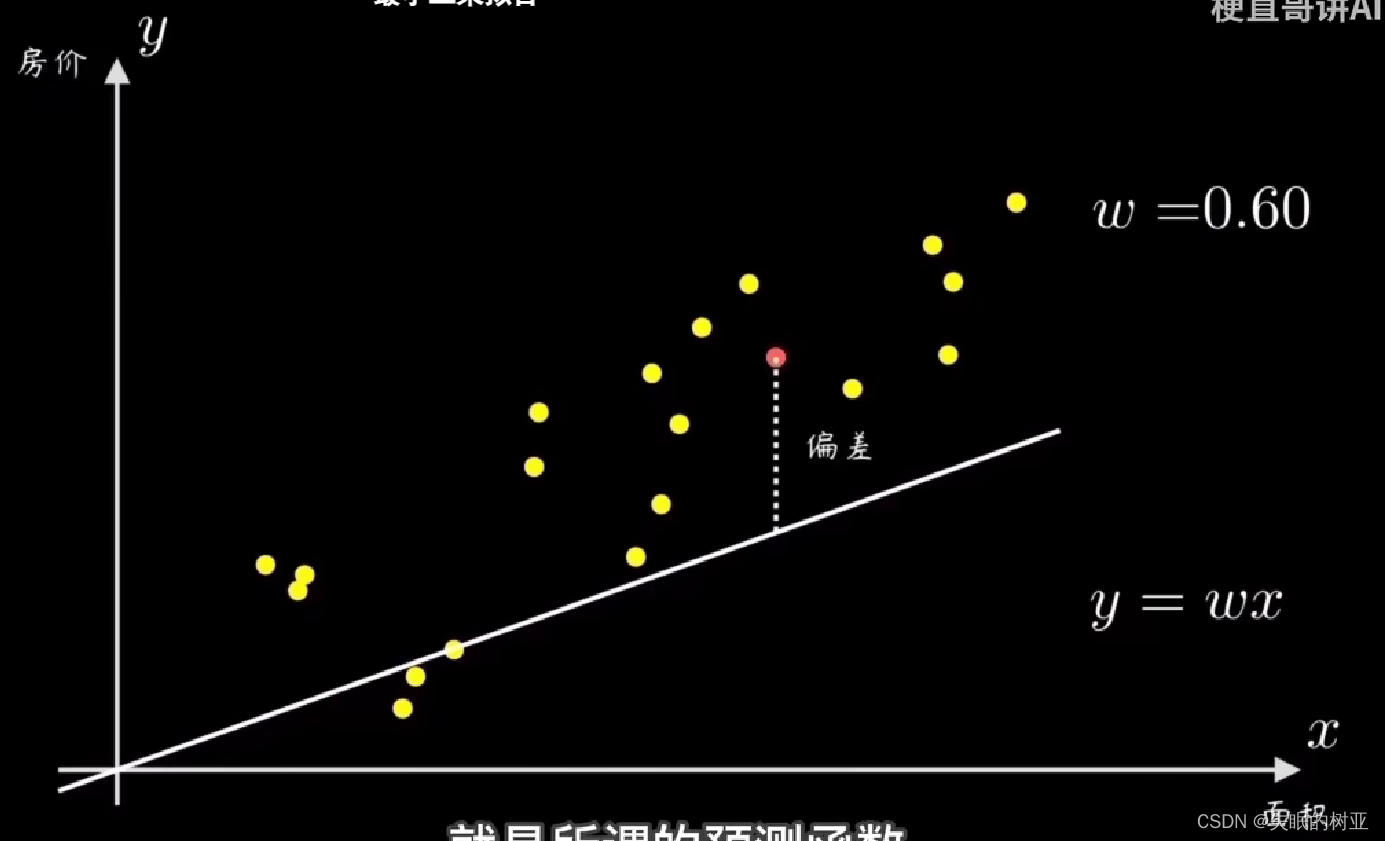
一个简单的方法是,先随机选一条过原点的直线,然后计算所有样本点和这条直线的偏离程度,再根据误差大小来调整w的值。
1.2 找到差距:代价函数
均方误差,所有点的误差相加求和再求平均值
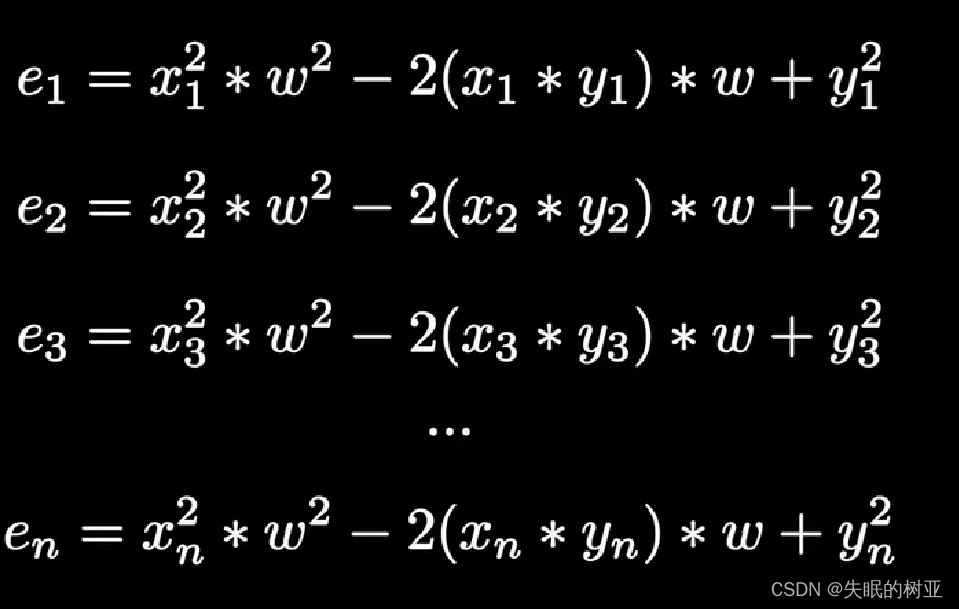
e1 e2 …en是每个点的误差值
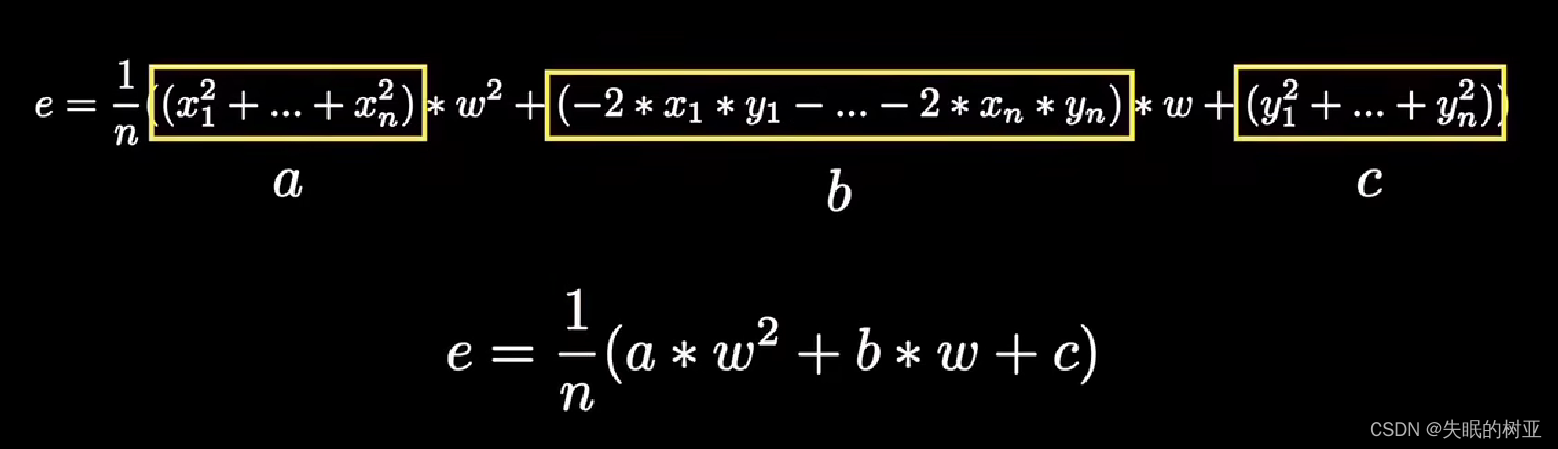
把每个点的误差值相加求和再求平均值,合并同类项
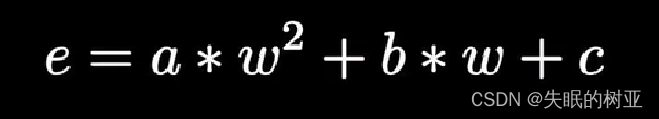
上面这个误差函数代表了学习需要付出的代价,也常被称为代价函数(cost function),
二次项的系数a>0,是一个开口向上的抛物线
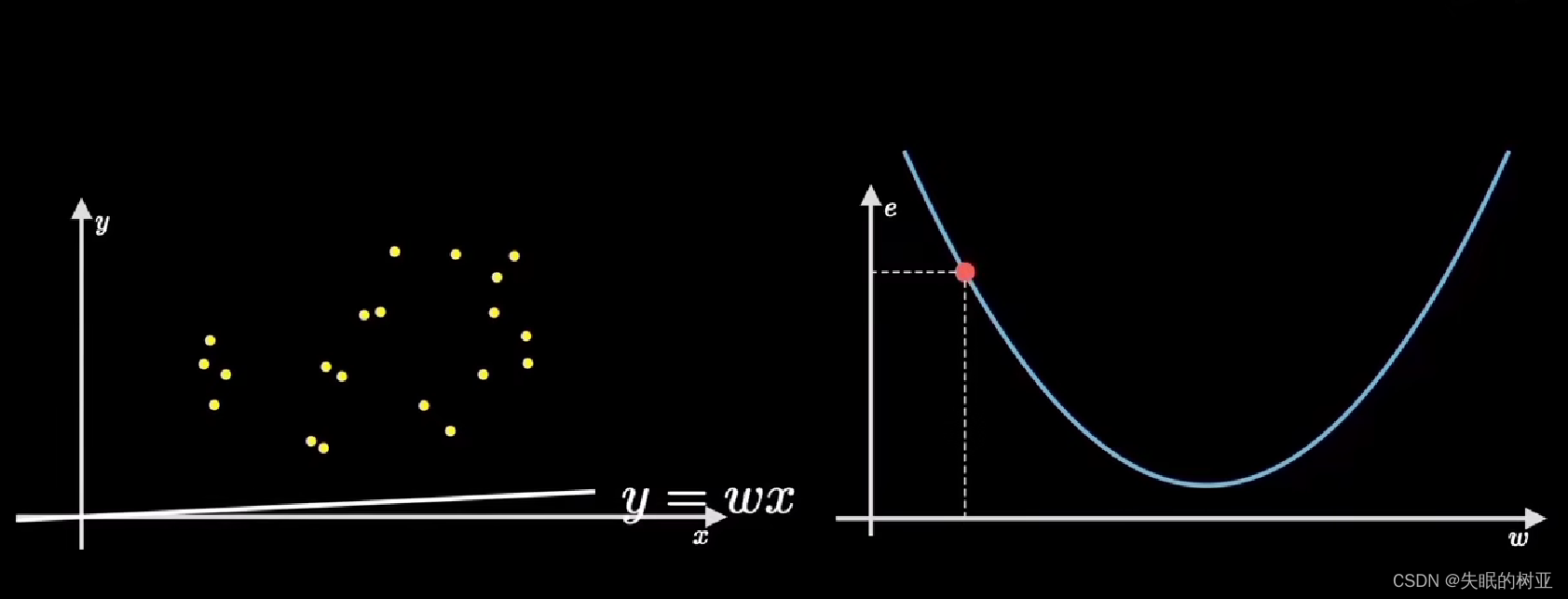
左边的直线绕原点旋转,对应到右边图像上就是取值点(红色)在抛物线上运动,
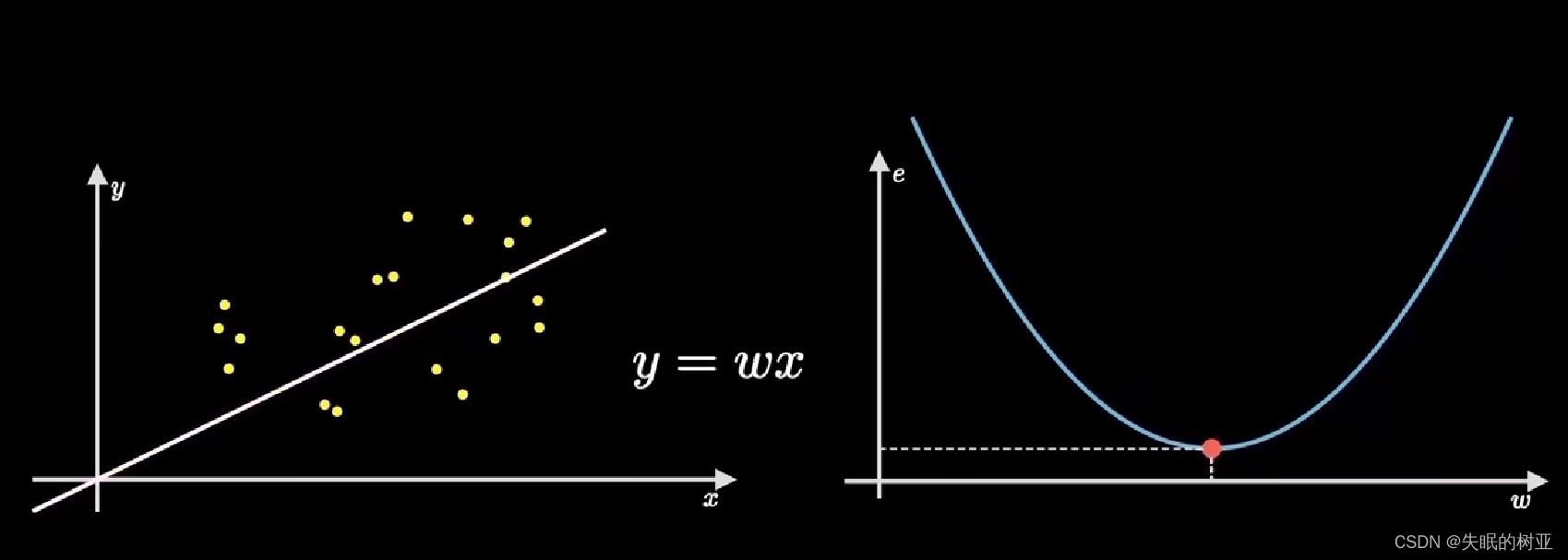
左边找到正确的w的值的时候,对应右边图像上取值点应该到最底部,即梯度为0的点
左边是预测函数,右边是代价函数
通过定义预测函数,根据误差公式,推导代价函数,可以成功地将样本点的拟合过程映射到一个函数图像上,
1.3 明确搜索方向:梯度下降
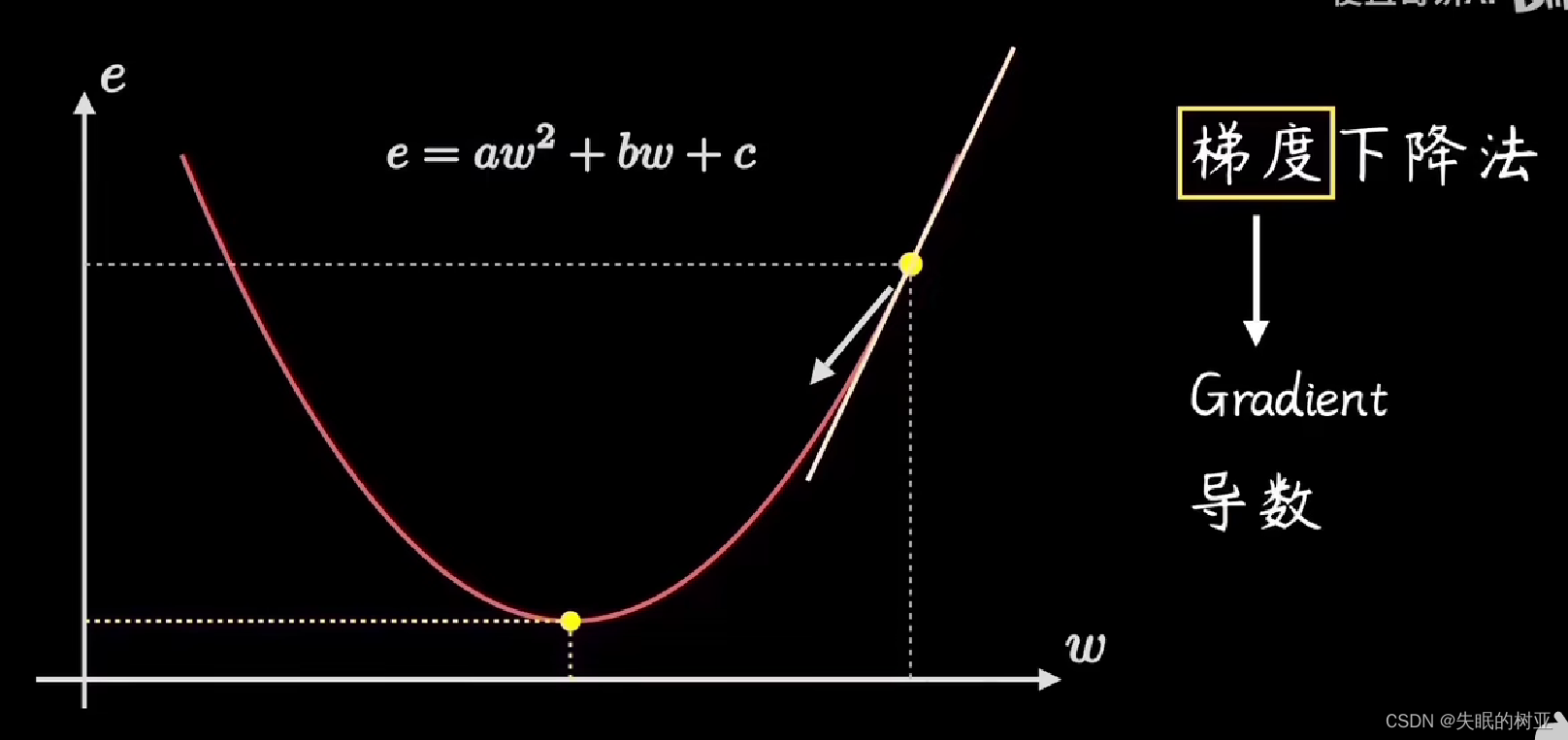
目标是找到代价函数的最低点,
从当前点的位置,每一步都选择“最陡峭”的方向走,这就是前进的方向 沿着这个方向走,就能最快到达最低点
“陡峭程度”就是梯度,是代价函数的导数,抛物线的曲线斜率
(补充:机器学习、深度学习中很多模型是非常复杂的,不能对整个函数求导,只能在一个函数的一个点上求导)
1.4 迈多大步子:学习率
步子太小,loss值会一直在最低点处震荡,难以收敛
直接使用斜率值做步长,步子太大,取值会左右横跳,loss难以收敛
正确的做法:给斜率值乘上一个很小的数值,也就是乘上学习率α,
调整权重参数w的公式是:

1.5 不达目的不罢休:循环迭代
1-4步如下图:

第5步就是重复3、4步,直到找到最低点
整个流程就是梯度下降算法
实际情况没这么简单,
因为实际情况中,训练样本的分布千奇百怪,代价函数也可能千变万化,不太可能是一条简单的抛物线。
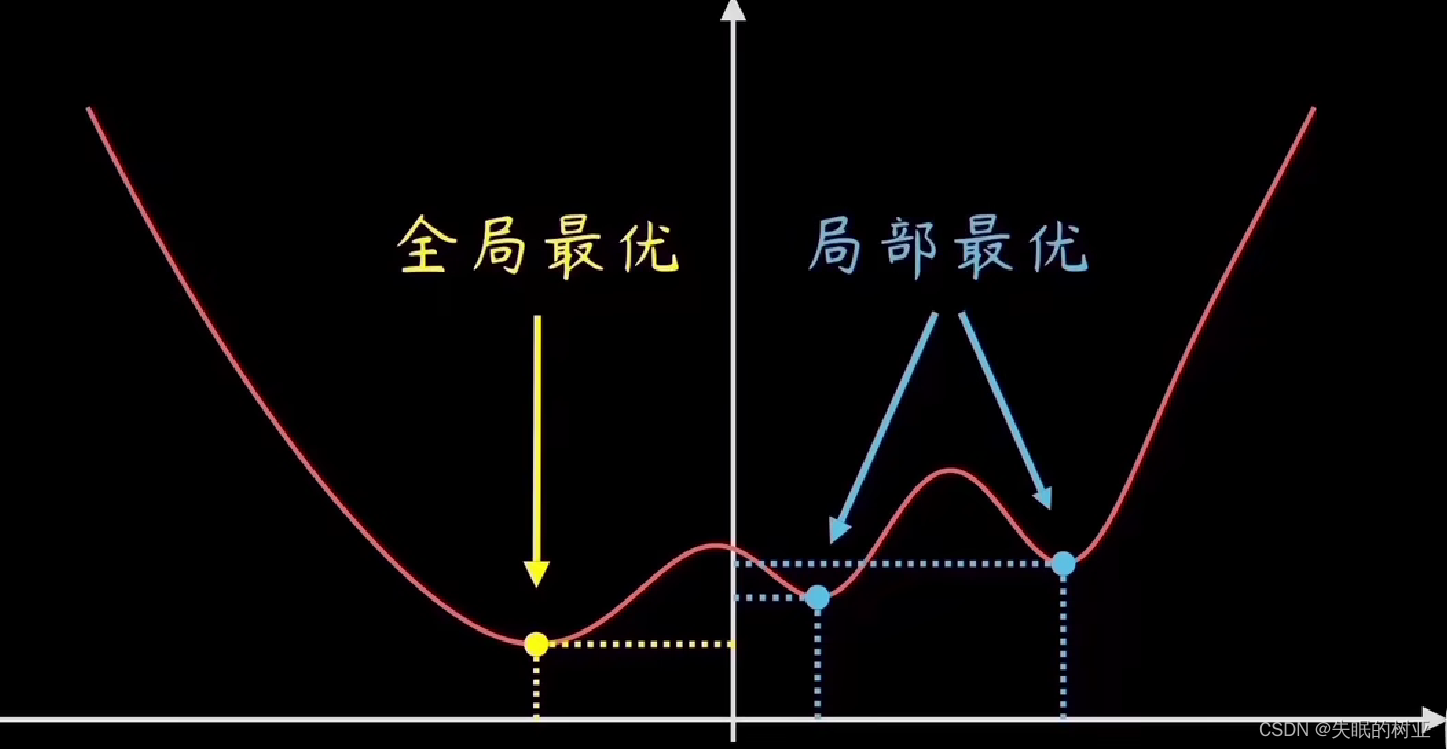
代价函数的图像是波浪线时,会有多个最低点,要找到全局最优
代价函数还有可能是高维的,十几维、百维,难以可视化;但都可以通过梯度下降法找到最低点。
2. 梯度下降算法的变体
2.1 批量梯度下降
每次用全部训练样本参与计算,梯度下降的非常平稳,
优点:保证算法的精准度,找到全局最优点
缺点:训练搜索过程慢,代价大
2.2 随机梯度下降
每次只用一个样本参与计算,
优点:提升了计算速度,
缺点:牺牲了一定的精准度
2.3 min-batch梯度下降
每次选用小批量样本进行计算
优点:比批量梯度下降快,比随机梯度下降准确
2.4 其它
其它改进的梯度下降算法:
AdaGrad 动态调节学习率,经常更新的参数学习率小一些,不常更新的参数学习率大
RMSProp 优化动态学习率
AdaDelta无需设置学习率
Adam 融合了AdaGrad和RMSProp
补充:
梯度下降是一种用来对模型的参数进行更新的优化算法,在机器学习和深度学习中,模型的目标是通过调整参数来最小化损失函数。梯度下降算法,通过计算损失函数对参数的梯度(即求导),来指导参数的更新方向。通过迭代地沿着梯度的反方向更新参数,梯度下降算法可以逐步地降低损失函数的值,从而使模型更准确地进行预测或分类。
道阻且长,行则将至!