隐藏层
该模型通过单个仿射变换将我们的输入直接映射到输出,然后进行softmax操作。 如果我们的标签通过仿射变换后确实与我们的输入数据相关,那么这种方法确实足够了。 但是,仿射变换中的线性是一个很强的假设。
线性模型可能会出错
例如,线性意味着单调假设: 任何特征的增大都会导致模型输出的增大(如果对应的权重为正), 或者导致模型输出的减小(如果对应的权重为负)。 有时这是有道理的。 例如,如果我们试图预测一个人是否会偿还贷款。 我们可以认为,在其他条件不变的情况下, 收入较高的申请人比收入较低的申请人更有可能偿还贷款。 但是,虽然收入与还款概率存在单调性,但它们不是线性相关的。 收入从0增加到5万,可能比从100万增加到105万带来更大的还款可能性。 处理这一问题的一种方法是对我们的数据进行预处理, 使线性变得更合理,如使用收入的对数作为我们的特征。
然而我们可以很容易找出违反单调性的例子。 例如,我们想要根据体温预测死亡率。 对体温高于37摄氏度的人来说,温度越高风险越大。 然而,对体温低于37摄氏度的人来说,温度越高风险就越低。 在这种情况下,我们也可以通过一些巧妙的预处理来解决问题。 例如,我们可以使用与37摄氏度的距离作为特征。
但是,如何对猫和狗的图像进行分类呢? 增加位置\((13, 17)\)处像素的强度是否总是增加(或降低)图像描绘狗的似然? 对线性模型的依赖对应于一个隐含的假设, 即区分猫和狗的唯一要求是评估单个像素的强度。 在一个倒置图像后依然保留类别的世界里,这种方法注定会失败。
与我们前面的例子相比,这里的线性很荒谬, 而且我们难以通过简单的预处理来解决这个问题。 这是因为任何像素的重要性都以复杂的方式取决于该像素的上下文(周围像素的值)。 我们的数据可能会有一种表示,这种表示会考虑到我们在特征之间的相关交互作用。 在此表示的基础上建立一个线性模型可能会是合适的, 但我们不知道如何手动计算这么一种表示。 对于深度神经网络,我们使用观测数据来联合学习隐藏层表示和应用于该表示的线性预测器。
在网络中加入隐藏层
我们可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。 要做到这一点,最简单的方法是将许多全连接层堆叠在一起。 每一层都输出到上面的层,直到生成最后的输出。 我们可以把前\(L-1\)层看作表示,把最后一层看作线性预测器。 这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。
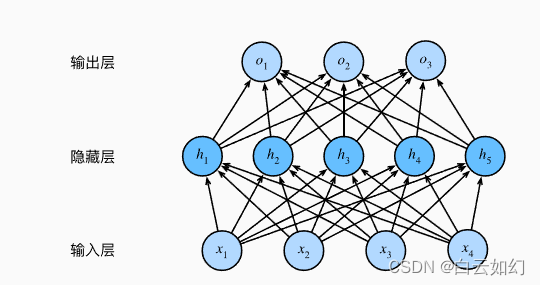
一个单隐藏层的多层感知机,具有5个隐藏单元
这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。 输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算。 因此,这个多层感知机中的层数为2。 注意,这两个层都是全连接的。 每个输入都会影响隐藏层中的每个神经元, 而隐藏层中的每个神经元又会影响输出层中的每个神经元。






![[架构之路-250/创业之路-81]:目标系统 - 纵向分层 - 企业信息化的呈现形态:常见企业信息化软件系统 - 企业内的数据与数据库](https://img-blog.csdnimg.cn/2eff2a6b8ce844f8babd97e7a77785f2.png)