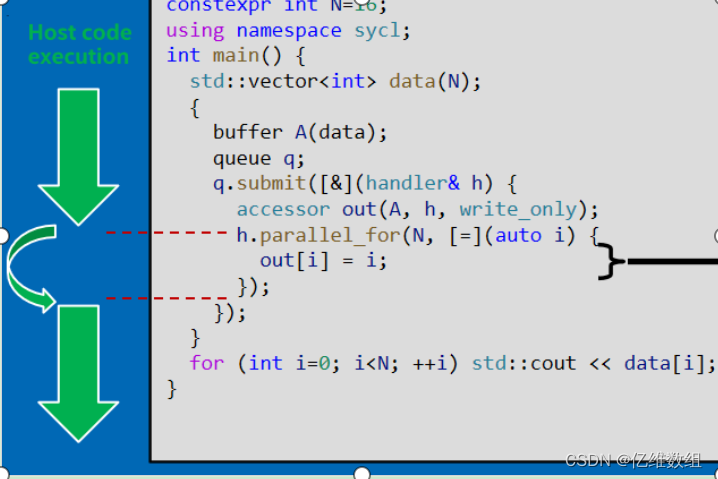
关于ViT的分析和教程,网上又虚又空的东西比较多,本文通过一个实例,将ViT全解析。
包括三部分内容,网络构建;orchview.draw_graph 将网络每一层的结构与输入输出可视化;数据预处理。附完整代码
网络构建
创建一个model.py,其中实现ViT网络构建
import torch.nn as nn
import torch
import torch.optim as optim
import torch.nn.functional as F
import lightning as Lclass AttentionBlock(nn.Module):def __init__(self, embed_dim, hidden_dim, num_heads, dropout=0.0):"""Inputs:embed_dim - Dimensionality of input and attention feature vectorshidden_dim - Dimensionality of hidden layer in feed-forward network(usually 2-4x larger than embed_dim)num_heads - Number of heads to use in the Multi-Head Attention blockdropout - Amount of dropout to apply in the feed-forward network"""super().__init__()self.layer_norm_1 = nn.LayerNorm(embed_dim)self.attn = nn.MultiheadAttention(embed_dim, num_heads)self.layer_norm_2 = nn.LayerNorm(embed_dim)self.linear = nn.Sequential(nn.Linear(embed_dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, embed_dim),nn.Dropout(dropout),)def forward(self, x):inp_x = self.layer_norm_1(x)x = x + self.attn(inp_x, inp_x, inp_x)[0]x = x + self.linear(self.layer_norm_2(x))return xclass VisionTransformer(nn.Module):def __init__(self,embed_dim,hidden_dim,num_channels,num_heads,num_layers,num_classes,patch_size,num_patches,dropout=0.0,):"""Inputs:embed_dim - Dimensionality of the input feature vectors to the Transformerhidden_dim - Dimensionality of the hidden layer in the feed-forward networkswithin the Transformernum_channels - Number of channels of the input (3 for RGB)num_heads - Number of heads to use in the Multi-Head Attention blocknum_layers - Number of layers to use in the Transformernum_classes - Number of classes to predictpatch_size - Number of pixels that the patches have per dimensionnum_patches - Maximum number of patches an image can havedropout - Amount of dropout to apply in the feed-forward network andon the input encoding"""super().__init__()self.patch_size = patch_size# Layers/Networksself.input_layer = nn.Linear(num_channels * (patch_size**2), embed_dim)self.transformer = nn.Sequential(*(AttentionBlock(embed_dim, hidden_dim, num_heads, dropout=dropout) for _ in range(num_layers)))self.mlp_head = nn.Sequential(nn.LayerNorm(embed_dim), nn.Linear(embed_dim, num_classes))self.dropout = nn.Dropout(dropout)# Parameters/Embeddingsself.cls_token = nn.Parameter(torch.randn(1, 1, embed_dim))self.pos_embedding = nn.Parameter(torch.randn(1, 1 + num_patches, embed_dim))def img_to_patch(self, x, patch_size, flatten_channels=True):"""Inputs:x - Tensor representing the image of shape [B, C, H, W]patch_size - Number of pixels per dimension of the patches (integer)flatten_channels - If True, the patches will be returned in a flattened formatas a feature vector instead of a image grid."""B, C, H, W = x.shapex = x.reshape(B, C, H // patch_size, patch_size, W // patch_size, patch_size)x = x.permute(0, 2, 4, 1, 3, 5) # [B, H', W', C, p_H, p_W]x = x.flatten(1, 2) # [B, H'*W', C, p_H, p_W]if flatten_channels:x = x.flatten(2, 4) # [B, H'*W', C*p_H*p_W]return xdef forward(self, x):# Preprocess inputx = self.img_to_patch(x, self.patch_size)B, T, _ = x.shapex = self.input_layer(x)# Add CLS token and positional encodingcls_token = self.cls_token.repeat(B, 1, 1)x = torch.cat([cls_token, x], dim=1)x = x + self.pos_embedding[:, : T + 1]# Apply Transforrmerx = self.dropout(x)x = x.transpose(0, 1)x = self.transformer(x)# Perform classification predictioncls = x[0]out = self.mlp_head(cls)return outclass ViT(L.LightningModule):def __init__(self, model_kwargs, lr):super().__init__()self.save_hyperparameters()self.model = VisionTransformer(**model_kwargs)def forward(self, x):return self.model(x)def configure_optimizers(self):optimizer = optim.AdamW(self.parameters(), lr=self.hparams.lr)lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[100, 150], gamma=0.1)return [optimizer], [lr_scheduler]def _calculate_loss(self, batch, mode="train"):imgs, labels = batchpreds = self.model(imgs)loss = F.cross_entropy(preds, labels)acc = (preds.argmax(dim=-1) == labels).float().mean()self.log("%s_loss" % mode, loss)self.log("%s_acc" % mode, acc)return lossdef training_step(self, batch, batch_idx):loss = self._calculate_loss(batch, mode="train")return lossdef validation_step(self, batch, batch_idx):self._calculate_loss(batch, mode="val")def test_step(self, batch, batch_idx):self._calculate_loss(batch, mode="test")
在其他文件中引入model.py,实现网络搭建
from model import ViTmodel = ViT(model_kwargs={"embed_dim": 256,"hidden_dim": 512,"num_heads": 8,"num_layers": 6,"patch_size": 4,"num_channels": 3,"num_patches": 64,"num_classes": 10,"dropout": 0.2,},lr=3e-4,)也可以下载预训练的模型
# Files to download
base_url = "https://raw.githubusercontent.com/phlippe/saved_models/main/"
CHECKPOINT_PATH = os.environ.get("PATH_CHECKPOINT", "saved_models/VisionTransformers/")
pretrained_files = ["tutorial15/ViT.ckpt","tutorial15/tensorboards/ViT/events.out.tfevents.ViT","tutorial5/tensorboards/ResNet/events.out.tfevents.resnet",
]
# Create checkpoint path if it doesn't exist yet
os.makedirs(CHECKPOINT_PATH, exist_ok=True)# For each file, check whether it already exists. If not, try downloading it.
for file_name in pretrained_files:file_path = os.path.join(CHECKPOINT_PATH, file_name.split("/", 1)[1])if "/" in file_name.split("/", 1)[1]:os.makedirs(file_path.rsplit("/", 1)[0], exist_ok=True)if not os.path.isfile(file_path):file_url = base_url + file_nameprint("Downloading %s..." % file_url)try:urllib.request.urlretrieve(file_url, file_path)except HTTPError as e:print("Something went wrong. Please try to download the file from the GDrive folder, or contact the author with the full output including the following error:\n",e,)pretrained_filename = os.path.join(CHECKPOINT_PATH, "ViT.ckpt")
model = ViT.load_from_checkpoint(pretrained_filename)torchview.draw_graph 网络可视化
model_graph = draw_graph(model, input_size=(1, 3, 16, 16))
model_graph.resize_graph(scale=5.0)
model_graph.visual_graph.render(format='svg')运行这段代码,会生成一个svg格式的图片,显示网络结构和每一层的输入输出

训练数据准备
新建一个prepare_data.py
import os
import json
import torch
from PIL import Image
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transformsclass CustomDataset(Dataset):def __init__(self, image_dir, names, labels, transform=None):self.image_dir = image_dirself.names = namesself.labels = labelsself.transform = transformdef __len__(self):return len(self.labels)def __getitem__(self, idx):name_ = self.names[idx]img_name = os.path.join(self.image_dir, name_)image = Image.open(img_name)if self.transform:image = self.transform(image)label = self.labels[idx]return image, labeldef load_img_ann(ann_path):"""return [{img_name, [ (x, y, h, w, label), ... ]}]"""with open(ann_path) as fp:root = json.load(fp)img_dict = {}img_label_dict = {}for img_info in root['images']:img_id = img_info['id']img_name = img_info['file_name']img_dict[img_id] = {'name': img_name}for ann_info in root['annotations']:img_id = ann_info['image_id']img_category_id = ann_info['category_id']img_name = img_dict[img_id]['name']img_label_dict[img_id] = {'name': img_name, 'category_id': img_category_id}return img_label_dictdef get_dataloader():annota_dir = '/home/robotics/Downloads/coco_dataset/annotations/instances_val2017.json'img_dir = "/home/robotics/Downloads/coco_dataset/val2017"img_dict = load_img_ann(annota_dir)values = list(img_dict.values())img_names = []labels = []for item in values:category_id = item['category_id']labels.append(category_id)img_name = item['name']img_names.append(img_name)# 检查剔除黑白的图片img_names_rgb = []labels_rgb = []for i in range(len(img_names)):# 检查文件扩展名,确保它是图片文件(可以根据需要扩展支持的文件类型)file_path = os.path.join(img_dir, img_names[i])# 打开图片文件img = Image.open(file_path)# 获取通道数num_channels = img.modeif num_channels == "RGB" and labels[i] < 10:img_names_rgb.append(img_names[i])labels_rgb.append(labels[i])# 定义一系列图像转换操作transform = transforms.Compose([transforms.Resize((16, 16)), # 调整图像大小transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 将图像转换为张量transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化图像])# 假设 image_dir 是包含所有图像文件的文件夹路径,labels 是标签列表train_set = CustomDataset(img_dir, img_names_rgb[-500:], labels_rgb[-500:], transform=transform)val_set = CustomDataset(img_dir, img_names_rgb[-500:-100], labels_rgb[-500:-100], transform=transform)test_set = CustomDataset(img_dir, img_names_rgb[-100:], labels_rgb[-100:], transform=transform)# 创建一个 DataLoadertrain_loader = DataLoader(train_set, batch_size=32, shuffle=True, drop_last=False)val_loader = DataLoader(val_set, batch_size=32, shuffle=True, drop_last=False, num_workers=4)test_loader = DataLoader(test_set, batch_size=32, shuffle=True, drop_last=False, num_workers=4)return train_loader, val_loader, test_loaderif __name__ == "__main__":train_loader, val_loader, test_loader = get_dataloader()for batch in train_loader:print(batch)
解释一下上面的代码:
这里使用的是coco数据集的2017,可以在官网自行下载,下载下来以后,annotations包含如下内容
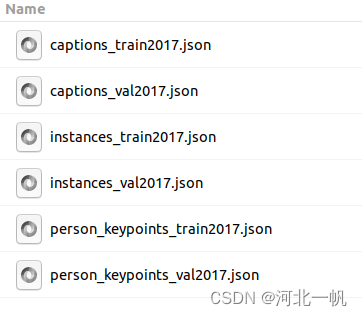
这里我们使用的是 instances_val2017.json,如果是正经做训练,应该用train2017,但是train2017文件太大了,处理起来速度很慢,本文仅为说明,不追求训练效果,所以使用val2017进行说明,instances就是用于图像识别的annotation,里面包括了每张图片的label和box,本文创建的ViT 不输出box,仅输出类别。函数
def load_img_ann(ann_path):是为了将图片的id(每张图片的唯一主键),name和category_id(属于哪一个类别,也就是label)关联起来。
# 获取通道数num_channels = img.modeif num_channels == "RGB" and labels[i] < 10:img_names_rgb.append(img_names[i])labels_rgb.append(labels[i])注意coco数据集有单通道的黑白图片,要剔除,因为本文的ViT比较简单,输出只能10个类别,所以预处理图片的时候,只选择10个类别。
定义操作变换
# 定义一系列图像转换操作transform = transforms.Compose([transforms.Resize((16, 16)), # 调整图像大小transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 将图像转换为张量transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化图像])创建一个自己的Dataset类,继承自 torch.utils.data.Dataset
class CustomDataset(Dataset):def __init__(self, image_dir, names, labels, transform=None):self.image_dir = image_dirself.names = namesself.labels = labelsself.transform = transformdef __len__(self):return len(self.labels)def __getitem__(self, idx):name_ = self.names[idx]img_name = os.path.join(self.image_dir, name_)image = Image.open(img_name)if self.transform:image = self.transform(image)label = self.labels[idx]return image, label先创建Dataset,再创建dataloader,从Dataset取minibatch。
# 假设 image_dir 是包含所有图像文件的文件夹路径,labels 是标签列表train_set = CustomDataset(img_dir, img_names_rgb[-500:], labels_rgb[-500:], transform=transform)val_set = CustomDataset(img_dir, img_names_rgb[-500:-100], labels_rgb[-500:-100], transform=transform)test_set = CustomDataset(img_dir, img_names_rgb[-100:], labels_rgb[-100:], transform=transform)# 创建一个 DataLoadertrain_loader = DataLoader(train_set, batch_size=32, shuffle=True, drop_last=False)val_loader = DataLoader(val_set, batch_size=32, shuffle=True, drop_last=False, num_workers=4)test_loader = DataLoader(test_set, batch_size=32, shuffle=True, drop_last=False, num_workers=4)以上,数据准备工作完成,对模型进行训练
trainer = L.Trainer(default_root_dir=os.path.join(CHECKPOINT_PATH, "ViT"),accelerator="auto",devices=1,max_epochs=180,callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc"),LearningRateMonitor("epoch"),],)trainer.logger._log_graph = True # If True, we plot the computation graph in tensorboardtrainer.logger._default_hp_metric = None # Optional logging argument that we don't needtrainer.fit(model, train_loader, val_loader)# Load best checkpoint after trainingmodel = ViT.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)# Test best model on validation and test setval_result = trainer.test(model, dataloaders=val_loader, verbose=False)test_result = trainer.test(model, dataloaders=test_loader, verbose=False)result = {"test": test_result[0]["test_acc"], "val": val_result[0]["test_acc"]}完整代码:
一共包括三个文件:model.py 搭建网络的功能, prepare_data.py 数据预处理工作, main.py 网络训练
model.py内容:
import torch.nn as nn
import torch
import torch.optim as optim
import torch.nn.functional as F
import lightning as Lclass AttentionBlock(nn.Module):def __init__(self, embed_dim, hidden_dim, num_heads, dropout=0.0):"""Inputs:embed_dim - Dimensionality of input and attention feature vectorshidden_dim - Dimensionality of hidden layer in feed-forward network(usually 2-4x larger than embed_dim)num_heads - Number of heads to use in the Multi-Head Attention blockdropout - Amount of dropout to apply in the feed-forward network"""super().__init__()self.layer_norm_1 = nn.LayerNorm(embed_dim)self.attn = nn.MultiheadAttention(embed_dim, num_heads)self.layer_norm_2 = nn.LayerNorm(embed_dim)self.linear = nn.Sequential(nn.Linear(embed_dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, embed_dim),nn.Dropout(dropout),)def forward(self, x):inp_x = self.layer_norm_1(x)x = x + self.attn(inp_x, inp_x, inp_x)[0]x = x + self.linear(self.layer_norm_2(x))return xclass VisionTransformer(nn.Module):def __init__(self,embed_dim,hidden_dim,num_channels,num_heads,num_layers,num_classes,patch_size,num_patches,dropout=0.0,):"""Inputs:embed_dim - Dimensionality of the input feature vectors to the Transformerhidden_dim - Dimensionality of the hidden layer in the feed-forward networkswithin the Transformernum_channels - Number of channels of the input (3 for RGB)num_heads - Number of heads to use in the Multi-Head Attention blocknum_layers - Number of layers to use in the Transformernum_classes - Number of classes to predictpatch_size - Number of pixels that the patches have per dimensionnum_patches - Maximum number of patches an image can havedropout - Amount of dropout to apply in the feed-forward network andon the input encoding"""super().__init__()self.patch_size = patch_size# Layers/Networksself.input_layer = nn.Linear(num_channels * (patch_size**2), embed_dim)self.transformer = nn.Sequential(*(AttentionBlock(embed_dim, hidden_dim, num_heads, dropout=dropout) for _ in range(num_layers)))self.mlp_head = nn.Sequential(nn.LayerNorm(embed_dim), nn.Linear(embed_dim, num_classes))self.dropout = nn.Dropout(dropout)# Parameters/Embeddingsself.cls_token = nn.Parameter(torch.randn(1, 1, embed_dim))self.pos_embedding = nn.Parameter(torch.randn(1, 1 + num_patches, embed_dim))def img_to_patch(self, x, patch_size, flatten_channels=True):"""Inputs:x - Tensor representing the image of shape [B, C, H, W]patch_size - Number of pixels per dimension of the patches (integer)flatten_channels - If True, the patches will be returned in a flattened formatas a feature vector instead of a image grid."""B, C, H, W = x.shapex = x.reshape(B, C, H // patch_size, patch_size, W // patch_size, patch_size)x = x.permute(0, 2, 4, 1, 3, 5) # [B, H', W', C, p_H, p_W]x = x.flatten(1, 2) # [B, H'*W', C, p_H, p_W]if flatten_channels:x = x.flatten(2, 4) # [B, H'*W', C*p_H*p_W]return xdef forward(self, x):# Preprocess inputx = self.img_to_patch(x, self.patch_size)B, T, _ = x.shapex = self.input_layer(x)# Add CLS token and positional encodingcls_token = self.cls_token.repeat(B, 1, 1)x = torch.cat([cls_token, x], dim=1)x = x + self.pos_embedding[:, : T + 1]# Apply Transforrmerx = self.dropout(x)x = x.transpose(0, 1)x = self.transformer(x)# Perform classification predictioncls = x[0]out = self.mlp_head(cls)return outclass ViT(L.LightningModule):def __init__(self, model_kwargs, lr):super().__init__()self.save_hyperparameters()self.model = VisionTransformer(**model_kwargs)def forward(self, x):return self.model(x)def configure_optimizers(self):optimizer = optim.AdamW(self.parameters(), lr=self.hparams.lr)lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[100, 150], gamma=0.1)return [optimizer], [lr_scheduler]def _calculate_loss(self, batch, mode="train"):imgs, labels = batchpreds = self.model(imgs)loss = F.cross_entropy(preds, labels)acc = (preds.argmax(dim=-1) == labels).float().mean()self.log("%s_loss" % mode, loss)self.log("%s_acc" % mode, acc)return lossdef training_step(self, batch, batch_idx):loss = self._calculate_loss(batch, mode="train")return lossdef validation_step(self, batch, batch_idx):self._calculate_loss(batch, mode="val")def test_step(self, batch, batch_idx):self._calculate_loss(batch, mode="test")
prepare_data.py内容:
import os
import json
import torch
from PIL import Image
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transformsclass CustomDataset(Dataset):def __init__(self, image_dir, names, labels, transform=None):self.image_dir = image_dirself.names = namesself.labels = labelsself.transform = transformdef __len__(self):return len(self.labels)def __getitem__(self, idx):name_ = self.names[idx]img_name = os.path.join(self.image_dir, name_)image = Image.open(img_name)if self.transform:image = self.transform(image)label = self.labels[idx]return image, labeldef load_img_ann(ann_path):"""return [{img_name, [ (x, y, h, w, label), ... ]}]"""with open(ann_path) as fp:root = json.load(fp)img_dict = {}img_label_dict = {}for img_info in root['images']:img_id = img_info['id']img_name = img_info['file_name']img_dict[img_id] = {'name': img_name}for ann_info in root['annotations']:img_id = ann_info['image_id']img_category_id = ann_info['category_id']img_name = img_dict[img_id]['name']img_label_dict[img_id] = {'name': img_name, 'category_id': img_category_id}return img_label_dictdef get_dataloader():annota_dir = '/home/robotics/Downloads/coco_dataset/annotations/instances_val2017.json'img_dir = "/home/robotics/Downloads/coco_dataset/val2017"img_dict = load_img_ann(annota_dir)values = list(img_dict.values())img_names = []labels = []for item in values:category_id = item['category_id']labels.append(category_id)img_name = item['name']img_names.append(img_name)# 检查剔除黑白的图片img_names_rgb = []labels_rgb = []for i in range(len(img_names)):# 检查文件扩展名,确保它是图片文件(可以根据需要扩展支持的文件类型)file_path = os.path.join(img_dir, img_names[i])# 打开图片文件img = Image.open(file_path)# 获取通道数num_channels = img.modeif num_channels == "RGB" and labels[i] < 10:img_names_rgb.append(img_names[i])labels_rgb.append(labels[i])# 定义一系列图像转换操作transform = transforms.Compose([transforms.Resize((16, 16)), # 调整图像大小transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 将图像转换为张量transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化图像])# 假设 image_dir 是包含所有图像文件的文件夹路径,labels 是标签列表train_set = CustomDataset(img_dir, img_names_rgb[-500:], labels_rgb[-500:], transform=transform)val_set = CustomDataset(img_dir, img_names_rgb[-500:-100], labels_rgb[-500:-100], transform=transform)test_set = CustomDataset(img_dir, img_names_rgb[-100:], labels_rgb[-100:], transform=transform)# 创建一个 DataLoadertrain_loader = DataLoader(train_set, batch_size=32, shuffle=True, drop_last=False)val_loader = DataLoader(val_set, batch_size=32, shuffle=True, drop_last=False, num_workers=4)test_loader = DataLoader(test_set, batch_size=32, shuffle=True, drop_last=False, num_workers=4)return train_loader, val_loader, test_loaderif __name__ == "__main__":train_loader, val_loader, test_loader = get_dataloader()for batch in train_loader:print(batch)
main.py内容:
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = '1' # 下面老是报错 shape 不一致
import urllib.request
from urllib.error import HTTPError
import lightning as L
from model import ViT
from torchview import draw_graph
from lightning.pytorch.callbacks import LearningRateMonitor, ModelCheckpointfrom prepare_data import get_dataloader# 加载模型
# Files to download
base_url = "https://raw.githubusercontent.com/phlippe/saved_models/main/"
CHECKPOINT_PATH = os.environ.get("PATH_CHECKPOINT", "saved_models/VisionTransformers/")
pretrained_files = ["tutorial15/ViT.ckpt","tutorial15/tensorboards/ViT/events.out.tfevents.ViT","tutorial5/tensorboards/ResNet/events.out.tfevents.resnet",
]
# Create checkpoint path if it doesn't exist yet
os.makedirs(CHECKPOINT_PATH, exist_ok=True)# For each file, check whether it already exists. If not, try downloading it.
for file_name in pretrained_files:file_path = os.path.join(CHECKPOINT_PATH, file_name.split("/", 1)[1])if "/" in file_name.split("/", 1)[1]:os.makedirs(file_path.rsplit("/", 1)[0], exist_ok=True)if not os.path.isfile(file_path):file_url = base_url + file_nameprint("Downloading %s..." % file_url)try:urllib.request.urlretrieve(file_url, file_path)except HTTPError as e:print("Something went wrong. Please try to download the file from the GDrive folder, or contact the author with the full output including the following error:\n",e,)pretrained_filename = os.path.join(CHECKPOINT_PATH, "ViT.ckpt")
needTrain = False
if not os.path.isfile(pretrained_filename):print("Found pretrained model at %s, loading..." % pretrained_filename)# Automatically loads the model with the saved hyperparametersmodel = ViT.load_from_checkpoint(pretrained_filename)
else:L.seed_everything(42) # To be reproducablemodel = ViT(model_kwargs={"embed_dim": 256,"hidden_dim": 512,"num_heads": 8,"num_layers": 6,"patch_size": 4,"num_channels": 3,"num_patches": 64,"num_classes": 10,"dropout": 0.2,},lr=3e-4,)needTrain = True# 网络结构可视化
model_graph = draw_graph(model, input_size=(1, 3, 16, 16))
model_graph.resize_graph(scale=5.0)
model_graph.visual_graph.render(format='svg')# 准备训练数据
train_loader, val_loader, test_loader = get_dataloader()if needTrain:trainer = L.Trainer(default_root_dir=os.path.join(CHECKPOINT_PATH, "ViT"),accelerator="auto",devices=1,max_epochs=180,callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc"),LearningRateMonitor("epoch"),],)trainer.logger._log_graph = True # If True, we plot the computation graph in tensorboardtrainer.logger._default_hp_metric = None # Optional logging argument that we don't needtrainer.fit(model, train_loader, val_loader)# Load best checkpoint after trainingmodel = ViT.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)# Test best model on validation and test setval_result = trainer.test(model, dataloaders=val_loader, verbose=False)test_result = trainer.test(model, dataloaders=test_loader, verbose=False)result = {"test": test_result[0]["test_acc"], "val": val_result[0]["test_acc"]}