oneAPI简介
Intel oneAPI是Intel提供的统一编程模型和软件开发框架。 它旨在简化可充分利用英特尔各种硬件架构(包括 CPU、GPU 和 FPGA)的应用程序的开发
oneAPI一个重要的特性是开放性,支持多种类型的架构和不同的硬件供应商,是一种统一的编程模型。使得开发人员拥有可以选择最佳硬件来做加速计算的自由,不用锁定某些厂商专有的硬件即可提高软件的开发生产力,并且获得与硬件加速设备相匹配的性能
随着大数据到来,仅仅依靠CPU平台的计算是不够的,使得不同种类的计算加速设备出现,比如:GPU、FPGA......但这些加速设备的引用也给应用程序的开发带来一个问题,如果想要从某个特定的计算加速设备切换到另一个厂商的另外一个加速设备,会带来非常大的工作量和开销,oneAPI这种统一变成模型的提出就是为了解决这个问题,它希望有一种统一的编程语言,有一种统一接口的库函数使得应用程序在不同硬件加速设备迁移的时候,所付出的代价可以达到最小

上图描述了异构计算软件生态现状,可以看出没有一个在总体上占优势的厂商,而是处于一种分散的状态。比如在AI的模型训练主要占主导地位的还是英伟达的一些库,高性能计算领域主导的还是英伟达的GPU
什么是异构计算?首先计算单元可以分成:通用计算单元(CPU),专用计算单元(GPU)等,简单说就是由一个或若干个通用计算单元加一个或若干个专用计算单元构建的系统就是异构计算系统,由两者协同起来共同执行通用计算任务就是异构计算,异构计算的目的一般是加速和节能,在过去GPU只能执行图形任务,现在GPU已经具备了通用计算的能力,和CPU协同工作就组成了一个异构计算系统。有了硬件的实现,同样需要软件的支持,目前比较流行的编程语言是C++AMP/OPENCL/CUDA

oneAPI有两种编程模型,第一种是直接编程(Direct Programming)有统一的编程语言SYCL,它是基于C++标准的编程语言。另一种是基于库的编程(API-Based Programming)。对于Level 0,这个跟硬件加速设备打交道的层上,如果硬件厂商实现了这层接口,那么它的设备就可以被oneAPI上层的框架使用
SYCL是由Khronos Group提供的一个开放的标准,主要是为了针对异构计算领域。标准C++是主机端适用的一个标准,针对异构计算领域,C++在不同种类的硬件加速设备的设备端的部分是没有提及的,SYCL就弥补了C++在异构计算领域硬件加速设备的缺失。SYCL是标准的C++,没有针对不同硬件有语法上的扩展。下图是SYCL和CUDA源代码在不同硬件设备上的比较
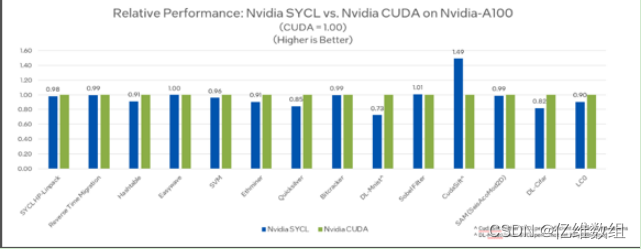
SYCLomatic是oneAPI产品里面的CUDA开源的迁移工具,所有源代码在github上:github.com/oneapi-src/SYCLomatic。
有的部分在CUDA源代码里面有,但是在迁移后的SYCL源代码里面没有,则会以注释的形式标记出来,程序员需要人工修改
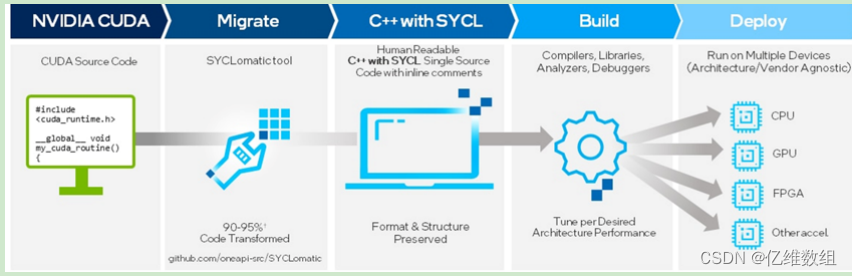
通过上面的介绍,我们就可以知道,在不同的计算领域里面,可以使用不同的Intel oneAPI开发包,可以使得程序运行在不同种类的计算加速设备上面,比如在高性能计算、人工智能、嵌入式等领域都有oneAPI相应的工具包

oneAPI工具包简介
Intel® oneAPI Base Toolkit是基础工具套件,直接编程包括Intel® oneAPI DPC++/C++ Compiler,Intel® oneAPI DPC++ Compatibility Tool,Intel® Distribution for Python,Intel® FPGA Add-on for oneAPI Base Toolkit,API编程包括Intel® oneAPI DPC++ Library oneDPL等库,分析调试工具包括Intel® VTune Profiler,Intel® Advisor等
除了基础工具套件之外,还有其它工具包,比如高性能计算、物联网、渲染、人工智能等领域,可以在官网查看:
https://www.intel.com/content/www/us/en/developer/tools/oneapi/toolkits.html
SYCL编程简介
CPU端也称Host端,异构平台上面的其它硬件加速器称为Device端,SYCL应用程序分为在主机端执行的部分和在设备端执行的部分,主机端就在CPU运行,设备端是要由主机端的CPU递交给某一个设备,递交的过程是通过Command Queue模块去做
一个程序分为Host code和Device code,其中后者又总被称为Kernel
一个程序分为很多scope,比如Application scope,Command group scope,Device scope,不是所有的C++的内容适用于Device scope
buffer对象包含了服务于不同种类计算设备的每个数据临时存储的一块空间
queue对象很重要的目的就是递交计算任务
buffer对象可以通过调用get_access,使buffer的数据可以传到针对这个硬件设备的数据区域上
handler对象调用parallel_for去执行设备端的计算任务,通常与lambda函数搭配使用
SYCL有两个内存模式
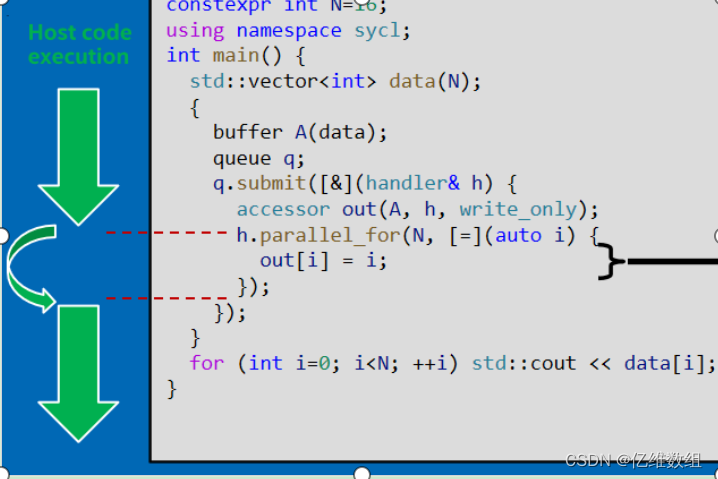
一是Buffer Memory Model(BMM)内存模式,是使用buffer对象的一种方式,如下图

使用malloc_shared函数创建指针变量,可以使用另一种Unified Shared Memory(USM)内存模式,即CPU,GPU共享一片内存区域,在这种模型之下,parallel_for需要通过queue对象调用,并在最后使用wait函数,是因为,虽然CPU和GPU共享内存,但在一个时间段内,只能有一个访问
演示一个完整的SYCL程序(USM内存模式):
#include<CL/sycl.hpp>
constexpr int N=16;
using namespace sycl;
int main(){
queue q;
int *data=malloc_shared<int>(N,q);
q.parallel_for(N,[=](auto i){
data[i]=i;
}).wait();
for(int i=0;i<N;i++)std::cout<<data[i]<<’\n’;
free(data,q);
return 0;
}device类描述硬件加速器,一个重要的接口是可以获取设备相关信息,可以通过这个设备信息创建设备选择器从而更好地选择设备,此外,queue的创建不需要参数,所以如果想要知道queue对应于异构计算平台的哪一个设备,就只能使用device类
device_selector包含default_selector,cpu_selector,gpu_selector,如果使用default_selector去创建queue,那么设备的选择就全部交给了SYCL内部的策略,比如:
default_selector selector;
queue q(selector);
std::cout<<”Device: “<<q.get_device().get_info<info::device::name>()<<std::endl;queue对象用于CPU和GPU信息交换
举一个handle对象调用parallel_for的例子:
h.parallel_for(range<1>(1024),[=](id<1>idx){
//PASS
});range对象用于描述设备端计算的范围,id对象用于描述kernel在并行空间中的某个实例,item对象和id的区别是在计算中可以显示更多细节
SYCL执行过程中,主机端在递交给设备端计算任务之后,可以计算去执行下面的事情
参考资料
1.http://t.csdnimg.cn/PNw2x
2.其它大部分内容是网上碎片化查找收集后进行的自我总结,部分图片侵权删







![[论文笔记]RetroMAE](https://img-blog.csdnimg.cn/img_convert/7e97dd435dd42fbbbb647c5f8d92549e.png)