2021-arxiv-GPT Understands, Too

Paper: https://arxiv.org/abs/2103.10385
Code: https://github.com/THUDM/P-tuning
Prompt 简单理解
举例来讲,今天如果有这样两句评论:
1. 什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃!
2. 这破笔记本速度太慢了,卡的不要不要的。
现在我们需要根据他们描述的商品类型进行一个分类任务,
即,第一句需要被分类到「水果」类别中;第二句则需要分类到「电脑」类别中。
一种直觉的方式是将该问题建模成一个传统文本分类的任务,通过人工标注,为每一个类别设置一个id,例如:
{'电脑': 0,'水果': 1,....
}
这样一来,标注数据集就长这样:
什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃! 1
这破笔记本速度太慢了,卡的不要不要的。 0
...
这种方法是可行的,但是需要「较多的标注数据」才能取得不错的效果。
由于大多数预训练模型(如BRET)在 pretrain 的时候都使用了 [MASK] token 做 MLM 任务,而我们在真实下游任务中往往是不会使用到 [MASK] 这个 token,这就意味着今天我们在训练下游任务时需要较多的数据集去抹平上下游任务不一致的 gap。
那,如果我们没有足够多的训练数据怎么办呢?
prompt learning 的出现就是为了解决这一问题,它将 [MASK] 的 token 引入到了下游任务中,将下游任务构造成和 MLM 类似的任务。
举例来讲,我们可以将上述评论改写为:
这是一条[MASK][MASK]评论:这破笔记本速度太慢了,卡的不要不要的。
然后让模型去预测两个 [MASK] token 的真实值是什么,那模型根据上下文能推测出被掩码住的词应该为「电脑」。
由于下游任务中也使用了和预训练任务中同样的 MLM 任务,这样我们就可以使用更少的训练数据来进行微调了。
但,这还不是 P-tuning。
通过上面的例子我们可以观察到,构建句子最关键的部分是在于 prompt的生成,即:
「这是一条[MASK][MASK]评论:」(prompt) + 这破笔记本速度太慢了,卡的不要不要的。(content)
被括号括起来的前缀(prompt)的生成是非常重要的,不同 prompt 会极大影响模型对 [MASK] 预测的正确率。
那么这个 prompt 怎么生成呢?
我们当然可以通过人工去设计很多不同类型的前缀 prompt,我们把他们称为 prompt pattern,例如:
这是一条[MASK][MASK]评论:
下面是一条描述[MASK][MASK]的评论:
[MASK][MASK]:
...
但是人工列这种 prompt pattern 非常的麻烦,不同的数据集所需要的 prompt pattern 也不同,可复用性很低。
那么,我们能不能通过机器自己去学习 prompt pattern 呢?
这,就是 P-Tuning。
P-Tuning 架构
给定一个预训练的语言模型 M M M,一个离散输入标记序列 x 1 : n = { x 0 , x 1 , … , x n } \mathbf{x}_{1: n}=\left\{x_0, x_1, \ldots, x_n\right\} x1:n={x0,x1,…,xn}将由预训练嵌入层 e ∈ M \mathbf{e} \in \mathcal{M} e∈M映射到输入嵌入 { e ( x 0 ) , e ( x 1 ) , … , e ( x n ) } \left\{\mathbf{e}\left(x_0\right), \mathbf{e}\left(x_1\right), \ldots, \mathbf{e}\left(x_n\right)\right\} {e(x0),e(x1),…,e(xn)}。在特定场景中,在上下文 x x x 的条件下,作者使用一组目标标记 y y y 的输出嵌入进行下游处理。例如,在预训练中, x x x 指的是未屏蔽的令牌,而 y y y 指的是 [MASK] 标记;在句子分类中, x x x 指的是句子标记,而 y y y 通常指的是 [CLS]。
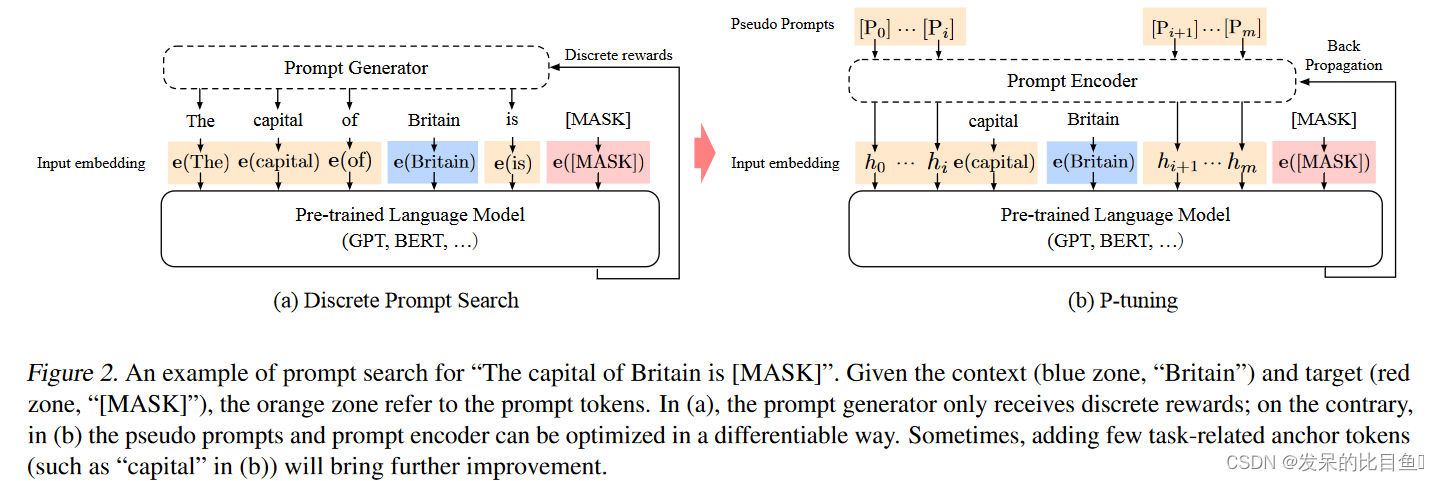
提示 p p p 的功能是将上下文 x x x、目标 y y y 和自身组织到模板 T 中。例如,在预测一个国家首都的任务 (LAMA-TREx P36) 中,模板可能是“The capital of Britain is [MASK]”。(见图2),其中“The capital of … is … .“是提示,”Britain"是上下文,”[MASK]“是目标。提示可以非常灵活,我们甚至可以将它们插入到上下文或目标中。
设 V V V 指语言模型 M M M 的词汇表, [ P i ] [P_i] [Pi] 指模板 T 中的第 i i i 个提示标记。为简单起见,给定模板 T = { [ P 0 : i ] , x , [ P i + 1 : m ] , y } T=\left\{\left[\mathrm{P}_{0: i}\right], \mathbf{x},\left[\mathrm{P}_{i+1: m}\right], \mathbf{y}\right\} T={[P0:i],x,[Pi+1:m],y},与满足 [ P i ] ∈ V \left[\mathrm{P}_i\right] \in \mathcal{V} [Pi]∈V 并将 T T T 映射为的传统离散提示相比
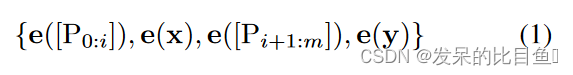
相反,P-tuning 将 [Pi] 视为伪令牌,并将模板映射到
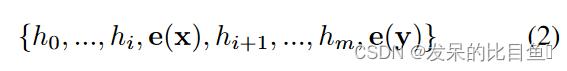
其中 h i ( 0 ≤ i < m ) h_i(0 \leq i<m) hi(0≤i<m) 是可训练的嵌入张量。能够找到超越 M M M的 V V V 可以表达的原始词汇的更好的连续提示。最后,利用下游损失函数 L L L,可以对连续提示 h i ( 0 ≤ i < m ) h_i(0 \leq i<m) hi(0≤i<m)进行差分优化
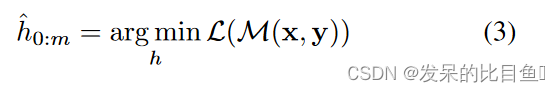
优化
1)离散性: M \mathcal{M} M的原始词嵌入 e e e在预训练后已经变得高度离散。如果用随机分布初始化 h h h,然后用随机梯度下降 (SGD) 进行优化,这已被证明只会改变小邻域中的参数,优化器很容易陷入局部最小值。
2)关联:另一个问题是,作者认为提示嵌入 h i h_i hi的值应该是相互依赖的,而不是独立的。需要一些机制来将提示嵌入相互关联。
鉴于这些挑战,在 P-tuning中,建议使用提示编码器将 h i h_i hi 建模为序列,该序列由一个非常精简的神经网络组成,可以解决离散性和关联问题。作者选择双向长短期记忆网络 (LSTM),并使用 ReLU 激活的两层多层感知器 (MLP) 来编码离散性。从形式上讲,将 h i ′ h_i^{\prime} hi′嵌入到语言模型 M \mathcal{M} M中的实际输入源自
h i = MLP ( [ h i → : h i ← ] ) = MLP ( [ LSTM ( h 0 : i ) : LSTM ( h i : m ) ] ) \begin{aligned} h_i & =\operatorname{MLP}\left(\left[\overrightarrow{h_i}: \overleftarrow{h_i}\right]\right) \\ & =\operatorname{MLP}\left(\left[\operatorname{LSTM}\left(h_{0: i}\right): \operatorname{LSTM}\left(h_{i: m}\right)\right]\right) \end{aligned} hi=MLP([hi:hi])=MLP([LSTM(h0:i):LSTM(hi:m)])
尽管 LSTM 头的使用确实为连续提示的训练增加了一些参数,但 LSTM 头比预训练模型小几个数量级。此外,在推理中,只需要输出嵌入 h h h,就可以丢弃 LSTM 头。
参考
https://zhuanlan.zhihu.com/p/583022692