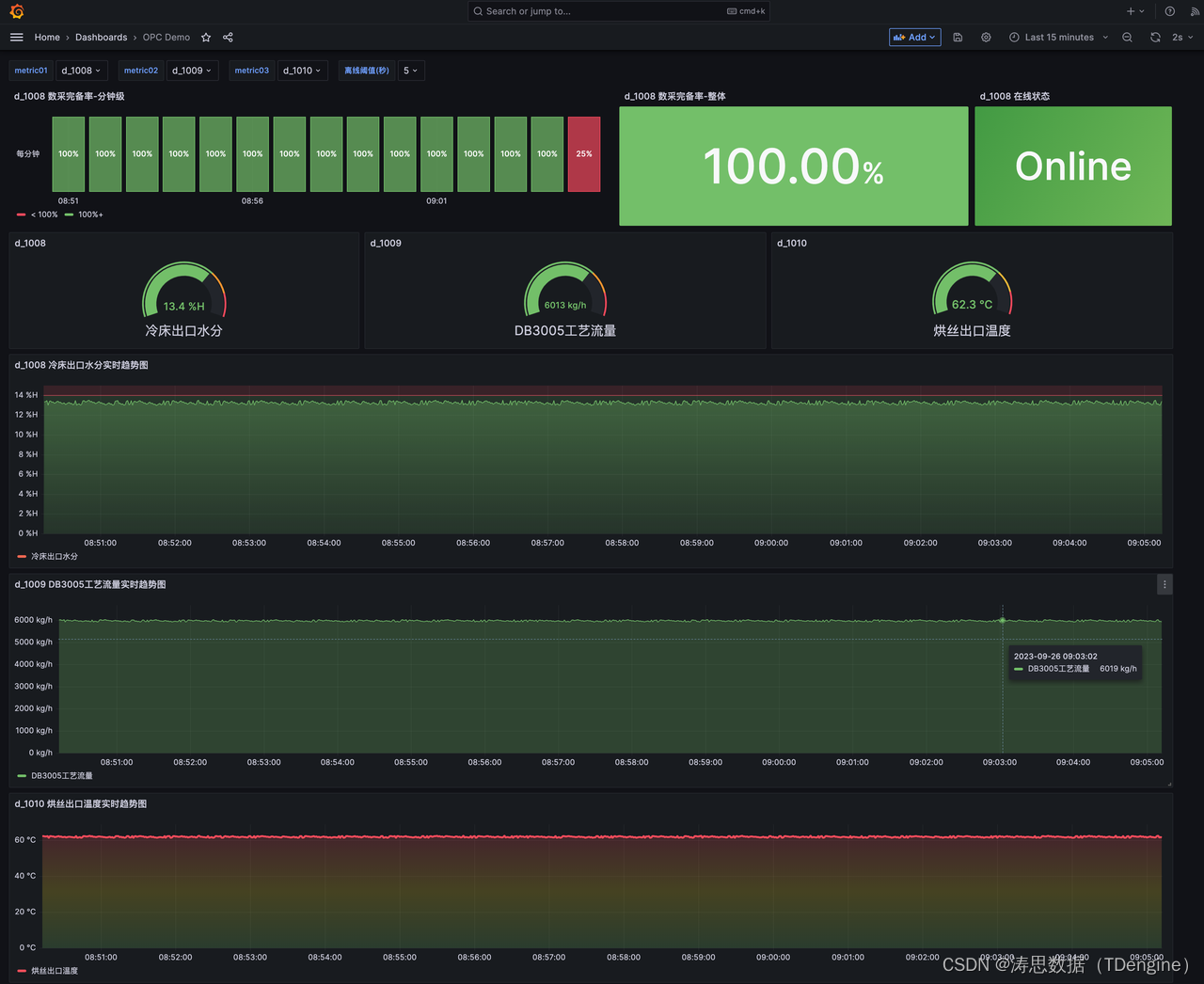
原文地址:DriveGPT - Lei Mao's Log Book
自动驾驶汽车的核心软件组件是感知、规划和控制。规划是指在给定场景或一系列场景的情况下为自动驾驶汽车制定行动计划的过程,以实现安全和理想的自动驾驶。
用于规划的场景是从感知软件组件获得的。计划的行动将由控制软件组件执行。
规划也可以进一步分为三类,任务规划、行为规划和地方规划。任务规划是旅程的最高级别规划。它决定了到达目的地的路线。例如,我们通常用于导航的谷歌地图就属于这一类。行为规划是指在给定实时动态场景的情况下,决定采取何种高级行动的中级规划。它决定车辆是否应该变道、加速、减速、转弯、停车等。局部规划是以平稳、安全的方式实现行为规划的低级规划。行为规划和地方规划之间的界限有时是模糊的。
DriveGPT专注于行为规划和本地规划。
Drive Language
Drive Language是一种用于描述驾驶实例的语言。驾驶实例可以使用驾驶语言来描述,即一个或多个驾驶语句。Drive语句由Drive标记组成。
Drive Language Tokens
因为坐标或实值可以被量化,所以感知信号表示,例如对象坐标、对象大小、车道坐标、ego-car轨迹坐标,可以被量化。根据如何量化感知信号,我们必须创建的令牌数量可能会有所不同。如果我们想有更高的令牌化分辨率,我们需要创建的令牌数量就会增加。例如,如果我们想使用一个令牌来描述2D对象的坐标,那么在2D BEV空间中所需的令牌数量将是很多。然而,如果我们可以使用两个标记来分别描述2D对象的x和y坐标,则所需的标记数量可以显著减少。
一旦一个场景中的感知信号被标记化,它们就可以用于描述场景。例如,在天真的场景中,在一个场景中,如果在特定大小x1、x2和x3的位置有三辆车,在位置和方向y 1、y 2、y 3、y 4有四条车道,而自我汽车的位置是z 1,则Drive语句可能只是,Token x 1、Token x 2、Token x 3、Token y 1、Token y 2、Token y 3、Token y4、Token z 1。描述场景的Drive语句序列也可用于描述场景序列和自我汽车行为。
一系列场景和自我汽车行为可能涉及人类意图或一系列人类意图,例如变道和经过邻居的汽车。这些人类意图也可以使用令牌或令牌序列来描述。根据令牌工程,人类意图令牌可以是来自人类自然语言的令牌,也可以是专门的令牌。这样,Drive语言中的一系列场景描述也可能伴随着Drive语言中人类的意图。
Drive Language Model
由于自动驾驶制造商拥有大量的人类驾驶数据,即场景序列,并且场景通常用感知信号标签、自我汽车行为和人类意图进行了很好的注释,因此在标记这些数据后,可以使用驱动语言模型来学习作为人类驾驶逻辑后端的驱动语言。
因为驱动语言模型和其他自然语言处理模型一样,是一个生成模型,它可以在先前标记化场景和自我汽车行为序列的基础上生成未来标记化场景序列和自我汽车行为。
此外,前面提到的人类意图注释自然是语言模型的提示。在用足够数量的标记化场景、自我-汽车行为和人类意图训练Drive语言模型之后,在给定人类意图提示的情况下,Drive语言模型可以遵循人类意图,生成未来场景和自我-汽车的行为,类似于它从训练数据中看到的情况。这类似于OpenAI InstructionGPT和ChatGPT,它们可以在提示中遵循人工指令并生成所需内容。
DriveGPT
在驱动语言模型的选择方面,正如浩默CEO所说,他们以前使用的是Transformer编码器-解码器架构,但现在他们已经完全转向了著名的OpenAI GPT模型所使用的仅Transformer解码器的架构。他们将他们的仅Transformer解码器架构的Drive语言模型命名为DriveGPT。
在上图中,Haomo使用之前的标记化场景、自我汽车行为和人类意图来预测未来的标记化自我汽车行为,对DriveGPT进行预训练。但在实践中,也可以预先训练DriveGPT,不仅预测未来的标记化自我汽车行为,还预测未来的符号化场景。通过这种方式,DriveGPT可以生成无限数量的Drive实例,郝默称之为Drive并行宇宙。
Human Feedback In the Loop
与OpenAI InstructGPT和ChatGPT类似,DriveGPT训练也可以在循环中进行人工反馈。它使用人类对未来标记化场景和自我汽车行为的质量和安全性进行排名的数据创建了一个奖励模型,并使用强化学习和奖励模型进一步微调预训练的DriveGPT。
人类反馈在环奖励模型不仅在普通人类驾驶或自动驾驶数据上进行了训练,而且还使用了自动驾驶数据,这些数据涉及人类参与,通常来自非常困难的驾驶场景。
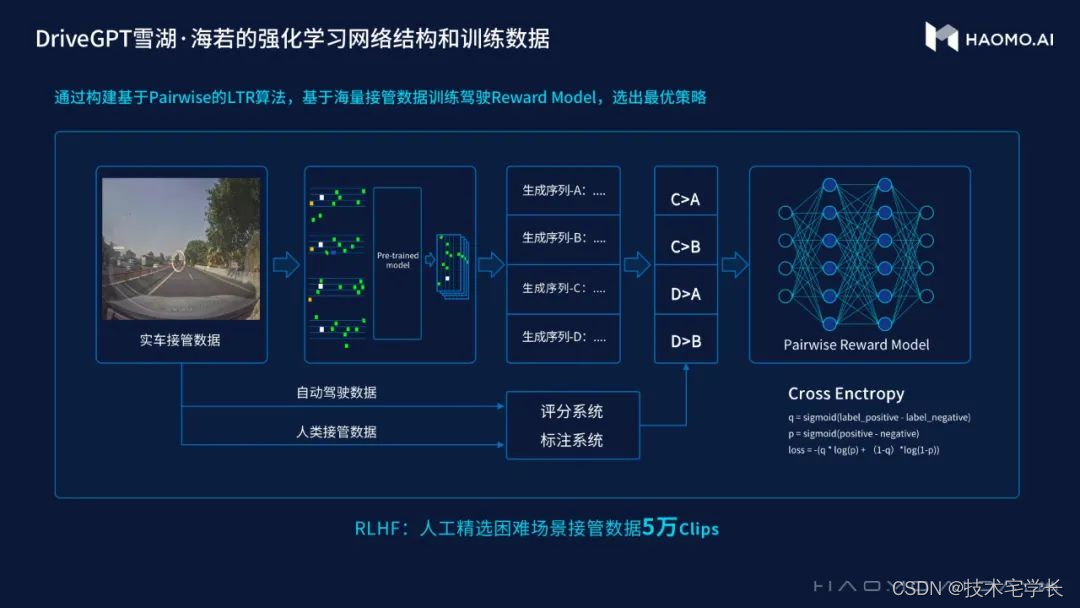
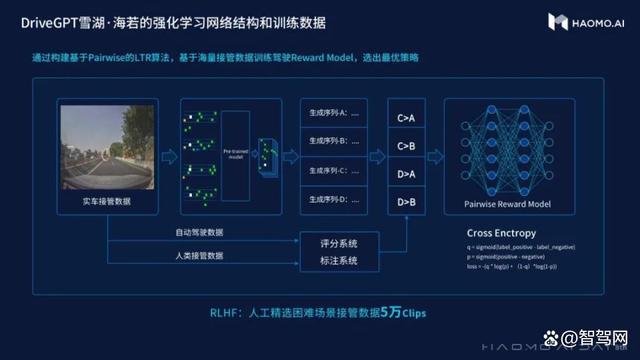
基本上,当自动驾驶汽车行驶时,如果人类选择在某些场景中接管,这意味着自动驾驶模型在这些场景中表现不佳。DriveGPT利用人类接管之前的标记化场景和自我汽车行为,可以在未来生成许多标记化场景或自我汽车行为。来自真实数据的标记化场景和自人类参与以来的自我汽车行为也是与来自相同先前场景和自我汽车行为的其他生成数据进行比较的非常重要的数据点。通常,与DriveGPT生成的DriveGPT奖励模型训练数据相比,它排名最高。
Chain of Thoughts
出于安全目的,规划的理由非常关键。神经网络通常是黑匣子。对于非安全应用,我们通常不在乎它们是否是黑匣子。然而,对于使用神经网络进行规划和决策的安全应用,非常有必要了解“神经网络的实际想法”。

给定先前的标记化场景、自我汽车行为和人类意图提示,DriveGPT可以生成未来的标记化场面和自我汽车行为。如果有一系列场景的人类意图提示注释的标记化思想链,给定一系列标记化场景和自我汽车行为,模型也可以学习生成标记化思想链条,使DriveGPT规划“不再是黑匣子”。然而,我认为有人可能仍然认为这仍然是一个黑匣子,因为思维链的生成过程仍然在神经网络中。这只是神经网络生成的内容似乎是人类可以解释的。
Critical Review
Haomo的DriveGPT是否真的能有好的表现仍然是个问题。即使DriveGPT可以在离线设置的GPU数据中心中表现良好,我认为在汽车SoC上实时运行DriveGPT可能太具挑战性了,因为为生成GPT模型运行推理的成本太高。
常见问题解答
自动驾驶可以从人类驾驶员那里端到端学习吗?
从理论上讲,我们可以。我们可以构建一个模型,并使用人类驾驶传感器数据和驾驶员行为数据对其进行端到端的训练(从传感器到动作),即使没有感知注释。然而,就目前的技术而言,这种端到端学习的性能还不足以用于生产,因为自动驾驶具有极高的安全标准,并且用现有的学习算法很难同时端到端地学习多个组件。这就是为什么大多数自动驾驶制造商将自动驾驶解决方案分为感知、规划和控制,并试图将它们完美地构建在一起。
haomo也是如此。DriveGPT需要高质量的感知信号输入。
每个 Drive Language token 都可以用于描述场景吗?
不太可能,因为场景太复杂了,无法用一个 token 来描述。即使我们将驱动空间量化为20个网格,每个网格都使用一个二进制值来指示是否存在障碍物。一个场景的可能 token数量为2^20=1048876,约为一百万,这对于当前的语言模型来说太大了,无法成功学习。这甚至没有考虑其他场景因素,如障碍物类型、大小和车道类型。
References
- OpenAI GPT Models
- Haomo Releases DriveGPT
- Haomo’s self-driving ambitions leap forward with launch of DriveGPT
- Planning and Decision-Making for Autonomous Vehicles
- Haomo 8th AI Day
- Haomo 7th AI Day
- Haomo 6th AI Day
- Haomo 5th AI Day
DriveGPT
DriveGPT - Lei Mao's Log Book
DriveGPT能做到什么?又是如何构建的?顾维灏在AI DAY上都做了详细解读。此外,AI DAY还展示了毫末自动驾驶数据体系MANA的升级情况,主要是其在视觉感知能力上的进展。
01.
什么是DriveGPT?能实现什么?
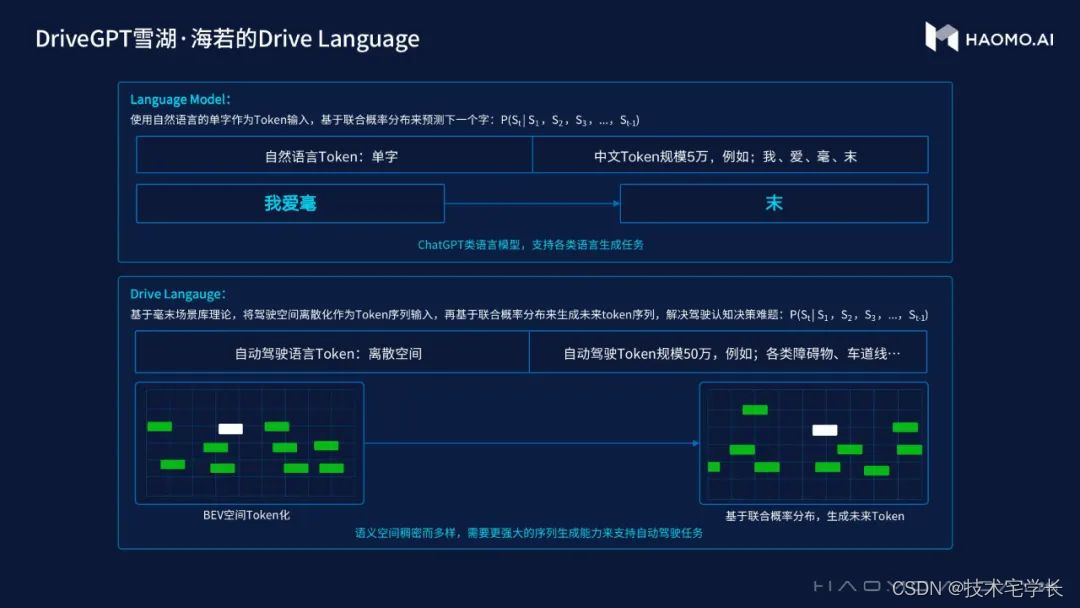
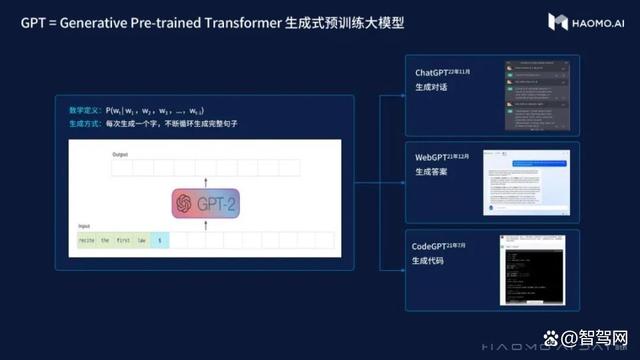
顾维灏首先讲解了GPT的原理,生成式预训练Transformer模型本质上是在求解下一个词出现的概率,每一次调用都是从概率分布中抽样并生成一个词,这样不断地循环,就能生成一连串的字符,用于各种下游任务。
以中文自然语言为例,单字或单词就是Token,中文的Token词表有5万个左右。把Token输入到模型,输出就是下一个字词的概率,这种概率分布体现的是语言中的知识和逻辑,大模型在输出下一个字词时就是根据语言知识和逻辑进行推理的结果,就像根据一部侦探小说的复杂线索来推理凶手是谁。
而作为适用于自动驾驶训练的大模型,DriveGPT雪湖·海若三个能力:
1.可以按概率生成很多个这样的场景序列,每个场景都是一个全局的场景,每个场景序列都是未来有可能发生的一种实际情况。
2.是在所有场景序列都产生的情况下,能把场景中最关注的自车行为轨迹给量化出来,也就是生成场景的同时,便会产生自车未来的轨迹信息。
3.有了这段轨迹之后,DriveGPT雪湖·海若还能在生成场景序列、轨迹的同时,输出整个决策逻辑链。
也就是说,利用DriveGPT雪湖·海若,在一个统一的生成式框架下,就能做到将规划、决策与推理等多个任务全部完成。

具体来看,DriveGPT雪湖·海若的设计是将场景Token化,毫末将其称为Drive Language。
Drive Language将驾驶空间进行离散化处理,每一个Token都表征场景的一小部分。目前毫末拥有50万个左右的Token词表空间。如果输入一连串过去已经发生的场景Token序列,模型就可以根据历史,生成未来所有可能的场景。
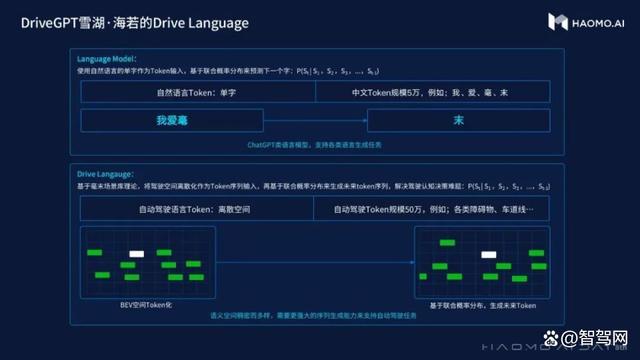
也就是说,DriveGPT雪湖·海若同样像是一部推理机器,告诉它过去发生了什么,它就能按概率推理出未来的多个可能。
一连串Token拼在一起就是一个完整的驾驶场景时间序列,包括了未来某个时刻整个交通环境的状态以及自车的状态。
有了Drive Language,就可以对DriveGPT进行训练了。
毫末对DriveGPT的训练过程首先是根据驾驶数据以及之前定义的驾驶尝试做一个大规模的预训练。

然后,通过在使用过程中接管或者不接管的场景,对预训练的结果进行打分和排序,训练反馈模型。也就是说利用正确的人类开法来替代错误的自动驾驶开法。
后续就是用强化学习的思路不断优化迭代模型。
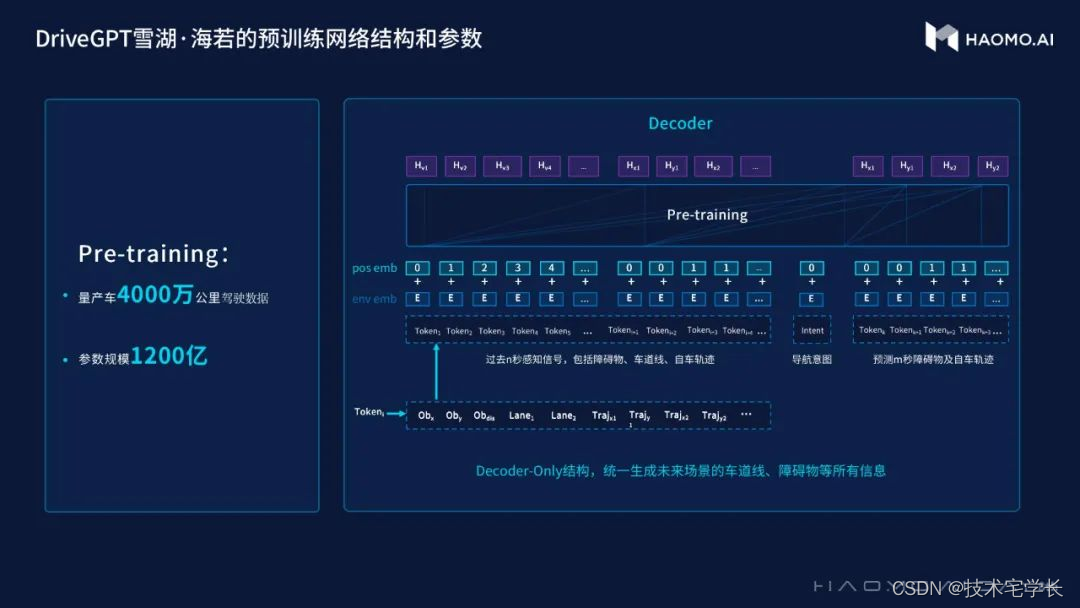
在预训练模型上,毫末采用Decode-only结构的GPT模型,每一个Token用于描述某时刻的场景状态,包括障碍物的状态、自车状态、车道线情况等等。

目前,毫末的预训练模型拥有1200亿个参数,使用4000万量产车的驾驶数据,本身就能够对各种场景做生成式任务。
这些生成结果会按照人类偏好进行调优,在安全、高效、舒适等维度上做出取舍。同时,毫末会用部分经过筛选的人类接管数据,大概5万个Clips去做反馈模型的训练,不断优化预训练模型。
在输出决策逻辑链时,DriveGPT雪湖·海若利用了prompt提示语技术。输入端给到模型一个提示,告诉它“要去哪、慢一点还是快一点、并且让它一步步推理”,经过这种提示后,它就会朝着期望的方向去生成结果,并且每个结果都带有决策逻辑链。每个结果也会有未来出现的可能性。这样我们就可以选择未来出现可能性最大,最有逻辑的链条驾驶策略。
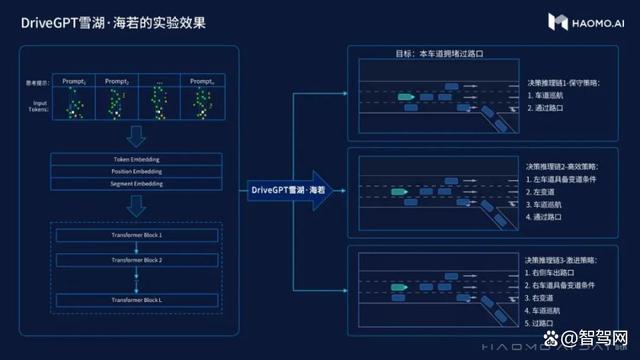
可以用一个形象的示例来解释DriveGPT雪湖·海若的推理能力。假设提示模型要“抵达某个目标点”,DriveGPT雪湖·海若会生成很多个可能的开法,有的激进,会连续变道超车,快速抵达目标点,有的稳重,跟车行驶到终点。这时如果提示语里没有其他额外指示,DriveGPT雪湖·海若就会按照反馈训练时的调优效果,最终给到一个更符合大部分人驾驶偏好的效果。
02.
实现DriveGPT毫末做了什么?
首先,DriveGPT雪湖·海若的训练和落地,离不开算力的支持。
今年1月,毫末就和火山引擎共同发布了其自建智算中心,毫末雪湖·绿洲MANA OASIS。OASIS的算力高达67亿亿次/秒,存储带宽2T/秒,通信带宽达到800G/秒。

当然,光有算力还不够,还需要训练和推理框架的支持。因此,毫末也做了以下三方面的升级。
一是训练稳定性的保障和升级。

大模型训练是一个十分艰巨的任务,随着数据规模、集群规模、训练时间的数量级增长,系统稳定性方面微小的问题也会被无限放大,如果不加处理,训练任务就会经常出错导致非正常中断,浪费前期投入的大量资源。
毫末在大模型训练框架的基础上,与火山引擎共同建立了全套训练保障框架,通过训练保障框架,毫末实现了异常任务分钟级捕获和恢复能力,可以保证千卡任务连续训练数月没有任何非正常中断,有效地保障了DriveGPT雪湖·海若大模型训练的稳定性。
二是弹性调度资源的升级。
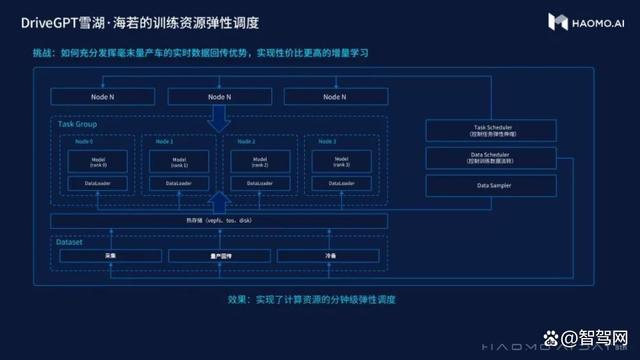
毫末拥有量产车带来的海量真实数据,可自动化的利用回传数据不断的学习真实世界。由于每天不同时段回传的数据量差异巨大,需要训练平台具备弹性调度能力,自适应数据规模大小。
毫末将增量学习技术推广到大模型训练,构建了一个大模型持续学习系统,研发了任务级弹性伸缩调度器,分钟级调度资源,集群计算资源利用率达到95%。
三是吞吐效率的升级。

在训练效率上,毫末在Transformer的大矩阵计算上,通过对内外循环的数据拆分、尽量保持数据在SRAM中来提升计算的效率。在传统的训练框架中,算子流程很长,毫末通过引入火山引擎提供的Lego算之库实现算子融合,使端到端吞吐提升84%。
有了算力和这三方面的升级,毫末可对DriveGPT雪湖·海若进行更好的训练迭代升级。
03.
MANA大升级,摄像头代替超声波雷达
毫末在2021年12月的第四届AI DAY上发布自动驾驶数据智能体系MANA,经过一年多时间的应用迭代,现在MANA迎来了全面的升级。
据顾维灏介绍,本次升级主要包括:
1.感知和认知相关大模型能力统一整合到DriveGPT。
2.计算基础服务针对大模型训练在参数规模、稳定性和效率方面做了专项优化,并集成到OASIS当中。
3.增加了使用NeRF技术的数据合成服务,降低Corner Case数据的获取成本。
4.针对多种芯片和多种车型的快速交付难题,优化了异构部署工具和车型适配工具。
前文我们已经详细介绍了DriveGPT相关的内容,以下主要来看MANA在视觉感知上的进展。
顾维灏表示,视觉感知任务的核心目的都是恢复真实世界的动静态信息和纹理分布。因此毫末对视觉自监督大模型做了一次架构升级,将预测环境的三维结构,速度场和纹理分布融合到一个训练目标里面,使其能从容应对各种具体任务。目前毫末视觉自监督大模型的数据集超过400万Clips,感知性能提升20%。

在泊车场景下,毫末做到了用鱼眼相机纯视觉测距达到泊车要求,可做到在15米范围内达测量精度30cm,2米内精度高于10cm。用纯视觉代替超声波雷达,进一步降低整体方案的成本。

此外,在纯视觉三维重建方面,通过视觉自监督大模型技术,毫末不依赖激光雷达,就能将收集的大量量产回传视频转化为可用于BEV模型训练的带3D标注的真值数据。
通过对NeRF的升级,毫末表示可以做到重建误差小于10cm,并且对于场景中的动态物体也能做到很好的重建和渲染,达到肉眼基本看不出差异的程度。
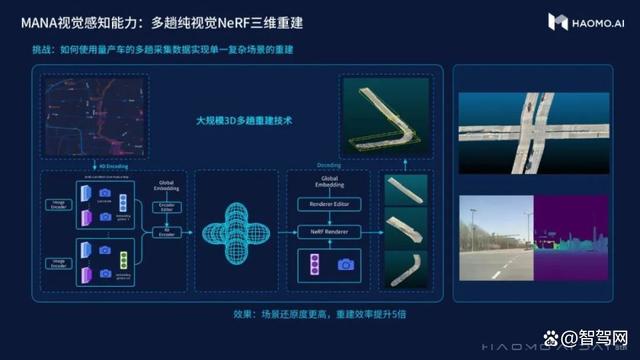
此外,由于单趟重建有时会受到遮挡的影响,不能完整的还原三维空间,毫末也尝试了多趟重建的方式,即多辆车在不同时间经过同一地方,可以将数据合在一起做多趟重建。
顾维灏表示,目前毫末已经实现了更高的场景还原度,重建效率提升5倍,同时,还可在重建之后编辑场景合成难以收集的Corner Case。
此外,毫末也训练了一个可以在静态场景做虚拟动态物体编辑的模型,并且可以控制虚拟物体在场景中按照设定的轨迹运动,以更加高效的合成各种hardcase,使系统能够见识到足够多的corner case,低成本的测试自身的能力边界,提升NOH应对城市复杂交通环境的能力。

顾维灏表示,毫末DriveGPT雪湖·海若大模型的成果将在搭载毫末HPilot3.0的新摩卡DHT-PHEV上首发落地。

同时,顾维灏也表示,毫末DriveGPT雪湖·海若大模型将对生态伙伴开放。
随着汽车智能化趋势加速,我国智能驾驶赛道迎来爆发。当前高阶智驾产品正经历从高速场景到城市场景落地的比拼,而城市辅助驾驶被认为是迈向真正自动驾驶的最后一个挑战。毫末认为,决定这场智能驾驶产品跃迁的关键,是自动驾驶AI算法在开发模式和技术框架的颠覆性变革,而AI大模型则成为引领这场技术变革的核心变量。
2023年10月11日第九届毫末AI DAY上,顾维灏发表了主题为《自动驾驶3.0时代:大模型将重塑汽车智能化的技术路线》的演讲,分享了毫末对于自动驾驶3.0时代AI开发模式和技术架构变革的思考,同时也公布了毫末DriveGPT大模型的最新进展和实践。其中,截至目前,毫末型DriveGPT雪湖·海若已累计计筛选出超过100亿帧互联网图片数据集和480万段包含人驾行为的自动驾驶4D Clips数据;在通用感知上,进一步升级引入多模态大模型,获得识别万物的能力;与NeRF技术进一步整合,渲染重建4D空间;在通用认知上,借助LLM(大语言模型),让自动驾驶认知决策具备世界知识,能够做出更好的驾驶策略。

(顾维灏:DriveGPT通用感知与通用认知能力全面升级)
毫末智行CEO顾维灏提出:“在大数据、大模型、大算力的自动驾驶3.0时代,自动驾驶技术框架也会发生颠覆性的变化。在感知阶段,通过海量的数据训练感知基础模型,学习并认识客观世界的各种物体;在认知阶段,则通过海量司机的驾驶行为数据,学习驾驶常识,通过数据驱动的方式不断迭代并提升整个系统的能力水平。毫末一直以数据驱动的方式来推动自动驾驶产品的升级,为进入自动驾驶3.0时代做准备。”
1
通用感知可识别万物、通用认知学会世界知识:毫末DriveGPT引领自动驾驶大模型新范式
顾维灏认为,与2.0时代相比,自动驾驶3.0时代的开发模式将发生颠覆性的变革。在自动驾驶2.0时代,以小数据、小模型为特征,以Case任务驱动为开发模式。而自动驾驶3.0时代,以大数据、大模型为特征,以数据驱动为开发模式。
相比2.0时代主要采用传统模块化框架,3.0时代的技术框架也发生了颠覆性变化。
首先,自动驾驶会在云端实现感知大模型和认知大模型的能力突破,并将车端各类小模型逐步统一为感知模型和认知模型,同时将控制模块也AI模型化。随后,车端智驾系统的演进路线也是一方面会逐步全链路模型化,另一方面是逐步大模型化,即小模型逐渐统一到大模型内。然后,云端大模型也可以通过剪枝、蒸馏等方式逐步提升车端的感知能力,甚至在通讯环境比较好的地方,大模型甚至可以通过车云协同的方式实现远程控车。最后,在未来车端、云端都是端到端的自动驾驶大模型

(毫末DriveGPT升级:大模型让自动驾驶拥有世界知识)
毫末DriveGPT大模型正是按照3.0时代的技术框架要求进行升级。在通用感知能力提升上,DriveGPT通过引入多模态大模型,实现文、图、视频多模态信息的整合,获得识别万物的能力;同时,通过与NeRF技术整合,DriveGPT实现更强的4D空间重建能力,获得对三维空间和时序的全面建模能力;在通用认知能力提升上,DriveGPT借助大语言模型,将世界知识引入到驾驶策略,从而做出更好的驾驶决策优化。
具体来讲,在感知阶段,DriveGPT首先通过构建视觉感知大模型来实现对真实物理世界的学习,将真实世界建模到三维空间,再加上时序形成4D向量空间;然后,在构建对真实物理世界的4D感知基础上,毫末进一步引入开源的图文多模态大模型,构建更为通用的语义感知大模型,实现文、图、视频多模态信息的整合,从而完成4D向量空间到语义空间的对齐,实现跟人类一样的“识别万物”的能力。
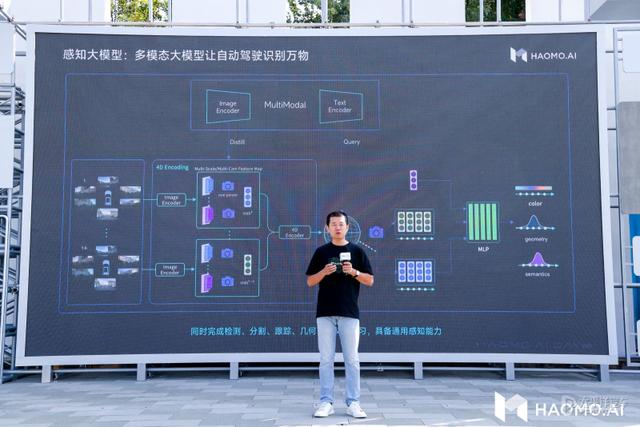
(毫末DriveGPT通用感知大模型:让自动驾驶认识万物)
毫末通用感知能力的进化升级包含两个方面。首先是视觉大模型的CVBackbone的持续进化,当前基于大规模数据的自监督学习训练范式,采用Transformer大模型架构,实现视频生成的方式来进行训练,构建包含三维的几何结构、图片纹理、时序信息等信息的4D表征空间,实现对全面的物理世界的感知和预测。其次是构建起更基础的通用语义感知大模型,在视觉大模型基础上,引入图文多模态模型来提升感知效果,图文多模态模型可以对齐自然语言信息和图片的视觉信息,在自动驾驶场景中就可以对齐视觉和语言的特征空间,从而具备识别万物的能力,也由此可以更好完成目标检测、目标跟踪、深度预测等各类任务。
在认知阶段,基于通用语义感知大模型提供的“万物识别”能力,DriveGPT通过构建驾驶语言(Drive Language)来描述驾驶环境和驾驶意图,再结合导航引导信息以及自车历史动作,并借助外部大语言模型LLM的海量知识来辅助给出驾驶决策。
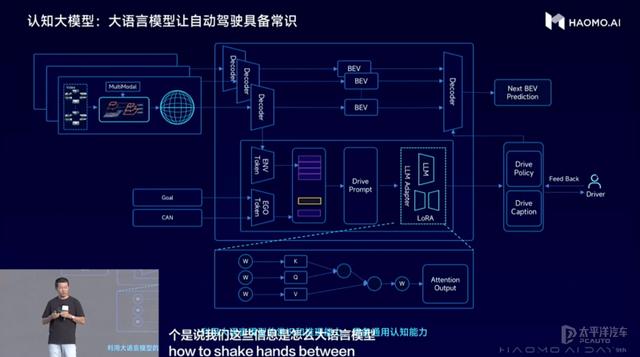
(毫末DriveGPT认知大模型:让自动驾驶具备常识)
由于大语言模型已经学习到并压缩了人类社会的全部知识,因而也就包含了驾驶相关的知识。经过毫末对大语言模型的专门训练和微调,从而让大语言模型更好地适配自动驾驶任务,使得大语言模型能真正看懂驾驶环境、解释驾驶行为,做出驾驶决策。
认知大模型通过与大语言模型结合,使得自动驾驶认知决策获得了人类社会的常识和推理能力,也就是获得了世界知识,从而提升自动驾驶策略的可解释性和泛化性。
顾维灏表示:“未来的自动驾驶系统一定是跟人类驾驶员一样,不但具备对三维空间的精确感知测量能力,而且能够像人类一样理解万物之间的联系、事件发生的逻辑和背后的常识,并且能基于这些人类社会的经验来做出更好的驾驶策略,真正实现完全无人驾驶。”
2
能生成、会解释、可预测:毫末DriveGPT大模型升级带来七大应用实践
在毫末DriveGPT大模型的最新开发模式和技术框架基础上,顾维灏同时分享了自动驾驶大模型的七大应用实践,包括驾驶场景理解、驾驶场景标注、驾驶场景生成、驾驶场景迁移、驾驶行为解释、驾驶环境预测和车端模型开发。

(毫末DriveGPT应用的七大实践)
顾维灏表示:“毫末DriveGPT大模型的应用,在自动驾驶系统开发过程中带来了巨大技术提升,使得毫末的自动驾驶系统开发彻底进入了全新模式,新开发模式和技术架构将大大加速汽车智能化的进化进程。”
第一、驾驶场景理解,可实现秒级数据筛选,为图文多模态模型发掘海量优质数据。
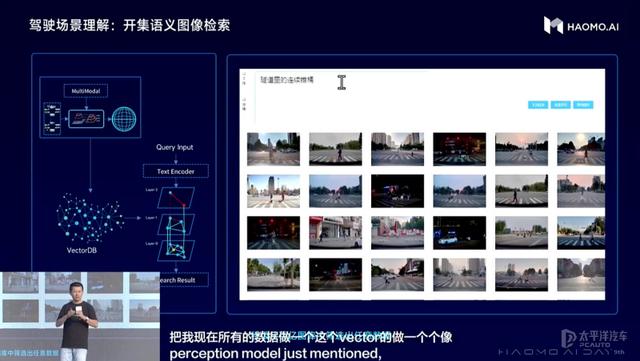
(驾驶场景理解:开集语义图像检索)
原有自动驾驶技术方案在解决Corner case时,都需要先收集一批与此case相关的数据,然后以标签加人工的方式进行数据标注,即先对图片打上标签,然后用标签做粗筛选、再人工细筛选,成本非常高、效率非常低。现在,毫末采用通用感知大模型,可以利用图文多模态模型对海量采集图片进行目标级别和全图级别的特征提取,变成图片表征向量,并对这些海量的向量数据建立向量数据库,可以从百亿级别的向量数据库中找到任意文本对应的驾驶场景数据,实现秒级搜索。
基于这一能力,毫末还构建了专有的自动驾驶场景多模态数据集,训练了毫末的图文多模态模型,来对如鱼骨线、双黄实线车道线等理解难度较大的驾驶环境特有场景进行专门训练和学习。
第二、驾驶场景标注,实现更高效的Zero-Shot的自动数据标注,让万物皆可被认出。
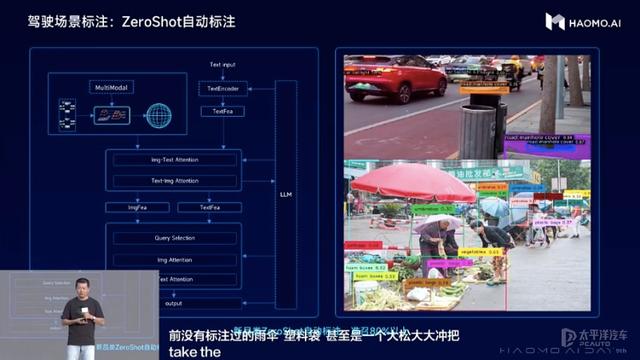
(驾驶场景标注:zeroShot自动标注)
原有的自动驾驶感知算法,仅仅能识别人工标注过的有限个品类的物体,一般也就几十类,这些品类之外的物体都无法识别,通常称之为闭集(Closed-set)数据。毫末通过图文多模态大模型将原有仅识别少数交通元素的闭集场景标注,升级为开集(Open-set)场景中进行Zero-Shot的自动标注,从而应对千变万化的真实世界的各类驾驶场景,实现对任意物体既快速又精准的标注。
通过多模态技术对齐图文表征,再利用大语言模型辅助用于提供开放词句的表征能力,最终完成Zero-Shot的自动标注。通过该方案,毫末不仅实现了针对新品类的Zero-Shot快速标注,而且精度还非常高,预标注准召达到80%以上。
第三、驾驶场景生成,实现无中生有的可控生成技术,让Hardcase不再难找。

(驾驶场景生成:无中生有的可控生成)
为应对海量数据中相关困难场景(Hardcase)数据不足的问题,毫末基于DriveGPT大模型构建了AIGC能力,从而生成平时难以获取的Hardcase数据。基于毫末丰富的驾驶数据,训练了驾驶场景的AIGC模型,可通过输入标注结果,比如路口、大区率弯道等车道线,再以这个标注结果为Prompt来生成对应的图像。基于这样的可控生成的图像,一方面可以通过标注进行更加精细的位置控制,另一方面也让新生成的数据自带了标注信息,可以直接用于下游任务的训练。
第四、驾驶场景迁移,通过瞬息万变的场景迁移技术,实现全天候驾驶数据的同时获取。

(驾驶场景迁移:轻松获取全天候驾驶数据)
除了基于标注结果的数据生成之外,DriveGPT还可以进行高效的场景迁移。通过引入文字引导,AIGC生成能力可以用单个模型实现多目标场景生成。基于毫末的感知大模型,以真实的采集图像作为引导,通过文本语言来描述希望生成的目标场景,可实现清晨、正午、黄昏、夜晚等多时间段光照变换,同时也可把晴天转换为雨天、雪天、雾天等各种极端天气。通过这种方式,能将采集到的一个场景,迁移到该场景的不同时间、不同天气、不同光照等各类新场景下,极大地丰富了训练数据,提高模型在极端场景下的泛化性。
第五、驾驶行为解释,通过引入大语言模型,让AI解说驾驶场景和驾驶策略。
毫末DriveGPT原本对自动驾驶策略解释的做法是引入场景库、并对典型场景用人工标注的方式给出驾驶解释,这次升级则是通过引入大语言模型来对驾驶环境、驾驶决策做出更丰富的解释,相当于让AI自己解释自己的驾驶策略。
首先,将感知大模型的结果解码得到当前的感知结果,再结合自车信息和驾驶意图,构造典型的Drive Prompt(驾驶提示语),将这些Prompt输入大语言模型,从而让大语言模型对当前的自动驾驶环境做出解释。其次,大语言模型也可以对自动驾驶系统所做出的驾驶行为给出合理的解释,掌握例如为什么要加速、为什么要减速、为什么要变道等,让大语言模型能够像驾校教练或者陪练一样,对驾驶行为做出详细的解释。大语言模型的引入,一方面能解决大模型不可解释的问题,另一方面也能基于这些驾驶解释来进行驾驶决策的优化。

(驾驶行为解释:让AI解释自己的驾驶决策)
第六、驾驶环境预测,让DriveGPT具备社会常识,从而可以准确地预测未来场景。
DriveGPT原有采用生成式预训练的方式,使用海量司机驾驶行为进行预训练以及引入大量司机接管数据座位人类反馈数据进行强化学习,从而基于已有的BEV场景来更好预测生成未来几秒的BEV场景。但是DriveGPT需要具备像人类一样对社会常识、社会潜规则的理解,并基于这种潜规则做出更好的预测。因此,除了使用驾驶行为数据,DriveGPT还需要引入大语言模型,才可以在预测规划中融入人类社会的知识或常识,才能给出更合理的驾驶决策。
顾维灏认为:“我们相信,必须要引入大语言模型,才能让自动驾驶具备常识,而自动驾驶必须具备常识,才能理解人类社会的各种明规则、潜规则,才能跟老司机一样,与各类障碍物进行更好地交互。”
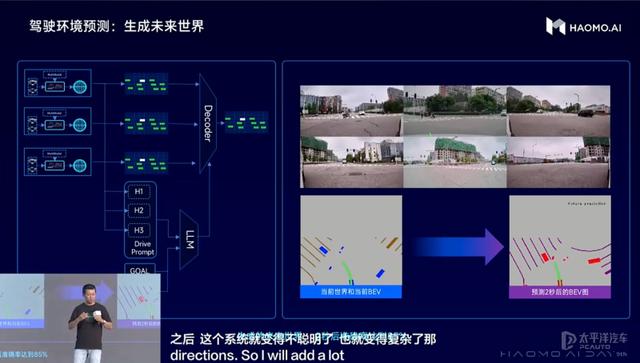
(驾驶环境预测:更像人类一样预测未来场景)
第七、车端模型开发,把大模型蒸馏成小模型,从而在有限车端算力上得到更好效果。
大模型训练需要依靠云端的海量数据和超大算力,短期内难以直接部署到车端芯片,而如何让大模型的能力帮助车端提升效果,可以采用蒸馏的方式。第一种蒸馏方法是使用大模型来输出各类伪标签,伪标签既可以作为训练语料,来丰富车端小模型的训练数据,也可以作为监督信号,让车端小模型来学习云端大模型的预测结果;第二种蒸馏方法是通过对齐Feature Map的方式,让车端小模型直接学习并对齐云端的Feature Map,从而提升车端小模型的能力。基于蒸馏的方式,可以让车端的感知效果提升5个百分点。
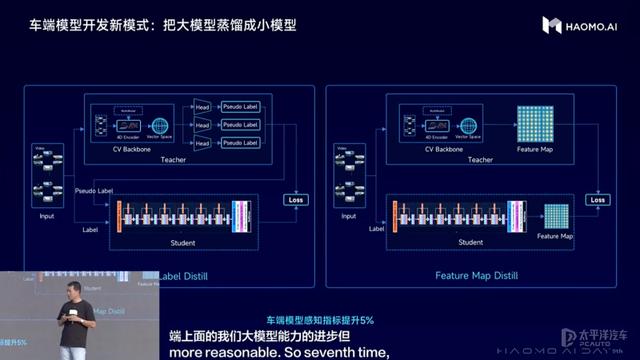
(车端模型开发新模式:把大模型蒸馏成小模型)
3
纯视觉泊车、道路全要素识别、小目标检测:毫末DriveGPT
赋能车端
感知提升
毫末利用视觉感知模型,使用鱼眼相机可以识别墙、柱子、车辆等各类型的边界轮廓,形成360度的全视野动态感知,可以做到在15米范围内达到30cm的测量精度,2米内精度可以高于10cm。这样的精度可实现用视觉取代USS超声波雷达,从而进一步降低整体智驾方案成本。

(毫末纯视觉泊车)
基于DriveGPT基于通用感知的万物识别的能力,毫末对交通场景全要素识别也有了较大提升,从原有感知模型只能识别少数几类障碍物和车道线,到现在可以识别各类交通标志、地面箭头、甚至井盖等交通场景的全要素数据。大量高质量的道路场景全要素标注数据,可以有效帮助毫末重感知的车端感知模型实现效果的提升,助力城市NOH的加速进城。

(毫末城市NOH感知全要素识别)
基于DriveGPT的通用语义感知模型能力对通用障碍物的开集场景标注,可实现对道路上小目标障碍物检测也有较好的效果。毫末在当前城市NOH的测试中,可以在城市道路场景中,在时速最高70公里的50米距离外,就能检测到大概高度为35cm的小目标障碍物,可以做到100%的成功绕障或刹停,这样可以对道路上穿行的小动物等移动障碍物起到很好地检测保护作用。

(毫末城市NOH小目标障碍物检测)
历届HAOMO AI DAY的核心主题都是聚焦最硬核的自动驾驶AI技术,这次更是专门聚焦AI大模型对于自动驾驶技术的赋能,提出了探索端到端自动驾驶技术路线的一种新可能。
正如顾维灏在结尾说道:“毫末即将成立四周年,一约既定,万山无阻。毫末人将继续用AI连接更广阔的世界,用技术叩问更浩远的未来。”HAOMO AI DAY成为中国自动驾驶技术的一面旗帜,同时也正在成为毫末向年轻的AI人才发出邀请的最好的一扇窗口。