文章目录
- 查找
- 基本概念
- 线性表查找
- 顺序查找
- 折半查找(二分)
- 分块查找
- 树查找
- 二叉排序树(BST)
- 平衡二叉树(AVL)的插入
- 平衡化
- 复杂度分析
- 平衡二叉树的删除
- 红黑树
- 红黑树的定义和性质
- 红黑树定义
- 红黑树性质
- 红黑树的插入
- 红黑树的删除
- B树
- B树基础
- B树插入和删除
- 裂变插入法
- 流动删除法
- B+树
- 定义和特性
- B+树查找
- B+树对比B树
- 与OS的联系
- 散列查找
- 基本概念
- 常见散列函数
- 除留余数法
- 直接定址法
- 数字分析法
- 平方取中法
- 冲突处理
- 拉链法
- 再散列法
- 开放定址法
- 线性探测法
- 平方探测法
- 伪随机序列法
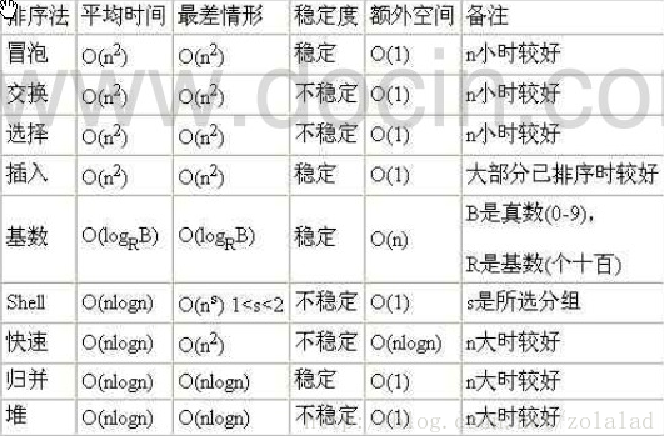
- 排序
- 插入类排序
- 插入排序
- 直接插入排序
- 折半插入排序
- 希尔排序
- 独家理解:希尔排序的本质与生效原理
- 具体操作
- 代码
- 总结
- 交换类排序
- 冒泡排序
- 快速排序(重点)
- 代码细节
- 算法分析
查找
基本概念

查找表,其实就类似于数据库的数据表。
所谓的数据项,就是数据库的一列,而关键字就是key,是唯一的。
查找长度(SL)即key的比较次数,ASL是Average SL
线性表查找
顺序查找

基本的查找算法,如果不会写就废了,注意循环跳出条件:key匹配则跳出
哨兵可以简化代码,本质在于,哨兵和普通元素的逻辑是一致的,但是可以发挥出终止的效果
因此,for循环不需要考虑越界,最后return的时候也不需要判断是否查找成功(哨兵本身的0下标就代表失败)
其实链表里的头结点也是一种哨兵。

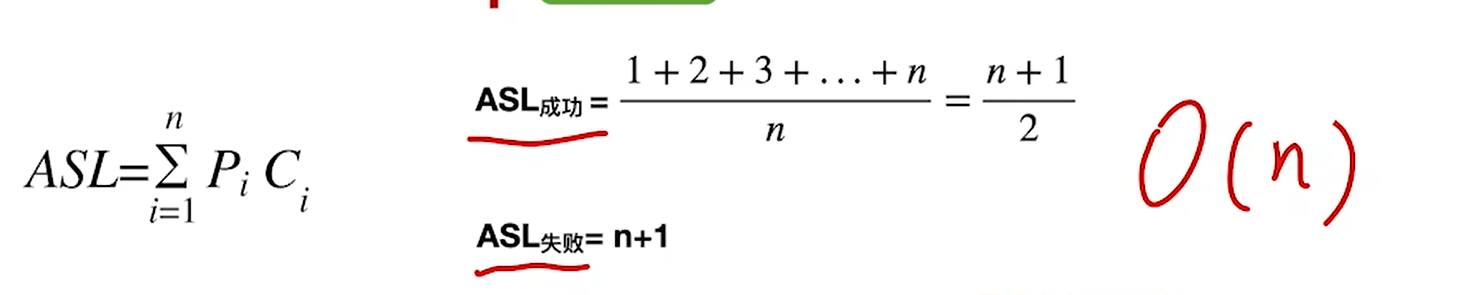
查找的优化思路有二:
- 有序情况下(假定顺序),如果key已经大于目标key了,那么后面也就没必要继续扫了,即
提前终止,可以减少失败ASL - 如果已知查找到的概率,那么可以将高概率的排在前面,即
提前成功,可以减少成功ASL
分析ASL的时候可以用判定树来分析,将判定逻辑写成树,分析ASL的思路如下:
- 成功的ASL,就把n个成功节点加权和,而失败的ASL,就把n+1个失败节点加权和
- 单个成功节点的SL=高度,而失败节点的SL=父节点高度
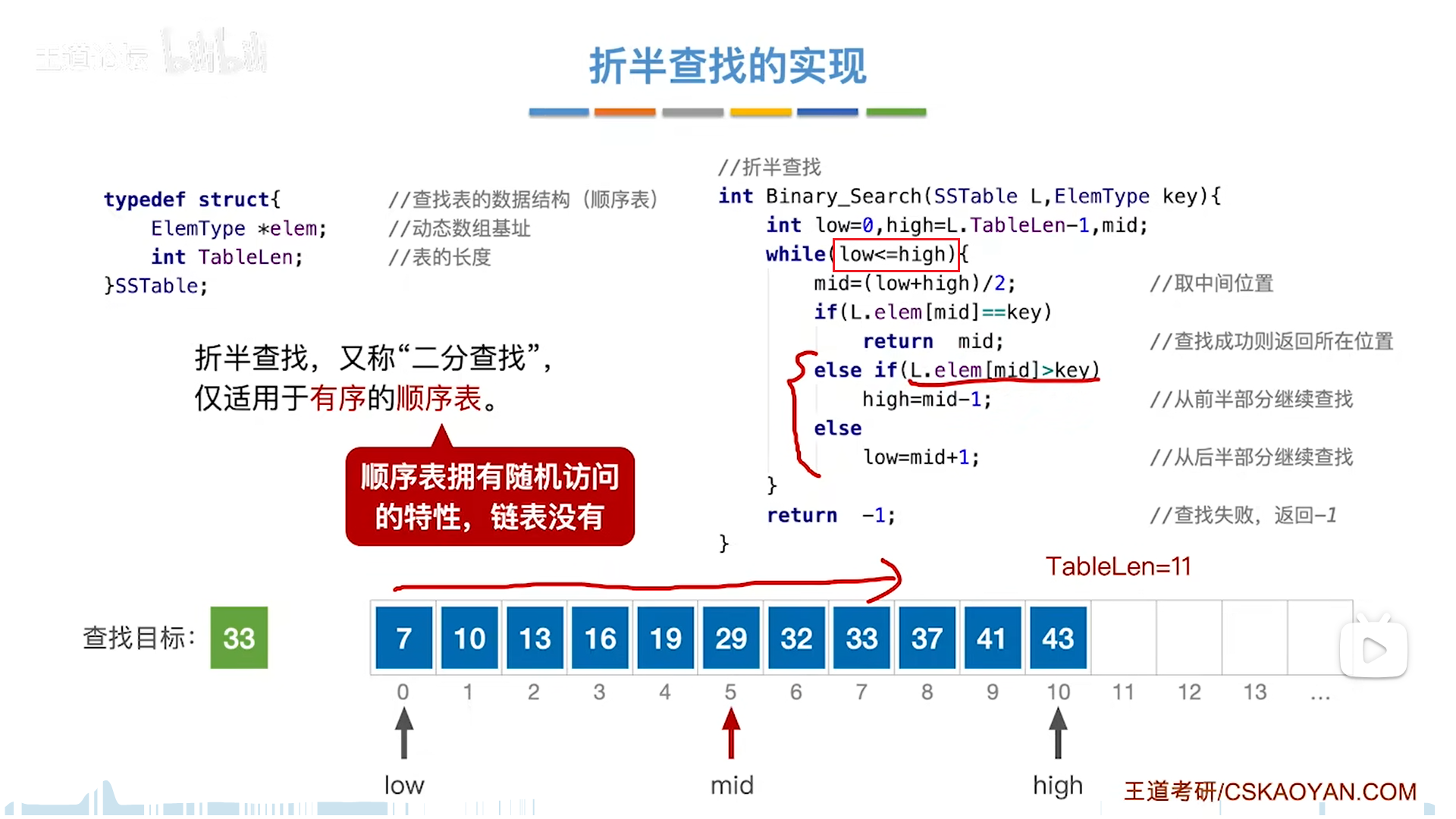
折半查找(二分)
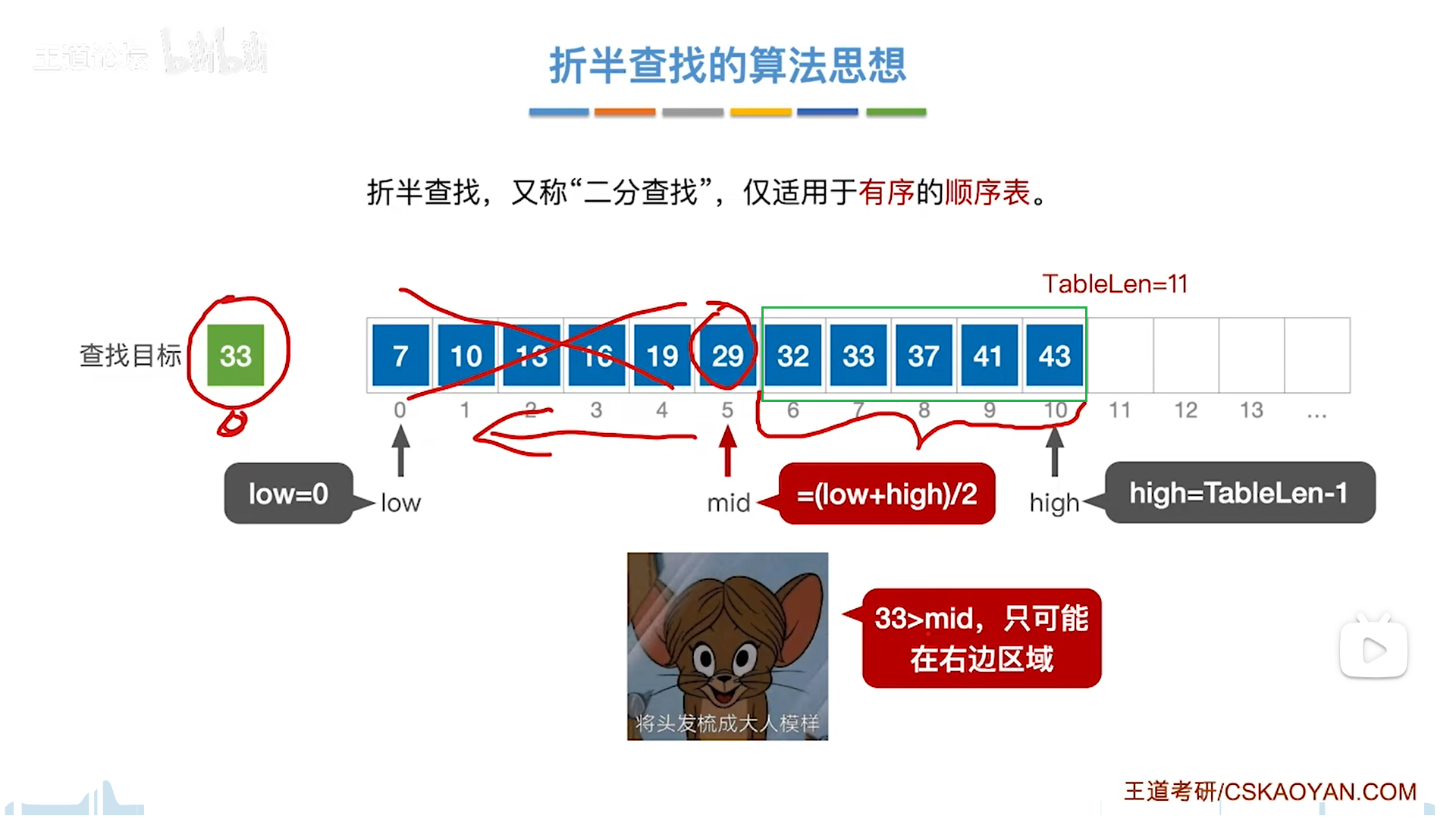
前提是有序。
low和high构成一个闭区间,目标元素只可能在闭区间内,每次要和mid对比。
和mid对比,情况有两大类:
- 等,则成功
- 不等,则代表只能在两侧区域,不包括mid,因此边界要调整为mid-1(小),mid+1(大)
此时你可能会怀疑,最后能不能收敛,如果你是以mid为新边界,下面这种情况可能就无法收敛了,但是如果你去掉mid,即以mid+1为新边界,假设能查到,最坏的情况也一定会收敛到具体的一个点上(此时low==high)
假设查不到,在收敛到具体的一个点后,low和high就要错开,构成low>high的情景,此时直接报错

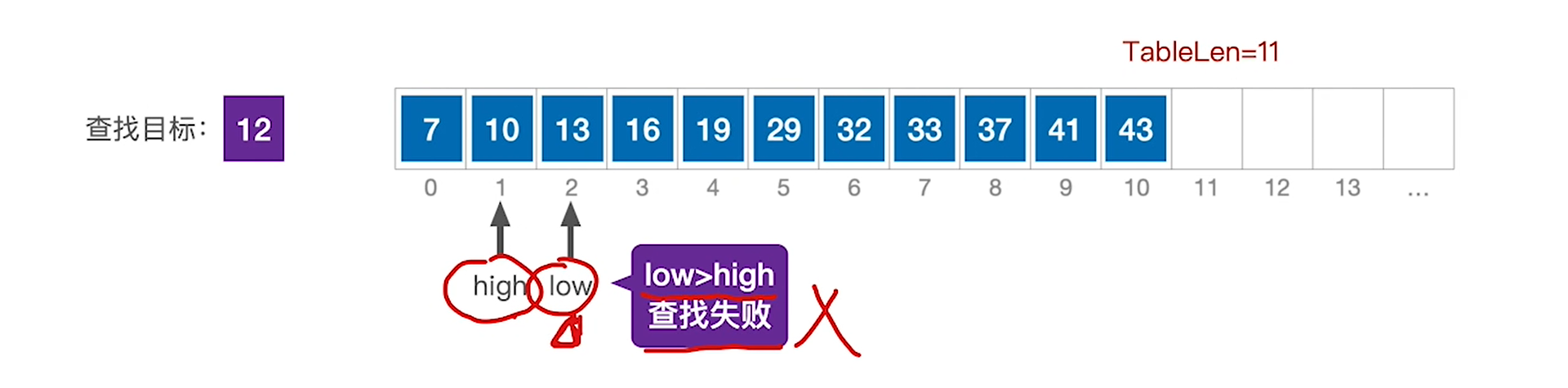
整体来看这个算法,过程如下:
- 考察区域从全部收敛到-1
- 极限情况:low≤high
- 一定会不断收缩,一定可以判定完最后一个点
- 之后继续走的话,low和high会交错,退出循环
- 在收敛过程中,如果成功则提前退出循环
因此这个算法是完美无缺的,可以全覆盖所有可能。
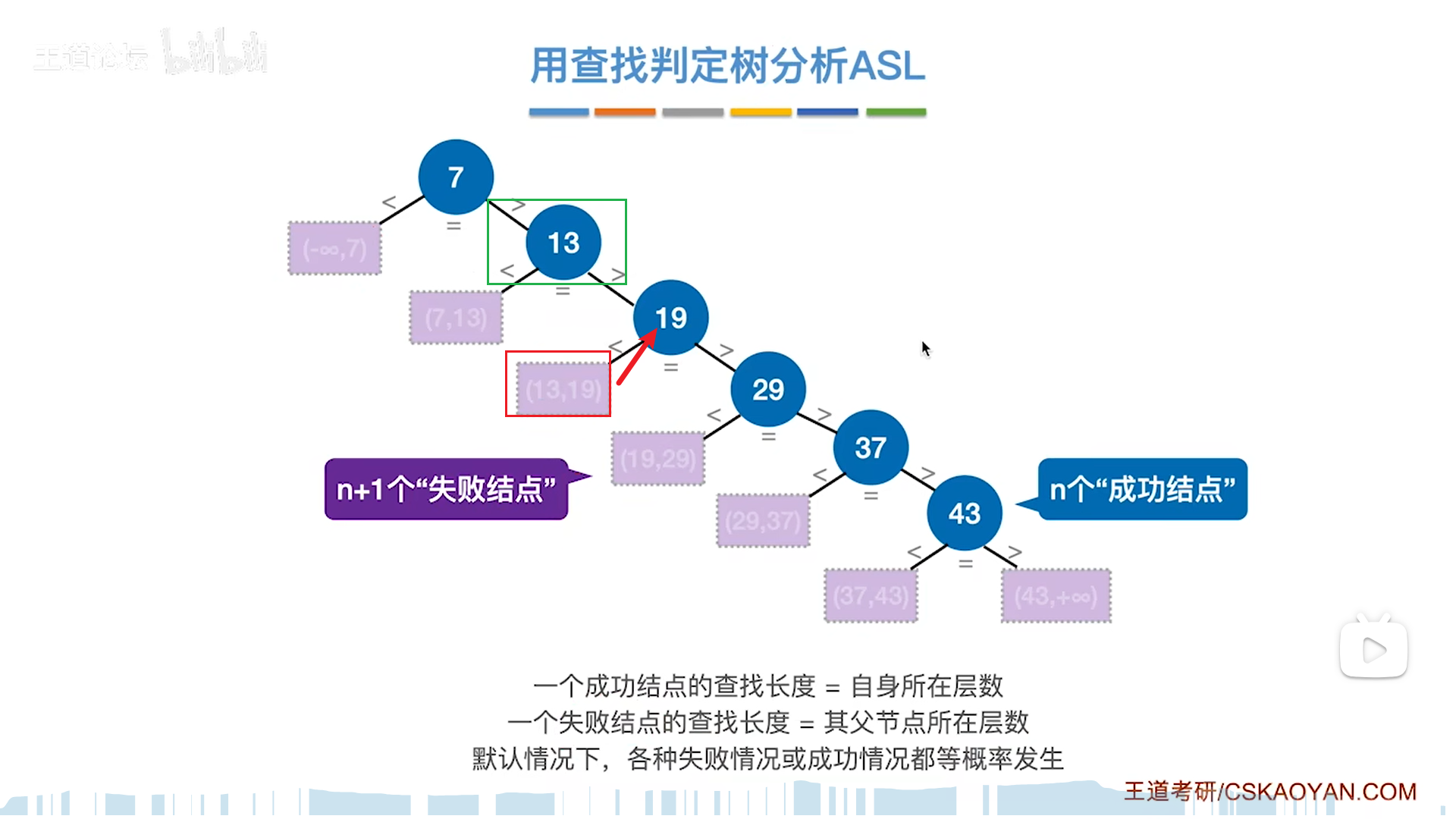
分析效率继续用判定树,这个判定树是非常的神奇好用,把成功节点(mid)逐层展开,再补上失败节点就如下图

需要注意的是,假如总结点数量为偶数个,那么考虑到mid是向下取整,就会出现右子树=左子树+1的现象,不可能更多了,也就是说,右子树-左子树=0或1,只有这两种可能。
反过来,如果mid向上取整,自然就是左-右=0或1
无论哪种方式,折半查找判定树是平衡二叉树,而且只可能有最下面一层不满,那么树高就可以用完全二叉树的算法去算,即log(n+1)向下取整

分块查找
其实分块的最佳储存结构是索引数组+n条链表,操作系统里也会有类似结构出现(比如文件索引)
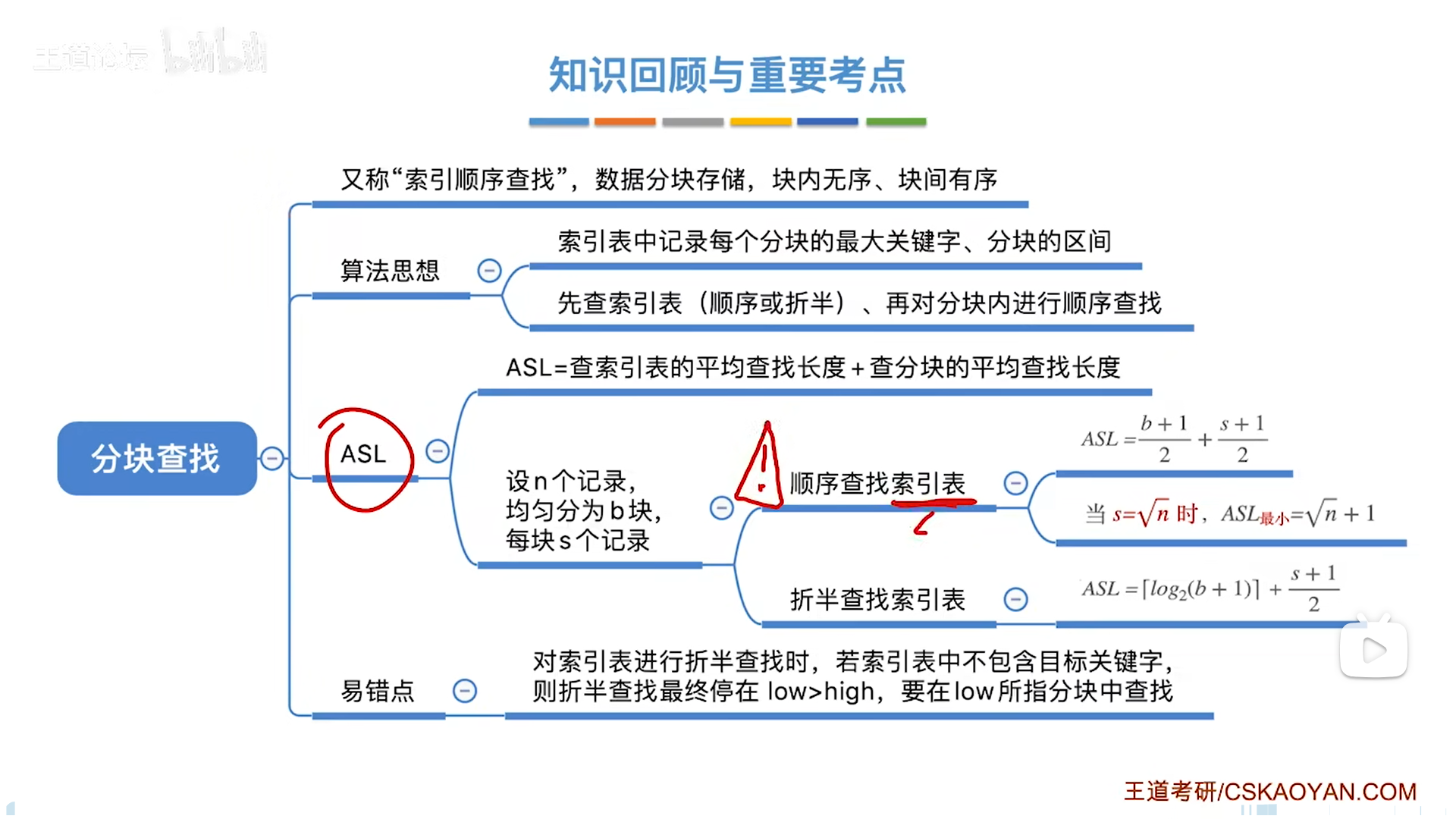
分块查找=索引+顺序,索引用来缩减范围,进而使得顺序查找次数更少
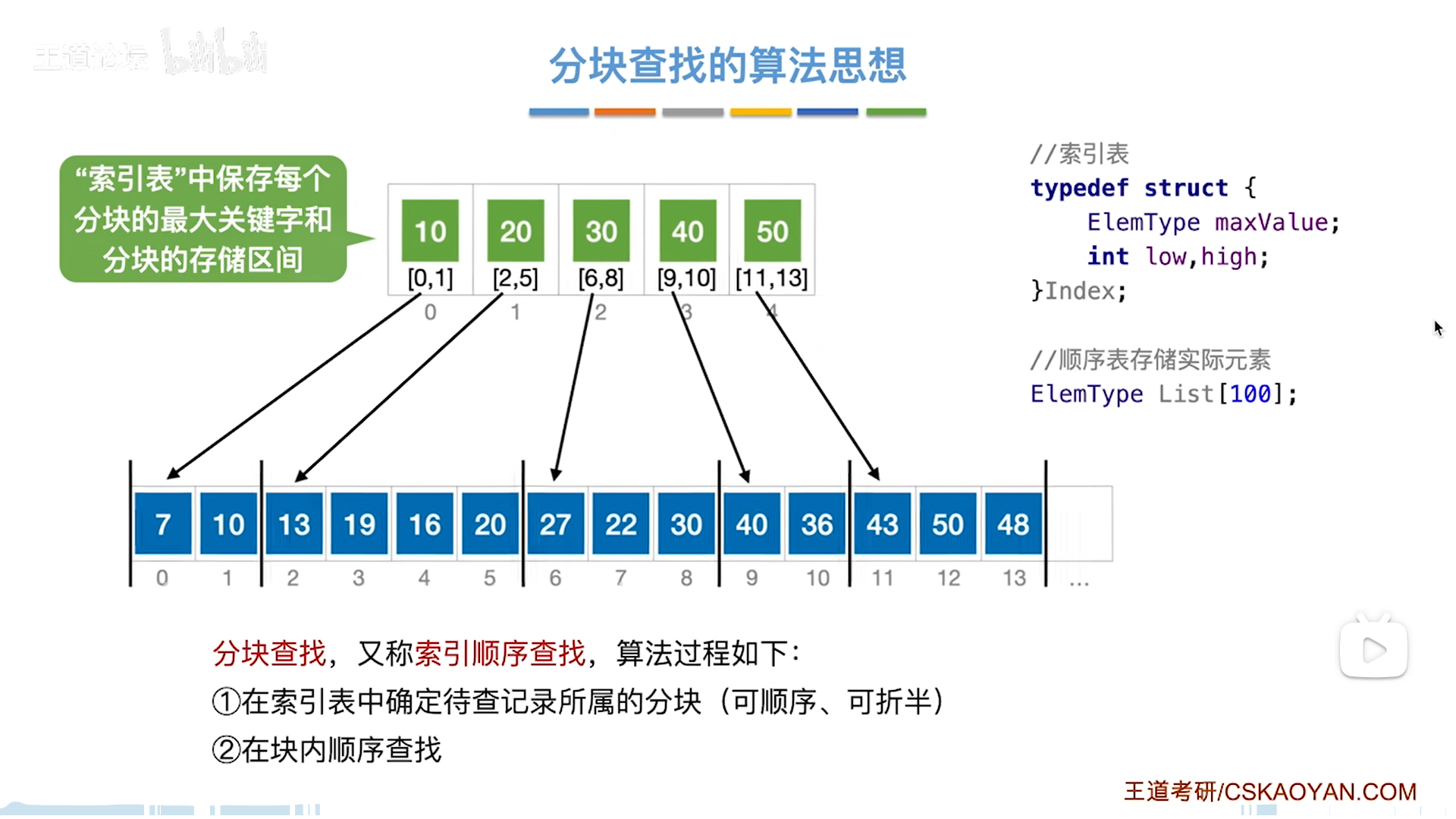
值得讨论的是查找索引的过程。
首先要明白,索引中的maxValue代表索引中最大的值(包括最大),这是后面讨论的基础:
- mid=key,这种情况其实比较少见
- mid≠key,则最终一定会停在low上
- 最终high在左,low在右
- 因为low左边都是小于目标key的,根据前面maxValue的意义,索引的值都小于key了,那必然不存在,所以low左边是不可能的(太小),而low右边又太大了,那么最后就会卡在low上
- 假如low越界,代表所有索引对应的块都不可能存在目标key

对于每一个节点,其SL=索引查找次数+顺序查找次数
需要注意折半情况下的索引查找次数,分析起来比较复杂,假如key≠mid,那么最后就要反复调整直到high<low的时候,这才是真正的索引次数。
因为SL有两部分,而且相关联,所以算ASL比较麻烦,为了便于分析,直接把数组等分,那么这两部分的关联性就打破了,可以分别计算ASL1和ASL2,最后相加。

具体分析,顺序情况下,n=sb,因此把b=n/s带进去ASL就可以得到一个式子,进而求得极限情况的ASL
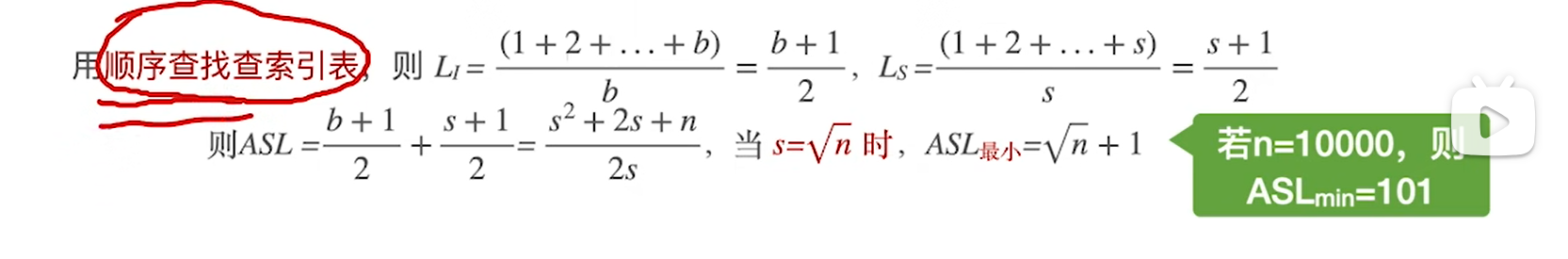

其实这才是最完美的索引顺序结构。
树查找
二叉排序树可以说是,带有伸缩功能的顺序数组,只是说不平衡会导致其效率退化
而进一步的AVL树,弥补了不平衡的问题,在保证伸缩性的前提下,最大化逼近数组的效率
可以说是比较完美的结构了。
二叉排序树(BST)
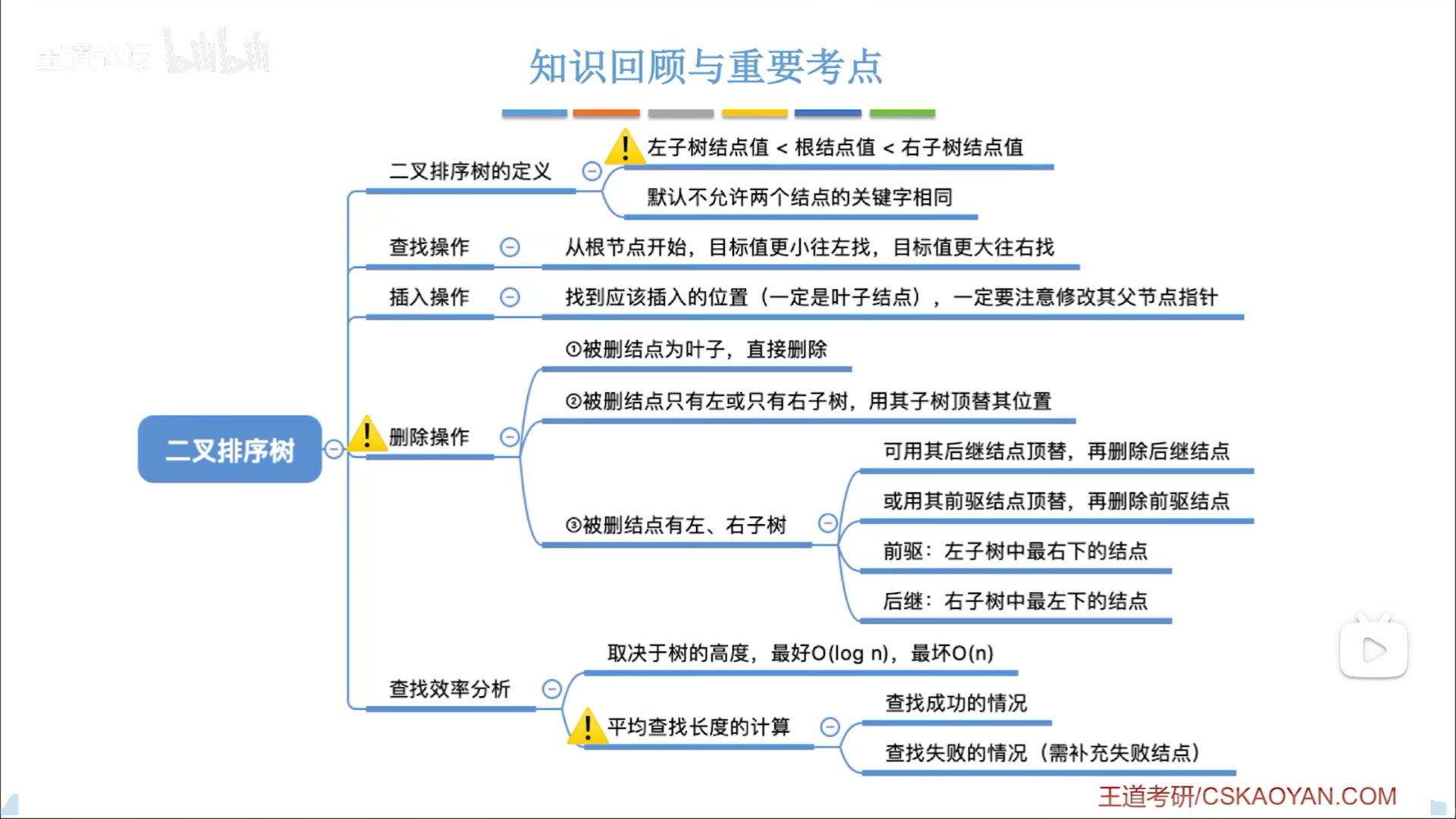
递归和循环的思路一样:
- 退出条件:空,或者匹配到
- 否则就查左/右子树

插入,就是要找到插入点位:
- 有一样的,失败
- 没有一样的,生成新节点,令父节点链域指向该节点。
- 父节点指针从何而来?需要注意BSTree &T,也就是说,在最后T==0的时候,这个T不仅仅是空指针,其本身还是父节点的孩子链域,因此我们直接把T指向新节点就可以了,在第一步就完成了。
- 记得初始化左右孩子为NULL
有了插入后,给定一个T=NULL的初始链域,就可以反复插入,形成二叉树。
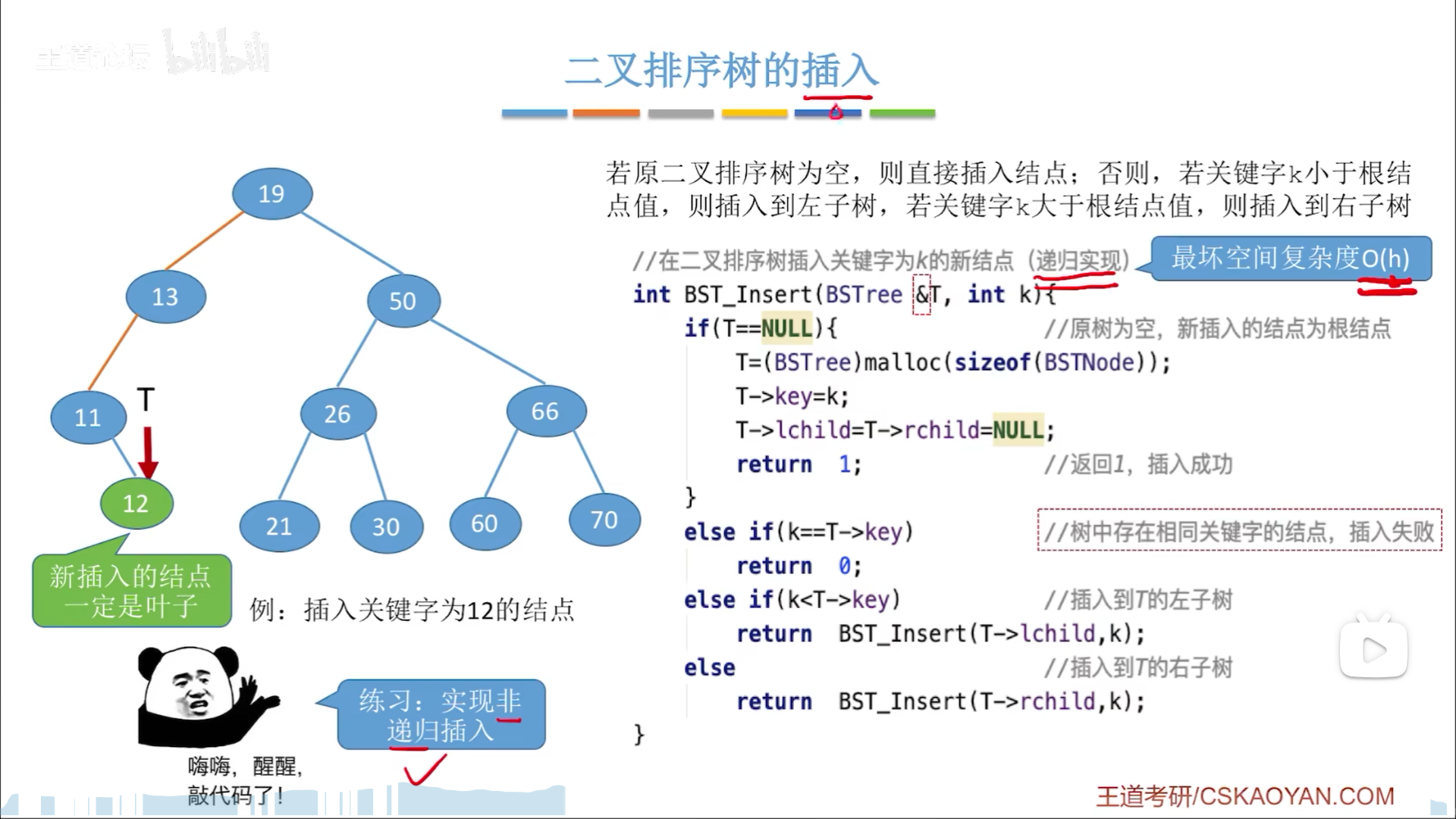
删除节点,这个涉及到树结构的重构,比较复杂:
- 叶子结点
- 只有单边孩子
- 有双边孩子,按照中序序列,上层是左根右,展开后变为(左根
右)根(左根右),删去根后有两种顶替思路- 以右子树最左边的节点顶替根(大中最小),那么拆掉的这个节点又该怎么补呢?恰好最左边的节点,一定不可能有左子树,这就划归到了2情况
- 左侧情况反过来就行

查找效率用ASL评估,这俩在查找中是等价的。
给定具体的一个例子,成功的ASL则要去计算n个成功节点的加权,而失败则要补n+1个失败节点,再加权
下图表示,二叉树查找的平均效率与其高度成正比,那么理想情况是把高度压制成平衡二叉树,这就是后面的内容了。

平衡二叉树(AVL)的插入
平衡化
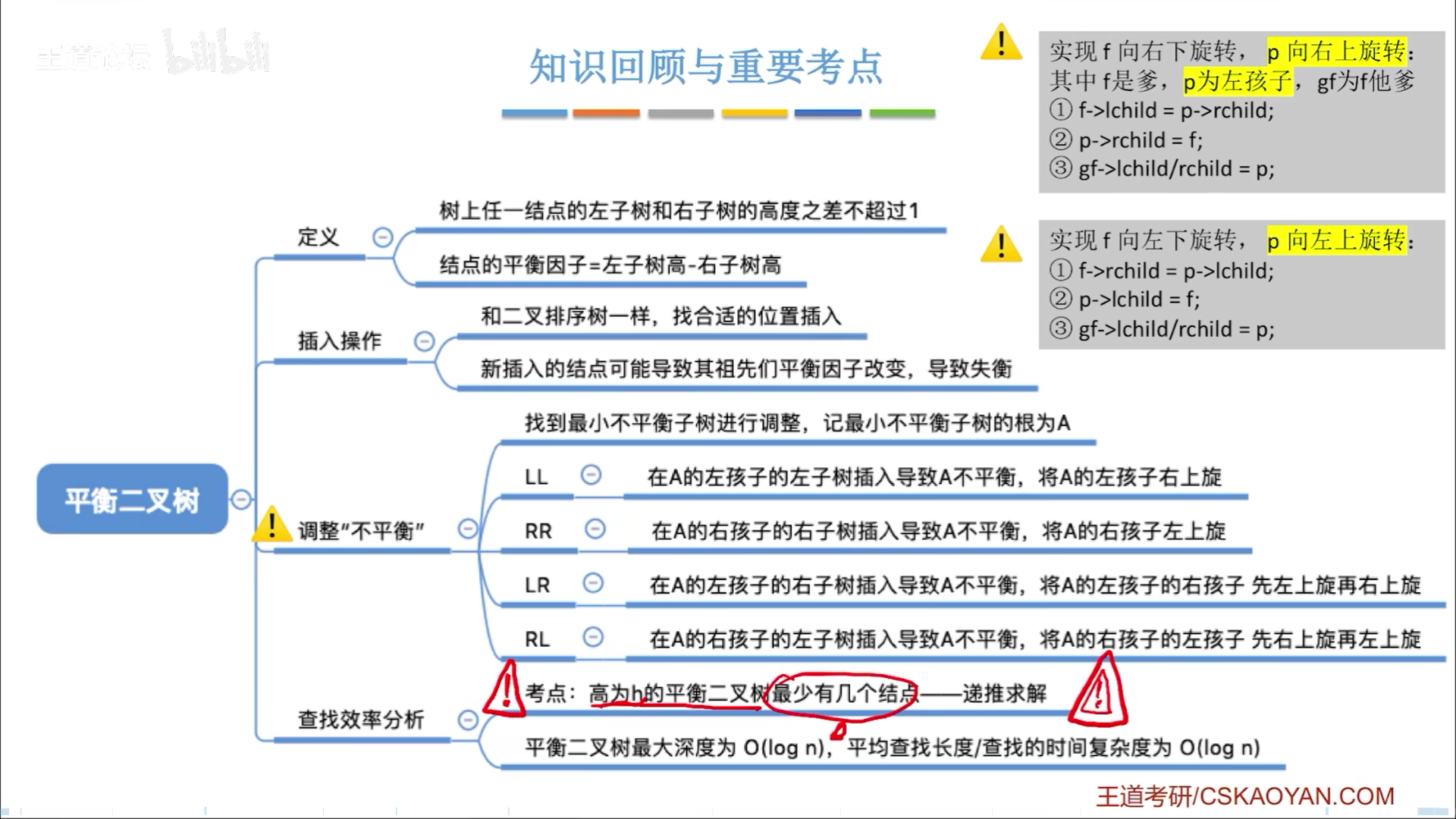
平衡二叉树,任一节点的平衡因子(左-右)都只可能是-1,0,1,如果添加节点导致破坏平衡性,就要找到最小不平衡树,进行平衡化修正

以最小不平衡树根节点为A,则不平衡无非就是四种情况,LL,LR,RL,RR,这四种情况的记忆方法如下:
- 第一个字母代表A的左右子树
- 第二个字母代表子树的左右孩子
因此LL就是左子树左孩子插入,导致不平衡,到时候自己画图就好。
首先要说明,三个子树都是H高度,这个是铁定的,否则插入就不会破坏平衡性。
LL和RR比较简单,本质在于让B当根节点,因此转一下就行
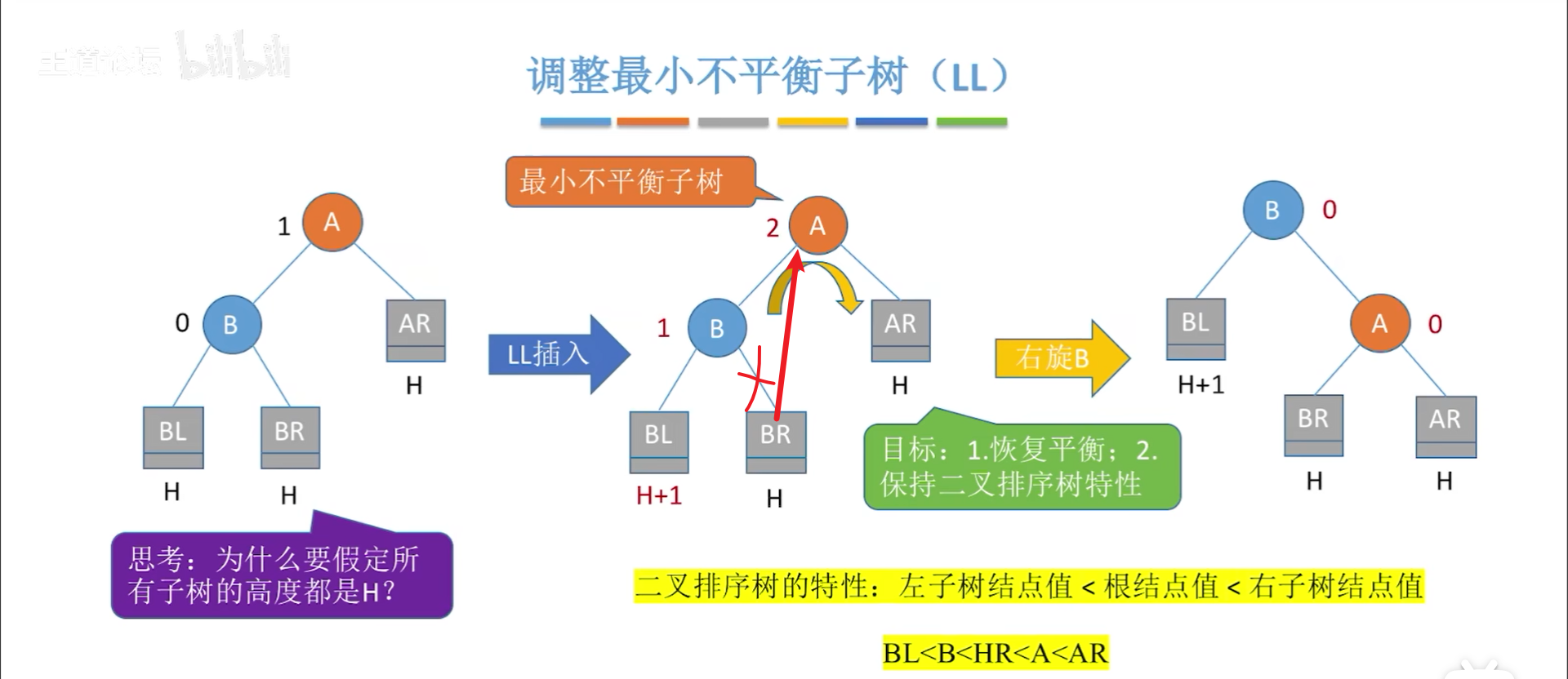

看下操作,实际上是要让B当根,A当孩子,因此分三步,写旋转代码要按这三个步骤来:
- 替换A的左孩子,此时A成为一颗可以随意挪动的树
- 让A成为B的孩子
- 让B成为根节点

LR和RL复杂一些,对于LR,具体还要把L子树的R孩子(高度为H+1)继续展开,以便于分析,但是实际上,这两种情况是一样的,因此假定是下图情况。
但是实际上本质不变,最终的目标是让C当根节点,BA分别为左右,那么C就要转两下,先和B在和A,这样C就可以变成根节点,两次旋转沿用前面的思路即可。
RL也是如此,最终要让C当根节点。

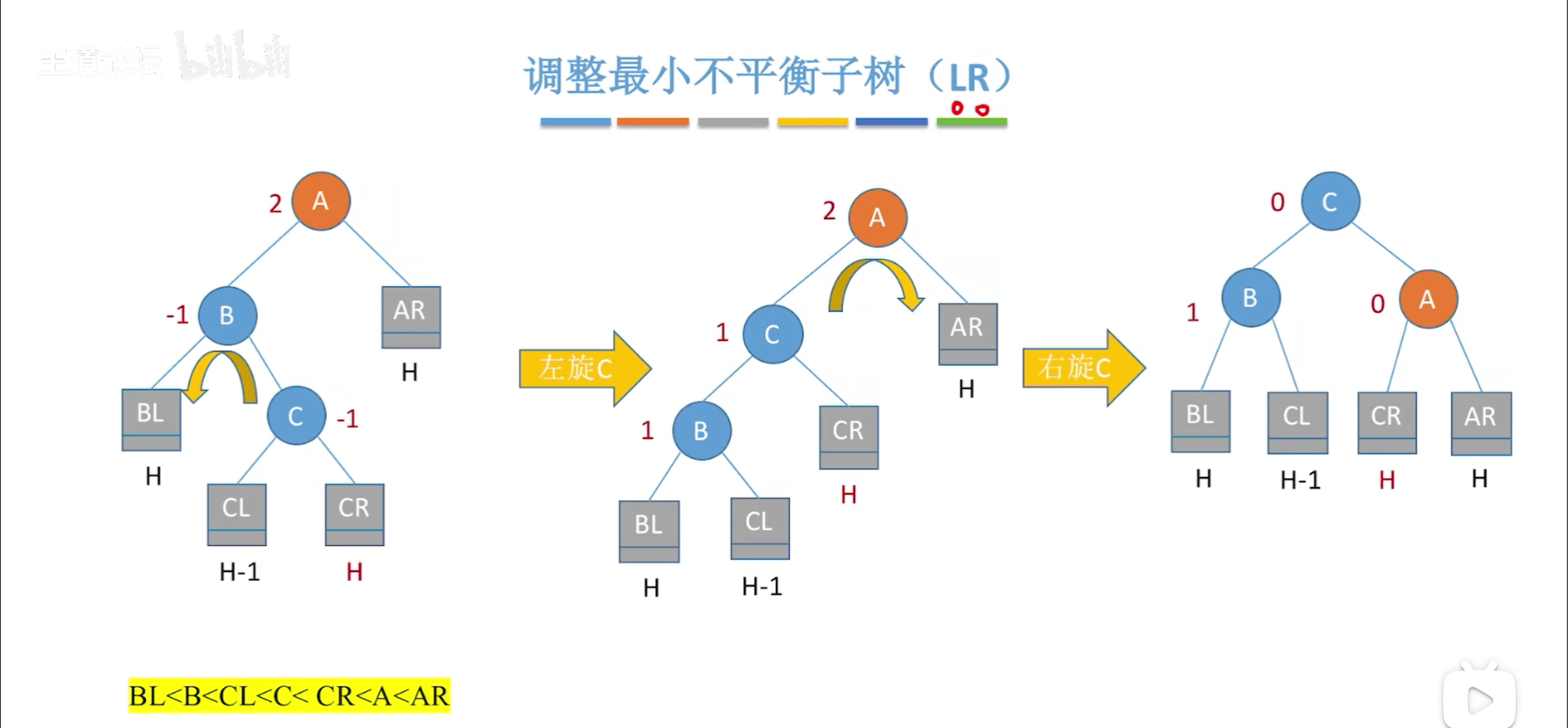

最后再整体总结一下,你会发现4类情况,最小不平衡子树本来都是H+2高度,然后插入新节点变成H+3,破坏平衡性,调整以后重归H+2,同时平衡性保持住了
之所以只调整最小不平衡树就可以保证整体平衡性,是因为这一通调整将多出来的高度抹平了,更上面的节点的平衡因子自然就退回到平衡状态了。
我们把眼光落实在做题上:你要盯一眼,从下往上找到第一个不平衡的节点,代表最小不平衡树的根节点,然后回忆4种情况,标上ABC,剩下步骤就很简单了,如此就秒杀了。

复杂度分析
无论是插入还是删除,费时间的其实还是查找目标位置,说白了ASL和查找是一样的,调平衡度不影响。
再有就是复杂度分析,ASL=层数,即O(h)效率,关键在于如何通过节点数量n计算h的上界(或者通过h计算n的下界)
这是个数学问题,根本在于AVL的特性,即平衡因子最多为1,那么极限情况就是高度为h的树,一颗子树高度为h-1,另一颗为h-2,因此这颗树的节点数 n h = n h − 1 + n h − 2 + 1 n_h=n_{h-1}+n{h-2}+1 nh=nh−1+nh−2+1=左子树+右子树+根
考虑初始情况,高度为012,最少节点也是012,按照递推就可以计算出任何高度的节点数下界。
反过来,已知n,就可以知道h上界
最后算ASL,经过一通推导,结果就是O(logN)

平衡二叉树的删除
第一步是按照二叉排序树删除,这一步本身就挺麻烦
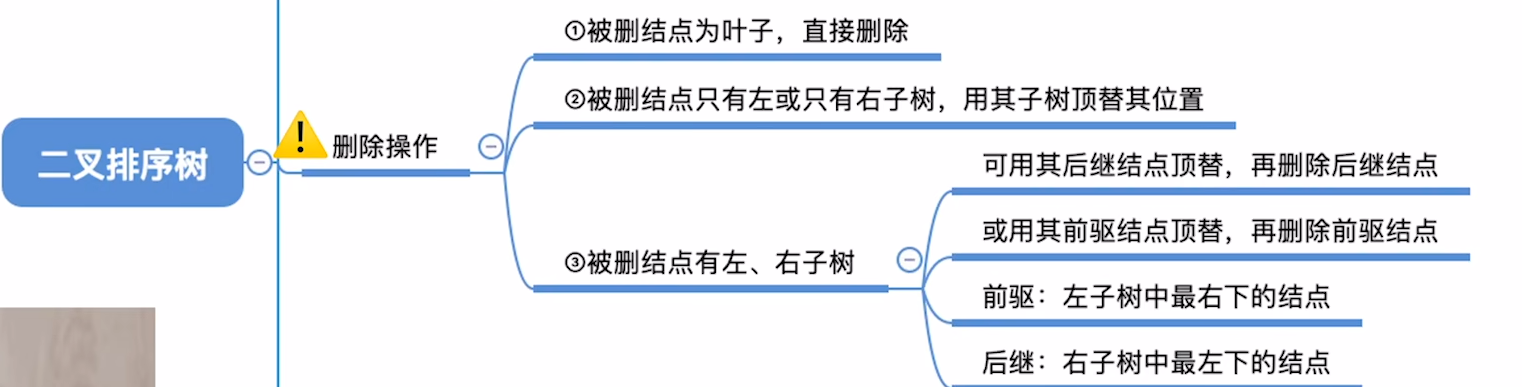
先看一个简单的例子,熟悉流程
- 从删去点向上找,找到第一个不平衡节点,这就是最小不平衡树的根
- 从根开始,找个头最高的儿子和孙子,其实就是从上往下,找到不平衡的传导链条
- 判断4类不平衡情况,进行旋转
- 这一步可以使得不平衡部分的H减小1,这样可能会导致树的另一侧过高失衡,要二次调整,回到1步开始
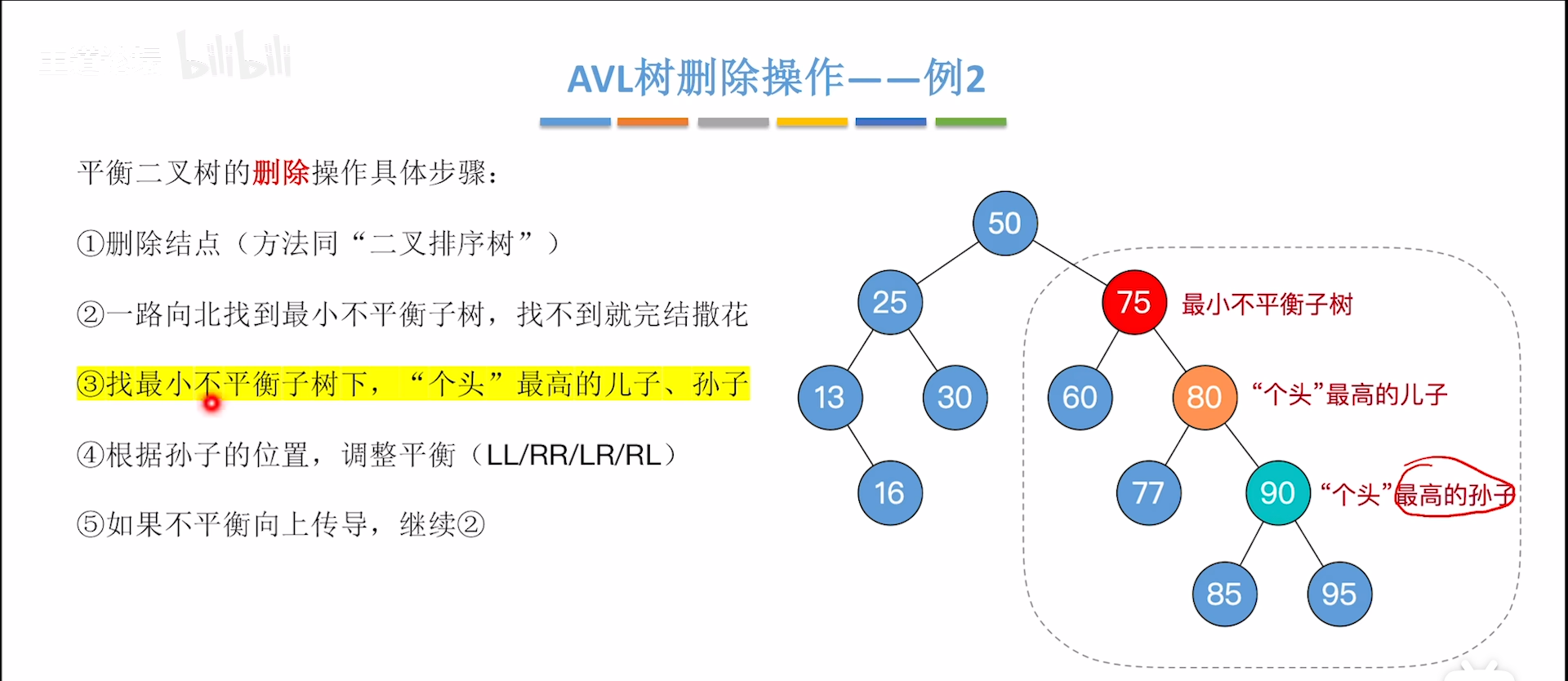
接下来举一个需要二次平衡的例子,下图进行第一次平衡后,右子树高度减一,导致左子树太高。
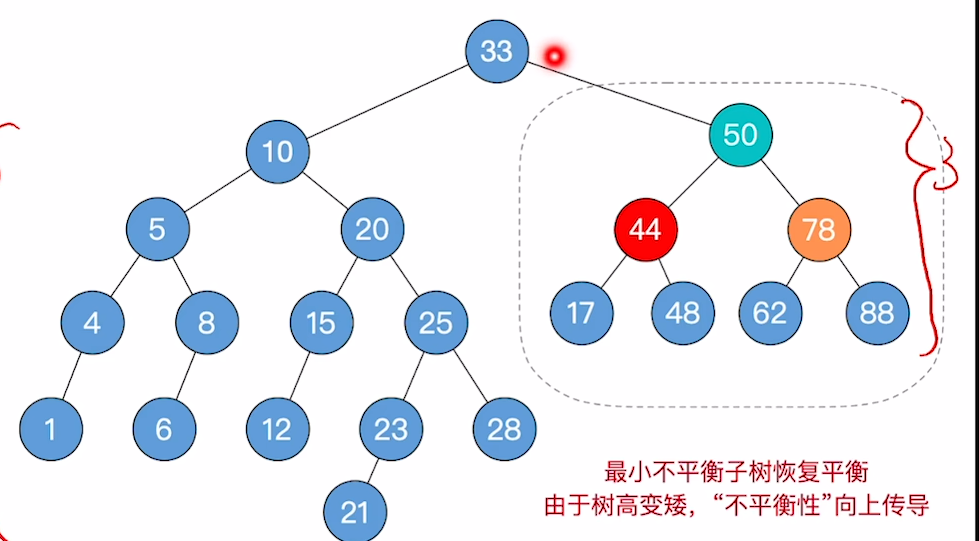
跳回到1步:
- 从调整点位开始向上找,找到第一个不平衡点,即33
- 然后从根节点开始向下找不平衡链条,为33-10-20
- 进行翻转,即可平衡
有没有可能出现第三次不平衡?有可能,因为我们这次找到根恰好也是整个树的根,因此一步到位,假设我们找到的根上面还有东西,那么这一层降低高度后还有可能导致另一侧失衡,总之是一定要向上找是否失衡

考试中可能出现的最极限的情况是,删除的节点同时有左右孩子,那么这个时候就有两种删除方案。
后面仍然按照我们的流程来进行调整
但是这其实就有歧义了,408不太可能出这种,最后提一嘴,复杂度同查找,O(logN)

红黑树
红黑树的定义和性质
虽说AVL的复杂度是logN,但是实际上,每次找最小不平衡树比较费时间,实际消耗时间会有一个常数级别的放大,如果要频繁改变结构,就比较慢,红黑树应运而生。
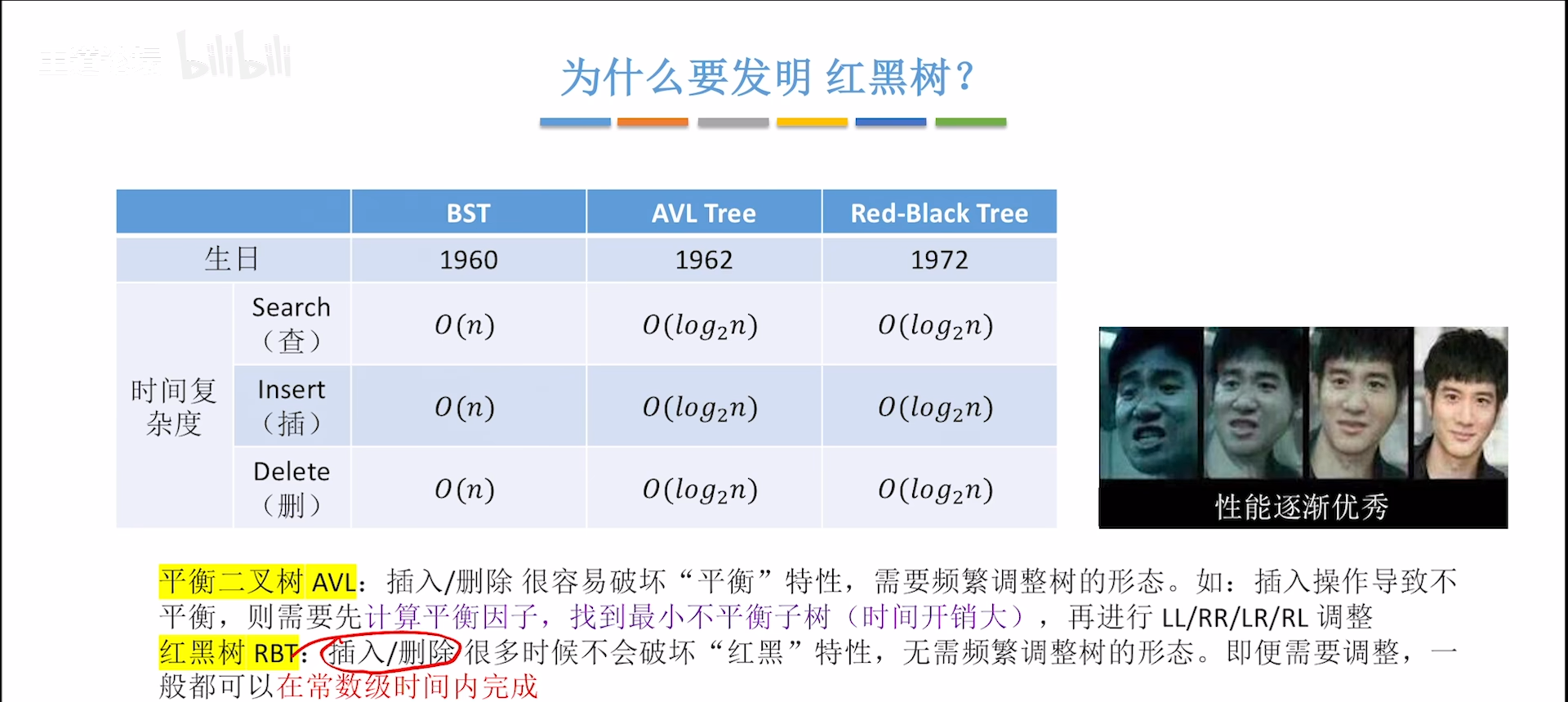
首先明白,红黑树是从BST,AVL一脉相承过来的,所以本身也具有BST性质:左<根<右
或者说,AVL和红黑树都是BST的改进,AVL和红黑树严格来说是并列关系,但是性能是要碾压的
红黑树相比于BST来说,有两点改变:
- 使用三叉链表结构
- 增加了节点的红黑特性(对标AVL的平衡因子,但是有所不同)
红黑树定义
多出来的两个信息,可以为操作带来诸多方便,理解一下下面的规律:
- 左根右。这告诉我们红黑树的本质还是BST
- 根叶黑。根节点和叶节点都是黑色的
- 叶节点并不是我们传统意义上的叶节点,而是代表(外部,NULL,失败),这三个说法是等同的,也就是我们之前判定树计算失败ASL时补上的节点。
- 与叶节点对应的就是内部节点,就是有具体意义的节点,可以成功的节点。
- 不红红。不存在相邻的红节点
- 这是对红节点的限制,但是黑节点无所谓,可以相邻
- 黑路同。任意节点(不一定只是根节点)到任一叶节点的通路上,路过的黑节点数量相同
- 这是对黑节点的限制,同理红节点无所谓

一个基本功就是判断红黑树是否符合定义,大致思路如下:
- 根叶黑。先看根节点和叶节点
- 不红红。扫一眼看看有没有红节点相邻
- 黑路同。这个就比较复杂了,你在看一眼黑色聚集的比较多的地方,那些地方极有可能会出现黑色路径过长,黑节点太多的问题
- 左根右。这个也
容易埋坑,你要知道红黑树首先是一颗BST,所以如果出题很阴,会出在这里。

下面这道题很阴,看哪个7,好在这种情况一般是出现在前三条都失效的时候,此时选择题里估计最多剩俩选项,硬着头皮细心对比就行

红黑树性质
性质清单:
- 黑高定义,h
- 给定h,内部节点下界
- 给定h,内部节点上界(红节点上界)
- 最长路径最多是最短路径的两倍
- 给定n,设H为总高度(非黑高),则高度上界 H ≤ 2 l o g 2 ( n + 1 ) H≤2log_2(n+1) H≤2log2(n+1)
前面铺垫一大堆,都是规定,通过这些复杂的规定,可以产生很多有趣的性质,这才是红黑树高效率的开始。
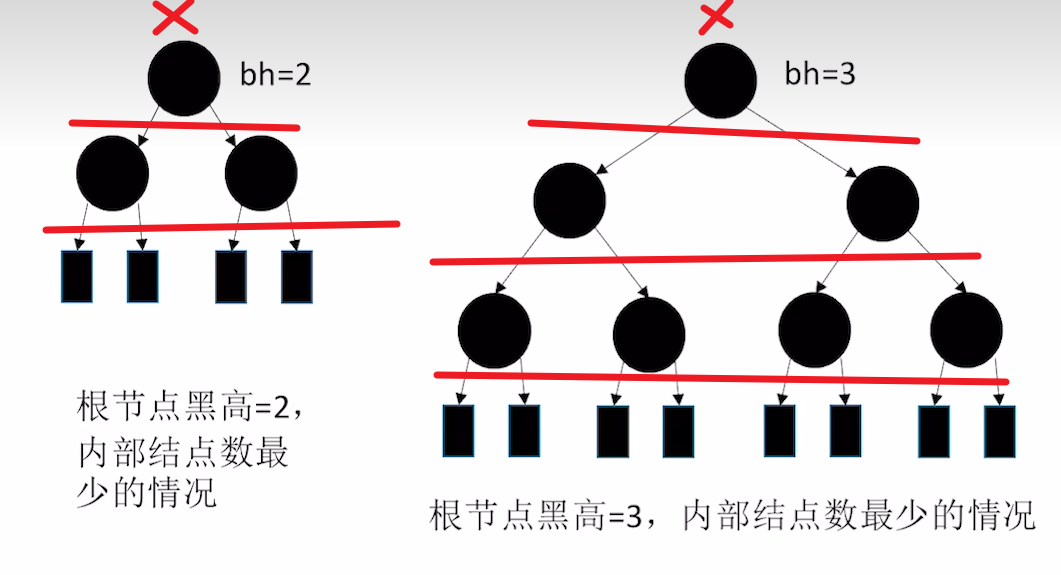
首先从“黑路同”里衍生一个概念:
黑高,即从这个节点开始,走到任意一个叶节点经过的黑节点个数(不包括自己)
根据黑路同逻辑,一个节点的黑高一定是一个具体的值,从一个特定节点开始,无论是从那条路走,黑高都是一致的,因此用统一的值描述。
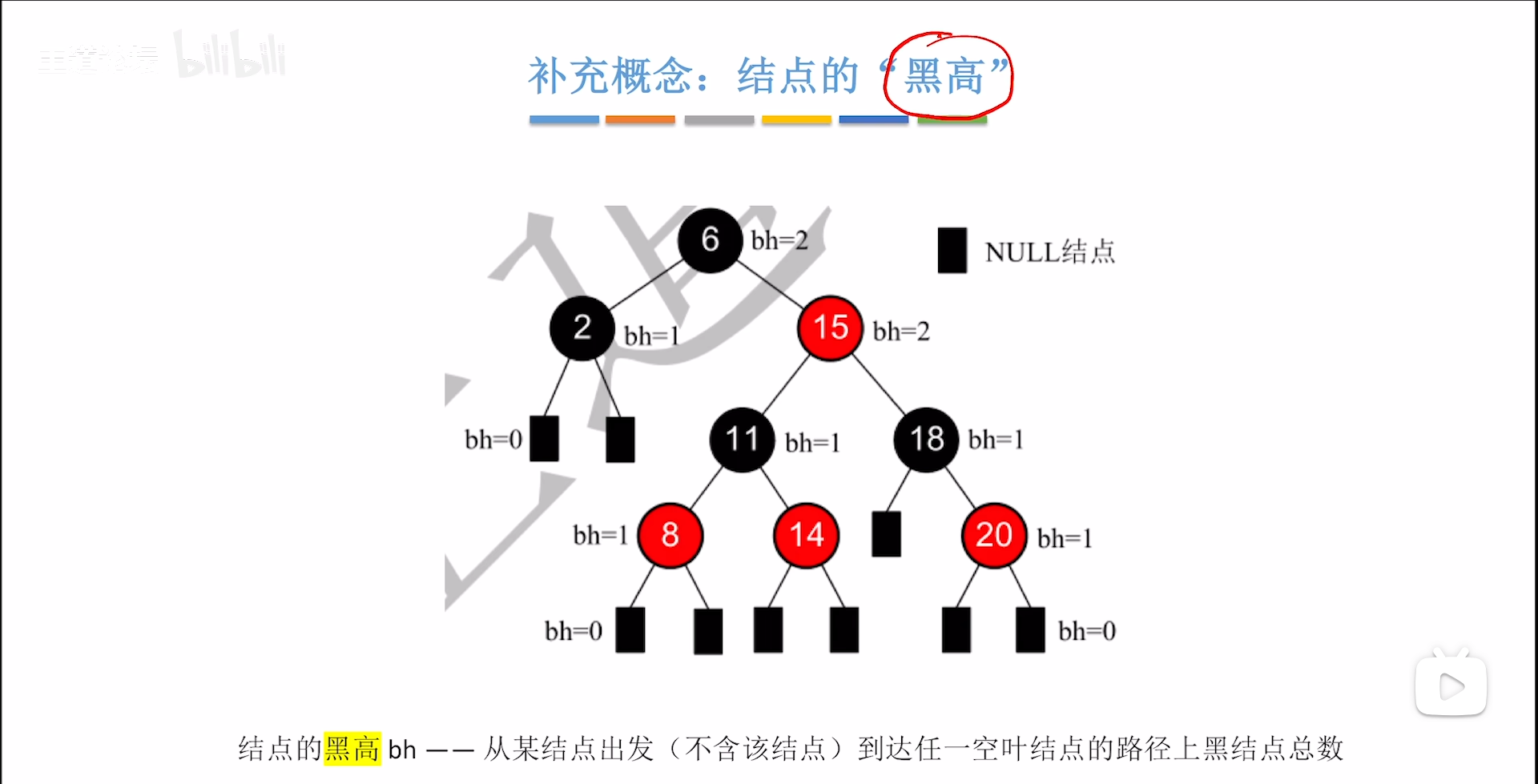
其实我们更深地考虑一下,黑路同这个特性很好玩,如果不考虑红节点的话,纯黑情况下一定是满二叉树,黑高就是内部节点的层数,因此黑高为h的红黑树,内部节点至少是 2 h − 1 2^h-1 2h−1

而红黑树是什么东西呢?其实就是在一个满二叉黑树之间,尽可能塞入不重复的红节点,那么给定黑高为h,极限情况下,可以塞入 2 h + 1 − 2 2^{h+1}-2 2h+1−2个红节点,
这个的计算如下图,给定h为黑高,算上最顶上的那个×,总共可以塞h+1层红节点,即 2 h + 1 − 1 2^{h+1}-1 2h+1−1个,然后你再去掉顶部×这个不能加的节点,因此就是-2
其次再论两个性质:
- 根节点到叶节点的极限路径长,最多为两倍关系
- 最短路径为纯黑
- 最长路径为从黑(根节点)开始:红-黑-红-黑,实际上路径就是一红一黑,插入尽可能多的红节点,也就是最短路径的两倍
- 给定内部节点N,则极限高度为2log(N+1),因此查找操作的ASL和AVL一致


红黑树的插入
如何构建一颗红黑树?
或者说如何在插入的时候保持红黑特性?
这就是本章研究的问题
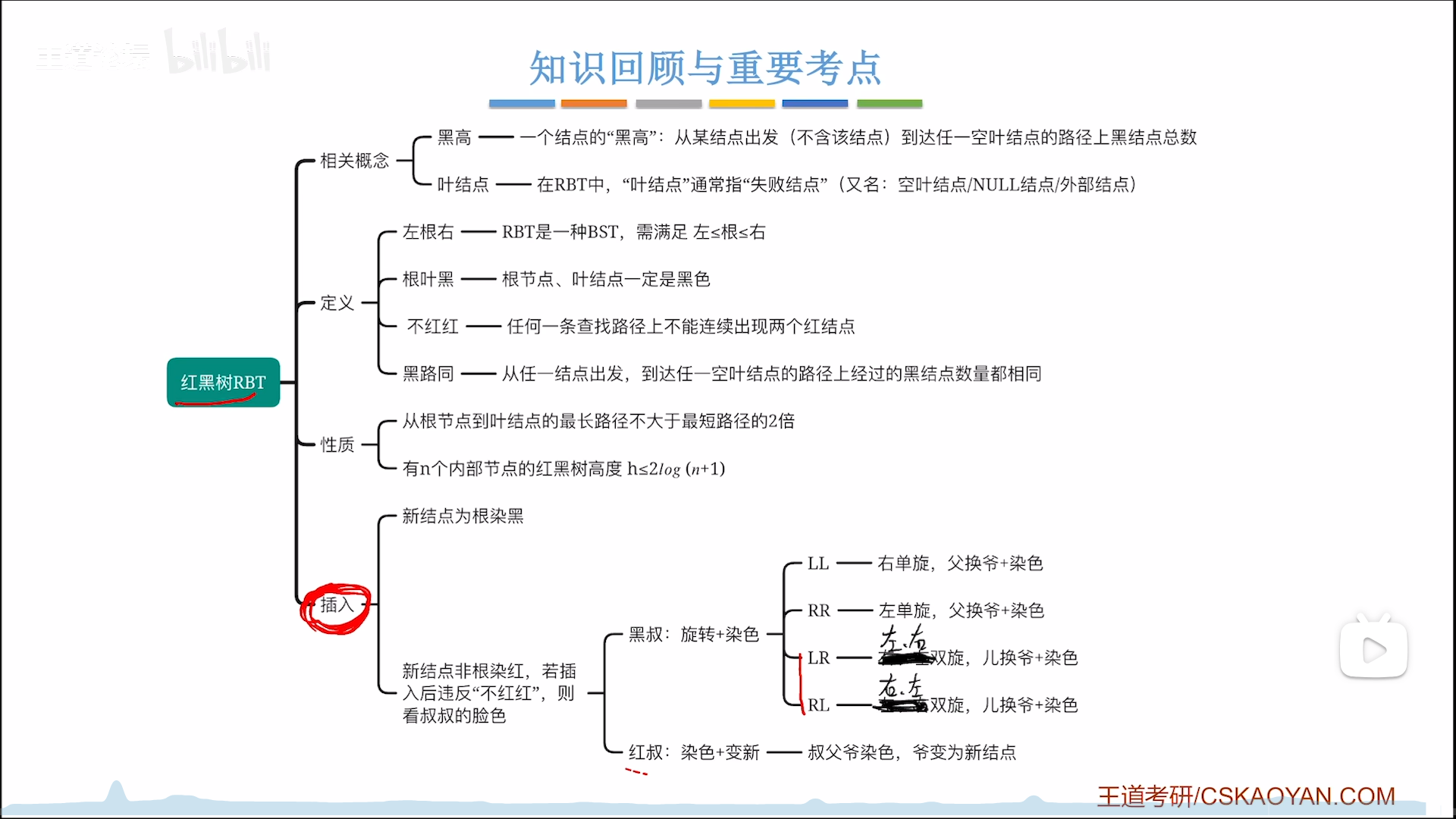
插入一个节点操作如下:
- 根节点染黑,根叶黑
- 非根节点染红,能够保证黑路同
- 可能不平衡,1,2条可以保证根叶黑,黑路同,而找节点的过程也满足BST特性,因此唯一可能不满足定义的地方就是红节点连续,而且不平衡只可能在非根节点时候发生
- 因此不平衡=红节点连续,调整要看
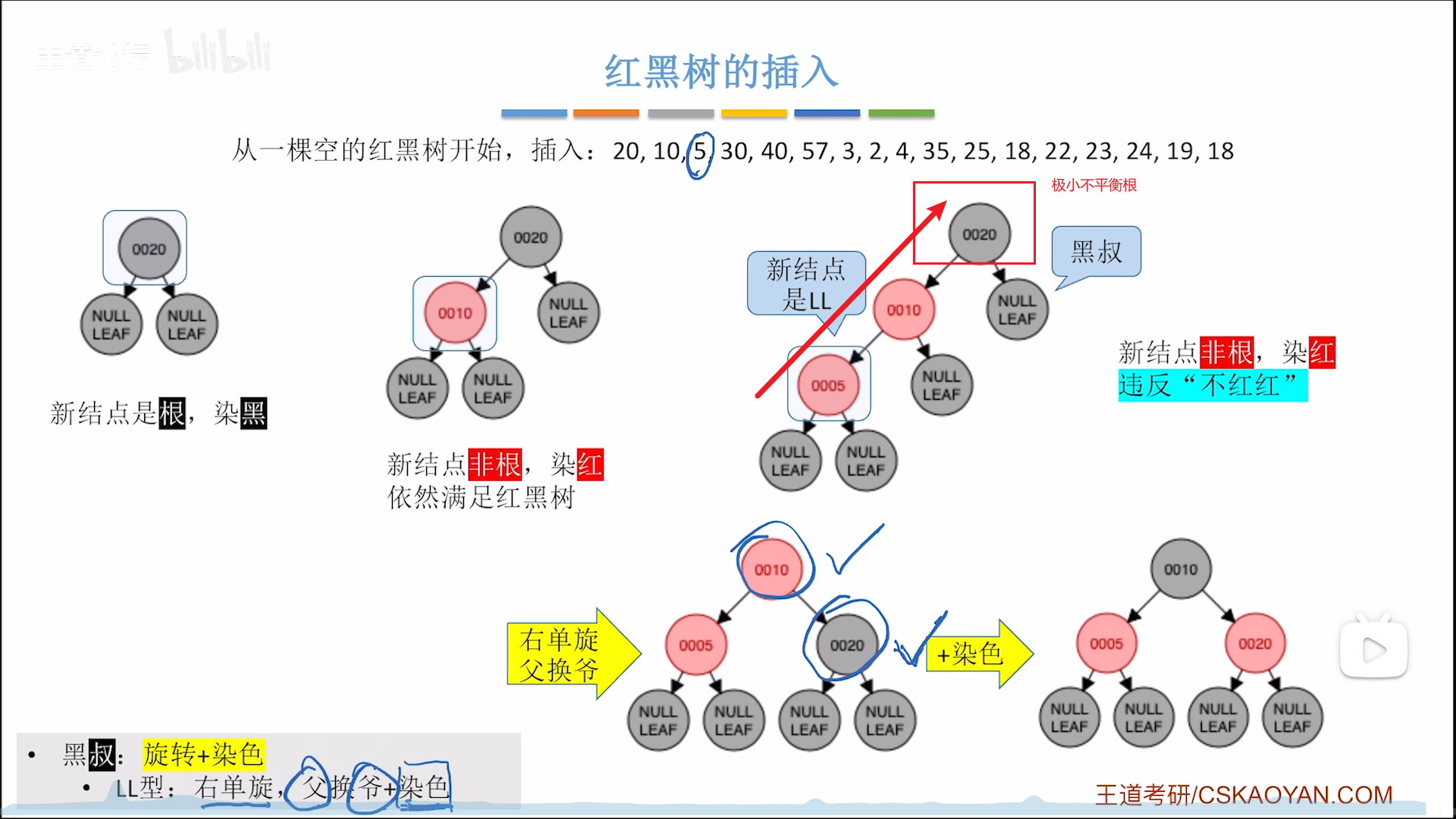
叔 - 叔黑,旋转+染色
- 首先要找到旋转的极大不平衡根节点,从下面插入的儿往上,上层为父,上上层为爷,爷其实就对应AVL里面极大不平衡树的根节点
- 对于LL,RR型,父爷换,之后令交换的两个节点反色
- 对于LR,RL型,把儿换到爷位,之后令交换的两个节点(爷儿)反色,父节点不反色
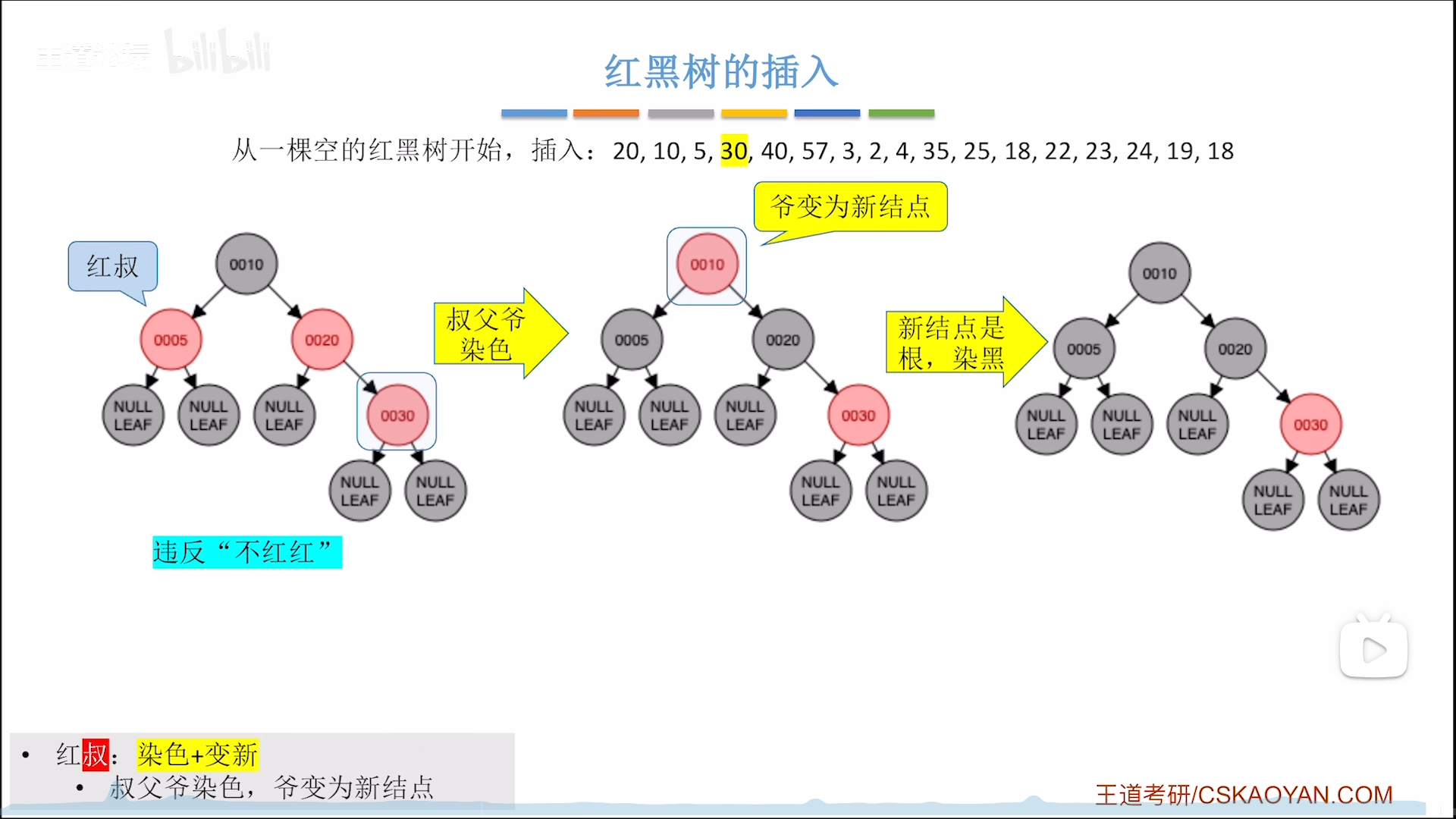
- 叔红,反色+判新(不用调整结构)
- 反色部分为父叔爷,其实就是把
上面两层反色 - 判新,指把爷当做新节点,跳到第1步
- 反色部分为父叔爷,其实就是把

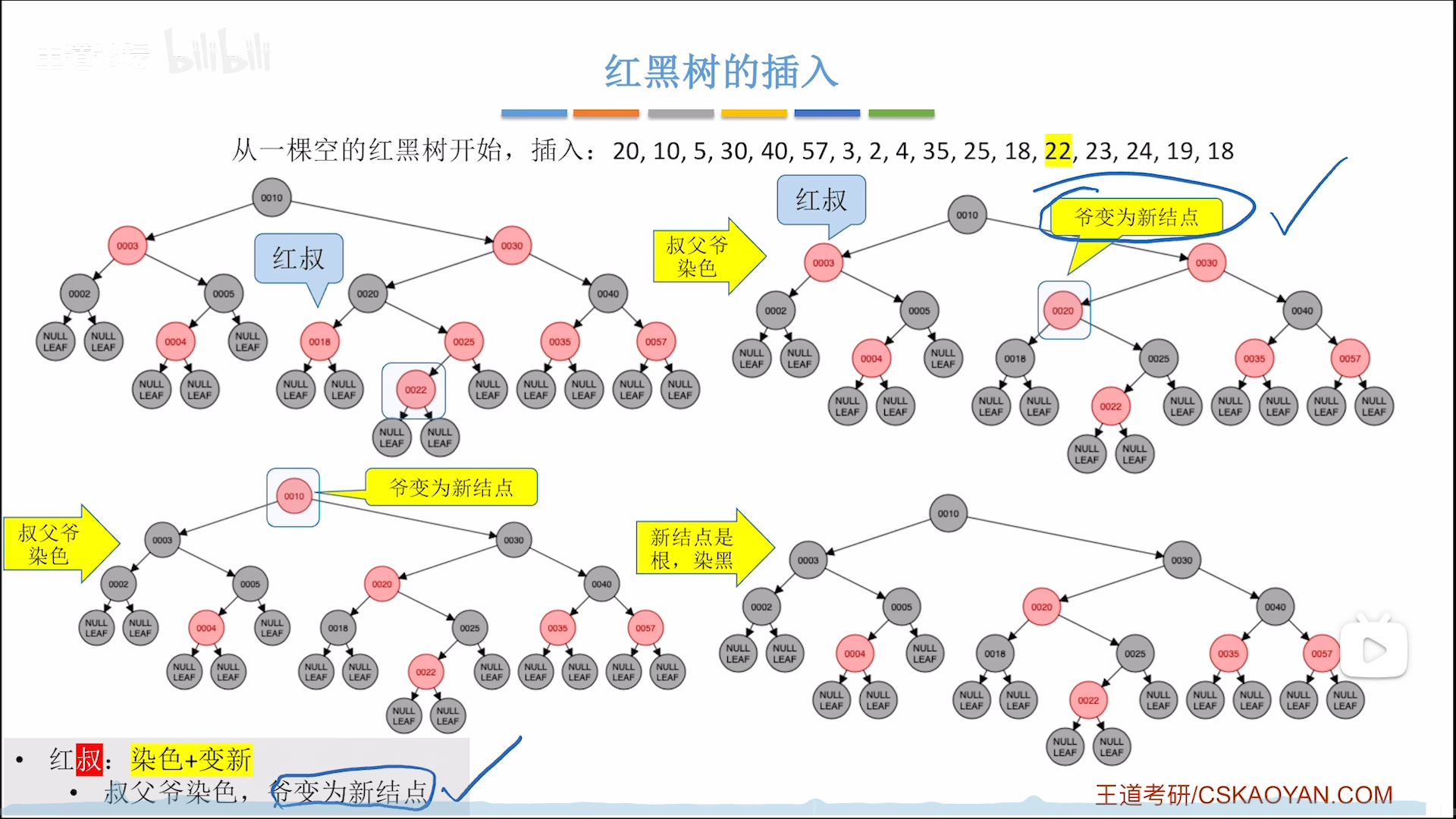
下面这个例子是:不平衡+黑叔+LL/RR型,先单旋再反色
下面这个例子是:不平衡+红叔,则反色上两层
然后以爷为新节点,再判断一轮,此时为:根,染黑
当红黑树逐渐变大,你会发现红黑树有一个有趣的特性,就是大部分情况下是不需要调整的(其实AVL和红黑树的最终目标都是平衡,那么AVL其实也差不了太多,关键在于AVL需要去向上找最大不平衡根,而红黑树的爷就是最大不平衡根,寻根效率更高,这才是红黑树碾压AVL的本质)
下图是一种连锁反应,这种连锁反应只可能在不平衡+红叔时发生,因为爷要当做新节点,跳回1,会触发连锁反应。
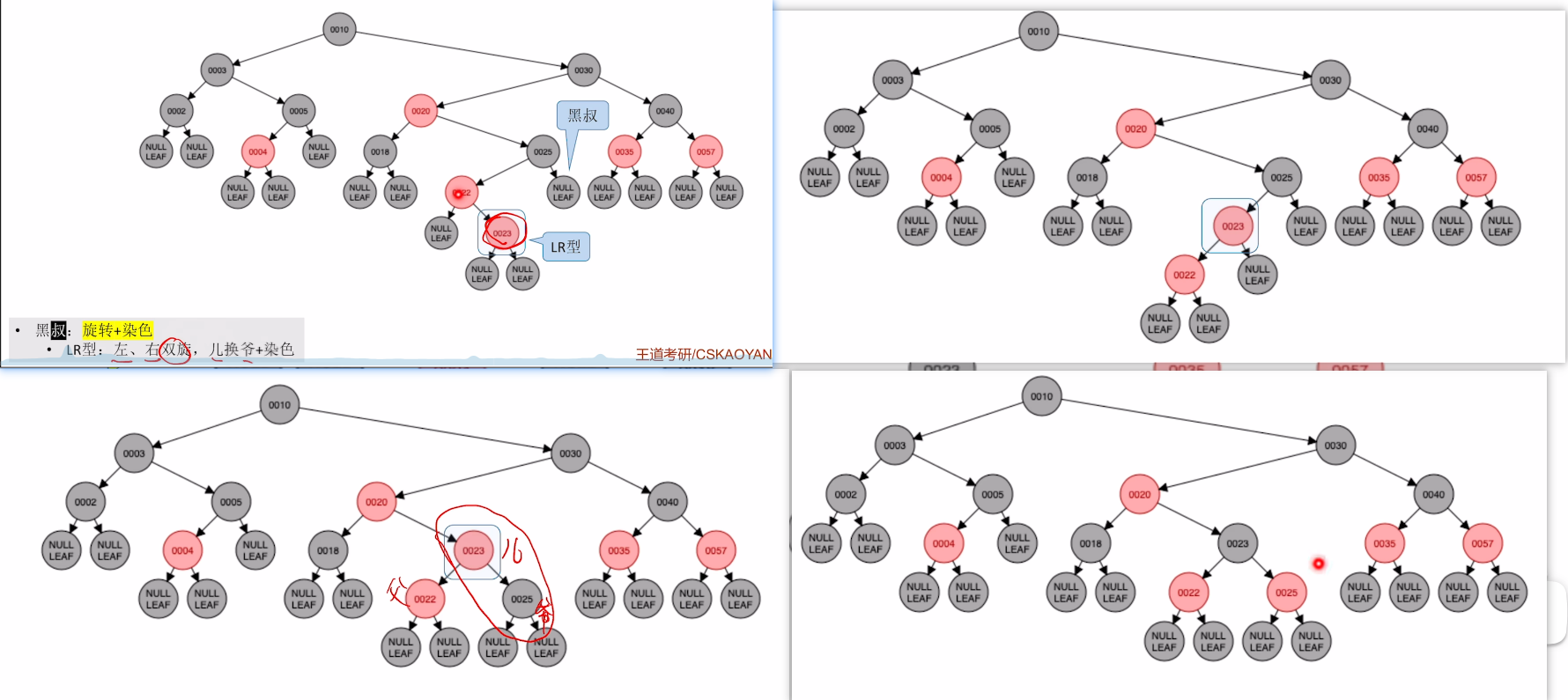
再来看一个LR的例子:不平衡+黑叔+LR=旋转+反色
- 先旋转两下
- 然后进行反色,注意只反爷儿,父不管
红黑树的删除
虽然视频没说,但是我脑子里已经有一个大致的思路了,因为删除的思路和插入其实一样。
首先按照BST删除思路,进行删除
之后必然面对结构破坏的问题,就要进行调整,我们可以利用一个逆向思维,假设自己是在进行插入操作,就当他是插入操作导致的结构破坏,然后我们用插入的思路来调整结构。
而这个思路的关键在于,你要明确儿子节点到底是哪个,又或者干脆就利用红黑树定义去修改颜色和位置
到时候凭感觉就行了,真考出来咱们就大难临头各自飞,我自己也不知道(乐)

B树
B树基础
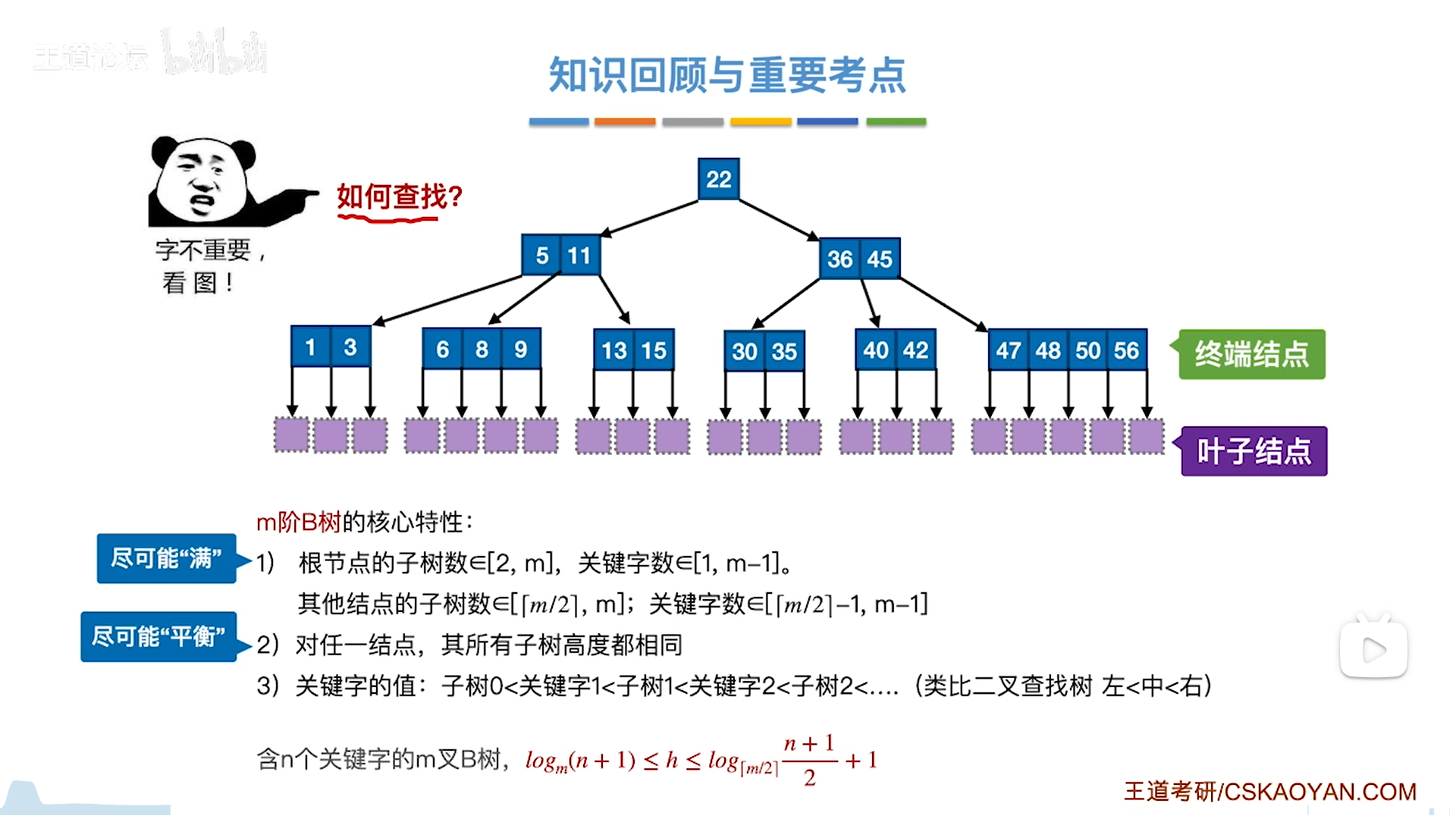
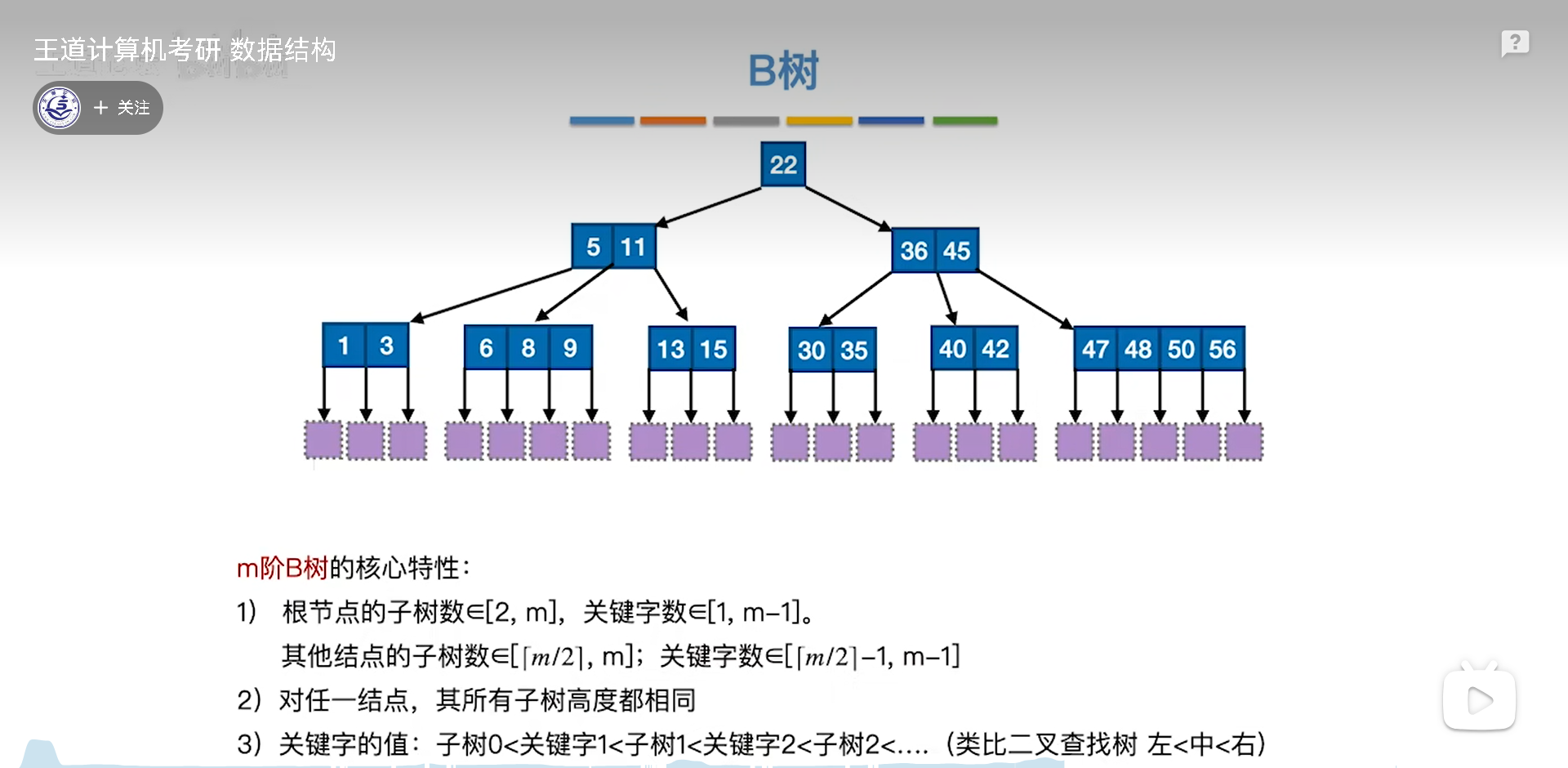
B数是BST的升级版,仍然保留了顺序性,如下图:
m阶B树,指的是m叉B树,其中有m个链域,m-1个关键字(BST实际上就是1个关键字,2个链域的B树)
要区分关键字和节点,一个节点里面可以有多个关键字,关键字=隔板
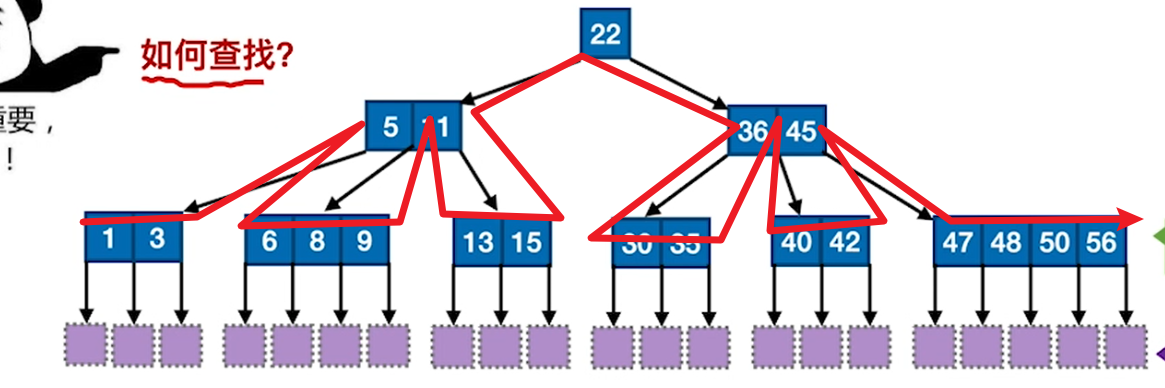
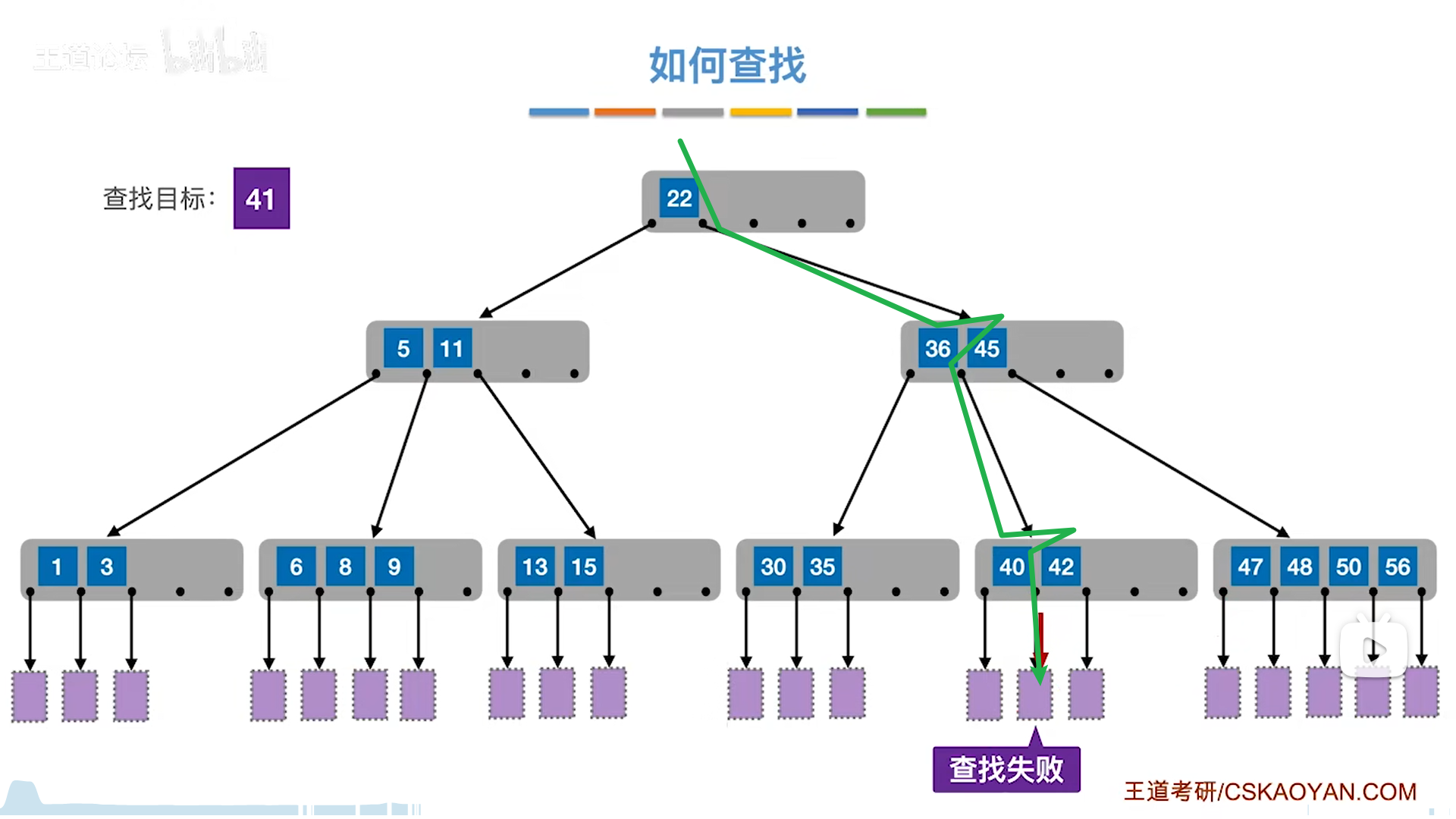
如何找一个key呢?
- 顺序匹配关键词,如果匹配到那就是相等
- 否则就要去找到两个隔板中间的一个链域,去找孩子
- 找到了就停,如果最后都没找到,即找到了NULL,就算失败。
每个关键字节点都是有序的,因此可以采用折半查找,我们这里都是用顺序去理解。

为了提高效率,B树强行规定了两个核心特色:
- 满,至少一半以上的链域
- 绝对平衡。这个绝对平衡,要求所有子树高度一样,不能有高度差
根据这两点,可以将节点分为四类:
- 根节点
- 普通节点,上有老下有小
- 终端节点,下面只有失败情况,只会出现在倒数第二层
- 叶子结点,失败,叶子只会出现在最后一层
叶子结点严格来说不是节点,只是臆想出来的,因此实际计算B树高度,是只考虑到终端节点的。
结合下面列出的核心特性,还可以引出一些具体的特色:
- 子树不可能只有一颗,非0情况下至少为2
- 因为要绝对平衡,一颗子树是不平衡的
- 非根节点的子树要求更高,非0情况下至少为m/2向上取整
- 结合1来看,以m=5举例,根节点要么为0,要么从2开始取,而非根要么0,要么从3开始取
- n个关键字,至少有n+1个叶子结点
- n个关键字,本质上是把总区间分割成n+1份,如果落在这n+1份区间内而不是隔板上,就是失败
设n为关键字数量,已知n,计算计算高度h的上下界:
注意,h下界是用的关键字数量计算,而h上界用的是节点数量(通过规则将关键字数量转化成了叶节点数量)
- 最小高度:尽可能满,
n≤关键字最大数量- 首先n是指总关键字个数,也就是key的个数(隔板的个数)
- 每个节点,最多有(m-1)个key,然后右边(1+···+ m h − 1 m^{h-1} mh−1)是总共的节点数 ,化简就是右式
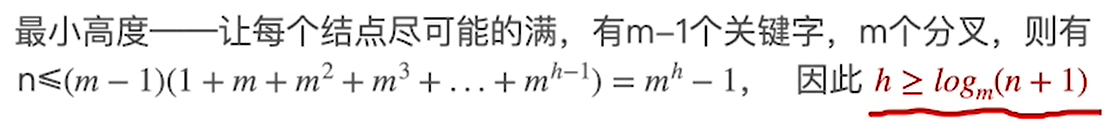
- 最大高度:尽可能分叉少,
叶节点个数n+1≥叶子层最少节点数- 分叉,根节点为2,非根为k=m/2向上取整
- 先推第h层最少节点数,第一层1,从2开始,则为 2 k h − 2 2k^{h-2} 2kh−2
- 因为n个关键字,叶节点为n+1个节点,所以n+1≥

B树插入和删除
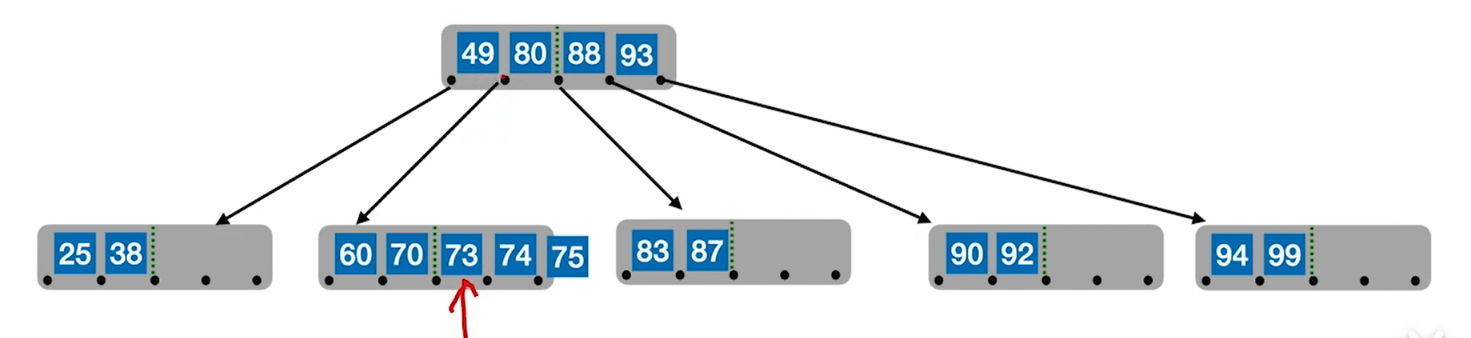
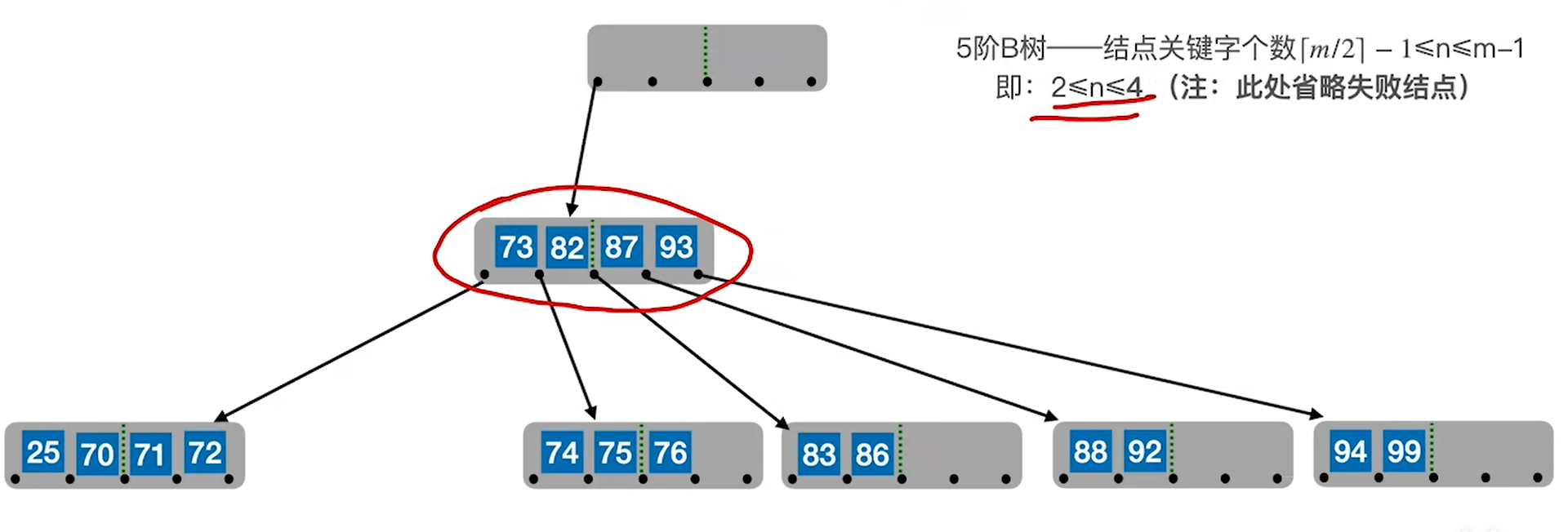
裂变插入法
我们前面说的BST,都是从上往下插,补在末端,但是B树反其道而行之,插到下面,然后通过裂变的思路裂出父节点,具体如下:
- 插入只能往终端节点插(刚开始根节点就是终端)
- 插入的时候,在一个节点内部,是顺序储存,因此插入方法也是顺序插入
- 可能要进行挪动节点,同时还要挪动链域,所以为了方便整体挪动,B树的关键字和链域是混在一起存的

- 任何节点,只要满了就裂变,分为左,中,右
- 左右分别变成两个节点
- 中关键字上提,如果有父节点就插入父节点(可能要挪动),如果没有父节点,则成为父节点
- 上提可能会引发连锁裂变反应,从下往上顺着裂就行,当分裂传递到根节点,则高度+1
裂变的思路,可以保证绝对平衡,子树要么是0,要么就至少满足最小值情况(包括根)

流动删除法
删除,可能是非终端,也可能是终端,但是类似于BST的删除,通过顶替的操作,最终都可以转嫁为终端节点的删除
删除终端分为三种情况:
- 关键字仍然够
- 关键字不够,但是兄弟够借
- 关键字不够,兄弟也不够,那就合并
先看2,框住的区域整体是有序的,因此两个兄弟只需要以父节点为中介,整体流动一下就好
注意这个整体流动是包括父节点的,因此那个70其实是从孩子流到父节点里的,而原有父节点的流到亏空的地方(怎么有种连通器的感觉?)
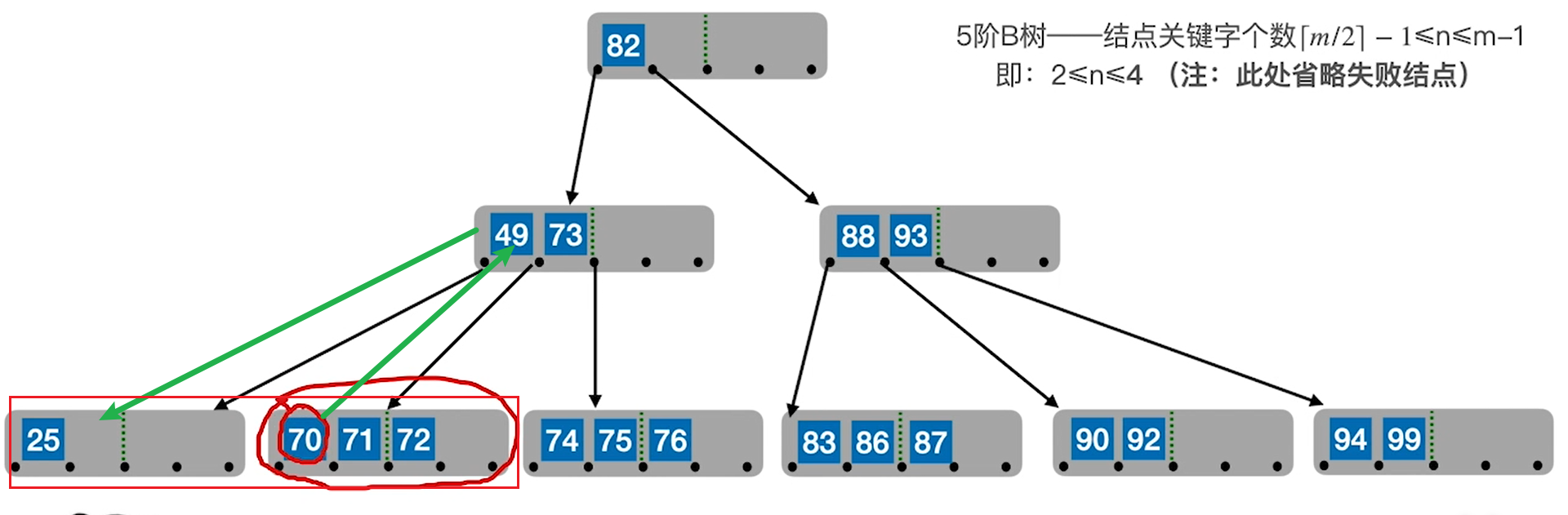

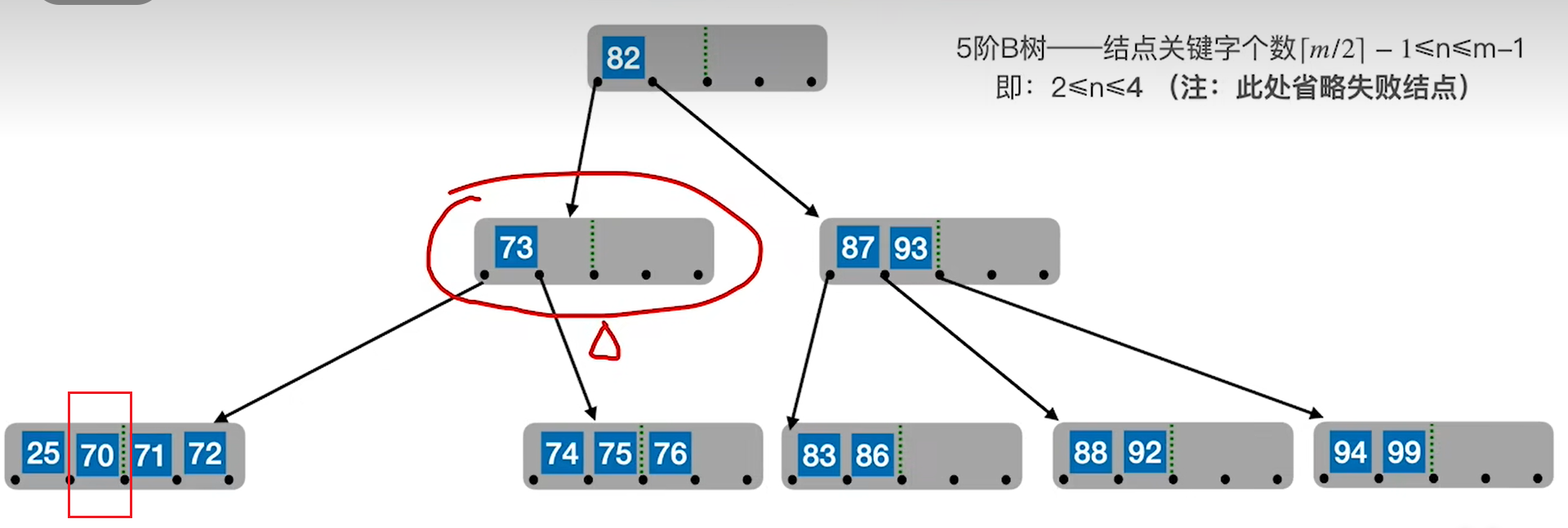
再看3,这次兄弟没有富裕,因此要合并。
同理,合并其实仍然是一种流动,可以理解为把兄弟的关键字全部流到了不够的节点里面(顺带带走一个父节点的关键字),下图中,70这个关键字被冲了下来。
注意,这种还会引发连锁反应,如果最后借得根节点为空,那么就要删去根节点,此时高度-1

B+树

定义和特性
首先给B+树一个定义,同B树,根节点要么是0子树,要么是2颗以上子树,这本质还是绝对平衡。

B+树和B树整体思想一致,多叉,但是细节差距很大,因为根本目标是不一样的
- B树是m个链域,m-1个关键字,也就是说关键字起到隔板作用,是要直接去匹配关键字的
- B树全体都是用来储存key的,叶节点=失败
- 但是B+树,
关键字=链域数量,起到的是类似于分块查找的作用,不会去直接匹配关键字- B+树分为两大部分,底部每个叶节点里面有n条记录,上面的所有部分是多级索引
- B+树其实是加强版的索引顺序储存,而且B+树的顺序部分一定是有序的(索引顺序里是无序的)
解释一下B+树的特性:
- 子树数量规则略有不同
- 叶子根节点可以是1个子树
- 非叶根节点0/2起
- 非根节点仍然是0/k起
- B+树实际是加强版索引顺序储存
- 关键字=链域,为链域内关键字
上界(包含) - 叶节点内部顺序,且链域指向关键字对应的数据域
- 叶节点一层整体是可以顺序查找的
- 关键字=链域,为链域内关键字

B+树查找
来看一下B+树的查找:
首先是类似于索引顺序查找的方式,从左往右(折半太麻烦不讲)扫,不断地递进索引,最后找到叶节点层:
- 有数据,成功
- 无数据,失败
无论如何,都到叶节点。
另一种思路是顺序查找,就是直接到叶节点层从头开始找

B+树对比B树

这一部分是对上面的整体总结,考试也爱考这些
- 两个树的本质不同,B+是索引储存,B是全体储存,因此会有大量的延伸特性
- 链域和关键字对应不同,B+:m——m,B:m——m-1
- 数据项内容不同:B+索引中出现的数必然在叶节点中出现,而且叶节点本身还会储存一个指向数据记录的指针,而B出现过的不会再重复,B的节点本身就存着key和数据记录
- 查找过程不同:B+树一定会查到最后一层,而B树匹配到就停
- 关键字数量不同
- B+:为链域下界,即1,k
- B:为链域下界-1,即1,k-1
- 注意到,B树链域下界是2,但是B+树链域下界可以是1,这种情况比较特殊,只有叶子根节点才允许,其他情况下界为2/k
与OS的联系
B+树用于磁盘和数据库的储存,MySQL的索引功能就是用B+树实现的
如下图,每个B+树节点都存在一个磁盘块中,下面的3层B+树,每次访问一个数据块实际上要经过4次:
- 读两次索引
- 读一次指针
- 根据指针读数据
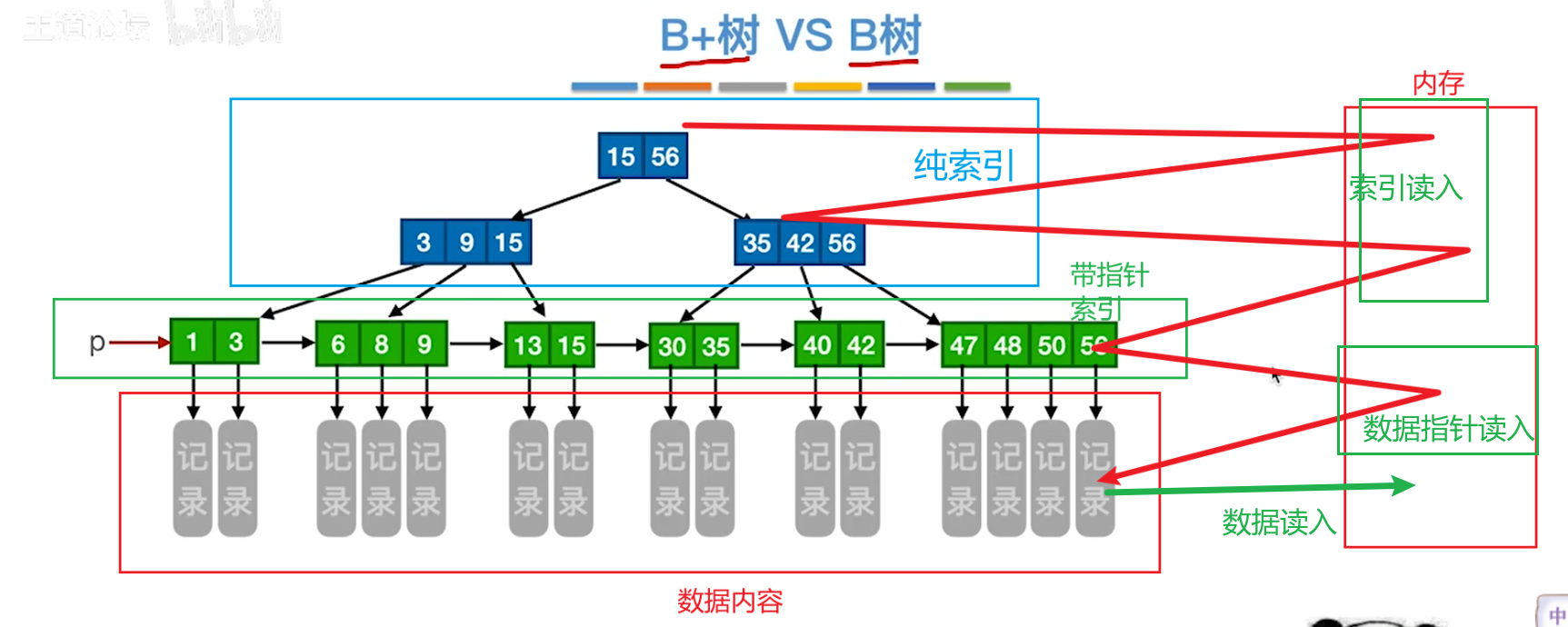
之所以要采用索引+指针的方式,是因为要尽可能精简B+树,但是一个磁盘块(对应一个节点)的大小是固定的,因此无论是索引还是叶子结点,里面的关键字都要尽可能多,这才能降低树高,进而减少读磁盘次数,因此要尽可能减小数据项的大小,最后就演变成只储存关键字了(叶节点还有指针)
而B树不适合储存磁盘,因为数据记录+key的空间比较大,一个磁盘块存不了几个key
散列查找

基本概念
散列函数的本质是空间换时间,给定key,可以瞬间计算出具体的储存位置,进而直接查找到元素,不需要比较,不需要遍历。
速度很快,代价就是空间浪费
如果不同key,位置一致,则代表同义词位置冲突,使用拉链法
采用拉链法后会进行额外的比较处理,每有一个元素,ASL则多1,比如27查找3次,21(对应8)则为0
因此提高hash效率的根本在于设计一个尽可能能把key均匀平铺开的hash函数

比较有意思的是,失败的ASL反而更小,因为成功情况下是不考虑空链域的。
直观理解一下装填因子:其实就是装的满不满
如果α>1,那么一定有冲突项目,一定有重叠项目
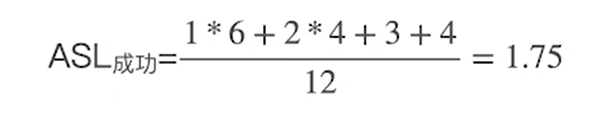

常见散列函数
记住这句话:提高hash效率的根本在于设计一个尽可能能把key均匀平铺开的hash函数,如果能均匀平铺,那么时空效率会同时达到最高
除留余数法
表长为m,则取素数p≤m,H(key)=key%p
之所以p一定要素数,是因为在大部分情况下这样可以让分布更均匀,即使关键字内部有联系,在素数的打击下,也会被分解的接近平均
实际上不一定效果更好,如果本来key就是均匀分布的,反而用length当做p也是不错的。
使用素数还有一个缺点,后面会有一截是用不到的,浪费空间,当然不排除有人盯上这片空间搞点事情,前有线索二叉树,这里说不定也会有花活

直接定址法
直接定址法本质就是一个一元的线性变换
如果原来就是均匀的,效果会很好,如果原来中间空位多,那么就会浪费空间

数字分析法
如何把零碎的key均匀平铺?
那就要寻找整体不均匀的key中均匀的部分,比如电话号,尾数基本是均匀的,那么就挑出来均匀的这一部分当做key设计hash函数。
如此,一个直接定址就可以搞定。

平方取中法
这个方法蛮抽象的,其实是数字分析法的延续
数字分析法是直接挑一些数字出来当key
而很多时候,数字之间是相互作用的,那么干脆就用一个函数把这些数字的总特征提取出来,得到一个精简的特征,当做key
平方其实就是这么个函数,平方后,中间的一截可以代表整个数字的头尾综合信息,此时或许会变得均匀

冲突处理
其实所有的冲突处理,本质上都是给被冲突元素找个新位置。
- 拉链法是把同义词的新位置放在了一个链表
- 走的是聚集同义词的路子
- 开放定址法是增加了一个偏移,根据偏移的不同分为三种方法
- 不同意义的词可以互相借住
- 再散列法则是直击本质,干脆用一个planB哈希函数,再来一次
- 本质上是一词多义
拉链法
拉链的本质是,数组不存key,而是存一个指向链表的头指针,实际的key存在链表里
前面说了,其实这个才是最常用的,只要你的哈希函数选的尽可能均匀,效率就是最高的,Java的HashMap都是用拉链法解决的,但是这个没啥考点,所以考试喜欢考开放定址法。
当然,拉链其实也可以优化,使用数组拉链+保持顺序折半可以稍微提高效率(但没必要,不如开大指针数组)
再散列法
用一个planB哈希函数,再来一次
因此哈希函数实际是 R H i ( k e y ) RH_i(key) RHi(key),i代表冲突次数,每冲突一次,则换个Hash函数再试一次。
开放定址法
开放定址法把冲突的项目放到数组的其他地方
也就是说,某一个地址不一定只放同义词,还可能有其他遇到冲突的非同义词过来借住
具体过程如下:
- 第一个地址是H(key)
- 冲突后则加一个偏移di后取模
- 若仍然冲突,则更换d偏移量,这就是所谓的尝试,一个地址不行就去试另一个地址
- 冲突次数=d的下标,0代表初始情况(假定不冲突)

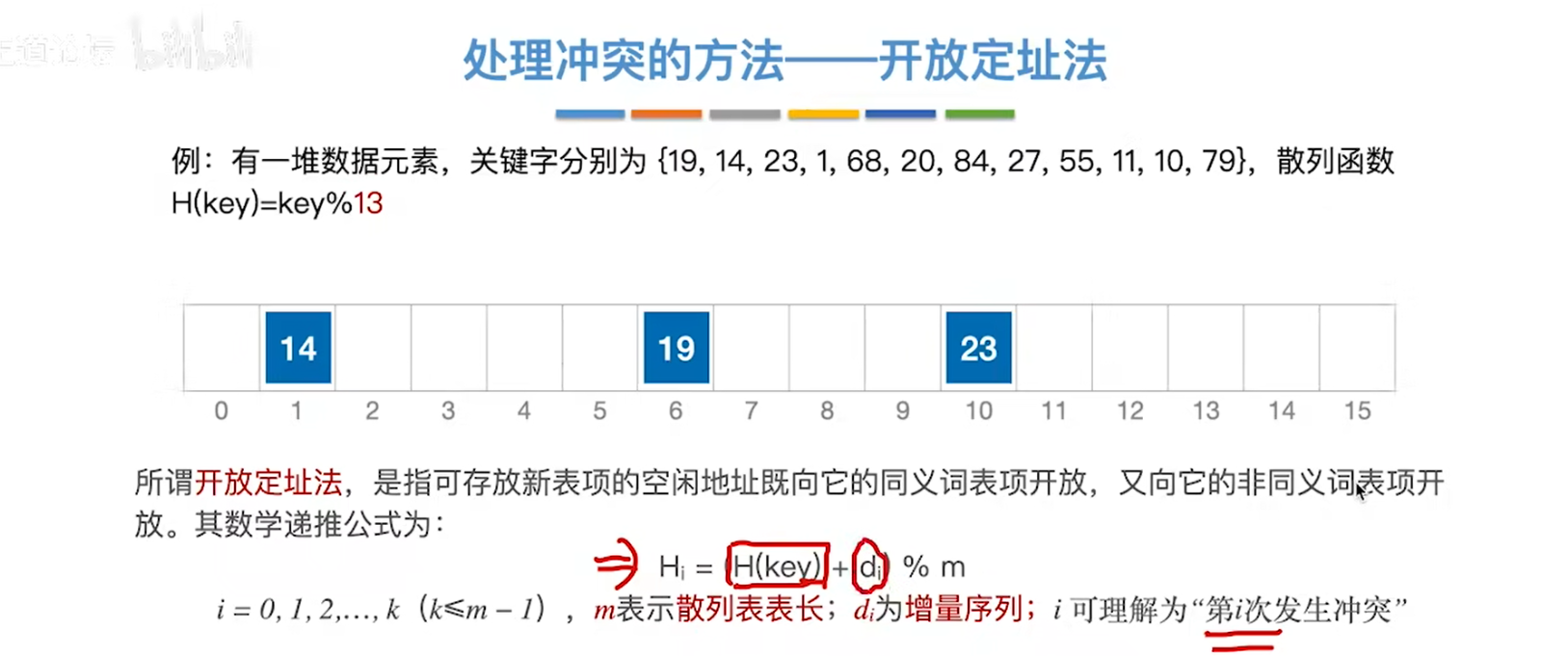
开放定址法原理一样,递推探测,只是di的设计各有不同
需要注意,开放定址法有一个恶心的地方:删除不能直接删除,否则会导致下次探测提前遇到空而掐断递推链条,要逻辑删除,而逻辑删除标记只能在后续插入的时候抹去。

线性探测法
所谓线性探测,就是这个不行,就往下一个找。
因此di的设计是从0开始递增,刚开始H0和H(key)是一样的,后面就会偏移,注意两个值的选择:
- Hash函数如果采用除留余数法,那么选素数,会有空间没用到
- 线性探测的模是数组长度,因此可以全覆盖,这就解决了除留余数法存在空间浪费的问题

下面为查找成功的一例,匹配4次

下面为查找失败的一例,空位置也要算一次比较
这里就和拉链法不同了,拉链法的数组存的是指针,空指针不需要比较,但是线性探测的数组里存的是数,即使是一个没有装填的key,也是一个key(可能弄个-1之类的当做空标志),仍然是要判断一次的


线性探测查找,只要遇到空位置,就代表失败,即使空的后面还有元素。

因为遇空会提前停止,所以删除只能逻辑删除,不能真正删除,否则会让线性探测提前停止,这会影响到前面的查找,以及进一步的删除(依赖查找)


因此实际删除是加一个标记,代表删除了,但是查找探测的时候还可以继续走。
这样会引发一个滑稽的后果,如果不插入,就会导致一个看起来很满实际很空的结果,效率很低。
什么时候才能抹去这个浪费时间的标记呢?就是插入的时候,真的插进去一个,标记就被覆盖。


效率分析:

成功ASL:
- 只考虑成功情况
- 不考虑空节点(比如0)
- 对每一个
关键字具体计算,最后平均- 没有统一公式

失败ASL:
- 考虑所有Hash函数覆盖的节点位置,对每一个
位置进行计算,平均- 包括0
- 最高到12,注意不是数组长度
- 计算单个节点的时候要找到空才算停止
- 而且空也算一次匹配,注意别翻车。
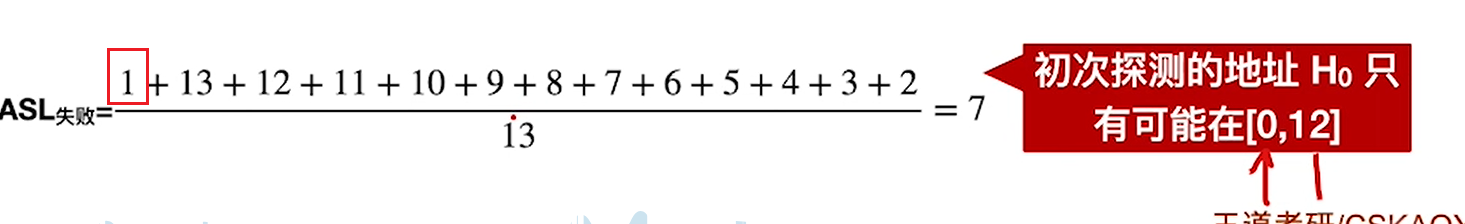
总的来说,线性探测效率低,会导致聚集,堆积现象,说白了就是依托#答辩
线性探测法的效率其实并不高,插入的时候要探测,查找的时候也要探测,虽然空间利用率是满的,但是浪费时间比较多,违背了Hash查找的本意,不然Java也不会用拉链法了
还有就是,这里也可以看出开放定址法会有一个滑稽的后果,本来一个地方是给同义词用的,结果有非同义词提前探测过来插入了,后面有同义词来了反而要绕道,这其实会整体拖累查找效率,因为如果把同义词放在应有的位置,把非同义词放在没人用的地方会更好一点。
还有就是删除导致的标记也很滑稽,总之线性探测法就是一坨#答辩,处处打补丁,搞得四不像。
平方探测法
平方探测法是用来处理堆积的问题的,下面这些数都是同义词,但是di设计的比较有意思,是会一左一右,间距逐渐拉大的。
1,4,9,同义词越多,甩的越远,这就是在人为地对抗堆积,防止同义词集中在一片区域造成大量的冲突。
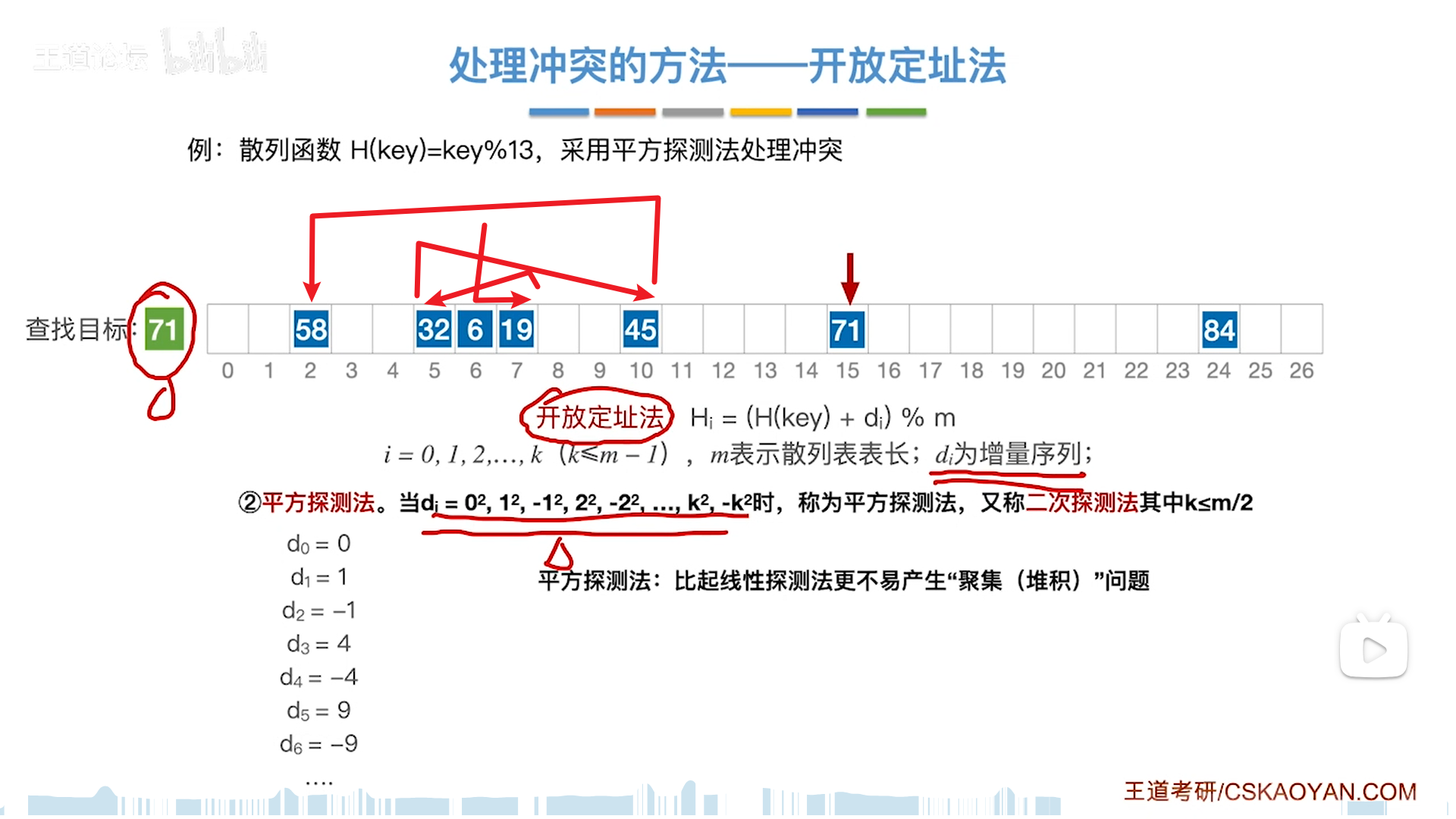
这个方法其实不错,但是有一个问题就是,是否会有一些位置探测不到。
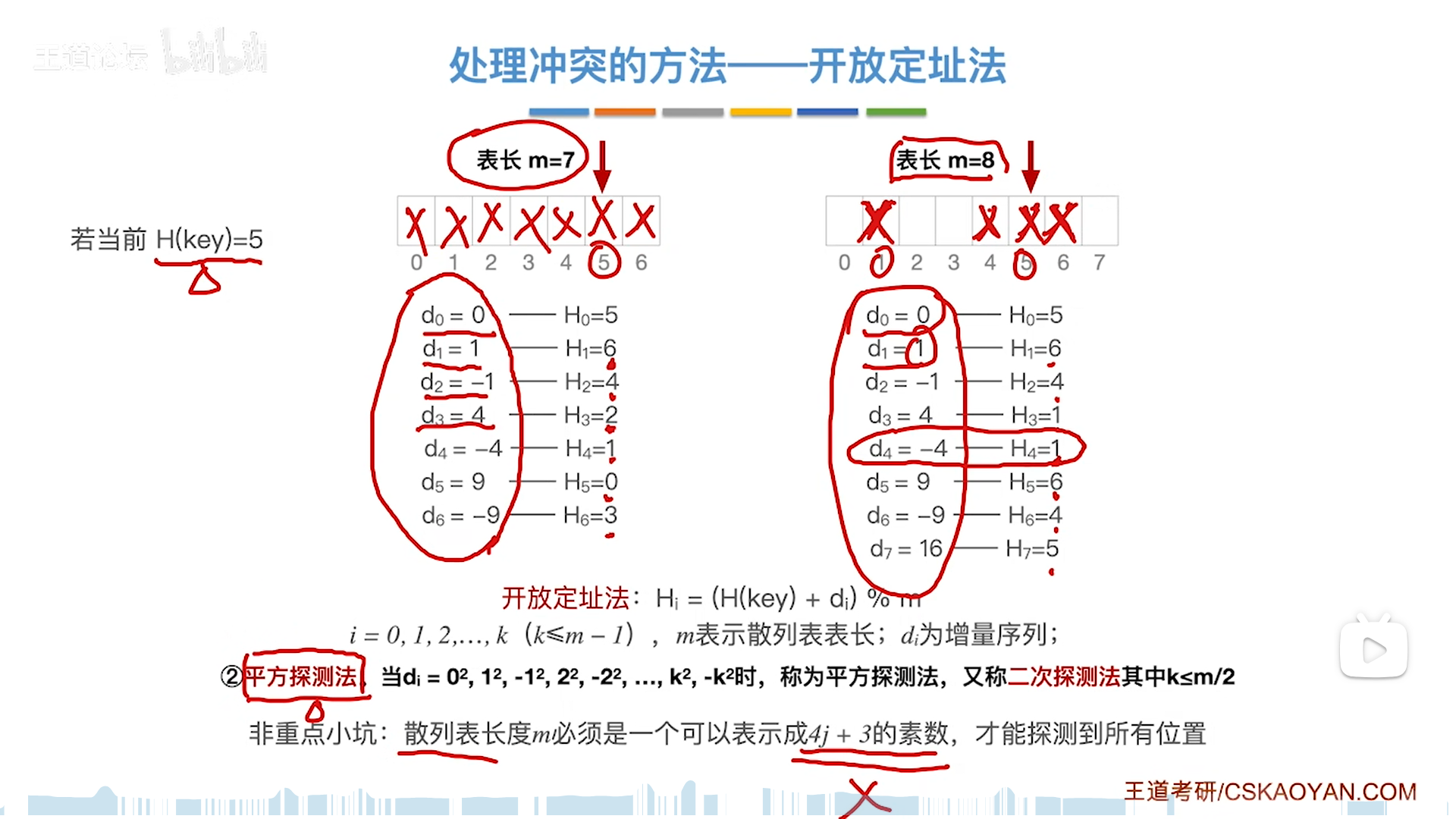
事实上,表长必须满足两个条件:
- m=4j+3
- m是素数
伪随机序列法
伪随机比较粗暴,di使用伪随机算法生成,乱拳打死老师傅。
排序

插入类排序
插入排序
递推思想:
- 初始一个key,为有序
- 将key插入有序序列,新序列仍然有序
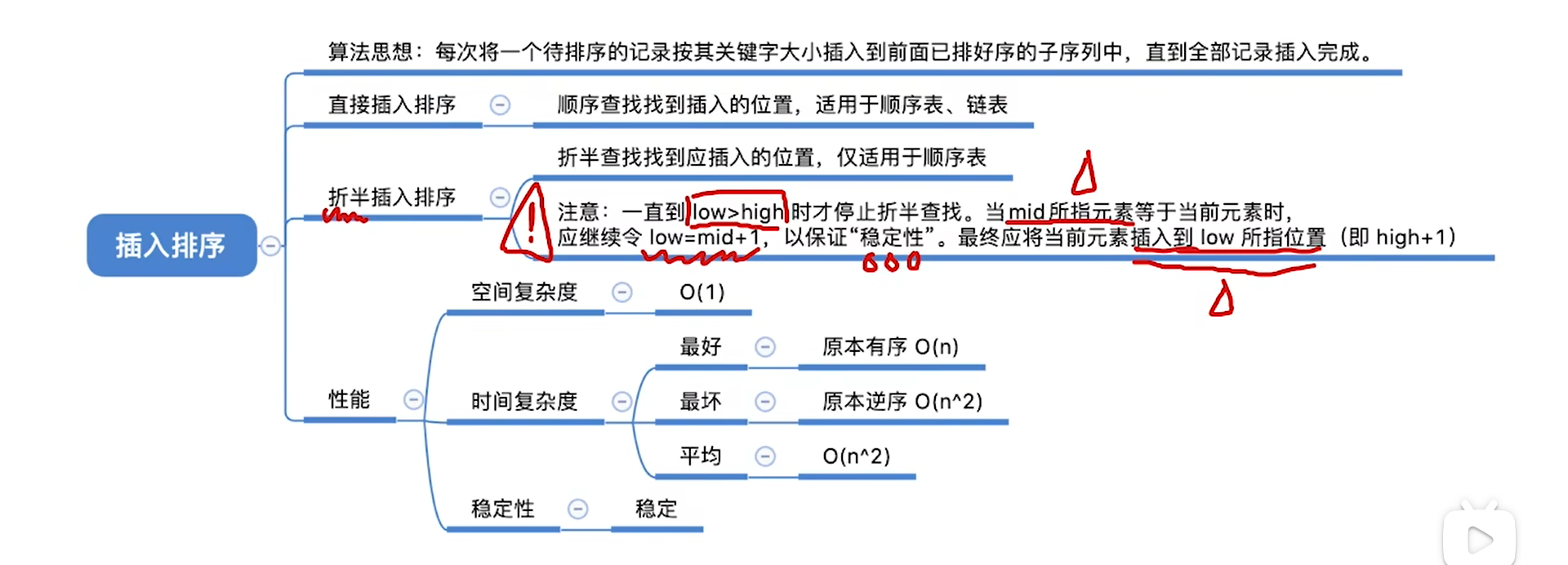
注意,折半插入的时候,顺序情况下,匹配要放入mid+1的情况里才能正确运行。
直接插入排序
顺序比较+插入
假定增序,比较是从后往前顺序比较的,从后面拿一个元素从后往前找:
- 顺序方向,取出i位元素
- 反向比较 j位元素,挪动
- 只有在严格小于的时候把元素挤到后面
- 大于等于则会卡住
- 放置
- 在j位卡住,实际放置位置是在卡住后面,即
j+1
- 在j位卡住,实际放置位置是在卡住后面,即
举个例子,49,66,49,在把第二个49左移的时候,遇到第一个49就会卡住,因此相同的两个key,次序是不会交换的,这就是稳定,这是前面“严格小于”的判断原则保证的
下面代码,其实最开始那个if可有可无,即使是关键字不小于前驱,在刚开始i-1的位置就卡住了,那么最后也就是回归i-1+1=i,原位。
分析一下极限情况,i的元素是最小的,那么j最后会变成-1,也就是说j+1=0,插到0位置。

哨兵版本其实也就那样:
- A[0]充当temp
- 0位置一定会导致循环退出,可以简化循环边界条件(j≥0)
- j=0代表最小,因此插到1位置,处理逻辑一致,所以
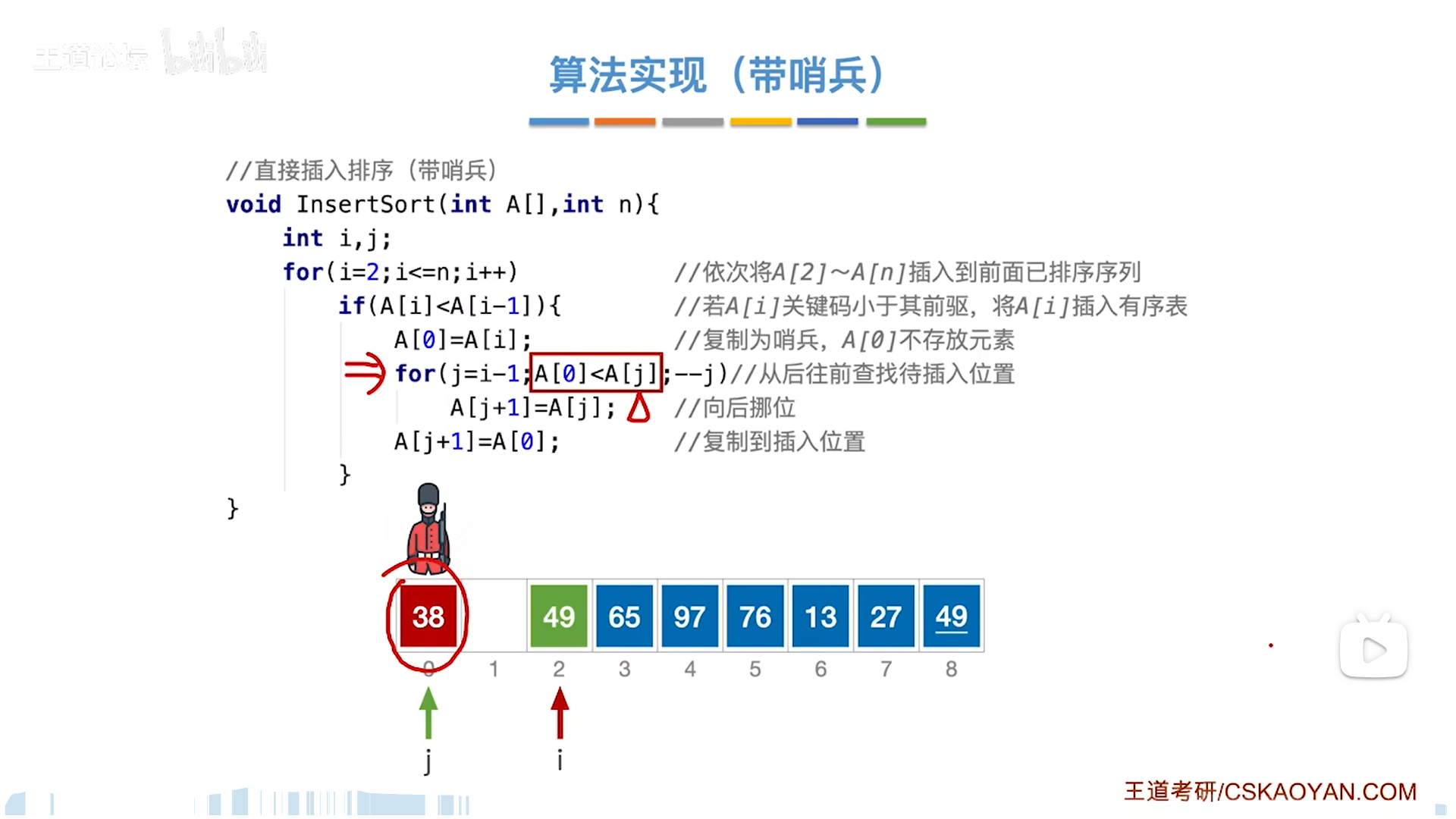
- j=0代表最小,因此插到1位置,处理逻辑一致,所以
分析效率:
空间O(1),只用了一个temp
时间,总共跑n-1趟,所以时间复杂度取决于一趟要跑多久:
- 最好:本来就是顺序,O(n),一趟跑一次
- 最坏:本来是逆序,O( n 2 n^2 n2),一趟就要从头跑到尾
- 平均:没办法写式子,直接把最好最坏平均一下,实际也是n方
稳定性前面已经讲了,只要判断条件不改(严格小于),就是稳定的
折半插入排序
折半比较+插入
折半查找带有跳跃性,所以需要格外注重稳定性,分为两种情况:

- 找到目标位置
- 不管能不能匹配到,要一直调整,直到high<low
- 这是因为匹配到一个并不能保证后面没有相同的数,所以不可以提前停止,不要提前停止,最终一定会high<low
- 具体来说,碰到匹配上,是按照
mid+1来调整的
- 调整+插入
- 找到low的位置,把[low,i-1]内的元素,全部右移
- 腾出一个地方把取出来的i的元素放进去(temp或者哨兵)
- 如果low>i-1,也就是我们前面给的这个区间无效,自然就说明不需要插入

论效率的话
其实没提升多少,因为插入排序的时间复杂度来自于查找+移动,虽然折半可以加快查找,但是移动可是一点都没省。
另一个提升效率的角度是加快移动,考虑链表,使用顺序查找+链表移动的方式,也可以和折半查找有匹敌的效果。
然而,插入排序的时间复杂度来自于查找+移动,总是顾得了这头顾不了那头,所以复杂度实际是降不下来的。
希尔排序
希尔其实是插入的优化版,即分批分步长插入

独家理解:希尔排序的本质与生效原理
希尔排序为什么有效呢?
这得先回顾插入排序了,怎么让插入排序变快?
- 降低复杂度。
- 对于有序性越强的序列,插入排序的效率越高
- 缩短序列长度。
- 这个看起来比轿扯,但是实际有妙用
- 给你一个长度为n的序列,你排序的时间是要大于给两个长度为 n 2 \frac{n}{2} 2n的序列排序的
- 因为 n 2 < ( n 2 ) 2 + ( n 2 ) 2 n^2<{(\frac{n}{2}})^2+{(\frac{n}{2}})^2 n2<(2n)2+(2n)2
希尔排序实际上就是把这两个思路综合起来
第一步是将序列按照步长切分为若干子序列,分别排序,速度肯定比整个排一次块
当然,分别排序并不能一次性排好,但是可以快速提高序列整体的有序性,此后只需要缩短步长,有序性就会飞快的提高,最后步长=1的时候,基本就只需要稍微排几下就可以。
希尔排序看起来多排了好几趟,但是实际上反而更快,多排几趟是你的损耗,但是你拆分排序提高有序性后,带来的效率提高是要大于这几趟的损耗的
这就是希尔排序的底层原理,也是其效率无法计算的原因。
具体操作
选定一个步长开始:
- 步长为k,则可以分割为k个子表
- 对k个子表内部插入排序
- 子表相对位次不变,交错组合为总表
- 减小步长
- 一般是除二,比如4变2,2变1(希尔本人建议),实际上都无所谓,最后是1就行
循环1-4步,直到k=1,退化为插入排序,但是此时整体有序性已经很高了,所以很快就可以完成。
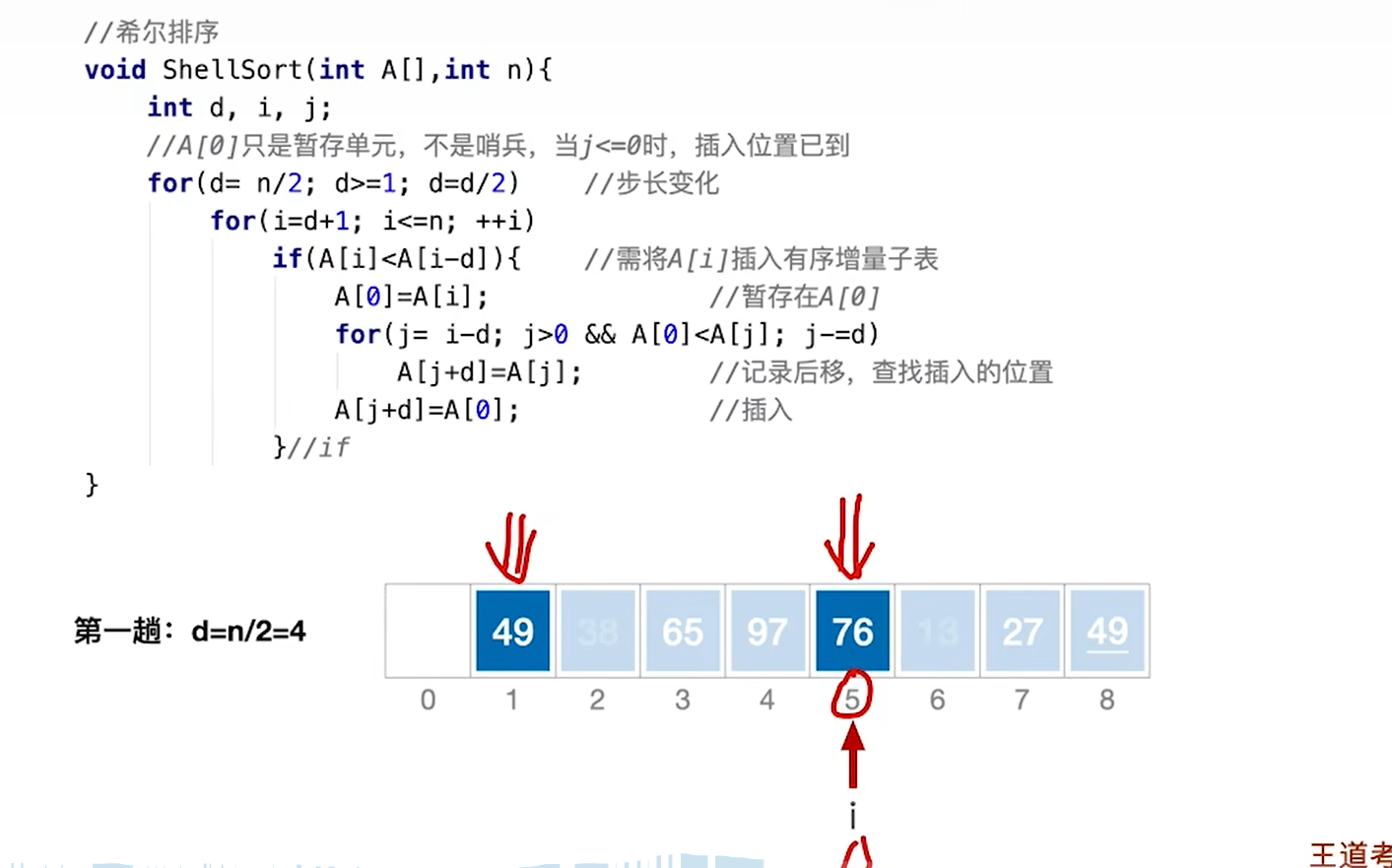
以k=4举例:
先拆分,排序

然后注意,子序列之间相对的位次是不变的,再排回去

代码
希尔排序比插入多了一层,就是步长层。
按照我们上面的逻辑,按理来说应该分组,每组进行插入排序,但是你仔细看一下就会发现,每一组的逻辑完全一样,其实完全可以套用插入排序:
- 直接第一组第二个元素开始进行排序,即d+1位
- 类比于插入排序第二个元素开始
- 所有组都一样,所以这里的步长为1,就是取元素不需要用步长,直接挨着取,所有组都一样。
- 比较和移动的过程需要用d步长
- 这是为了满足分组
所以和插入相比,就三点不同:
- 加了步长变化循环
- 取第一个元素从d+1开始
- 比较和移动逻辑要有步长
- 有步长情况下,哨兵已经无法发挥边界效果,纯粹就一temp,所以边界条件又得重新加上
总结
- 空间为O(1)
- 时间不明
- 比直接快
- 最差情况无非就是一个k=1的最坏插入,即O( n 2 n^2 n2)
- 稳定性,不稳定
- 因为希尔排序实际上是会跳步的,跳跃性会破坏稳定性,又没有一个措施来保证稳定性
- 适用性,仅数组
- 步长这个特性,仅能用在数组上
交换类排序
冒泡排序
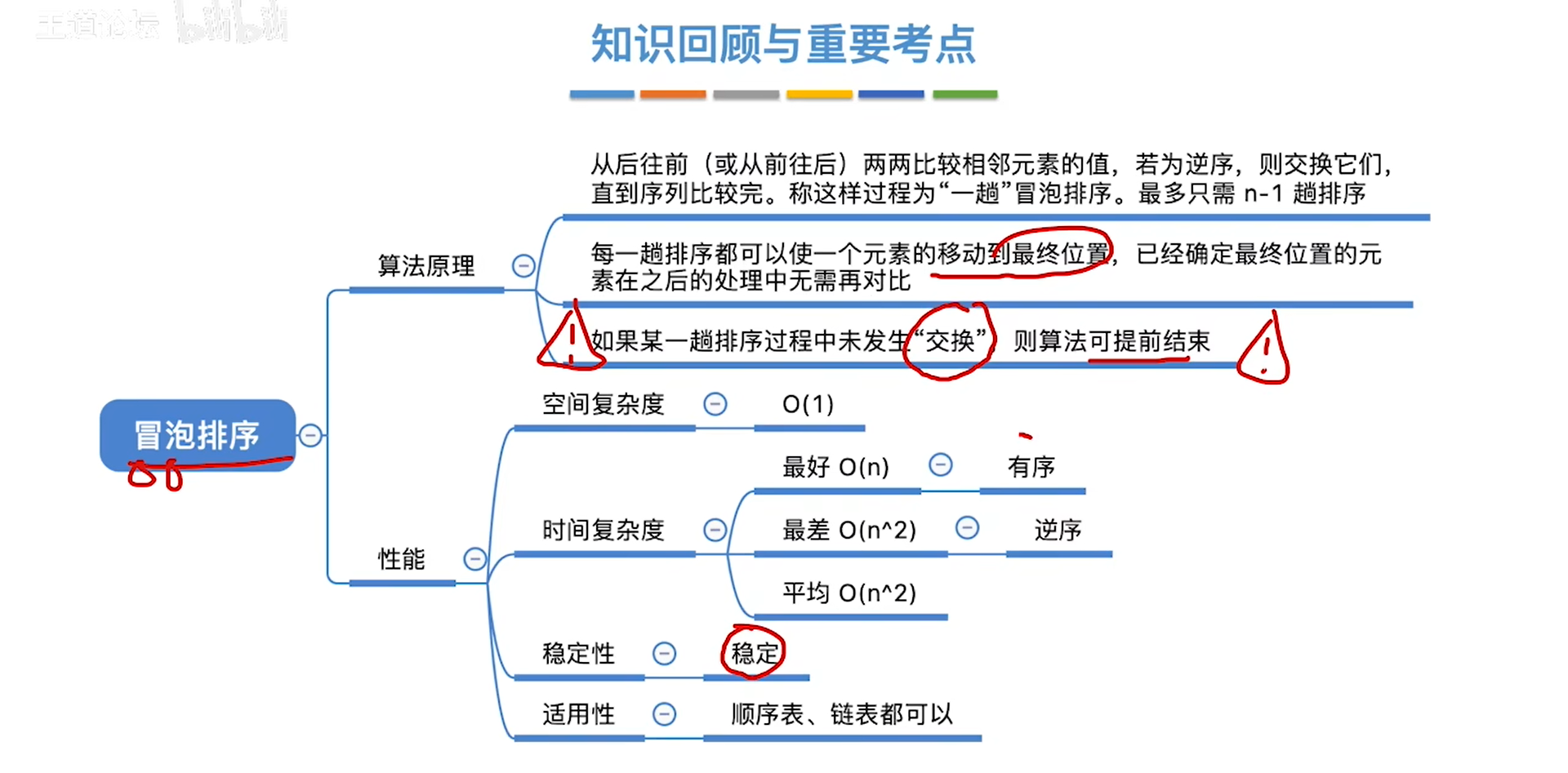
冒泡的本质:
- 从结尾开始,往前推,可以将最小的推到第1位
- 之后继续从结尾开始,往前推,可以将
倒数第k小的推到第k位,k之前的位已经排好,也无法继续推进 - 循环,直到n-1轮后,n-1个数已经排好,最后一个肯定也是好的了
直接结合代码说要点:
- 循环n-1轮,第k轮要把未排序部分的最小数推到第k位
- i从0开始,到倒数第二位(n-2)
- j从倒数第一开始(n-1),倒着和j-1位比,比到i+1位停
- 以flag监控是否没发生交换
- 如果一轮下来没有交换,说明是彻底有序的,提前退出


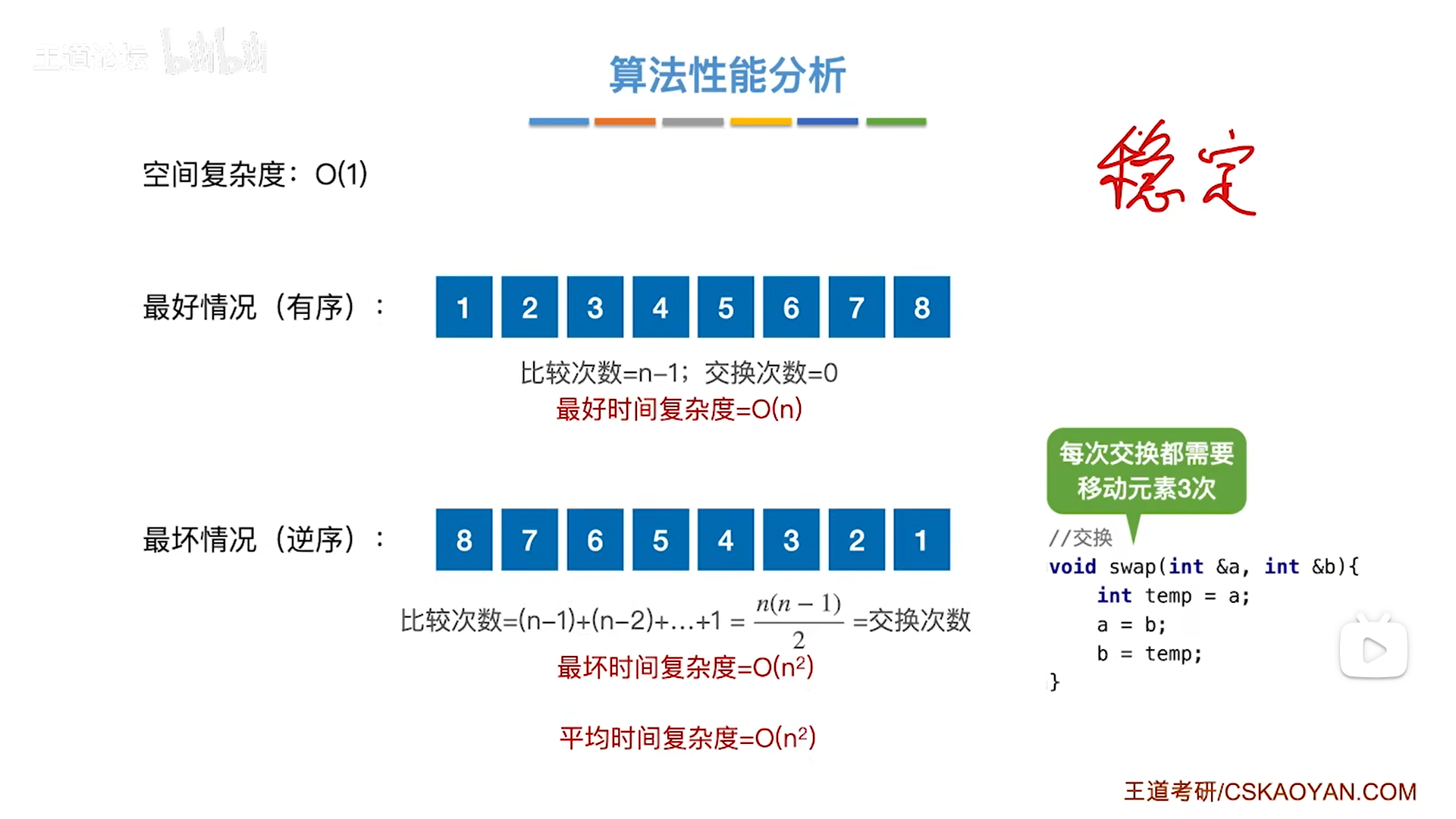
复杂度分析:
- 最好:有序则O(n),跑一轮,发现没交换,提前退出
- 最坏:逆序则O( n 2 n^2 n2),跑n-1轮,比较次数=交换次数=3×移动次数,是一个从n-1到1的等差数列
- 需要注意,考试考具体次数计算的时候,移动次数和交换次数要区分
- 平均:好+坏平均
最后分析稳定性,结论是稳定:
- 相邻,不存在跳跃情况
- 严格逆序才可以交换,因此稳定
因为是相邻步长为1,连续处理,所以链表也可以用冒泡。
回顾,直接插入排序可以用链表(因为也是连续处理),而折半插入和希尔排序都有跳跃现象,只能用数组。
快速排序(重点)
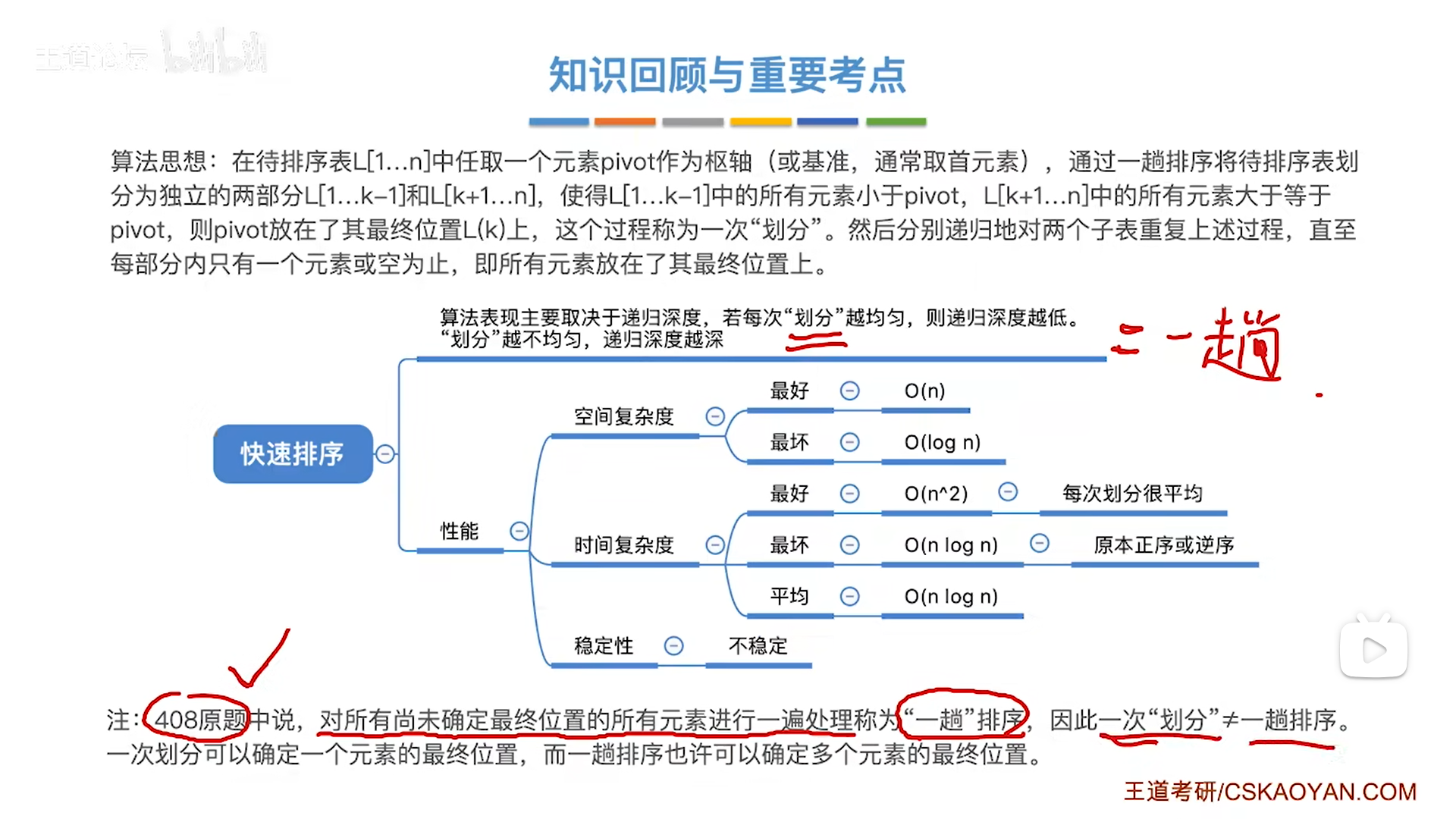
注意:
- 一趟排序,严格来说指的是把数组整个处理一遍,对应到分析树就是搞定树的一层(我们实际手算不是按照递归来的,所以可以按照层序处理)
- 一次划分,只是找到一个pivot,一趟是找到了一层的pivot
很多教材认为一趟=一次,实际408原题,是按照上面严格定义来的
代码细节
- 一次划分:选定一个pivot,然后就可以将数组切分为左右两侧,左边的小于pivot,右边的大于pivot
- 左右子数组本身又是数组,也都可以划分,进而递归地不断分治
- 最后当数组长度只有1的时候,已经是有序状态了
划分的细节,划分过程可以看做是空位左右移动,最后停在中间的过程:
- 取出枢轴后,pivot的位置是空的
- high和low进行移动的前提是,指针指向的元素以及经过的元素都已经满足要求,因此可以断定,low左边<pivot,high右边≥povot
- low和high会有指向空的情况,此时就需要令另一个指针将一个符合要求的数填到空位,此时指针当前位变空,被填为满足要求,指针移动
- 最终low和high会停在空位,此时就将pivot填入
代码还是比较简单的:
- 当一个指针悬停,此时代表空位
- 移动的指针找到不符合要求的元素,则抛到空位,攻守易势
- 循环的退出情况
- 任何一个循环提前退出,代表low==high,此时指针换不换都无所谓

算法分析
递归分析比较麻烦,要自己用栈分析,递归栈的写法技巧:
- 一层的写法
- #后面接行号,可以让你分清这一层调用的是什么函数
- 一层还要写明局部变量的值,在快排里就是当前这一个数组的边界,排序后的pivot
- 一层的函数要完全执行完全部子函数后才能卸掉
- 以QuickSort函数举例,96执行完后要执行97,98,都执行完这一层才能卸掉
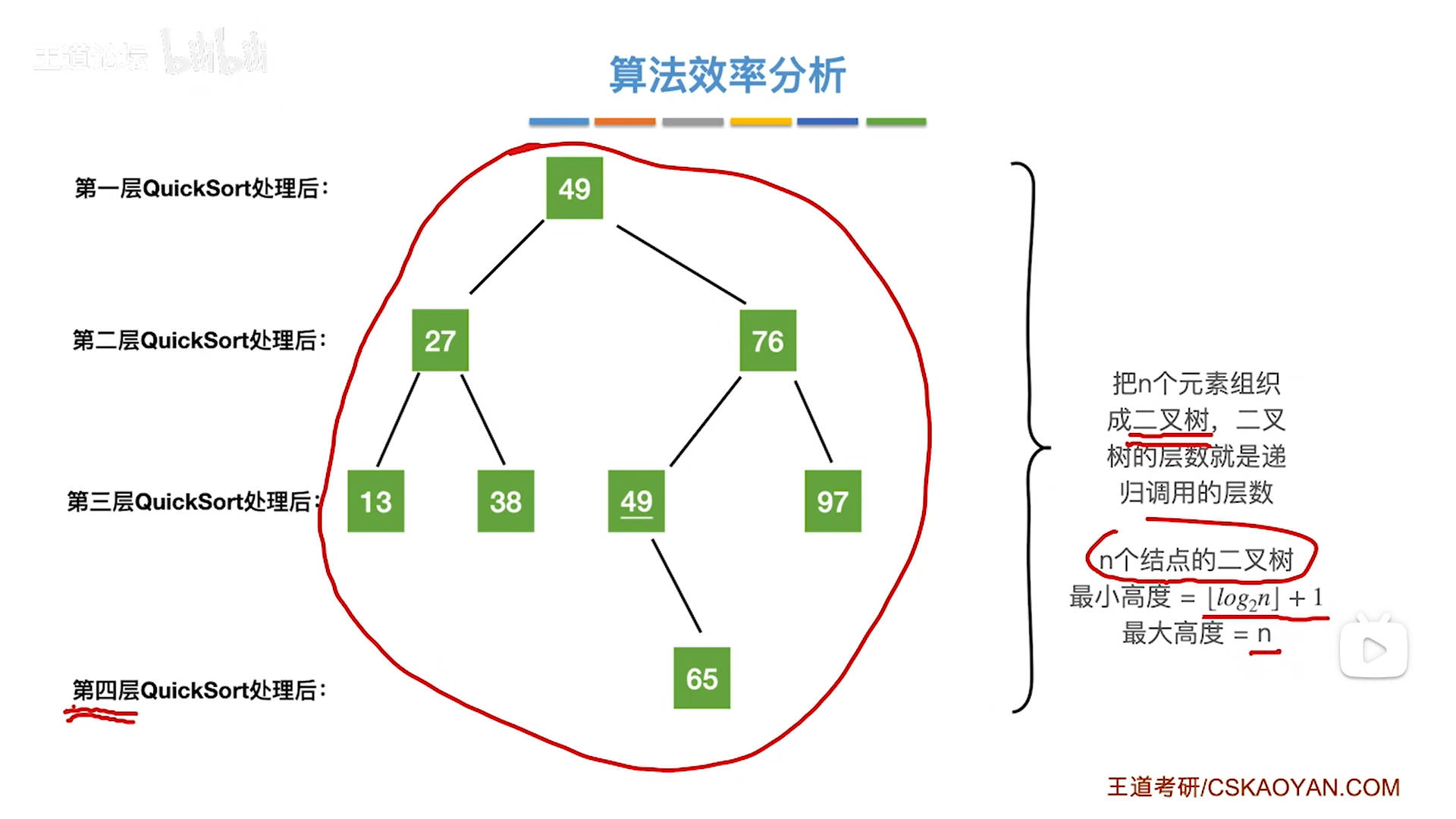
递归过程分析还是比较麻烦的,还有另一种思路,树展开:
快排是先序遍历,按照根左右顺序,先找pivot(根),然后能左就左,到头了再去找右,你把树画出来,逐层看其实就是下图的样子

时间复杂度:
- 从展开树来看,每一层的所有子数组加起来接近原始数组,所以对于一层来说,排序过程类似于遍历,因此一层的复杂度是O(n)
- 对于n个数,会有n个pivot,即n个二叉树节点,根据二叉树高度原理
- 最低是log级别,因此快排最好是NlogN
- 最高是n(单支树),因此快排最坏是 n 2 n^2 n2。
空间复杂度其实就是O(h),因此类似:
- 最好logN
- 最坏N
因此快排其实最喜欢的是纯乱序,反而是纯顺序/逆序的情况会构成单支树,效率最差
知道了复杂度变化的原理,就可以针对性优化,要想让高度最矮,就要尽可能地让pivot落在中间,因此思路有二:
- 选头中尾,找中间值作为pivot
- 随机选pivot
最后看稳定性:
快排要跳步交换,同希尔,不稳定