文章目录
- Diffusion Model原理
- Reverse Process
- Denoise模块
- Forward Process(Diffusion Process)
- 文字生成图片by Diffusion Model
- 文字生成图像的常见套路
- Text Encoder
- Fréchet Inception Distance
- Contrastive Language-Image Pre-Training(CLIP)
- Decoder
- Generation Model
部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索。
论文地址: Denoising Diffusion Probabilistic Models (DDPM)
Diffusion Model原理
从搞屎分布里面采样出一个向量,该向量大小应该和你想要生成的图片大小一样。

Reverse Process
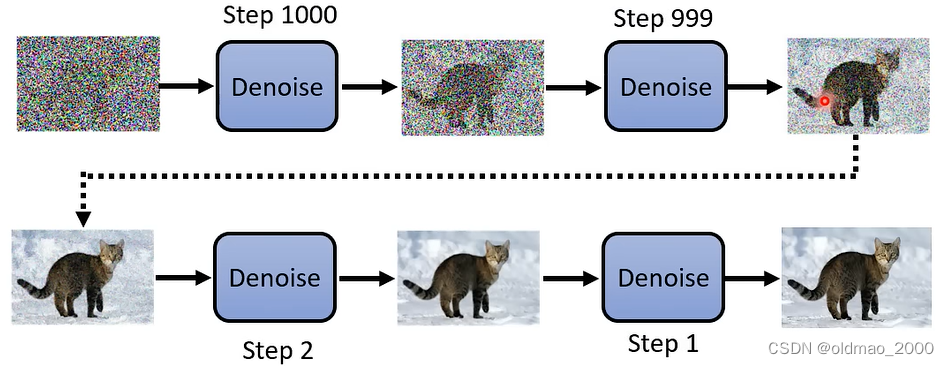
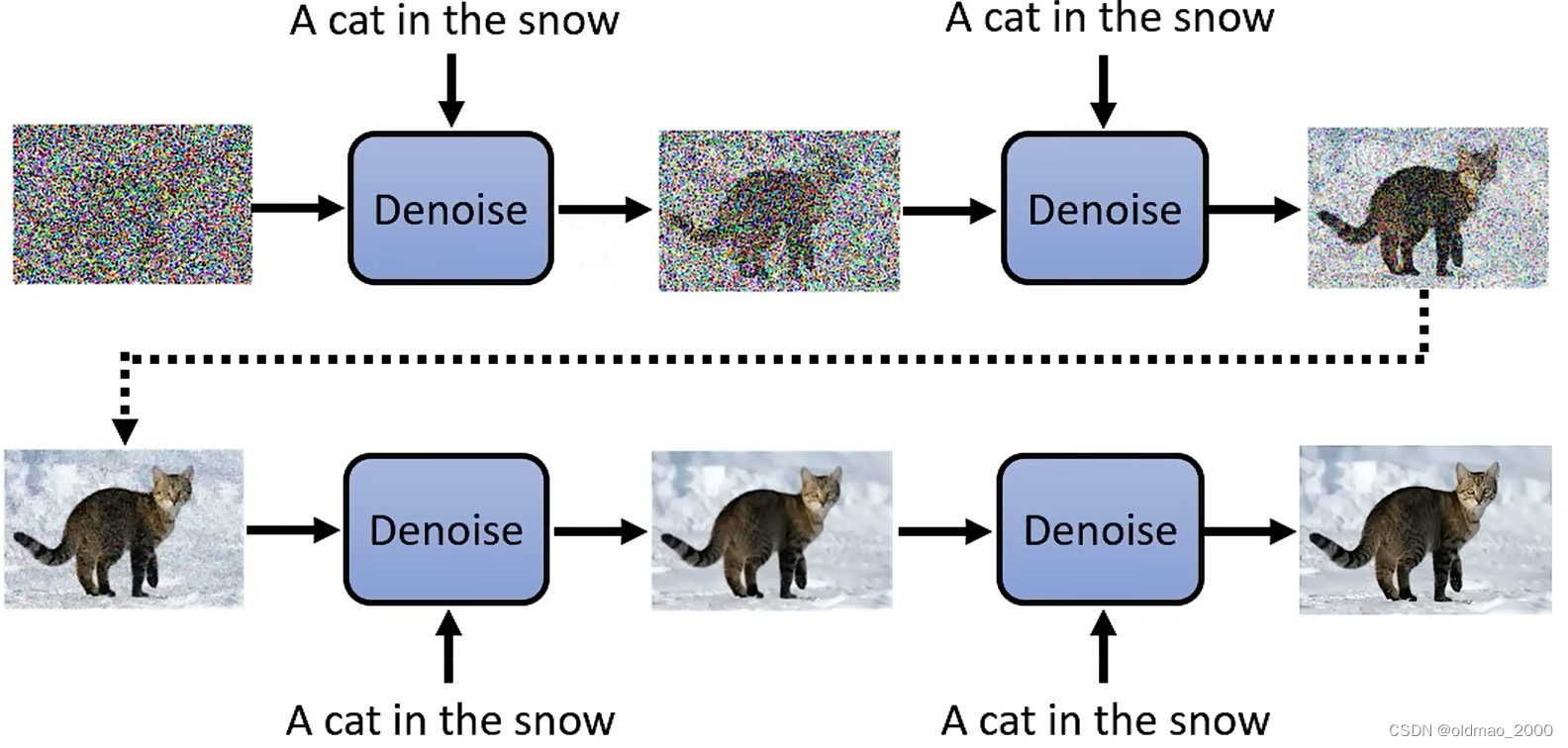
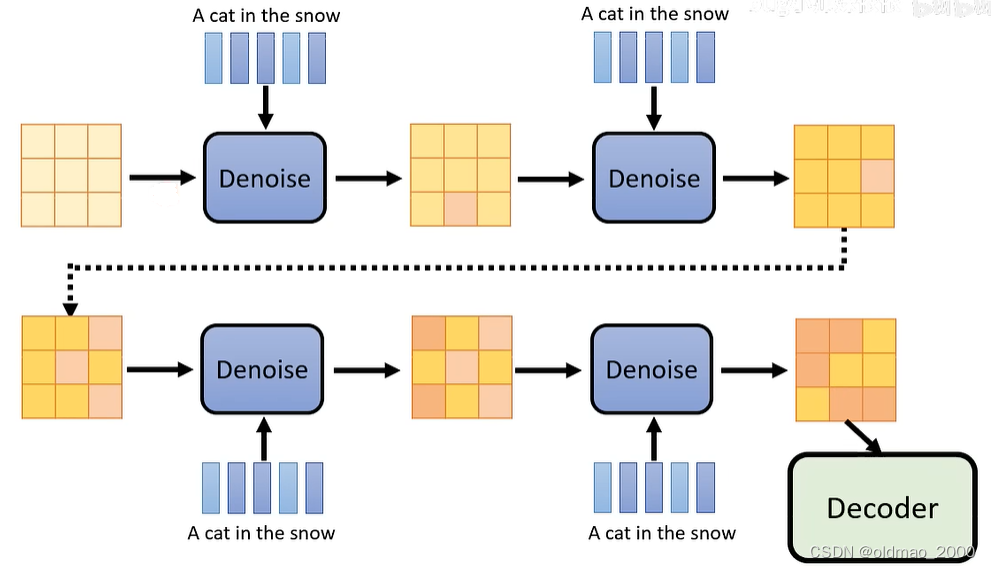
然后一步步通过Denoise模块,逐步将图片显示出来,每一步都会有一个编号,这里的蓝色Denoise模块用的都是同一个。
The sculpture is already complete within the marble block, before I start my work. lt isalready there, I just have to chisel away the superfluous material. - Michelangelo,
米开朗基罗·博那罗蒂代表作:大卫

Denoise模块
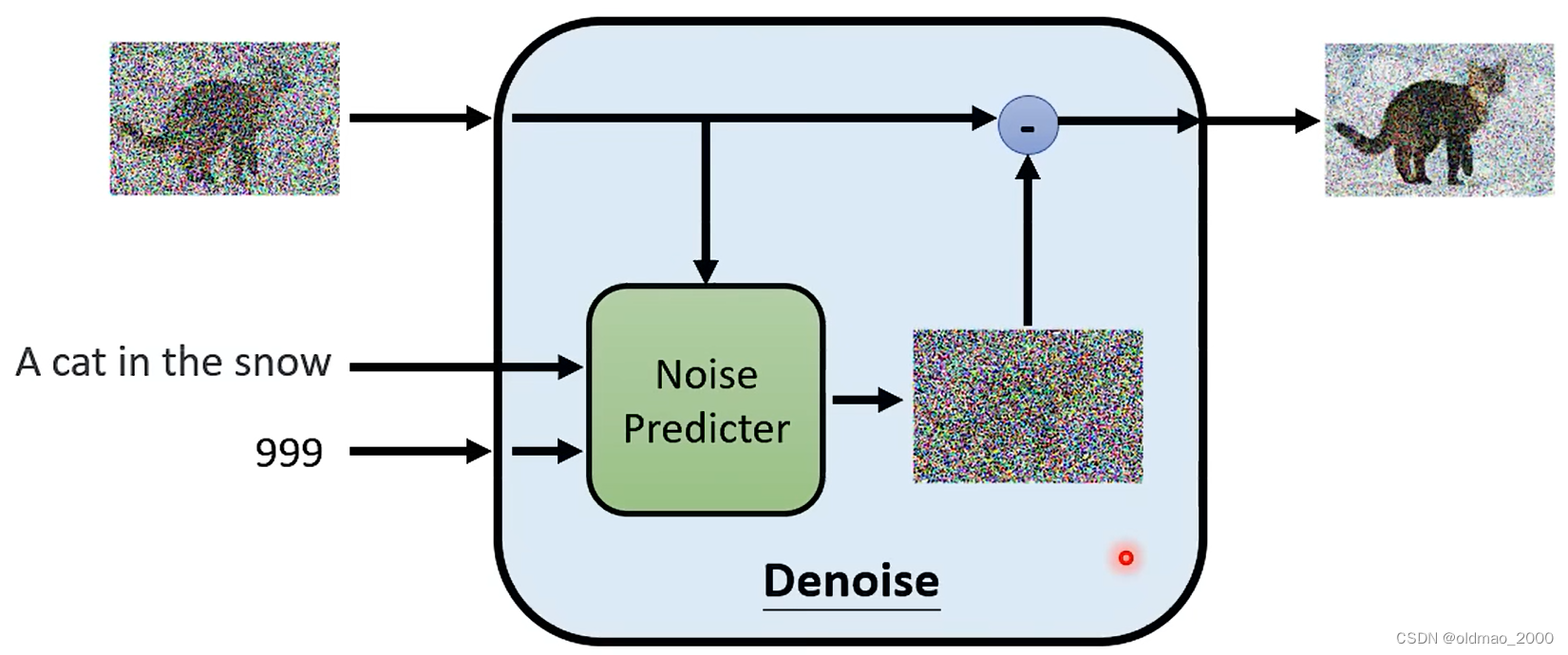
由于Reverse Process用的是同一个Denoise模块,但是每次输入都不一样,要想逐步得到清晰的图片,还需要有额外的输入,就是可以代表当前图片中noise多少的编号,例如下图中就是第1000和第1个编号作为额外输入的例子:

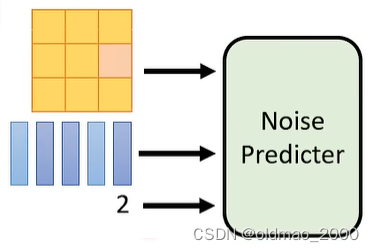
Denoise模块内部结构如下图所示,先是将输入图片和当前编号丢进噪音预测模块,得到当前噪声图片,然后通过与输入图片相减得到输出结果。
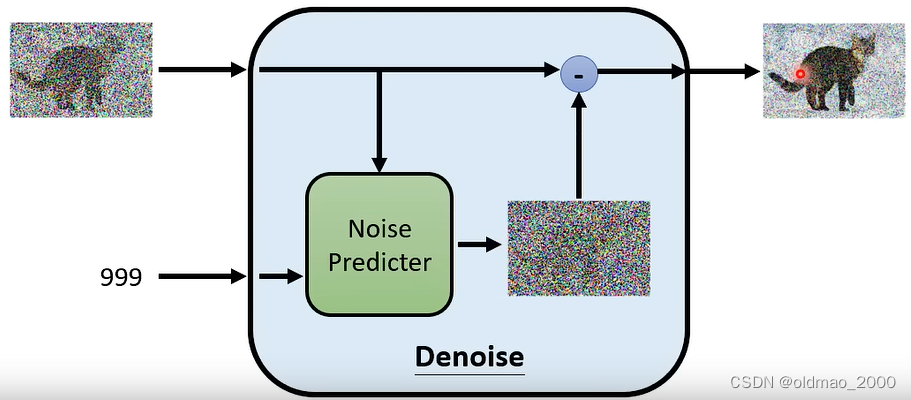
为什么要先预测噪音,而不是直接预测要输出的图片?
直接产生带猫咪的图片和产生噪音的图片难度不一样,前者隐含我们的Ground Truth,是模型未知的内容,如上图中的模型能生成带噪音的猫咪,那就意味模型基本上会生成猫咪了,干嘛还要训练?
Forward Process(Diffusion Process)
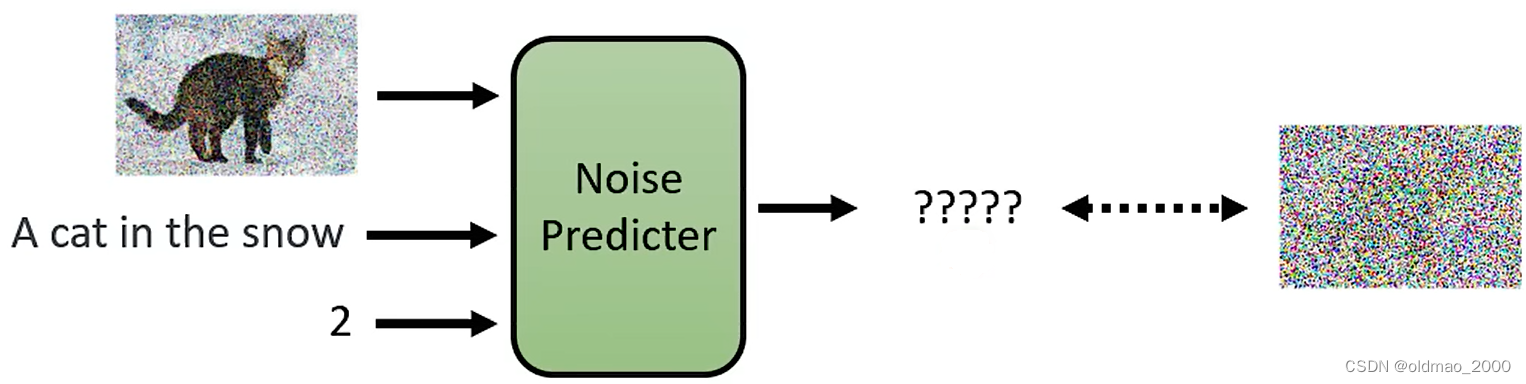
Denoise模块的训练就是要根据输入得到图片中的噪音,大概流程如下图,但如何找到类似的训练数据?
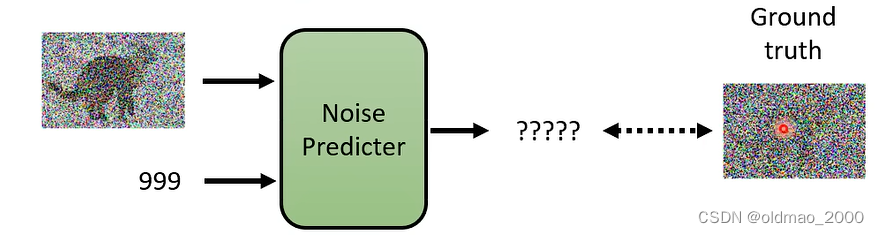
去掉噪音可能很难,但是加噪音很简单,这个过程称为Forward Process(Diffusion Process),具体如下图所示,找一张图片,然后从搞屎分布随机采样一个噪音,加入图片,一直重复多次。
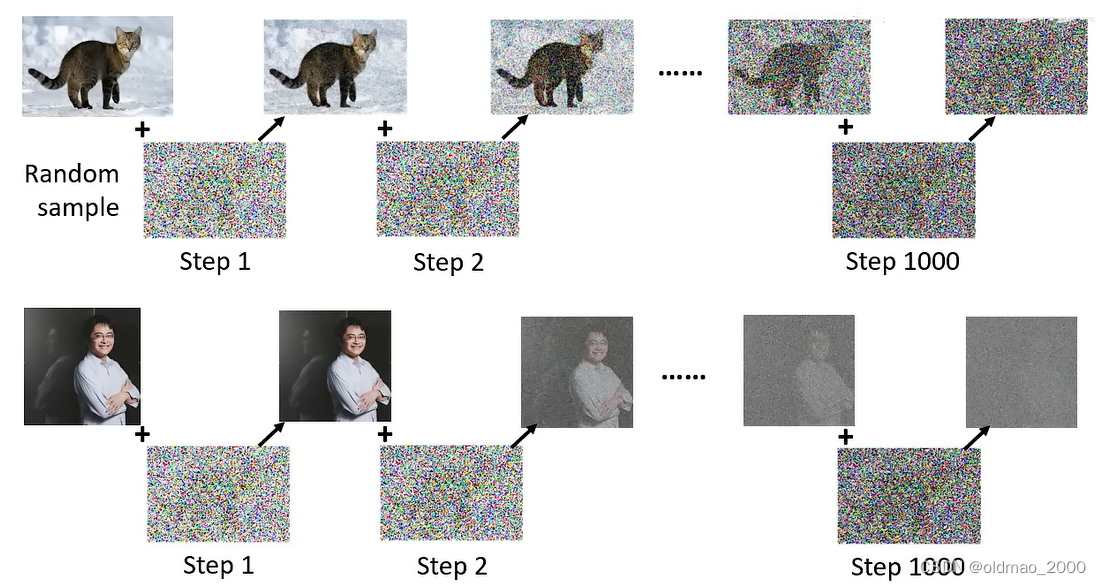
从上面的不断加噪音的过程中,无形中就得到了Denoise模块的训练数据:
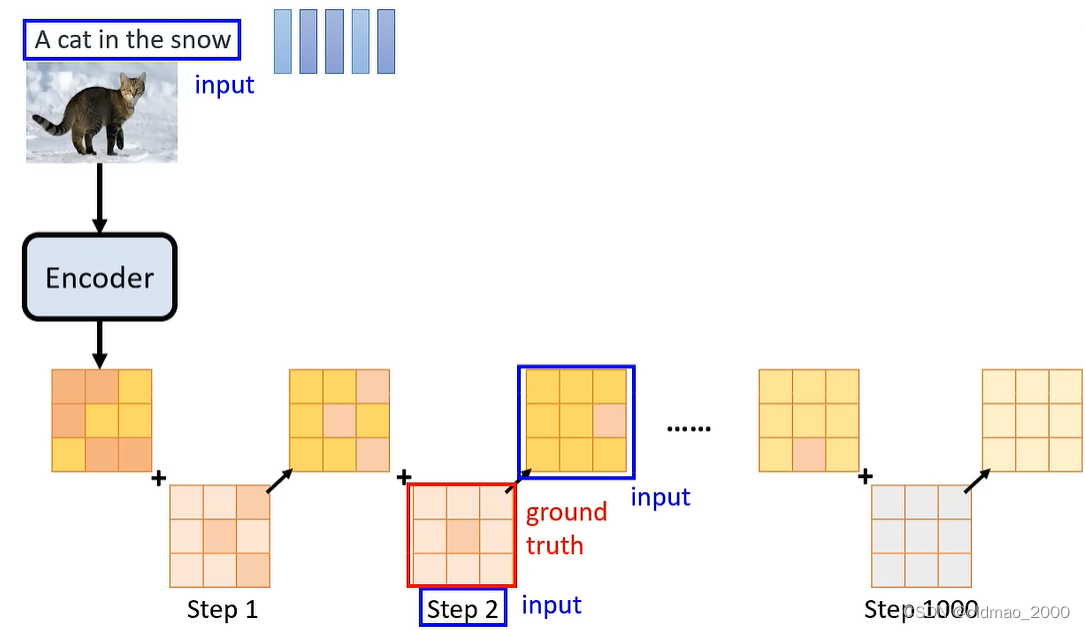
输入1:带有噪音的图片(下图蓝框图片)
输入2:编号(下图中的step 2)
输出:输入1中的噪音(下图红框图片)

文字生成图片by Diffusion Model
上面的Diffusion Model只是生成图片,如果要完成文字生成图片任务,还需要成对的文字+图片的训练数据

当前比较知名的文字生成图片训练数据集是:LAION-5B,大概有58.5亿个图片与文字的数据,文字还包含多个语种。
每个Denoise模块当然还要吃文字作为输入。
Denoise模块内部也没有太大编号
Denoise模块的训练数据的生成过程没有什么变化,文字并不需要参与加噪音的过程:

只是将输入加了一个:
输入1:带有噪音的图片(上图蓝框图片)
输入2:编号(上图中的step 2)
输入3:图片对应的文字描述
输出:输入1中的噪音(上图红框图片)
文字生成图像的常见套路
常见的文字生成图像的模型通常由三个魔祖:
1.文字的编码器,吃文字得到embedding表示;
2.Diffusion模型,吃文字的embedding和从高斯分布采样出来的噪音(粉色方块),得到中间产物(可以是模糊图片,也可以是看不懂的图片);
3.解码器,吃中间产物,得到目标图片。
这三个魔祖分开训练,然后合体。

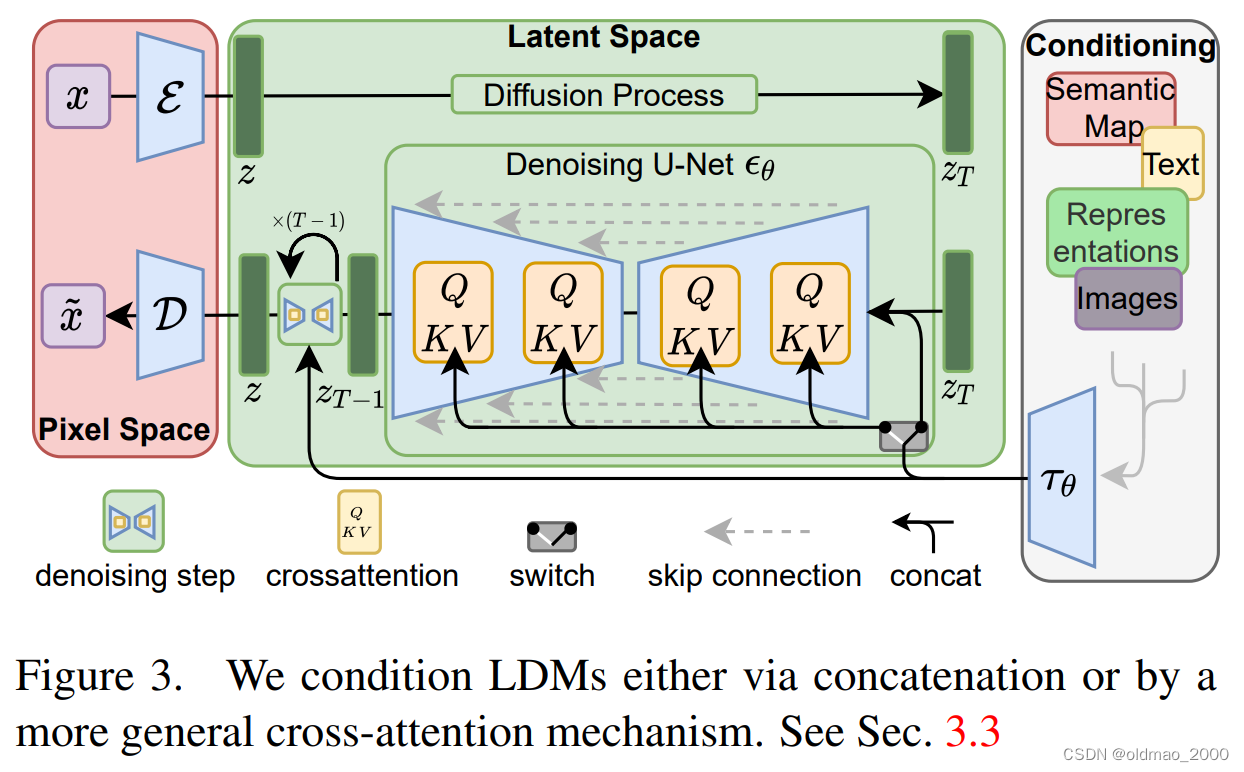
这些模型中比较知名的就是Stable Diffusion Model:High-Resolution Image Synthesis with Latent Diffusion Models,三个模块分别从右到左:灰色,绿色,粉红,值得注意的是,灰色部分不但可以吃文字,还可以吃其他非结构化的信息。
还有DALL-E系列:
Hierarchical Text-Conditional Image Generation with CLIP Latents
Zero-Shot Text-to-Image Generation
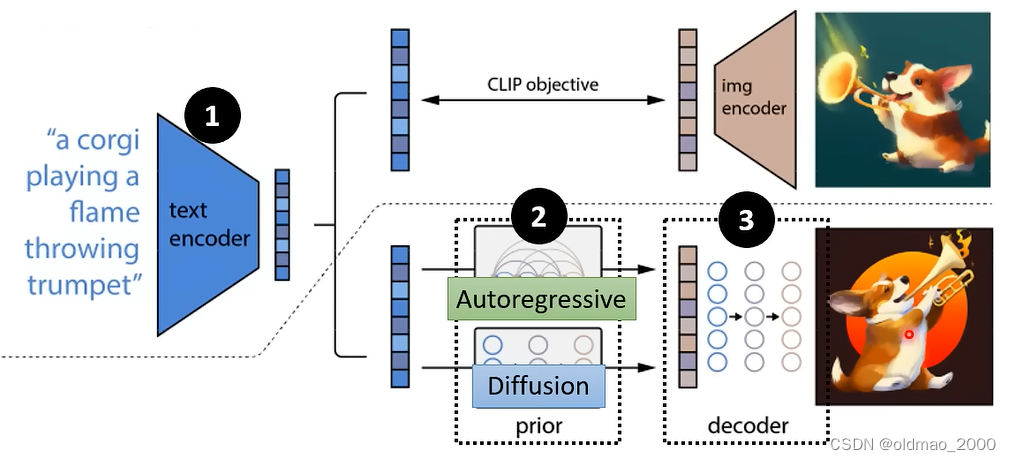
Figure 2: A high-level overview of unCLIP. Above the dotted line, we depict the CLIP training process, through which we learn a joint representation space for text and images. Below the dotted line, we depict our text-to-image generation process: a CLIP text embedding is first fed to an autoregressive or diffusion prior to produce an image embedding, and then this embedding is used to condition a diffusion decoder which produces a final image. Note that the CLIP model is frozen during training of the prior and decoder.
这里不一样的是在第二魔祖里面有两种选择,Autoregressive和Diffusion,后者优先。
谷歌的Imagen:
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding

这里蓝色对应魔祖1,然后用红色Diffusion模型生成一个小图(大小是64×64),然后再用魔祖3(黄色和绿色,这里也算不上是decoder,也是Diffusion模型)将图片加大到1024×1024。
下面分别介绍三个魔祖。
Text Encoder
Text Encoder技术上之前已经讲过很多,在谷歌的Imagen里面给出了该魔祖对图像生成任务的影响:
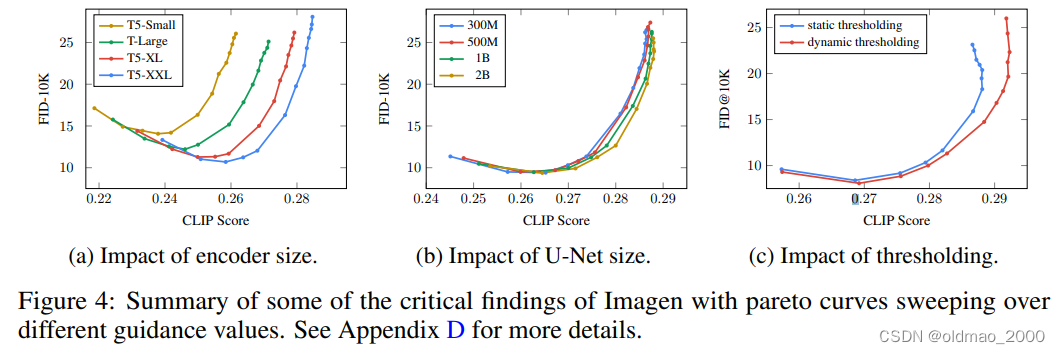
这里用的T5,纵轴是FID,越小越好;横轴是CLIP Score,越大越好。上面的图a表示模型越大生成图像的品质越好。
仅凭LAION中那一丢丢文字语料是无法获得很好的文字embedding表达的,有很多未知词汇在语料中都没有见过,因此使用预训练的大模型可以有效提升图像生成任务的性能,也就是说能看懂文字是生成图像的前提,若是准星有问题是无法命中目标的。
相较魔祖1而言,魔祖2的大小就没有这么重要了,上图b也显示了该结果。
Fréchet Inception Distance
该指标来自文章:GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
由于图片生成的结果没有标准答案,因此该文章提出了一种评判生成图像与真实图像之间差异的标准。
先要有一个预先训练好的图像分类模型(CNN就阔以),然后把生成图像与真实图像都丢进分类模型,将进入Softmax之前的图像embedding拿出来如下图所示:
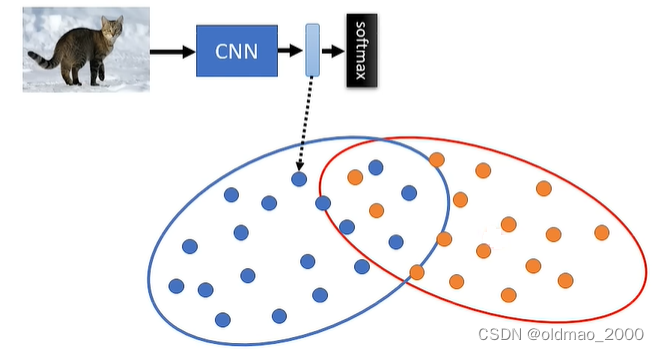
其中黄色点表示真实图片,蓝色点表示生成图片,Fréchet Inception Distance就表示两类图片分布的距离。这里的分布距离不好算,这里直接假设两个分布都是搞屎(你肯定想问为什么不是别的分布,我只能告诉你这是一个假设,等你写论文的时候就可以做主用其他分布)。距离越小代表生成图片与真实图片越接近。
这个方法的缺点是需要大量图片来拟合分布,上面的FID 10K就表示sample了10000张图片来完成FID的计算。
Contrastive Language-Image Pre-Training(CLIP)
CLIP来自文章:Learning Transferable Visual Models From Natural Language Supervision
这个玩意很简单,吃文字和图片,分别经过文字和图片的Encoder,得到各自的embedding表达,然后计算二者的距离作为CLIP值,距离越近得分越大,CLIP值越大越好。

这个模型在400万个图片文字对上进行了训练。原文做zero-shot prediction下游任务还做为结果做了处理,这里不需要。

Decoder
这个魔祖不需要文字与图片对进行训练,只需要无文本标记的图片就可以训练。
根据Generation Model生成的中间产物不一样,训练Decoder的方法也不同。
如果中间中间产物小图(谷歌的Imagen),Decoder需要将分辨率小的图片生成高分辨率的图片,则我们可以线找高清图片,然后对图片进行downsample操作得到小图,就可以得到训练数据与GroundTruth:
如果中间产物是embedding表征(DALL-E、Stable Diffusion):

则可以使用Auto-Encoder的套路来训练Decoder,结构如下图所示,目的就是要使得两处的图片越接近越好:
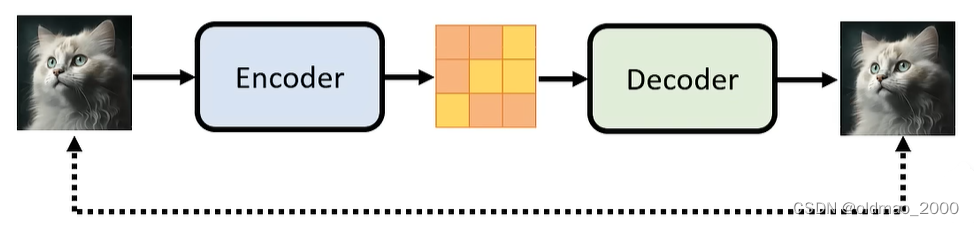
训练好了就可以把Decoder拿出来用。
把上面两种方法结合起来,若我们把输入图片的维度看成 H × W × 3 H\times W\times 3 H×W×3,中间产物无论是压缩的小图也好还是embedding也好,都可以看做是一个 h × w × c h\times w\times c h×w×c的向量。
Generation Model
上面的Forward Process(Diffusion Process)在讲解原理是,是将Noise加到图片上的,但是在实作的时候,从下图可以看到,Noise是加到中间产物上的,这里需要注意的是,Noise的维度大小要和中间产物一致。
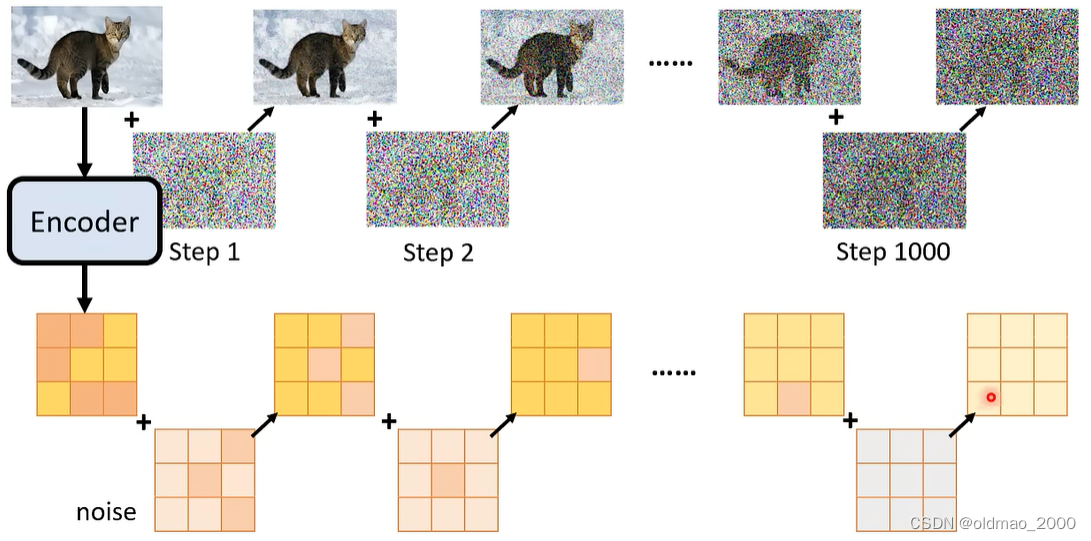
根据原理,Generation Model的输入如下图所示:
具体包括:
输入1:带有噪音的中间产物(上图蓝框黄色矩阵)
输入2:编号(上图中的step 2)
输入3:图片的文字描述的embedding(上图蓝色向量)
输出:输入1中的噪音(上图红框中的矩阵)
同理,Reverse Process如下图所示:
midjourney在生成图片的过程中并不是从噪音慢慢变成图片,而是把每一步的噪音接到Decoder把中间过程放出来,所以我们看到感觉是图片在变清晰。





![[SSD综述1.7] SSD接口形态: SATA、M.2、U.2、PCIe、BGA](https://img-blog.csdnimg.cn/0888a7fb5e504800bc792a7d74b0ac8e.png)

![旋转图像[中等]](https://img-blog.csdnimg.cn/040f90bbd07b4545bf54158d772588f7.png)