前言
上一篇文章 TensorFlow案例学习:简单的音频识别 我们简单学习了音频识别。这次我们继续学习如何使用成熟的语音分类模型来进行迁移学习
官方教程: 使用 YAMNet 进行迁移学习,用于环境声音分类
模型下载地址(需要科学上网): https://tfhub.dev/google/yamnet/1
YAMNet简介
YAMNet(Yet Another Music Recognition Network)是由谷歌开发的音乐识别模型。它是一个基于深度学习的模型,可以用于识别音频中的各种环境音、乐器音、人声等。
YAMNet 使用了卷积神经网络(CNN)作为主要的网络结构。它的输入是音频波形数据,通过一系列卷积和池化层来捕获不同尺度的特征。训练过程中,YAMNet 使用大量的带有标签的音频数据,通过监督学习的方式来学习到不同音频类别的特征表示。
YAMNet 的输出是一个分类器,可以将输入的音频波形数据预测为音频对应的类别。在预测过程中,YAMNet 会将输入音频进行分帧处理,并对每一帧进行分类。最后,通过对所有帧的分类结果进行平均,得到整个音频的分类结果。
YAMNet 的优势在于它专门用于音频场景的识别,可以识别出许多现实生活中的环境声音,包括动物叫声、乐器音、机械声、交通声等。它在对音频进行标签分类的任务中表现出色,并且在公开数据集上取得了很好的性能。
YAMNet 的开源实现可供使用,并提供了训练好的模型权重,可以直接应用于音频识别任务。它可以用于音频分类和标签预测,也可以作为其他音频应用中的基础模块。
安装tensorflow-io
我这里遇到一个问题,安装成功后一直提示找不到模块,我这里使用librosa来解决这部分问题
基本使用
加载模型
yamnet_model = hub.load('./yamnet_1')
print("yamnet_model:", yamnet_model)
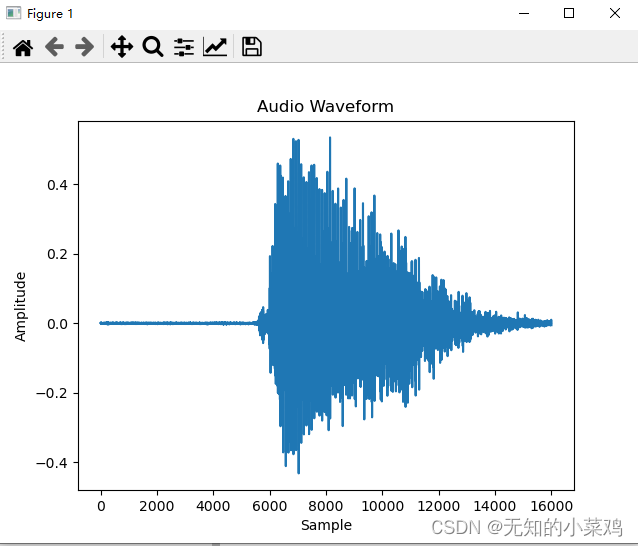
绘制音频波形
# 加载本地wav文件,并制定采样率为16000和单声道的形式进行重采样
def load_wav_16k_mono(filename):wav, sample_rate = librosa.load(filename, sr=16000, mono=True)return wavtesting_wav_data = load_wav_16k_mono('./test_data/down.wav')# 创建x轴坐标,以样本点为单位
x = np.arange(len(testing_wav_data))
# 绘制波形图
plt.plot(x, testing_wav_data)
plt.xlabel('Sample')
plt.ylabel('Amplitude')
plt.title('Audio Waveform')
plt.show()
加载类映射
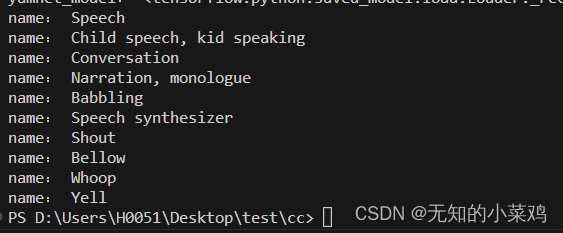
# 加载类映射
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names = list(pd.read_csv(class_map_path)['display_name'])for name in class_names[0:10]:print("name:", name)
预测
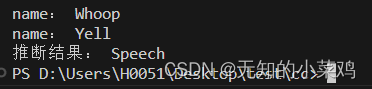
# 预测,获取最大可能性
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores,axis=0)
top_class = tf.math.argmax(class_scores)
inferred_class = class_names[top_class]print("推断结果:",inferred_class)
迁移学习一
处理数据集
下载数据集并解压到项目里
ESC-50数据集下载地址: https://github.com/karoldvl/ESC-50/archive/master.zip
该数据集由2000个50秒的环境音频记录的标记集合,该数据集由40个类组成。
筛选数据
官方文档筛选的是狗和猫,这里我们使用狗、猫、羊
my_classes = ['dog', 'cat', 'sheep']
map_class_to_id = {'dog': 0, 'cat': 1, 'sheep': 2}pd_data = pd.read_csv('./ESC-50-master/meta/esc50.csv')
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
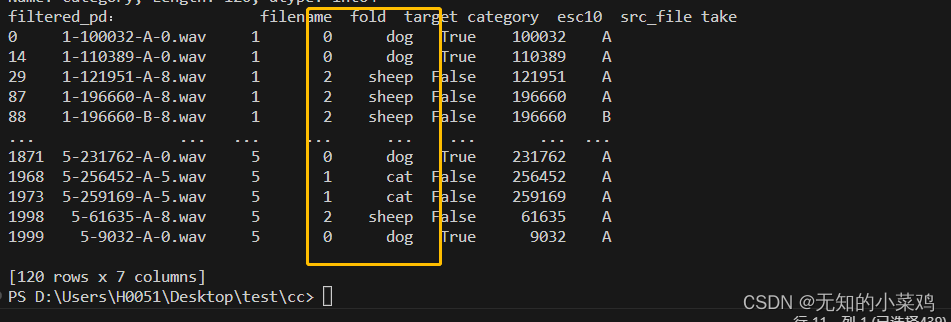
print("filtered_pd:", filtered_pd)class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
print("class_id:",class_id)filtered_pd = filtered_pd.assign(target=class_id)
print("filtered_pd:", filtered_pd)
这段代码的作用就是对三种动物进行筛选,并按照{'dog': 0, 'cat': 1, 'sheep': 2}进行划分,三种动物共120条数据
# 筛选数据:2、获取到文件完整的路径
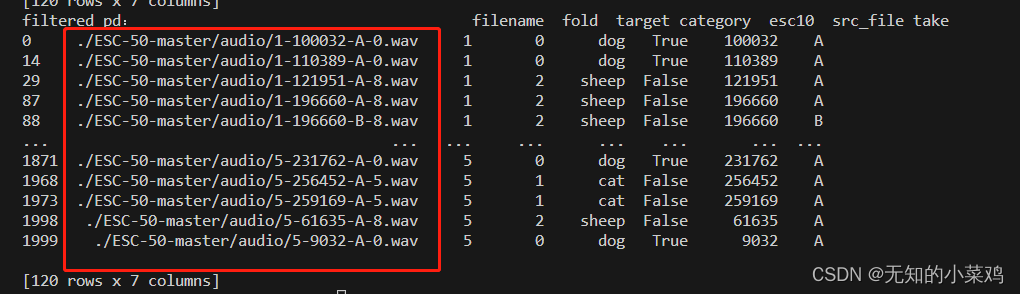
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
print("filtered_pd:", filtered_pd)
加载音频文件
# 加载音频文件并检索嵌入:1、filenames文件路径,target类别,
# fold每个音频文件所属的交叉验证折叠,可以理解为将不同种类的文件放在一个文件夹里,这个fold代表这个文件是在哪一个文件夹里,相当于文件夹的标记
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
print("filenames-targets-folds", filenames[0], targets[0], folds[0])# 加载音频文件并检索嵌入:2、创建包含三个元素:filenames、targets和folds的一个数据集对象
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
print("main_ds:", main_ds)
print("element_spec:", main_ds.element_spec)# 加载音频文件并检索嵌入:3、将音频变成单声道的16kHz采样的音频数据,使其符合模型的输入
def load_wav_16k_mono(filename):file_contents = tf.io.read_file(filename)wav, sample_rate = tf.audio.decode_wav(file_contents,desired_channels=1)wav = tf.squeeze(wav, axis=-1)sample_rate = tf.cast(sample_rate, dtype=tf.int64)wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)return wavdef load_wav_for_map(filename, label, fold):return load_wav_16k_mono(filename), label, foldmain_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
处理训练集数据
# 处理训练集数据
def extract_embedding(wav_data, label, fold):scores, embeddings, spectrogram = yamnet_model(wav_data)num_embeddings = tf.shape(embeddings)[0]return (embeddings,tf.repeat(label, num_embeddings),tf.repeat(fold, num_embeddings))main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
拆分数据
将数据拆分为训练集、验证集、测试集
# 拆分数据
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)# 删除fold列,训练时不需要def remove_fold_column(embedding, label, fold): return (embedding, label)train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
创建模型
# 创建模型,这里的1024与512是怎么来的一直没搞明白
my_model = tf.keras.Sequential([tf.keras.layers.Input(shape=(1024), dtype=tf.float32,name="input_embedding"),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dense(len(my_classes))
], name="my_model")my_model.summary()
编译训练模型
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),optimizer="adam",metrics=['accuracy'])callback = tf.keras.callbacks.EarlyStopping(monitor='loss',patience=3,restore_best_weights=True)
history = my_model.fit(train_ds,epochs=20,validation_data=val_ds,callbacks=callback)评估模型
loss, accuracy = my_model.evaluate(test_ds)print("Loss: ", loss)
print("Accuracy: ", accuracy)

测试模型
testing_wav_data = load_wav_16k_mono('./ESC-50-master/audio/1-57795-A-8.wav')
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')

将模型保存为可直接将WAV文件作为输入的模型
当您将嵌入作为输入时,您的模型就会起作用。
在实际场景中,您需要使用音频数据作为直接输入。
为此,您需要将 YAMNet 与模型合并到一个模型中,您可以导出该模型以供其他应用程序使用。
class ReduceMeanLayer(tf.keras.layers.Layer):def __init__(self, axis=0, **kwargs):super(ReduceMeanLayer, self).__init__(**kwargs)self.axis = axisdef call(self, input):return tf.math.reduce_mean(input, axis=self.axis)saved_model_path = './dogs_cats_sheep_yamnet'input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer('./yamnet_1',trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
完整代码
import tensorflow_hub as hub
import tensorflow as tfimport numpy as np
import pandas as pd
import os
import tensorflow_io as tfioyamnet_model = hub.load('./yamnet_1')base_data_path = './ESC-50-master/audio/'# 筛选数据
# 筛选数据:1、将数据按照{'dog': 0, 'cat': 1, 'sheep': 2}进行划分
my_classes = ['dog', 'cat', 'sheep']
map_class_to_id = {'dog': 0, 'cat': 1, 'sheep': 2}
pd_data = pd.read_csv('./ESC-50-master/meta/esc50.csv')
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
#print("filtered_pd:", filtered_pd)class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
#print("class_id:", class_id)filtered_pd = filtered_pd.assign(target=class_id)
#print("filtered_pd:", filtered_pd)
# 筛选数据:2、获取到文件完整的路径
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
#print("filtered_pd:", filtered_pd)# 加载音频文件并检索嵌入
# 加载音频文件并检索嵌入:1、filenames文件路径,target类别,
# fold每个音频文件所属的交叉验证折叠,可以理解为将不同种类的文件放在一个文件夹里,这个fold代表这个文件是在哪一个文件夹里,相当于文件夹的标记
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
print("filenames-targets-folds", filenames[0], targets[0], folds[0])# 加载音频文件并检索嵌入:2、创建包含三个元素:filenames、targets和folds的一个数据集对象
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
# print("main_ds:", main_ds)
# print("element_spec:", main_ds.element_spec)# 加载音频文件并检索嵌入:3、将音频变成单声道的16kHz采样的音频数据,使其符合模型的输入def load_wav_16k_mono(filename):file_contents = tf.io.read_file(filename)wav, sample_rate = tf.audio.decode_wav(file_contents,desired_channels=1)wav = tf.squeeze(wav, axis=-1)sample_rate = tf.cast(sample_rate, dtype=tf.int64)wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)return wavdef load_wav_for_map(filename, label, fold):return load_wav_16k_mono(filename), label, foldmain_ds = main_ds.map(load_wav_for_map)
print("main_ds:", main_ds)
# main_ds.element_spec# 处理训练集数据def extract_embedding(wav_data, label, fold):scores, embeddings, spectrogram = yamnet_model(wav_data)num_embeddings = tf.shape(embeddings)[0]return (embeddings,tf.repeat(label, num_embeddings),tf.repeat(fold, num_embeddings))main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec# 拆分数据
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)# 删除fold列,训练时不需要def remove_fold_column(embedding, label, fold): return (embedding, label)train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)# 创建模型,这里的1024与512是怎么来的一直没搞明白
my_model = tf.keras.Sequential([tf.keras.layers.Input(shape=(1024), dtype=tf.float32,name="input_embedding"),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dense(len(my_classes))
], name="my_model")my_model.summary()# 编译训练模型
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),optimizer="adam",metrics=['accuracy'])callback = tf.keras.callbacks.EarlyStopping(monitor='loss',patience=3,restore_best_weights=True)
history = my_model.fit(train_ds,epochs=20,validation_data=val_ds,callbacks=callback)
# 评估模型
loss, accuracy = my_model.evaluate(test_ds)print("Loss: ", loss)
print("Accuracy: ", accuracy)# 导出模型
class ReduceMeanLayer(tf.keras.layers.Layer):def __init__(self, axis=0, **kwargs):super(ReduceMeanLayer, self).__init__(**kwargs)self.axis = axisdef call(self, input):return tf.math.reduce_mean(input, axis=self.axis)saved_model_path = './dogs_cats_sheep_yamnet'input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer('./yamnet_1',trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)测试模型
import tensorflow as tf
import tensorflow_io as tfiodef load_wav_16k_mono(filename):file_contents = tf.io.read_file(filename)wav, sample_rate = tf.audio.decode_wav(file_contents,desired_channels=1)wav = tf.squeeze(wav, axis=-1)sample_rate = tf.cast(sample_rate, dtype=tf.int64)wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)return wav# 加载模型
my_model = tf.saved_model.load('./dogs_cats_sheep_yamnet')
# 测试
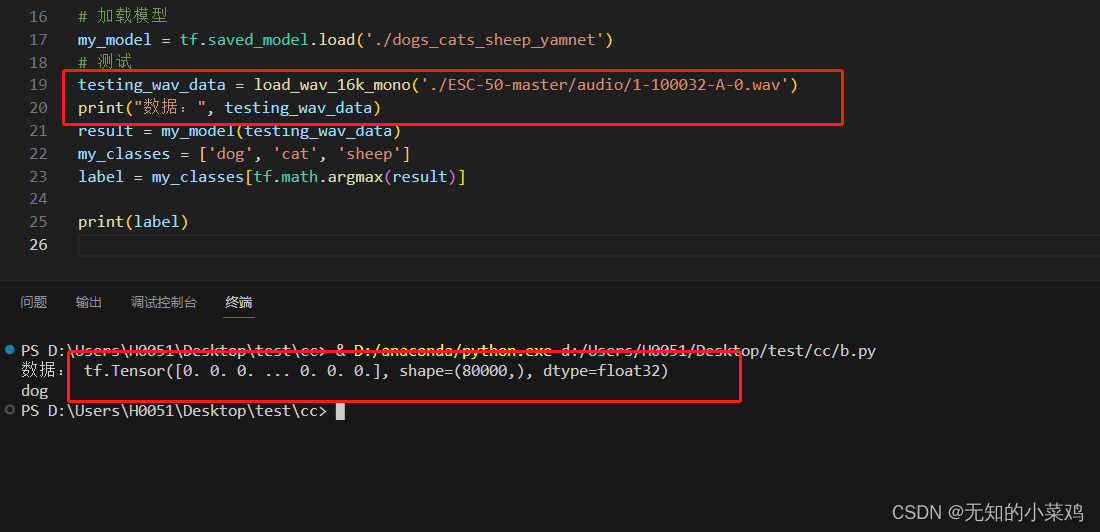
testing_wav_data = load_wav_16k_mono('./ESC-50-master/audio/1-100032-A-0.wav')
result = my_model(testing_wav_data)
my_classes = ['dog', 'cat', 'sheep']
label = my_classes[tf.math.argmax(result)]print(label)

迁移学习二
上面的迁移学习一直是按照教程来的,使用的数据集ESC-50 数据集 格式也不怎么常见。那么我们能不能根据这个格式,来构建自己的数据集,使代码可以复用。
数据集这里选择上一篇文章中的 mini_speech_commands 数据集。共有8种类别的音频,这里我们采用每种类别选择5个音频,一共40个音频,来构建自己的数据集。
说一下测试结果,由于数据太少,一个类别才5条数据。并且有3条数据是训练数据、1条数据是验证数据、1条数据是测试数据。导致测试结果不好,只有当数据是训练数据时能够得出正确结果,是其他数据时结果大部分适合都是不对的。
因此如果真的要使用的话,数据要多一点。上面的官方教程是共120条数据,一个类别有40条数据,训练数据要尽可能的多一些。

audio存放音频文件,commands.csv 存放音频的信息。从后面代码看我们只需要在commands.csv 中维护三列就行
filename文件名target文件所属的类别序号category文件所属的类别名称fold标识,代表这个文件是在哪一个文件夹里
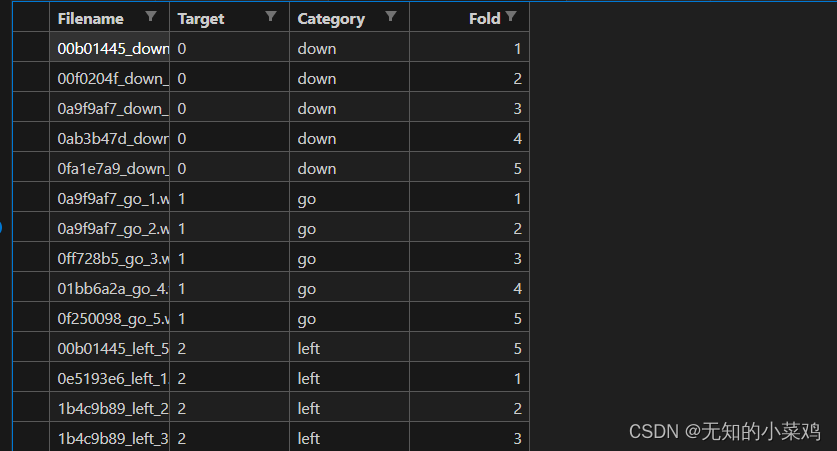
target的值要与你设置的相对应
map_class_to_id = {'down': 0, 'go': 1, 'left': 2,'no': 3, 'right': 4, 'stop': 5, 'up': 6, 'yes': 7}
修改训练文件
import tensorflow_hub as hub
import tensorflow as tfimport numpy as np
import pandas as pd
import os
import tensorflow_io as tfioyamnet_model = hub.load('./yamnet_1')base_data_path = './commands/audio'
csv_path = './commands/commands.csv'# 筛选数据
my_classes = ['down', 'go', 'left', 'no', 'right', 'stop', 'up', 'yes']
map_class_to_id = {'down': 0, 'go': 1, 'left': 2,'no': 3, 'right': 4, 'stop': 5, 'up': 6, 'yes': 7}
pd_data = pd.read_csv(csv_path)
#print("pd_data:", pd_data)
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
# 筛选数据获取完整路径
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
#print("filtered_pd:", filtered_pd)# 加载音频文件并检索嵌入
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
print("filenames-targets-folds", filenames[0], targets[0], folds[0])
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
# print("main_ds:",main_ds)# 将音频变成单声道的16kHz采样的音频数据,使其符合模型的输入def load_wav_16k_mono(filename):file_contents = tf.io.read_file(filename)wav, sample_rate = tf.audio.decode_wav(file_contents,desired_channels=1)wav = tf.squeeze(wav, axis=-1)sample_rate = tf.cast(sample_rate, dtype=tf.int64)wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)return wavdef load_wav_for_map(filename, label, fold):return load_wav_16k_mono(filename), label, foldmain_ds = main_ds.map(load_wav_for_map)
print("main_ds:", main_ds)# 处理训练集数据def extract_embedding(wav_data, label, fold):scores, embeddings, spectrogram = yamnet_model(wav_data)num_embeddings = tf.shape(embeddings)[0]return (embeddings,tf.repeat(label, num_embeddings),tf.repeat(fold, num_embeddings))main_ds = main_ds.map(extract_embedding).unbatch()# 拆分数据
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)# 删除fold列,训练时不需要def remove_fold_column(embedding, label, fold): return (embedding, label)train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)# 创建模型,这里的1024与512是怎么来的一直没搞明白
my_model = tf.keras.Sequential([tf.keras.layers.Input(shape=(1024), dtype=tf.float32,name="input_embedding"),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dense(len(my_classes))
], name="my_model")my_model.summary()# 编译训练模型
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),optimizer="adam",metrics=['accuracy'])callback = tf.keras.callbacks.EarlyStopping(monitor='loss',patience=3,restore_best_weights=True)
history = my_model.fit(train_ds,epochs=20,validation_data=val_ds,callbacks=callback)
# 评估模型
loss, accuracy = my_model.evaluate(test_ds)print("Loss: ", loss)
print("Accuracy: ", accuracy)# 导出模型class ReduceMeanLayer(tf.keras.layers.Layer):def __init__(self, axis=0, **kwargs):super(ReduceMeanLayer, self).__init__(**kwargs)self.axis = axisdef call(self, input):return tf.math.reduce_mean(input, axis=self.axis)saved_model_path = './command_yamnet'input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer('./yamnet_1',trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
补充
如果想直接在浏览器里使用,需要解决的一个问题就是如何将一个音频文件变成符合模型的输入,下面是我找到的方式(没有测试,不知道是否可以)
async function audioFileToTensor(audioFile) {// 读取音频文件const audioBuffer = await fetch(audioFile).then(response => response.arrayBuffer()).then(arrayBuffer => audioContext.decodeAudioData(arrayBuffer));// 获取音频数据const audioData = audioBuffer.getChannelData(0); // 获取音频的第一个通道的数据// 创建一个全零的Tensorconst tensor = tf.tensor(audioData, [audioData.length]);return tensor;
}// 使用示例
const audioFile = 'path/to/your/audio/file.mp3';
const audioContext = new AudioContext();
const tensor = await audioFileToTensor(audioFile);
console.log(tensor);
本质上就行需要想办法处理音频,让音频变成符合的格式。