在初期,已经讲述了Redis安装问题。现在正式进入Redis的入门阶段
系统架构的演进
传统单机架构
一台机器运行应用程序、数据库服务器
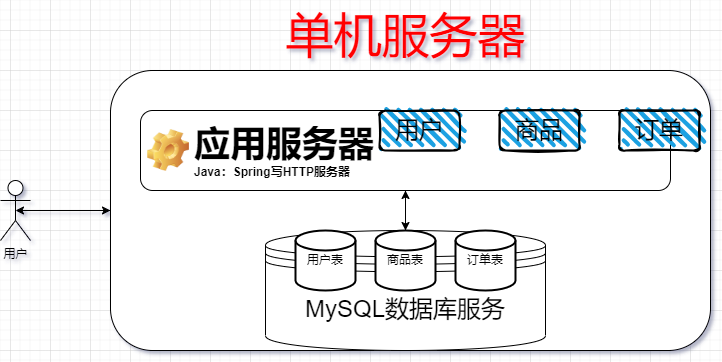
现在大部分公司的产品都是这种单机架构。因为现在计算机硬件发展速度很快,哪怕只有一台主机,性能也很高的。可以支持几万级别的高并发和庞大的数据存储。
当业务进一步增长,用户量和数据量水涨船高。一台主机难以应付的时候就需要引入更多的主机和硬件资源
最主要的是CPU、内存、硬盘、网络
服务器每次收到一个请求,都是需要消耗上述的资源。如果同一时刻请求多了,某个硬件资源不够用【木桶效应】都可能会导致服务器处理请求时间变长甚至出错。一般的解决方案也是围绕着开源节流
- 开源:简单粗暴,增加更多的硬件资源【但一个主机能增加的硬件资源也是有限的】
- 一台主机扩展到了极限就会引入多台机器【可以通过一致性哈希算法分配和调整机器】,一旦引入多台主机就可以称为“分布式”
引入分布式是万不得已的方案。系统的复杂程度会大大提高,出现BUG的概率越高。加班概率&丢失年中奖的概率也随之提高
- 节流:软件上优化【通过性能测试,找到哪个环节出现了瓶颈再去对症下药】。但对技术水平要求高
引入分布式
传统的单主机架构既负责应用服务又要负责存储服务当业务量增长的时候就会出现第一次的性能瓶颈,此时可以通过基础的分布式:应用和存储分离进而分散流量压力,根据业务进行自定义服务器配置
应用和数据库分离,分别部署到不同主机上
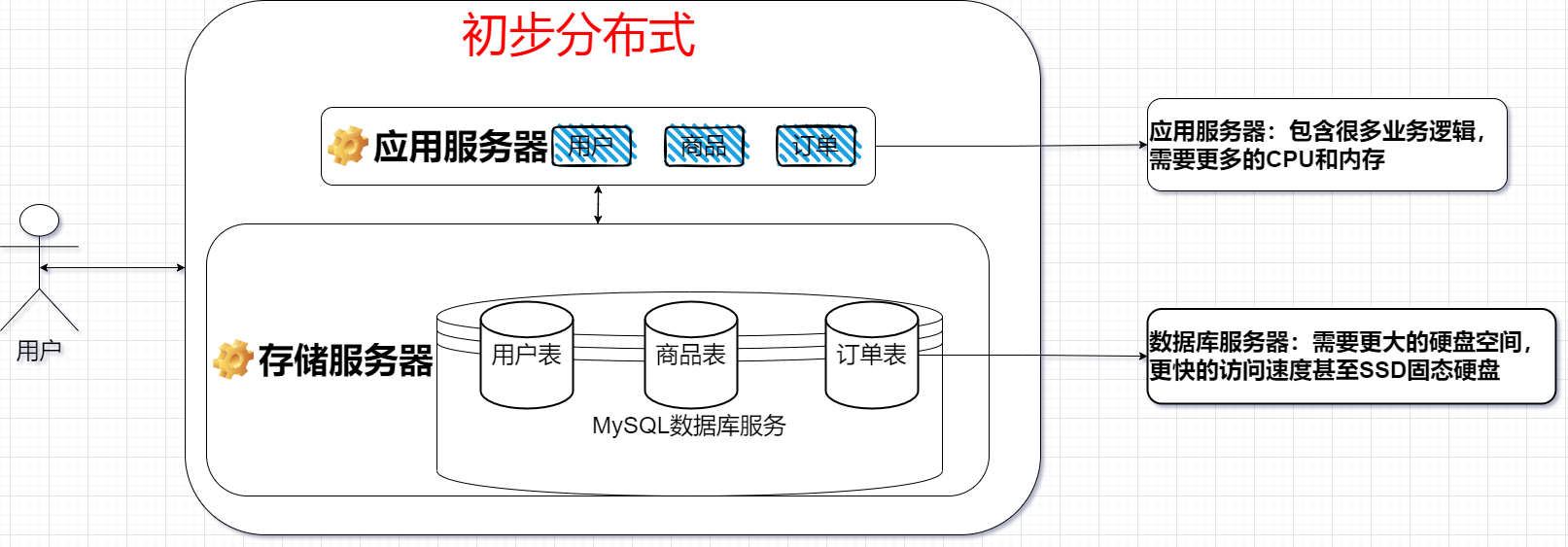
如果还需要提升性能,可以考虑引入负载均衡,合理分配流量到对应的应用服务器
分布式解决的是初步的处理HTTP请求和数据库读写的性能瓶颈
引入负载均衡
如果应用服务器的CPU和内存资源吃完之后,还可以引入更多的应用服务器通过负载均衡器比较均匀的分配请求给应用服务器就可以有效解决第二次的性能瓶颈。集群中的某个主机宕机、其它的主机仍然可以承担服务提高整个系统的可用性

假设有1w个用户请求,有两个应用服务器就可以负载均衡模式就可以让每个应用服务器承担0.5w的访问量
和多线程有点像
负载均衡器就像公司的一个组的领导一样,要负责管理,把任务分配给每个组员。对于负载均衡器来说,有很多的 负载均衡 具体的算法,它对于请求量的承担能力远远超过服务器
负载均衡器是领导,分配任务
应用服务器是组员,执行任务
如果出现了请求量大到负载均衡器也扛不住压力的时候可以再引入更多的负载均衡器,甚至引入硬件资源(F5)进行更大的分流
负载均衡结局的是应用服务器处理大量HTTP请求问题
引入数据库读写分离
虽然增加应用服务器、确实可以处理更高的请求量。但是随之而来的存储服务器要承担的请求量也就更多
处理办法还是:开源+节流(门槛高,更复杂)。简单粗暴的增加一个存储服务器,将读写操作分离
一个数据库节点作为主节点负责写数据,其它N个数据库节点作为从节点负责读数据
主节点需要把修改的数据同步给从节点
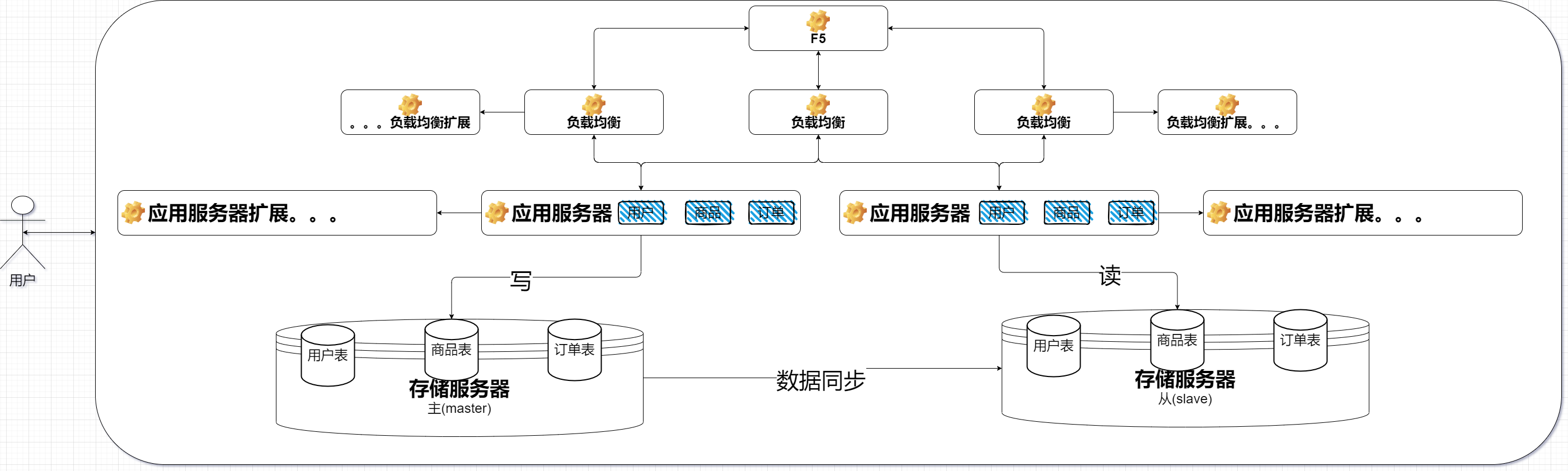
但是数据库天然的问题就是:响应速度慢。解决方案就是进行数据区分引入缓存
数据库读写分离解决的是数据库读写性能瓶颈问题
引入缓存
把数据区分“冷热”、热点数据放到缓存中,缓存的访问速度比数据库很多
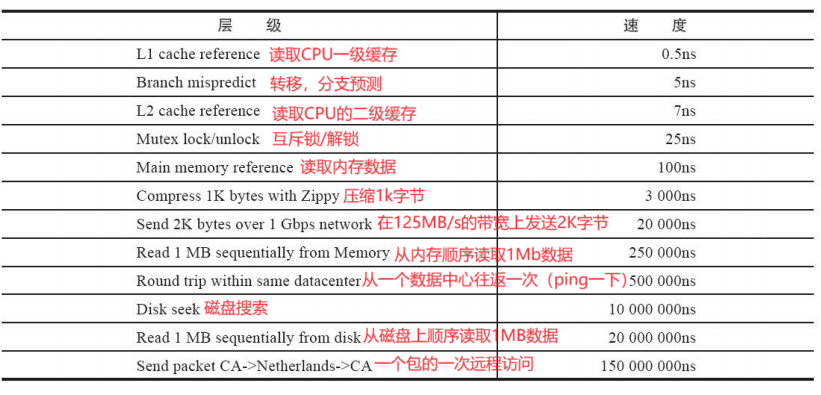
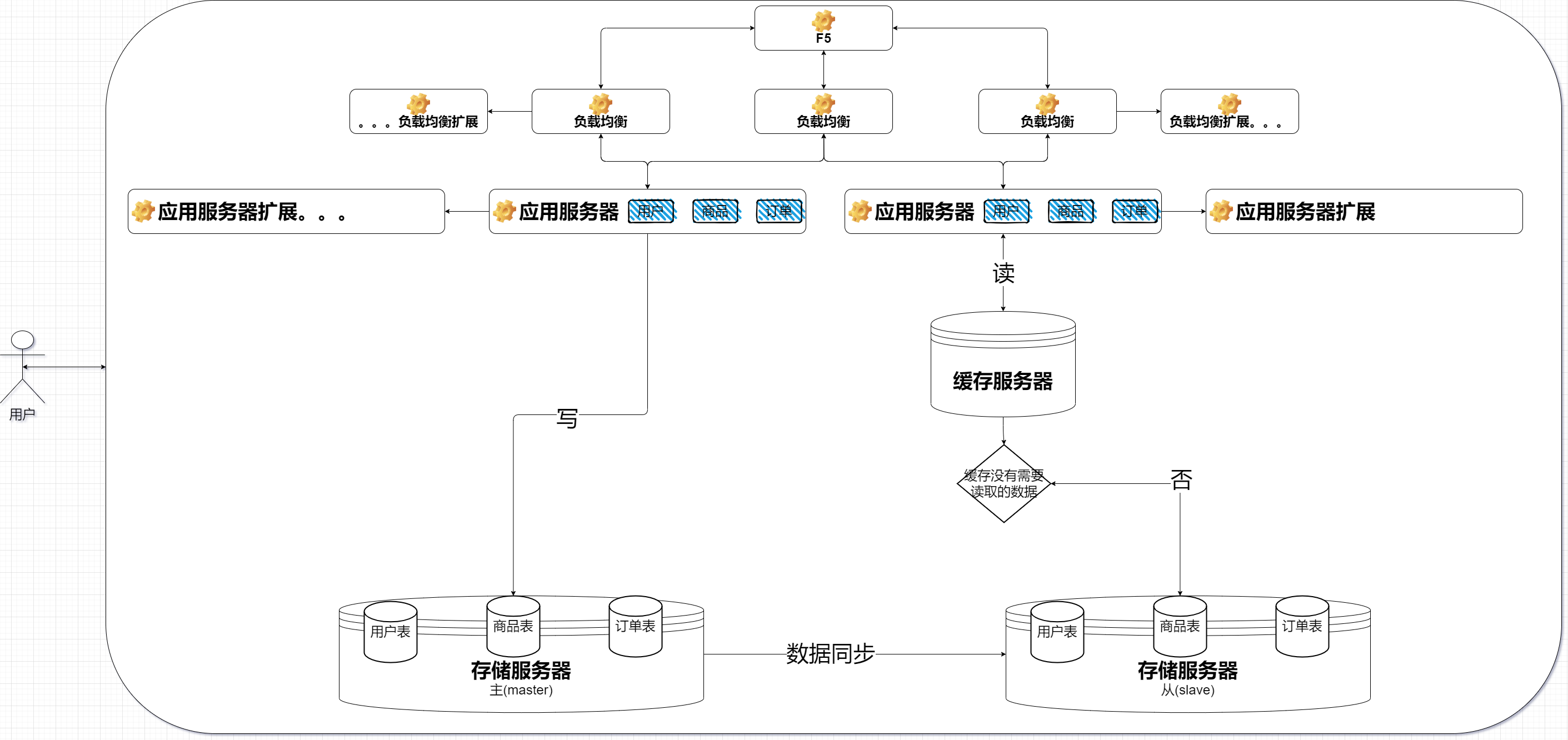
缓存服务器只是存放一小部分热点数据,采取二八原则【20%数据能够支持80%的访问量】
具体的 二八,三七,一九得看实际场景,略有差异
这里的缓存就用的Redis、但缺点就是内存小。从此可以看出缓存服务器扛住了大量的读请求负重前行,因此需要一个皮实的缓存服务器就可以进一步提高并发量
这里也需要考虑缓存中的数据同步问题,比如双十一商品会打折。那么主从数据库更新数据之后缓存也需要跟着修改
引入缓存解决的是数据库读的瓶颈问题
隐入新的问题:缓存的修改可能会出现数据同步一致性的问题
引入数据库分库分表
引入了分布式不仅要能够去应对高并发的请求量,同时也要能应对更大的数据量。因为依旧会存在一台服务器已经存不下数据的意外发生
比如短视频平台虽然一个服务器存储的数据量可以达到几十TB,但即使如此也会有大量用户数据存不下的情况发生
我们可以针对数据进一步的分析:分库分表
一个数据库服务器上有多个数据库(逻辑上的数据集合CREATE DATABASE db_name)。现在就可以引入多个数据库服务器,每个数据库服务器存储一个或者一部分数据库
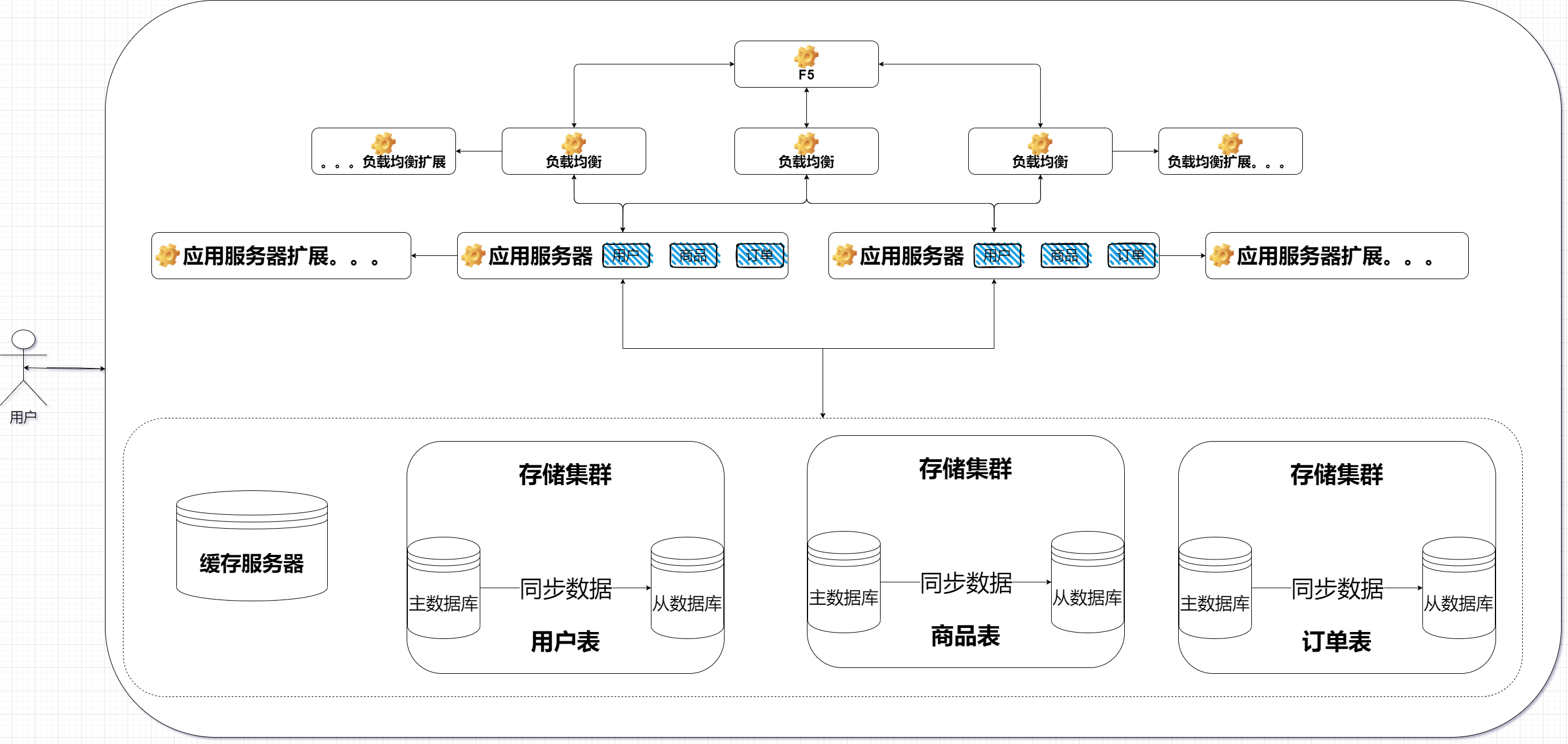
如果某个表特别大,比如订单表。大到一个服务器存不下,就需要对表进行拆分成多个服务器进行分开存储
数据库分库分表解决的是存储海量数据的问题
引入微服务
之前单个应用服务器做了很多业务,可能会导致服务器代码越来越复杂。后期为了维护方便,就可以把这样的一个复杂的服务器拆分成更多、功能更单一但是更小的服务器(微服务)
此时服务器的种类和数量就增加了
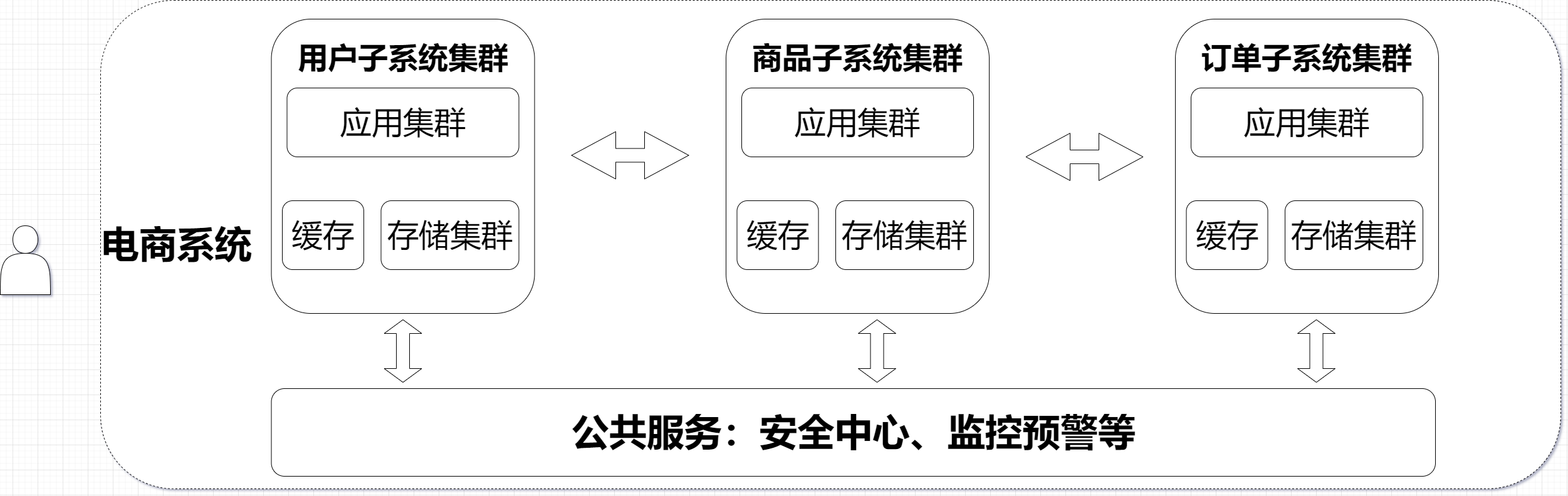
微服务本质上是解决的 “人” 的问题,但应用服务器复杂了,势必需要更多的人来维护了但也需要付出一定的代价
- 微服务优势
- 解决人的问题
- 使用微服务可以实现功能复用
- 可以给不同的服务进行不同的部署
- 微服务劣势
- 系统性能下降
- 拆出来更多的服务,多个功能之间更依赖网络通信,而网络通信的速度实际上可能比硬盘更慢。但现在有些 万兆网卡 的读写性能已经超过硬盘读写了
- 系统复杂程度提高,可用性受到影响
- 服务器更多了,出现问题的概率就更大了。【更丰富的监控机制、配套的运维人员】
有的业务场景适合微服务,有的不一定适合微服务(钞能力)
- 服务器更多了,出现问题的概率就更大了。【更丰富的监控机制、配套的运维人员】
- 系统性能下降
Redis特性介绍
Redis的初心是用来作为一个“消息中间件”使用(消息队列),但当前很少使用Redis作为消息中间件(业界有更多更专业的消息中间件使用)
如果单机程序、直接通过变量存储数据的方式比Redis更优。但由于进程的隔离性,需要通过“网络”进行进程间通信
Redis就是基于网络把自己内存中的数据给被的进程甚至被的主机使用【分布式的前提准备】
通常互联网的热点数据也会遵守一个“二八原则”:20%的热点数据能满足80%的访问需求
打开官网就会发现它的特性
In-memory data structures

- MySQL主要是通过 “表” 的方式来存储组织数据【关系型数据库】
- Redis主要是通过 “键值对” 的方式来存储组织数据【非关系型数据库】
- key都是string,value则可以使上述的这些数据结构
Programmability

- Lua也是一个编程语言。针对Reis操作,可以直接通过简单的交互式命令进行操作也可以通过一些脚本的方式批量执行一些操作(可带有一定逻辑)
Extensibility

- 通过这些语言可以编译出Redis扩展【win的dll、linux的.so】
- 可以扩展出Redis支持一个搜索二叉树的数据结构
- 通过这些语言可以编译出Redis扩展【win的dll、linux的.so】
Persistence
-

- Redis把数据存储在内存上,当进程/系统重启内存的数据就会丢失。为此Redis会把数据存储的硬盘上。内存为主、硬盘为辅
硬盘相当于对内存数据备份。当Redis重启就会在重启是加载硬盘中的备份数据使Redis的内存恢复到重启前的状态
- Redis把数据存储在内存上,当进程/系统重启内存的数据就会丢失。为此Redis会把数据存储的硬盘上。内存为主、硬盘为辅
Clustering
-

- Redis作为一个分布式系统的中间件,能够支持集群是很关键的。这个水平扩展类似于“分库分表”
一个Redis能够存储的数据有限(内存空间有限),引入多个主机。部署多个 Redis 节点,每个 Redis 存储数据的一部分
- Redis作为一个分布式系统的中间件,能够支持集群是很关键的。这个水平扩展类似于“分库分表”
High availability
-

- 高可用也可以换做说话冗余/备份
- Redis本身也是支持“主从”结构,从节点就相当于主节点备份,主节点挂掉的话从节点就会充当主节点
为什么Redis速度很快
-
Redis数据在内存中,就比访问硬盘的速度快很多
-
Redis的核心功能都是比较简单的逻辑:操作内存的数据结构
-
从网络角度上,Redis使用了IO多路复用的方式(epoll)
- 使用一个线程,管理多个socket
-
Redis使用的是单线程模型
- 高版本的Redis引入了多线程,但也只是网络IO中用到了多线程。核心业务逻辑依旧是单线程
- 这样的单线程模型减少了不必要的线程之间的竞争开销
- 这可能和之前的人之中多线程提高业务效率有悖论
多线程提高效率的前提是:CPU密集型的任务。使用多个线程可以充分利用CPU多核资源
但是Redis的核心人物主要就是操作内存的数据结构,不会吃很多CPU,因此使用多线程还需要数据安全问题,锁竞争,开锁解锁的操作反而会拖累效率
- 这可能和之前的人之中多线程提高业务效率有悖论
-
Redis是用C语言开发的所以就快
MySQL也是C语言开发的,那么MySQL的慢和Redis的快也似乎没有必定的关联关系。如果用Python开发也会比C慢,但一般说Redis的快都是和MySQL作比较的
应用场景
Real-time data store
把Redis当作数据库使用:存全量数据
- Redis’ versatile in-memory data structures enable building data infrastructure for real-time applications that require low latency and high-throughput.
Redis 的多功能内存数据结构能够为需要低延迟和高吞吐量的实时应用程序构建数据基础设施
在线搜索引擎项目中构建的一些索引数据结构
Caching & session storage
把Redis当作缓存使用:存热点数据/会话
- Redis’ speed makes it ideal for caching database queries, complex computations, API calls, and session state
Redis 的速度使其成为缓存数据库查询、复杂计算、API 调用和会话状态的理想选择
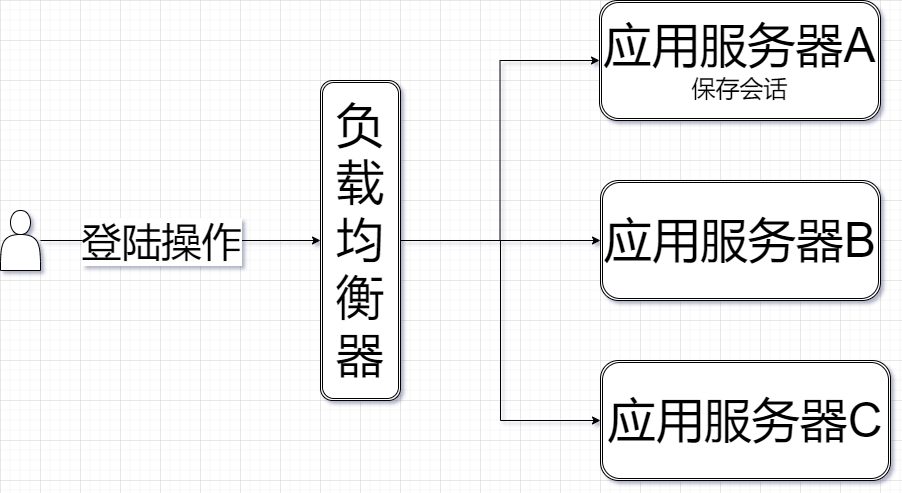
当用户第一次登陆时,负载均衡器分配A服务器,此时BC服务器没有保存用户的会话sessionID。当用户再次访问的时候如果分配到了BC服务器处理该用户请求的话就会重新登陆
解决方案:- 想办法让负载均衡器把同一个用户的请求时中达到同一个服务器【不采取轮询,而是通过userID求余之类的方式来分配服务器】
- 把会话单独拎出来,放到Redis服务器上进行保存。这样每次请求,ABC服务器都会从Redis服务器上拿会话
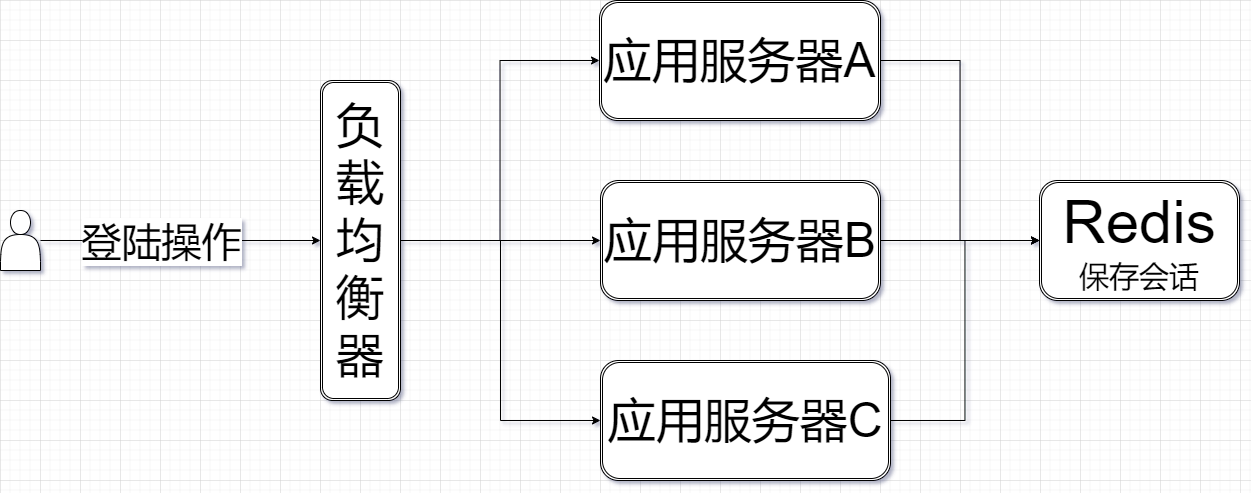
当应用服务器重启,用户也不需要重新登陆
Streaming & messaging
消息队列
- The stream data type enables high-rate data ingestion, messaging, event sourcing, and notifications
流数据类型支持高速数据摄取、消息传递、事件源和通知
- 可以实现一个网络版本的生产者消费者模型。对于分布式系统来说,服务器之间有时候也需要使用到生产者消费者模型【解耦合、削峰填谷】
但业界更多的是用RabitMQ、Kafka、RocketMQ
Redis初衷是做消息队列,但是阴差阳错它的缓存功能大火被当作缓存用。它的消息队列功能后续也就停止发展,没有其它专业的消息队列功能强大
Redis最不能做的事情就是存储大规模的数据
通用命令
redis中的命令不区分大小写
keys
-
作用:通过正则查询当前服务器上匹配的key
-
语法
-
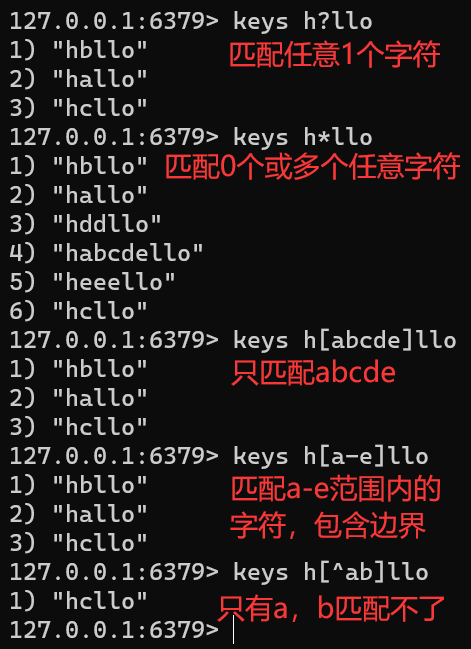
KEYS patternset hallo 1 set hbllo 1 set hcllo 1 set hddllo 1 set heeello 1 set habcdello 1keys h?llo keys h*llo keys h[abcde]llo keys h[a-e]llo # 由于 heeello 中间是3个e而不是单独的字符,所以无法匹配 keys h[^ab]llo # 生产环境禁止查询全部key keys * -
h?llomatcheshello,halloandhxllo -
h*llomatcheshlloandheeeello -
h[ae]llomatcheshelloandhallo,but nothillo -
h[^e]llomatcheshallo,hbllo, … but nothello -
h[a-b]llomatcheshalloandhbllo -
-
-
时间复杂度:O(N)
-
注意
redis 是一个单线程服务器,keys * 执行的时间非常长,就使 redis 服务器被阻塞,此时其它请求的查询超时之后就会直接查询MySQL数据库,突然一大波请求过来,MySQL措手不及就容易挂掉
整个系统也就基本瘫痪了,要是没能及时发现及时恢复的话年终奖妥妥的就没啦,更严重工作也被一波带走未来工作中会涉及到的几个环境
- 办公环境
- 入职之后,公司给你发的个人办公电脑
- 开发环境
- 有时候开发环境和办公环境是同一个【前端/客户端】
- 也有时候开发开发环境是单独的服务器【后端】
- 有的后端程序很有可能是单独的服务器,编译一次时间特别久
- 有的后端程序已启动要消耗很多的 cpu 和 内存 资源
办公电脑难以支撑
- 有的程序比较依赖 Linux,在 Windows 环境中搭不起来
- 测试环境
- 测试工程师使用的【一般配置都很高】
- 线上环境/生产环境
办公环境、开发环境、测试环境、线下环境。外界用户无法访问到
线上环境则是 外界用户 能够访问到的,一但生产环境出问题,一定会对于用户的使用产生影响
- 办公环境
exists
- 作用:判断某个 key 是否存在
- 语法
-
EXISTS key [key ...]exists hbllo exists hallo exists hbllo hallo ```
-
- 时间复杂度:O(1)
redis 组织这些 key 是按照 哈希表 的方式来组织的
- 返回值:key 存在的个数
这里针对的是多个 key 来说,是非常有用的
比如上文中分两次判定 key 是否存在和一次判定两个 key 的存在。redis 是一个客户端《==》服务器结构的程序,客户端和服务器之间通过网络来进行通信,网络通信成本高效率低(封装复用)
del
- 作用:删除指定的 key
- 语法
-
DEL key [key ...]del hallo del hbllo hcllo hzllo ```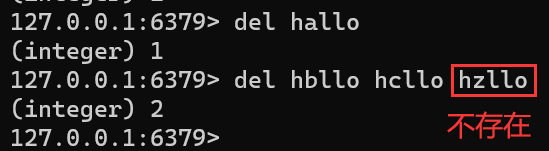 > Redis的删除操作危险程度远低于MySQL的删除操作(DROP DATABASE、DROP TABLE、DELETE FROM)。Redis主要应用场景就是作为缓存,此时Redis里存的只是一个热点数据,全量数据是在MySQL数据库中。相比之下如果是MySQL这样的数据,哪怕删除了一条数据,都可能影响很大 > <font color=skyblue>作为缓存,如果Redis大半的数据没了,这种影响会很大</font> > <font color=skyblue>作为数据库,如果Redis误删数据,这种影响会很大</font> > <font color=skyblue>作为MQ消息队列,如果Redis误删数据,这种影响需要具体问题具体分析</font>
-
- 时间复杂度:O(1)
- 返回值:删除掉的 key 的个数
expire
- 作用:给指定的 key 设置过期时间
key 存活时间超出这个指定的时间,就会被自动删除
很多业务场景都有时间限制:手机验证码5分钟内有效,外卖的优惠券,基于 redis 实现 分布式锁(为了避免出现不能正确解锁的情况,通常都会在加锁的时候设置一下过期时间) - 语法
EXPIRE key seconds [NX | XX | GT | LT]expire hzllo 10 expire habcdello 5 get habcdello# 对于计算机来说:秒 是一个非常长的时间 PEXPIRE key milliseconds [NX | XX | GT | LT] ```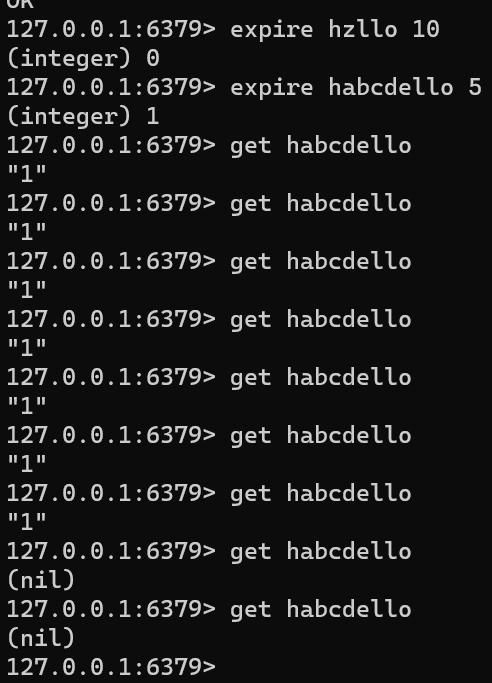 - 时间复杂度:O(1)
- 返回值:1表示设置成功、0表示设置失败
必须针对已经存在的 key
ttl
- 作用:time to live。剩余的过期时间
IP协议包头中就有一个字段TTL,它用转发次数衡量的
- 语法
TTL keyexpire hddllo 10 ttl hddllo get hddllo# 如果对时间有更高的精度,则可以使用 PTTL PTTL key ``` - 时间复杂图:O(1)
- 返回值:剩余过期时间(s)。-1:key无过期时间,-2:key不存在
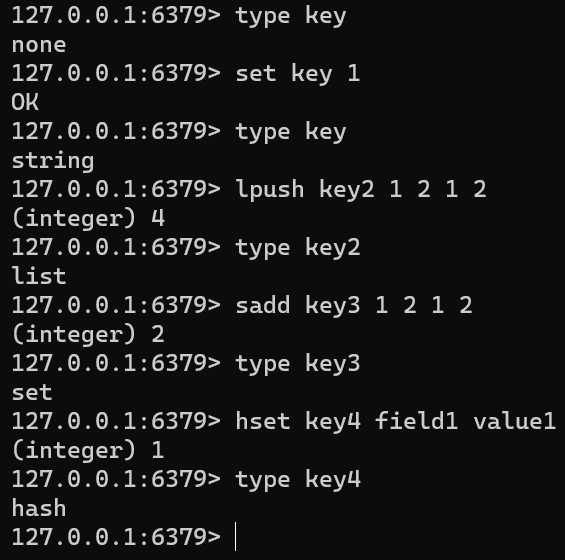
type
- 作用:返回 key 对应的数据类型
- none、string、list、set、zset、hash 和 stream
- stream:Redis 当消息队列的时候
- none、string、list、set、zset、hash 和 stream
- 语法
-
TYPE keytype key set key 1 type key lpush key2 1 2 1 2 type key2 sadd key3 1 2 1 2 type key3 hset key4 field1 value1 type key4lpush:左边插入【头插】、rpush右边插入【尾插】
-
- 时间复杂度:O(1)
- 返回值:key 对应的数据类型
key的过期策略
redis 的 key 过期策略是怎么实现的?
一个 reids 中可能同时存在很多 key,这些 key 中可能有很大一部分有过期时间。此时 redis 服务器如何知道哪些 key 已经过期要被删除,哪些 key 还未过期呢?
redis过期策略主要分为两大类
-
定期删除
-
每次抽取一部分验证过期时间,保证这个抽取检查的过程足够快
这里对定期删除有明确的时间要求原因:因为 redis 是单线程程序,如果扫描过期 key 消耗时间过多就可能导致正常处理请求命令被阻塞(产生类似于 key * 效果)
-
-
惰性删除
- 假设 key 已经到过期时间但暂时还没把它删除紧接着后面又一次访问正好用到了这个 key,于是这次访问就会让 redis 服务器触发删除 key 的操作,同时再返回一个 nil
虽然有了上述两种策略结合,但整体效果一般。仍然可能会有很多过期的 key 被残留,没有被及时清理
因此 redis 又提供了一些列的内存定期淘汰策略
定时器的实现原理
定时器:在某个时间到达之后执行指定任务
-
优先级队列
实现原理:把要执行的任务放入优先级队列中,此时定时器中只要分配一个线程,让这个线程去检查队首元素是否过期
用小堆: 此时只需要每次扫描堆顶元素而不需要遍历所有 key
扫描线程检查队首元素是否过期时候也不能太频繁,因为会无缘无故消耗很多CPU资源。优化方案: 根据当前时间和队首元素设置一个等待时间,当时间到之前唤醒此扫描线程
如果线程休眠的时候放入了一个优先级更高【更早执行】的新任务,此时可以在任务添加的时候唤醒一下扫描线程,重新检查队首元素,再根据时间差重新调整阻塞时间
一个利用阻塞队列+线程模拟实现的定时器
package src;import java.util.concurrent.PriorityBlockingQueue;class MyTimer {static class Task implements Comparable<Task> {//1.执行具体的任务private Runnable runnable;//2.执行任务等待的时间private long time;public Task(Runnable runnable, long time) {this.runnable = runnable;this.time = System.currentTimeMillis() + time;}@Overridepublic int compareTo(Task o) {return (int) (this.time - o.time);}public void run() {this.runnable.run();}}//3.把任务组织在一起private PriorityBlockingQueue<Task> tasks = new PriorityBlockingQueue();// 4.往定时器中加任务public void schedule(Runnable runnable, long after) {Task task = new Task(runnable, after);tasks.put(task);}// 4.创建一个扫描线程,扫描队首元素private Object locker = new Object();public MyTimer() {Thread t = new Thread(() -> {while (true) {try {Task task = tasks.take();long cur_tim = System.currentTimeMillis();if (cur_tim <= task.time) {tasks.put(task);synchronized (locker) {locker.wait(task.time - cur_tim);}} else {task.run();}} catch (InterruptedException e) {throw new RuntimeException(e);}}});t.start();}
}public class TimerPrinciple {public static void main(String[] args) {MyTimer myTimer = new MyTimer();Runnable runnable = new Runnable() {@Overridepublic void run() {System.out.printf("%s任务执行完毕\n", Thread.currentThread().getName());}};long after = 1000;System.out.printf("%s线程开始执行,%s 秒后开始执行Task任务\n", Thread.currentThread().getName(), after / 1000);myTimer.schedule(runnable, after);}
}- 时间轮
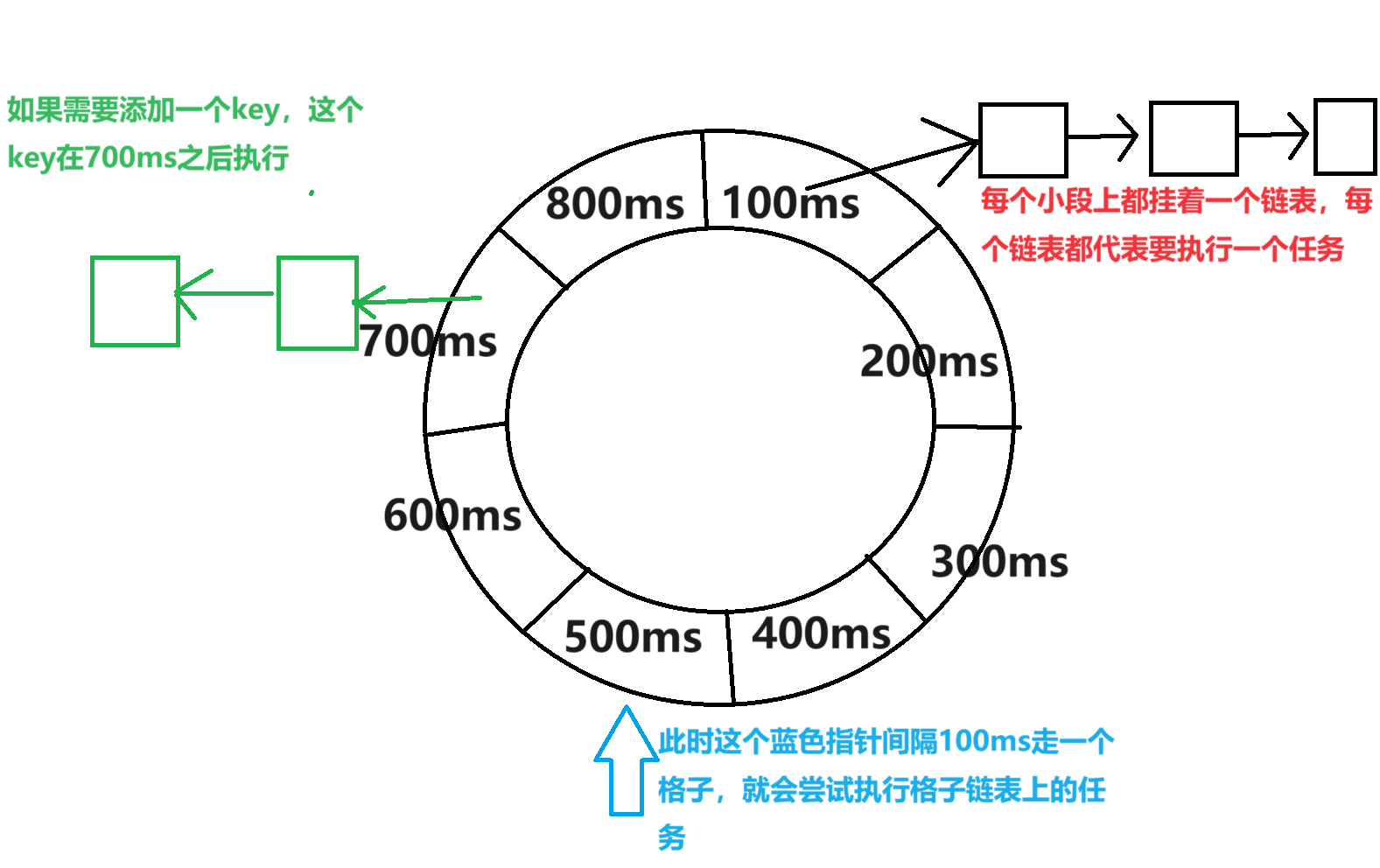
如果有一个key设置的过期时间特别长,比如3000ms。则会转3圈过后放在第5个格子【600ms】,然后当蓝色指针转到第6个格子时会检查该链表上的任务时间是否到了,到了才执行
- 箭头相当于一个函数指针【指向函数的指针】以及对应的参数
- 时间划分成很多小段,划分的粒度看实际需求
但Redis的定时器并未按照上述两种方案进行设计,初衷可能是不引入多线程。但上述两种方案是比较高效的实现方式,很多场景也会用到
数据类型和编码方式
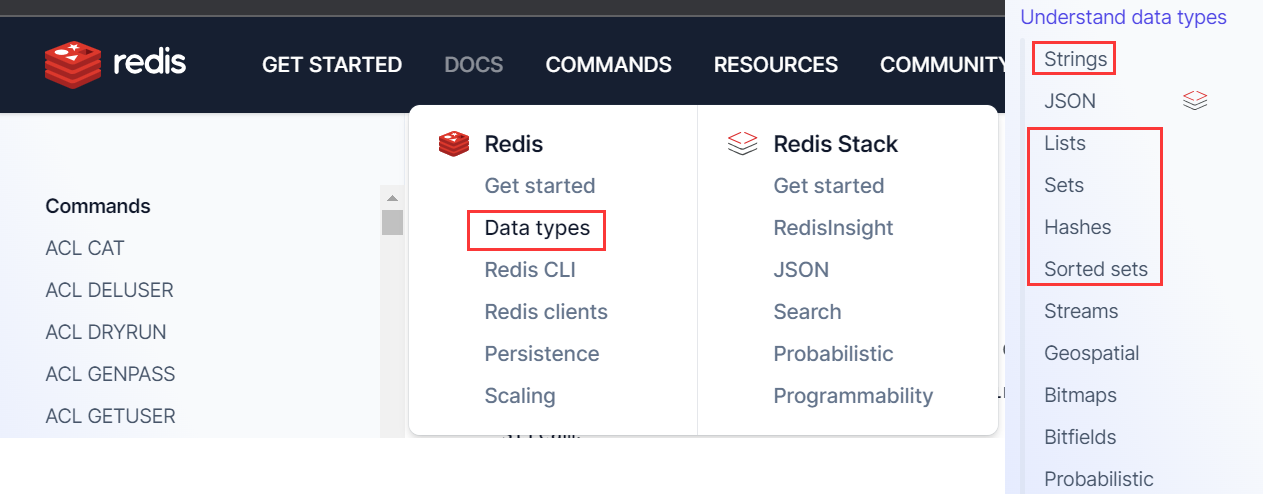
圈红的是常用的
Redis底层在实现上述数据结构的时候会在源码层面进行优化来达到 节省时间/空间 效果。
Redis内部有个 hash表 再进行 CRUD 操作可以保证 O(1) 复杂度但是背后的实现不一定是一个标准的 hash表,可能特定场景下使用别的数据结构但是仍然保证时间复杂度符合 O(1)
Redis会自动根据当前的实际情况选择内部的编码方式自动适应【只需要理解思想而不是全部记住】

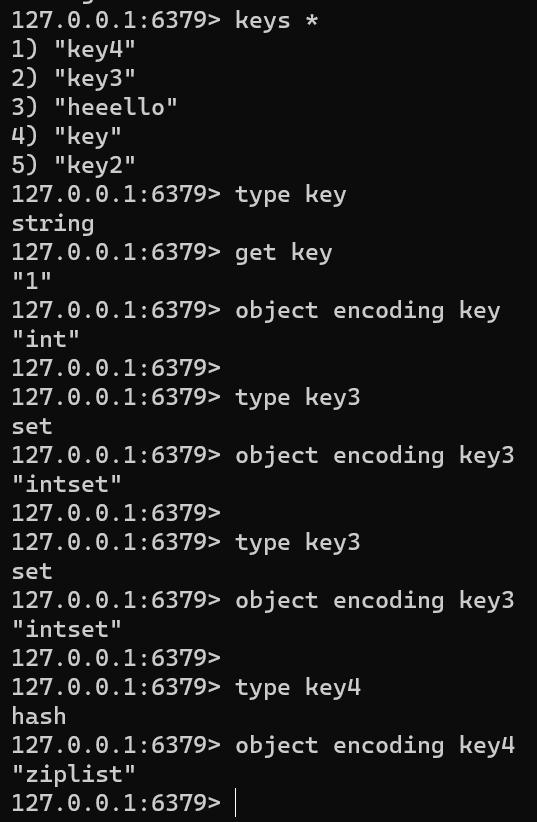
keys *
type key
get key
object encoding keytype key3
object encoding key3type key3
object encoding key3type key4
object encoding key4
单线程模型的工作过程
单线程并非是Redis服务器内部只有一个线程,而是只有一个线程处理所有的命令请求。其实Redis内部有多个线程,这些线程处理网络IO
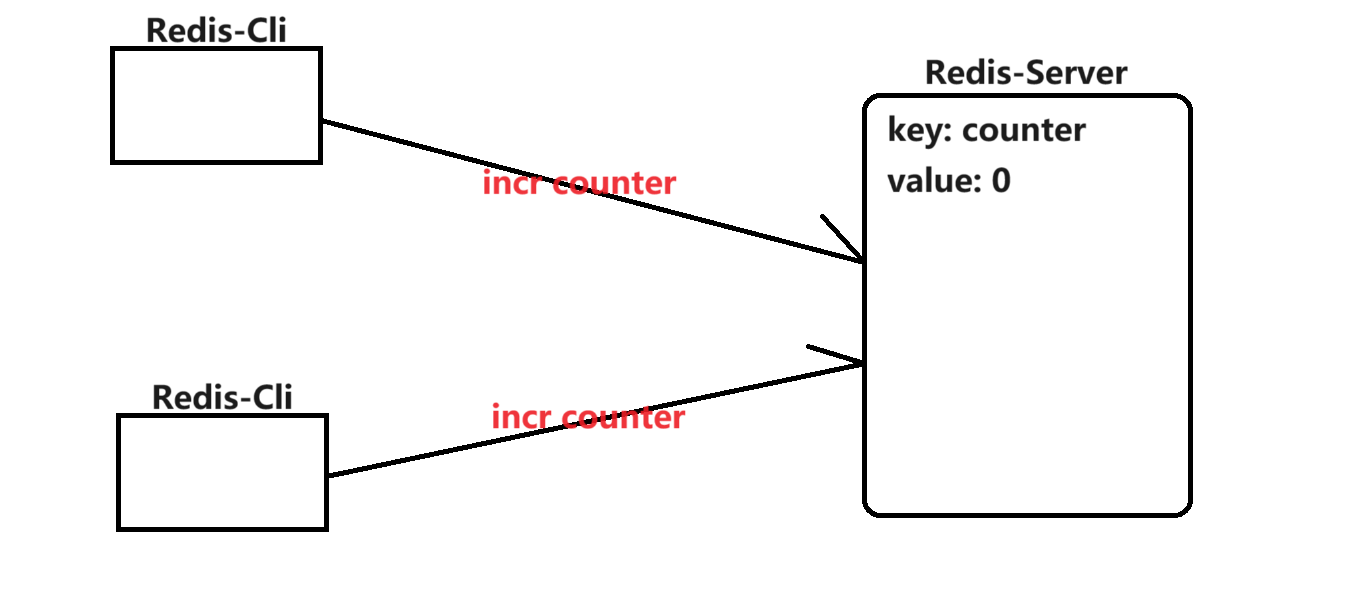
当前这两个客户端 “并发” 的发起了上述的请求,是否会有线程安全问题呢?
答案:并不会。Redis 服务器实际上是单线程模型,保证了当前收到的这个请求是串行执行的
多个请求同时到达Redis服务器也是要在队列中排队,在等待Redis服务器一个一个的取出里面的命令再执行【微观上讲Redis服务器是串行执行多个命令的】
单线程为什么快
这里的快参照物是数据库(MySQL,Oracle,SQLServer等)
- Redis 访问内存,数据库访问的是硬盘
- Redis 核心功能比数据库核心功能更简单
- 数据库对数据的CRUD都有更复杂的功能支持,势必会花费更多的开销【主外键约束、唯一性索引等】
- 采取单线程模型,避免了一些不必要的线程竞争
- Redis 每个基本操作都是 短平快 简单的操作一下内存,不是什么特别消耗 CPU 的操作,就算做多线程提升也不大
- 处理网络IO的时候用的 epoll 这样的 IO 多路复用机制
- 一个线程就可以管理多个 socket ,针对 TCP 来说,服务器每次服务一个客户端需要给客户端安排一个 socket,这些 socket 上并非都无时不刻的传输数据【很多情况下客户端和服务器之间的通信也没那么频繁,直播游戏除外】
- 同一时刻只有少数 socket 是活跃的
- 一个线程就可以管理多个 socket ,针对 TCP 来说,服务器每次服务一个客户端需要给客户端安排一个 socket,这些 socket 上并非都无时不刻的传输数据【很多情况下客户端和服务器之间的通信也没那么频繁,直播游戏除外】
5种常用数据类型
整体上来说Redis是键值对结构,key 固定就是字符串,value实际上会有多种类型
- 字符串
- 哈希表
- 列表
- 集合
- 有序集合
-
Redis 中的字符串按照二进制数据的方式存储(不会做任何编码转换)
-
文本字符串,xml,json,帧数,二进制数据(图片/音频/视频)
二进制数据提及可能会比较大,最大限制为512MB
-
-
一般来讲,Redis乱码概率很小
string类型
String字符串是Redis最简单的存储类型。
根据字符串格式不同,可以分为3类
- String:普通字符串
- int:整形,可自增、自减操作
- float:整形,可自增、自减操作
不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。字符串类型的最大空间不能超过512MB
| KEY | VALUE |
|---|---|
| name | 张三 |
| num | 1 |
| price | 1.1 |
| 语法 | 含义 |
|---|---|
| SET | 添加/修改 已经存在的一个String 类型的键值对 |
| GET | 根据 KEY 获取 VALUE |
| MSET | 批量添加多个 String 类型键值对 |
| MGET | 根据多个 KEY 获取多个 String 类型的 VALUE |
| INCR | 让一个整形的 KEY 自增/自减 |
| INCRBY | 让一个整形的 KEY 自增指定大小【INCRBY num -2:num -= 2】 |
| INCRBYFLOAT | 让一个浮点型数据自增 |
| SETNX | 添加一个 String 类型键值对,前提是这个 KEY 不存在,否则不执行 |
| SETEX | 添加一个 String 类型键值对,并且指定有效期 |
KEY 结构
Redis没有MySQL中Table表的概念。如何区分不同类型的 KEY 呢?
比如存储一个ID都为1的用户数据和文章数据,那么 SET ID 1 就会冲突。解决方案是:多个单词之间用 : 分隔开,格式如下:
项目名:业务名:类型:id
user相关的key:BlogSystem:user:1
文章相关的key:BlogSystem:article:1
如果VALUE是一个对象,则可以将对象序列化为JSON字符串后存储
| KEY | VALUE |
|---|---|
| BlogSystem:user:1 | {“id”:1, “name”: “张三”, “age”:13} |
| BlogSystem:article:1 | “id”:1, “title”: “Redis快速入门”, “updateTime”: “2022-12-23” |

-
set 和 get
-
set
-
语法
-
SET key VALUE [expiration PX seconds|PX milliseconds] [NX|XX]FLUSHALL keys *set key1 1 set key2 2 ex 5 ttl key2set key2 2 NX set key1 1 NX get key1 set key1 111 XX set key3 333 XX exists key3FLUSHALL:相当于数据库的 DROP DATABASE
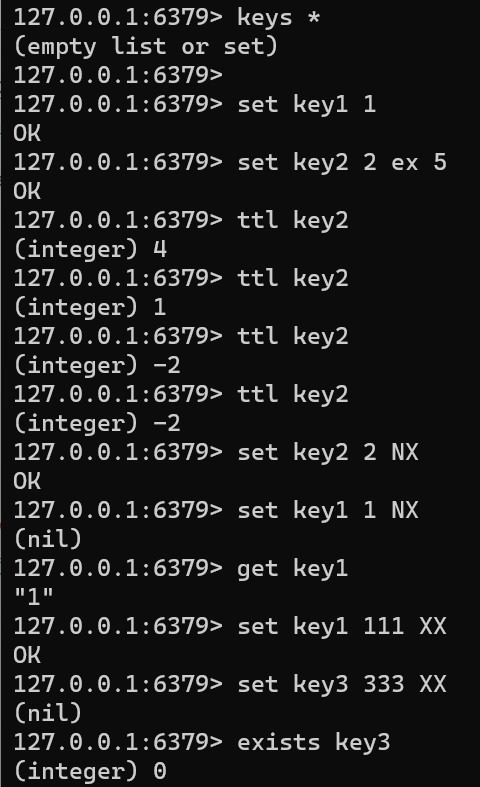
-
时间复杂度:O(1)
-
这里的 key value 不需要加上引号就表示字符串类型【如果要加上也是可以的(单双引号都可以)】
如果key不存在则新建键值对
如果key存在则覆盖旧的value,可能会更改原来的数据类型、原来的TTL也会失效
-
NX:如果 key 不存在,则设置(存在则返回NIL)
XX:如果 key 存在,则设置(不存在则返回NIL)
-
-
将两步操作并为一步
-
set key1 value1 expire value1 10set key1 value1 ex 5
-
-
-
-
get
-
语法
-
RPUSH key4 11 22 33 get key4 type list
-
-
时间复杂度:O(1)
-
注意
-
get 只支持字符串类型的 value,如果 value 是其它类型,使用 get 就会出错
如果当前 key 不存在则会返回 nil
-
-
-
-
mset 和 mget
-
-
MSET
MSET key value [key value ...]mset key1 111 key2 222 key3 333 -
MGET
MGET key [key ...]mget key1 key2 key3 -
时间复杂度:O(N)
- N:命令中 key 的个数,可以认为是 O(1)
-
-
setnx、setex、psetex
-
语法
-
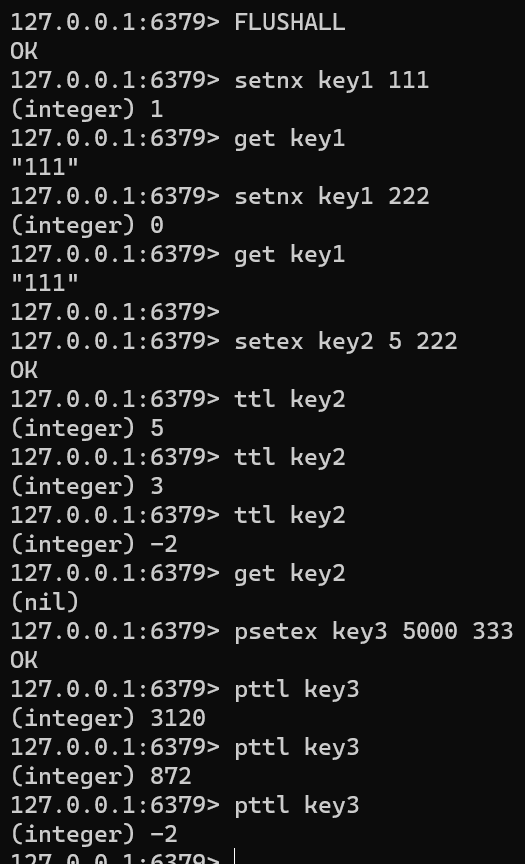
SETNX SETEX PSETXFLUSHALL setnx key1 111 get key1 setnx key1 222 get key1setex key2 5 222 ttl key2 get key2psetex key3 5000 333 pttl key3没有 setxx 指令
-
-
-
incr,incrby和incrbyfloat
-
incr
-
作用:针对value+1
-
语法
-
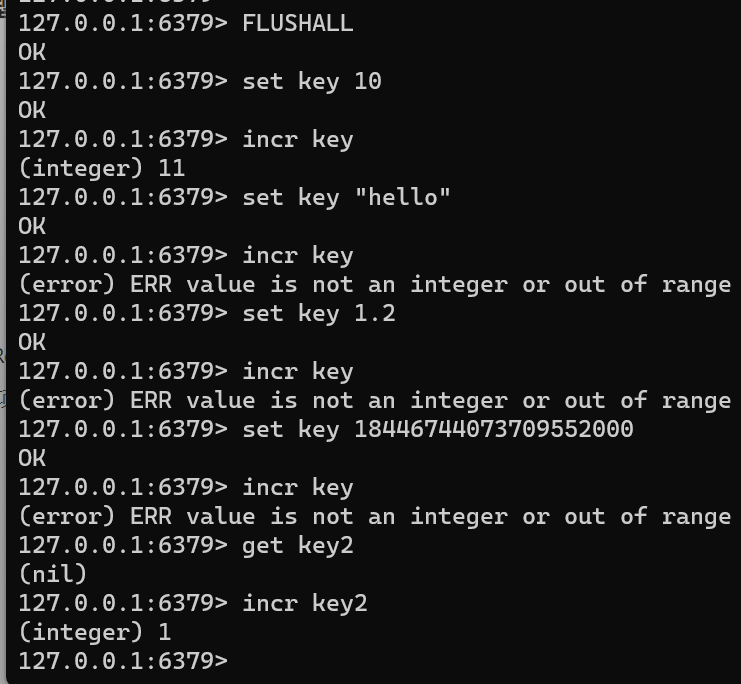
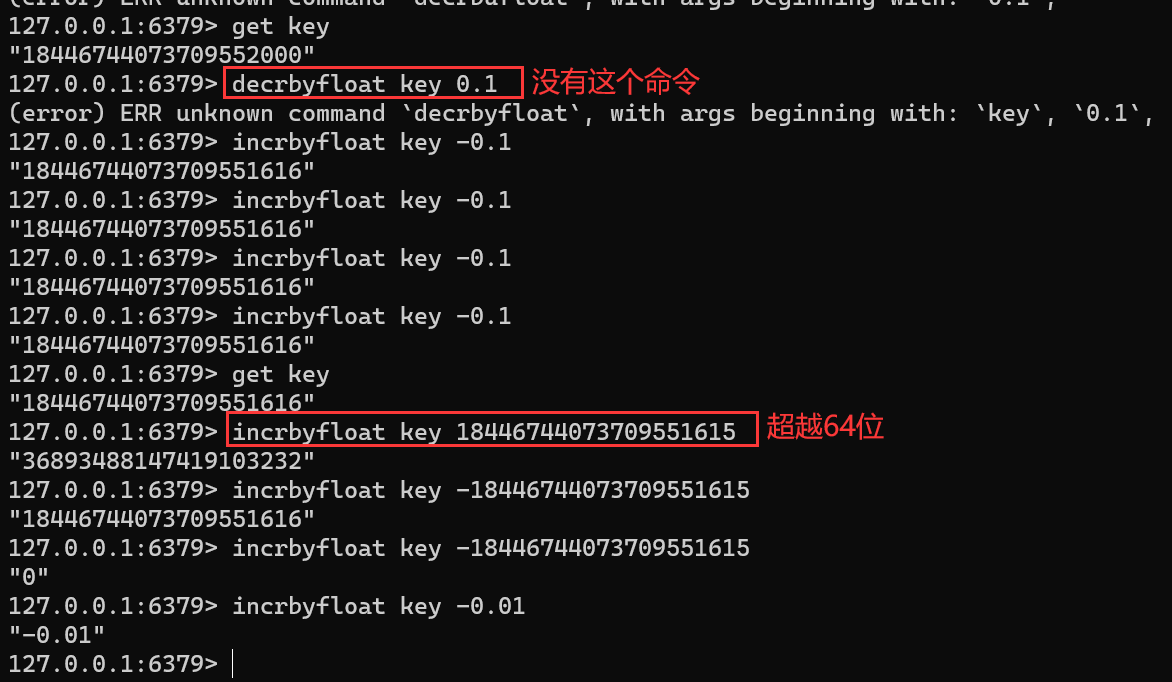
INCR keyFLUSHALL set key 10 incr key set key "hello" incr key set key 1.2 incr key set key 18446744073709552000 incr key get key2 incr key22 64 = 18446744073709552000 2^{64}=18446744073709552000 264=18446744073709552000,Redis中的 insteger 不能超过此范围
-
-
时间复杂度:O(1)
-
返回值:+1 之后的值【++i】
-
注意
此时 key 对应的 value 必需为整数
-
-
incrby
-
作用:针对value+n
-
语法
-
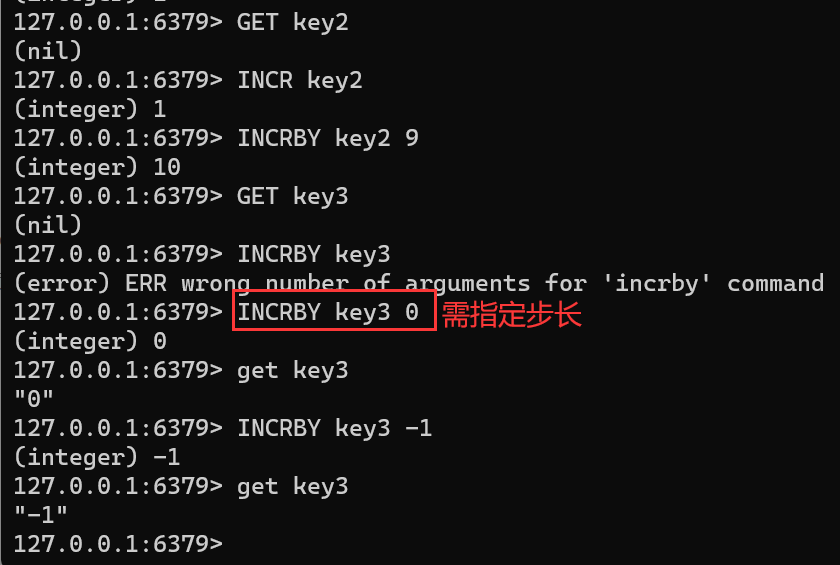
incrby key nget key2 incr key2 incrby key2 9 get key3 incrby key3 incrby key3 0 incrby key3 -1 get key3
-
-
返回值:+n之后的值【+=n】
-
-
incrbufloat
-
作用:针对value +/- 小数
-
语法
-
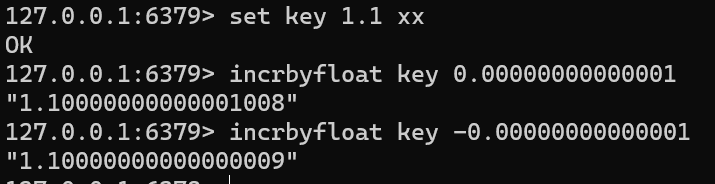
set key 1.1 xx incrbyfloat key 0.00000000000001 incrbyfloat key -0.00000000000001
-
-
返回值:+小数之后的值
-
注意
-
小数位数过多精度会有缺失
incrbyfloat会改变数据位数
-
-
-
-
decr 和 decrby
- decr:针对value-1
- decrby:针对value-n
-
其它字符串操作
-
append
-
作用
- key存在且是一个string,会在原有字符串末尾追加新string
- key不存在 :效果等同于 SET
-
语法
-
APPEND key valueFLUSHALL append key hello get key append key2 你好windows下客户端连接redis是可以加上
--raw参数,这样取得时候就会按照原来的编码读取出数据如果是UTF-8编码,一个汉字3字节则“你好”会返回6
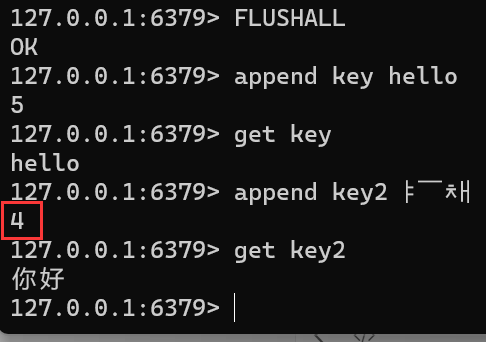
-
-
时间复杂度:O(1)
-
返回值:追加完成之后string的长度【返回的是字节数】
-
-
getrange
-
作用:获取子串
-
语法
-
GETRANGE start endget key getrange key 0 -1 getrange key 0 -2Java:substring(),Java中字符串基本单位是字符,采取 Unicode编码 一个汉字2字节;String字符串,采取UTF-8编码 一个汉字3字节
C++:substr()。C++中字符串基本单位是字节
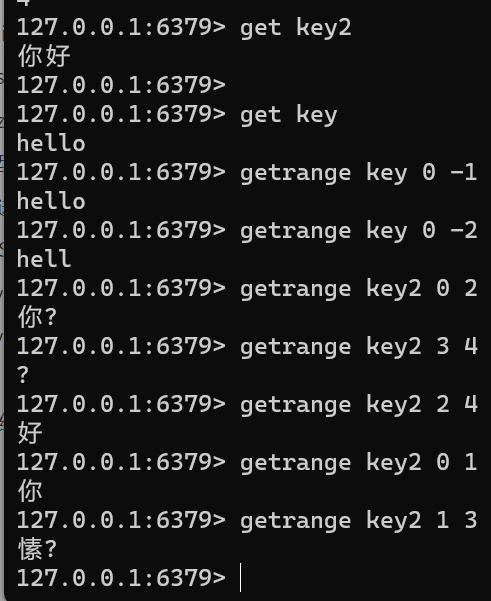
-
-
时间复杂度:O(N)
N:代表的是value长度,但实际情况依旧是可以当为1【几百个字节对计算机也是小问题 】
-
返回值:string类型的字串
-
注意
- 左闭右闭区间
- 超过范围的偏移量会根据string长度调整成正确的值
- -1:倒数第一个,-2:倒数二个
- 如果是汉字,则容易出错
-
-
setrange
-
作用:替换字符串
从第几个字介开始,往后覆盖掉value个字符
-
语法
-
SETRANGE key offset valueFLUSHALL set key helloworld nx setrange key 1 aaa get key setrange key 1 bbbb get key setrange key 1 zzzzzzzzzzz get key setrange key2 1 aaa get key2-
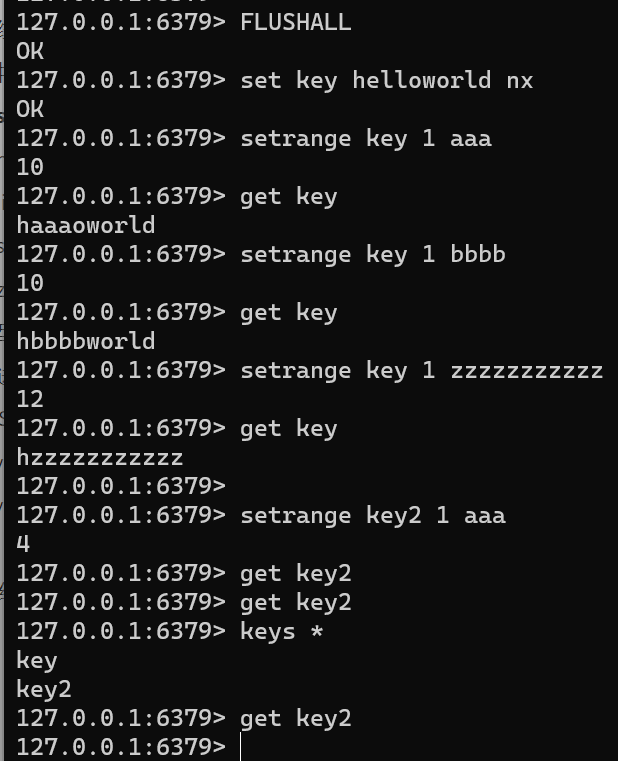
-
针对不存在 key时,windows下没有效果也不报错。而Linux中则正常,偏移1个量后续追加3个a。之前的内容会由 \x00 填充【\x00aaa】
-
-
-
时间复杂度:O(N)
N:代表的是value长度,但实际情况依旧是可以当为1【几百个字节对计算机也是小问题 】
-
返回值:替换之后新字符串长度
-
注意
- 同样中文无法解决
-
-
strlen
-
作用:获取字符串长度【单位是字节】
-
语法
-
STRLEN keyFLUSHALL set key helloworld strlen key strlen key1
-
-
时间复杂度:O(1)
-
返回值:string的长度,如果key不存在则返回0
-
注意
- 如果key存放的类型不是string时就报错
-
-
-
string类型编码方式
字符串类型的内部编码有3中:
- int:8个字节的长整型
- embstr:小于等于39个字节的字符串
- raw:大于39个字节的字符串
Redis会自动调整对应字符串的编码方式
FLUSHALL set key 123 object encoding keyset key2 qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq object encoding key2set key3 qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq object encoding key3set key4 1.1 object encoding key4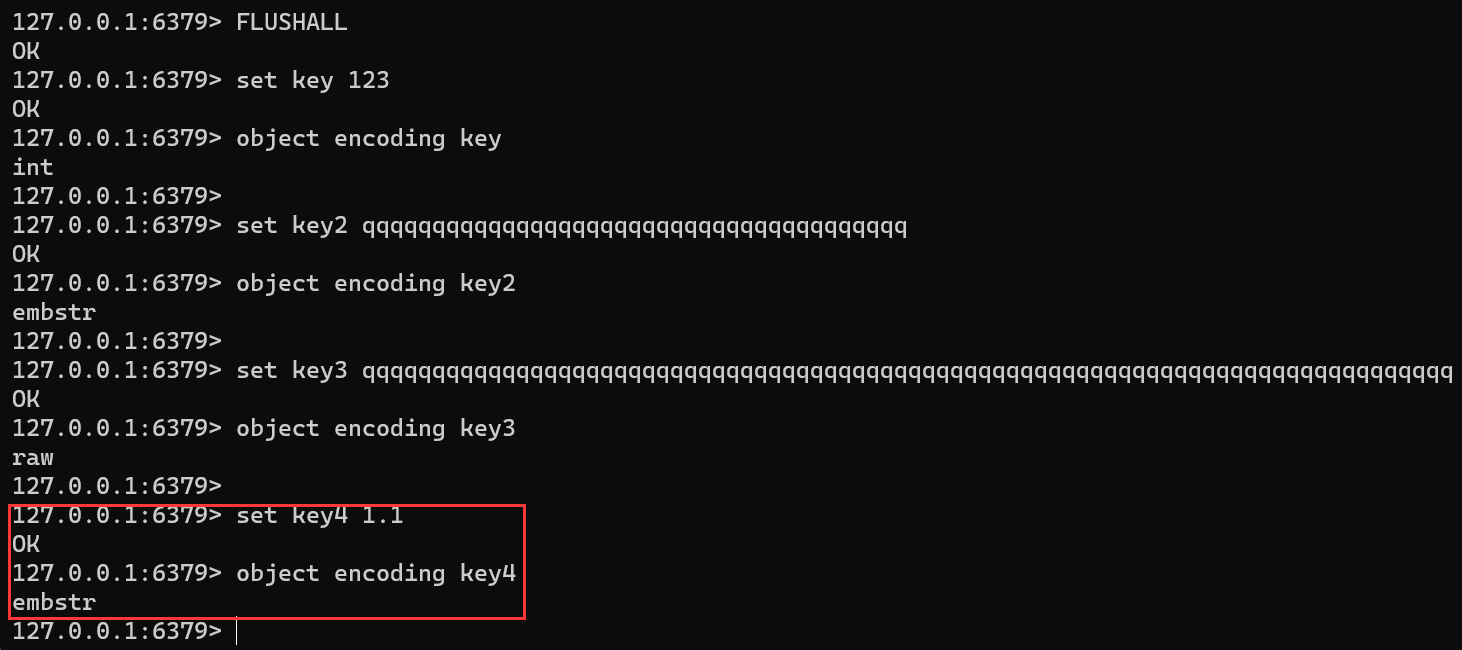
说明Redis存储小数本质上是存储字符串意味着:每次进行算术运算都需要把字符串转成小数进行运算再转会字符串保存
-
string类型应用场景
-
缓存
Redis+MySQL组成的缓存架构
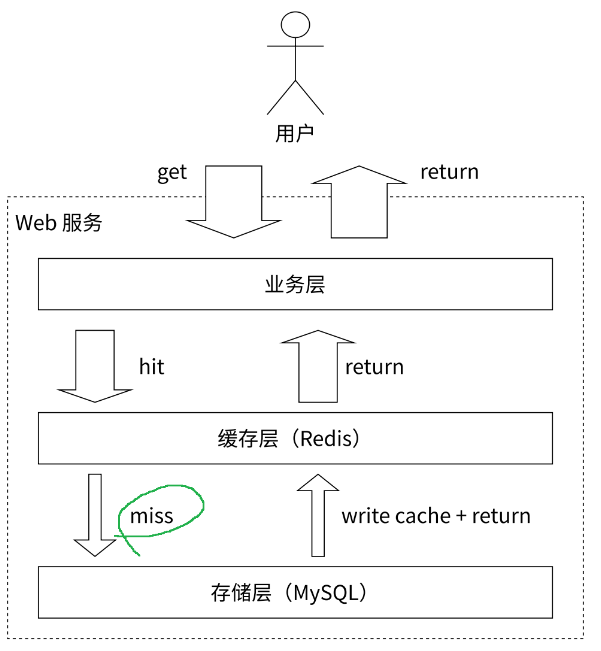
Redis缓存经常会存储 热点数据
经常使用的数据
最近被使用的数据
上述业务中随着时间退役,Redis会有越来越多的数据。因此就Redis诞生了内存淘汰策略,我们一般在写入数据的时候会加给key设置一个过期时间来防止数据积累
public UserInfo getUserInfo(long uid) {// 根据 uid 得到 Redis 的 keyString key = "user:info:" + uid;// 尝试从 Redis 中获取值String vlaue = Redis执行命令.get(key);// 如果缓存命中(hit)if (value != null) {// 把用户数据反序列化UserInfo userInfo = JSON反序列化(value);return userInfo;}// 如果缓存未命中(miss)if (value == null) {// 从数据库中,根据 uid 获取⽤⼾信息UserInfo userInfo = MySQL 执⾏SQL:select * from user_info where uid = <uid >;// 如果表中没有 uid 对应的⽤⼾信息if (userInfo == null) {响应 404return null;}// 将⽤⼾信息序列化成 JSON 格式String value = JSON 序列化(userInfo);// 写⼊缓存,为了防⽌数据腐烂(rot),设置过期时间为 1 ⼩时(3600 秒)Redis 执⾏命令:set key value ex 3600// 返回⽤⼾信息return userInfo;} }Redis设计合理的key有助于区分数据对象,比如:
MySLQ库名:cux_om,供应商表:cux_om_vendors,对应的 Redis key:cov:6379:vendor_info: telephone:123456789
但是这样的key虽然完整,但是键名过长也会降低性能:cov:6379:vi:tel:123456789
-
计数(Counter)功能
记录视频播放次数

为什么使用Redis统计而不用MySQL?
因为用户数量多的时候,MySQL针对相应的视频执行一条 UPDATE 命令,尤其是短视频平台,一个用户不会只刷一个视频,因此MySQL会承受不了这样的压力
什么是异步写入?
写入统计数据库步骤不一定和Redis统计步骤一致,MySQL数据库慢一点但是一直在写来保证跟上Redis进度。当流量低的时候会能写多少数据就尽量写多少
实际开发过程中还要考虑很多:防作弊【此用户单个视频刷了成百上千遍】、按照不同维度统计【用户点进去就滑走】、避免单点登录问题【某台服务器挂掉后用户需要重复登陆】、数据持久化到底层数据源【不能服务器重启就丢失数据】
-
Session会话
Cookie:浏览器存储数据机制
Session:服务器存储数据的机制
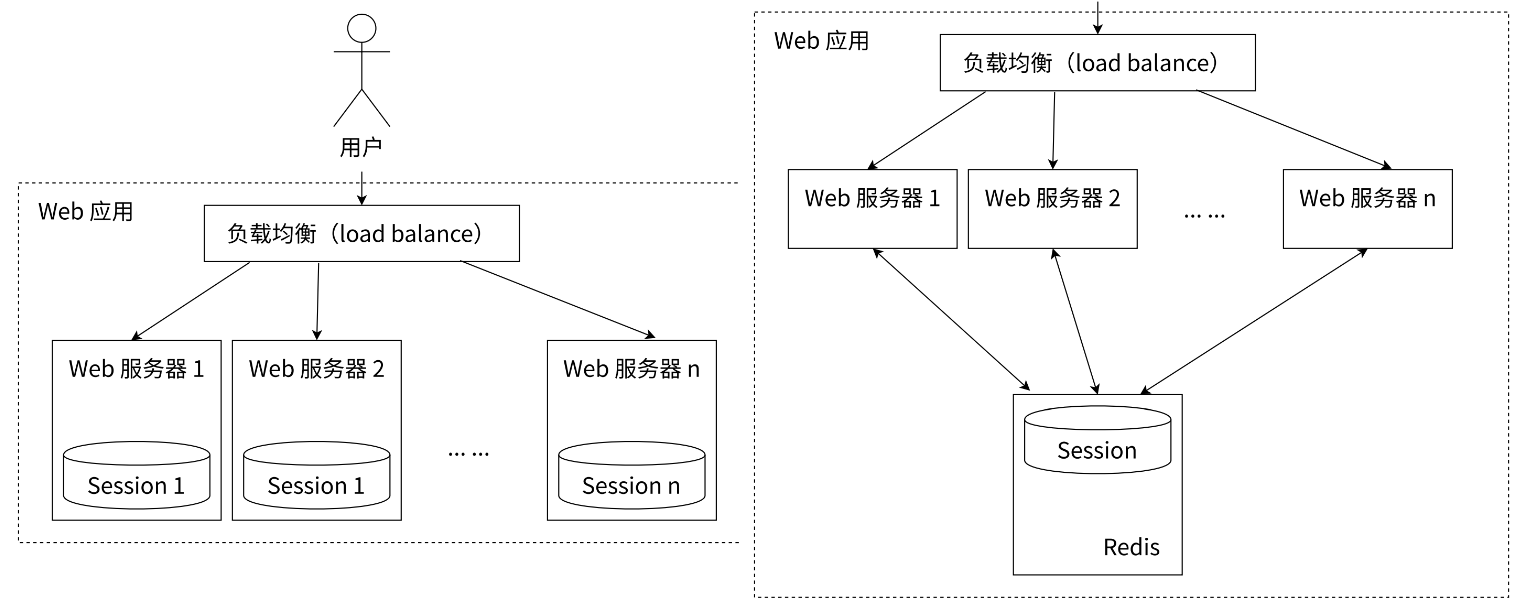
左边:如果每个服务器只存储自己的会话信息不共享,当用户请求到不同服务器上就会可能出现不能处理的情况
右边:此时所有的会话信息都存储到Redis,多个服务器共享此Redis数据
-
手机验证码
很多应用出于安全考虑,安全登陆的时候让用户输入手机号再发送验证码短信,再让用户输入验证码从而验证是本人
为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率比如一分钟5次
public String SendVerificationCode(String phoneNumber) {String key = "shortMsg:limit:" + phoneNumber;boolean flag = Redis执行命令:set key 1 ex 60 nx;if (flag == false) {// 说明之前手机设置过严证码long c = Redis执行命令:get key;if (c > 5) {//说明一分钟发送超过5次,限制发送return null;}}//之前没有发送过验证码,设置随机的6位字符串验证【一般是数字验证码:(int) (((Math.random()) * 9 + 1) * 100000)】String validationCode = randomCharacterGenerator();// 5分钟(300s)有效String validationKey = Redis执行命令:set "validation" + phoneNumber validationCode ex 300;return validationCode; }private String randomCharacterGenerator() {long timeStamp = System.currentTimeMillis();Random random = new Random(timeStamp);StringBuilder stringBuilder = new StringBuilder();for (int i = 0; i < 6; i++) {int randomInt = random.nextInt(26) + 97;char randomChar = (char) randomInt;String randomString = Character.toString(randomChar);stringBuilder.append(randomString);}return stringBuilder.toString(); }public boolean verifyVerificationCOde(String phoneNumber, String verificationCode) {// 1.先从Redis中获取对应的验证String validationKey = "validation" + phoneNumber;String value = Redis执行命令:get validationKey;if (value == null) {// 没有发送过验证码或者验证码过期return false;}if (value.equals(verificationCode)) {return true;} else {return true;} }
-
-
什么是业务
- 公司/产品 如何解决一个/一系列 问题,而解决问题的过程就是业务
- 当技术手段无法优化的时候可以考虑优化业务
- 典型的12306例子:放票分开时间段发放而不是某个时间段发放全国的票

hash类型
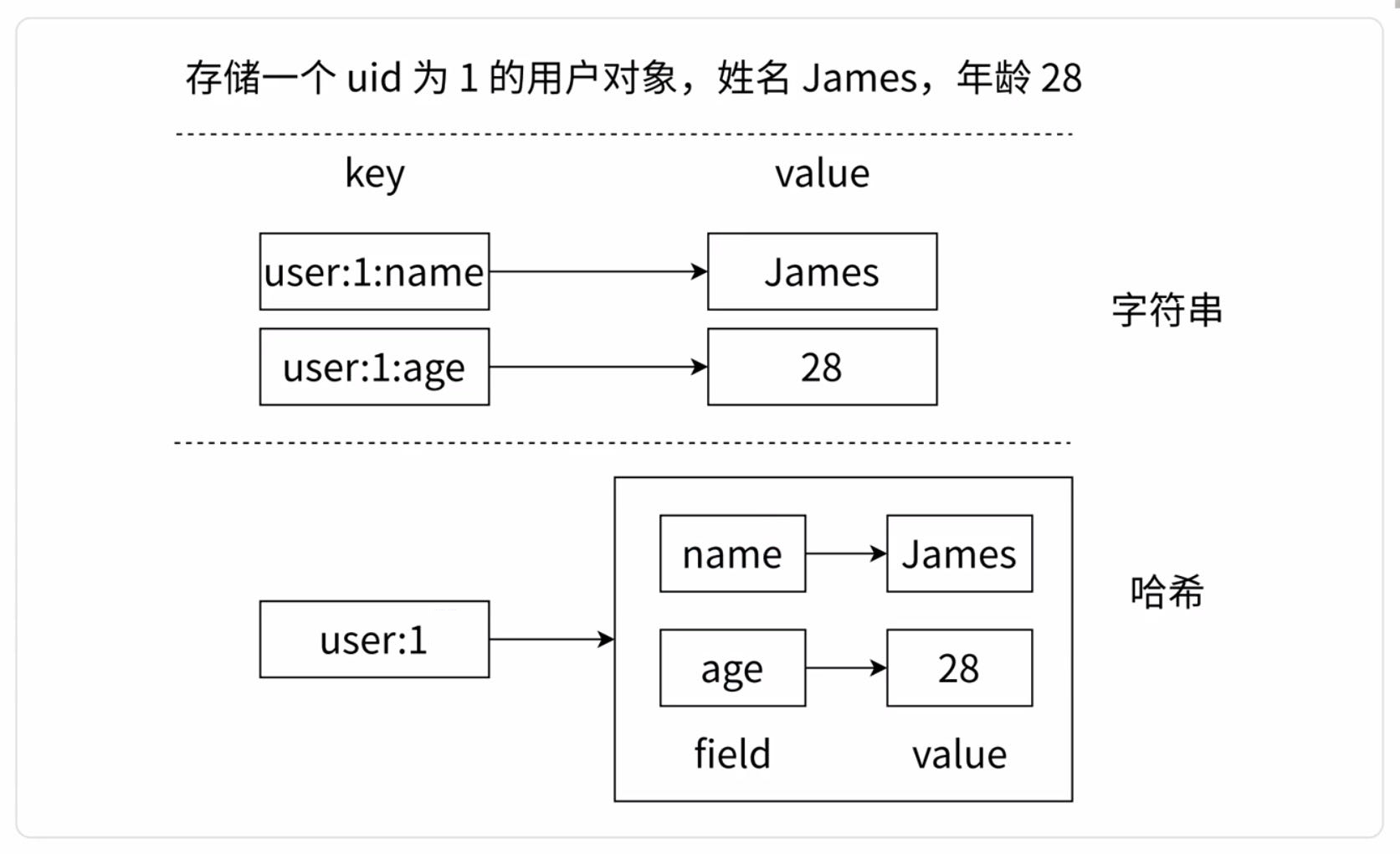
String结构将对象序列化为JSON格式存储后,当需要修改某个字段是很不方便。
Hash结构可以将对象字段单独存储,方便修改
| KEY | FILED | VALUE |
|---|---|---|
| BlogSystem:user:1 | name | “张三” |
| BlogSystem:user:1 | age | 13 |
| BlogSystem:user:2 | name | “李四” |
| BlogSystem:user:2 | age | 14 |
Hash常用语法
| 语法 | 含义 |
|---|---|
| HSET key field value | 添加或者修改hash类型key的field的值 |
| HGET key field | 获取一个hash类型key的value |
| HMSET | 批量添加多个hash类型key的field的值 |
| HMGET | 批量获取多个hash类型key的field的值 |
| HGETALL | 获取一个hash类型的key中的所有的field和value |
| HKEYS | 获取一个hash类型的key中所有的field |
| HINCRBY | 让一个hash类型key的value自增指定步长 |
| HSETNX | 添加一个hash类型的key的field之,前提是这个field不存在否则不执行 |
H系列命令必须要保证 key 对应的 value 是 哈希 类型
-
hset、hget、hexists和hdel
-
hset
-
作用:设置 hash 中指定的字段(field)和值(value)
-
语法
-
HSET key field value [field value ...]
-
-
时间复杂度:O(1)
-
返回值:添加的字段个数
-
注意:HSET 已经支持同时设置多个【Redis也提供了HMSET】
-
-
hget
-
作用
-
语法
-
HGET key fieldFLUSHALL hset key f1 111 hset key f2 222 f3 333 f4 444 hget key f1 hget key1 f1 hget key f5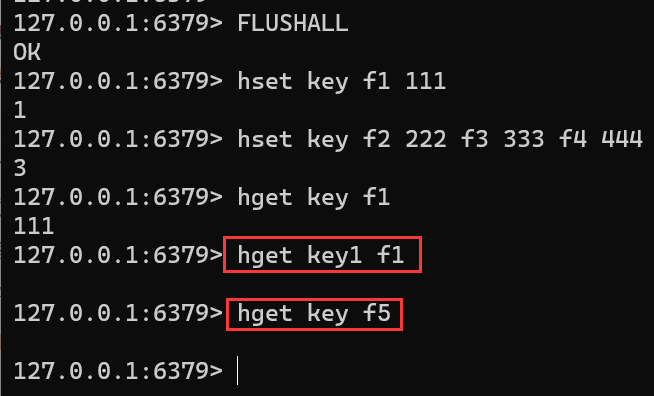
-
-
时间复杂度:O(1)
-
注意
无论是 key 不存在还是 field 不存在,都会返回 nil
-
-
hexists
-
作用:判断 hash 中是否有指定的字段
-
语法
-
HEXISTS key fieldhexists key f1 hexists key1 f1 hexists key f5
-
-
时间复杂度:O(1)
-
返回值:0:不存在、1:存在
-
-
hdel
-
作用:删除 hash 中指定的字段
-
语法
-
HDEL key field [field ...]hdel key f1 hexists key f1 hdel key f2 f3 hget key f2 hget key f3 hget key f4 hget key2 f1
-
-
时间复杂度:O(N),N:删除的字段个数
-
返回值:成功删除字段个数
-
注意
- DEL 删除的是 KEY
- HDEL 删除的是 FIELD
-
-
-
hkeys和hvals
-
hkeys
-
作用:获取 hash 中全部字段
-
语法
-
HKEYS keyFLUSHALL hset key f1 111 f2 222 f3 333 f4 444 hkeys key
-
-
时间复杂度:O(N),N字段个数
-
返回值:字段列表
-
注意:不要触发 KEYS * 这种类似效果
-
-
hvals
-
作用:获取 hash 中所有的值
-
语法
-
HVALS keyhvals key
-
-
时间复杂度:O(N),N:元素个数
-
返回值:所有的值
-
-
-
hgetall和hmget
-
hgetall
-
作用:获取 hash 中所有字段及对应的值
-
语法
-
HGETALL keyhgetall key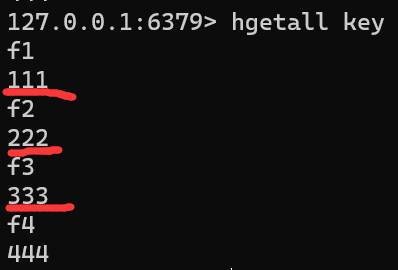
-
-
时间复杂度:O(N),N:元素个数
-
返回值:字段和对应的值
-
-
hmget
-
作用:一次获取 hash 中多个字段的值
-
语法
-
HMGET key field [field ...]hmget key f1 f2 f3 f5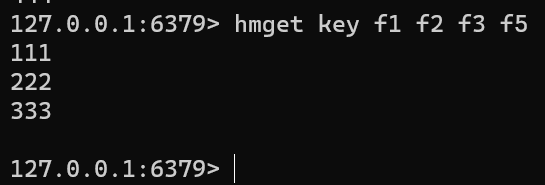
-
-
时间复杂度:O(N),N:元素个数
-
返回值:字段对应的值或者 nil
-
上述 hkeys,hvals,hgetall 都是一次性获取全部。因此需要用渐进式遍历 hscan,运行一次遍历一小部分再运行再遍历一小部分,连续多次就可完成整个遍历过程
-
-
hlen、hsetnx、hincr、hincrby和hincrbyfloat
-
hlen
-
作用:获取 hash 中的所有字段的个数
-
语法
-
HLEN keyhgetall key hlen key
-
-
时间复杂度:O(1)
-
返回值:返回字段个数
-
-
hsetnx
-
作用:在字段不存在的情况下,设置 hash 中的字段和值
-
语法
-
HSETNX key field valuehsetnx key f5 555 hsetnx key f5 666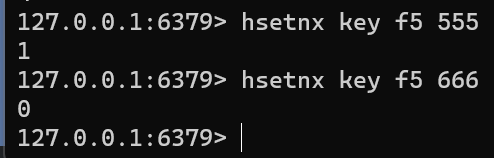
-
-
时间复杂度:O(1)
-
返回值:0 表示失败;1表示设置成功
-
-
hincrby
-
作用:将 hash 中字段对应的数值添加指定的整数值
-
语法
-
HINCRBY key field incrementhincrby key f1 0.01 hincrby key f1 10 hget key f1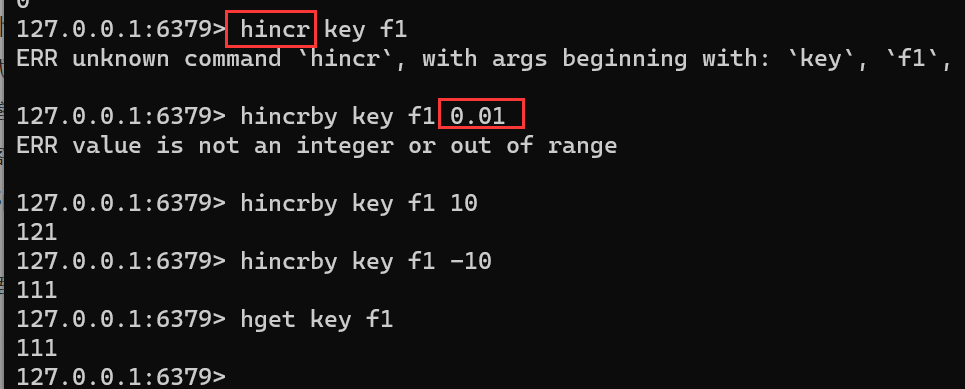
-
-
时间复杂度:O(1)
-
返回值:该字段变化之后的值
-
-
hincrbyfloat
-
作用
-
语法
-
HINCRBYFLOAT key field incrementhincrbyfloat key f1 0.01 hincrbyfloat key f1 -0.01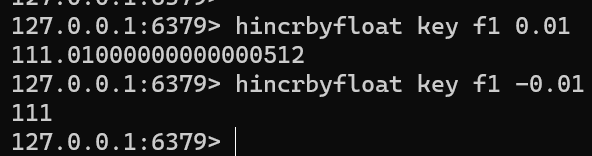
-
-
时间复杂度:O(1)
-
返回值:该字段变化之后的值
-
-
-
hash内部编码
哈希表编码方式主要有两种,ziplist和hashtable
- ziplist
- 当哈希元素个数小于 hash-max-ziplist-entries 配置(默认512)同时所有值都小于 hash-max-ziplist-value 配置(默认64字节),Redis会使用内部ziplist作为哈希的内部实现更加紧凑的数据结构,所以会节省很多空间
- hashtable
- 当哈希类型无法满足 ziplist 条件时,Redis会使用内部hashtable作为哈希内部实现,因为此时ziplist读写效率会下降而hashtable的读写时间复杂度为O(1)

- ziplist
-
哈希应用
-
作为缓存
-
关系型数据表保存用户信息
-
映射关系表示用户信息
-

-
相较于JSON格式字符串存储用户数据,哈希类型显得更直观,并且操作起来更灵活。在每个用户后面的ID作为后缀,多对field-value对应用户属性
-
public UserInfo getUserInfo(long uid) {// 1.根据 uid 得到 Redis的keyString key = "user:" + uid;// 2.根据 key 查询 valueUserInfoMap userInfoMap = Redis执行命令: hgetall key;// 3.如果缓存命中if (value != null){UserInfo userInfo = 利用映射关系构建对象(userInfoMap);return userInfo;}// 4.缓存未命中,则从MySQL中取数据UserInfo userInfo = MySQL执⾏SQL: select * from user_info where uid = <uid>;if (userInfo == null){响应 404;return null;}// 5.将缓存以哈希类型进行保存Redis执行命令: hset key name userInfo.name age userInfo.age city userInfo.city;// 6.设置过期时间位1小时Redis执行命令: expire key 3600;return userInfo; }JSON格式如果要想获取某个 field或者修改某个 field,就需要把整个 json 读出来,解析成对象,操作 field 之后才重写转成 json 字符串再写回去
-
-
-
数据库稀疏性对比
-
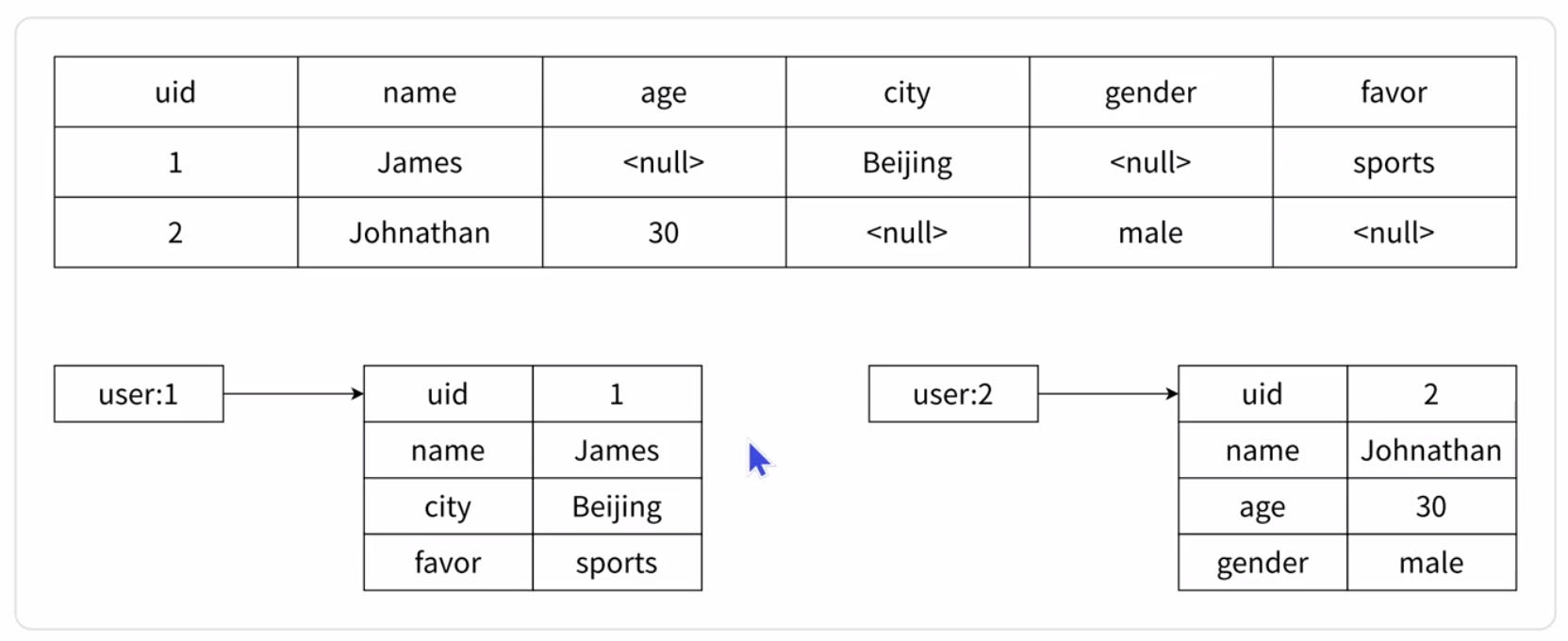
- 哈希类型是稀疏的,二关系型数据库是完全结构化的。例如哈希类型每个键可以有不同的 field,而关系型数据库 一旦添加新的列,所有行都要为其设置新值【包含null】
- 关系型数据库可以做复杂的查询,而Redis无法去模拟实现多表联查,聚合查询等复杂拆线呢,维护成本太高
- 对于 uid 再存储一份也可以省下来,但是如果存储的话后续开发代码的话会更方便
-
-
-
-
缓存方式对比
-
原生字符串类型:每个属性一个键
set user:1:name James set user:1:age 23 set user:1:city Beijing- 优点:实现简单,针对个别属性变更也很灵活
- 缺点:占用过多的键导致内存占用过大,用户信息在Redis中比较分散,缺少内聚性因此没什么实用性
-
序列化字符串JSON格式
set user:1 经过序列化后的用户对象字符串- 优点:针对总是以整体位操作的数据比较合适,编程简单。同时如果序列化方案合适,内存使用效率也很高
- 缺点:本身序列化和反序列化有一定开销,同时如果操作个别属性会不方便
-
哈希类型
hmset user:1 name James age 23 city Beijing- 优点:简单、直观、灵活。尤其是针对局部信息变更或者获取操作
- 缺点:需要控制 ziplist 和 hashtable 两种编码方式转换,否则可能会造成较大消耗
-
-
list类型
列表(List)相当于数组或者顺序表【并非是一个简单数组二十一个更接近于双端队列deque】,两端可以插入(push)或者弹出(pop),还可以获取指定范围的元素列表
从两端插入/删除元素都是非常高效O(1)
rpush 和 rpop:栈
rpush 和 lpop:队列
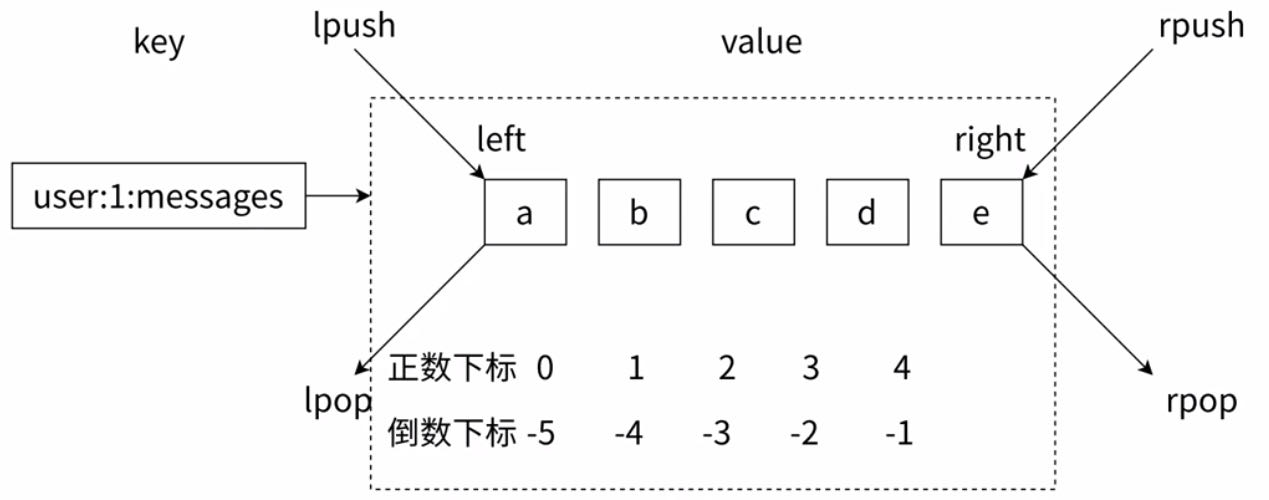
列表中的元素是有序的【输出顺序按照存放顺序】
元素允许重复
因为当前的 List 头和尾都能高校插入删除元素、就可以把这个 List 当作一个 栈/队列 来使用
Redis中的List类型与Java中的LinkedList类似,可以看作是一个双向链表结构。既可以支持正向检索也支持反向检索。
特征与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询一般
用来存储一个有序数据。例如:朋友圈点赞列表,评论列表
常用语法
| 语法 | 含义 |
|---|---|
| LPUSH key element | 在列表左侧插入一个或多个元素 |
| RPUSH key element | 向列表右侧插入一个或多个元素 |
| LPOP key | 移除并返回列表左侧的第一个元素,没有则返回nil |
| RPOP key | 移除并返回列表右侧的第一个元素,没有则返回nil |
| BLPOP和BRPOP | 与LPOP和RPOP类似,只不过在没有元素时等待指定时间而不是直接返回nil |
| LRANGE key star end | 返回一段表范围内的所有元素【0下标开始计算】 |
-
lpush和lrange
-
lpush
-
作用:一个或多个元素从左侧插入【头插】
-
语法
-
LPUSH key element [element ...]
-
-
时间复杂度:插入一个元素:O(1);插入N个元素O(N)
-
返回值:插入之后 list 长度
-
注意:如果 key 已经存在,并且 key 对应的 value 类型不是 list则 lpush 会报错
-
-
lrange
-
作用:获取从 start 到 stop 区间的所有元素,左闭右闭
-
语法
-
LRANGE key start stopFLUSHALL lpush key 1 2 3 4 lpush key 5 6 7 8 lrange key 0 -1 lrange key 0 100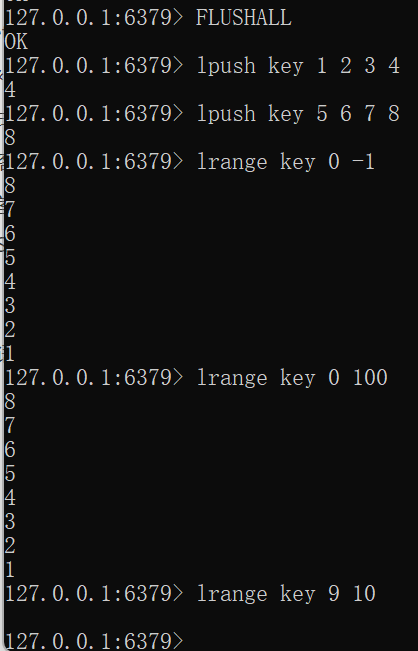
-
-
时间复杂度:O(N)
-
返回值:指定区间的元素
-
注意
用法和string的getrange一样:别的编程语言当范围超出之后会报错:C++未定义、Java抛异常。而Redis则是尽可能地给出范围内的值
虽然是lrange,但这里的l是list的意思并非lfet的意思。所以没有rrange命令
-
-
-
lpushx,rpush,rpushx
-
lpushx
-
作用:在 key 存在时,将⼀个或者多个元素从左侧放入(头插)到 list 中。不存在,直接返回
-
语法
-
1 LPUSHX key element [element ...]FLUSHALL lpush key 1 2 3 4 lpushx key 5 6 7 8 lrange key 0 -1 keys * lpushx key2 1 2 3 4 lrange key2 0 -1 exists key2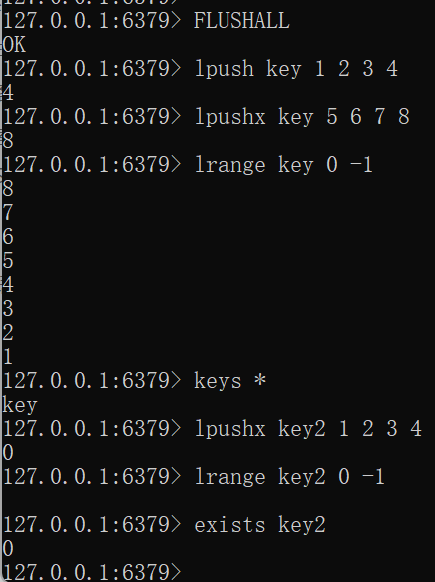
-
-
时间复杂度:插入一个元素:O(1);插入N个元素:O(N)
-
返回值:返回值是 list 长度
-
注意
- 针对不存在的 key 进行插入则会失败,相较于 lpush 多了一层 exists 判断key是否存在
- x:是exists的意思
-
-
rpush
-
作用:将⼀个或者多个元素从右侧放入(尾插)到 list 中
-
语法
-
RPUSH key element [element ...]
-
-
时间复杂度:插入一个元素为O(1);插入N个元素为O(N)
-
返回值:插入后 list 的长度
-
-
rpushx
-
作用:在 key 存在时,将⼀个或者多个元素从右侧放入(尾插)到 list 中。
-
语法
-
RPUSHX key element [element ...]
-
-
时间复杂度:插⼊一个元素为O(1);插⼊N个元素为O(N)
-
返回值:插入后 list 的长度
-
-
-
lpop和rpop
-
lpop
-
作用:从 list 左侧取出元素【头删】
-
语法
-
LPOP key [count]FLUSHALL rpush key 1 2 lpop key lpop key lrange key 0 -1 lpop key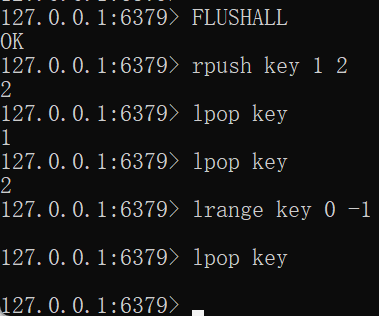
-
-
时间复杂度:O(1)
-
返回值:取出的元素或者nil
-
-
rpop
-
作用:从 list 右侧取出元素【尾删】
-
语法
-
RPOP key [count]
-
-
时间复杂度:O(1)
-
返回值:取出的元素或者nil
-
注意
- Linux下,从 redis6.2 版本增加了一个 count 参数,代表这次要删除多少个元素
-
-
-
lindex,linsert,llen
-
lindex
-
作用:获取下标元素值
-
语法
-
LINDEX key indexFLUSHALL rpush key 1 2 3 4 5 6 7 8 9 lindex key 3 lindex key -1 lindex key 10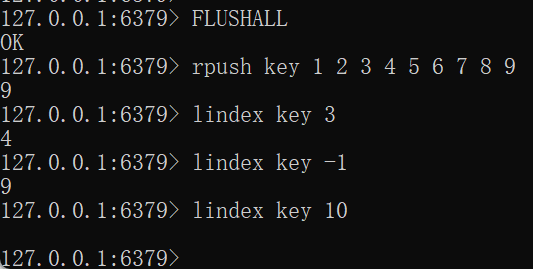
-
-
时间复杂度:O(N)【由于是list所以是N】,N:list中元素个数
-
返回值:获取下标元素的值
-
注意
- 下标 0 开始
- 如果下标非法,返回nil
-
-
linsert
-
作用:
-
语法
-
LINSERT key <BEFORE | AFTER> pivot elementlinsert key before 4 4 linsert key before 4 401 linsert key after 4 402 lrange key 0 -1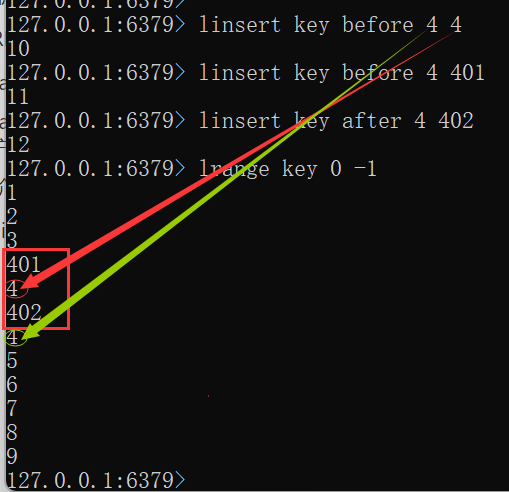
linsert插入的时候从左往右找到第一个符合基准值的位置插入
-
-
时间复杂度:O(N)
-
返回值:插入之后新的list长度
-
注意:只会在遇到的第一个元素进行插入
-
-
llen
-
作用:获取list长度
-
语法
-
LLEN key
-
-
时间复杂度:O(1)
-
返回值:list长度
-
-
-
lrem
-
作用:【remove】
-
语法
-
LREM key count elementFLUSHALL rpush key 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 lrem key 2 1 lrange key 0 -1FLUSHALL rpush key 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 lrem key -2 1 lrange key 0 -1FLUSHALL rpush key 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 lrem key 0 1 lrange 0 -1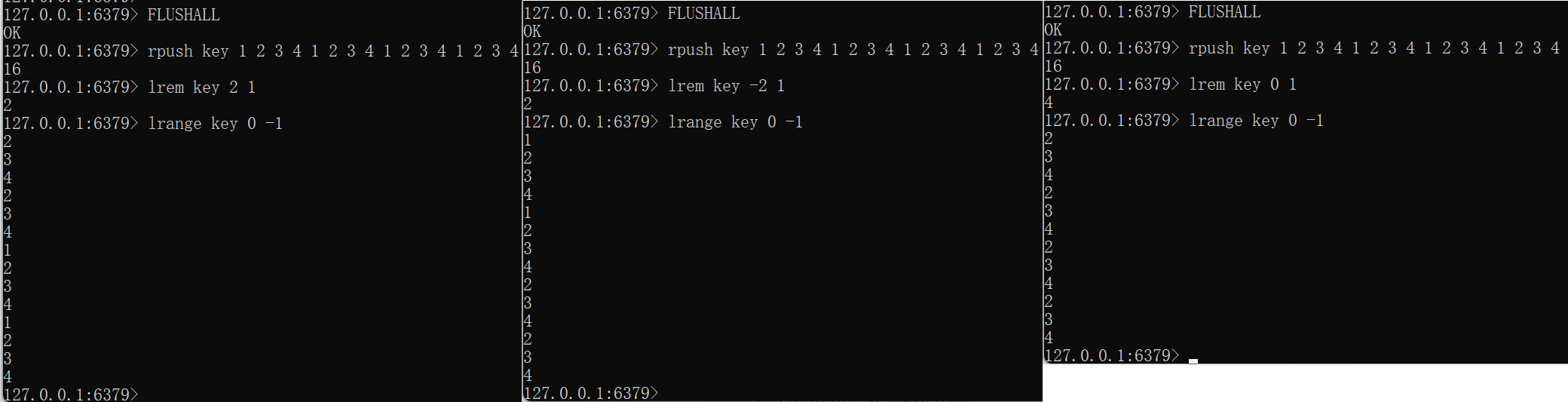
count:要删除的元素个数【正数:从左往右;负数:从右往左】
element:要删除的元素
-
-
时间复杂度:O(N+M)
-
返回值:被删除元素个数
-
-
ltrim,lset
-
ltrim
-
作用:保留 [start, stop] 闭区间内的元素【区间外的元素被删除】
-
语法
-
LTRIM key start stopFLUSHALL rpush key 1 2 3 4 5 6 7 8 ltrim key 2 5 lrange key 0 -1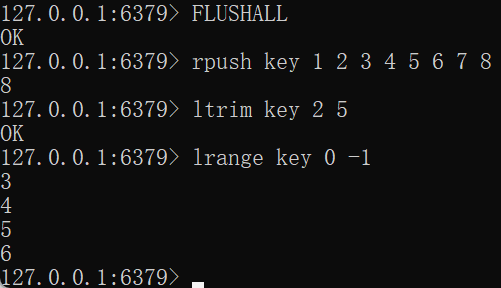
-
-
时间复杂度:O(N),N:删除个数
-
-
lset
-
作用:
-
语法
-
LSET key index elementFLUSHALL rpush key 1 2 3 4 5 lset key 0 100 lset key 5 600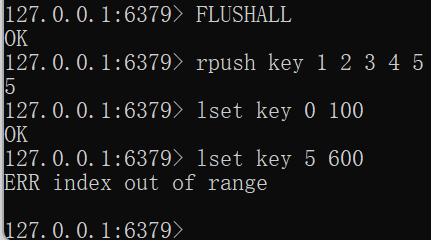
-
-
时间复杂度:O(N),N:list元素个数
-
注意:如果下标越界,则会报错
-
-
-
blpop和brpop
阻塞版本命令:blpop,brpop分别是lpop,rpop的阻塞版本
redis中的list也相当于阻塞队列一样,线程安全是通过单线程模型支持的,阻塞:则只支持“队列为空”的情况而不考虑“队列为满”的情况
如果 list 中存在元素:blpop,brpop和 lpop,rpop 作用完全相同
如果 list 为空:blpop和brpop就会产生阻塞,一直阻塞到队列不为空为止【但一般不提倡无休止的等】
队列空 lpop,rpop nil blpop,brpop 根据timeout阻塞一段时间,阻塞期间redis可以执行其它命令 这里的阻塞看似会产生一些耗时操作,但其实并不会对redis服务器产生负面影响
这两个阻塞命令主要用来满足 “消息队列” 这样需求
blpop和brpop都是可以同时去尝试获取多个 key 的列表的元素。命令中如果设置了多个键,它会从左至右进行遍历键,一旦有一个键对应的列表可以弹出元素,命令就返回哪个元素。
如果多个客户端同时多个键执行 bl/rpop,则最先执行命令的客户端会得到弹出的元素
-
blpop
-
作用:
-
语法
-
BLPOP key [key ...] timeoutFLUSHALL rpush key 1 blpop key 60 blpop key 60rpush key 1FLUSHALL blpop key key2 key3 key4 500rpush key 1 2 rpush key2 1 2 rpush key3 1 2 rpush key4 1 2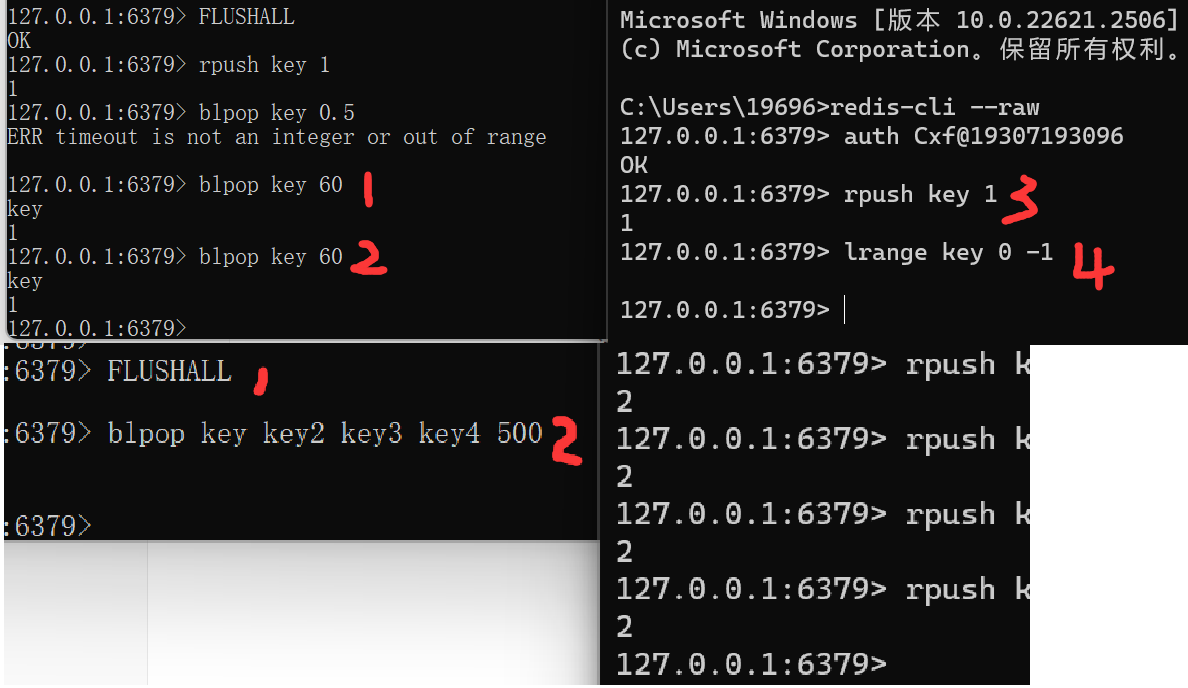
-
-
时间复杂度:O(N),N:list元素个数
-
返回值:相当于一个pair(二元组)【数据来自哪个key、数据是什么】
-
注意:timeout 时间单位是:s【redis5:时间为整数】
-
-
brpop
-
作用:
-
语法
-
BRPOP key [key ...] timeout
-
-
时间复杂度:O(N),N:list元素个数
-
-
-
list内部编码
list列表内部编码方式也有两种
-
ziplist(压缩列表):列表元素个数小于 list-max-ziplist-entries 配置(默认 512 个)。redis会选用ziplit作为列表内部编码方式来减少内存消耗
-

有5个档位选择,3~5不推荐
-
-
linkedlist(链表):list类型无法满足 ziplist 时就会使用 linkedlist 作为列表内部实现
-
quicklist:相当于list和linkedlist的结合。整体还是一个链表,每个节点是一个压缩列表。
-
-
list应用场景
-
用 list 作为 “数组” 这样的结构来存储多个元素
-
消息队列
-
阻塞消息队列模型
-
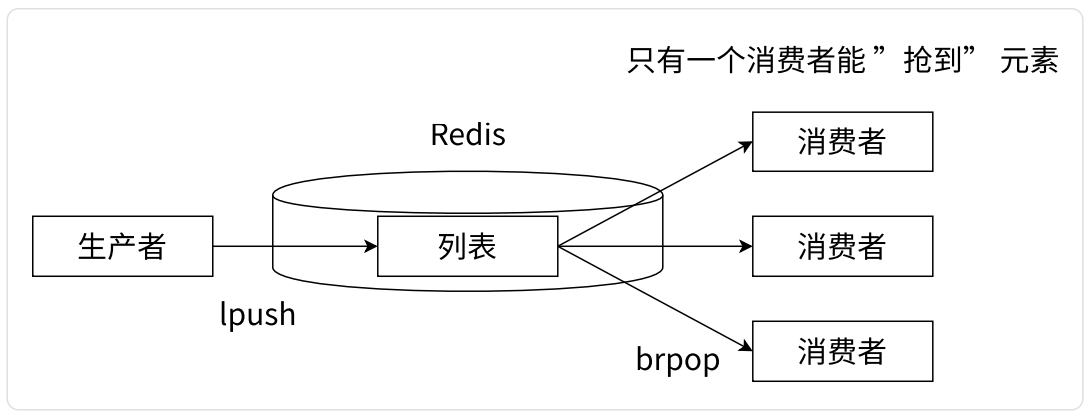
先执行 brpop 的消费者会第一个拿到。像这样的设定,就能构成一个 “轮询” 式的效果
-
-
多个列表/分频道阻塞消息队列模型
-
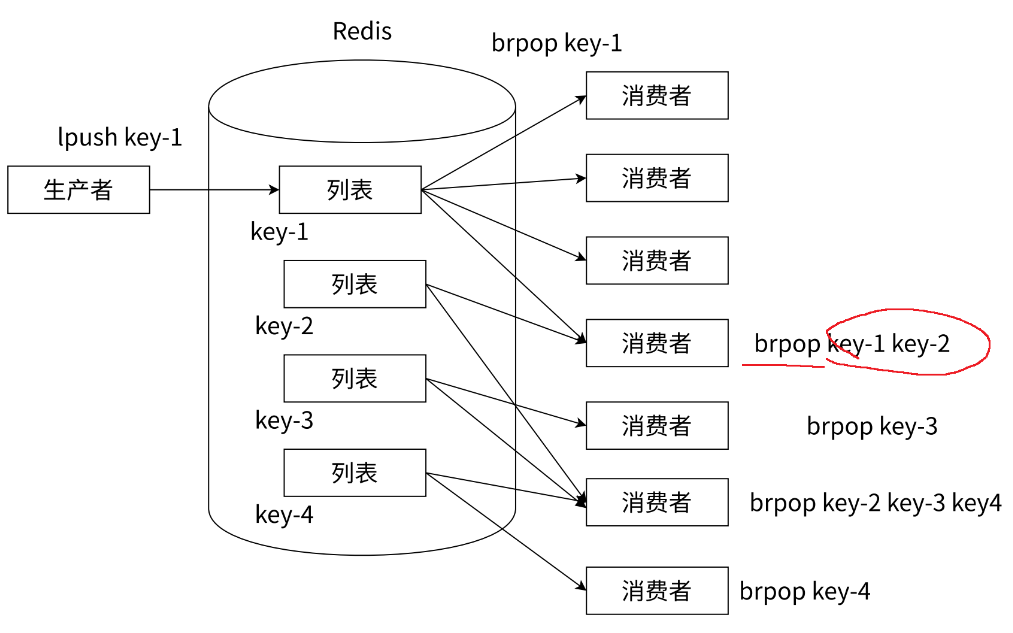
- 通道1:传输短视屏数据
- 通道2:传输弹幕
- 通道3:传输点赞、转发和收藏等数据
- 通道4:传输评论
- …
搞成多个频道,就可以在某种数据发生问题的时候不会对其他数据造成影响
-
-
-
微博TimeLine(微博列表)
每个用户都有属于自己的Timeline,现在需要分页展示文章列表。此时可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素
-
假设每篇微博都有 title,timestamp和content属性
-
hmset myblog:1 title redis从入门到入坟 timestamp 1698656594345 content "Redis架构演进" hmset myblog:2 title Oracle从入门到入坟 timestamp 1698656293856 content "Oracle基础语法" hmset myblog:3 title PLSQL从入门到入坟 timestamp 1698660209945 content "PLSQL存储过程" hmset myblog:4 title Spring从入门到入坟 timestamp 1698660931000 content "Spring入门"
-
-
用户发布4条微博
-
lpush user:1:myblogs myblog:1 myblog:2 myblog:3 myblog:4
-
-
分页获取用户微博
-
keyList = lrange user:1:myblogs 0 1 for key in keyList{hgetall key }keyList = lrange user:1:myblogs 2 3 for key in keyList{hgetall key }
此方案存在一定的问题
- 现在是只有4篇微博。但是我们熟悉的微博可能某个知名博主会有成千上万的微博,因此需要执行多次 hgetall 操作【在循环里访问查询数据库】。势必会造成很多次无效的网络IO请求
- 分页获取文章时,lrange 两端的文章还好。如果是中间的文章则会效率很慢,如果中间微博有1w条,如果将这1w条再拆分成10组,每组1k条,则会有一定的效率提升
-
-
-
set类型
Redis的Set结构与Java中的HashSet类似,可以看作是一个value为null的HashMap。
- 无序
- 不可重复
- 查找快
- 支持交并补查询
Set常用语法
| 语法 | 含义 |
|---|---|
| SADD key member | 向set中添加一个或多个元素 |
| SREM key element | 移除set中的指定元素 |
| SCARD key | 返回set中元素的个数 |
| SISMEMBER key member | 判断一个元素是否存在于set中 |
| SMEMBERS | 获取set中所有元素 |
| SINTER key1 key2 | key1 和 key2 交集 |
| SDIFF key1 key2 | key1 和 key2 差集集 |
Set集合,设置(和get相对)。把一些相关联的数据放到一起,集合中的元素是无序和不可重复的
有序:顺序很重要,变换一下顺序就是两个不同的list
- list:[1, 2, 3] 和 [1, 3, 2] 是两个不同的 list
无需:顺序不重要,变换一下顺序集合还是原来的集合
- set:[1, 2, 3] 和 [1, 3, 2] 是同一个集合
-
sadd、smembers、sismember
-
sadd
-
作用:把集合中的元素叫做 member
-
语法
-
SADD key member [member ...]FLUSHALL sadd key 1 2 3 1 2 3
-
-
时间复杂度:O(1)
-
返回值:本次操作成功添加了多少个元素
-
-
smembers
-
作用:获取set集合中全部元素,元素间的顺序无序
-
语法
-
SMEMBERS keysmembers key
-
-
时间复杂度:O(N),N:元素个数
-
-
sismember
-
作用:判断元素是否在集合中
-
语法
-
SISMEMBER key membersismember key 3 sismember key 4
-
-
时间复杂度:O(1)
-
返回值:0:不在;1:在
-
-
-
spop和srandmember
-
spop
-
作用
- 无count:随机删一个
- count:写多少就删除多少直到空为止
-
语法
-
SPOP key [count]spop key spop key spop key spop key
-
-
时间复杂度:O(N)
-
返回值:删除的元素
-
-
srandmember
-
作用:随机获取一个元素
-
语法
-
SRANDMEMBER key [count]FLUSHALL sadd key 1 2 3 1 2 3 srandmember key srandmember key srandmember key srandmember key srandmember key srandmember key srandmember key 2 srandmember key 3
-
-
时间复杂度:O(N),N:返回的元素个数
-
返回值:返回的值【数组】
-
-
-
smove,srem,scard
-
smove
-
作用:把 member 从 source 上删除再插入到 destination 中
-
语法
-
SMOVE source destination memberFLUSHALL sadd key 1 2 3 4 sadd key2 5 6 7 8 smove key key2 5 smembers key smembers key2 smove key key2 100
-
-
时间复杂度:O(1)
-
返回值:0:成功;1:失败
-
注意:移动一个不存在的数据也不会报错而是返回0
-
-
srem
-
作用:一次可以删除1个member也可以删除多个member
-
语法
-
SREM key member [member ...]srem key 1 srem key 2 3
-
-
时间复杂度:O(N)
-
返回值:删除元素个数
-
-
scard
-
作用:返回集合元素个数
-
语法
-
SCARD key
-
-
时间复杂度:O(1)
-
-
返回值:集合元素个数
-
-
集合间【交并差】
A:1, 2, 3, 4
B:3, 4, 5, 6
A ∩ B = 3 , 4 A \cap B = 3,4 A∩B=3,4
A ∪ B = 1 , 2 , 3 , 4 , 5 , 6 A \cup B = 1,2,3,4,5,6 A∪B=1,2,3,4,5,6
A ∖ B = 1 , 2 A \setminus B = 1,2 A∖B=1,2
B ∖ A = 5 , 6 B \setminus A = 5,6 B∖A=5,6
-
交集
-
sinter
-
作用:计算两个或多个集合交集
-
语法
-
SINTER key [key ...]FLUSHALL sadd key1 1 2 3 4 sadd key2 3 4 5 6 sinter key1 key2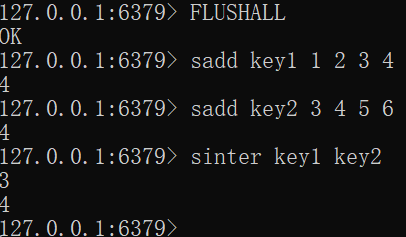
-
-
时间复杂度:O(N*M)【N:最小集合元素个数;M:最大集合元素个数】
-
返回值:交集结果
-
-
sinterstore
-
作用:计算好的交集结果放到destination这个key对应的集合中
-
语法
-
SINTERSTORE destination key [key ...]FLUSHALL sadd key1 1 2 3 4 sadd key2 3 4 5 6 sinterstore key3 key1 key2 smembers key3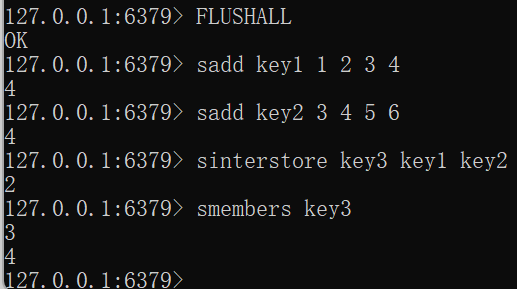
-
-
时间复杂度:O(N*M)【N:最小集合元素个数;M:最大集合元素个数】
-
返回值:交集的元素个数【要想知道交集的内容,直接按照集合的方式访问】
-
-
-
并集
-
sunion
-
作用:计算两个或多个集合并集
-
语法
-
SUNION key [key ...]FLUSHALL sadd key1 1 2 3 4 sadd key2 3 4 5 6 sunion key1 key2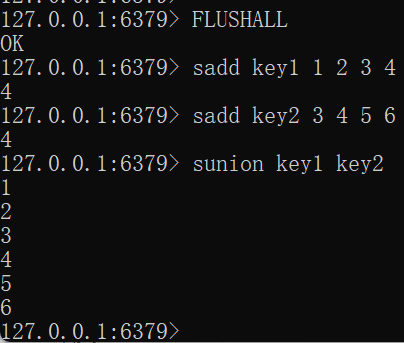
-
-
时间复杂度:O(N),N:总的元素个数
-
返回值:并集结果
-
-
sunionstore
-
作用:计算好的并集结果放到destination这个key对应的集合中
-
语法
-
SUNIONSTORE destination key [key ...]FLUSHALL sadd key1 1 2 3 4 sadd key2 3 4 5 6 sunionstore key3 key1 key2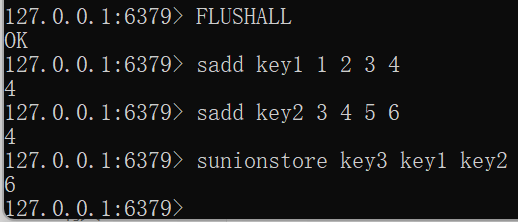
-
-
时间复杂度:O(N),N:总的元素个数
-
返回值:并集元素个数
-
-
-
差集
-
sdiff
-
作用:计算两个或多个集合差集
-
语法
-
SDIFF key [key ...]FLUSHALL sadd key1 1 2 3 4 sadd key2 3 4 5 6 sdiff key1 key2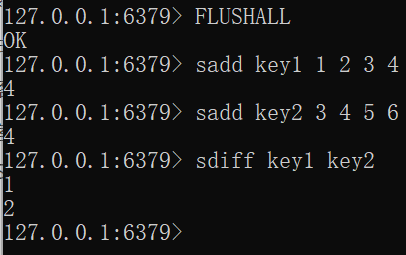
-
-
时间复杂度:
-
返回值:差集结果
-
-
sdiffstore
-
作用:计算好的差集结果放到destination这个key对应的集合中
-
语法
-
SDIFFSTORE destination key [key ...]FLUSHALL sadd key1 1 2 3 4 sadd key2 3 4 5 6 sdiff key1 key2 sdiffstore key3 key1 key2
-
-
时间复杂度:O(N)
-
返回值:差集元素个数
-
-
-
-
set内部编码
集合内部编码方式有两种
-
inset
-
intset(整数集合):当集合中的元素是整数并且元素个数小于 set-max-intset-entries配置(默认512)时,Redis会使用inset作为内部实现从而节约内存

-
-
hashtable
- 不满 inset 条件就会转为 hashtable
-
-
set应用场景
-
使用Set保存用户标签
-
给用户贴标签
-
sadd user:1:tags tag1 tag2 tag3...
-
-
给标签添用户
-
sadd tag1:users user1 user2 user3...
-
-
删除用户下标签
-
srem user:1:tags tag1 tag2 tag3...
-
-
删除标签下用户
-
srem tag1:users user1 user2 user3...
-
-
计算用户共同爱好
-
sinter user:1:tags user:2:tags对于增强用户体验、提升用户粘性有巨大帮助【偷窥隐私】逐渐形成信息茧房
-
-
-
使用Set计算公共好友
基于“集合交集”
-
使用Set统计 UV
UV:user view,每个用户,访问服务器都会产生一个uv,但同一个用户多次访问不会使uv增加
uv需要按照用户进行去重,可用set实现
PV:page view,每个用户访问该服务器,都会产生一个pv
-
zset类型
Redis的SortedSet是一个可排序的Set集合。与Java中的TreeSet类似,但底层数据结构差异很大。SortedSet中的每个元素都带有score属性,可以基于score属性对元素排序,底层是一个调表(SkipList)+Hash表
- 可排序
- 不可重复
- 查询快
因为SortedSet可排序特性,经常用来实现排行榜这样的功能
SortedSet常用语法
| 语法 | 含义 |
|---|---|
| ZADD key score member | 添加一个或多个元素到SortedSet,如果已经存在则更新其score值 |
| ZREM key member | 删除SortedSet中指定元素的score值 |
| ZSCORE key member | 获取SortedSet中指定元素的score值 |
| ZRANK key member | 获取SortedSet中指定元素排名【升序】 |
| ZREVRANK key member | 获取SortedSet中指定元素排名【降序】 |
| ZCOUNT key min max | 统计score值在给定范围内的所有元素的个数 |
| ZINCRBY key increment member | 让SortedSet中指定元素自增,步长为指定的increment值 |
| ZRANGE key min max | 按照score排序后,获取指定排名范围内的元素 |
| ZRANGEBYSCORE key min max | 按照score排序后,获取指定score范围内的元素 |
| ZINTER,ZUNION,ZDIFF | 交并差 |
List:有序【孙行者、行者孙、者行孙:不同的猴】
Set:无序,唯一【孙行者、行者孙、者行孙:同一只猴】
Zset:有序,唯一【所谓的有序性:升序、降序】
实际上 zset 内部是按照升序组织数据
Zset为了有一个排序规则,给Zset中的member引入了一个属性分数(score),浮点类型。进行排序的时候就会按照此处的 分数 大小升/降序
分数相同:关羽张飞都是 97.8 分,会按照雨字符串本身字典徐来排序
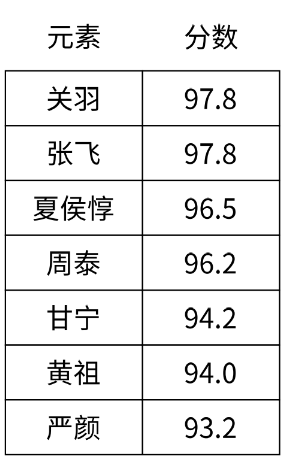
-
zadd,zrange
-
zadd
-
作用:添加元素
-
语法
-
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member...]FLUSHALL zadd key 99 吕布 98 赵云 96 典韦 95 关羽 zrange key 0 -1 zrange key 0 -1 withscoreszadd key 10 赵云 zrange key 0 -1 withscores- 不加 NX | XX
- member不存在:新建
- member存在:更新
- NX:必须不存在,达到新建效果
- XX:必须要求存在,达到更新效果
- GT:新的分数比旧分数大才能更新,如果元素不存在则会达到“新建”
- LT:新的分数比旧分数小才能更新,如果元素不存在则会达到“新建”
- CH:changed缩写,返回值是更改【添加+更改】的元素总数,ZADD只会返回统计添加的个数
- INCR:相当于 ZINCRBY
如果修改的分数,则会重新排序

zadd key NX 94 张飞 zrange key 0 -1 withscores zadd key NX 92 张飞 zrange key 0 -1 withscores zadd key XX 92 张飞 zadd key XX 90 马超zadd key XX 92 张飞返回值是0代表添加了0个元素而不是修改失败zadd key XX 90 马超XX的原因导致添加了0条数据
使用
ch影响返回结果zadd key ch 90 张飞
使用
incr在原有基础上进行新增【类似于zincrby修改效果】zadd key incr 4 张飞
- 不加 NX | XX
-
-
时间复杂度: O ( l o g N ∗ K ) O(log^{N} * K) O(logN∗K),K:添加 K 个元素
由于zset是有序结构,要求新增元素要放到合适的位置上(找位置)
zset内部数据结构本质是 跳表
-
-
zrange
-
作用:查看有序集合中元素详情【类似 lrange 可以指定一对下标构成的区间】
-
语法
-
ZRANGE key start stop [BYSCORE | BYLEX] [REV] [LIMIT offset count] [WITHSCORES]zrange key 0 -1 rev withscores
-
-
时间复杂度: O ( l o g N + M ) O(log^{N}+M) O(logN+M)
-
-
-
zcard,zcount
-
zcard
-
作用:返回当前集合元素个数
-
语法
-
ZCARD keyzrange key 0 -1 withscores zcard key
-
-
时间复杂度:O(1)
-
返回值:当前集合元素个数
-
-
zcount
-
作用:返回分数在 [min, max] 闭区间之间的元素个数,可通过 ( 排除
-
语法
-
ZCOUNT key min maxzrange key 0 -1 withscores zcount key 94 96 zcount key (94 96 zcount key (94 (96此处标识比较奇葩。闭区间:“”;开区间:“(”
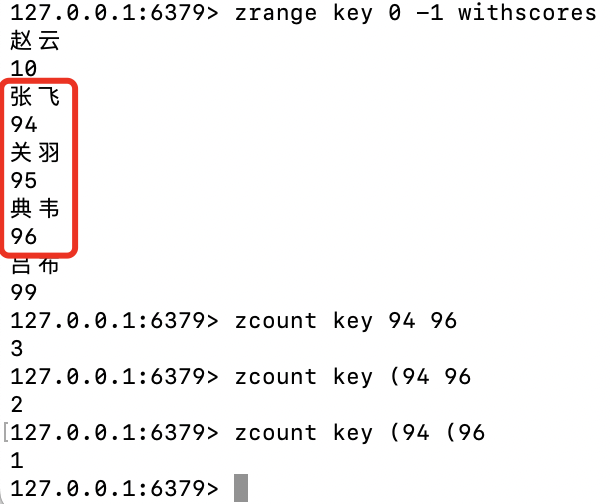
-
-
时间复杂度: O ( l o g N ) O(log^{N}) O(logN)
-
先根据 min 找到一个元素下标
-
再根据 max 找到一个元素下标
下标相减求个数
-
-
返回值:满足条件的元素列表个数
-
扩展
-
zset在浮点数中,也支持 inf,-inf做为max,min
- -inf:负无穷大【不是无穷小区近0的意思,而是远离0】
- inf:正无穷大
zrange key 0 -1 withscores zcount key 0 99 zcount key -inf inf zrange -inf inf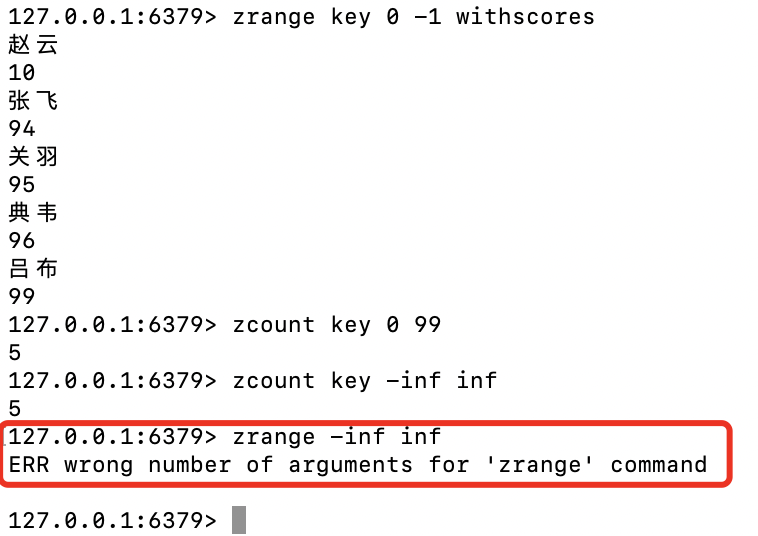
-
-
-
-
zrange,zrevrange,zrangebyscore
-
zrange
-
作用:查看集合,按照分数升序排序
-
语法
-
ZRANGE key start stop [BYSCORE | BYLEX] [REV] [LIMIT offset count] [WITHSCORES]FLUSHALL zadd key 99 吕布 98 赵云 96 典韦 96 马超 95 关羽 94 张飞 zrange key 0 -1 withscores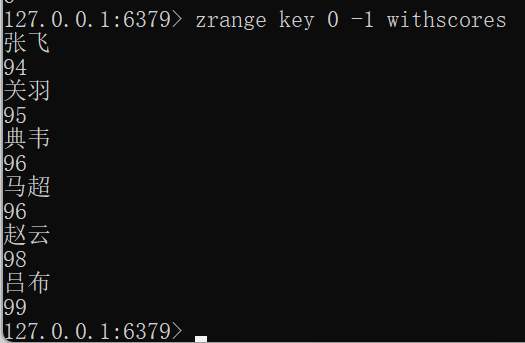
-
-
时间复杂度: O ( l o g N + M ) O(log^{N} + M) O(logN+M)
-
-
zrevrange
-
作用:查看集合,按照分数降序排序
-
语法
-
ZREVRANGE key start stop [WITHSCORES]FLUSHALL zadd key 99 吕布 98 赵云 96 典韦 96 马超 95 关羽 94 张飞 zrevrange key 0 -1 withscores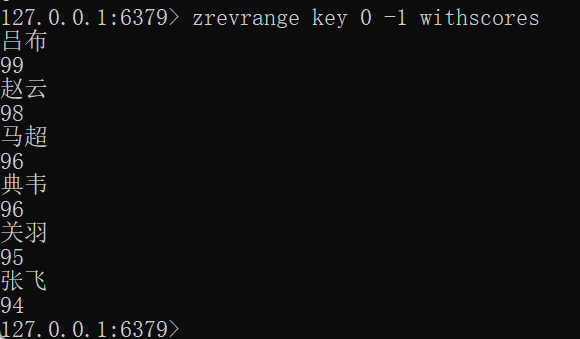
-
-
时间复杂度: O ( l o g N + M ) O(log^{N} + M) O(logN+M)
-
返回值:
-
-
zrangebyscore-
作用:按照分数找元素,类似于 zcount【未来将弃用】
-
语法
-
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]FLUSHALL zadd key 99 吕布 98 赵云 96 典韦 96 马超 95 关羽 94 张飞 zrangebyscore key 94 96 withscores
-
-
时间复杂度: O ( l o g N + M ) O(log^{N} + M) O(logN+M)
-
返回值:
-
-
-
zpopmax
-
zpopmax
-
作用:删除并返回分数最高的 count 个元素
-
语法
-
ZPOPMAX key [count]FLUSHALL zadd key 99 吕布 96 赵云 96 典韦 96 马超 96 关羽 94 张飞 zpopmax key zpopmax key zpopmax key 2删除 99 吕布之后出现了再删除一个元素发现有3个同分数96,结果会按照字典序降序排序删除
字典升序:典 < 马 < 赵
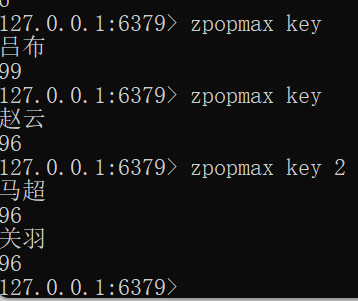
-
-
时间复杂度: O ( l o g N ∗ M ) O(log^{N}*M) O(logN∗M)。N:有序集合元素个数,M:count要删元素个数
-
这里的 l o g N log^N logN 我们可以通过一个变量记录尾删的位置,后续删除是不是可以达到 O(1) 呢?省区查找过程
但是redis目前没有这样做:redis源码中,针对有序集合,确实记录了尾部这样的特定位置,但实际上在删除的时候调用了一个 “通用的删除函数”【给定一个 member 值,进行查找。找到位置之后再删除】
-
-
返回值:被删除元素(member 和 score)
-
-
-
bzpopmax
有序集合其实也可以看为一个 “优先级队列”,有的时候也需要一个带有 “阻塞功能的” 的优先级队列。每个 key 都是一个有序集合
阻塞也是发生在有序集合为空的时候,阻塞到有其他客户端插入元素,也会有一个超时时间【s为单位,double类型】
-
bzpopmax
-
作用:删除最大值的阻塞版本【zpopmax有一个 count 参数,而阻塞版本没有这个参数】
-
语法
-
客户端1
-
BZPOPMAX key [key ...] timeoutFLUSHALL bzpopmax key 600
-
-
客户端2
-
FLUSHALL zadd key 10 张三 20 李四 30 王五
-
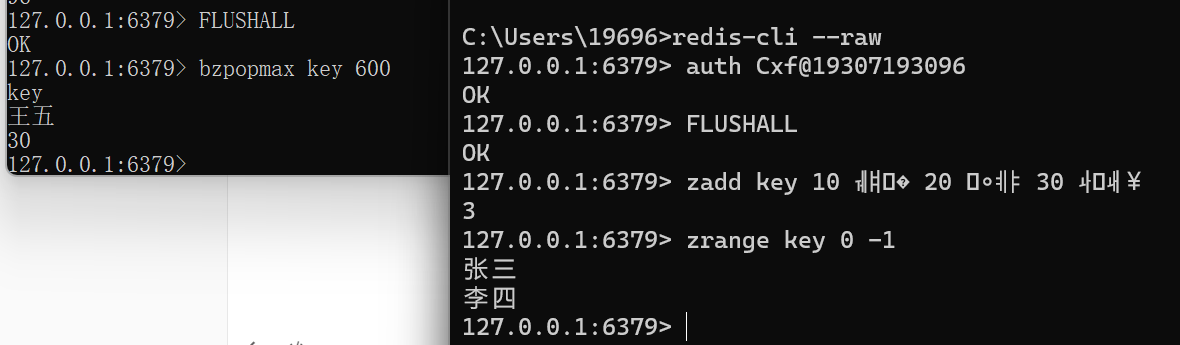
-
-
时间复杂度: O ( l o g N ) O(log^{N}) O(logN)
-
-
-
zpopmin、bzpopmin
-
zpopmin
-
作用:删除有序集合中最小的元素
-
语法
-
ZPOPMIN key [count]FLUSHALL zadd key 10 张三 20 李四 30 王五 zpopmin key zpopmin key 2
-
-
时间复杂度: O ( l o g N ∗ M ) O(log^{N} * M) O(logN∗M)
-
返回值:被删除的元素集
-
-
bzpopmin
-
作用:删除有序集合中的最小元素阻塞版
-
语法
-
BZPOPMIN key [key ...] timeout
-
-
时间复杂度: O ( l o g N ) O(log^{N}) O(logN)
-
-
-
zrank、zrevrank、zscore
-
zrank
-
作用:得到元素在有序集合中的排名
-
语法
-
ZRANK key member [WITHSCORE]FLUSHALL zadd key 10 张三 20 李四 30 王五 40 赵六 zrank key 李四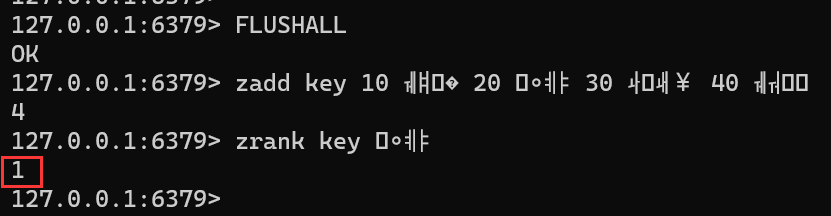
-
-
时间复杂度: O ( l o g N ) O(log^{N}) O(logN)
-
返回值:zrank得到的下标是升序计算的下标
-
-
zrevrank
-
作用:
-
语法
-
ZREVRANK key member [WITHSCORE]FLUSHALL zadd key 10 张三 20 李四 30 王五 40 赵六 zrevrank key 李四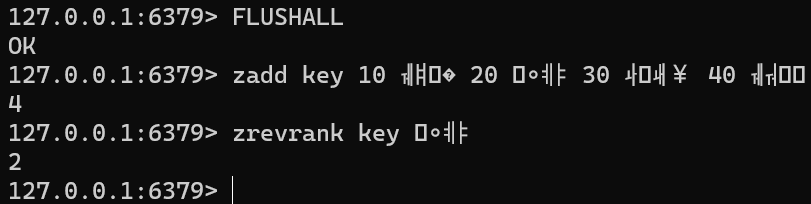
-
-
时间复杂度: O ( l o g N ) O(log^{N}) O(logN)
-
返回值:
-
-
zscore
-
作用:得到 member 的 score
-
语法
-
ZSCORE key memberFLUSHALL zadd key 10 张三 20 李四 30 王五 40 赵六 zscore key 张三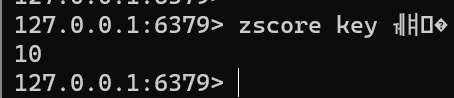
-
-
时间复杂度:O(1)
根据 member 找元素,之前都是 O ( l o g N ) O(log^{N}) O(logN) 此处 redis 做了优化。付出额外空间
-
返回值:
-
-
-
zrem、zremrangebyrank、zremrangebyscore
-
zrem
-
作用:删除有序集合中的member元素
-
语法
-
ZREM key member [member ...]FLUSHALL zadd key 10 张三 20 李四 30 王五 40 赵六 zrem key 张三 zrem key 李四 王五 小七
-
-
时间复杂度: O ( l o g N ∗ M ) O(log^{N} * M) O(logN∗M)。N:有序集合中元素个数,M:参数中member个数
-
返回值:删除成功的元素个数
-
-
zremrangebyrank
-
作用:根据下标,删除 [start, stop] 闭区间范围内的元素
-
语法
-
ZREMRANGEBYRANK key start stopFLUSHALL zadd key 10 张三 20 李四 30 王五 40 赵六 zremrangebyrank key 1 2 zrange key 0 -1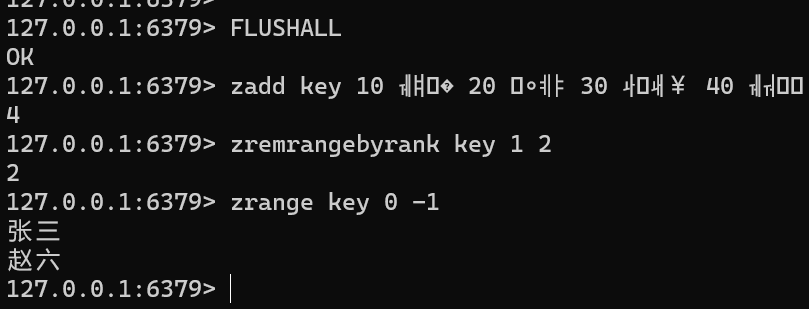
-
-
时间复杂度: O ( l o g N + M ) O(log^{N} + M) O(logN+M)
M:start-stop+1 区间中元素个数
-
返回值:成功删除元素个数
-
-
zremrangebyscore
-
作用:根据分数,删除指定 [min, max] 闭区间内元素
-
语法:
-
ZREMRANGEBYSCORE key min maxFLUSHALL zadd key 10 张三 20 李四 30 王五 40 赵六 zremrangebyscore key 20 30 zrange key 0 -1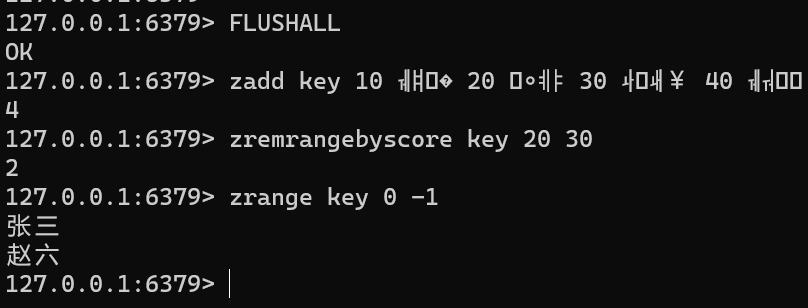
-
-
时间复杂度: O ( l o g N + M ) O(log^{N} + M) O(logN+M)
-
返回值:成功删除元素个数
-
-
-
zincrby
-
zincrby
-
作用:为指定元素的关联分数添加指定分数值【负数就减少】
-
语法
-
ZINCRBY key increment memberFLUSHALL zadd key 10 zhangsan 20 lisi 30 wangwu 40 zhaoliu zincrby key 15 zhangsan zrange key 0 -1 withscores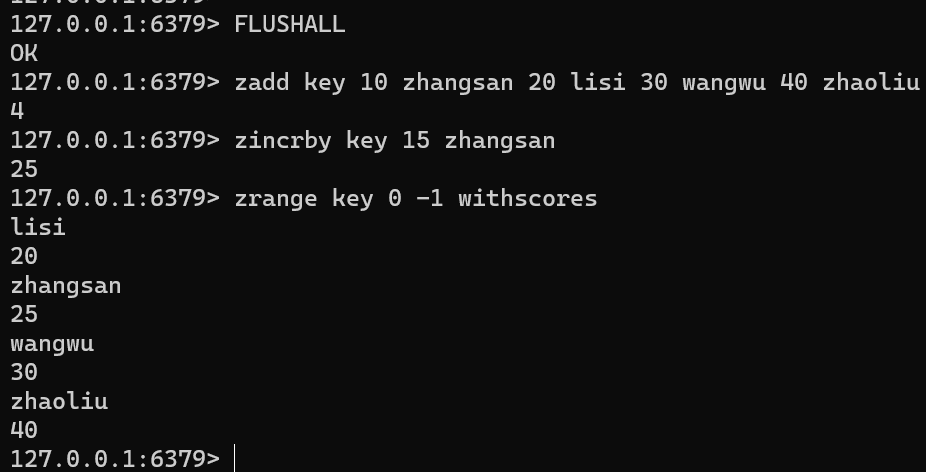
-
-
时间复杂度: O ( l o g N ) O(log^{N}) O(logN)
-
返回值:增加元素后的分数
-
-
-
集合的交并差
之前集合的 sinter、sunion、sdiff 操作针对 zset 也有 zinter、zunion、zdiff
后缀 store 可以将集合计算结果保存到另一个集合中
zset 的多集合运算多了个 numkeys 指定多少个 key 参与计算
-
zinterstore
-
作用:将有序集合的计算结果保存到另一个集合中
-
语法
-
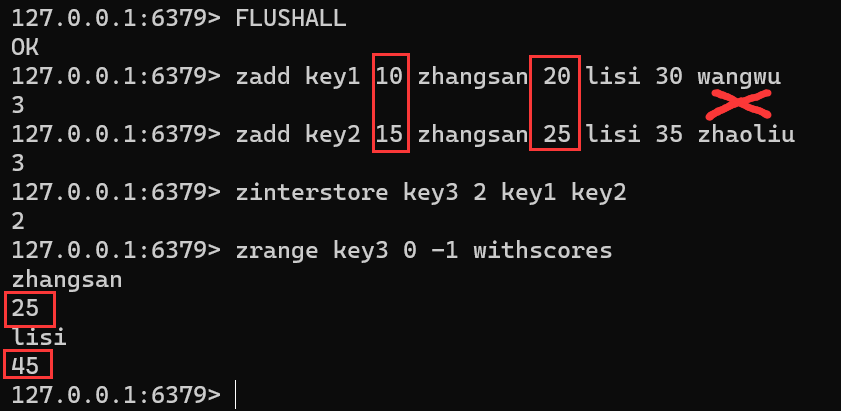
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>]FLUSHALL zadd key1 10 zhangsan 20 lisi 30 wangwu zadd key2 15 zhangsan 25 lisi 35 zhaoliu zinterstore key3 2 key1 key2 zrange key3 0 -1 withscoresnumkeys:后续有多少个 key 参与计算
WEIGHTS:权重
AGGREGATE:对于不同分数但相同的 member 结合运算完之后的分数如何统计【默认求和】
默认就是分数相加
带有 WEIGHTS 权重的计算
zinterstore key3 2 key1 key2 weights 2 3 zrange key3 0 -1 withscores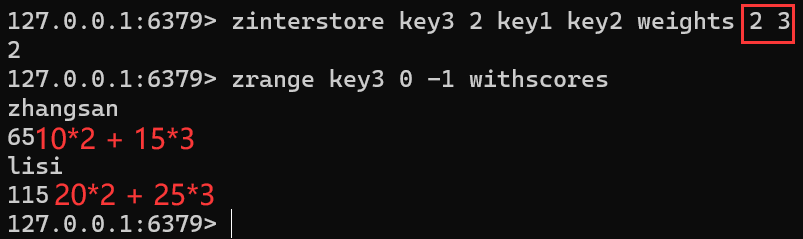
带有 AGGREGATE 设计分数计算方式
zinterstore key3 2 key1 key2 aggregate max zrange key3 0 -1 withscores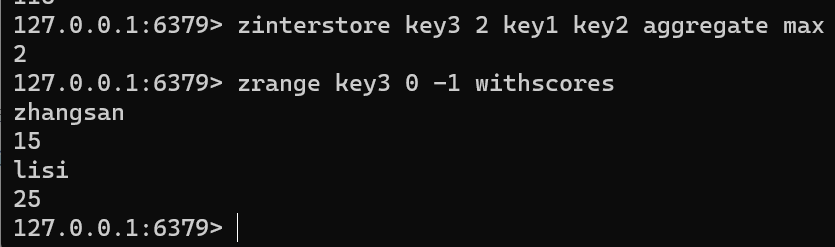
-
-
时间复杂度: O ( N ∗ K ) + O ( l o g M ∗ M ) O(N * K) + O(log^{M} * M) O(N∗K)+O(logM∗M)
N:若干集合中里面集合元素个数最小的个数
K:K个集合求交集
M:排序结果集中M个元素
-
返回值:计算的集合中元素个数
-
-
-
zset内部编码
zset内部编码方式有两种:
- ziplist:个数少于 zset-max-ziplist-entries 配置(默认 128 个) + 每个元素值小于 zset-max-ziplist-value 配置(默认 64 字节) 。用 ziplist 节约内存
- skiplist:当 ziplist 条件不满足就会自动转为 skiplist
-
zset应用场景
有序集合最典型的应用场景就是排行榜系统。榜单的排名为度有多方面:时间、点赞量、浏览量。举一个按照点赞维护排行榜的例子:
对于内存的考虑:假设按照最火游戏之一王者荣耀计算
userID:4字节
score:8字节
thousand千:kb
million百万:mb
billion十亿:G
一个用户12字节。假设有1亿用户就是就是12亿字节也就是1.2G
-
添加用户赞数
-
lihua发布的文章获得3个赞
-
zadd user:ranking:2023-10-31 3 lihua
-
-
后续又有人点赞
-
zincrby user:ranking:2023-10-31 1 lihua
-
-
-
取消点赞
-
lihua注销,平台删除时可以将用户从榜单中删除
-
zrem user:ranking:2023-10-31 lihua
-
-
-
查看点赞最多前10
-
zrevrangebyrank user:ranking:2023-10-31 0 9
-
-
展示用户信息及分数
用户名作为键后缀,将用户信息保存在哈希类型中。分数和排名可用
zscore和zrank获取-
hgetall user:info lihua zscore user:ranking:2023-10-31 lihua zrank user:ranking:2023-10-31 lihua
-
-
类型补充
-
stream
- List版本的 b l/r pop 的升级版消息队列,使用也更复杂
-
geospatial
- 存储经纬度
-
hyperloglog
-
应用场景只有一个:估算集合中元素个数【计数功能】
假设Set有一个应用场景,统计服务器的UV(用户访问次数)。但问题在于:如果UV数据量非常大,Set就会消耗很多的内存空间
1亿UV,假设一个 userID 8字节,则一共 0.8G ≈ \approx ≈ 800MB。而Hyperloglogs则最多使用 12KB 达到此效果
-
Hyperloglog不存储元素内容大能够记录“元素特征”,能够知道当前新增的元素是一个已经存在的元素还是一个崭新第一次出现的元素
精确性还是有一定的误差
HyperLogLog 是一种概率数据结构,用于估计集合的基数。 作为一种概率数据结构,HyperLogLog 以完美的准确性换取高效的空间利用
Redis HyperLogLog 实现最多使用 12 KB,并提供 0.81% 的标准错误

-
-
bitmap
-
位图本质上还是一个集合,属于是Set类型针对整数的特殊化版本【节省空间】
-
Hyperloglog更省空间:存数字、字符串但不存元素内容只是计数效果。没有元素内容
存储元素的时候提取特征的过程是不可逆的【信息量丢失了】
-
bitmap:存储元素内容,有些业务场景还是需要bitmap存储的内容
-
-
-
bitfield
-
位域【类似于C语言中结构体在内存中的布局。主要是内存对齐】
-
struct type_my{char a;int b;int c; }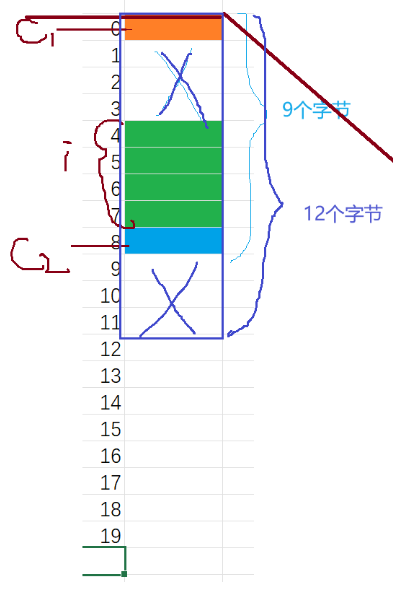
-
-
redis官网用了一个 魔兽世界的梗 哥布林举例:补刀+金币的例子。补1个刀加50金币
-
初始化u32玩家金币
-
u32玩家补了一个刀,增加50金币
-
u32玩家买了件装备,扣掉999金币
-
查看u32玩家的数据
-
所以类似于C语言结构体
-
struct Player{int count;int gold; }
-
-
-




渐进式遍历 scan
使用 scan 命令进行渐进式遍历从而防止 keys * 可能导致阻塞问题。每次 scan 时间复杂度 O(1)。需要完整地遍历完全部 key 需要多次运行 scan
首次运行
scan会从 0 开始当
scan返回的下次位置为 0 时,遍历结束
作用:渐进式的方式遍历全部 key
语法
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]FLUSHALL
set k0 000
mset k1 111 k2 222 k3 333 k4 444 k5 555 k6 666 k7 777 k8 888 k9 999
scan 0

pattern:匹配模式
count:限制这一次遍历能够获取到多少个元素,默认10【此处的count只是给redis服务器一个提示/建议】
此处的限制并非和MySQL的 limit不同,MySQL更精确
type:匹配的 key 类型
时间复杂度:O(1)
返回值:下一次 scan 的游标(cursor)以及本次 得到的 key
指定一下 count 参数
FLUSHALL
set k0 000
mset k1 111 k2 222 k3 333 k4 444 k5 555 k6 666 k7 777 k8 888 k9 999
scan 0 count 3
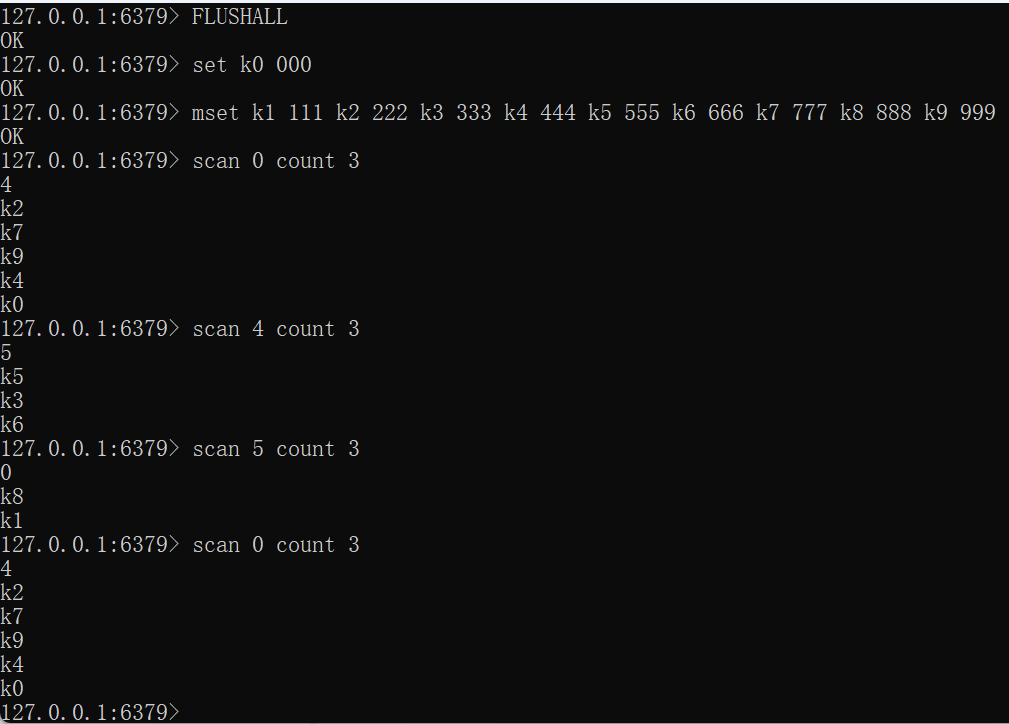
不需要管每次 cursor值多少,只需要根据redis服务器告知的cursor遍历即可
注意
- 除了
scan外,Redis 面向哈希类型、集合类型、有序集合类型分别提供了 hscan、sscan,zscan 用法和scan类似- 虽然渐进式遍历解决了阻塞问题,但是如果在遍历期间发生的(CRUD)是感知不到的,所以就可能导致遍历时 key 的 重复 或者 遗漏
- Redis服务器不会保留任何状态,因此遍历过程中可以任意中断
数据库管理
切换数据库
关系型数据库中比如 MySQL 支持一个实例通过 字符串 控制多个数据库,而 Redis 则通过 数字 来控制16 个数据库。0:1号数据库,15:16号数据库。数据库中存储的数据即使重复也互不冲突,默认情况下使用的是0数据库

虽然 Redis 支持多数据库,当需要两套完全隔离的数据库环境的时候建议用多个 Redis实例 而不是一个 Redis实例 创建出多个数据库这种做法
Redis实例对多数据库未提供太多特性,其次是无论多少个数据库Redis都是单线程模型,所以彼此之间还是需要排队等待。同时还会让开发、调试和运维工作变得复杂。因此推荐使用数据库0
清除数据库
-
清除本数据库
-
FLUSHDB [ASYNC | SYNC] -
时间复杂度:O(N)
-
-
清除全部数据库
-
FLUSHALL
-
获取数据库中key个数
DBSIZEFLUSHALL
mset k0 000 k1 111 k2 222 k3 333 k4 444 k5 555 k6 666 k7 777 k8 888 k9 999
dbsize

Java客户端
MavenJedis快速入门
- Jedis和Lettuce:这两个主要是提供了Redis命令对应的API,方便操作Redis。而SpringDataRedis又针对这两种做了抽象和封装
- Jedis:语法和Redis类似,优点是使用快捷缺点是多线程环境下会出现不安全
- Lettuce:依靠opsForXxx进行操作Redis数据库,可解决多线程不安全情况
- Redisson:是在Redis基础上实现了分布式的可伸缩的Java数据结构。例如Map、Queue等。而且支持跨进程的同步机制:Lock、Semaphore等待,比较适合用来实现特殊功能需求
创建一个Maven项目,引入需要的依赖
Jedis官网
<!-- redis依赖 -->
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>4.3.1</version>
</dependency>
<!-- 测试依赖 -->
<dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>5.9.1</version><scope>test</scope>
</dependency>
一个redis小测试
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;import java.util.Map;public class JedisTest {private Jedis jedis;@BeforeEachvoid setUp() {// 1.建立连接jedis = new Jedis("127.0.0.1", 6379);// jedis = JedisConnectionFactory.getJedis();// 2.设置密码jedis.auth("123456");// 3.选择数据库jedis.select(0);}@AfterEachvoid close() {if (jedis != null) {jedis.close();}}@Testvoid testString() {// 存数据String result = jedis.set("name", "张三");System.out.println("result = " + result);// 取数据String name = jedis.get("name");System.out.println("name = " + name);}@Testvoid testHash() {jedis.hset("user:1", "name", "张三");jedis.hset("user:1", "age", "13");jedis.hset("user:1", "sex", "male");Map<String, String> map = jedis.hgetAll("user:1");System.out.println(map);}
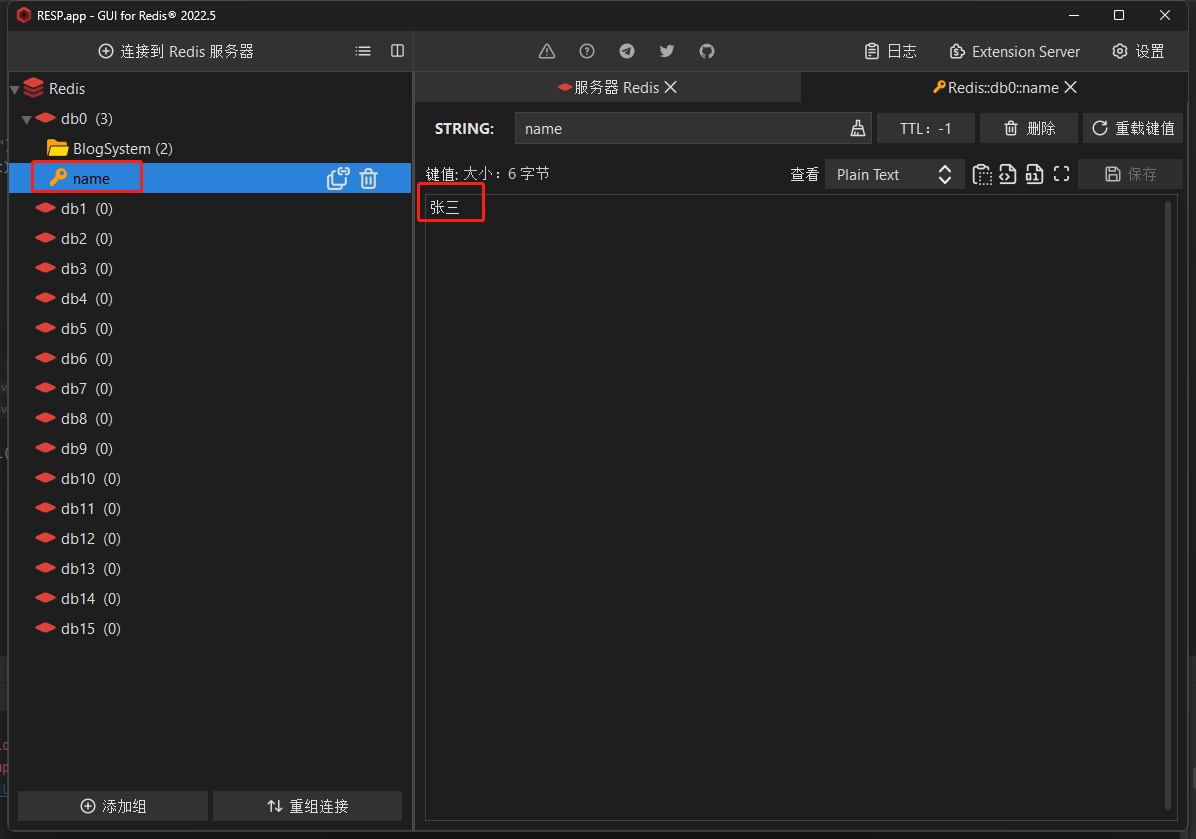
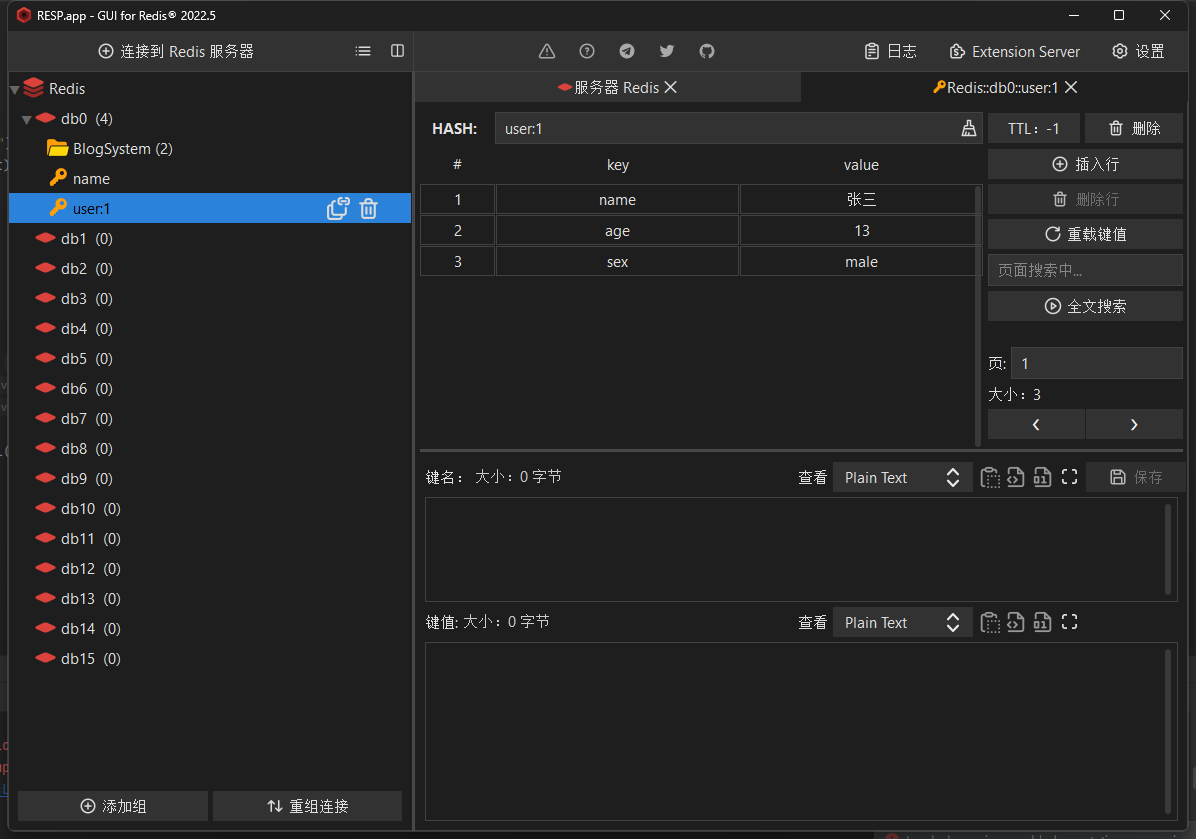
}打开客户端可以看到已经成功插入String和Hash类型的数据
由于经常的断开连接,建立连接会有消耗。所以以创建一个连接池
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;public class JedisConnectionFactory {private static final JedisPool jedisPool;static {// 配置连接池JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();// 最大连接数jedisPoolConfig.setMaxTotal(10);// 最大空闲连接jedisPoolConfig.setMaxIdle(10);// 最小空闲连接jedisPoolConfig.setMinIdle(0);// 等待空闲时间[ms]jedisPoolConfig.setMaxWaitMillis(100);// 创建连接池对象,参数:连接池配置,服务端IP,服务端接口,超时时间,密码jedisPool = new JedisPool(jedisPoolConfig, "127.0.0.1", 6379, 100, "123456");}public static Jedis getJedis() {return jedisPool.getResource();}
}SpringDataRedis客户端
SpringDataRedis官网简介
可以看到Redis的支持

创建一个Spring项目,添加如下依赖
yml配置如下
spring:redis:host: 127.0.0.1port: 6379password: Cxf@19307193096lettuce:pool:max-active: 8 #最大连接数max-idle: 8 #最大空闲连接min-idle: 0 #最小空闲连接max-wait: 1000ms #超时时间
测试代码如下
package app;import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;@SpringBootTest
class TestRedisTemplate {private RedisTemplate redisTemplate;@Autowiredpublic TestRedisTemplate(RedisTemplate redisTemplate) {this.redisTemplate = redisTemplate;}@Testpublic void testString() {// 写入一条 String 数据redisTemplate.opsForValue().set("name", "张三");// 获取一条 String 数据Object name = redisTemplate.opsForValue().get("name");System.out.println(name);}
}

会发现已经是乱码,可读性很差,因此需要用到Redis的序列化。那么问题出现在哪儿呢?我们顺着RedisTemplate 部分源码阅读一下
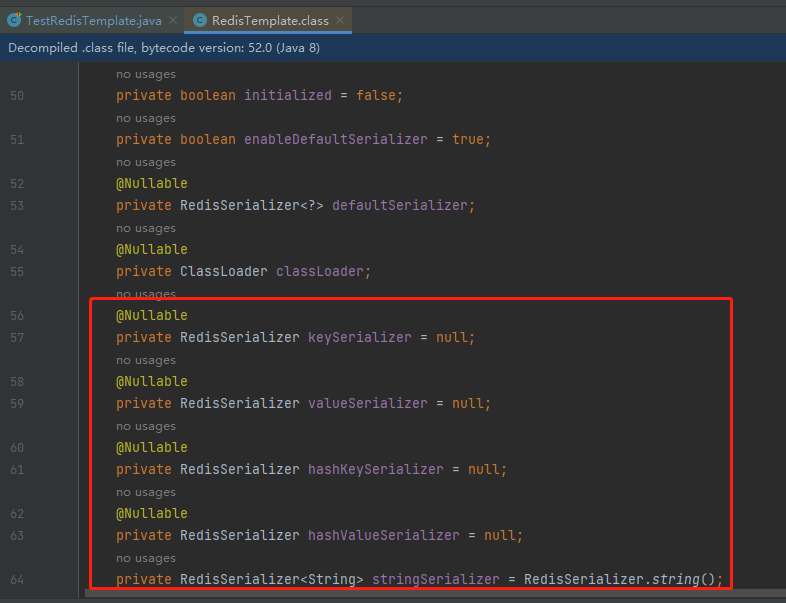
主要是 key和value 的序列化。redis中key一般用的都是字符串类型,因此使用的是String类型的序列化
程序会先通过 afterPropertiesSet 确定序列化方式
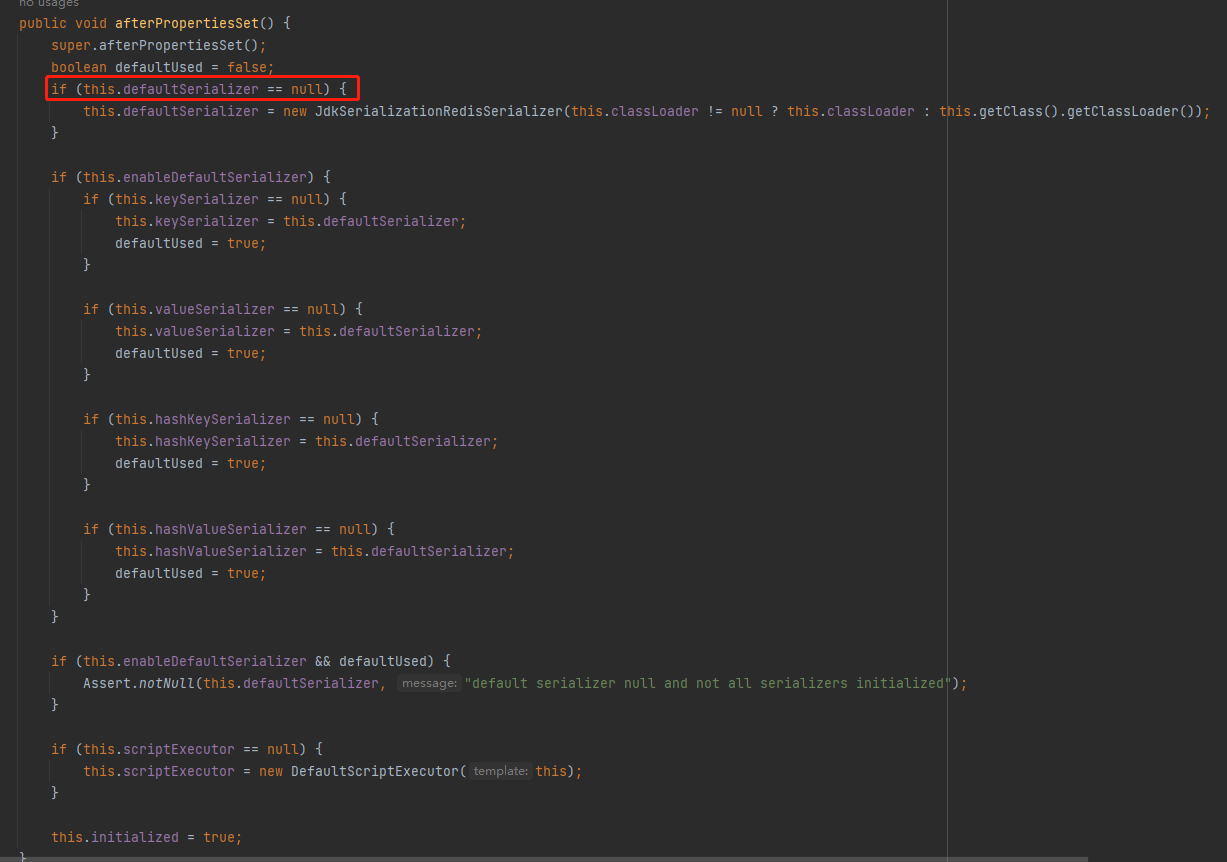
查看默认的 defaultSerializer 的属性如下所示,是一个 null 。所以会使用默认的 JDK序列化工具
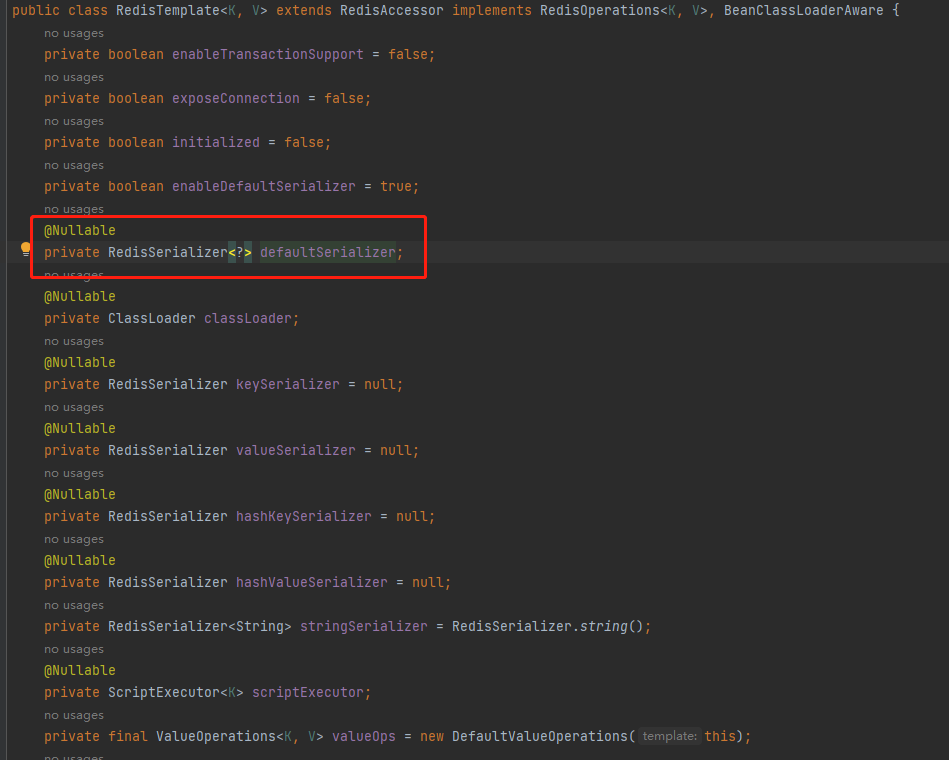
我们再看 this.defaultSerializer = new JdkSerializationRedisSerializer(this.classLoader != null ? this.classLoader : this.getClass().getClassLoader()); 方法
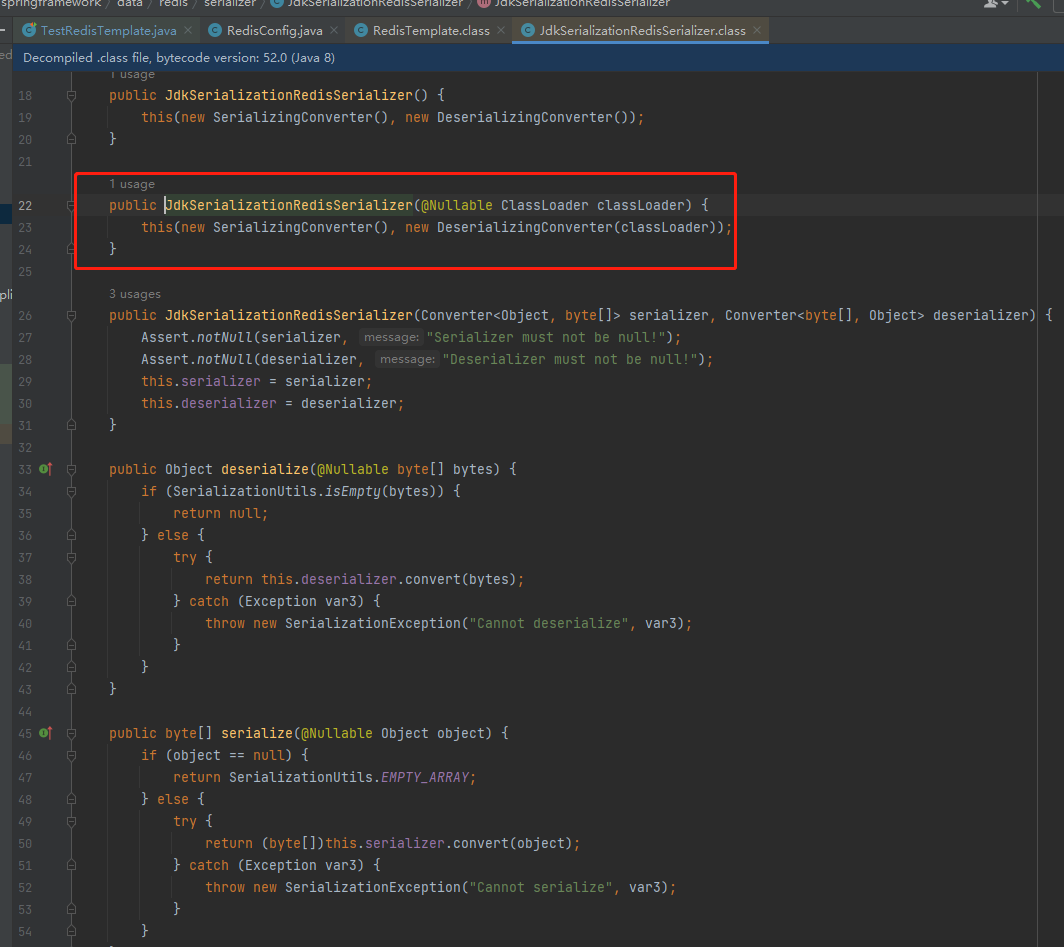
再看 (new SerializingConverter() 代码
再看 new DefaultSerializer() 代码
再看 serialize() 用的是 ObjectOutPutStream 序列化
上面了解了 JDK的序列化方式,SpringDataRedis集成了众多序列化工具,默认使用的是JDK序列化方式,对于普通对象而言使用则会出现一定乱码问题,SpringDataRedis更推荐使用大名鼎鼎的 Jackson 进行对对象序列化
自定义 Redis 的序列化器
package app.config;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
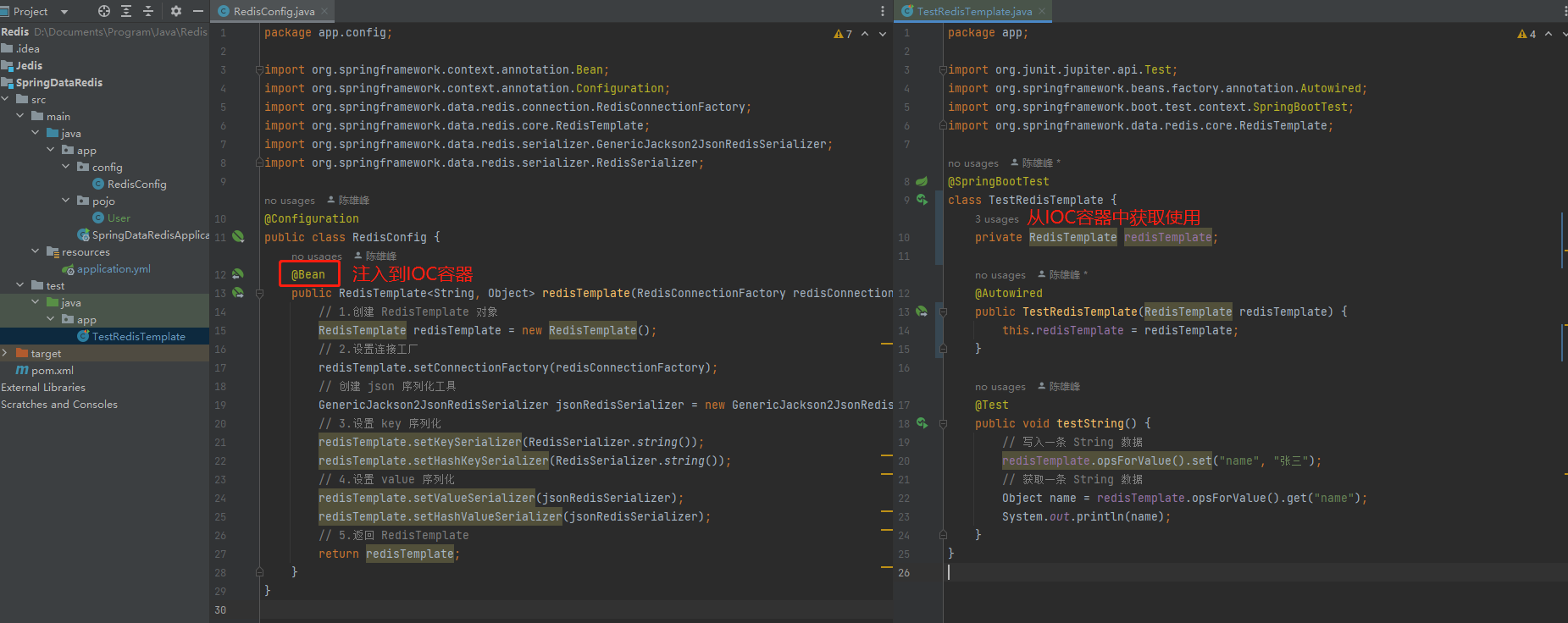
import org.springframework.data.redis.serializer.RedisSerializer;@Configuration
public class RedisConfig {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {// 1.创建 RedisTemplate 对象RedisTemplate redisTemplate = new RedisTemplate();// 2.设置连接工厂redisTemplate.setConnectionFactory(redisConnectionFactory);// 创建 json 序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// 3.设置 key 序列化redisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setHashKeySerializer(RedisSerializer.string());// 4.设置 value 序列化redisTemplate.setValueSerializer(jsonRedisSerializer);redisTemplate.setHashValueSerializer(jsonRedisSerializer);// 5.返回 RedisTemplatereturn redisTemplate;}
}
测试结果如下所示
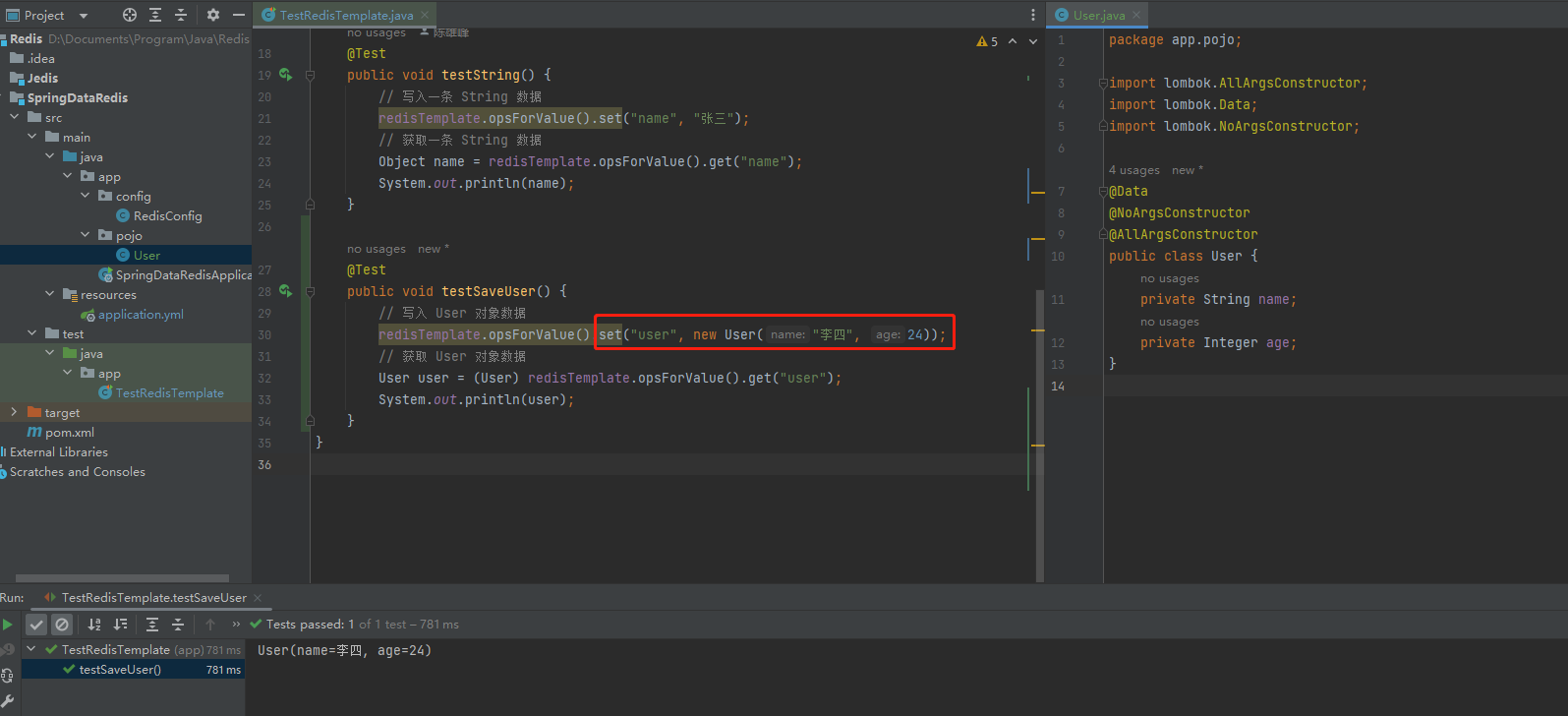
我们再测试一下对象的存储结果
再去redis数据库中查看
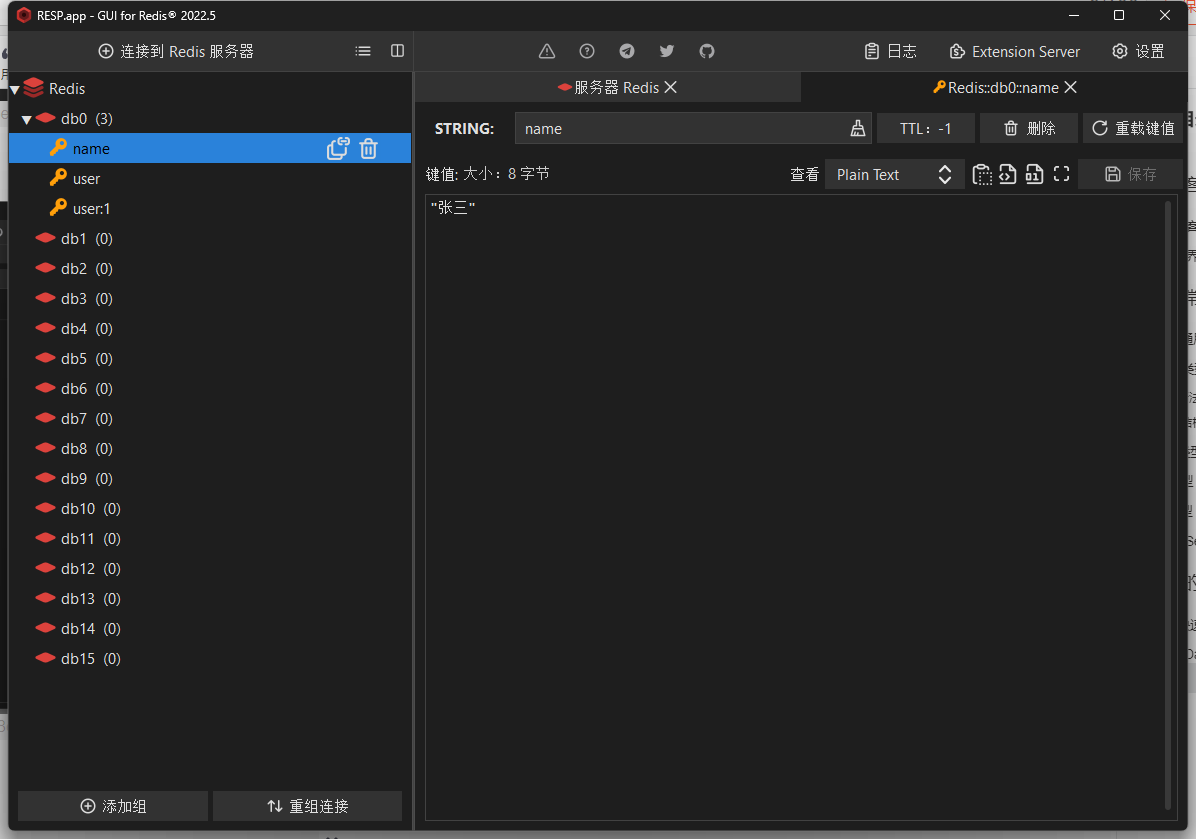
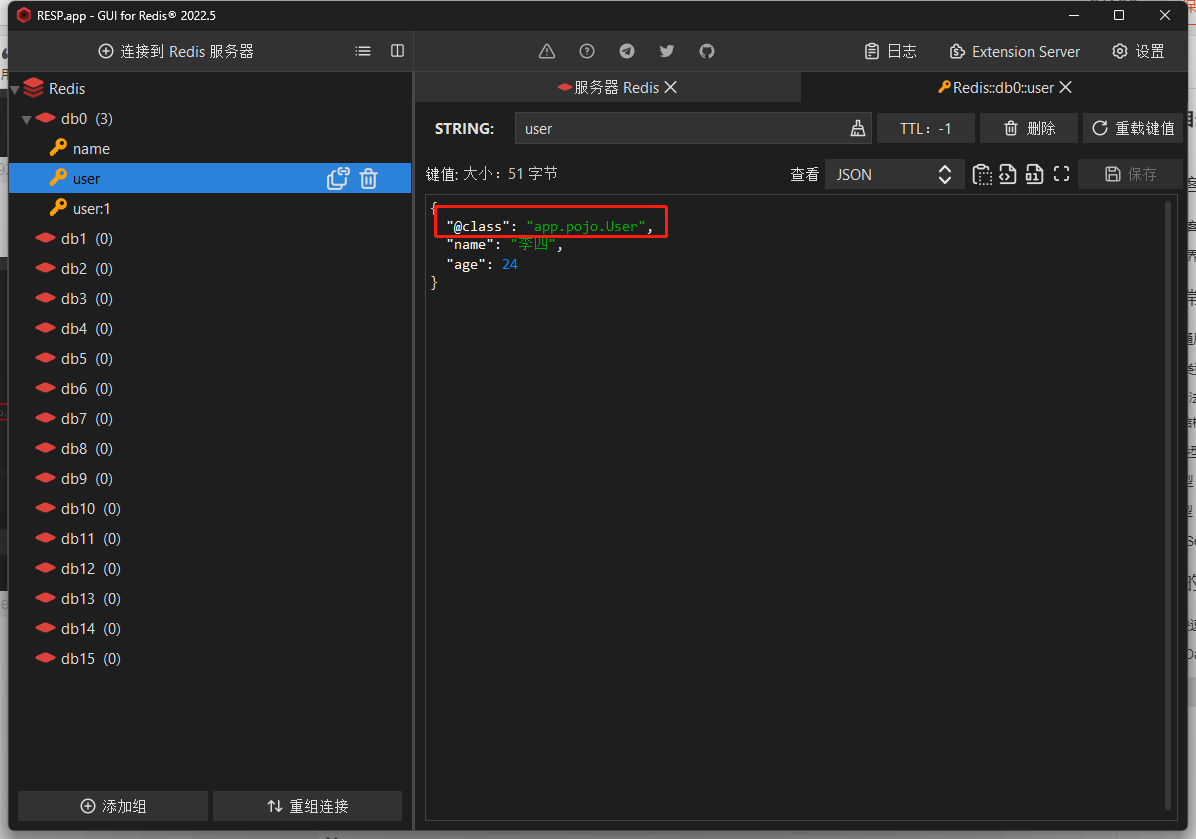
说明:对于普通字符串 “张三” 直接按照String类型存入到了redis中;而对于 User 对象则被 Jackson 序列化为了为了 json 类型的数据,为了能够方便通过 json 数据返回序列化出 User 对象还会多存入一条属性 "@class": "app.pojo.User"。然而这样虽然反序列化方便了,但是数据量堆叠起来之后会给redis带了额外的内存开销
StringRedisTemplate 使用String序列化器
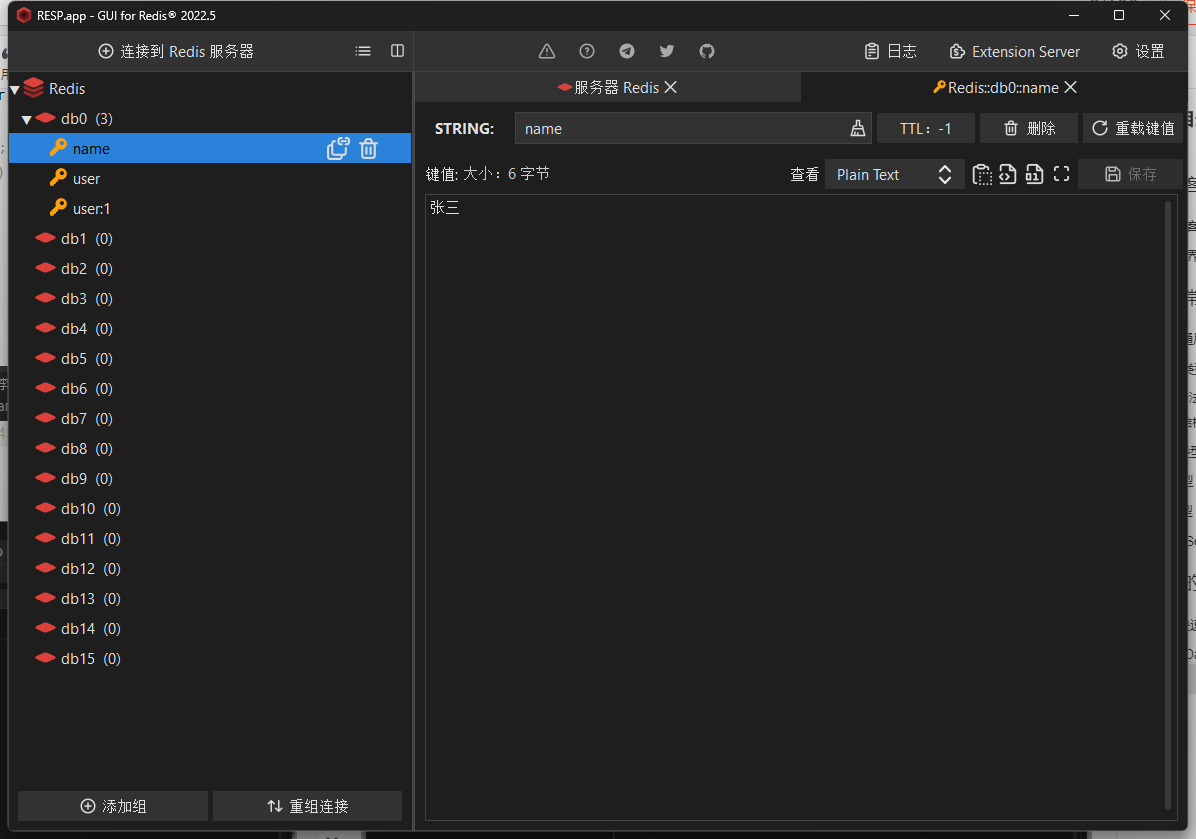
因此为了节省内存,一般并不会使用JSON序列化器,而是统一使用String序列化器,要求之存储String类型的key和value。当需要的时候在手动序列化或反序列化。

主要利用jackson的 ObjectMapper 类来实现手动的序列化和反序列化而不是通过Redis自带的JSON序列化工具
读写String
package app;import app.pojo.User;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.StringRedisTemplate;@SpringBootTest
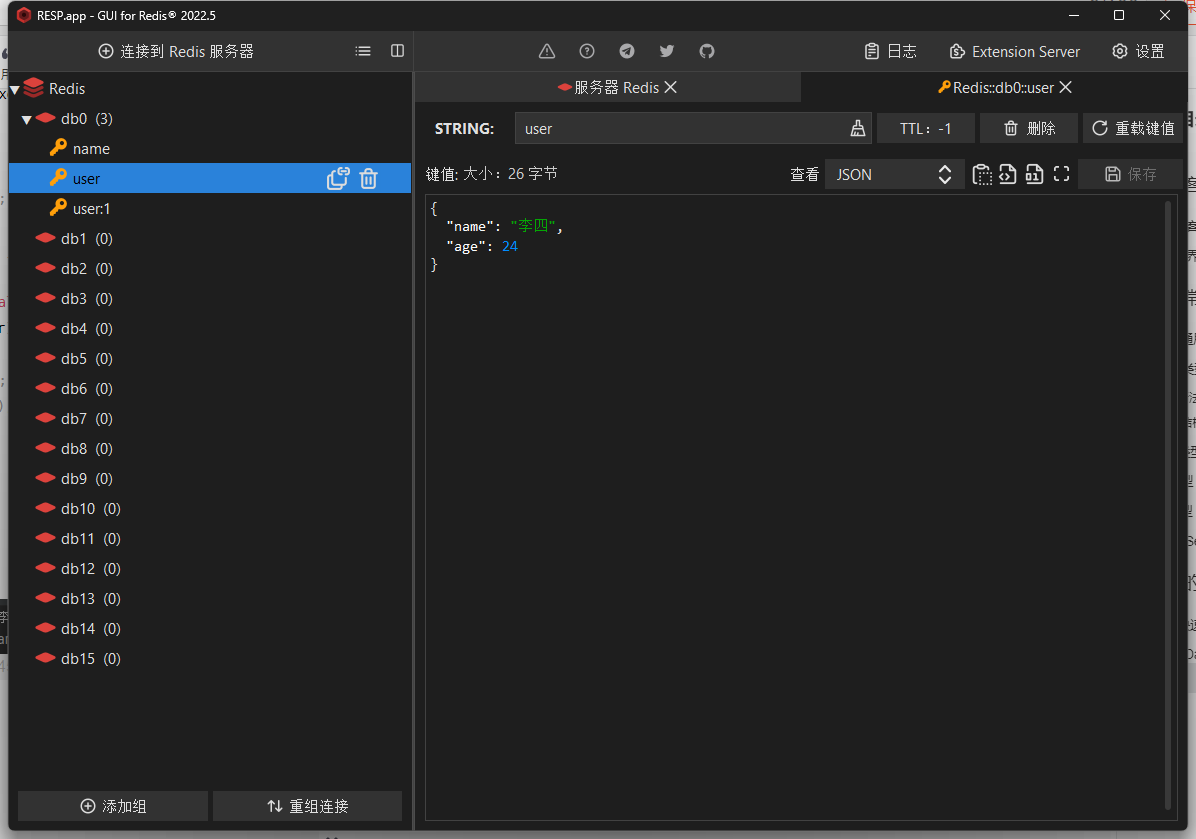
public class TestStringRedisTemplate {private StringRedisTemplate stringRedisTemplate;private static final ObjectMapper mapper = new ObjectMapper();@Autowiredpublic TestStringRedisTemplate(StringRedisTemplate stringRedisTemplate) {this.stringRedisTemplate = stringRedisTemplate;}@Testpublic void testString() {// 写入 String 数据stringRedisTemplate.opsForValue().set("name", "张三");// 读取 String 数据String name = stringRedisTemplate.opsForValue().get("name");System.out.println(name);}@Testpublic void testSaveUser() throws JsonProcessingException {// 创建对象User user = new User("李四", 24);// 手动序列化String json = mapper.writeValueAsString(user);// 写入 User 数据stringRedisTemplate.opsForValue().set("user", json);// 读取 User 数据String jsonUser = stringRedisTemplate.opsForValue().get("user");System.out.println("redis读取结果: " + jsonUser);// 手动反序列化user = mapper.readValue(jsonUser, User.class);System.out.println("jsonUser反序列化: " + user);}
}会发现Redis在存储的时候已经消除掉多余的数据

读写Hash
在处理 Hash 类型的时候,语法hset有些不同,更偏向于 Java 语法 put
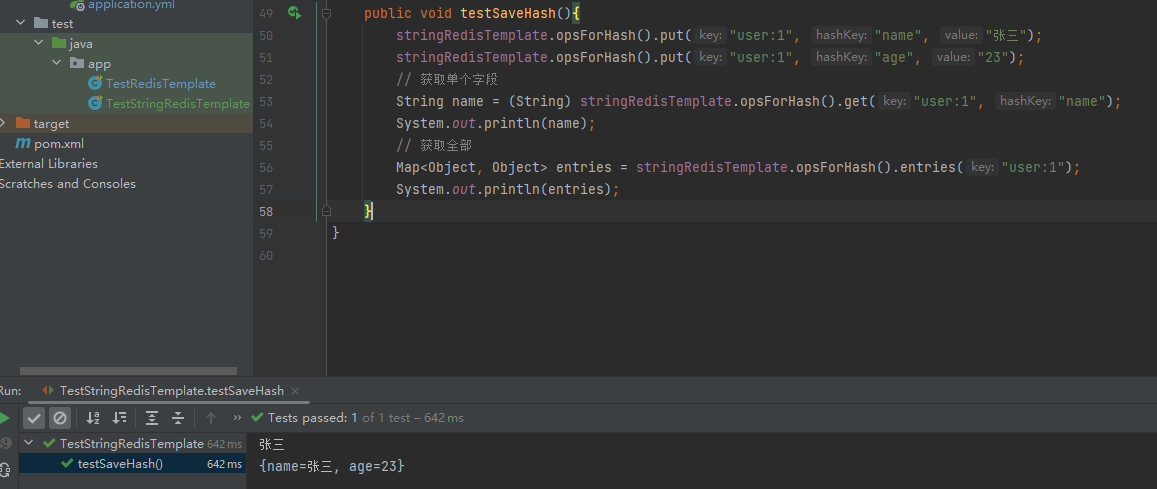
@Test
public void testSaveHash(){stringRedisTemplate.opsForHash().put("user:1", "name", "张三");stringRedisTemplate.opsForHash().put("user:1", "age", "23");// 获取单个字段String name = (String) stringRedisTemplate.opsForHash().get("user:1", "name");System.out.println(name);// 获取全部Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:1");System.out.println(entries);
}
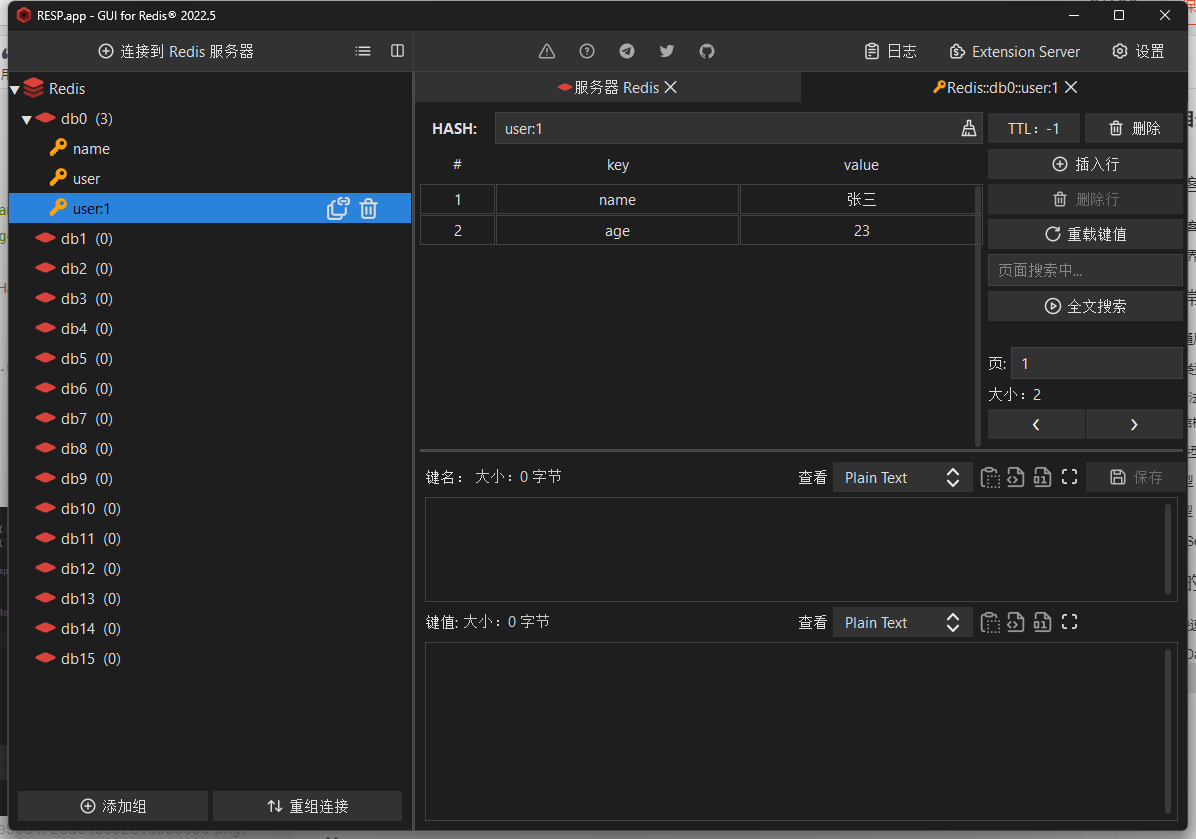
总结
方案一
- 自定义
RedisTemplate - 修改
RedisTemplate序列化器为GenericJackson2JsonRedisSerializer
方案二
- 使用
StringRedisTemplate - json序列化处理之后再写入redis
- 读取完redis之后再json反序列化成对象