1. JVM内存区域划分
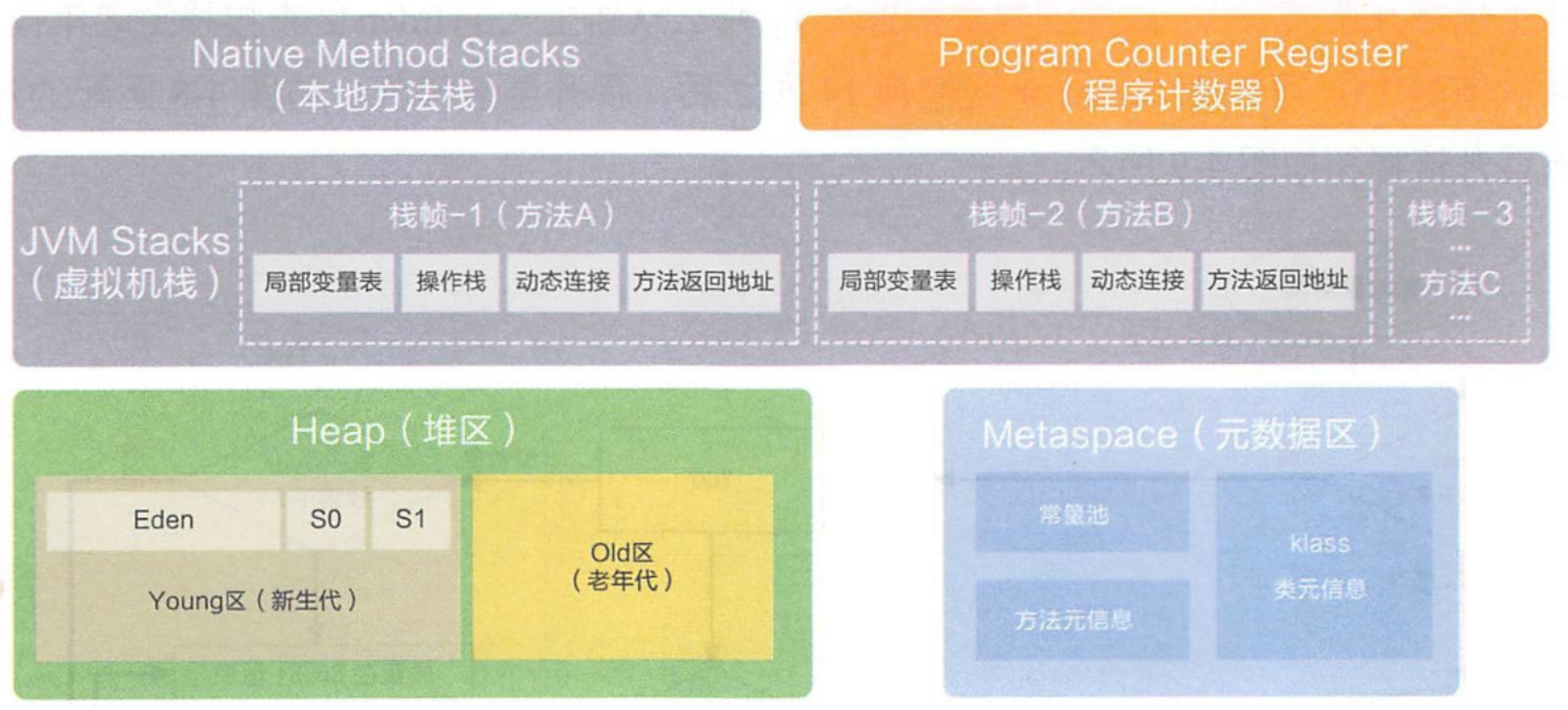
jvm在启动的时候,会申请到一整个很大的内存区域。整个一大块区域,不太好用。为了更方便使用,把整个区域隔成了很多区域,每个区域都有不同的作用。
本地方法栈
此处提到的栈和数据结构中的栈不是一个东西,数据结构中的栈是一个通用的,更广泛的概念。此处谈到的栈是JVM中的一个特定的内存空间。
native就表示JVM内部的C++代码。这块区间是为了给调用native方法(JVM内部的方法)准备的栈空间,存储的是native方法方法之间的调用关系。
虚拟机栈
JVM虚拟机栈存储的是方法之间的调用关系。
整个栈空间内部,可以认为包含很多个元素(每个元素代表一个方法),这里的每个元素成为是一个"栈帧"。这一个栈帧里包含这个方法的入口地址,方法的参数,返回地址,局部变量……
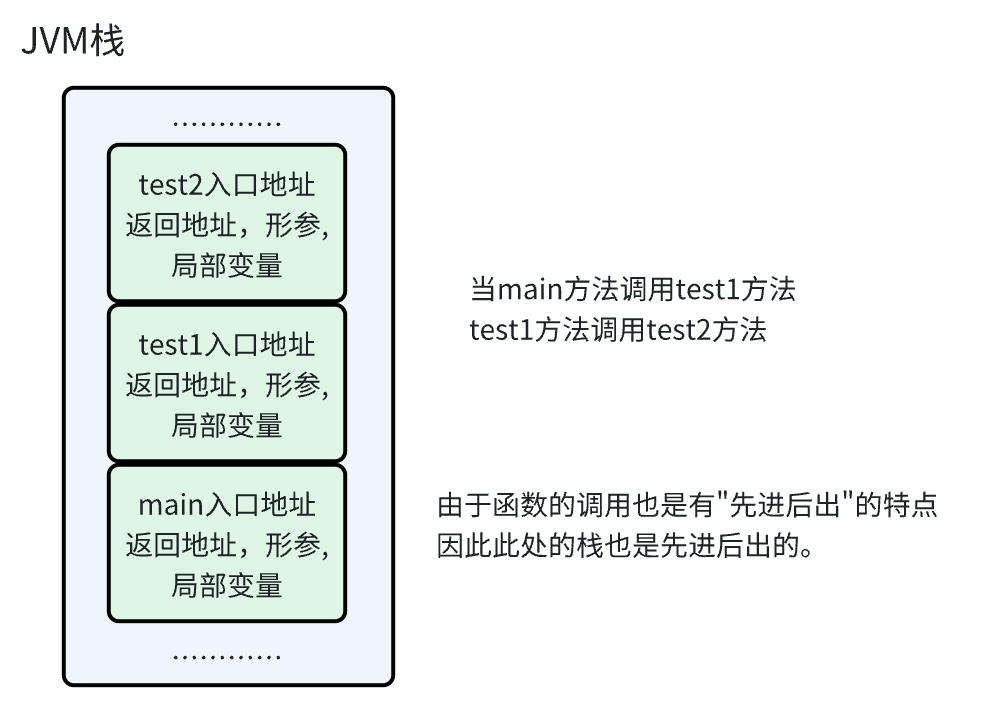
线程是一个独立的执行流。这个栈空间,有很多个,每个线程都有一个,有的地方说是线程私有的,这个私有是每个线程有一份,并不是栈空间中的数据只能本线程访问。
程序计数器(线程私有)
记录当前线程执行到哪个指令了,是很小的一块内存空间存储一个地址。是每个线程都有一份的。
堆区(线程共享)
堆是整个JVM空间最大的区域。new出来的对象都在堆上。类的成员变量也在堆上。堆是整个进程只有一份,栈是每个线程都有一份,一个进程有N个。
元数据区(方法区)
在java8之前叫做方法区,从java8开始改名字叫元数据区。类对象,常量,常量池(jdk8新增),静态成员,即时编译器编译后的代码等数据都在这这个区域中。这块区域一个进程只有这一块,多个进程共用这一块。
主要考点
给你一段代码,问你某个变量是在哪个区域上的?
原则:
- 普通局部变量在 栈
- 普通成员变量在 堆
- 静态成员变量在 方法区/元数据区。
2. JVM类加载机制
类加载准确的来说就是.class文件,从文件(硬盘)被加载到内存中(元数据区)的过程。

类加载的过程
类加载的过程就是类的生命周期前5个阶段,加载,验证,准备,解析,初始化。
加载:把 .class文件找到,读取文件内容。
验证:根据JVM虚拟机规范,检查.class文件的格式是否符合要求。
准备:给类对象分配内存空间(此时内存全初始化为0) => 静态成员变量也就是设为0值了。
解析:针对字符串常量进行初始化,把符号引用转为直接引用。
- 字符串常量,得有一块内存空间,存这个字符的实际内容。还得有一个引用,来保存这个内存空间的起始地址。
- 符号引用:在类加载之前,字符串常量此时处在.class文件中,此时这个”引用“记录的并非是字符串真正的地址,而是它在文件中的"偏移量“这个东西。(或者是个占位符)
- 直接引用:类加载之后,才真正把这个字符串常量给放到内存中。此时 才有”内存地址“,这个引用才能被真正的赋值成指定的内存地址。
初始化:真正针对类对象里面的内容进行初始化,加载父类,执行静态代码块中的代码……
类加载的时机
不是java一运行就把所有的类都加载了。而是真正用到才加载(懒汉模式)
- 构造 类 的实例
- 调用这个类的 静态方法/使用静态属性
- 加载子类,就会先加载其父类
用到了才加载,一旦加载之后,后续使用就不必重复加载了。
双亲委派模型
加载:把 .class文件找到,读取文件内容。
双亲委派模型描述的就是这个加载找到.class文件的基本过程
JVM默认提供了三个类加载器:
-
启动类加载器 (Bootstrap Class Loader):负责加载标准库中的类(java规范提供的那些类)
-
扩展类加载器(Extension Class Loader):负责加载JVM扩展库中的类 (除了规范外,由实现JVM的厂商/组织,提供额外的功能)
-
应用程序类加载器(Application Class Loader):负责加载用户提供的第三方库/用户项目代码中的类
上面三个类加载器存在“父子关系”。不是父类子类,相当于每个Class Loader有一个parent属性,指向自己的父类加载器
上述类加载器如何配合工作的?
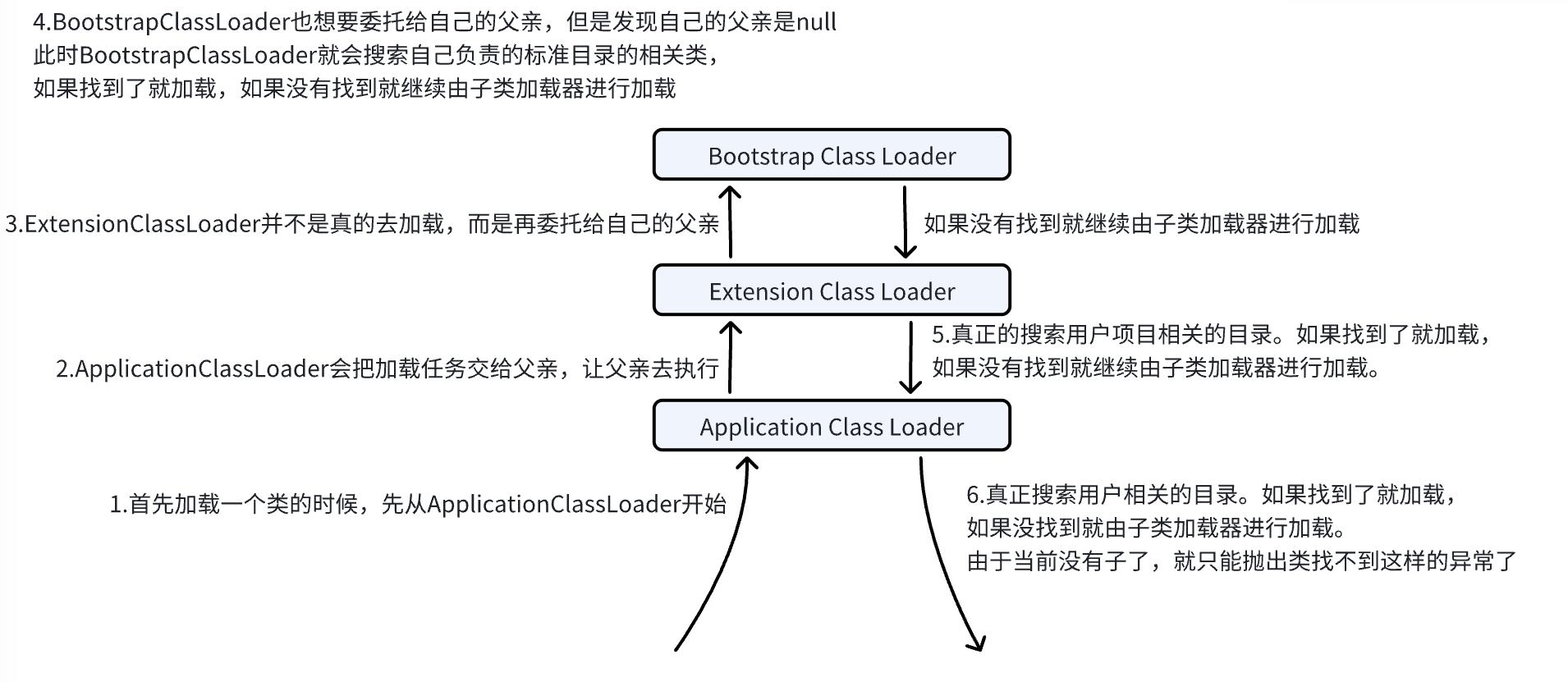
上面的这个顺序是由于JVM内部代码是按着“递归”的方式来实现的。
这个顺序主要目的是为了保障Bootstrap能够先加载,Application能够后加载。避免用户自己创建的类引起不必要的bug。假设用户自己代码中写了和标准款中名称相同的类,不会执行用户自己的类,会执行标准库中的类。这样就能保障JVM已有的代码不会出现混乱,最多就是用户自己写的代码不生效罢了。
类加载器用户可以用户自己定义的。自己定义的类加载器,可以加入到上述流程中,就可以搭配现有的类加载器配合使用了。
主要考点
- 类加载的整体流程
- 类加载的时机
- 双亲委派模型是怎么回事
破坏双亲委派模型
自己写的类加载器,可以去遵守也可以不去遵守,主要看需求。Tomcat去加载webapp这里的单独类加载器,不遵守双亲委派模型
3. JVM垃圾回收机制(GC)
垃圾:指的是不再使用的内存
垃圾回收:把不再使用的内存帮我们自动释放掉
栈上的内存空间使跟着方法走的,调用一个方法,就会创建栈帧。方法执行结束了,这个栈帧就销毁了。不需要进行垃圾回收机制。
元数据区是存放一些静态成员,常量和类对象的不需要 去进行垃圾回收,程序技术器空间太小有专门的作用没必要进行垃圾回收。
**垃圾回收机制针对的是堆区。**堆区上的内存的生命周期比较长,不像栈空间会随着方法的执行结束栈帧会自动的释放。堆默认不能自动释放。
不能自动释放会导致 一个严重的问题内存泄漏。如果内存一直占着不用,又不释放,就会导致剩余空间越来越少,进一步导致后续的内存申请失败。在自己电脑上的进行还好,进程一关闭就会全部释放。但是7*24运行的服务器最害怕这个。
GC是最主流的一种垃圾回收方式。
- GC好处:非常省心,让程序员写代码简单点,不容易出错
- GC坏处:需要消额外的系统资源,也有额外的性能开销。
GC有一个比较关键性的问题,SWT(stop the world)问题.
如果有时候,内存中的垃圾已经很多了,此时触发一次 GC 操作。开销可能非常大,大到可能就把系统资源吃了很多。另一方面 GC 回收垃圾的时候可能会涉及到一些 锁操作,导致业务代码无法正常执行。会造成一些卡顿,这样的卡顿,极端情况下,可能是出现几十毫秒甚至上百毫秒。
GC 是以"对象”为基本单位, 进行回收的。而不是字节。
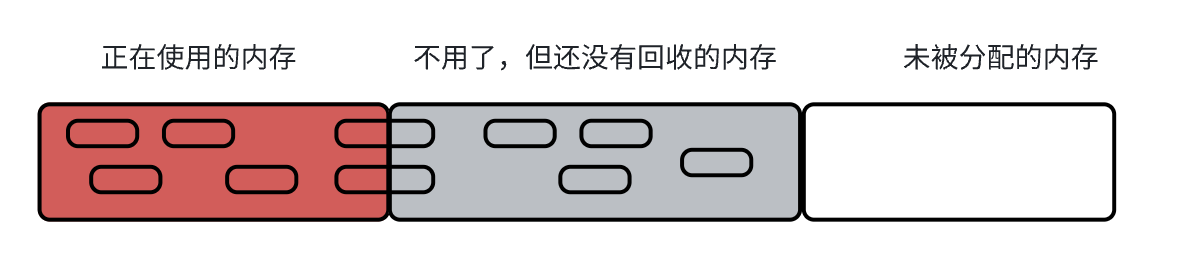
GC 回收的是,整个对象都不再使用的情况。而一部分使用,一部分不使用的对象,暂先不回收。一个对象,里面有很多属性,可能其中 10 个属性后面要用,10个属性后面再也不用了,这种情况是不能够进行回收的。这样设定的原因是“简单”。
GC的实际工作过程:
- 1.找到垃圾/判定垃圾.(哪个对象是垃圾,哪个不是? 哪个对象以后一定不用了? 哪个对象后面还可能使用?)
- 2.再进行对象的释放
1. 判定垃圾
关键思路, 抓住这个对象,看看它到底有没有“引用”指向它。
Java 中,使用对象,只有这一条路, 通过引用 来使用。如果一个对象,有引用指向它,就可能被使用到。如果一个对象,没有引用指向了,就不会再被使用了。
1. 引用计数[不是java中的做法]
这个方法是python和php的做法。
问题是: 谈谈 垃圾回收 中的如何判定对象是垃圾,此时你可以说引用计数法。
问题是: 谈谈 java 的垃圾回收中如何判定对象是垃圾。这个时候你再说引用计数就不合适了
给每个对象分配了一个计数器(整数)。每次创建一个引用指向该对象,计数器就 + 1。每次该引用被销毁了,计数器就 - 1。
{ListNode t = new ListNode();//ListNode对象的引用计数1ListNode t2 = t;//t2也指向了t,引用计数2ListNode t3 = t;//引用计数是3
}
//大括号结束,上述三个引用超出作用域,失效,此时引用计数就是0了此时 new ListNode() 对象就是 垃圾了
这个办法简单有效,但是 java 没有使用,主要有以下两点原因。
-
内存空间浪费的多(利用率低)
每个对象都要分配一个计数器,如果按 4 个字节算的代码中的对象非常少,无所谓。如果对象特别多了,占用的额外空间就会很多.尤其是每个对象都比较小的情况。一个对象体积 1k,此时,多 4 个字节, 无所谓。但是一个对象体积是 4字节,此时多 4 个字节,相当于体积扩大 一倍。
-
存在循环引用的问题
class Test {Test t = null; } Test a = new Test();// 1号对象,引用计数是 1 Test b = new Test();// 2 号对象,引用计数也是 1 a.t = b // a.t 也指向 2 号对象,2 号对象引用计数是2了 b.t = a // b.t 也指向 1 号对象了,1 号对象引用计数也是 2 了接下来,如果 a 和 b 引用销毁,此时 1 号对象和 2 号对象引用计数都 -1,但是结果都还是 1,不是0。但是虽然不是 0,不能释放内存,但是实际上这俩对象已经没有办法被访问到了。Python/PHP 使用用计数,需要搭配其他的机制,来避免循环引用。
此时没有其他途径能找到 1 或者 2 了此时这俩东西就是“垃圾"。但是由于引用计数 不是 0。还不能释放内存
2. 可达性分析[Java语言的做法]
Java 中的对象,都是通过引用来指向并访问的。经常,是一个引用指向一个对象,这个对象里的成员,又指向别的对象。
class TreeNode {int value;TreeNode left;TreeNode right;//这里也可以有其他别的类型的属性
}
TreeNode root = new TreeNode();
root.left = ……
整个 Java 中所有的对象,就通过类似于上述的关系。通过这种 链式/树形 结构,整体给串起来。
可达性分析,就是把所有这些对象被组织的结构视为是树。就从树根节点出发,遍历树,所有能被访问到的对象,标记成**“可达”**(不能被访问到的,就是不可达).
JVM 自己有一个所有对象的名单,通过上述遍历,把可达的标记出来了。剩下的不可达的就可以作为垃圾进行回收了。
可达性分析需要进行类似于“树遍历”这个操作,相比于引用计数来说肯定要更慢一些的。但是速度慢,没关系.上述可达性分析遍历操作,并不需要一直执行.只需要每隔一段时间,分析一遍 就可以了。
进行可达性分析遍历的起点,称为 GCroots。GCroots是可能会是:
- 栈上的局部变量
- 常量池中的对象
- 静态成员变量
一个代码中有很多这样的起点把每个起点都往下遍历一遍,就完成了一次扫描过程。
2. 垃圾清理
1. 标记清除法
发现谁是垃圾就直接释放掉
标记清除法:简单效率高。但是会产生内存碎片问题。被释放的空闲空间,是零散的,不是连续的。
申请内存要求的是连续空间。总的空闲空间可能很大,但是每一个具体的空间都很小,可能导致申请大一点内存的时候就失败了。 例如,总的空闲空间是 10K,分成 1K 一个一共10个。此时如果申请 2K 内存, 就会申请失败了。
2. 复制算法
复制算法:把"不是垃圾”的对象复制到另外一半,然后把整个空间删除掉。每次触发复制算法,都是向另外一侧进行复制,内存中的数据拷贝过去。
复制算法解决了内存碎片化的问题,但是又引出了新的问题:
-
空间利用率低
-
如果要是垃圾少,有效对象多,复制成本就比较大了。
3. 标记整理
类似于顺序表删除中间元素,会有元素搬运的操作。
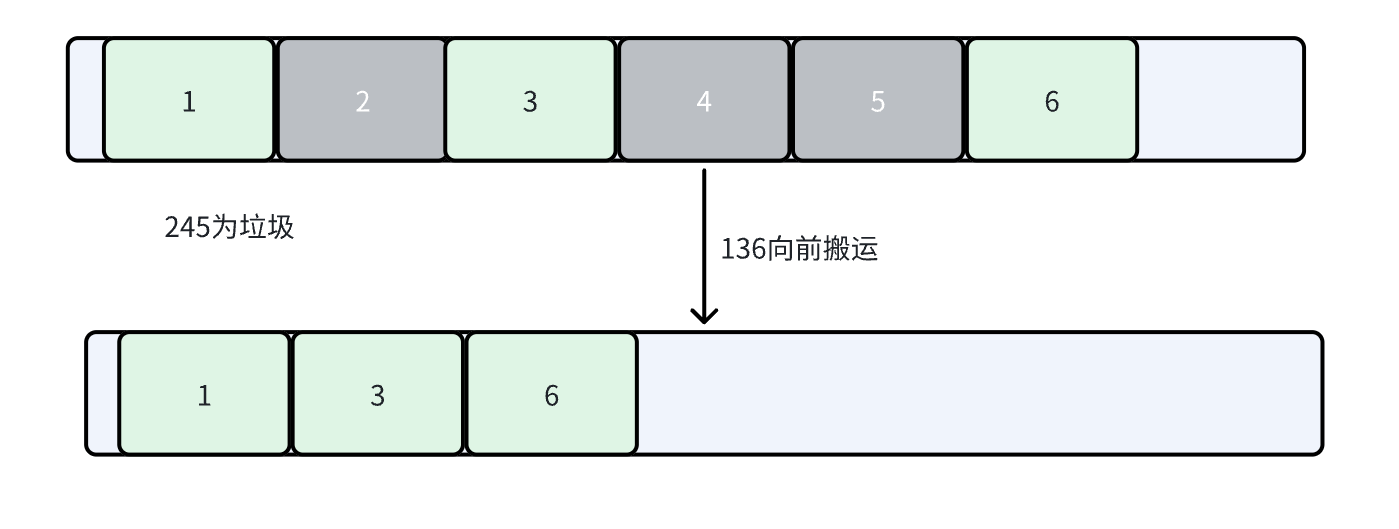
优点:保证了空间利用率,同时也解决了内存碎片问题
缺点:效率也不高,如果要搬运的空间比较大,此时开销也很大
4. 分代回收
基于上述这些基本策略, 搞了一个复合策略“分代回收“。把垃圾回收,分成不同的场景,不同场景有不同算法,各展所长。
分带基于一个经验规律:如果一个东西,存在的时间比较长了,那么大概率还会继续的长时间持续存在下去。(要没早就没了,既然存在,肯定有点东西)
比如 C 语言,诞生于 197x,现在已经存在 50 年了。50 年前,流行的编程语言也有很多别的。但是现在,仍然活跃的,也就是 C了。因此认为 C 语言有点东西, 我们就认为,它还能再继续存在 50 年。
上述规律,对于 Java 的对象也是有效的。(是有一系列的实验和论证过程)
java 的对象要么就是生命周期特别短要么就是特别长。根据生命周期的长短,分别使用不同的算法。给对象引入一个概念:年龄(单位不是 年而是 过 GC 的轮次)。年龄越大,这个对象存在的时间就越久。
经过了这一轮可达性分析的遍历,发现这个对象还不是垃圾这就是"熬过一轮 GC"
堆, 划分成一系列区域 :
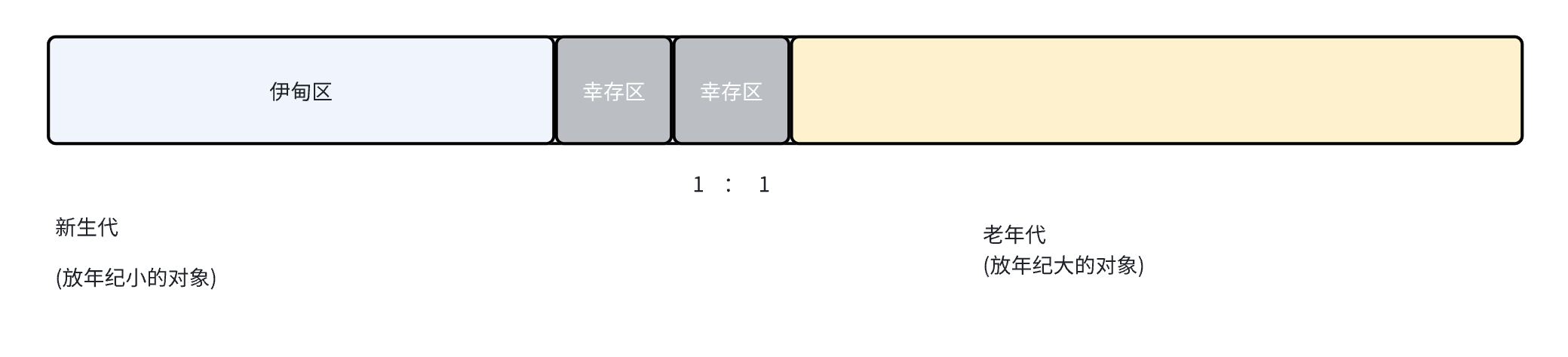
刚 new 出来的,年龄是 0 的对象,放到伊甸区.(出自圣经,上帝在伊甸园造小人)。过一轮 GC,对象就要被放到 幸存区了。虽然看起来 幸存区很小,伊甸区很大,一般够放。[根据上述经验规律,大部分的 java 中的对象都是“朝生夕死”生命周期非常短]
伊甸区 => 幸存区 :复制算法
幸存区之后,也要周期性的接受 GC 的考验。如果变成垃圾,就要被释放。如果不是垃圾,拷贝到另外一个幸存区、(这俩幸存区同一时刻只用一个),在两者之间来回拷贝(复制算法)。
如果这个对象已经再两个幸存区中来回拷贝很多次了。这个时候就要进入老年代了。老年代都是年纪大的对象.生命周期普遍更长针对老年代,也要周期性 GC 扫描但是频率更低了。如果老年代的对象是垃圾了,使用标记整理的方式进行释放。