1、大数据引擎
大数据引擎是用于处理大规模数据的软件系统,
常用的大数据引擎包括Hadoop、Spark、Hive、Pig、Flink、Storm等。
其中,Hive是一种基于Hadoop的数据仓库工具,可以将结构化的数据映射到Hadoop的分布式文件系统上,并提供类SQL查询功能。
与传统数据库相比,Hive的优势在于能够处理海量数据,并且可以在廉价的硬件上运行。同时,Hive的查询语言与SQL相似,易于使用和学习。
与传统数据库相比,数据引擎的区别在于:
1.数据量:传统数据库通常处理的是小规模数据,而大数据引擎可以处理海量数据。
2.处理方式:传统数据库采用事务处理的方式,而大数据引擎采用批处理或流处理的方式。
3.硬件要求:传统数据库需要高性能的硬件支持,而大数据引擎可以在廉价的硬件上运行。
4.数据类型:传统数据库通常处理结构化数据,而大数据引擎可以处理结构化、半结构化和非结构化数据。
总之,大数据引擎是为了处理海量数据而设计的软件系统,与传统数据库相比具有更高的数据处理能力和更灵活的数据处理方式。
数据处理方式对比
- 批处理:批处理是一种数据处理方式,它将一批数据作为一个整体进行处理,通常是离线处理。批处理适合处理大量数据,但处理速度较慢,适用于需要全量数据分析的场景,例如数据仓库、离线计算等。
- 流处理:流处理是一种实时数据处理方式,它将数据流作为输入,实时处理并输出结果。流处理适合处理实时数据,处理速度快,适用于需要实时计算的场景,例如实时监控、实时推荐等。
数据类型对比:
- 半结构化数据:半结构化数据是介于结构化数据和非结构化数据之间的一种数据类型,它具有一定的结构,但不像结构化数据那样严格定义。半结构化数据通常采用XML、JSON、YAML等格式存储,例如网页、日志等。
- 非结构化数据:非结构化数据是指没有固定结构的数据,例如文本、图片、音频、视频等。非结构化数据通常难以通过传统的关系型数据库进行处理,需要借助大数据技术进行处理和分析。
Hadoop、Hive和Spark对比
虽然都是大数据处理的开源框架,它们有着不同的特点和用途。
- Hadoop是一个分布式计算框架,主要用于存储和处理大规模数据集。它包括HDFS(Hadoop分布式文件系统)和MapReduce两个主要组件,可以实现分布式存储和计算,以及高可靠性和容错性。
- Hive是基于Hadoop的数据仓库工具,它提供了类SQL查询功能,可以将结构化的数据映射到Hadoop的分布式文件系统上。Hive通过将SQL语句转换为MapReduce任务来实现查询和分析,可以方便地进行数据处理和分析。
- Spark是一个**快速、通用、可扩展的大数据处理引擎,它支持批处理和流处理,**并提供了高级API,如Spark SQL、Spark Streaming、MLlib和GraphX等。Spark通过内存计算和RDD(弹性分布式数据集)来提高计算性能,可以处理更大规模的数据和更复杂的计算任务。
- 总体来说,Hadoop提供了分布式存储和计算的基础设施,Hive提供了类SQL查询功能,而Spark则提供了更高级的数据处理和分析功能。
- 它们可以相互配合使用,例如使用Hadoop作为底层存储和计算基础设施,使用Hive进行数据查询和分析,使用Spark进行更高级的数据处理和分析。
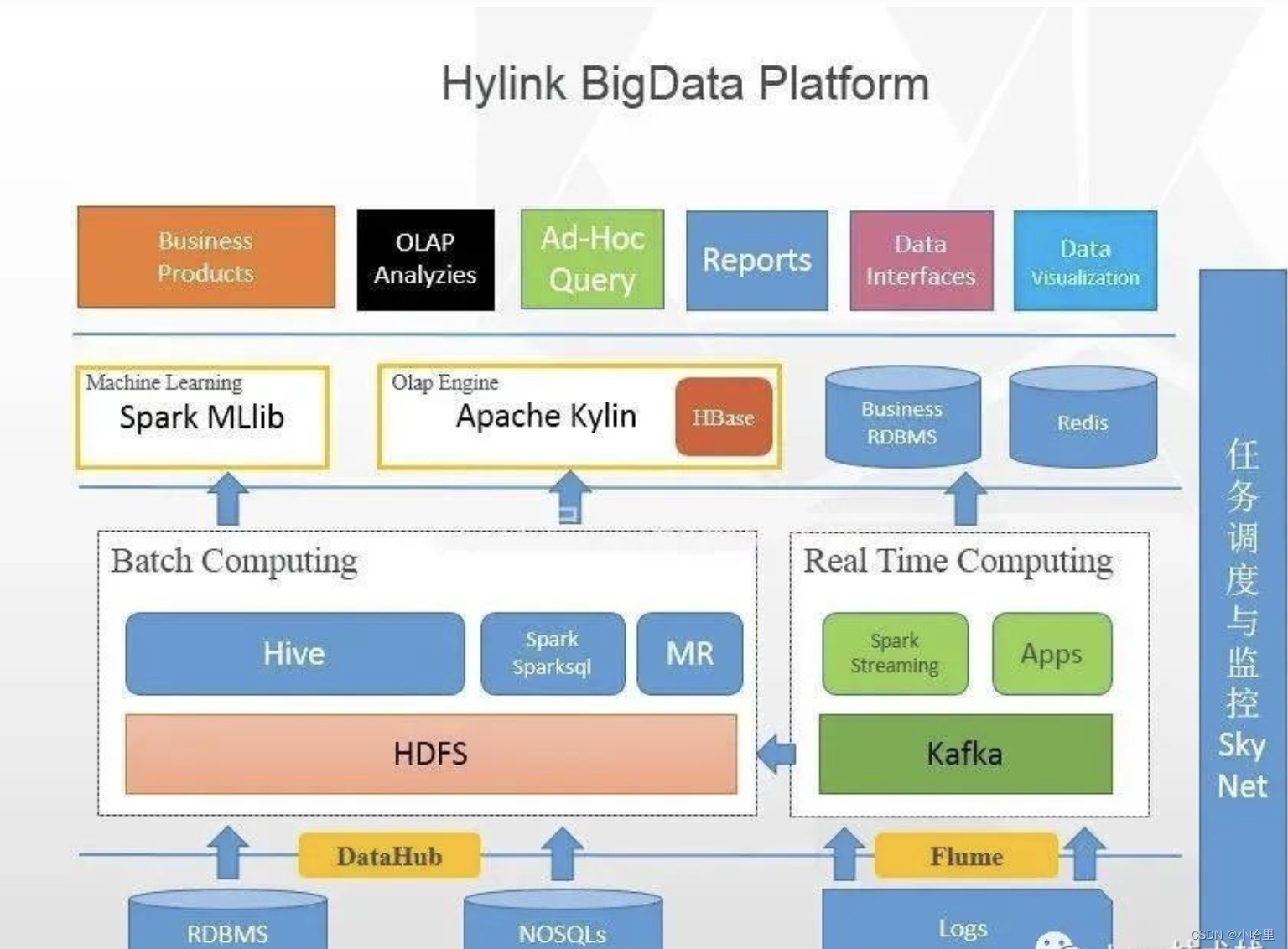
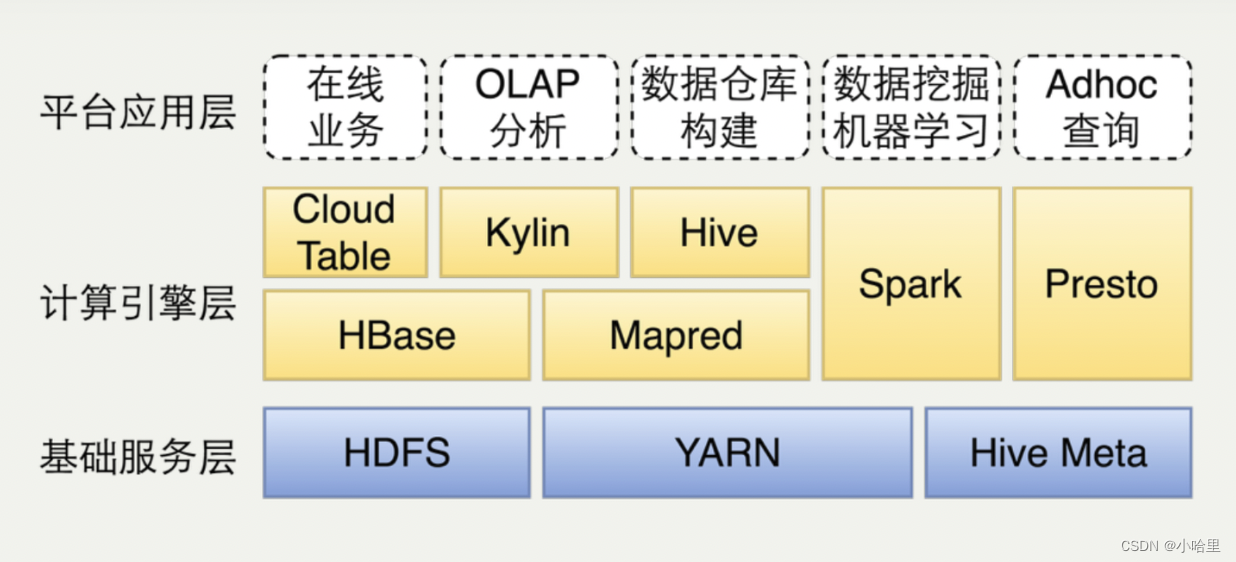
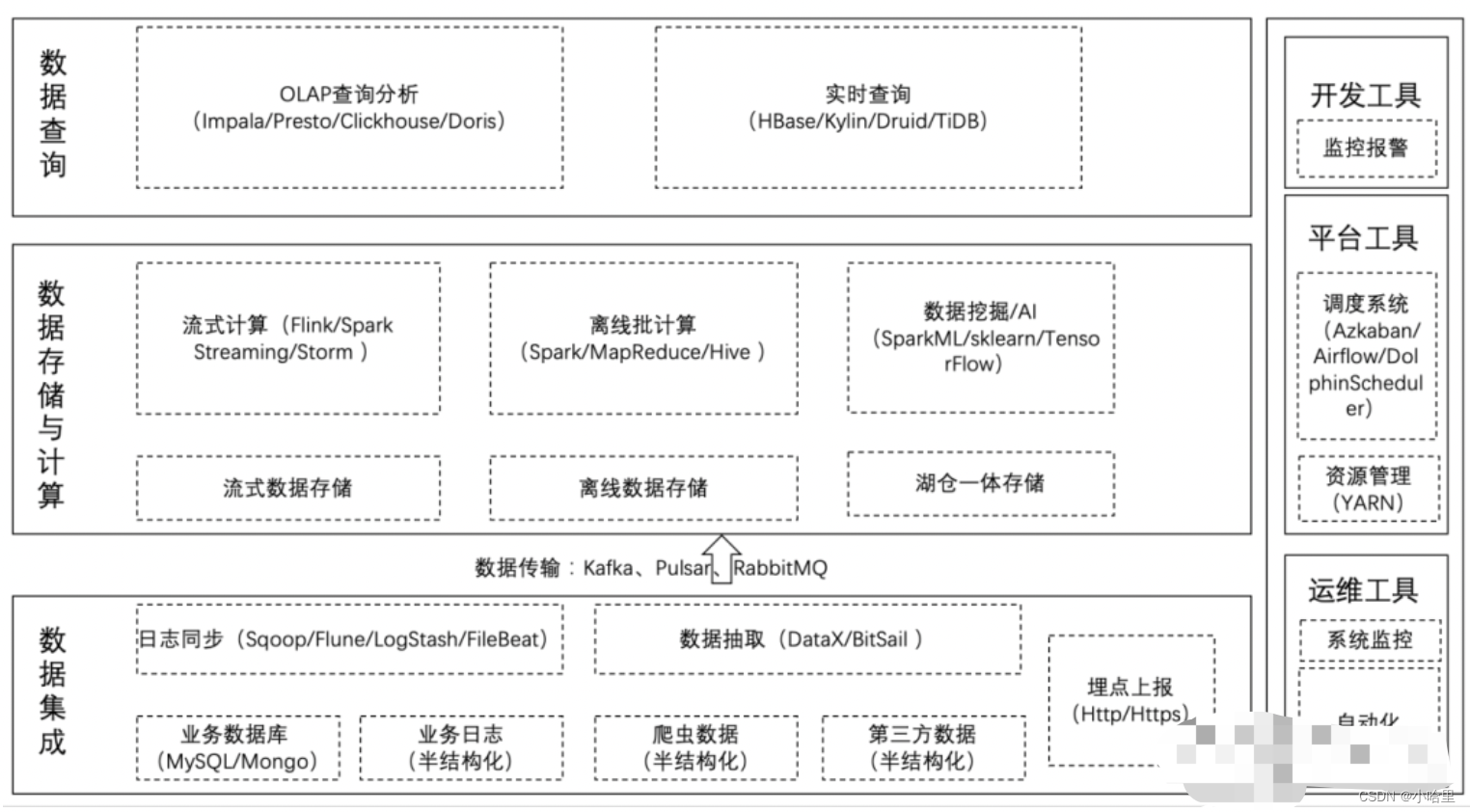
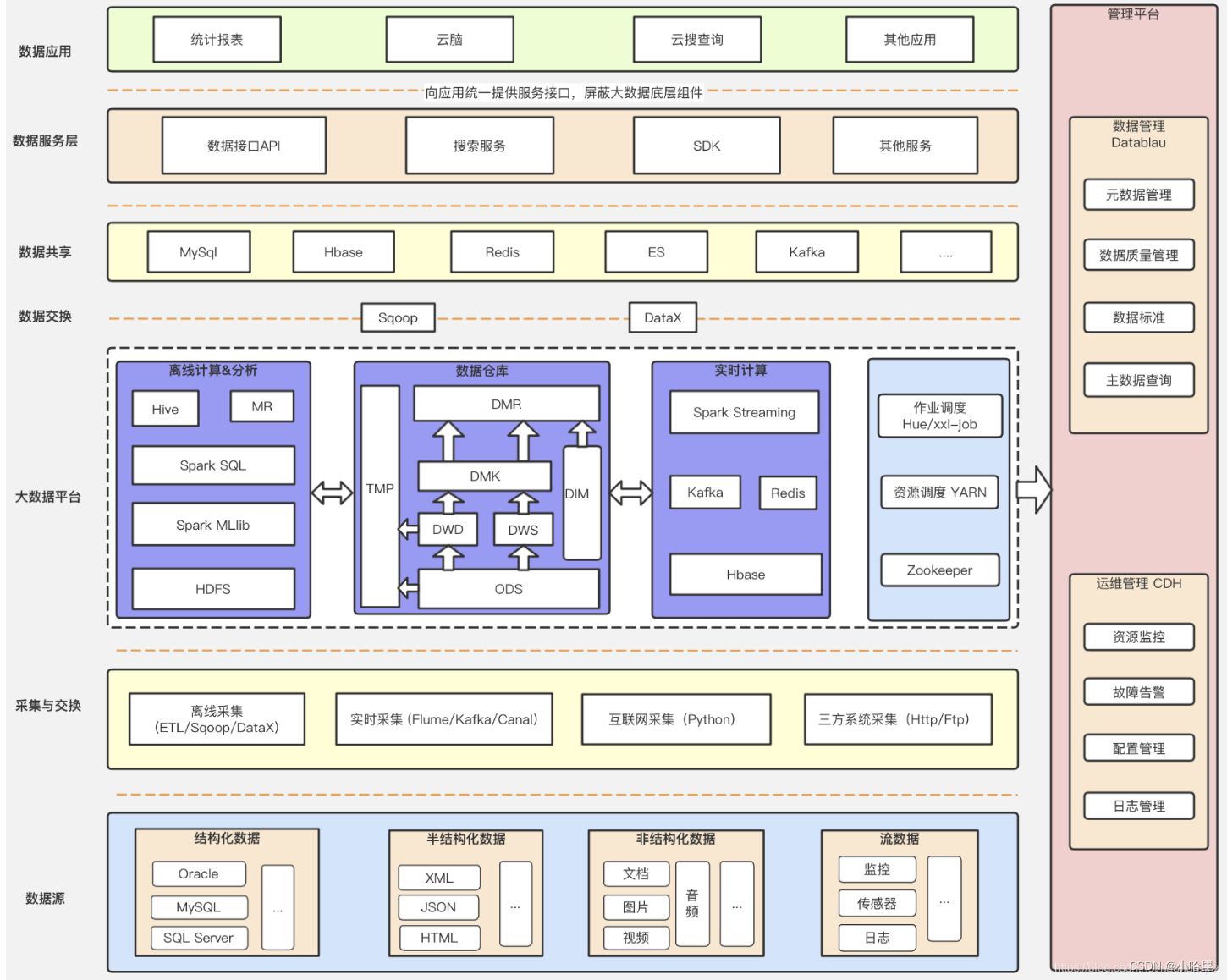
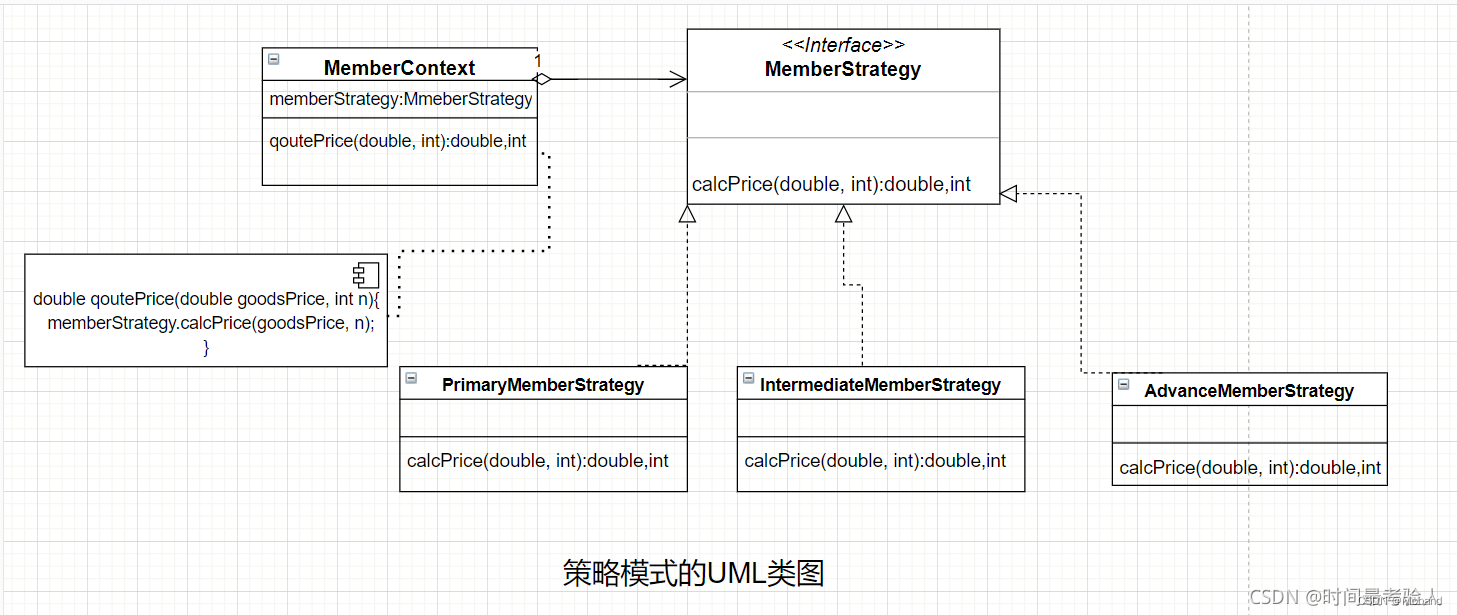
2、什么是Hive / THive
什么是Hive?
- Hive是一个基于Hadoop的数据仓库工具。
- 它提供了一个类似于SQL的查询语言,称为HiveQL,用于查询和分析大规模数据集。
- Hive将结构化数据映射到Hadoop的分布式文件系统和Hadoop的分布式处理引擎上,允许用户使用类似于SQL的语言查询数据,并将数据转换为其他格式,例如MapReduce任务。
- Hive引擎是一个基于Hadoop的数据仓库工具,它提供了一个类似于SQL的查询语言,称为HiveQL,用于查询和分析大规模数据集。
什么是THive?
- THive是一个开源的Hive JDBC驱动程序,它可以让用户使用任何支持JDBC的工具(例如Tableau,Excel等)连接到Hive。
- 因此,THive并不是一个数据仓库工具,而是一个Hive的JDBC驱动程序。
因此,Hive和THive是两个不同的东西,Hive是一个数据仓库工具,而THive是一个Hive的JDBC驱动程序。
Hive引擎分类
- 速度排名:THive on MapReduce < THive on Spark < Presto
- Hive可以使用两种不同的引擎:MapReduce和Tez。MapReduce是Hadoop的默认引擎,而Tez是一个更快的引擎,它使用了更高级别的优化技术。
- THive on MapReduce是THive的另一个变种,它使用了MapReduce作为计算引擎。MapReduce是Hadoop的默认计算引擎,它可以处理大规模数据集,但速度较慢。
- THive on Spark是THive的一个变种,它使用了Spark作为计算引擎。Spark是一个快速的分布式计算引擎,它可以在内存中进行计算,因此比MapReduce更快。THive on Spark可以提供更快的查询速度和更好的性能。
- Presto是一个分布式SQL查询引擎,它可以查询多个数据源,包括Hive、MySQL、PostgreSQL等。Presto的查询速度非常快,可以处理PB级别的数据。与Hive不同,Presto不需要将数据转换为MapReduce任务,因此可以提供更快的查询速度和更好的性能。
- 因此,Hive、THive on Spark、THive on MapReduce和Presto都是用于查询和分析大规模数据集的工具,但它们使用的计算引擎不同,因此在性能和查询速度方面也存在一定的差异。
3、数据存储: Mysql=>HDFS=>数仓
Mysql=>HDFS=>数仓
- 数仓有更强的数据处理能力,但是限定数据格式之类的要求
- Mysql轻量级,数据量少,但是格式和可定义的的功能多。
- Mysql和数仓都是结构化数据,HDFS是非结构化数据。
HDFS(Hadoop分布式文件系统)和MySQL是两种不同类型的数据存储系统,它们有以下区别:
- 数据类型:HDFS适合存储大规模的非结构化数据,如日志、图像、音频、视频等,而MySQL适合存储结构化数据,如表格数据。
- 存储方式:HDFS是一种分布式文件系统,数据被分割成多个块并存储在不同的服务器上,而MySQL是一种关系型数据库系统,数据被存储在表格中。
- 存储容量:HDFS可以存储海量数据,可以通过添加新的服务器来扩展存储容量,而MySQL存储容量相对较小,需要更高级的硬件支持才能扩展存储容量。
- 数据处理方式:HDFS采用批处理方式进行数据处理,适合离线数据处理和分析,而MySQL支持实时查询和更新,适合在线数据处理和交互式查询。
- 数据安全性:HDFS提供了数据冗余和备份机制,可以保证数据的高可靠性和容错性,而MySQL需要通过备份和复制等方式来保证数据的安全性。
总之,HDFS和MySQL是两种不同类型的数据存储系统,适用于不同的数据存储和处理场景。HDFS适合存储大规模的非结构化数据,如日志、图像、音频、视频等,而MySQL适合存储结构化数据,如表格数据。
数据仓库(Data Warehouse)是一种用于存储和管理企业数据的系统,它可以将不同来源的数据集成到一个统一的数据模型中,以便进行数据分析和决策支持。与HDFS和MySQL相比,数据仓库有以下区别:
-
数据类型:数据仓库通常存储结构化数据,如表格数据,而HDFS适合存储大规模的非结构化数据,如日志、图像、音频、视频等,MySQL则可以存储结构化数据和半结构化数据。
-
数据集成:数据仓库可以将不同来源的数据集成到一个统一的数据模型中,以便进行数据分析和决策支持,而HDFS和MySQL通常只能存储和处理单一来源的数据。
-
数据处理方式:数据仓库通常采用OLAP(联机分析处理)方式进行数据处理,支持复杂的多维分析和数据挖掘,而HDFS和MySQL通常采用OLTP(联机事务处理)方式进行数据处理,支持实时查询和更新。
-
存储容量:HDFS可以存储海量数据,可以通过添加新的服务器来扩展存储容量,MySQL存储容量相对较小,需要更高级的硬件支持才能扩展存储容量,而数据仓库也需要高性能的硬件支持来存储和处理大规模的数据。
总之,数据仓库、HDFS和MySQL都是不同类型的数据存储和处理系统,适用于不同的数据存储和处理场景。数据仓库适合存储和处理结构化数据,支持复杂的多维分析和数据挖掘,HDFS适合存储大规模的非结构化数据,MySQL适合存储结构化数据和半结构化数据。
将MySQL中的数据导出到HDFS,再将HDFS中的数据导入到数据仓库,中间的原理主要包括以下几个方面:
-
数据抽取:将MySQL中的数据抽取到HDFS中,通常采用Sqoop进行数据抽取。Sqoop通过MapReduce作业实现数据抽取,首先将数据划分为多个数据块,然后在每个数据块上运行MapReduce作业,将数据转换为Hadoop的输入格式并写入HDFS。
-
数据转换:将抽取的数据进行转换和清洗,使其符合数据仓库的数据模型和数据质量要求。通常采用ETL(Extract-Transform-Load)工具进行数据转换和清洗,如Apache Nifi、Talend等。ETL工具可以对数据进行格式转换、数据清洗、数据合并等操作,以便将数据转换为数据仓库需要的格式。
-
数据加载:将转换后的数据加载到数据仓库中,通常采用数据仓库的ETL工具进行数据加载,如ODI(Oracle Data Integrator)、Informatica等。ETL工具可以将转换后的数据加载到数据仓库中,并进行数据校验和质量控制,以保证数据的准确性和完整性。
-
数据建模:在数据仓库中进行数据建模,以便进行数据分析和决策支持。数据建模通常采用ER建模工具进行建模,如ERwin、PowerDesigner等。ER建模工具可以根据数据仓库的需求进行数据建模,包括实体、属性、关系等。
-
数据分析:在数据仓库中进行数据分析和决策支持,通常采用BI(Business Intelligence)工具进行数据分析和报表生成,如Tableau、QlikView等。BI工具可以从数据仓库中提取数据,并进行数据分析和可视化展示,以便进行决策支持和业务分析。
总之,将MySQL中的数据导出到HDFS,再将HDFS中的数据导入到数据仓库,需要进行数据抽取、转换、加载、建模和分析等多个步骤,其中涉及到多种技术和工具的应用,以实现数据的高效、准确和可靠的处理和分析。