-
基本信息
产品名称:ATS3.0
问题分类:编码问题
环境类型:环境无关
-
问题现象
11月1日上午华润DBA收到数据库磁盘空间告警,检查后发现skywalking连接的mysql数据库占用空间从之前一直是比较稳定的,但是10月31日开始激增,一天左右原来剩250G+的磁盘空间只剩下了50G左右。进一步排查发现数据主要集中在skywalking的segment表中。 -
问题原因
seata回滚一个数据库操作较多的事务,由于seata客户端的问题,没有正常关闭PrepareStatement最终触发了ORA-01000-超出打开游标的最大数问题(生产库游标单个session最大300),导致回滚失败。然后seata每秒都会再次触发重试,又因为是一个大事务,导致每秒都有大量的事务回滚的sql操作。因为我们安装了skywalking的oracle插件,程序调用oracle的请求也会被记录,最终导致大量的链路信息被记录到segment表中造成了skywalking的存储数据库空间暴增。 -
排查过程
4.1 紧急处置
1.先让客户删除了mysql库今天之前的binlog,释放出部分空间,否正剩余50G很可能几个小时候就会耗尽,释放后剩余空间回到了250G左右,有了比较充足的排查时间。
2.预案:如果空间持续上升,且还没找到原因的话可以尝试临时删除部分skywalking的数据,因为只是用于监控,不影响业务。或者暂时停止下skywalking。
4.2 定位skywalking的空间是被什么请求占用
1.segment表里的endpoint_id表示请求服务及地址的信息,根据这个字段分类排序可以判断一段时间主要是哪个请求占用了空间。
sql: select count(*) as total , endpoint_id from segment s where start_time > 1667286000000 group by endpoint_id order by total desc;start_time要根据查询的时间调整这个毫秒数


2. 发现主要是有两个请求触发的频率比较高
3. endponit_id下划线左边是服务名(最后的.1也要去掉才是服务名),右边是请求URL,查看skywalking源码,确定这串字符的编码规则,写了一个转换的逻辑new String(Base64.getDecoder().decode(待转换内容), StandardCharsets.UTF_8);
4. 转换后发现这两个请求分别是ntms-financing的Oracle/JDBI/PreparedStatement/executeQuery和Oracle/JDBI/PreparedStatement/executeUpdate
5. 发现都是数据库操作后去ELK查了下financing服务的日志发现有大量的数据库操作日志,都是seata回滚线程操作的,此时基本可以判断是seata不断尝试回滚事务产生的日志,接下来就需要具体是哪些事务回滚失败不停重试,以及回滚失败的原因。
4.3 确认为什么会触发大量的问题请求
触发大量请求的原因:
seata事务失败,如果能回滚成功,则会直接释放掉,如果回滚失败,则会一直尝试重试回滚,每1s重试一次,我们没有配置停止时间,所以会一直重试。回滚的时候会去做undo_log表的查询、根据undo_log表的数据做业务表的查询等操作,如果一个事务操作的数据量很大,那么每次回滚都会打印很多sql语句,也就会对skywalking记录的数据有影响了。
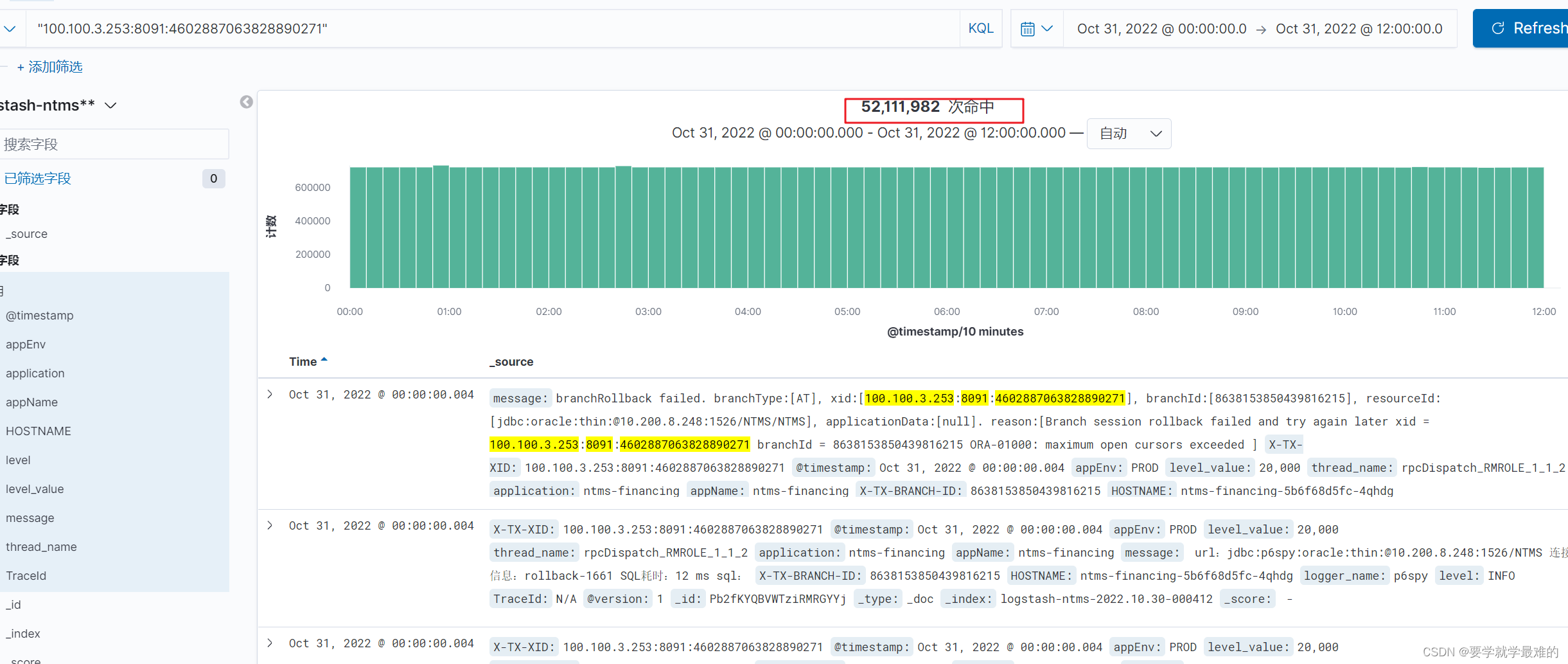
假设一个全局事务是插入1000条数据到表中,那么回滚的时候,会执行一次查询undo_log,对于每行数据,执行一次select for update,执行一次delete,共2001条sql。一次回滚正常要执行这么多sql,如果回滚失败了,过1s后还要再执行,可以看到数据量是很大的。一天之内回滚日志就有五千多万条:
查找回滚失败原因:
通过查看日志找到每次执行一堆回滚sql后都会有一个报错:

报错日志为”ORA-01000: maximum open cursors exceeded“,也就是说seata很可能因为这个问题导致数据无法回滚。
对这个异常的解释:oracle ORA-01000: maximum open cursors exceeded问题的解决方法-CSDN博客
简单地说就是conn.prepareStatement()会打开一个游标,如果循环里调用这段代码,并且没调用close方法的话,就有可能造成上面的问题。
一些命令:oracle怎么查询游标-Oracle-PHP中文网
# 查看当前打开的游标总数
select count(*) from v$open_cursor;
# 每个连接能打开的最大游标数
select value from v$parameter where name = 'open_cursors';
# 更改连接能开启的最大游标数(改成1000)alter system set open_cursors=1000 scope=both;定位问题:
通过条件"100.100.3.253:8091:4602887063828890271" and "error" 可以看到有一个异常日志,通过调用栈可以大概找到报错的地方

再结合上面的”branchRollback failed. branchType:“可以大概定位到报错位置。
在io.seata.rm.datasource.undo.AbstractUndoLogManager#undo这段代码的位置,是对当前事务分支做回滚的操作。先获取undo_log的中该分支的数据,做反序列化后可以得到执行的每条sql的undo_log。(一个本地事务每次执行sql都会生成一个SQLUndoLog,在连接最后提交时会把该本地事务操作的所有SQLUndoLog封装为BranchUndoLog,序列化到undo_log表中)
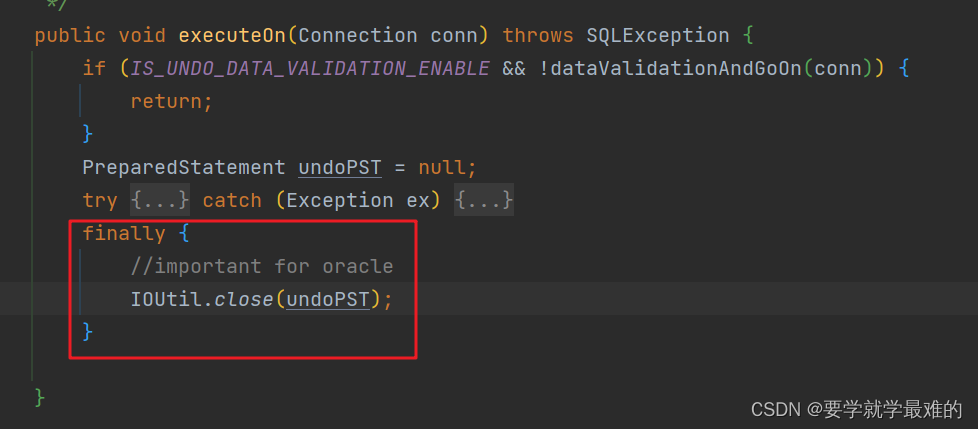
再遍历该BranchUndoLog的SQLUndoLog的list,对每一条SQLUndoLog执行io.seata.rm.datasource.undo.AbstractUndoExecutor#executeOn回滚操作。问题就出在这个方法
public void executeOn(Connection conn) throws SQLException {//dataValidationAndGoOn执行一下select xxx for update,对该数据加锁。if (IS_UNDO_DATA_VALIDATION_ENABLE && !dataValidationAndGoOn(conn)) {return;}PreparedStatement undoPST = null;try {String undoSQL = buildUndoSQL();//在这里开启一个游标undoPST = conn.prepareStatement(undoSQL);TableRecords undoRows = getUndoRows();for (Row undoRow : undoRows.getRows()) {ArrayList<Field> undoValues = new ArrayList<>();List<Field> pkValueList = getOrderedPkList(undoRows, undoRow, getDbType(conn));for (Field field : undoRow.getFields()) {if (field.getKeyType() != KeyType.PRIMARY_KEY) {undoValues.add(field);}}undoPrepare(undoPST, undoValues, pkValueList);//做undolog的回滚undoPST.executeUpdate();}} catch (Exception ex) {if (ex instanceof SQLException) {throw (SQLException) ex;} else {throw new SQLException(ex);}}//处理完并没有关闭游标
}看到该方法只开启了游标,并没有关闭。外面还有一个undo_log的循环,当BranchUndoLog的list过多时,会超过游标数量。
代码模拟:
public void add() {for (int i1 = 0; i1 < 10000; i1++) {TestPO testPO = new TestPO();testPO.setUrid("" + i1);testPO.setName("name" + i1);testPO.setAge(i1);testMapper.insert(testPO);}}@GlobalTransactionalpublic void update() {((TestService)AopContext.currentProxy()).doupdate();int i = 1/0;}@Transactionalpublic void doupdate(){for (int i1 = 0; i1 < 10000; i1++) {TestPO testPO = new TestPO();testPO.setUrid("" + i1);testPO.setName("name2" + i1);testPO.setAge(i1);testMapper.updateById(testPO);}}create table TSYS_TEST
(URID VARCHAR2(64) not nullconstraint TSYS_TEST_PKprimary key,NAME VARCHAR2(64),AGE NUMBER(38)
)
/执行完add后,再执行update,会报上面超过游标数量的问题。
该问题seata新版本已经更改。就是在上面的方法后面把statement关闭了。
现场的解决方案时先把游标数调成了3000,该事务可以正常回滚了,把资源都释放掉了。等下次xx发版的时候,再把这段逻辑加上。
现场的最大游标是300,也就是说每次失败大概会打印300(回滚条数)+300(select for update)+1(select from undo_log)条日志,一天要打印601*60*60*24=51,926,400 ,基本上就是上面所有命中次数了。所以该结论没什么问题。
-
解决方案
1.临时调大了生产oracle库的游标数,从300调整到了3000,因为游标数不够而一直重试的回滚操作回滚成功了,暂时解决了问题
2.seata client没有正常关闭PrepareStatement的问题已修复,等下下次华润升级的时候更新过去
3. seata事务没有正常结束的情况需要监控起来,不然只能等到引起问题才发现,如果此时存在大量的未完成事务可能就非常难以解决了。