责编 | 王子彧
出品 |进迭时空SpacemiT
AI 应用出现在我们日常的生产生活当中,赋能各行各业的劲头势不可挡。近些年,AI 算力芯片领域群雄逐鹿,通过对芯片、算力与 AI 三者发展迭代过程的理解,我们发现高能效比的算力、通用的软件栈以及高度优化的编译器,是我们的 AI 算力产品迈向成功的必要条件。
进迭时空作为计算芯片企业,对 RISC-V 架构 CPU 进行高度定制,不断挖掘其在计算中的潜力,在 RISC-V 生态强大的软件栈与 CPU 领域成熟的编译器的基础上对 RISC-V DSA 进行联合优化并提供软硬一体的计算解决方案,给 AI 领域带来高效、易用的算力。

GPGPU 作为 HPC 领域(通用算力)的
DSA 打开了 AI 的大门
在上世纪80年代到90年代之间,随着科技的发展,CPU 的性能每隔 18 到 20 个月左右就能翻倍。这就是英特尔(Intel)创始人之一戈登·摩尔提出的摩尔定律(Moore's law)的主要内容。这意味着每隔18个月左右,同一款软件在新发售的 CPU 处理器上的运行速度可以直接翻倍。
转折点大概在2004年5月份, 当时 Intel 取消了其新一代的单核处理器开发工作转头主攻双核处理器设计。在同年稍晚一些,Herb Sutter 写了著名的《The Free Lunch Is Over(不再有免费午餐)》,文章主要表达除非软件的开发进行了多核多线程的设计,否则将无法像过去一样每隔一年多时间即可获取一倍的加速效果。如下图所示,CPU 处理器的单核计算性能开始趋近于一个平台区间,依靠增加晶体管密度来提升计算性能已趋于乏力,不断缩小的芯片尺寸总会遇到其物理极限。这意味着获得更高的性能提升需要新的方法。
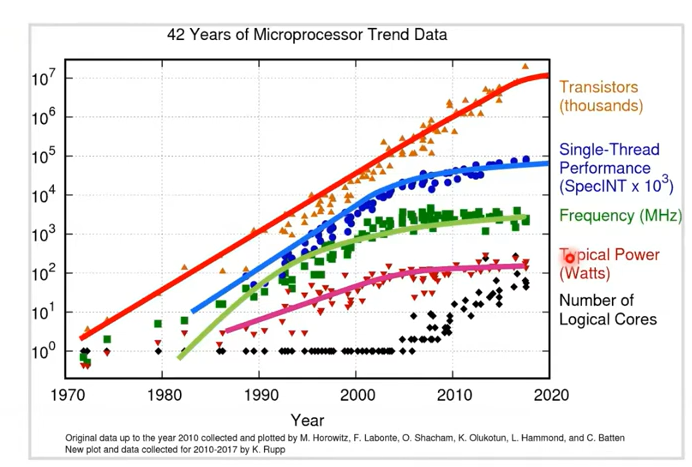
上图为42年间的微处理器趋势数据
在摩尔定律的加倍效应已经放缓的后摩尔时代,持续提升处理器性能的一种重要的技术理念就是 Domain-Specific Architectures(DSA),即采用可编程的专用集成电路(ASICs)去加速特定的高强度的处理器负载,比如加速图形渲染、加速 AI 神经网络的前向推理计算、提高巨量网络数据的吞吐等。
架构的定义包含指令集架构与微架构。指令集架构是软件与硬件进行对话的接口,如果说一条指令是一个单词,那么指令集(ISA)就是词典,而软件程序就像是一本使用特定词典中的词汇编写出来的一本书。

架构设计
通过对架构进行面向特定领域的设计,缩小应用范围,获得更高的性能,或者更好的能效比,保持可编程的灵活性,这就是 DSA 的理念。
面向领域的架构设计可以以较低的成本获取较高的算力,以满足算力需求。
指令集架构的可编程性带来了相对通用的算力,为下一代算法的应用和覆盖更广泛的领域提供了无限的可能。
DSA 的概念由 2017 年图灵奖得主 Henessy 和 Patterson 提出,并进行了题为《创新体系结构将迎来新的黄金时代》的演说。我们生活中最为熟悉的DSA 可能就是显卡(Graphics Processing Unit即GPU),游戏影音娱乐都离不开它。
1999年,NVIDIA 公司在发布其标志性产品 GeForce 256时,首次提出了 GPU 的概念。其实就是 DSA for 3D Graphics,目的是为了加速计算 3D 虚拟世界的渲染,降低 CPU 的负载。GPU 技术的发展也促进了显卡杀手级游戏引擎的激进发展,时至今日游戏画面的逼真程度堪比真人版电影。
时间来到2006年,NVIDIA 发布了 GeForce 8800 GTX(核心代号G80),与 G80 一同发布的还有著名的 CUDA(compute unified device architecture)并提供了驱动程序和 C 语言扩展 。
CUDA 发展到今日,区别于开放计算语言 (OpenCL 跨平台并行编程的独立开放标准) ,开发人员可以使用流行的语言(C、C++、Fortran、Python、MATLAB 等)编写 CUDA 程序,并使用几个基本的关键字即可将并行性添加到他们的代码中,而不仅仅是局限于使用 C 语言。理论上 OpenCL 的运行时编译能够带来较高的执行效率,但是实际上由于 CUDA 是由同一家开发执行其功能的硬件的公司开发,所以后者能更好地匹配 GPU 的计算特性,从而提供更好的性能。
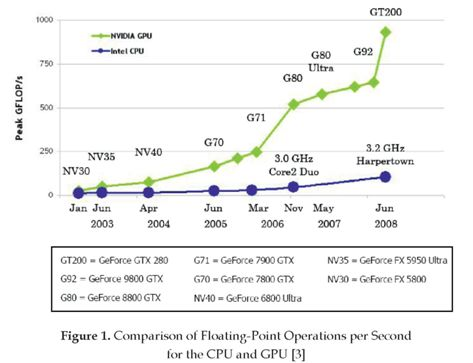
由于 CUDA 便捷的编程模型与优秀的编译器,硬件资源可以较为容易的被充分利用,使得 GPU 上的通用计算能力被充分开发,拓展了 GPU 的应用领域。如下图所示 G80 核心能够提供比同时期的以 CPU 为中心的高性能处理器相当甚至更高的计算能力。再加上便于编程利用的这一特点开始逐渐被高性能计算(High-Performance Computing HPC)社区注意到,并加入到 CUDA 的生态当中开展研究。NVIDIA 公司也提供了 cuBLAS、cuRAND、cuSPARSE、cuSolver、cuFFT、NPP 等一众实用高效的计算库,进一步扩充了 NVIDIA 的算力生态。
2012年多伦多大学的 Alex Krizhevsky 发表了一种新的深度神经网络(DNN 亦或深度卷积神经网络 CNN 本文中一律以 DNN 指代)模型 AlexNet,该模型在 ImageNet 图像比赛中取得了有史以来最好的成绩。15.3%的 top-5 错误率与此同时第二名的错误率高达26.2%。这一结果震惊了世界,从此AI竞赛开始拉开帷幕。该网络模型拥有60 million 的单精度浮点参数量,存储到磁盘上要占用 240MB 的空间。作者表示在显存和算力依然不够的影响下这是他在两块GTX 580 3GB GPU 上能做到的极限了,如果能够有更快的 GPU 按照经验,他可以得到更好的分类结果。【ImageNet Classification with Deep Convolutional Neural Networks】
从那时起, 几乎所有的AI研究员都开始使用 GPU 去进行算法领域的探索与突破。同时 GPU 的架构设计也倾向于提供越来越多的3D能力以外的通用算力,这种设计理念被称为 General-Purpose GPU(GPGPU)。
2011年 TESLA GPU 计算卡发布,标志着 NVIDIA 将正式用于计算的 GPU 产品线独立出来,凭借着架构上的优势,GPU 在通用计算及超级计算机领域,逐渐取代 CPU 成为主角。【 HU L, CHE X, ZHENG S Q, et al. A closer look at GPGPU[J]. ACM Computing Surveys, 2016, 48(4): 1-20.】
伴随着 GPU 技术的发展,AI算法研究也突飞猛进。2014 年前后,香港中文大学的 Sun Yi 等人将卷积神经网络应用在人脸识别领域,采用20万训练数据,在 LFW 数据集上第一次得到超过人类水平的识别精度。2015年10月, AlphaGo 击败樊麾,成为第一个无需让子即可在19路棋盘上击败围棋职业棋士的电脑围棋程序,创造了历史,并于2016年1月发表在知名期刊《自然》。在 CES 2023上,奔驰宣布成为美国首家获得 L3 自动驾驶认证的厂商。AI算法在越来越多的领域的能力上接近和超越人类,也就是说在这些领域AI可以帮助降低人们的负担,释放了人类的潜力。同时也意味着商机与产业化的机会。

通用算力、专用算力,
GPGPU与AI DSA相向而行,殊途同归
在2014年,世界上第一款 supercomputer on a module, Jetson TX1问世,TX1采用256个NVIDIA Maxwell 架构 CUDA cores 提供了超过1 TeraFLOPs 性能。旨在能够为当时最新视觉计算应用提供所需的性能和能效。定位为Deep Learning, Computer Vision, Graphics、GPU Computing 的嵌入式平台。
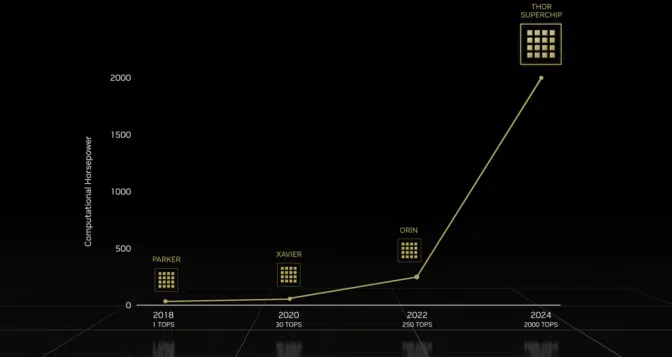
图5.DRIVE Thor is the next generation in the NVIDIA AI compute roadmap。
来源【https://blogs.nvidia.com/blog/2022/09/20/drive-thor/】
该系列产品从2018年的1T算力的 TX1 一路发展到2024年预计发售的拥有2000T算力的 THOR 平台。值得注意的是在 XAVIER 与 ORIN 平台上有超过一半的标称算力是由 DLA 提供。
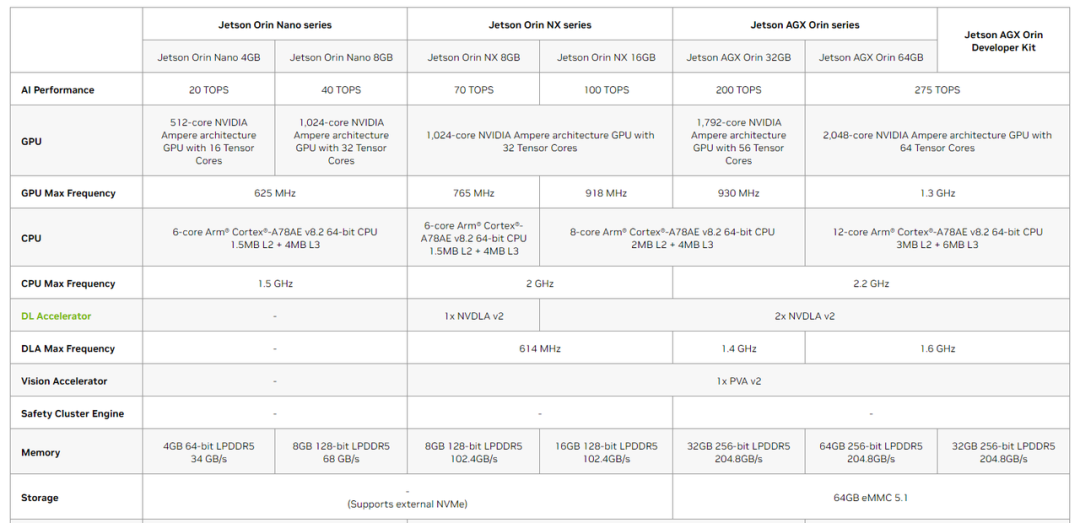
图6.Jetson Orin Technical Specifications
来源【https://www.nvidia.com/en-sg/autonomous-machines/embedded-systems/jetson-orin/】
采用 DLA 可以加速部分计算密集的算子,与采用 GPGPU 计算相比,在损失部分推理精度的前提下,采用 DLA 加速推理计算不仅能加速更快而且能耗更低。但这并不是免费的午餐,首先要想把 GPGPU 与 DLA 两块算力同时利用起来软件上就需要比较精巧的异步设计使得 CPU 负载、编解码模块、图像处理模块、GPGPU 以及 DLA 五者流水化并行处理。然而到了 THOR 这代自动驾驶平台的产品。DLA 提供的算力甚至直接被砍掉,其中原由目前还不清楚。
但是从NVDIA的官方文档中我们可以看到,DLA 支持了约15种主要 AI 算子的执行,不支持的算子类型将会回退到GPGPU进行运算。【https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#dla_layers】
值得关注的是 THOR 平台的 CUDA 引入了 Transformer Engine 用来加速时下大火的基于 attention 机制的 DL 算法,Transformer 正是当下正被热议的 ChatGPT 的网络模型的重要组成部分。并且引入了对8-bit floating point (FP8) 精度的支持,这是 INT8(8-bit整形数据类型,用于加速 DNN 推理计算)的替代品能够在同等的位宽下提供更高的精度。Nvidia 在其 Edge 平台产品线上开始放弃专有的定制化大算力,逐步的在通用算力的基础上来增加领域的定制化。这也与其发布会上反复提到的,提高开发效率和加快软件迭代、算法迭代的目的相吻合。
GPU 也是一种的 DSA,GPU 的发展论证了 DSA 取得的成功。DSA、GPU、AI 这是个互相成就的故事。而 Nvidia的GPGPU 硬件的成功,与其 CUDA 生态丰富的算力软件包、易于使用的编程接口、优秀的编译器脱不开干系。由此我们可以得出一条结论,对于 DSA 算力硬件来说,这些都是走向商业成功的必要条件。
从 TX1 推出开始,对标 TX1 的竞品层出不穷。TX1 的算力来自于 GPGPU,而更加客制化的 ASIC,利用卷积操作的空间局部性进行数据复用的精妙设计,在达到同等甚至更高算力的同时硬件的成本更低。最普遍的设计是一个高能效比的 CPU 小核如 Arm Cortex A7/A53加固化的 2D 图像处理(CV)模块与固化的神经网络处理(DNN/NPU)模块。
由于小 CPU 的计算能力非常受限,将主要负责应用软件的任务调度部分,AI 应用的前处理(非 DNN 算法模型部分)主要由2D图像处理模块来承接。问题在于前处理是非常碎片化的算法,除了个别的插值、颜色域转换功能几乎所有图像处理软件都会用到,其他所需功能非常的广泛。仅 OpenCV 的核心函数、图像处理函数就包含矩阵变换、滤波、分辨率变换、颜色空间转换、直方图等等几个大类,其中每个大类中的子方法又会有若干个,无法定义哪些功能需要被固化。这还不包含3D数据处理能力与特征描述子的使用。算法厂商的需求各不相同,固化的多了浪费面积,固化的少了产品开发的难度将大幅提升。
ONNX 是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架训练得到的网络模型可以以相同的格式进行存储。ONNX 的规范及代码主要由微软,亚马逊,Facebook 和 IBM 等公司共同开发。以 NVIDIA 的 AI 软件生态中最富盛名的 DNN 推理开发工具库 TensortRT 为例,5.1版本支持87个 ONNX 算子,到了7.1版本支持的ONNX 算子数量为108个。功能高度固化的 ASIC 无法对新增的算子计算类型进行支持,将会越来越约束算法的迭代。而在这之上进行 AI 产品开发的算法工程师们无异于是戴着镣铐跳舞。
Google 公司研发了张量处理单元 (TPU),TPU v1 于 2015 年投入生产,并被谷歌内部用于其应用程序。TPU 是一种应用于AI领域,为AI算法提供算力的 ASIC,利用了神经网络对于数值精度不敏感的特性,其思想核心是采用低精度矩阵 Systolic Array 提供巨大算力,同时提供满足 AI 需求的最小化的运算功能。此版本(即 TPUv1)的云服务从未对用户开放开发使用。现在TPUv2 以及后续版本被广泛的应用于谷歌的搜索排序、语音识别、以图搜图、谷歌翻译等领域。
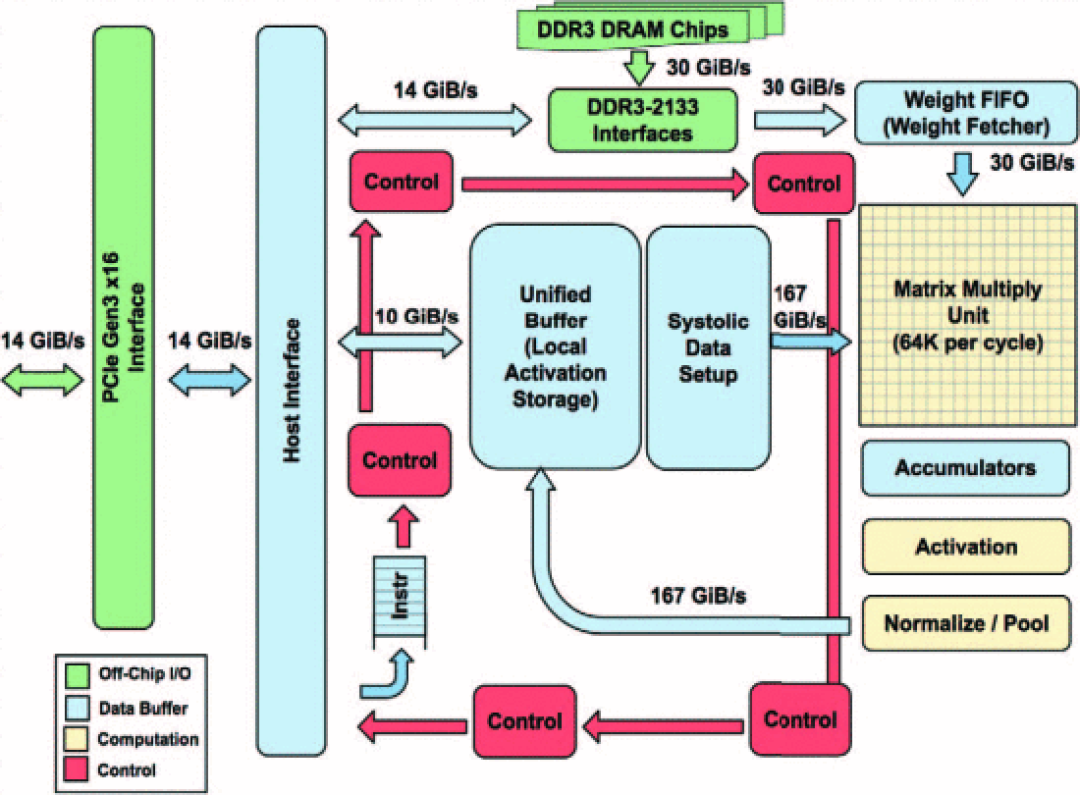
图:TPUv1硬件架构图
在 TPUv1 版本硬件架构图上,我们可以看到 Matrix Multiply 模块提供了64K operations 每时钟的超大算力,紧随其后的是 Activation(激活)、Normalize/Pool(归一化/池化)这些非常具现化的运算。而到了 TPUv2,我们可以看到通用的 Vector 单元代替了v1版本中 activation pipe 中的固定功能。
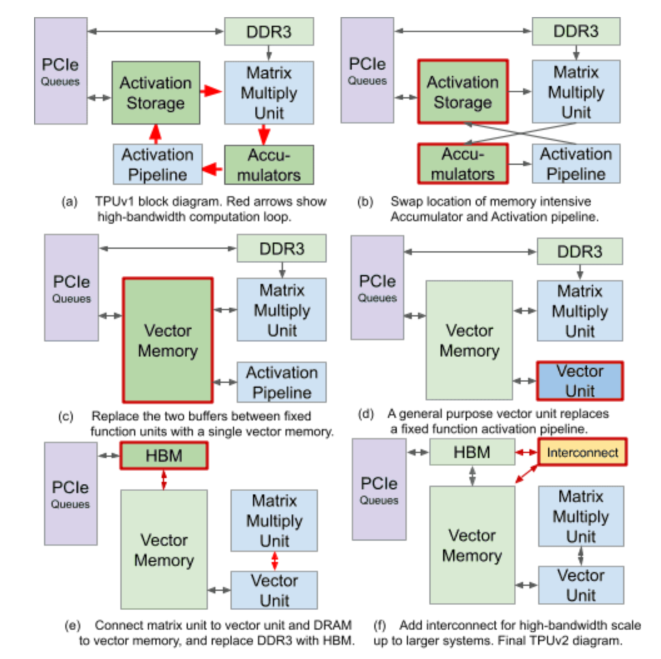
图:Transforming the TPUv1 datapath into the TPUv2 datapath
来源:【The Design Process for Google’s Training Chips: TPUv2 and TPUv3 】
“我们已经在我们的数据中心内运行 TPU 一年多了,并且发现它们为机器学习提供了一个数量级更好的每瓦优化性能。这大致相当于未来七年左右的快进技术(三代摩尔定律)。谷歌的 CEO 这样评价了 TPU。”【 Google CEO Sundar Pichai cloudplatform.googleblog.com/2016/05/Google-supercharges-machine-learning-tasks-with-custom-chip.html】
在21年,David Patterson 进行了 TPU 演进十年的总结:Google 的十大经验教训 【Ten Lessons From Three Generations Shaped Google’s TPUv4i : Industrial Product】 其中就指出DSA既要专门优化,也要灵活。TPUv2 引入的通用算力给 TPU 提供了更强大的能力,不仅仅局限于 TPUv1的模型推理功能,还能进行模型的训练,这往往需要更复杂的运算。Google 也是通过 XLA:一个用于 TPU 的高度定制优化的机器学习编译器,为机器学习(PyTorch、TensorFlow)与数值、科学计算(Jax、Julia、Nx)提供便捷通用的编程使用接口,通过云服务提供给用户,为尤其此生态下的用户带来了良好的用户体验。

DSA成功带来的启示
通过以上的成功案例我们可以发现,GPGPU、TPU 的迭代的共同点是通过越来越高度的架构定制带来了越来越澎湃的专用算力。同时保留或者新增通用的算力。通过高度优化的编译器和丰富的软件栈,让用户能够轻松的将硬件算力充分地利用起来。那么通用算力、编译器、软件栈这些显然都在 CPU 平台是最丰富最成熟的,而对于 CPU 来说 “ Domain-specific architecture design is all you need ”。

RISC-V DSA能否把AI算力做好
GPU 的发展,满足了大型 DNN 网络的内存带宽和计算能力的需求。由于计算能力的提高和可用数据量的增加,DNN 已经演变成更宽、更深的架构。DNN 中的层数可以达到数万层,参数达数十亿,研究人员很难在硬件资源(例如,内存、带宽和功耗)有限的便携式设备中部署 DNN。迫切需要在资源受限的边缘设备(例如,手机、嵌入式设备、智能可穿戴设备、机器人、无人机等)中有效部署 DNN 的方法。于是AI科学家们又开展 AI 模型小型化的研究,也就是用最少的参数量,最少的计算量去达到想要的模型精度。于是shufflenet、mobilenet、网络架构搜索 (NAS) 算法等轻量级神经网络结构开始被推出。能够在很少的参数量上去达到与大参数量模型接近的精度。同时神经网络的参数剪枝、参数量化、紧凑网络、知识蒸馏、低秩分解、参数共享、混合方式等等压缩技术与计算加速技术开始成为研究的热门。
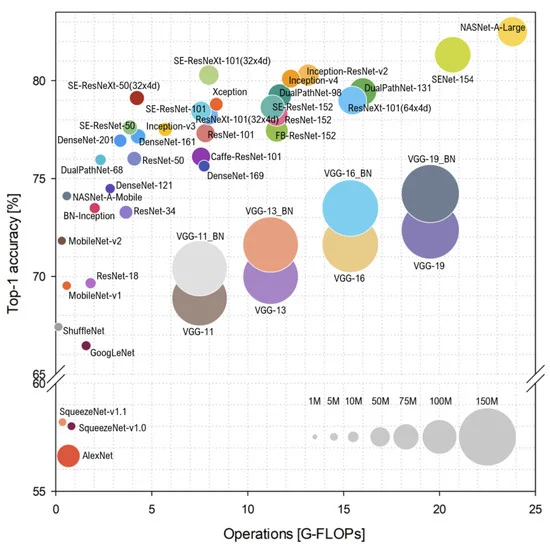
图 3. Top-1 ImageNet-1k 精度与计算复杂度的球形图。
每个球的大小对应于模型的复杂性。(转载自参考文献 [ Bianco, S.; Cadene, R.; Celona, L.; Napoletano, T. Benchmark Analysis of Representative Deep Neural Network Architectures. IEEE Access. 2018, 6, 64270–67277.])。
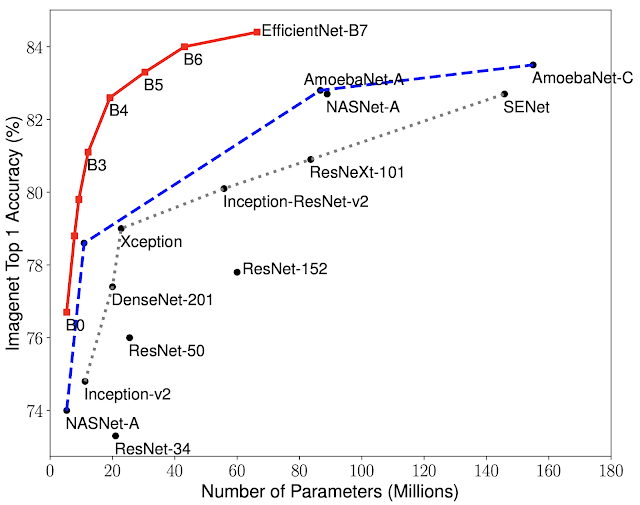
图4. 模型大小与精度比较。
EfficientNet-B0 是AutoML MNAS开发的基线网络,而 Efficient-B1 到 B7 是基线网络扩展得到的。特别的,EfficientNet-B7 达到了最新的 84.4% top-1 / 97.1% top-5 精度,同时比现有最好的 CNN 小 8.4 倍。
同时 AI 科学家们也发现提升模型参数量带来模型精度提升的效应在减弱,如图4所示在图像分类的任务上,模型的精度随着参数量的提升是越来越接近85% Top-1准确率的这个平台。也就是说在成熟的视觉领域我们得到一定 AI 能力的算力需求是趋于收敛的。那么给定任务给定模型给定图像处理的帧率我们就可以得到我们的算力需求。完成指定领域的任务,最终的算力需求是可以被定义并且趋同。
这一切都意味着 AI 不再是超级算力、超级计算机上独享的能力。AI 将会在任何地方,这同时也对我们的通用处理器发起了挑战。
DSA 可以有效、高效的去完成领域任务,然而 C++ 编程、CPU 上的经验可能就无法被利用上了。在 David Patterson 的十大经验教训里也提到 DSA 的软件栈目前不及 CPU,尤其在编译器领域还不够成熟。那么如果 DSA 能够利用 CPU 的软件栈丰富且成熟的优势岂不是如虎添翼?
例如 CUDA 以提供了多种常用编程语言的支持加以关键字拓展的方式去进行并行软件编程,加之本身卓越的通用计算能力。使得其开发生态越来越壮大。有实力的客户甚至放弃使用 TensoRT 通过自身的 GPGPU 技术积累开发出了适合自己业务需求的更高效的软件,比 NVIDIA 提供的 TensoRT 性能提高了一倍。【滴滴自研NVIDIA GPU汇编器:https://on-demand.gputechconf.com/gtc-cn/2019/pdf/CN9667/presentation.pdf】
那么我们何不在CPU上将AI算力提供出来,这条路是不是可行的呢?
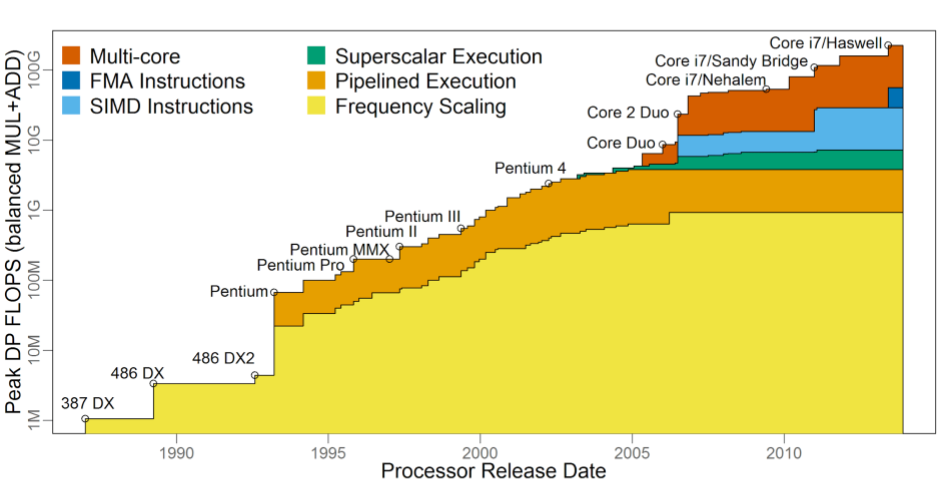
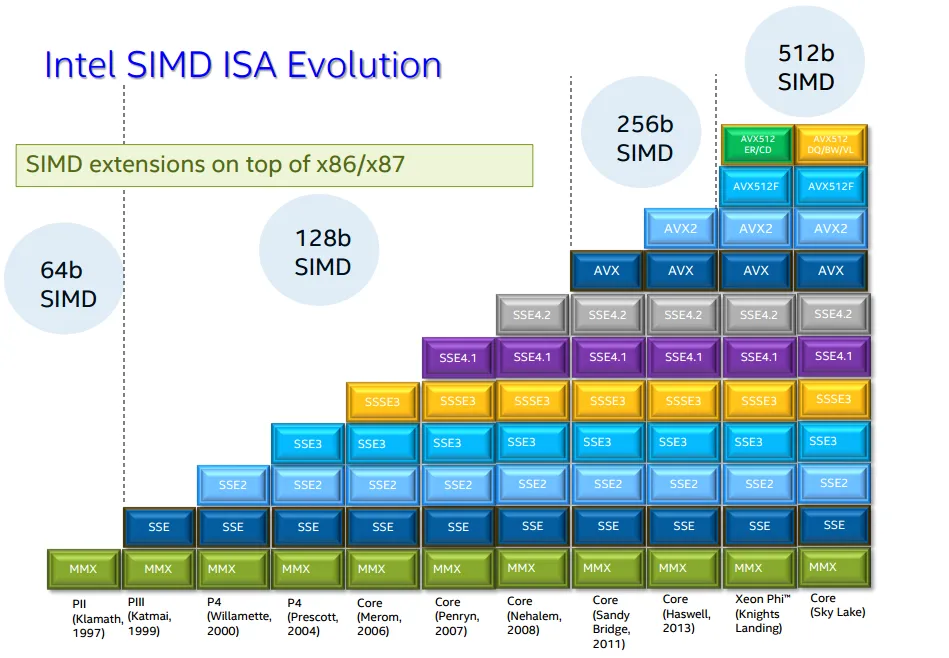
如上图所示,在过去CPU上的浮点能力由于SIMD拓展的提出,
在频率提升很缓慢的时代依旧得到了巨大的提升。
并随着SIMD数据并行宽度的提升有一个线性的增长。
近年来 Intel x86 CPU 处理器上的 SIMD 由64bit 的 MMX(Multi Media eXtension,多媒体扩展指令集)增长到了512bit 的数学拓展 AVX512 与 AI 拓展 VNNI。使得在四核 Core i7-1185G7 @ 3.00GHz 的处理器上可以获取 3Tops 的算力。提供了 AI 所谓的 MAC 能力,加之本身的通用 SIMD 计算能力是可以有效 COVER 如智能机器人、智能视频、语音终端设备等 AI 场景。但此等 SOC 做 AI 终端过于奢侈,且定位还是通用而不是 AI DSA。
Intel 最新的 AMX 矩阵拓展架构、Arm 架构下的 SME 矩阵拓展架构以及IBM 的 AMM 指令集更是将 CPU 能提供的 AI 算力又提升了一个台阶。在架构代号为 Sapphire Rapids 的 server 级处理器上可以通过 AMX 获得每时钟周期1024个 mac 是 VNNI 拓展提供的算力的8倍(128个 mac 每时钟周期)。
【https://edc.intel.com/content/www/tw/zh/products/performance/benchmarks/architecture-day-2021/】
CPU 上完全可以长出使能 AI 应用大算力,正如过去长出了适合多媒体处理的算力。【https://en.wikipedia.org/wiki/MMX_(instruction_set)】

为什么是RISC-V
如果要对CPU架构进行领域定制,需要获取对应的架构级授权(Architectural License)。区别于 IP Core 的授权,架构级授权特指指令集(ISA)授权,允许客户自行定制优化。
关于 CPU 业界两大阵营 x86 与 ARM 的架构授权的情况是什么样的呢?x86的专利主要掌握在英特尔和 AMD 这两家公司手中,到目前为止国内没有任何一家厂商拥有 x86 的架构级授权,海光信息与兆芯采用的是 x86 架构 IP 内核授权模式。海思、飞腾均已经获得 ARMv8 架构的永久授权。尽管 ARM 此前表态 ARMv9 架构不受美国出口管理条例 (EAR) 约束,华为海思等国内 CPU 产商依然可获授权,但是 ARMv9 不再提供永久授权,采用 ARM 架构仍有长期隐患。而且即使在拥有 ARM 架构级授权的情况下做出指令集定制与改动,也必须经由 ARM 参与支持修改才可以,否则将触发违约条款。
RISC-V 因其相对精简的指令集架构(ISA)以及开源宽松的 BSD 协议使得Fabless 可以基于 RISC-V 架构进行任意的架构拓展与定制。相信 RISC-V DSA 可以利用其经典的 CPU 的编程模型与相对低成本获取的 AI 算力,加之标准 RISC-V Vector 拓展提供的通用算力。能够给 AI 嵌入式场景下 1-10T算力需求范围的 AI 产业应用带来全新的商业化硬件方案。
参考资料:
《Intel cancels Tejas, moves to dual-core designs》, 【https://www.eetimes.com/Intel-cancels-Tejas-moves-to-dual-core-designs/】
《The Free Lunch Is Over》,
【http://www.gotw.ca/publications/concurrency-ddj.htm】
《ImageNet Classification with Deep Convolutional Neural Networks》,Alex Krizhevsky,Ilya Sutskever,Geoffrey E。
【 HU L, CHE X, ZHENG S Q, et al. A closer look at GPGPU[J]. ACM Computing Surveys, 2016, 48(4): 1-20.】
《DRIVE Thor is the next generation in the NVIDIA AI compute roadmap》
【https://blogs.nvidia.com/blog/2022/09/20/drive-thor/】
Jetson Orin Technical Specifications,
https://www.nvidia.com/en-sg/autonomous-machines/embedded-systems/jetson-orin/】
DLA支持的层和限制,【https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#dla_layers】
ONNX-Tensorrt,
https://github.com/onnx/onnx-tensorrt/blob/7.1/operators.md】
《Google CEO Sundar Pichai》, 【cloudplatform.googleblog.com/2016/05/Google-supercharges-machine-learning-tasks-with-custom-chip.html】
MnasNet: Towards Automating the Design of Mobile Machine Learning Models
– Google AI Blog (googleblog.com)
滴滴自研 NVIDIA GPU 汇编器:
https://on-demand.gputechconf.com/gtc-cn/2019/pdf/CN9667/presentation.pdf】
intel性能指标参数,
https://edc.intel.com/content/www/tw/zh/products/performance/benchmarks/architecture-day-2021/】
MMX介绍,
https://en.wikipedia.org/wiki/MMX_(instruction_set)】