文章目录
- 知识回顾
- &取地址重定向
- 重定向底层
- 文件描述符分配规则
- dup2
- 标准输出和标准错误的区别
- 缓冲区
- 缓冲区总结
知识回顾
我们在之前有了解过输出重定向>, >>,可以让echo命令本来是打印到屏幕上而变成了把这些数据写到文件中,并且可以追加或者覆盖文件内容进行写入,输入<可以让文件中的内容重定向到屏幕上
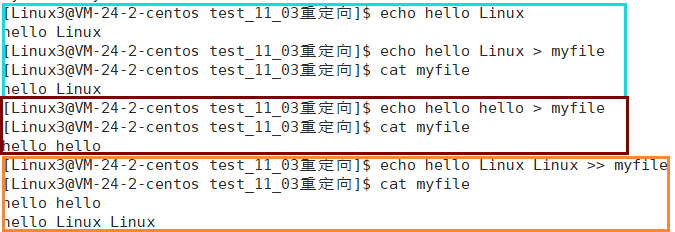
echo后面只跟跟字符串,就把字符串打印到了屏幕上
echo后面加上加字符串再加>后跟文件,就把对应的字符串写入了文件中,并且会把文件中之前的数据覆盖
echo后面加上字符串再加>>后跟文件,也是把字符串写入了文件中,但是不同的是它不会把文件中原有的数据进行覆盖

< 把文件中的内容输出到了屏幕上

&取地址重定向
#include <stdio.h>
#include <unistd.h>
#include <string.h>int main()
{const char* msg1 = "hello normal message\n";const char* msg2 = "hello error message\n";fwrite(msg1, 1, strlen(msg1), stdout);fwrite(msg1, 1, strlen(msg1), stdout);fwrite(msg1, 1, strlen(msg1), stdout);fwrite(msg1, 1, strlen(msg1), stdout);fwrite(msg1, 1, strlen(msg1), stdout);fwrite(msg2, 1, strlen(msg2), stderr);fwrite(msg2, 1, strlen(msg2), stderr);fwrite(msg2, 1, strlen(msg2), stderr); fwrite(msg2, 1, strlen(msg2), stderr);fwrite(msg2, 1, strlen(msg2), stderr);return 0;
}
解释:

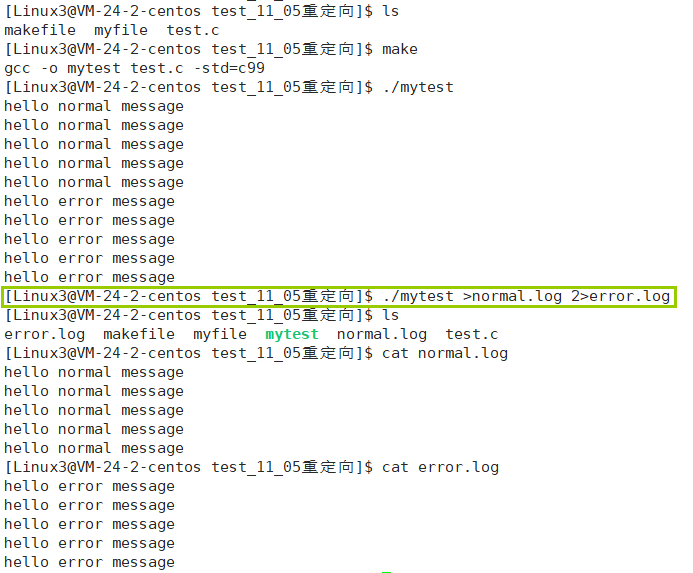
这句话其实是一个简写,写全的话应该是./mytest 1>normal.log 2>error.log,这个命令意为执行可执行文件./mytest并把要输出到1号文件描述符的数据重定向到文件normal.log,把要输出到二号文件描述符的数据重定向到文件error.log
那么此时如果我就是想把要写入到文件1,2号文件描述符的数据都重定向到一个文件呢?
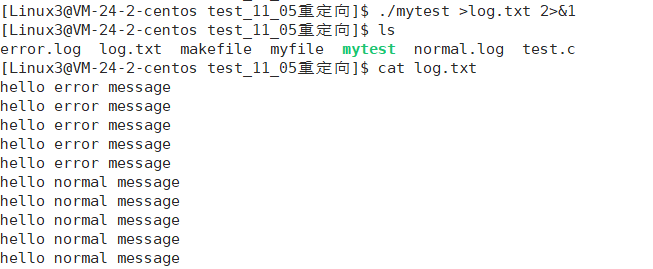
./mytest >log.txt 2>&1这句话的意思是:标准输出的输出到文件log.txt,标准错误也输出到文件log.txt
区别:

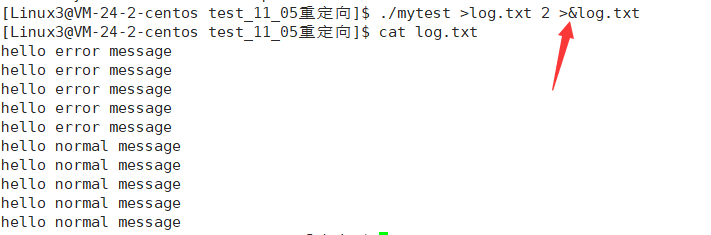
语法规定重定向到同一个文件时,后面的要加符号&
重定向底层
文件描述符分配规则
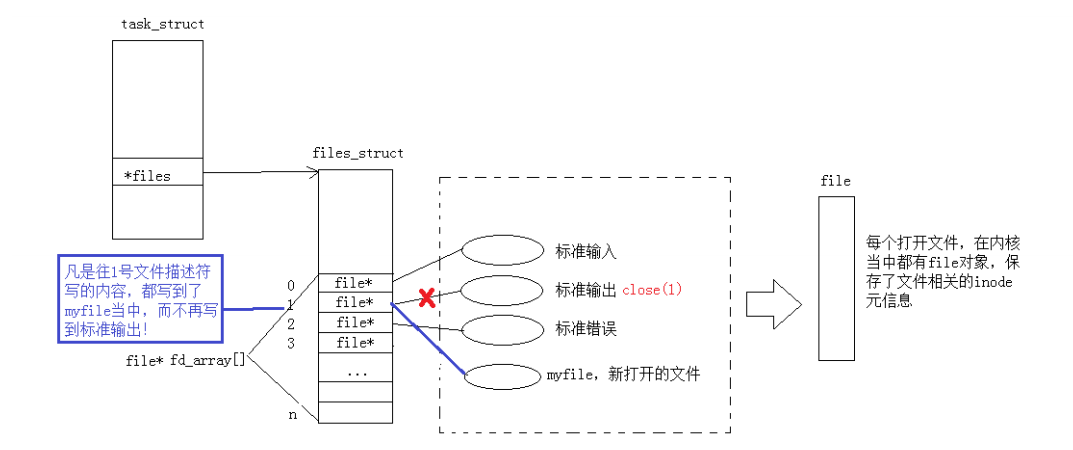
Linux进程默认会打开三个文件描述符标准输入0,标准输出1,标准错误2,对应的物理设备一般是键盘,显示器,显示器。那么我们在进行输出时底层默认是打开文件标准输出或标准错误进行写入,也就是输出到键盘上,那么是如何把数据不输出到显示器而是文件中的呢?
其实是把默认的1或2文件给关闭,再把要被写入的文件放到文件描述符1或2的位置,那么在底层系统仍会向1或2文件进行输出,此时却不是再向显示器进行输出了,而是刚放到1或2处文件进行写入。怎么把文件放到1位置的呢?这就和底层的文件描述符分配规则有关了
在打开一个文件放到files_struct表中的时候,系统会默认从下表0位置开始找,当找到第一个没有放文件的位置时,就会把该文件放到这,并把该位置的文件描述符分配给这个文件,
一句话理解文件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
如下图所示:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
{close(1);umask(0);int fd = open("myfile", O_WRONLY|O_CREAT, 0644);if(fd < 0){perror("open");return 1;}printf("fd: %d\n", fd);printf("hello Linux\n");fflush(stdout);close(fd);return 0;
上面使我们自己实现的,也符合我们的预期,但是略显挫,因此库里面给我们提供了相应的重定向的接口。
dup2
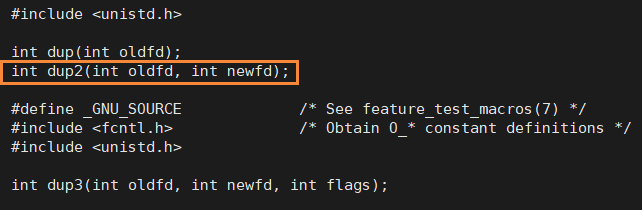
先打开一个文件,产生新的文件描述符,然后再把新的文件描述符放到想要重定向到的文件描述符那里
返回值:

成功返回新产生的描述符,失败返回-1
作用: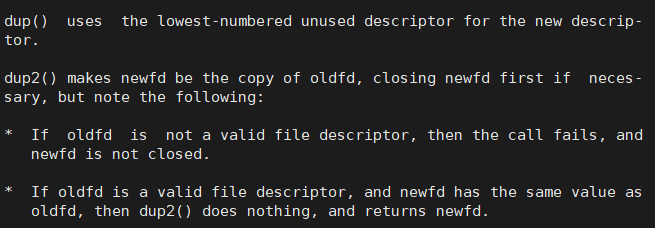
dup2的作用就是让旧的描述符指针内容被新的描述符指针内容拷贝,这句话听起来好像产生的结果是,最终这两个位置描述符都变成旧的描述符指针的内容?其实不然,这里会使我们产生混淆,系统这里是把原来已有的文件描述符称为了新的,而刚打开的文件产生的文件描述符是旧的,但我们可以这么理解新的就是先产生的,旧的就是后产生的,注意这里的文件描述符的拷贝并不是数组下标之间的拷贝,而是文件描述符在特定文件描述符数组下标里面的指针内容在进行拷贝
函数要求:
1.如果新的描述符是不明确的,就会调用失败并且原有的文件不会被关闭
2.如果新的文件描述符是明确的,并且两个参数的描述符相同,那么什么也不做并返回旧的文件描述符
参数:
oldfd:新产生的文件描述符
newfd:原来已有的文件描述符
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>int main()
{umask(0);int fd = open("myfile2", O_WRONLY|O_CREAT, 0644);if(fd < 0){perror("open");return 1;}dup2(fd, 1);close(fd);//把原来的打开的文件给关掉,当然也可以不关const char* msg = "abcdefg\n";write(1, msg, strlen(msg));printf("%d\n", fd);return 0;
} 本来应该打印到屏幕打印的数据此时已经打印到了我们的文件里
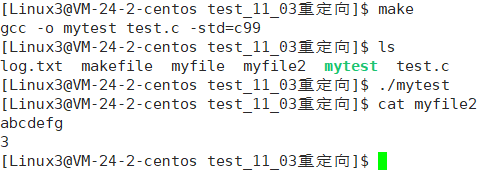
上层在进行写入或者打印时,还是会向1号文件描述符里面输入,他以为是在向屏幕上打印,其实我们已经在底层将1号文件描述符换成了我们新打开的这个文件描述符
标准输出和标准错误的区别
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>int main()
{umask(0);int fd = open("myfile2", O_WRONLY|O_CREAT, 0644);if(fd < 0){perror("open");return 1;}dup2(fd, 1);close(fd);//把原来的打开的文件给关掉,当然也可以不关perror("i am stderror\n"); const char* msg = "abcdefg\n";write(1, msg, strlen(msg));printf("%d\n", fd);return 0;
}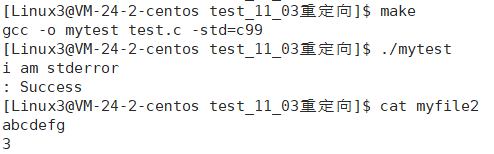
perror(“i am stderror\n”);
perror在底层默认是向2号文件描述符标准错误打印,因此我们把1号文件描述符换掉,并不影响perror向屏幕的打印,只会影响原来要想1号文件描述符打印的函数调用。
为什么要有标准错误呢?
因为我们不想让错误和正常的输出混淆,把错误打印到一个专门保存错误的文件,便于我们查看错误。
缓冲区
此外这里还有一个疑问

echo后面什么都不跟时,为什么会打印出一个换行符,而且我们再重定向追加时,字符串会进行换行打印?
这是因为我们在输入结束时会按下换行键,换行符是有效字符自然就会被写入
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <stdio.h>
#include <unistd.h>int main()
{char buf[1024];ssize_t s = read(0, buf, sizeof(buf));if(s > 0){buf[s] = 0;write(1, buf, strlen(buf));write(2, buf, strlen(buf)); write(1, buf, strlen(buf) - 1);write(2, buf, strlen(buf) - 1);}return 0;
}
上面这部分代码就可以证明换行符\n也被写入到了文件中
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
{close(1);umask(0);int fd = open("myfile", O_WRONLY|O_CREAT, 0644);if(fd < 0){perror("open");return 1;}printf("fd: %d\n", fd);printf("hello Linux\n");fflush(stdout);close(fd);return 0;
}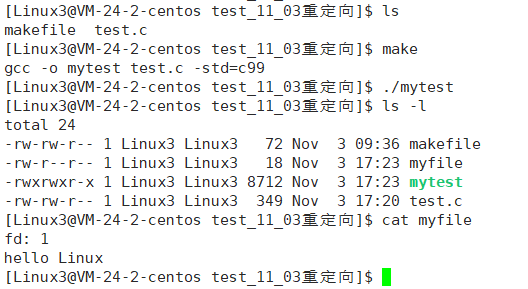
如果不加fflush(stdout),结果如下:
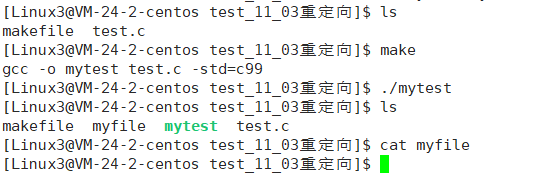
为什么文件myfile中没有内容?fflush()的作用是什么?

将对应缓冲区当中的内容立即刷新出来,fflush(stdout)就是把标准输出的缓冲区内容立即刷新,为什么会有缓冲区呢?缓冲区的作用是为了减少对磁盘的读写次数,提高计算机的运行效率。系统调用时需要时间的,程序频繁地使用系统调用会降低程序的运行效率,库函数访问文件时会根据不同的需要,设置不同类型的缓冲区,从而减少直接调用IO系统调用的次数,也就提高了效率,调用printf时,输出的结果一般会被标准库缓存起来,等到缓冲区满了再一次性写入到文件,在缓冲区没满的时候要想及时的输出就可以使用fflush(stdout)强制把缓存内容进行输出。
#include <stdio.h>
#include <unistd.h>
#include <string.h>int main()
{const char *msg0="hello printf\n";const char *msg1="hello fwrite\n";const char *msg2="hello write\n";printf("%s", msg0);fwrite(msg1, strlen(msg1), 1, stdout);write(1, msg2, strlen(msg2));fork();return 0;
}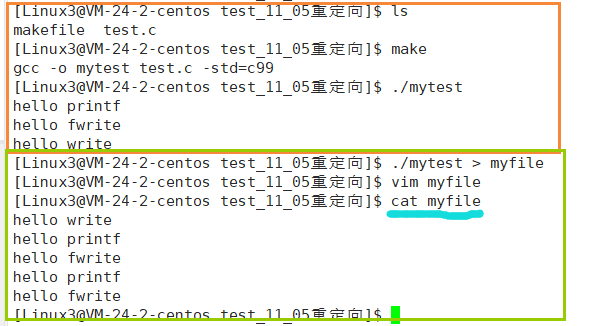
通过上述例子我们可以发现一个现象,当直接运行该可执行程序打印到屏幕上时,fwrite,printf,write函数各被执行了一次,但是当把该进程重定向到文件时,却发现printf和fwrite函数被执行了两次,而write函数只被执行了一次,这是为什么呢?
同一段代码既然会被执行两次,那么一定与fork函数有关
首先在向文件写入时库函数会先把要输出的,放到用户层的缓冲区,等到缓冲区满了或者进程结束时才会一起刷新到内核缓冲区,而系统调用write会直接把数据放到内核缓冲区,因此在fork之前write函数就已经被刷新输出了,而printf,fprintf,fwrite等还在用户缓冲区里面等着,当执行fork时,创建子进程,此时子进程和父进程的数据是一样的,共用一个缓冲区,但是当进程退出时要进行缓冲区刷新,此时无论是父进程缓冲区刷新还是子进程缓冲区刷新,就会使得共用一份数据的父子进程数据不一样,此时就会发生写时拷贝,再次创建一个缓冲区,因此在用户层的数据就被刷新了两次。
那么为什么直接向屏幕输出时,fork后数据不会被打印两次呢?
因为向屏幕打印时,是行刷新,就是遇到\n就会刷新,因此在执行fork之前,用户层的缓冲区内就已经被刷新了,执行fork后进程退出不会发生,应用层的缓冲区内没有数据被修改,因为没有数据了,所以就不会发生写时拷贝。
缓冲区总结
缓冲区分为内核缓冲区和应用层缓冲区,对于库函数会先把数据写入到应用层缓冲区,而系统调用一般是直接写到内核缓冲区,当写到应用层缓冲区又会分三种情况:直接刷新,行刷新,全缓冲。直接刷新就是不在应用层缓冲区等待,只要是有数据就直接刷新到内核缓冲区,对于行刷新就是只要遇到\n就向内核缓冲区进行刷新,全缓冲就是等缓冲区写满了才向内和缓冲区进行刷新。对于向屏幕打印时采用的是行缓冲,向文件写入时采用的是全缓冲对于fflush函数就是直接刷新向内核缓冲去写入,因此我们可以断定,该函数一定在底层会调用write函数。想文件写入采用全缓冲是为了减少IO的调用次数,提高效率。
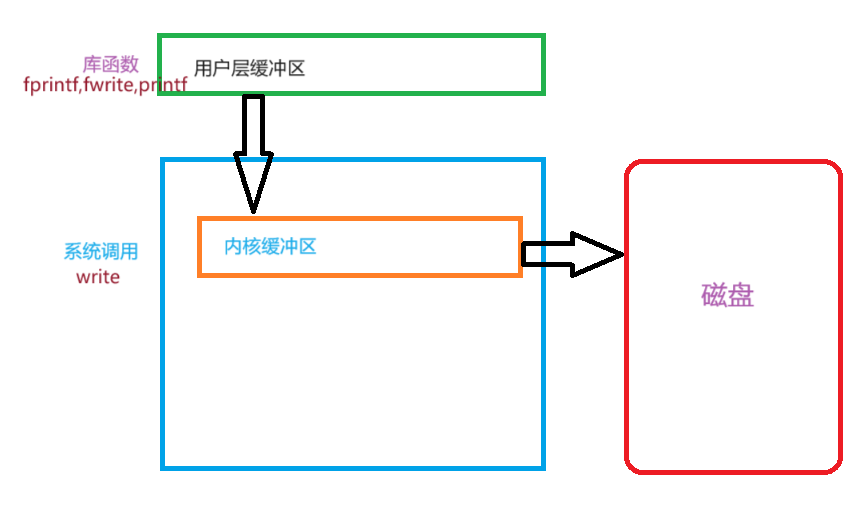
库函数先写入到用户层缓冲区再通过底层调用的write函数写入到内核缓冲区
用于层的缓冲区,是语言级别的缓冲区,是在堆上malloc出来的,并且每一个进程都会有一个缓冲区