模型模块
本书的第5-9章重点介绍了各种2D和3D的语义分割和实例分割网络模型,所以在模型模块中,我们需要做的事情就是将要实验的分割网络写在该目录下。有时候我们可能想尝试不同的分割网络结构,所以在该目录下可以存在多个想要实验的网络模型定义文件。对于PASCAL VOC这样的自然数据集,我们可能想实验Deeplab v3+、PSPNet、RefineNet等网络的训练效果。代码11-3给出了Deeplab v3+网络封装后的主体部分,完整网络搭建代码可参考本书配套代码对应章节。
代码11-3 Deeplab v3+网络的主体部分
# 定义Deeplab V3+类
class DeepLabHeadV3Plus(nn.Module):def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36]):super(DeepLabHeadV3Plus, self).__init__()self.project = nn.Sequential(nn.Conv2d(low_level_channels, 48, 1, bias=False),nn.BatchNorm2d(48),nn.ReLU(inplace=True),)# ASPPself.aspp = ASPP(in_channels, aspp_dilate)# classifier headself.classifier = nn.Sequential(nn.Conv2d(304, 256, 3, padding=1, bias=False),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(256, num_classes, 1))self._init_weight()# forward methoddef forward(self, feature):# print(feature['low_level'].shape)# print(feature['out'].shape)low_level_feature = self.project(feature['low_level'])output_feature = self.aspp(feature['out'])output_feature = F.interpolate(output_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)return self.classifier(torch.cat([low_level_feature, output_feature], dim=1))# weight initilizedef _init_weight(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)对于复杂网络搭建,一般都是采用自下而上的搭建方法,先搭建底层组件,再逐步向上封装,对于本例中的Deeplab v3+,可以先分别搭建backbone骨干网络、ASPP和编解码结构,最后再进行封装。
工具函数模块
工具函数是为项目完成各项功能所自定义的辅助函数,可以统一定义在utils文件夹下,根据实际项目的不同,工具函数也各不相同。常用的工具函数包括各种损失函数的定义loss.py、训练可视化函数的定义visualize.py、用于记录训练日志的log.py等。代码11-4给出了一个关于Focal loss损失函数的定义,该损失函数作为工具函数可放在loss.py文件中。
代码11-4 工具函数示例:定义一个Focal loss
# 导入相关库
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义一个Focal loss类
class FocalLoss(nn.Module):def __init__(self, alpha=1, gamma=2):super(FocalLoss, self).__init__()self.alpha = alphaself.gamma = gammadef forward(self, inputs, targets):# Compute cross-entropy lossce_loss = F.cross_entropy(inputs, targets, reduction='none')# Compute the focal losspt = torch.exp(-ce_loss) focal_loss = self.alpha * (1 - pt) ** self.gamma * ce_lossreturn focal_loss.mean()配置模块
配置模块是为项目模型训练传入各种参数而进行设置的模块,比如训练数据所在目录、训练所需要的各种参数、训练过程是否需要可视化等。一般来说,我们有两种方式来对项目执行参数进行配置管理,一种是直接在主函数main.py中使用argparse库对参数进行配置,然后再命令行中进行传入;另一种则是单独定义一个config.py或者config.yaml文件来对所有参数进行统一配置。基于argparse库的参数配置管理简单示例如代码11-5所示。
代码11-5 argparser参数配置管理
# 导入argparse库
import argparse
# 创建参数管理器
parser = argparse.ArgumentParser()
# 涉及数据相关的参数管理
parser.add_argument("--data_root", type=str, default='./dataset',help="path to Dataset")
parser.add_argument("--save_root", type=str, default='./',help="path to save result")
parser.add_argument("--dataset", type=str, default='voc',choices=['voc', 'cityscapes', 'ade'], help='Name of dataset')
parser.add_argument("--num_classes", type=int, default=None,help="num classes (default: None)")在上述代码中,我们基于argparse给出了一小部分参数配置管理代码,涉及训练数据相关的部分参数,包括数据读取路径、存放路径、训练所用数据集、分割类别数量等。
主函数模块
主函数模块main.py是项目的启动模块,该模块将定义好的数据和模型模块进行组装,并结合损失函数、优化器、评估方法和可视化等组件,将config.py中配置好的项目参数传入,根据训练-验证的模式,执行图像分割项目模型训练和验证。代码11-6是VOC数据集训练验证部分代码。
代码11-6 主函数模块中的训练迭代部分
# 初始化区间损失
interval_loss = 0
while True: # 执行训练model.train()cur_epochs += 1for (images, labels) in train_loader:cur_itrs += 1images = images.to(device, dtype=torch.float32)labels = labels.to(device, dtype=torch.long)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()np_loss = loss.detach().cpu().numpy()interval_loss += np_lossif vis is not None:vis.vis_scalar('Loss', cur_itrs, np_loss)# 打印训练信息if (cur_itrs) % opts.print_interval == 0:pass# 保存模型if (cur_itrs) % opts.val_interval == 0:pass# 日志记录logger.info("Save the latest model to %s" % save_path_checkpoints)# 模型验证print("validation...")model.eval()val_score, ret_samples = validate(opts=opts, model=model, loader=val_loader, device=device, metrics=metrics,ret_samples_ids=vis_sample_id)logger.info("Validation performance: %s", val_score)# 保存最优模型if val_score['mean_dice'] > best_score: best_score = val_score['mean_dice']save_ckpt(os.path.join(save_path_checkpoints, 'best_%s_%s_os%d.pth' %(opts.model, opts.dataset, opts.output_stride)))logger.info("Save best-performance model so far to %s" % save_path_checkpoints)# 训练过程可视化if vis is not None: vis.vis_scalar("[Val] Overall Acc", cur_itrs, val_score['Overall Acc'])vis.vis_scalar("[Val] Mean IoU", cur_itrs, val_score['Mean IoU'])vis.vis_table("[Val] Class IoU", val_score['Class IoU'])for k, (img, target, lbl) in enumerate(ret_samples):img = (denorm(img) * 255).astype(np.uint8)target = train_dst.decode_target(target).transpose(2, 0, 1).astype(np.uint8)lbl = train_dst.decode_target(lbl).transpose(2, 0, 1).astype(np.uint8)concat_img = np.concatenate((img, target, lbl), axis=2) vis.vis_image('Sample %d' % k, concat_img)scheduler.step()在代码11-6中,我们展示了一个图像分割项目主函数模块中最核心的训练和验证部分。在训练时,按照指定迭代次数保存模型和对训练过程进行可视化展示。图11-2为训练打印的部分信息。

图11-2 VOC训练过程信息
图11-3为基于visdom的训练过程可视化展示,包括当前训练配置参数信息,训练损失函数变化曲线、验证集全局准确率、mIoU和类别IoU等指标变化曲线图。
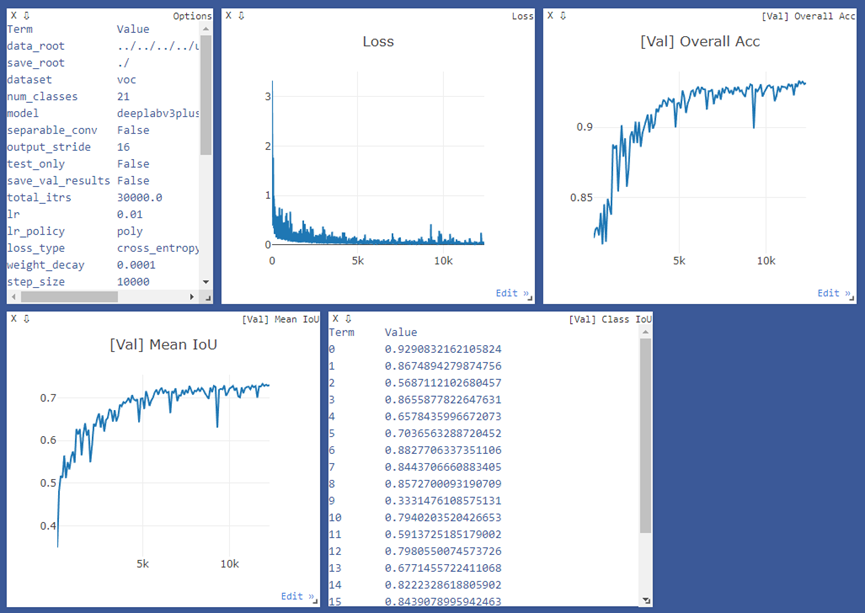
图11-3 Deeplab v3+训练过程可视化
图11-4展示了两组训练过程中验证集的输入图像、标签图像和模型预测图像的对比图。可以看到,基于Deeplab v3+的分割模型在PASCAL VOC 2012上表现还不错。

图11-4 验证集模型效果图
后续全书内容和代码将在github上开源,请关注仓库:
https://github.com/luwill/Deep-Learning-Image-Segmentation
(未完待续)

![[架构之路-254/创业之路-85]:目标系统 - 横向管理 - 源头:信息系统战略规划的常用方法论,为软件工程的实施指明方向!!!](https://img-blog.csdnimg.cn/74a4f8b6f7f4410bb73a8a165d306f78.png)