群公告
Java每日大厂面试题:
1、Spring 是如何解决循环依赖?
答案:三级缓存,简单来说,A创建过程中需要B,于是A将自己放到三级缓存里面,去实例化B,B实例化的时候发现需要A,于是B先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了A然后把三级缓存里面的这个A放到二级缓存里面,并删除三级缓存里面的A,B顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A依然是创建中状态)然后回来接着创建A,此时B已经创建结束,直接从一级缓存里面拿到B,然后完成创建,并将A放到一级缓存中。
1. 背景
在最近的业务需求开发过程中遇到了“传说中”的循环依赖问题,在之前学习Spring的时候经常会看到Spring是如何解决循环依赖问题的,所谓循环依赖即形成了一个环状的依赖关系,这个环中的某一个点产生不稳定变化都会导致整个链路产生不稳定的变化;此外循环依赖还会导致应用程序启动失败、内存溢出、甚至出现一些难以排查的问题,于是便系统性的对该问题进行学习和总结并整理文章如下。
2. 循环依赖
2.1. 什么是循环依赖?
循环依赖指的是多个对象之间的依赖关系形成了一个闭环。图1、2分别是两个对象和多个对象形成循环依赖图示,实际编程中由于依赖层次深、关系复杂等因素,导致依赖关系难以清晰梳理。
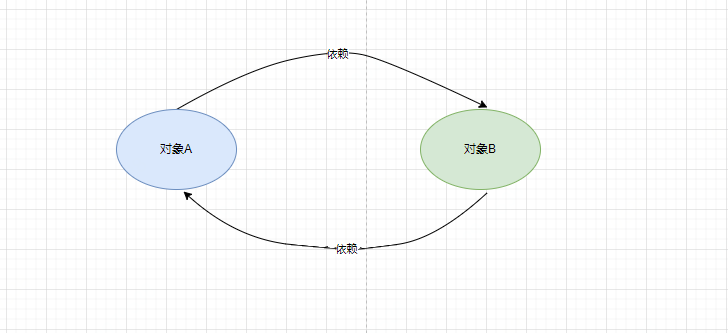
图1 两个对象间的循环依赖
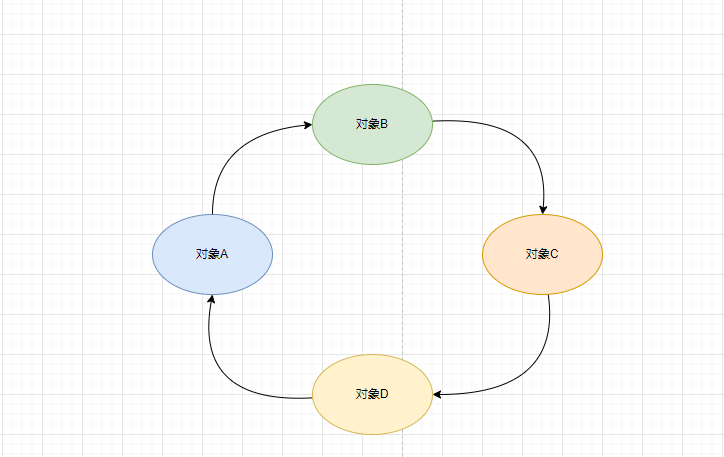
图2 多个对象间的循环依赖
2.2. 为什么会产生循环依赖?
Spring创建bean的本质还是创建对象,一个完整的对象包含两部分:当前对象的实例化和对象属性的实例化。在Spring中,对象的实例化是通过反射实现的,而对象的属性则是在对象实例化之后通过一定的方式设置的。
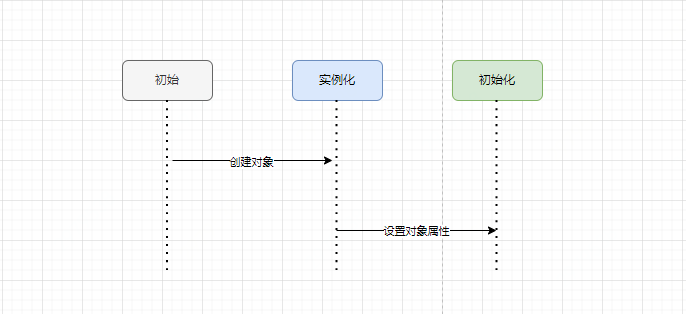
图3 Spring创建Bean流程
接下来以Demo中的类A、B为例描述循环依赖产生过程:
Demo中的类A、B中各自都以对方为自己的全局属性,并且在Spring中实例化bean是通过ApplicationContext.getBean()方法来进行的。
如果获取的对象依赖了另一个对象,那么会首先创建当前对象,然后通过递归的调用ApplicationContext.getBean()方法来获取所依赖的对象,最后将获取到的对象注入到当前对象中。
@Component
public class A {private B b;public void setB(B b) {this.b = b;}
}
@Component
public class B {private A a;public void setA(A a) {this.a = a;}
}此处以Demo中初始化A对象为例,
◦ 第一步:首先Spring尝试通过ApplicationContext.getBean()方法获取A对象的实例,由于Spring容器中还没有A对象实例,因而其会创建一个A对象,然后发现其依赖了B对象,所以会尝试递归的通过ApplicationContext.getBean()方法获取B对象的实例,但是Spring容器中此时也没有B对象的实例,因而其还是会先创建一个B对象的实例。( 此时A对象和B对象都已经创建了,并且保存在Spring容器中了,只不过A对象的属性b和B对象的属性a都还没有设置进去。)
◦第二步:在前面Spring创建B对象之后,Spring发现B对象依赖了属性a,因而此时还是会尝试递归的调用ApplicationContext.getBean()方法获取A对象的实例,因为Spring中已经有一个A对象的实例,虽然只是半成品(其属性b还未初始化),但其也还是目标bean,因而会将该A对象的实例返回。(此时,B对象的属性a就设置进去了,然后还是ApplicationContext.getBean()方法递归的返回,也就是将B对象的实例返回,此时就会将该实例设置到A对象的属性b中。)
◦第三步:在上面这个递归过程的最后,Spring将获取到的B对象实例设置到了A对象的属性b中了,这里的A对象其实和前面设置到实例B中的半成品A对象是同一个对象,其引用地址是同一个,这里为A对象的b属性设置了值,其实也就是为那个半成品的a属性设置了值。
实际加载过程流程图如图4所示:其中图中getBean()表示调用Spring的ApplicationContext.getBean()方法,而该方法中的参数,则表示我们要尝试获取的目标对象。图中的黑色箭头表示一开始的方法调用走向,走到最后,返回了Spring中缓存的A对象之后,表示递归调用返回了,此时使用红色的箭头表示。从图中我们可以很清楚的看到,B对象的a属性是在第三步中注入的半成品A对象,而A对象的b属性是在第二步中注入的成品B对象,此时半成品的A对象也就变成了成品的A对象,因为其属性已经设置完成了。
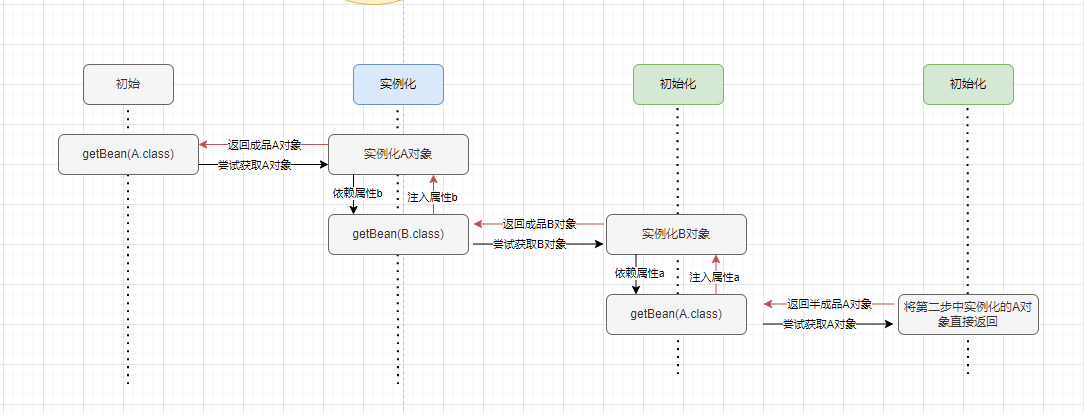
图4 Bean加载流程图
3. Spring缓存机制
3.1. Spring是如何解决循环依赖的?
Spring在DefaultSingletonBeanRegistry类中维护了三个Map,也就是我们通常说的三级缓存。
◦singletonObjects (一级缓存)它是我们最熟悉的朋友,俗称“单例池”“容器”,缓存创建完成单例Bean的地方。
◦earlySingletonObjects(二级缓存)映射Bean的早期引用,也就是说在这个Map里的Bean不是完整的,甚至还不能称之为“Bean”,只是一个Instance。
◦singletonFactories(三级缓存) 映射创建Bean的原始工厂。
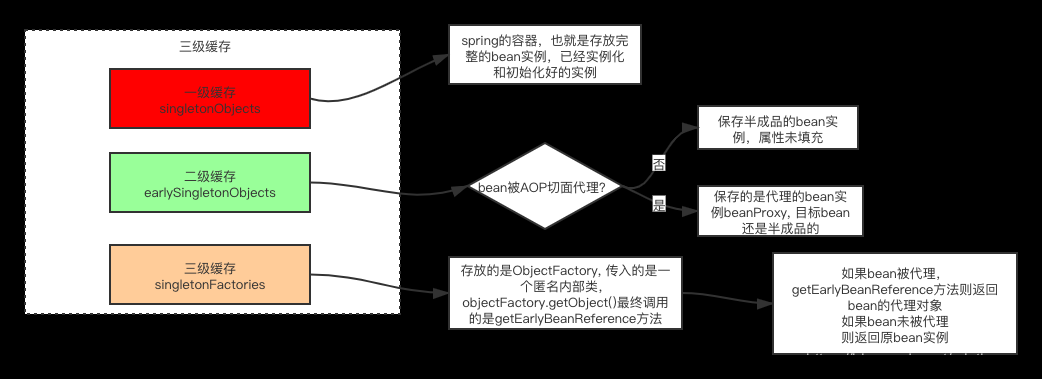
图5 Spring三级缓存
3.2. Spring源码之“获取Bean
接下来结合具体的Spring源码进行分析,首先分析“获取Bean”的源码,注意getSingleton()方法。
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {//第1级缓存 用于存放 已经属性赋值、完成初始化的 单例Beanprivate final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);//第2级缓存 用于存在已经实例化,还未做代理属性赋值操作的 单例Beanprivate final Map<String, Object> earlySingletonObjects = new HashMap<>(16);//第3级缓存 存储创建单例Bean的工厂private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);//已经注册的单例池里的beanNameprivate final Set<String> registeredSingletons = new LinkedHashSet<>(256);//正在创建中的beanName集合private final Set<String> singletonsCurrentlyInCreation =Collections.newSetFromMap(new ConcurrentHashMap<>(16));//缓存查找bean 如果第1级缓存没有,那么从第2级缓存获取。如果第2级缓存也没有,那么从第3级缓存创建,并放入第2级缓存。protected Object getSingleton(String beanName, boolean allowEarlyReference) {Object singletonObject = this.singletonObjects.get(beanName); //第1级if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {synchronized (this.singletonObjects) {singletonObject = this.earlySingletonObjects.get(beanName); //第2级if (singletonObject == null && allowEarlyReference) {//第3级缓存 在doCreateBean中创建了bean的实例后,封装ObjectFactory放入缓存的bean实例ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {//创建未赋值的beansingletonObject = singletonFactory.getObject();//放入到第2级缓存this.earlySingletonObjects.put(beanName, singletonObject);//从第3级缓存删除this.singletonFactories.remove(beanName);}}}}return singletonObject;} }3.3. Spring源码之“添加到第1级缓存”
其中“添加到第1级缓存”的源码为:
protected void addSingleton(String beanName, Object singletonObject) {synchronized (this.singletonObjects) {// 放入第1级缓存this.singletonObjects.put(beanName, singletonObject);// 从第3级缓存删除this.singletonFactories.remove(beanName);// 从第2级缓存删除this.earlySingletonObjects.remove(beanName);// 放入已注册的单例池里this.registeredSingletons.add(beanName);}}添加到“第3级缓存”的源码为:
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {synchronized (this.singletonObjects) {// 若第1级缓存没有bean实例if (!this.singletonObjects.containsKey(beanName)) {// 放入第3级缓存this.singletonFactories.put(beanName, singletonFactory);// 从第2级缓存删除,确保第2级缓存没有该beanthis.earlySingletonObjects.remove(beanName);// 放入已注册的单例池里this.registeredSingletons.add(beanName);}}}“创建Bean”的源码为下面所示,通过这段代码,我们可以知道:Spring 在实例化对象之后,就会为其创建一个 Bean 工厂,并将此工厂加入到三级缓存中。
因此,Spring 一开始提前暴露的并不是实例化的 Bean,而是将 Bean 包装起来的ObjectFactory。为什么要这么做呢?
这实际上涉及到 AOP。如果创建的 Bean 是有代理的,那么注入的就应该是代理 Bean,而不是原始的 Bean。但是,Spring一开始并不知道 Bean是否会有循环依赖,通常情况下(没有循环依赖的情况下),Spring 都会在“完成填充属性并且执行完初始化方法”之后再为其创建代理。但是,如果出现了循环依赖,Spring 就不得不为其提前创建"代理对象";否则,注入的就是一个原始对象,而不是代理对象。因此,这里就涉及到"应该在哪里提前创建代理对象。
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, Object[] args) throws BeanCreationException {BeanWrapper instanceWrapper = null;if (instanceWrapper == null) {//实例化对象instanceWrapper = this.createBeanInstance(beanName, mbd, args);}final Object bean = instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null;Class<?> beanType = instanceWrapper != null ? instanceWrapper.getWrappedClass() : null;//判断是否允许提前暴露对象,如果允许,则直接添加一个 ObjectFactory 到第3级缓存boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&isSingletonCurrentlyInCreation(beanName));if (earlySingletonExposure) {//添加到第3级缓存addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));}//填充属性this.populateBean(beanName, mbd, instanceWrapper);//执行初始化方法,并创建代理exposedObject = initializeBean(beanName, exposedObject, mbd);return exposedObject;
}Spring通过在ObjectFactory中去提前创建代理对象,该对象会执行getObject()方法来获取Bean。执行方法如下:
public abstract class AbstractAutoProxyCreator extends ProxyProcessorSupportimplements SmartInstantiationAwareBeanPostProcessor, BeanFactoryAware {@Overridepublic Object getEarlyBeanReference(Object bean, String beanName) {Object cacheKey = getCacheKey(bean.getClass(), beanName);// 记录已被代理的对象this.earlyProxyReferences.put(cacheKey, bean);return wrapIfNecessary(bean, beanName, cacheKey);}
}提前进行对象的代理工作,并在 earlyProxyReferences map中记录已被代理的对象,是为了避免在后面重复创建代理对象。
public abstract class AbstractAutoProxyCreator extends ProxyProcessorSupportimplements SmartInstantiationAwareBeanPostProcessor, BeanFactoryAware {@Overridepublic Object getEarlyBeanReference(Object bean, String beanName) {Object cacheKey = getCacheKey(bean.getClass(), beanName);// 记录已被代理的对象this.earlyProxyReferences.put(cacheKey, bean);return wrapIfNecessary(bean, beanName, cacheKey);}
}再次分析获取bean的方法getSingleton()方法,可知:提前暴露的对象,虽然已实例化,但是没有进行属性填充,还没有完成初始化,是一个不完整的对象。 这个对象存放在二级缓存中,对于三级缓存机制十分重要,是解决循环依赖一个非常巧妙的设计。接下来我们结合Spring缓存机制来分析上面Demo中A、B循环依赖。
◦A 调用doCreateBean()创建Bean对象:由于还未创建,从第1级缓存singletonObjects查不到,此时只是一个半成品(提前暴露的对象),放入第3级缓存singletonFactories。
◦A在属性填充时发现自己需要B对象,但是在三级缓存中均未发现B,于是创建B的半成品,放入第3级缓存singletonFactories。
◦B在属性填充时发现自己需要A对象,从第1级缓存singletonObjects和第2级缓存earlySingletonObjects中未发现A,但是在第3级缓存singletonFactories中发现A,将A放入第2级缓存earlySingletonObjects,同时从第3级缓存singletonFactories删除。
◦将A注入到对象B中。
◦B完成属性填充,执行初始化方法,将自己放入第1级缓存singletonObjects中(此时B是一个完整的对象),同时从第3级缓存singletonFactories和第2级缓存earlySingletonObjects中删除。
◦A得到“对象B的完整实例”,将B注入到A中。
◦A完成属性填充,执行初始化方法,并放入到第1级缓存singletonObjects中。
在创建过程中,都是从第三级缓存(对象工厂创建不完整对象),将提前暴露的对象放入到第二级缓存;从第二级缓存拿到后,完成初始化,并放入第一级缓存。
4. 总结
以上便是有关Spring如何利用缓存机制来解决循环依赖的学习和总结。