进程创建&fork函数
fork函数之前就已经提到,它从已存在进程中创建一个新进程,新进程为子进程,而原进程为父进程。
调用接口:fork()
头文件:unistd.h
功能:创建一个子进程,给子进程返回0,父进程返回子进程pid
#include<stdio.h>
#include<unistd.h>
int main()
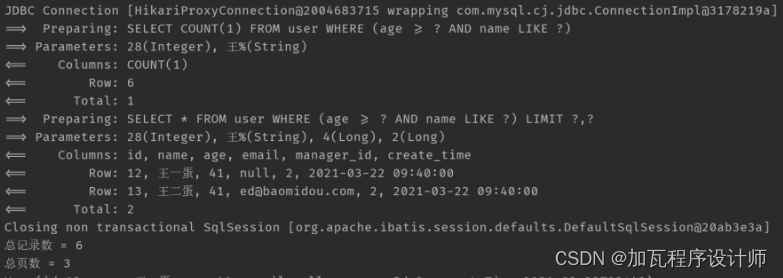
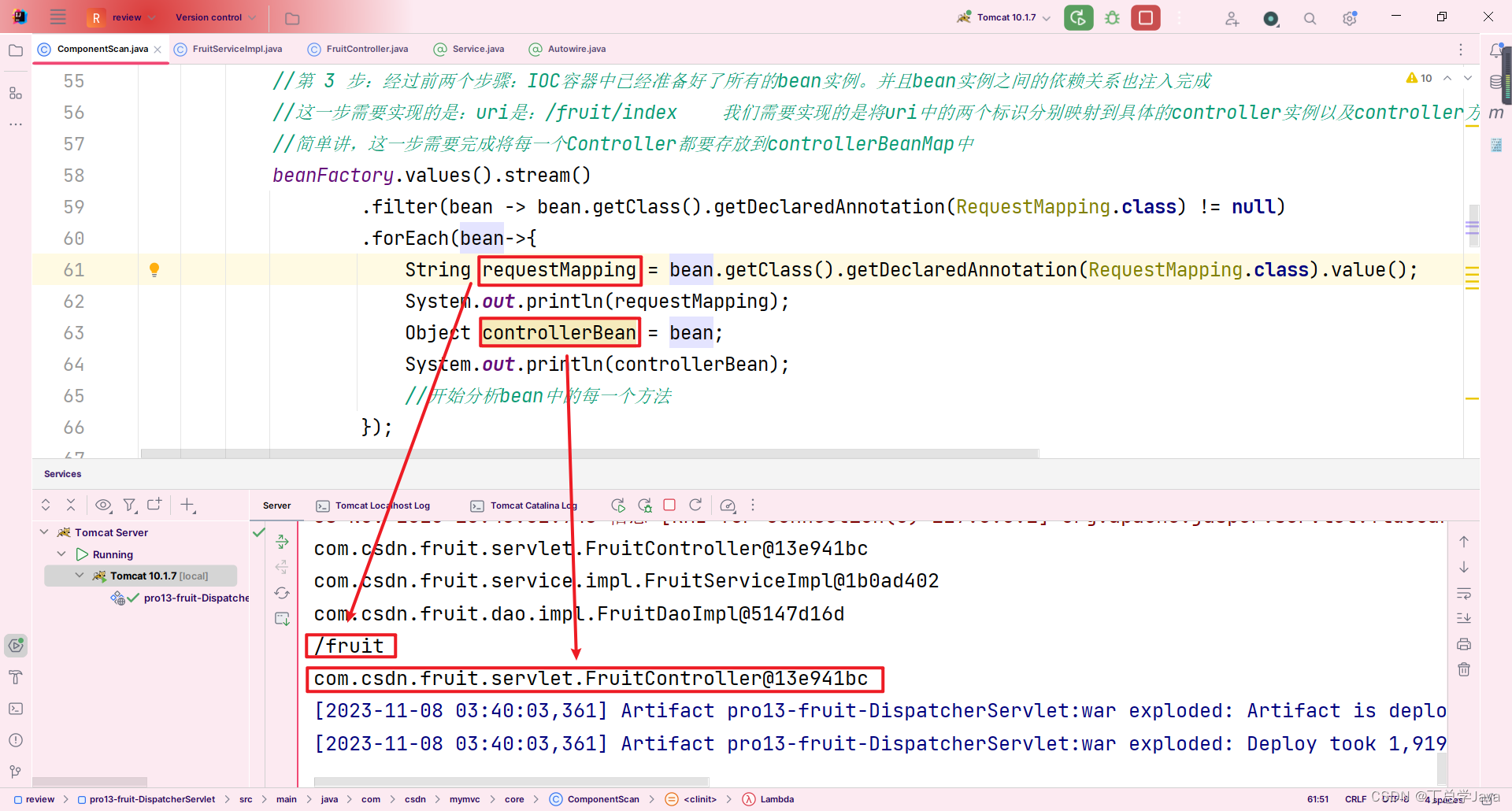
{printf("fork前当前进程的pid:%d\n", getpid());pid_t id = fork();if(id < 0){perror("fork");return 1; }printf("fork前当前进程的pid:%d,fork的返回值为:%d\n", getpid(), id);return 0;
}
进程调用fork,当控制转移到Linux内核中的fork代码后,内核做:
1.分配新的内存块和内核数据结构给子进程
2.将父进程部分数据结构内容拷贝至子进程
3.添加子进程到系统进程列表当中
4.fork返回,开始调度器调度
fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定,并不是一定要子进程或者父进程先执行。
进程控制的写时拷贝
我们还是需要理解fork的两个返回值是如何产生的,这就涉及到写时拷贝。
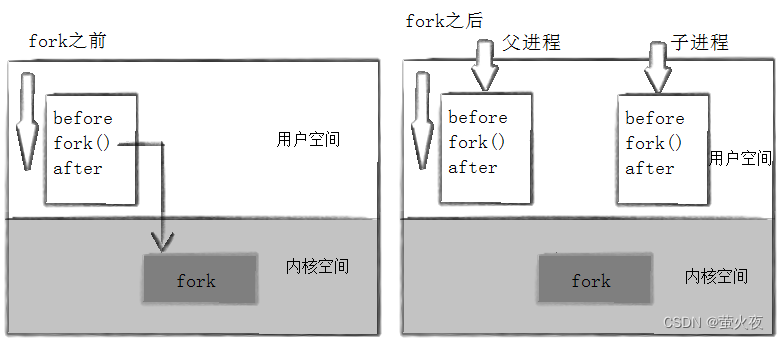
每一个进程都有其虚拟地址空间, 虚拟地址空间通过页表对应物理内存, 数据储存在物理内存中。
一个进程被创建后,操作系统会为其创建PCB和虚拟地址空间,建立页表映射并把代码数据拷贝到物理内存。此时一个进程就开始运行了,在fork后子进程被创建,子进程也拥有父进程相同的数据结构,原进程成为父进程。在父子进程都没有对物理内存中的数据进行修改时,两个进程的数据通过页表都会指向一块物理内存。但是一旦父子进程有其一修改了数据,为了保证进程的独立性,操作系统就会给父子进程中修改数据的那一个开辟新的物理内存,将数据拷贝到新空间再修改,同时页表也会改变物理空间的指向。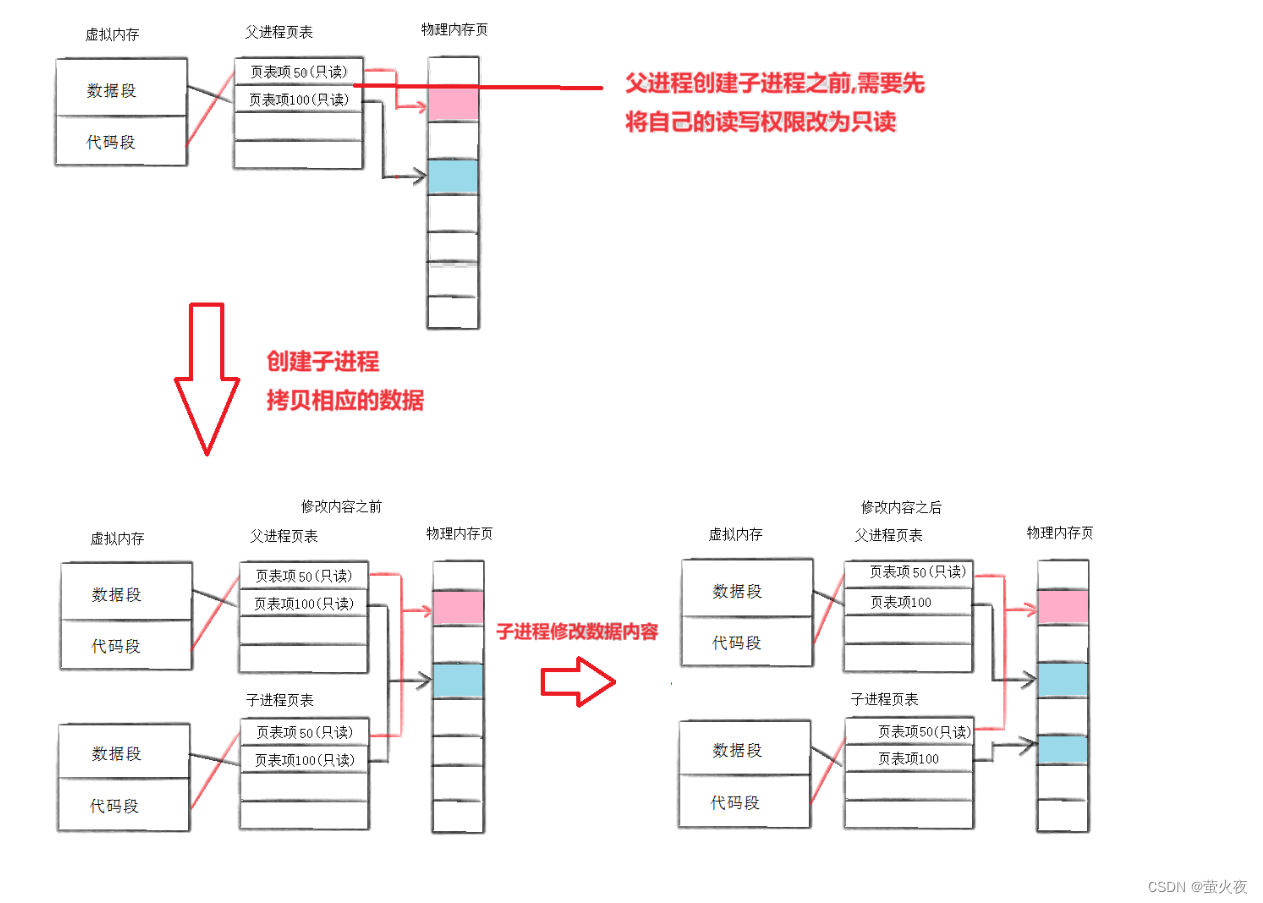
操作系统如何辨别进程要采取写时拷贝?
当父子进程任意一方想要进行修改的时候,操作系统必然需要为这个进程重新申请物理内存空间,然后将原来的数据拷贝一份到新申请的空间中,并且还需要修改页表的映射关系,所以操作系统需要对我们想要写入父进程或者子进程的数据的行为进行识别,以采取相应的措施。
结合上面的写时拷贝示意图,当用户需要对父进程或者子进程进行写入操作时,此时,由于父子进程的页表项的虚拟地址都是只读状态,用户的写入操作会和页表项的访问权限冲突,此时操作系统就可以识别这个行为,并将该行为识别为需要进行写时拷贝的信号.
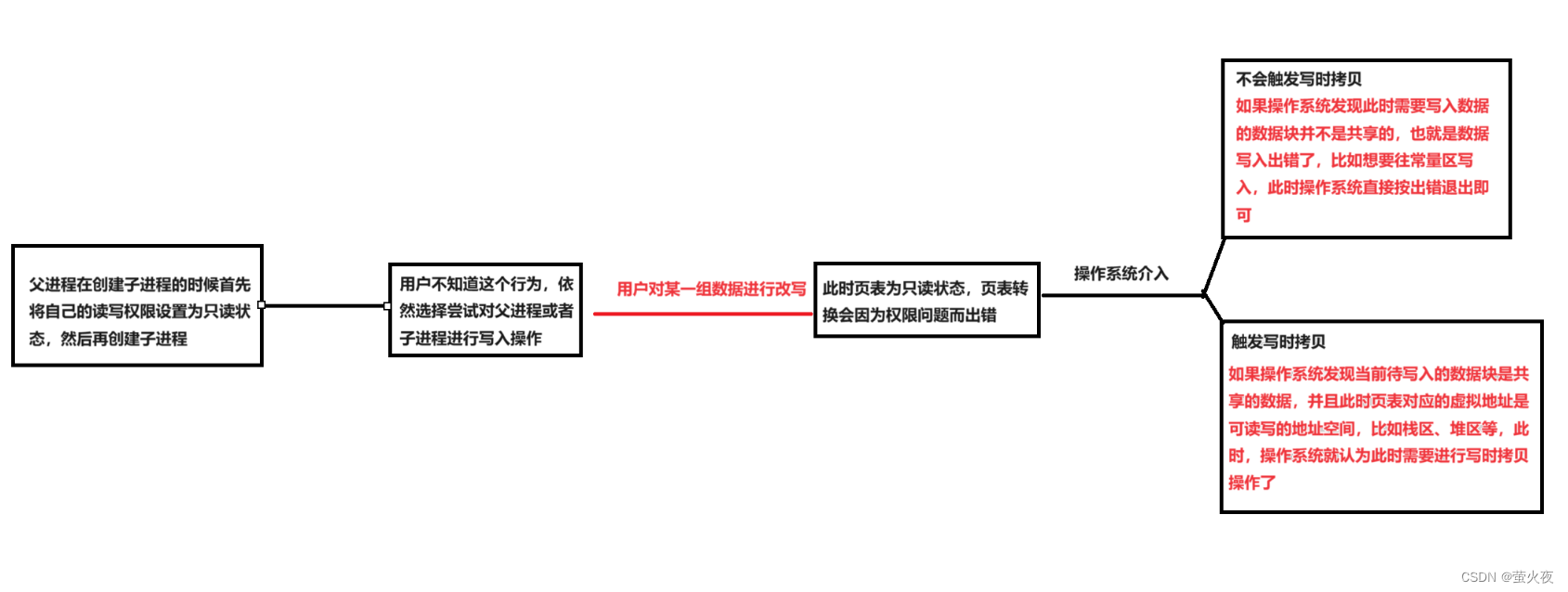
既然需要修改,为什么还要进行拷贝操作?
当我们需要写入的时候,不论父子进程,最终的目的都是需要修改该进程中的值,但是,为什么一定要将原进程的数据拷贝一份到需要修改的进程的新的物理内存处呢?按我们的想法,直接开辟一份大小和原进程一模一样的数据块,直接等待数据写入不就行了?为何要多此一举呢?
进行写时拷贝的内存往往不止一个变量,而是一个数据块,里面往往可能包含多个数据成员或者一个数据整体,比如结构体,链表等,一般情况下,我们不会修改全部的数据, 只是修改一小部分, 在写入之前拷贝, 可以尽可能的保存原始数据, 无需进行全部写入的操作。
进程终止
进程常见的退出场景一般有如下三种:
一: 进程正常退出
1.代码运行完毕,结果正确
2.代码运行完毕,结果不正确
二: 进程异常退出
代码异常终止
进程正常退出
错误码vs退出码
C语言中的退出码
我们在写main函数时,最后都要返回0,返回值为0表示成功,非零表示失败。一个进程,最终运行成功了(返回0),我们一般不会在对该进程的执行情况做过多的探究.
但是, 一旦进程最终运行异常退出了(返回非0), 我们就想想方设法的搞清楚这个进程为什么会异常退出, 是哪里的原因导致异常退出, 这也就导致了进程异常退出会被分为多种情况类型,每种情况类型的异常状态都不同, 借此来反应异常的原因。我们main函数的返回值, 都叫做退出码。
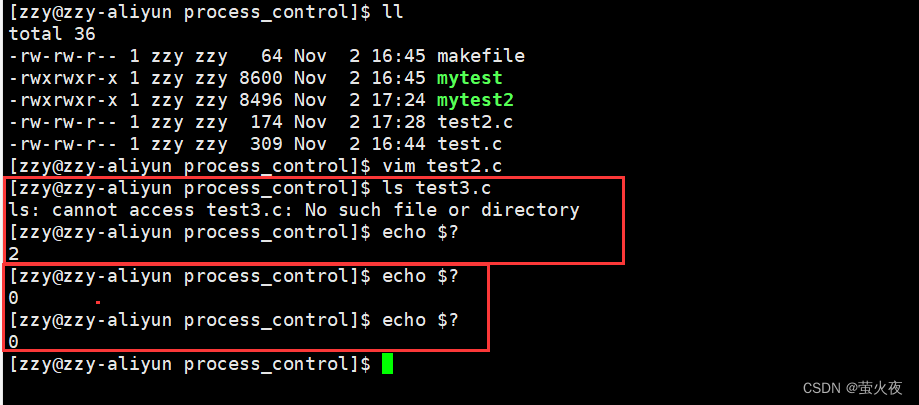
我们可以通过 echo $? 命令来查看最近的一个子进程的退出码,其中?保存的是最近一个进程退出的退出码:
C语言中内置了一些退出码,用不同的数字表示不同的退出码的解释,其包含在头文件string.h里面的strerror函数中,我们可以试着将其打印出来:
1 #include<stdio.h>2 #include<string.h>3 4 int main()5 {6 int i = 0;7 for(;i<150;i++)8 {9 printf("%d: %s\n",i,strerror(i)); 10 }11 return 0;12 }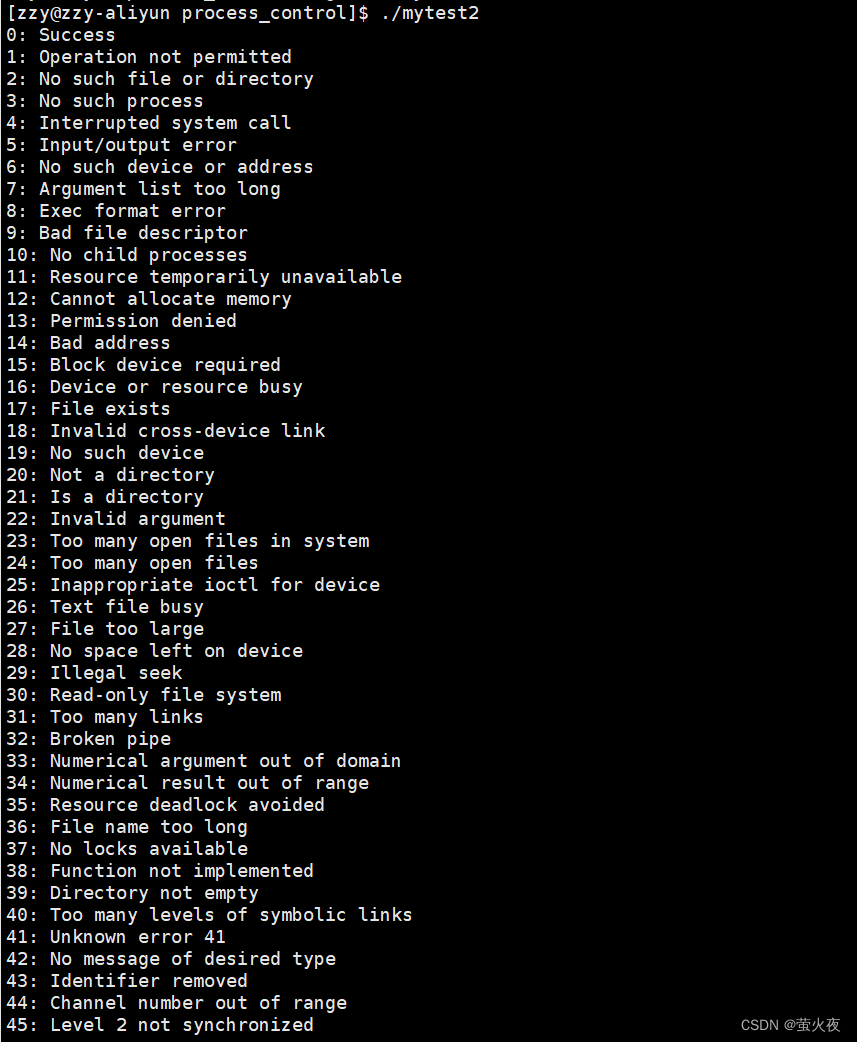
C语言中的错误码
C语言中有一个内置的全局变量errno,该变量专门用来保存最后一次调用的函数或者系统调用出错返回的错误码,这个错误码和我们的退出码是相同的,只是用专门的变量来保存,当然也可以用strerrno函数来打印出这个错误。但是需要注意,errno的使用,需要包含errno.h头文件。
perror是C语言中常用的关于错误的函数
perror函数总是和errno搭配在一起,此函数会输出errno错误码对应的错误信息,并且,perror的参数代表是哪个地方有问题,是用户自己决定的!
比如我们通常这样来写一段代码:
1 #include <stdio.h> 2 #include <stdlib.h> 3 int main() 4 { 5 FILE* fp = fopen("non-existent.txt","r");6 if(fp==NULL) 7 { 8 perror("fopen"); 9 exit(1); 10 } 11 } 
注意:打印出来的信息中,前面的fopen:是用户输入的信息,后面的语句是errno错误码对应的错误信息
总结:
退出码通常是一个进程退出的时候, 它的退出结果,
错误码是用来衡量库函数或者是系统调用函数的调用情况.
两者都是当失败的时候, 用来衡量函数,进程出错时的详细原因.
进程异常终止
进程出异常,本质上是收到了信号,自己终止了进程,此时虽然也有退出码,但是此时的退出码已经没有意义。比如我们熟知的杀死进程的指令: kill -9, 该命令其实就是一个信号,当进程收到这样的一个信号,就会自己停止并退出进程。我们常见的一些信号如下:
 上面的这些信号,每一种信号都有对应的数字, 当我们的代码出现了问题导致无法正常执行, 操作系统就会给我们的进程发送指定的信号, 进程收到指定的信号之后, 就会对应的停止我们进程并返回错误原因,既然是这样的话,也就是说,一个正常的代码,在运行过程中,只要收到了信号,该进程就会立即响应并退出,我们来验证一下,
上面的这些信号,每一种信号都有对应的数字, 当我们的代码出现了问题导致无法正常执行, 操作系统就会给我们的进程发送指定的信号, 进程收到指定的信号之后, 就会对应的停止我们进程并返回错误原因,既然是这样的话,也就是说,一个正常的代码,在运行过程中,只要收到了信号,该进程就会立即响应并退出,我们来验证一下,
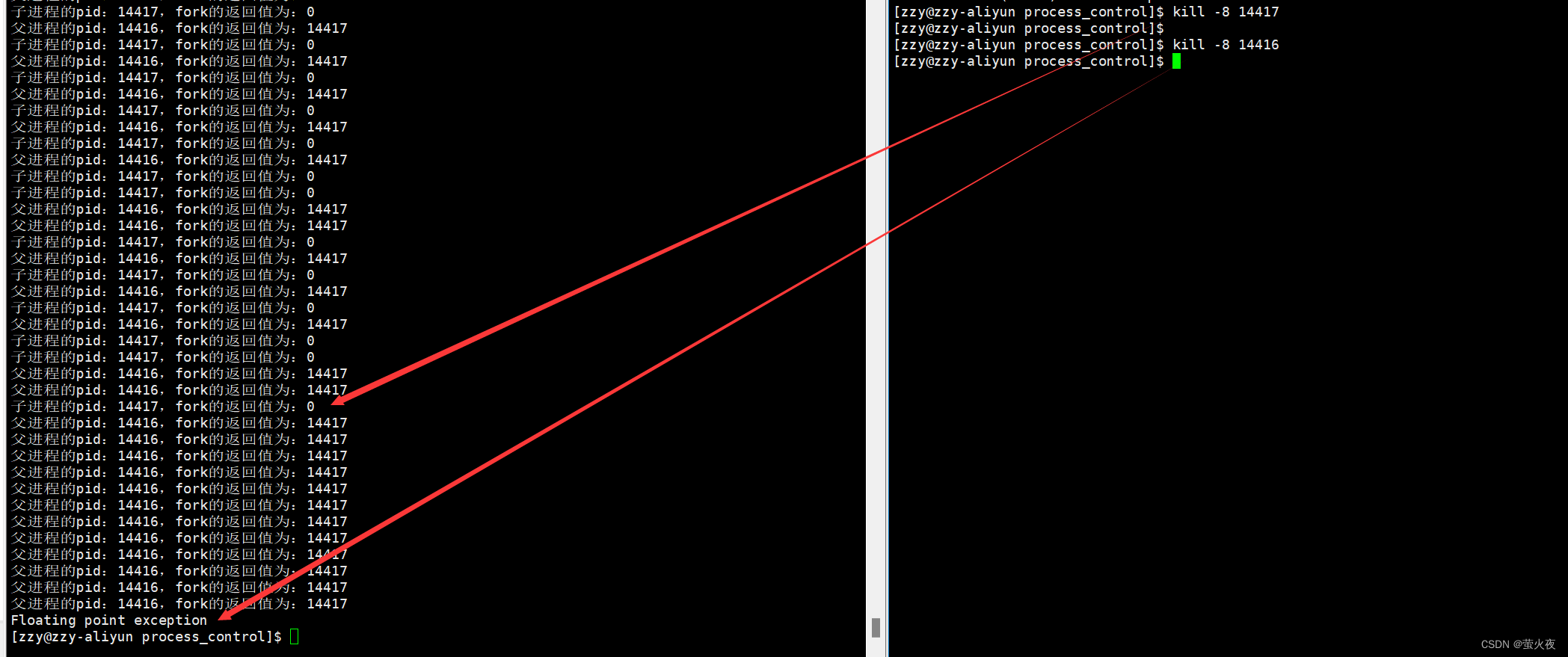
使用kill命令传递信号,只要进程接收到了信号,不论进程是否真的发生了这个错误,都会按这个信号对应的信号退出, 异常后fork创建的子进程没有回显, 而父进程显示错误信息, 因为此父进程的父进程是bash会对错误信息做处理, fork创建的子进程的父进程并没有对相应的信号作处理, 所以不会显示信息.
总结:

exit()和_exit()
exit的参数即为错误码,和main函数的return值是一个意思
exit函数和return的区别:
return只有在main中使用时才代表此进程退出
exit函数在程序任一地方使用都可以直接退出程序,并且返回错误码
man的2号手册可以看见_exit系统调用, 3号手册可以看到exit, 这也说明exit()是一个C语言的库函数,而_exit()是一个系统调用,在本质上exit()是_exit()的封装,exit()会比_exit()多做一些事情。
下面两个打印函数都没有提前刷新缓冲区:
#include<stdio.h>
int main()
{printf("hello world");exit(0);
}
//运行结果:前几秒不动,后几秒打印hello world#include<stdio.h>
int main()
{printf("hello world");_exit(0);
}
//运行结果:不会打印hello world,过几秒程序直接退出到这里我们认识到:exit函数终止进程也主动刷新缓冲区,_exit终止进程且不会刷新缓冲区。
同时缓冲区也不集成在操作系统中: 如果缓冲区真的在操作系统中, 那么不管是exit还是_exit都会刷新缓冲区,(退出就要清除该进程的所有数据和代码,如果在操作系统内那缓冲区的内容也不能留下)而是在用户级的缓存区,具体在IO部分再说。
前面说到exit是_exit的封装, 但exit在调用_exit之前, 还做了其他工作:
(1)执行用户通过 atexit或on_exit定义的清理函数。
(2)关闭所有打开的流,所有的缓存数据均被写入
(3)调用_exit退出该进程
进程等待
什么是进程等待
如果子进程结束父进程没有对子进程进行处理的话, 子进程就会变成一个僵尸进程处于这个状态的进程无法被kill指令杀死因为你无法杀死一个已经死去的进程, 虽然这个进程的数据和代码已经被操作系统删除, 但是该进程的PCB中还存储着各种退出信息所以它还一直存储在内存中等待着被父进程处理
如果父进程一直运行并且不进行处理话那么这就是一个内存泄漏的现象因为PCB也是占空间的, 所以为了解决内存泄漏的问题为了查看进程的运行结果如何就有了进程等待这个东西, 它可以释放PCB所占用的空间, 并且还会读取PCB中的数据拿到子进程的退出信息.
实现进程等待有两个方式: 一个是调用wait函数另外一个是waitpid函数, 这两个函数都可以处理子进程, 但是他们的用法和处理的方式不同, 那么接下来看看这两个函数的用法:
进程等待的方式
wait函数
调用接口:pid_t wait(int*status);
头文件:sys/types.h、sys/wait.h
参数:status是输出型参数, 用来接收子进程返回的退出码和信号
功能:获取子进程退出状态,并保存在status变量中,不关心则可以传空指针。等待成功返回被等待进程pid,失败返回-1
这个函数用到两个头文件并且该函数的返回值类型为pid_t,当进程等待成功之后wait函数就会返回等待的子进程pid, wait函数的作用是读取子进程的退出信息, 所以我们需要传给他一个参数用来记录他读取的信息, 并且这个参数的类型是一个整型指针, 如果不想读取子进程的运行结果的话就可以直接传递一个空指针给这个函数
在linux上运行如下代码:
1 #include <stdio.h>2 #include <unistd.h>3 #include <stdlib.h>4 #include <sys/types.h>5 #include <sys/wait.h>6 7 int main()8 {9 pid_t id = fork();10 if(id == 0)11 {12 int cnt = 5;13 while(cnt)//子进程睡眠一秒打印一次,共五次 14 {15 printf("我是子进程: %d, 父进程: %d, cnt: %d\n", getpid(), getppid(), cnt--); 16 sleep(1);17 }18 exit(0);//退出19 }20 sleep(10); //父进程睡眠10秒 21 pid_t ret = wait(NULL);22 if(id > 0)23 {24 printf("wait success: %d", ret);25 } 26 }
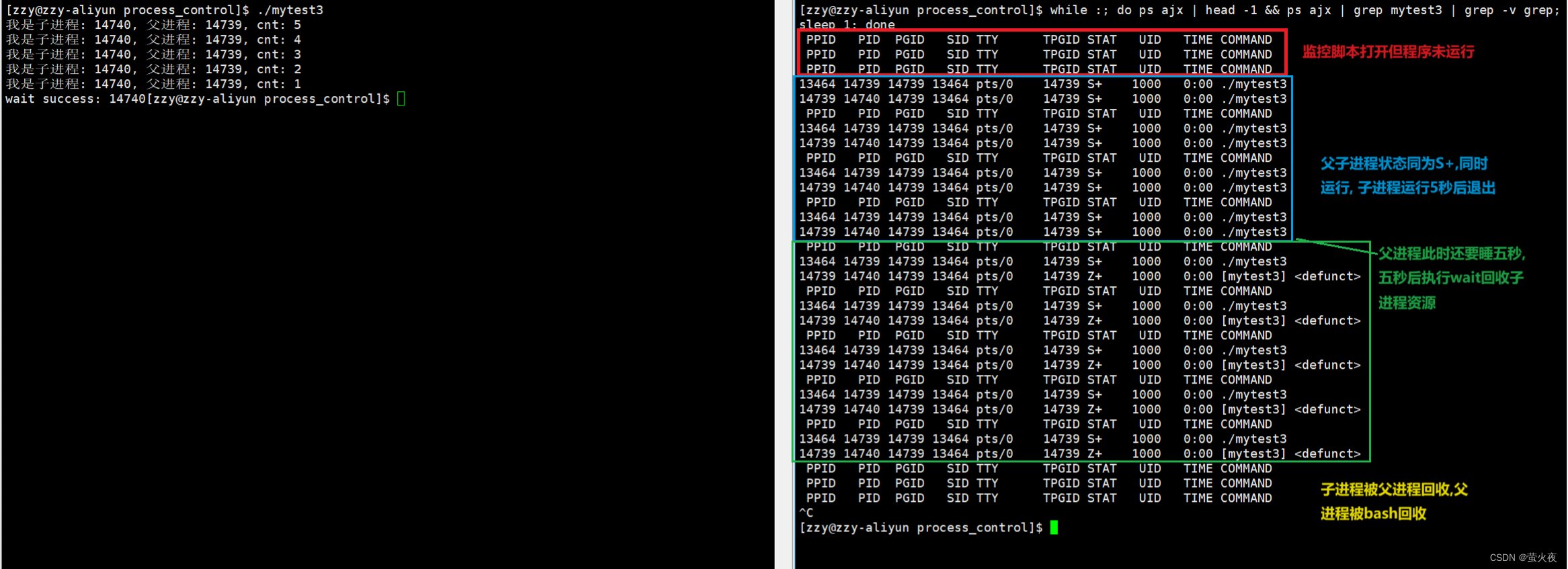
首先通过fork函数创建子进程, 然后通过if else语句让父子进程执行后序代码的不同部分
子进程执行首先经历while循环,该循环会执行5次内部的内容每次都打印一句话并且休眠一秒, 循环结束之后就调用exit函数来结束子进程, 所以子进程的执行时间为5秒。
父进程执行首先执行sleep函数将父进程休眠10秒, 然后再使用wait函数将子进程的内容进行回收并根据变量id值来判断是否回收成功, 所以子进程在前10秒钟会是阻塞状态, 执行完代码之后(5秒后)子进程就结束了, 由于此时的父进程还在休眠没有对子进程的PCB进行处理,所以子进程就由阻塞状态变成了僵尸状态, 等父进程的sleep函数执行完之后就会调用wait函数对子进程进行回收, 所以这时子进程就会由僵尸状态变成了死亡状态, 然后屏幕上就会打印wati success.
wait函数可以帮助我们回收已经结束的子进程, 并且父进程使用wait函数回收子进程时采用的是阻塞式等待的方式也就是说当父进程执行到wait函数时如果子进程没有运行结束, 那么父进程就会一直在那里等着, 直到子进程运行结束wait函数将子进程处理完才执行父进程剩下的代码.
注意:当内存中存在多个子进程时wait函数回收的就是最先结束的子进程
waitpid函数
调用接口: pid_ t waitpid(pid_t pid, int *status, int options);
头文件: sys/types.h、sys/wait.h
参数:
1.pid表示需要等待的进程的pid值,pid可以传指定进程的pid, 也可以传-1表示等待任意一个进程。
2.status是输出型参数该函数会将读到的信息全部放到这个参数里面,与wait函数一样如果不想获取退出信息的话这里的参数就传空指针
3.options表示等待方式, 如果你想使用阻塞等待的话就传0, 如果想要非阻塞等待的话这里就传WNOHANG (理解为不夯住) 阻塞等待和非阻塞等待下面会说, 现在统一用阻塞等待.
功能: 回收指定pid的进程数据

status不能只是看作一个32比特位整型值, 它的不同位置都有它的作用, 我们只看它的后16位, 也就是次低位和低位。
首先明确一下什么是高位和低位:
例如:00000000 00000000 00000000 00000000
高位 次高位 次低位 低位
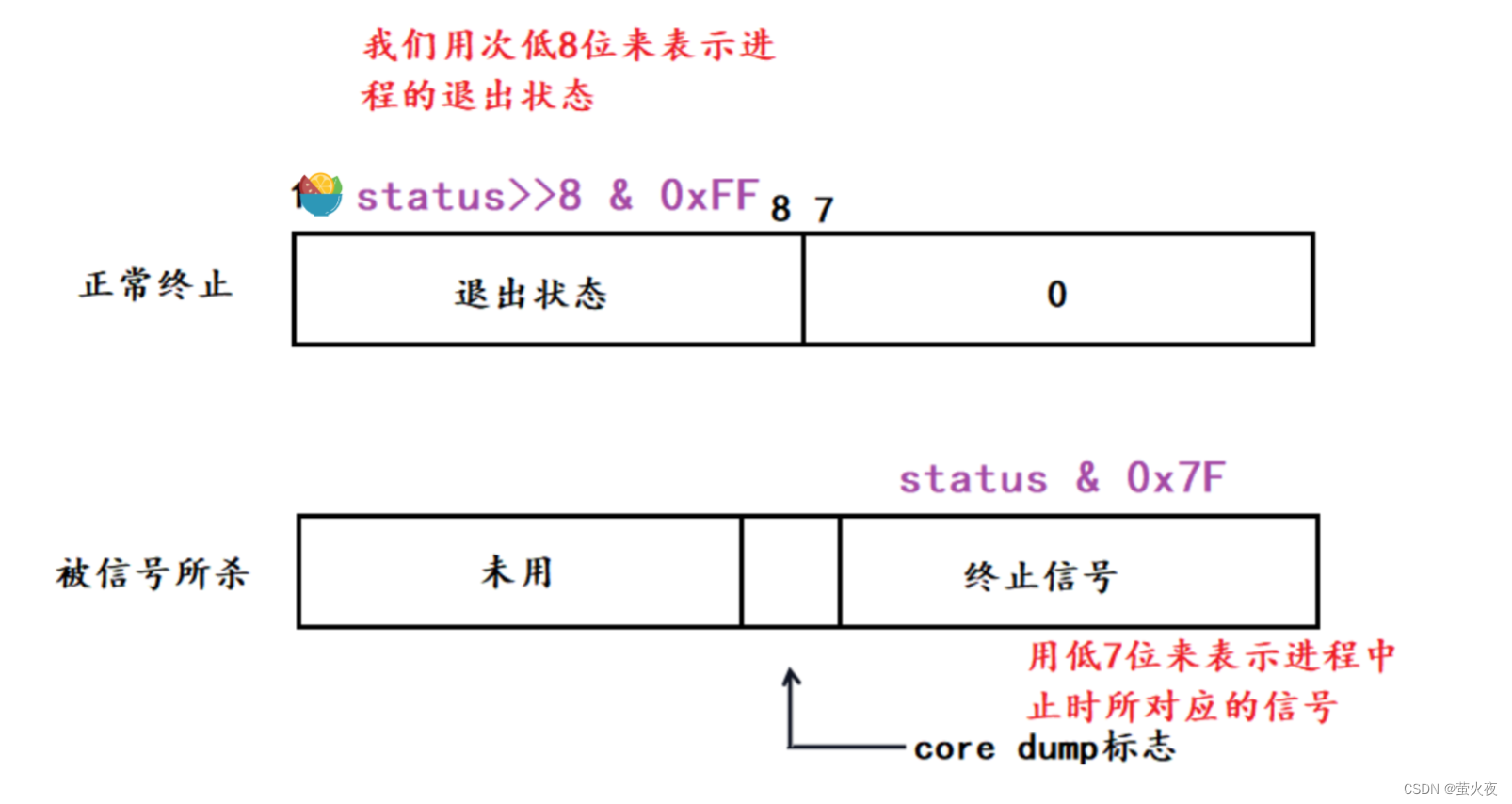
如果进程是被传入的信号终止的(异常终止), 那么传递来的这个信号的代号会被保存在status的低八位中, 从左向右数第一位保存core dump标志(暂时不管), 剩下的七位保存这个终止的信号代码, 如果没有终止信号默认就为0.
如果进程可以正常终止, status的的次低八位用于保存退出状态, 进程如果异常终止, 这八位的值是不确定的, 也就是无意义.
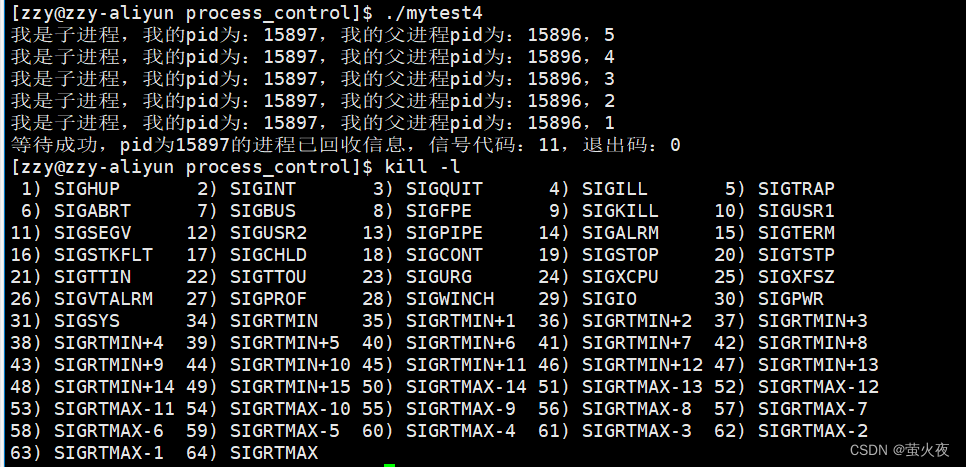
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h>4 #include<sys/wait.h>5 #include<stdlib.h>6 int main()7 {8 pid_t id = fork();9 if(id == 0)10 {11 int cnt = 5;12 while(cnt)13 {14 printf("我是子进程,我的pid为:%d,我的父进程pid为:%d,%d\n", getpid(), getppid(), cnt--);15 sleep(1);16 }17 int* p = NULL;18 *p = 10;19 exit(0);20 }21 sleep(8); 22 int status = 0;23 pid_t ret = waitpid(id, &status, 0);//options传0表示阻塞式等待24 if(id > 0)25 {26 printf("等待成功,pid为%d的进程已回收信息,信号代码:%d,退出码:%d\n", ret, (status & 0x7f), (st atus >> 8) & 0xff);27 }28 sleep(2);29 return 0;30 }
(status & 0x7f): 0x7f是二进制的1111111, 将status的低位后七位按位与1111111即可得到退出状态码
(status >> 8) & 0xff): 0xff是二进制的11111111, 将status的次低位全部挪到低位再按位与1111111即可得到退出状态码
这里很明显看到程序收到信号退出, 信号的代码为11表示野指针, 下面的kill表格有对应, 退出码也存在但是没有信息价值.
上面获取退出码和信号代码需要手动进行位运算获取,用宏可以更方便的进行退出信息的处理:
1.WIFEXITED(status) 若此值为非0 表明进程正常结束。
若上宏为真,此时可通过WEXITSTATUS(status)获取进程退出状态(exit时参数)
修改一下代码:
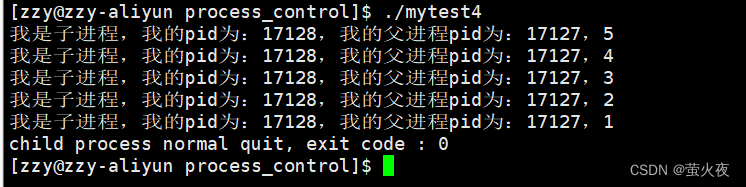
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h>4 #include<sys/wait.h>5 #include<stdlib.h>6 int main()7 {8 pid_t id = fork();9 if(id == 0)10 {11 //child12 int cnt = 5;13 while(cnt)14 {15 printf("我是子进程,我的pid为:%d,我的父进程pid为:%d,%d\n", getpid(), getppid(), cnt--);16 sleep(1);17 }18 int* p = NULL;19 *p = 10;20 exit(0);21 }22 else 23 {24 //father25 sleep(8);26 int status = 0;27 pid_t ret = waitpid(id, &status, 0);//options传0表示阻塞式等待28 if(ret == id)29 {30 31 //printf("等待成功,pid为%d的进程已回收信息,信号代码:%d,退出码:%d\n", ret, (status & 0x7f ), (status >> 8) & 0xff); 32 if(WIFEXITED(status))33 { 34 printf("child process normal quit, exit code : %d\n", WEXITSTATUS(status));35 }36 else37 {38 printf("child process quit except!\n");39 }40 }41 }42 return 0;43 }
程序异常退出:

如果把解引用空指针注释掉,程序正常退出:
2. WIFSIGNALED(status)为非0 表明进程异常终止。
若上宏为真,此时可通过WTERMSIG(status)获取使得进程退出的信号编号
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h> 4 #include<sys/wait.h> 5 #include<stdlib.h> 6 int main() 7 { 8 pid_t id = fork(); 9 if(id == 0) 10 { 11 //child 12 int cnt = 5; 13 while(cnt) 14 { 15 printf("我是子进程,我的pid为:%d,我的父进程pid为:%d,%d\n", getpid(), getppid(), cnt--); 16 sleep(1); 17 } 18 int* p = NULL;19 *p = 10; 20 exit(0); 21 } 22 else 23 { 24 //father 25 sleep(8); 26 int status = 0; 27 pid_t ret = waitpid(id, &status, 0);//options传0表示阻塞式等待28 if(ret == id) 29 { 32 if(WIFEXITED(status))33 { 34 printf("child process normal quit, exit code : %d\n", WEXITSTATUS(status));35 } 37 if(WIFSIGNALED(status))//因为某种信号中断获取状态38 { 39 printf("child killed by %d\n", WTERMSIG(status));40 }41 42 }43 }44 return 0; 45 } 程序异常退出:
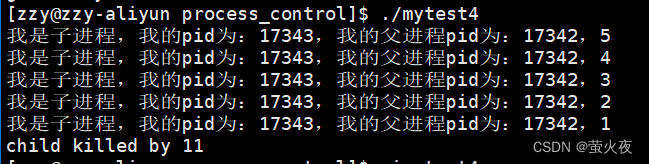
总结: 如果子进程已经退出(变为Z状态), 调用wait/waitpid时,wait/waitpid会立即返回 ,并且释放资源, 获得子进程退出信息。
如果在子进程存在且正常运行时调用wait/waitpid, 则父进程可能会阻塞(options为0进行阻塞式等待)。如果等待失败比如不存在该子进程, 则立即出错返回-1。
阻塞式等待与非阻塞式等待
阻塞等待处理子进程就是如果子进程没有运行完, 那么父进程就会一直卡在wait函数或者waitpid函数那里, 这样做的话会影响父进程的效率.
为了解决这个问题就有了一个新的处理进程的方式叫做非阻塞等待:
当子进程没有退出时父进程不会一直卡在waitpid函数那里, 而是继续往下执行其他的代码并且这个函数就会返回0(如果子进程结束了这个函数就会返回子进程的pid)。
举个例子:
比如小明平时用手机给其他人打电话, 这里打电话就有两个方式一个是一直打电话并且不挂断电话,默认在通话的时候手机不能干其他事情, 如果我手机想干其他事情的话就只能等待对方跟我说我好了我们出发吧, 这时再挂断电话用手机去干其他事情, 那么这种情况就相当于阻塞等待,父进程的wait或者waitpid函数只能等着子进程运行完才能去干其他事情.
还有一种情况就是隔一段时间打一个电话, 比如说现在打一个电话问好了没?他跟我说没好, 这时就挂断电话用手机去干其他事情,过了10分钟再打电话问好了没, 他说没好的话就再挂断电话用手机去干其他的事情, 过10分钟再打一个电话问好了没这样不停的循环下去,这就是非阻塞等待, 当发现子进程还在运行时父进程就去干其他的事情不会一直在那等着, 这样就可以提高父进程的效率不会占用父进程的资源.
简单来说是:
阻塞等待就是父进程在子进程终止之前什么事情也不做, 就干等着子进程工作。
非阻塞等待就是父进程干活期间, 过来看一眼, 子进程如果还没终止父进程就自己干自己的事情,子进程如果终止了就回收子进程。由于我们应用中的非阻塞等待大部分不止一次,所以这种多次非阻塞等待也叫轮询。
阻塞式等待时, 父进程一直盯着子进程导致自己也无法进行下一步工作。而轮询的非阻塞等待中父进程除了定期来查看子进程情况, 剩下的时间还是可以干自己的时间较短的任务, 这样就提高了效率。
我们可以通过下面的代码来看看非阻塞等待的使用:
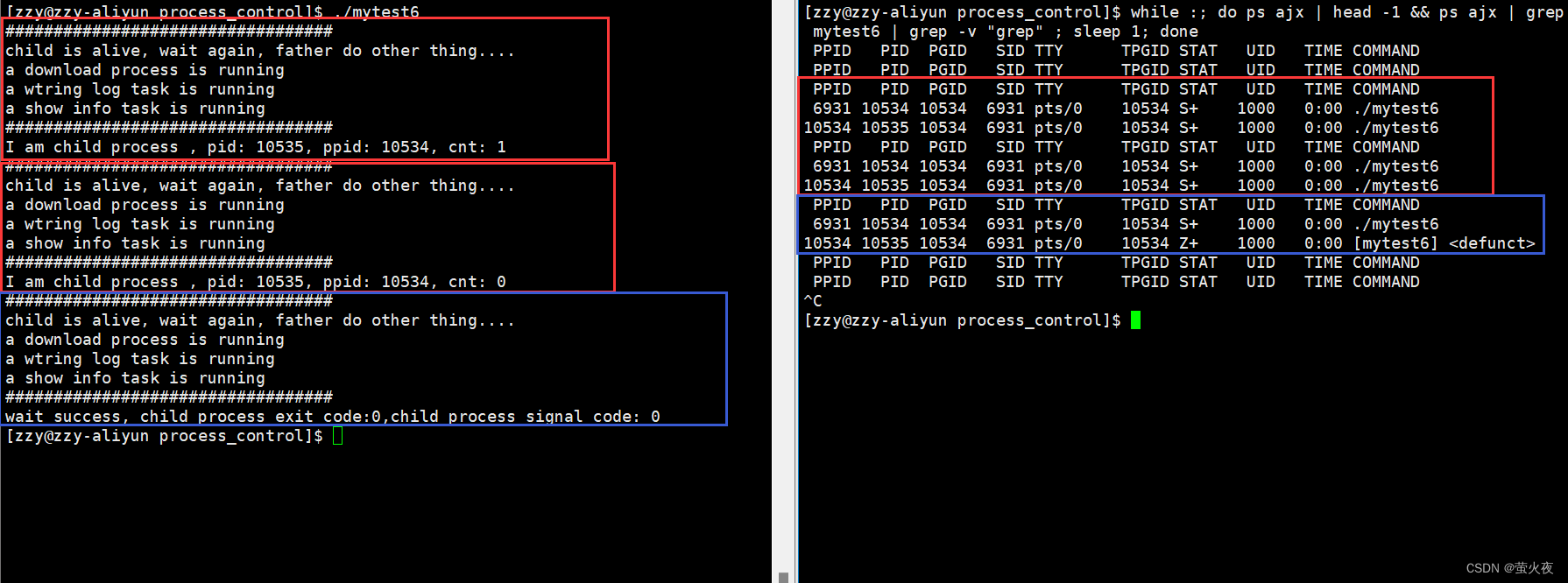
我们可以看到这里通过循环的方式不停的查看子进程运行的状态, 当子进程还在运行时父进程就可以执行其他的事情, 这里创建了一个函数指针数组, 数组的每个元素都指向一个函数, 在父进程等待子进程的时候就可以执行数组中的函数来执行其他的功能, 一旦子进程运行结束wait成功ret大于0,break结束循环.
如果非阻塞式等待父进程不轮询,而只等待一次呢?
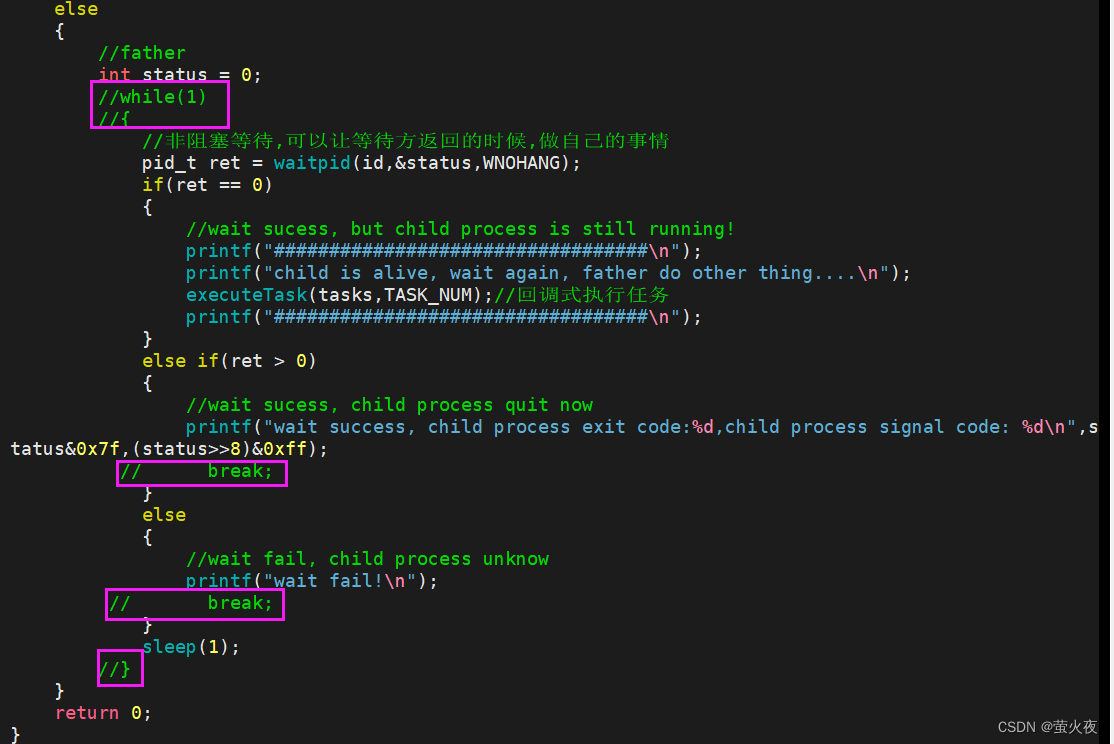
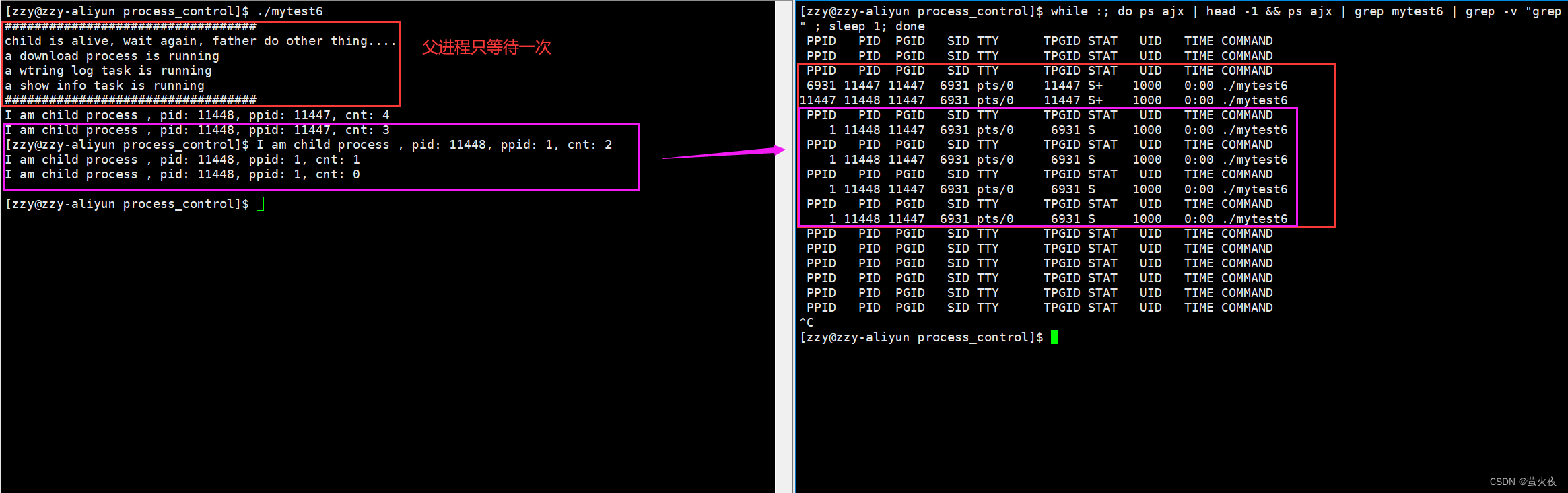
父进程只等待了一次就返回了, 后几个进程就都变成了孤儿进程, 托管给了bash.