LLama2是meta最新开源的语言大模型,训练数据集2万亿token,上下文长度由llama的2048扩展到4096,可以理解和生成更长的文本,包括7B、13B和70B三个模型,在各种基准集的测试上表现突出,该模型可用于研究和商业用途。
LLama2模型权重和tokenizer下载需要申请访问。
申请链接:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
由于下载的原始LLama2模型权重文件不能直接调用huggingface的transformers库进行使用,如果要使用huggingface transformer训练LLaMA2,需要使用额外的转换脚本。
转换脚本:https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py
现在huggingface上已发布了llama的hf版本,可以直接使用。
现在介绍LLama2模型的原始权重获取和转换脚本。
LLama2模型原始权重获取
在MetaAI申请通过后将会在邮件中提及到PRESIGNED_URL,运行download.sh,按照提示输入即可。
set -eread -p "Enter the URL from email: " PRESIGNED_URL
echo ""
read -p "Enter the list of models to download without spaces (7B,13B,70B,7B-chat,13B-chat,70B-chat), or press Enter for all: " MODEL_SIZE
TARGET_FOLDER="../target/file" # where all files should end up
mkdir -p ${TARGET_FOLDER}if [[ $MODEL_SIZE == "" ]]; thenMODEL_SIZE="7B,13B,70B,7B-chat,13B-chat,70B-chat"
fiecho "Downloading LICENSE and Acceptable Usage Policy"
wget --continue ${PRESIGNED_URL/'*'/"LICENSE"} -O ${TARGET_FOLDER}"/LICENSE"
wget --continue ${PRESIGNED_URL/'*'/"USE_POLICY.md"} -O ${TARGET_FOLDER}"/USE_POLICY.md"echo "Downloading tokenizer"
wget --continue ${PRESIGNED_URL/'*'/"tokenizer.model"} -O ${TARGET_FOLDER}"/tokenizer.model"
wget --continue ${PRESIGNED_URL/'*'/"tokenizer_checklist.chk"} -O ${TARGET_FOLDER}"/tokenizer_checklist.chk"
CPU_ARCH=$(uname -m)if [ "$CPU_ARCH" = "arm64" ]; then(cd ${TARGET_FOLDER} && md5 tokenizer_checklist.chk)else(cd ${TARGET_FOLDER} && md5sum -c tokenizer_checklist.chk)fifor m in ${MODEL_SIZE//,/ }
doif [[ $m == "7B" ]]; thenSHARD=0MODEL_PATH="llama-2-7b"elif [[ $m == "7B-chat" ]]; thenSHARD=0MODEL_PATH="llama-2-7b-chat"elif [[ $m == "13B" ]]; thenSHARD=1MODEL_PATH="llama-2-13b"elif [[ $m == "13B-chat" ]]; thenSHARD=1MODEL_PATH="llama-2-13b-chat"elif [[ $m == "70B" ]]; thenSHARD=7MODEL_PATH="llama-2-70b"elif [[ $m == "70B-chat" ]]; thenSHARD=7MODEL_PATH="llama-2-70b-chat"fiecho "Downloading ${MODEL_PATH}"mkdir -p ${TARGET_FOLDER}"/${MODEL_PATH}"for s in $(seq -f "0%g" 0 ${SHARD})dowget ${PRESIGNED_URL/'*'/"${MODEL_PATH}/consolidated.${s}.pth"} -O ${TARGET_FOLDER}"/${MODEL_PATH}/consolidated.${s}.pth"donewget --continue ${PRESIGNED_URL/'*'/"${MODEL_PATH}/params.json"} -O ${TARGET_FOLDER}"/${MODEL_PATH}/params.json"wget --continue ${PRESIGNED_URL/'*'/"${MODEL_PATH}/checklist.chk"} -O ${TARGET_FOLDER}"/${MODEL_PATH}/checklist.chk"echo "Checking checksums"if [ "$CPU_ARCH" = "arm64" ]; then(cd ${TARGET_FOLDER}"/${MODEL_PATH}" && md5 checklist.chk)else(cd ${TARGET_FOLDER}"/${MODEL_PATH}" && md5sum -c checklist.chk)fi
done
运行download.sh:
sh download.sh
代码注释
# 导入包
import argparse
import gc
import json
import os
import shutil
import warnings
import torch
from transformers import LlamaConfig, LlamaForCausalLM, LlamaTokenizer# 判断LlamaTokenizerFast是否可用,LlamaTokenizerFast可以加速tokenization
try:from transformers import LlamaTokenizerFast
except ImportError as e:warnings.warn(e)warnings.warn("The converted tokenizer will be the `slow` tokenizer. To use the fast, update your `tokenizers` library and re-run the tokenizer conversion")LlamaTokenizerFast = None# 不同版本的LLama模型的分片数目
NUM_SHARDS = {"7B": 1,"7Bf": 1,"13B": 2,"13Bf": 2,"34B": 4,"30B": 4,"65B": 8,"70B": 8,"70Bf": 8,
}# 计算中间层大小,优化计算效率
def compute_intermediate_size(n, ffn_dim_multiplier=1, multiple_of=256):return multiple_of * ((int(ffn_dim_multiplier * int(8 * n / 3)) + multiple_of - 1) // multiple_of)# 读取json文件
def read_json(path):with open(path, "r") as f:return json.load(f)# 写入json文件
def write_json(text, path):with open(path, "w") as f:json.dump(text, f)def write_model(model_path, input_base_path, model_size, tokenizer_path=None, safe_serialization=True):# 检查参数文件路径if not os.path.isfile(os.path.join(input_base_path, "params.json")):input_base_path = os.path.join(input_base_path, model_size)# 创建模型临时保存目录os.makedirs(model_path, exist_ok=True)tmp_model_path = os.path.join(model_path, "tmp")os.makedirs(tmp_model_path, exist_ok=True)# 读取参数params = read_json(os.path.join(input_base_path, "params.json"))num_shards = NUM_SHARDS[model_size]n_layers = params["n_layers"]n_heads = params["n_heads"]n_heads_per_shard = n_heads // num_shardsdim = params["dim"]dims_per_head = dim // n_headsbase = params.get("rope_theta", 10000.0)inv_freq = 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))if base > 10000.0:max_position_embeddings = 16384else:max_position_embeddings = 2048# 初始化tokenizertokenizer_class = LlamaTokenizer if LlamaTokenizerFast is None else LlamaTokenizerFastif tokenizer_path is not None:tokenizer = tokenizer_class(tokenizer_path)tokenizer.save_pretrained(model_path)vocab_size = tokenizer.vocab_size if tokenizer_path is not None else 32000# 处理键值对头信息if "n_kv_heads" in params:num_key_value_heads = params["n_kv_heads"] # for GQA / MQAnum_local_key_value_heads = n_heads_per_shard // num_key_value_headskey_value_dim = dim // num_key_value_headselse: # compatibility with other checkpointsnum_key_value_heads = n_headsnum_local_key_value_heads = n_heads_per_shardkey_value_dim = dim# 张量变换def permute(w, n_heads=n_heads, dim1=dim, dim2=dim):return w.view(n_heads, dim1 // n_heads // 2, 2, dim2).transpose(1, 2).reshape(dim1, dim2)print(f"Fetching all parameters from the checkpoint at {input_base_path}.")# 加载权重if num_shards == 1:loaded = torch.load(os.path.join(input_base_path, "consolidated.00.pth"), map_location="cpu")else:loaded = [torch.load(os.path.join(input_base_path, f"consolidated.{i:02d}.pth"), map_location="cpu")for i in range(num_shards)]param_count = 0index_dict = {"weight_map": {}}# 处理每一层的原始权重,并转化为bin文件for layer_i in range(n_layers):filename = f"pytorch_model-{layer_i + 1}-of-{n_layers + 1}.bin"if num_shards == 1:# Unshardedstate_dict = {f"model.layers.{layer_i}.self_attn.q_proj.weight": permute(loaded[f"layers.{layer_i}.attention.wq.weight"]),f"model.layers.{layer_i}.self_attn.k_proj.weight": permute(loaded[f"layers.{layer_i}.attention.wk.weight"]),f"model.layers.{layer_i}.self_attn.v_proj.weight": loaded[f"layers.{layer_i}.attention.wv.weight"],f"model.layers.{layer_i}.self_attn.o_proj.weight": loaded[f"layers.{layer_i}.attention.wo.weight"],f"model.layers.{layer_i}.mlp.gate_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w1.weight"],f"model.layers.{layer_i}.mlp.down_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w2.weight"],f"model.layers.{layer_i}.mlp.up_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w3.weight"],f"model.layers.{layer_i}.input_layernorm.weight": loaded[f"layers.{layer_i}.attention_norm.weight"],f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[f"layers.{layer_i}.ffn_norm.weight"],}else:# Sharded# Note that attention.w{q,k,v,o}, feed_fordward.w[1,2,3], attention_norm.weight and ffn_norm.weight share# the same storage object, saving attention_norm and ffn_norm will save other weights too, which is# redundant as other weights will be stitched from multiple shards. To avoid that, they are cloned.state_dict = {f"model.layers.{layer_i}.input_layernorm.weight": loaded[0][f"layers.{layer_i}.attention_norm.weight"].clone(),f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[0][f"layers.{layer_i}.ffn_norm.weight"].clone(),}state_dict[f"model.layers.{layer_i}.self_attn.q_proj.weight"] = permute(torch.cat([loaded[i][f"layers.{layer_i}.attention.wq.weight"].view(n_heads_per_shard, dims_per_head, dim)for i in range(num_shards)],dim=0,).reshape(dim, dim))state_dict[f"model.layers.{layer_i}.self_attn.k_proj.weight"] = permute(torch.cat([loaded[i][f"layers.{layer_i}.attention.wk.weight"].view(num_local_key_value_heads, dims_per_head, dim)for i in range(num_shards)],dim=0,).reshape(key_value_dim, dim),num_key_value_heads,key_value_dim,dim,)state_dict[f"model.layers.{layer_i}.self_attn.v_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.attention.wv.weight"].view(num_local_key_value_heads, dims_per_head, dim)for i in range(num_shards)],dim=0,).reshape(key_value_dim, dim)state_dict[f"model.layers.{layer_i}.self_attn.o_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.attention.wo.weight"] for i in range(num_shards)], dim=1)state_dict[f"model.layers.{layer_i}.mlp.gate_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.feed_forward.w1.weight"] for i in range(num_shards)], dim=0)state_dict[f"model.layers.{layer_i}.mlp.down_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.feed_forward.w2.weight"] for i in range(num_shards)], dim=1)state_dict[f"model.layers.{layer_i}.mlp.up_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.feed_forward.w3.weight"] for i in range(num_shards)], dim=0)state_dict[f"model.layers.{layer_i}.self_attn.rotary_emb.inv_freq"] = inv_freqfor k, v in state_dict.items():index_dict["weight_map"][k] = filenameparam_count += v.numel()torch.save(state_dict, os.path.join(tmp_model_path, filename))# 处理最后一层权重,并保存filename = f"pytorch_model-{n_layers + 1}-of-{n_layers + 1}.bin"if num_shards == 1:state_dict = {"model.embed_tokens.weight": loaded["tok_embeddings.weight"],"model.norm.weight": loaded["norm.weight"],"lm_head.weight": loaded["output.weight"],}else:state_dict = {"model.norm.weight": loaded[0]["norm.weight"],"model.embed_tokens.weight": torch.cat([loaded[i]["tok_embeddings.weight"] for i in range(num_shards)], dim=1),"lm_head.weight": torch.cat([loaded[i]["output.weight"] for i in range(num_shards)], dim=0),}for k, v in state_dict.items():index_dict["weight_map"][k] = filenameparam_count += v.numel()torch.save(state_dict, os.path.join(tmp_model_path, filename))# 写入配置文件index_dict["metadata"] = {"total_size": param_count * 2}write_json(index_dict, os.path.join(tmp_model_path, "pytorch_model.bin.index.json"))ffn_dim_multiplier = params["ffn_dim_multiplier"] if "ffn_dim_multiplier" in params else 1multiple_of = params["multiple_of"] if "multiple_of" in params else 256config = LlamaConfig(hidden_size=dim,intermediate_size=compute_intermediate_size(dim, ffn_dim_multiplier, multiple_of),num_attention_heads=params["n_heads"],num_hidden_layers=params["n_layers"],rms_norm_eps=params["norm_eps"],num_key_value_heads=num_key_value_heads,vocab_size=vocab_size,rope_theta=base,max_position_embeddings=max_position_embeddings,)config.save_pretrained(tmp_model_path)# 释放内存空间,以便正确加载模型del state_dictdel loadedgc.collect()print("Loading the checkpoint in a Llama model.")# 从临时文件中加载模型model = LlamaForCausalLM.from_pretrained(tmp_model_path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True)# 避免将此作为配置的一部分保存del model.config._name_or_pathmodel.config.torch_dtype = torch.float16print("Saving in the Transformers format.")# 保存LLama模型到指定的路径model.save_pretrained(model_path, safe_serialization=safe_serialization)# 删除临时文件中的所有内容shutil.rmtree(tmp_model_path)# 保存tokenizer
def write_tokenizer(tokenizer_path, input_tokenizer_path):# Initialize the tokenizer based on the `spm` modeltokenizer_class = LlamaTokenizer if LlamaTokenizerFast is None else LlamaTokenizerFastprint(f"Saving a {tokenizer_class.__name__} to {tokenizer_path}.")tokenizer = tokenizer_class(input_tokenizer_path)tokenizer.save_pretrained(tokenizer_path)def main():# 参数处理parser = argparse.ArgumentParser()parser.add_argument("--input_dir",help="Location of LLaMA weights, which contains tokenizer.model and model folders",)parser.add_argument("--model_size",choices=["7B", "7Bf", "13B", "13Bf", "30B", "34B", "65B", "70B", "70Bf", "tokenizer_only"],help="'f' models correspond to the finetuned versions, and are specific to the Llama2 official release. For more details on Llama2, checkout the original repo: https://huggingface.co/meta-llama",)parser.add_argument("--output_dir",help="Location to write HF model and tokenizer",)parser.add_argument("--safe_serialization", type=bool, help="Whether or not to save using `safetensors`.")args = parser.parse_args()spm_path = os.path.join(args.input_dir, "tokenizer.model")# 判断转换的对象if args.model_size != "tokenizer_only":write_model(model_path=args.output_dir,input_base_path=args.input_dir,model_size=args.model_size,safe_serialization=args.safe_serialization,tokenizer_path=spm_path,)else:write_tokenizer(args.output_dir, spm_path)if __name__ == "__main__":main()
脚本运行
python convert_llama_weights_to_hf.py --input_dir raw-llama2-7b --output_dir llama2_7b_hf
raw-llama2-7b文件夹内容:

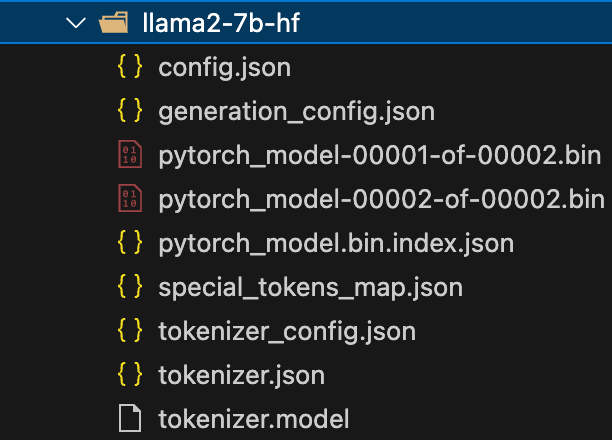
llama2_7b_hf转换文件内容: