最近在使用LangChain来做一个LLMs和KBs结合的小Demo玩玩,也就是RAG(Retrieval Augmented Generation)。
这部分的内容其实在LangChain的官网已经给出了流程图。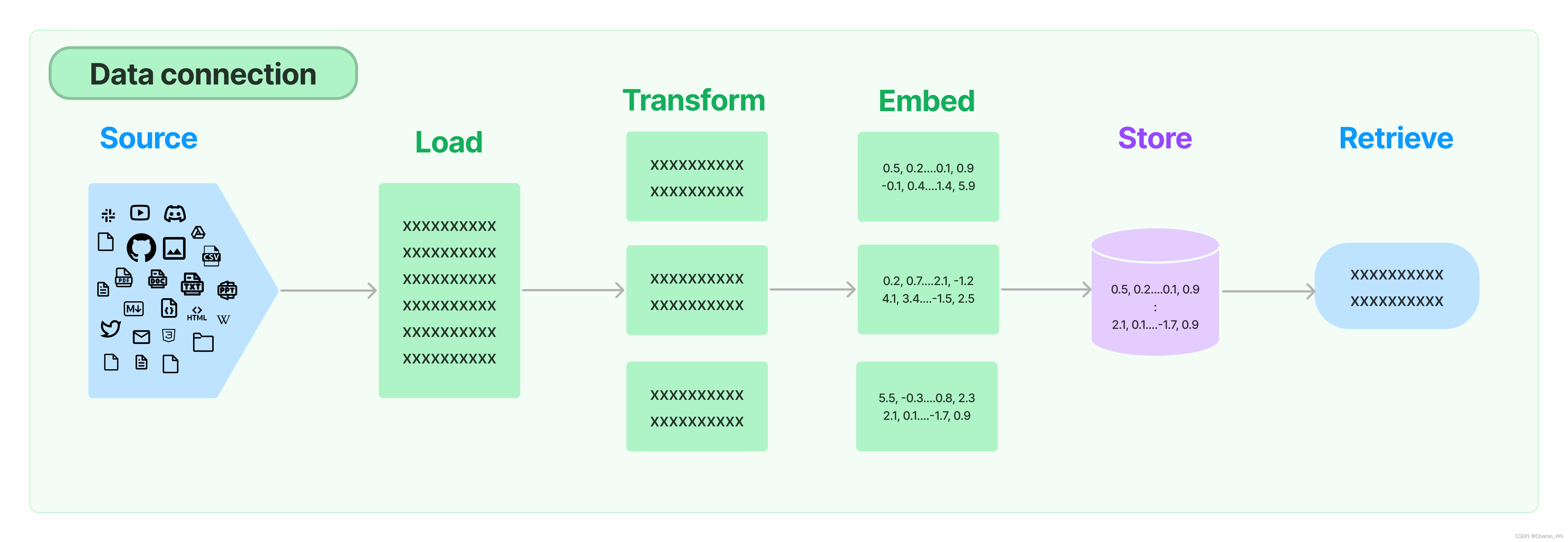
我这里就直接偷懒了,准备对Webui的项目进行复刻练习,那么接下来就是照着葫芦画瓢就行。
那么我卡在了Retrieve这一步。先放有疑惑地方的代码:
if web_content:prompt_template = f"""基于以下已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息",不允许在答案中添加编造成分,答案请使用中文。已知网络检索内容:{web_content}""" + """已知内容:{context}问题:{question}"""else:prompt_template = """基于以下已知信息,请简洁并专业地回答用户的问题。如果无法从中得到答案,请说 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。不允许在答案中添加编造成分。另外,答案请使用中文。已知内容:{context}问题:{question}"""prompt = PromptTemplate(template=prompt_template,input_variables=["context", "question"])......knowledge_chain = RetrievalQA.from_llm(llm=self.llm,retriever=vector_store.as_retriever(search_kwargs={"k": self.top_k}),prompt=prompt)knowledge_chain.combine_documents_chain.document_prompt = PromptTemplate(input_variables=["page_content"], template="{page_content}")knowledge_chain.return_source_documents = Trueresult = knowledge_chain({"query": query})return result
我对prompt_template、knowledge_chain.combine_documents_chain.document_prompt和 result = knowledge_chain({"query": query})这三个地方的input_key不明白为啥一定要这样设置。虽然我也看了LangChain的API文档。但是我并未得到详细的答案,那么只能一行行看源码是到底怎么设置的了。
注意:由于LangChain是一层层封装的,那么
result = knowledge_chain({"query": query})可以认为是最外层,那么我们先看最外层。
result = knowledge_chain({“query”: query})
其实这部分是直接与用户的输入问题做对接的,我们只需要定位到RetrievalQA这个类就可以了,下面是RetrievalQA这个类的实现:
class RetrievalQA(BaseRetrievalQA):"""Chain for question-answering against an index.Example:.. code-block:: pythonfrom langchain.llms import OpenAIfrom langchain.chains import RetrievalQAfrom langchain.vectorstores import FAISSfrom langchain.schema.vectorstore import VectorStoreRetrieverretriever = VectorStoreRetriever(vectorstore=FAISS(...))retrievalQA = RetrievalQA.from_llm(llm=OpenAI(), retriever=retriever)"""retriever: BaseRetriever = Field(exclude=True)def _get_docs(self,question: str,*,run_manager: CallbackManagerForChainRun,) -> List[Document]:"""Get docs."""return self.retriever.get_relevant_documents(question, callbacks=run_manager.get_child())async def _aget_docs(self,question: str,*,run_manager: AsyncCallbackManagerForChainRun,) -> List[Document]:"""Get docs."""return await self.retriever.aget_relevant_documents(question, callbacks=run_manager.get_child())@propertydef _chain_type(self) -> str:"""Return the chain type."""return "retrieval_qa"
可以看到其继承了BaseRetrievalQA这个父类,同时对_get_docs这个抽象方法进行了实现。
这里要扩展的说一下,_get_docs这个方法就是利用向量相似性,在vector Base中选择与embedding之后的query最近似的
Document结果。然后作为RetrievalQA的上下文。具体只需要看BaseRetrievalQA这个方法的_call和就可以了。
接下来我们只需要看BaseRetrievalQA这个类的属性就可以了。
class BaseRetrievalQA(Chain):"""Base class for question-answering chains."""combine_documents_chain: BaseCombineDocumentsChain"""Chain to use to combine the documents."""input_key: str = "query" #: :meta private:output_key: str = "result" #: :meta private:return_source_documents: bool = False"""Return the source documents or not."""……def _call(self,inputs: Dict[str, Any],run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:"""Run get_relevant_text and llm on input query.If chain has 'return_source_documents' as 'True', returnsthe retrieved documents as well under the key 'source_documents'.Example:.. code-block:: pythonres = indexqa({'query': 'This is my query'})answer, docs = res['result'], res['source_documents']"""_run_manager = run_manager or CallbackManagerForChainRun.get_noop_manager()question = inputs[self.input_key]accepts_run_manager = ("run_manager" in inspect.signature(self._get_docs).parameters)if accepts_run_manager:docs = self._get_docs(question, run_manager=_run_manager)else:docs = self._get_docs(question) # type: ignore[call-arg]answer = self.combine_documents_chain.run(input_documents=docs, question=question, callbacks=_run_manager.get_child())if self.return_source_documents:return {self.output_key: answer, "source_documents": docs}else:return {self.output_key: answer}
可以看到其有input_key这个属性,默认值是"query"。到这里我们就可以看到result = knowledge_chain({"query": query})是调用的BaseRetrievalQA的_call,这里的question = inputs[self.input_key]就是其体现。
knowledge_chain.combine_documents_chain.document_prompt
这个地方一开始我很奇怪,为什么会重新定义呢?
我们可以先定位到,combine_documents_chain这个参数的位置,其是StuffDocumentsChain的方法。
@classmethod
def from_llm(cls,llm: BaseLanguageModel,prompt: Optional[PromptTemplate] = None,callbacks: Callbacks = None,**kwargs: Any,
) -> BaseRetrievalQA:"""Initialize from LLM."""_prompt = prompt or PROMPT_SELECTOR.get_prompt(llm)llm_chain = LLMChain(llm=llm, prompt=_prompt, callbacks=callbacks)document_prompt = PromptTemplate(input_variables=["page_content"], template="Context:\n{page_content}")combine_documents_chain = StuffDocumentsChain(llm_chain=llm_chain,document_variable_name="context",document_prompt=document_prompt,callbacks=callbacks,)return cls(combine_documents_chain=combine_documents_chain,callbacks=callbacks,**kwargs,)
可以看到原始的document_prompt中PromptTemplate的template是“Context:\n{page_content}”。因为这个项目是针对中文的,所以需要将英文的Context去掉。
扩展
- 这里PromptTemplate(input_variables=[“page_content”], template=“Context:\n{page_content}”)的
input_variables和template为什么要这样定义呢?其实是根据Document这个数据对象来定义使用的,我们可以看到其数据格式为:Document(page_content=‘……’, metadata={‘source’: ‘……’, ‘row’: ……})
那么input_variables的输入就是Document的page_content。 StuffDocumentsChain中有一个参数是document_variable_name。那么这个类是这样定义的This chain takes a list of documents and first combines them into a single string. It does this by formatting each document into a string with the document_prompt and then joining them together with document_separator. It then adds that new string to the inputs with the variable name set by document_variable_name. Those inputs are then passed to the llm_chain.这个document_variable_name简单来说就是在document_prompt中的占位符,用于在Chain中的使用。
因此我们上文prompt_template变量中的“已知内容: {context}”,用的就是context这个变量。因此在prompt_template中换成其他的占位符都不能正常使用这个Chain。
prompt_template
在上面的拓展中其实已经对prompt_template做了部分的讲解,那么这个字符串还剩下“问题:{question}”这个地方没有说通
还是回归源码:
return cls(combine_documents_chain=combine_documents_chain,callbacks=callbacks,**kwargs,)
我们可以在from_llm函数中看到其返回值是到了_call,那么剩下的我们来看这个函数:
......
uestion = inputs[self.input_key]
accepts_run_manager = ("run_manager" in inspect.signature(self._get_docs).parameters
)
if accepts_run_manager:docs = self._get_docs(question, run_manager=_run_manager)
else:docs = self._get_docs(question) # type: ignore[call-arg]
answer = self.combine_documents_chain.run(input_documents=docs, question=question, callbacks=_run_manager.get_child()
)
......这里是在run这个函数中传入了一个字典值,这个字典值有三个参数。
注意:
- 这三个参数就是kwargs,也就是_validate_inputs的参数input;
- 此时已经是在Chain这个基本类了)
def run(self,*args: Any,callbacks: Callbacks = None,tags: Optional[List[str]] = None,metadata: Optional[Dict[str, Any]] = None,**kwargs: Any,) -> Any:"""Convenience method for executing chain.The main difference between this method and `Chain.__call__` is that thismethod expects inputs to be passed directly in as positional arguments orkeyword arguments, whereas `Chain.__call__` expects a single input dictionarywith all the inputs"""
接下来调用__call__:
def __call__(self,inputs: Union[Dict[str, Any], Any],return_only_outputs: bool = False,callbacks: Callbacks = None,*,tags: Optional[List[str]] = None,metadata: Optional[Dict[str, Any]] = None,run_name: Optional[str] = None,include_run_info: bool = False,) -> Dict[str, Any]:"""Execute the chain.Args:inputs: Dictionary of inputs, or single input if chain expectsonly one param. Should contain all inputs specified in`Chain.input_keys` except for inputs that will be set by the chain'smemory.return_only_outputs: Whether to return only outputs in theresponse. If True, only new keys generated by this chain will bereturned. If False, both input keys and new keys generated by thischain will be returned. Defaults to False.callbacks: Callbacks to use for this chain run. These will be called inaddition to callbacks passed to the chain during construction, but onlythese runtime callbacks will propagate to calls to other objects.tags: List of string tags to pass to all callbacks. These will be passed inaddition to tags passed to the chain during construction, but onlythese runtime tags will propagate to calls to other objects.metadata: Optional metadata associated with the chain. Defaults to Noneinclude_run_info: Whether to include run info in the response. Defaultsto False.Returns:A dict of named outputs. Should contain all outputs specified in`Chain.output_keys`."""inputs = self.prep_inputs(inputs)......
这里的prep_inputs会调用_validate_inputs函数
def _validate_inputs(self,inputs: Dict[str, Any]) -> None:"""Check that all inputs are present."""missing_keys = set(self.input_keys).difference(inputs)if missing_keys:raise ValueError(f"Missing some input keys: {missing_keys}")
这里的input_keys通过调试,看到的就是有多个输入,分别是"input_documents"和"question"
这里的"input_documents"是来自于BaseCombineDocumentsChain
class BaseCombineDocumentsChain(Chain, ABC):"""Base interface for chains combining documents.Subclasses of this chain deal with combining documents in a variety ofways. This base class exists to add some uniformity in the interface these typesof chains should expose. Namely, they expect an input key related to the documentsto use (default `input_documents`), and then also expose a method to calculatethe length of a prompt from documents (useful for outside callers to use todetermine whether it's safe to pass a list of documents into this chain or whetherthat will longer than the context length)."""input_key: str = "input_documents" #: :meta private:output_key: str = "output_text" #: :meta private:那为什么有两个呢,“question”来自于哪里?
StuffDocumentsChain继承BaseCombineDocumentsChain,其input_key是这样定义的:
@propertydef input_keys(self) -> List[str]:extra_keys = [k for k in self.llm_chain.input_keys if k != self.document_variable_name]return super().input_keys + extra_keys
原来是重写了input_keys函数,其是对llm_chain的input_keys进行遍历。
那么llm_chain的input_keys是用其prompt的input_variables。(这里的input_variables是PromptTemplate中的[“context”, “question”])
@propertydef input_keys(self) -> List[str]:"""Will be whatever keys the prompt expects.:meta private:"""return self.prompt.input_variables
至此,我们StuffDocumentsChain的input_keys有两个变量了。