从机器人辅助手术到医学成像技术,人工智能在医疗保健领域的应用正在迅速改变医疗保健行业,并改善服务成本和服务质量。例如,埃森哲表示,到 150 年,人工智能临床健康应用每年可以为美国医疗保健行业节省 2026 亿美元。
然而,数据隐私问题限制了医疗保健行业的创新程度。患者医疗数据包含高度敏感且可识别个人身份的数据类型,例如:
- 完整的病史
- 持续状况
- 社会安全号码
- 付款和信用卡信息
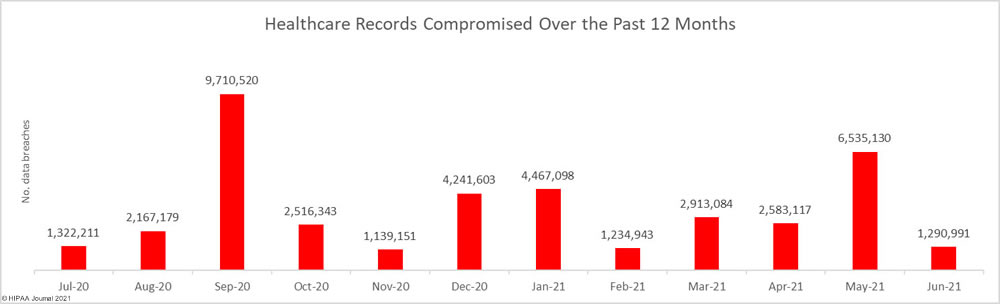
这就是为什么 HIPAA 等法规严格保护患者医疗记录的原因。尽管如此,HIPAA Journal 报告称,在 40 年 2020 月至 2021 年 <> 月期间,美国有超过 <> 万份医疗记录未经许可被曝光或披露。恶意内部人员的黑客攻击和未经授权的披露是医疗保健行业数据泄露的两个最常见原因。
埃森哲的调查报告称,五分之一的医疗保健员工愿意以低至 500 美元的价格将患者数据出售给未经授权的各方。因此,数据隐私似乎是医疗保健领域创新和更先进的人工智能应用道路上的最大障碍。合成(即人工生成)患者数据可以成为应对医疗保健创新挑战的解决方案。
合成数据如何帮助医疗保健行业?
在构建 AI 解决方案的研究人员、机构和公司之间共享医疗保健数据可以带来许多好处。然而,由于 HIPAA 等法规,安全共享患者数据是医疗保健行业的一项严峻挑战。合成数据可以帮助医疗保健研究人员创建可共享的数据并克服这些挑战。
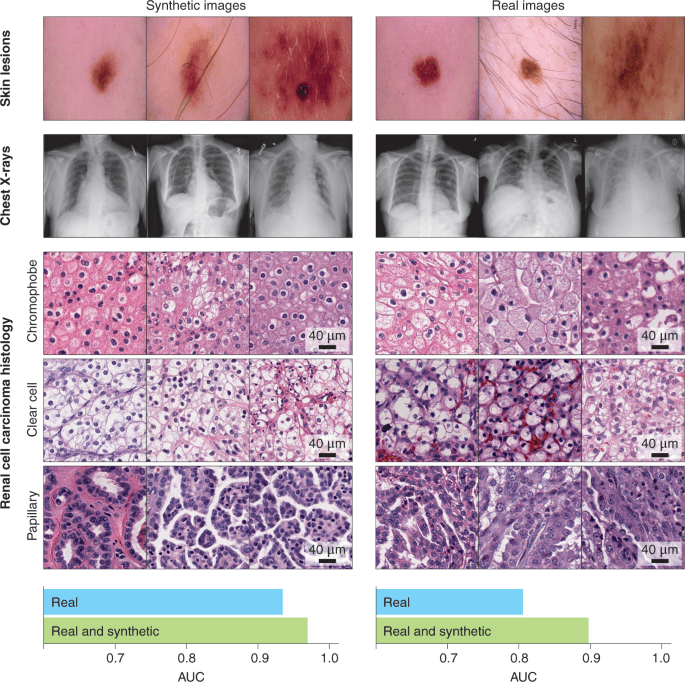
提高机器学习模型的准确性
机器学习和深度学习模型用于医疗保健领域的众多人工智能应用,例如医学成像、患者数据分析或药物发现。为这些算法提供充足且准确的训练患者数据对于成功预测至关重要。
合成数据在不违反数据隐私法规的情况下,通过增加训练数据集的大小来提高机器学习/深度学习模型的准确性。
能够预测罕见疾病
在患者很少的情况下进行临床试验会导致结果不准确。合成数据可用于为与缺乏足够现有数据的罕见或最近发现的疾病相关的临床试验创建对照组,从而能够预测罕见疾病。
这类似于合成数据支持 ML 模型准确性的好处,但在数据稀缺的情况下,这种好处可能更明显。
实现协作
医疗和制药机构之间的合作可以帮助医疗专业人员快速诊断患者或加速药物发现。再现真实患者特征的合成患者数据可以促进协作。
为医学研究提供可重复性
能够重现研究或实验的结果是科学进步的重要组成部分。然而,患者数据隐私法规可能会阻碍临床研究的可重复性。通过对合成患者数据集进行研究和共享,临床研究人员可以确保其结果的可重复性。
它的替代品是什么?
基于真实数据或真实数据和合成数据组合构建的模型可以优于仅依赖合成数据的模型。但是,当真实数据以图像形式出现时,需要对其进行注释。注释公司提供数据注释平台。
有哪些案例研究?
- M-sense 是一款偏头痛监测和健康援助移动应用程序。它允许用户了解和减轻他们的偏头痛症状。该应用程序还为偏头痛研究的科学界提供基于真实数据的合成用户数据。
- 国家卫生信息技术协调员办公室(ONC)正在领导一个项目,以增强开源合成数据引擎,以加速科学研究。他们旨在为阿片类药物成瘾、儿科和复杂的护理用例生成高质量的合成数据。
- 美国退伍军人事务部为研究影响退伍军人健康的因素提供合成医学数据。研究人员和医疗专业人员可以通过 Lighthouse API 访问退伍军人健康数据。
合成数据工具
与合成数据相关的工具通常是为了满足以下需求之一而开发的:
- 用于软件开发和类似目的的测试数据
- 机器学习模型的训练数据
UnrealSynth 虚幻合成数据生成器 利用虚幻引擎的实时渲染能力搭建逼真的三维场景,为 YOLO 等 AI 模型的训练提供自动生成的图像和标注数据。UnrealSynth 生成的合成数据可用于深度学习模型的训练和验证,可以极大地提高各种行业细分场景中目标识别任务的实施效率,例如:安全帽检测、交通标志检测、施工机械检测、车辆检测、行人检测、船舶检测等。
UnrealSynth 生成合成数据的步骤:
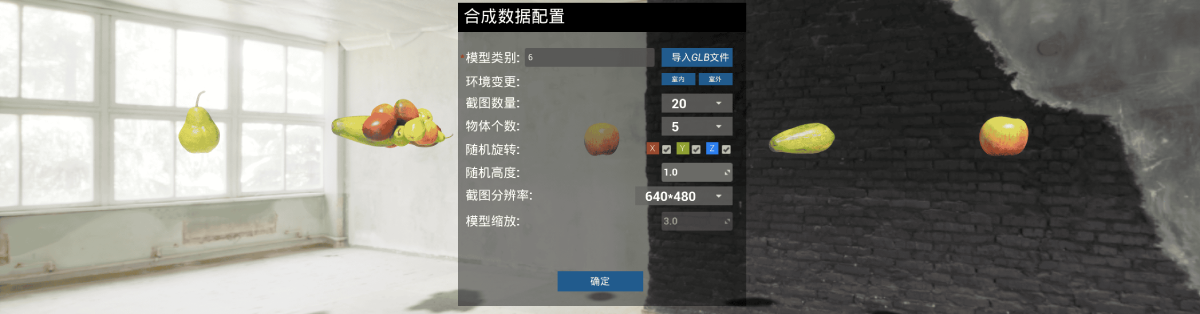
1、将 GLB 文件添加到场景后,接下来就可以配置 UnrealSynth 合成数据生成参数,参数配置说明如下:
- 模型类别: 生成合成数据 synth.yaml 文件中记录物体的类型
- 环境变更 : 变更场景背景
- 截图数量 : 生成合成数据集 image 目录下的图像数量,在 train 和 val 目录下各自生成总数一半数量的图片
- 物体个数 : 设置场景中的物体个数,目前最多支持 5 个,并且是随机的选取模型的类别
- 随机旋转 : 场景中的物体随机旋转角度
- 随机高度 : 场景中的物体随机移动的高度
- 截图分辨率: 生成的 images 图像数据集中的图像分辨率
- 缩放 : 物体缩放调整大小
2、点击【确定】后会在本地目录中...\UnrealSynth\Windows\UnrealSynth\Content\UserData 自动生成两个文件夹以及一个 yaml 文件:images、labels、test.yaml 文件。
UnrealSynth\Windows\UnrealSynth\Content\UserData|- images|-train|- 0.png|- 1.png|- 2.png|- ...|-val|- 0.png|- 1.png|- 2.png|- ...|- labels|-train|- 0.txt|- 1.txt|- 2.txt|- ...|-val|- 0.txt|- 1.txt|- 2.txt|- ...|- synth.yaml3、模型训练:数据集生成后有三个办法可以进行模型训练:使用 python 脚本、使用命令行、使用在线服务。
第一种是使用 python 脚本,需首先安装 ultralytics 包,训练代码如下所示:
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.yaml') # build a new model from YAML
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights# Train the model
results = model.train(data='synth.yaml', epochs=100, imgsz=640)
第二种是使用命令行,需安装 YOLO 命令行工具,训练代码如下:
# Build a new model from YAML and start training from scratch
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640# Start training from a pretrained *.pt model
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640# Build a new model from YAML, transfer pretrained weights to it and start training
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
第三种是使用ultralytics hub 或者其他在线训练工具。
转载:合成数据在医疗保健行业的案例研究 (mvrlink.com)