阅读时间:2023-10-29
1 介绍
年份:2016
作者:李志忠; 德里克·霍伊姆,伊利诺伊大学
期刊:IEEE transactions on pattern analysis and machine intelligence
引用量:3353
提出一种名为"无忘记学习"的算法,用于在卷积神经网络(Convolutional Neural Network, CNN)中添加新的视觉能力,同时保留原有的能力,而无需使用旧的训练数据。这种算法只使用新任务的数据来训练网络,同时保持原有的能力。相比于常用的特征提取和微调适应技术,以及可能无法获取的原始任务数据的多任务学习,这种方法表现出色。该方法在计算效率上高效,不需要保留或重新应用训练数据,并且在部署上非常简单。通过更多实验证明了作者之前工作的可行性,并与其他方法进行了比较。该论文与诸如蒸馏网络、微调、多任务学习、领域适应、迁移学习、终身学习和不断学习等方法相关。该论文的方法提供了一种更直接的方式来保留对于原有任务重要的表示,相对于微调,它在大多数实验中提高了原有任务和新任务的性能。
类似算法,iead来源: Active long term memory networks
本文主要区别在于用于训练的权重衰减正则化和在完全微调之前使用的预热步骤。
本文使用大型数据集来训练我们的初始网络(例如ImageNet),然后从较小的数据集(例如PASCAL VOC)扩展到新任务。而A-LTM则使用小型数据集进行旧任务和大型数据集进行新任务。相比之下,LWF的实验表明,在没有原始任务数据的情况下,可以保持旧任务的良好性能,同时在新任务上表现得与或者有时比微调更好。
2 创新点
无遗忘学习方法LWF可以看作是反馈网络【 Distilling the knowledge in a neural network 】和微调【 Rich feature hierarchies for accurate object detection and semantic segmentation 】的结合。
微调从在相关数据丰富问题上训练的现有网络的参数初始化,并通过使用较低的学习率为新任务优化参数,找到新的局部最优点。反馈网络的思想是通过学习较简单的网络参数,使其在训练集或大型无标签数据集上产生与一个更复杂的网络集合相同的输出。LWF的方法不同之处在于,LWF使用相同数据来监督学习新任务并为旧任务提供无监督输出引导来解决适用于新旧任务的一组参数。
3 算法
(1)对比的方法
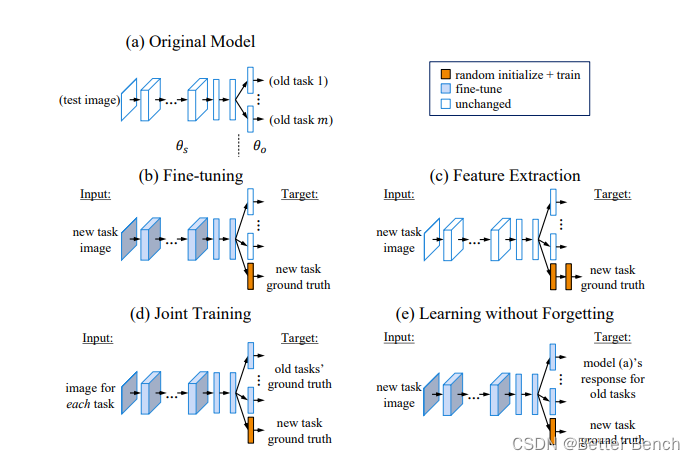
- 特征提取: 这种方法使用预训练的深度卷积神经网络(CNN)从图像中提取特征。这些特征然后用于训练新任务的分类器。虽然这种方法不修改原始网络并且可以取得良好的结果,但提取的特征可能不专门用于新任务,并且可能需要进行微调。
- 微调: 这种方法修改现有CNN的参数以训练新任务。输出层通过随机初始化权重进行扩展,并使用较小的学习率来最小化新任务的损失。有时,网络的某些层被冻结以防止过拟合。微调是使共享参数更具有辨别性的方法。这种方法通常优于特征提取。
- 多任务学习: 这种方法旨在通过结合所有任务的共同知识来同时改进所有任务。网络的底层是共享的,而顶层是针对特定任务的。多任务学习需要所有任务的数据都存在。
- 添加新节点到每个网络层: 这种方法在网络的每个层中添加新节点来学习新的辨别特征,同时保留原始网络参数。这可以扩展网络中的参数数量,如果没有足够的训练数据来学习新的参数,则可能表现不佳,因为这种方法需要从头开始训练大量参数。作者尝试扩展原始网络的全连接层,但发现这种扩展在LWF的方法上没有提供改进。
(2)相关的研究
知识蒸馏的方法,其中知识是从一个大型网络或网络组件传递给一个较小的网络,以实现高效部署。
- A-LTM【Active long term memory networks】是在独立开发的基础上几乎相同的方法,但在实验和结论方面有很大的差异。方法的主要差异在于训练中使用的权重衰减正则化和在完全微调之前使用的预热步骤。本文作者使用大型数据集来训练初始网络(例如ImageNet),然后从较小的数据集(例如PASCAL VOC)扩展到新任务,而A-LTM使用小型数据集用于旧任务和大型数据集用于新任务。A-LTM中的实验发现了比LWF有更大的微调损失,并得出结论认为维护原始任务的数据对于维持性能是必要的。相比之下,实验证明LWF可以在不访问原始任务数据的情况下保持旧任务的良好性能,并在新任务中表现得和甚至更好。作者分析主要的区别在于旧任务-新任务配对的选择,并且观察到由于选择的差异(部分原因是预热步骤)导致的微调对旧任务性能的下降较小。作者认为从训练有素的网络开始并使用较少的训练数据添加任务的实验从实用角度更具有有效性。
- Less Forgetting Learning【Less-forgetting learning in deep neural networks】也是一种类似的方法,通过阻止共享表示发生变化来保持旧任务的性能。该方法认为任务特定的决策边界不应改变,并保持旧任务的最后一层不变,LWF的方法则通过限制旧任务的输出变化来同时优化共享表示和最终层。LWF在新任务上表现优于Less Forgetting Learning。
(3)算法步骤
首先对于一个新任务来说,我们模型已经有了在之前任务训练的出来的共享参数 θ s \theta_s θs和旧任务参数 θ n \theta_n θn
,对于当前新到来的任务我们有了 X n X_n Xn和 Y n Y_n Yn。
初始化:
首先是根据新任务数据拟合出来一个旧任务标签
Y o = C N N ( X n , θ s , θ o ) Y_o = CNN(X_n,\theta_s,\theta_o) Yo=CNN(Xn,θs,θo)
随机初始化: θ n \theta_n θn
训练:
旧任务预测出的结果:
Y o ′ = C N N ( X n , θ s ′ , θ o ′ ) Y_o'=CNN(X_n,\theta_s',\theta_o') Yo′=CNN(Xn,θs′,θo′)
新任务预测结果:
Y n ′ = C N N ( X n , θ s ′ , θ n ′ ) Y_n'=CNN(X_n,\theta_s',\theta_n') Yn′=CNN(Xn,θs′,θn′)
最后定义损失函数即可:
L o s s = λ 0 L o l d ( Y o , Y o ′ ) + L n e w ( Y n , Y n ′ ) + R ( θ s , θ o , θ n ) Loss = \lambda_0L_{old}(Y_o,Y_o')+L_{new}(Y_n,Y_n')+R(\theta_s,\theta_o,\theta_n) Loss=λ0Lold(Yo,Yo′)+Lnew(Yn,Yn′)+R(θs,θo,θn)
其中对于旧任务预测 L o l d L_{old} Lold,作者使用了蒸馏的交叉熵损失函数的方式,即
L o l d ( Y o , Y o ′ ) = − ∑ i = 1 l y o ′ ( i ) l o g y o ′ ( i ) L_{old}(Y_o,Y_o') = -\sum_{i=1}^{l}y_o'^{(i)}logy_o'^{(i)} Lold(Yo,Yo′)=−i=1∑lyo′(i)logyo′(i)
y o ′ ( i ) = ( y o ′ ( i ) ) 1 / T ∑ j ( y o ′ ( i ) ) 1 / T y_o'^{(i)} = \frac{({y_o'^{(i)})}^{1/T}}{\sum_j({y_o'^{(i)})}^{1/T}} yo′(i)=∑j(yo′(i))1/T(yo′(i))1/T
对于新任务 L n e w L_{new} Lnew,采用交叉熵损失函数
L n e w = − y n l o g y n ^ L_{new} = -y_n log{\hat{y_n}} Lnew=−ynlogyn^
使用带有正则化的 SGD 训练网络
1) 首先固定 θ s \theta_s θs和 θ o \theta_o θo不变,然后使用新任务数据集训练 θ n \theta_n θn 直至收敛;
2) 然后再联合训练所有参数 θ s \theta_s θs、 θ o \theta_o θo和 θ n \theta_n θn 直至网络收敛。
4 实验分析
(1)实验设计
原始旧任务数据集:ImageNet [4]的ILSVRC 2012子集和Places365-standard [30]数据集
新任务大规模数据集:PASCAL VOC 2012图像分类[31](VOC)、Caltech-UCSD Birds-200-2011细粒度分类[32](CUB)和MIT室内场景分类[33](Scenes)、MNIST [34]
ImageNet [4]的ILSVRC 2012子集和Places365-standard [30]数据集、
权重:使用开放的ImageNet和Places365-standard上预训练的原始网络模型
(2)分析角度
- 添加单个新任务到网络中的效果研究
- 逐一添加多个任务的效果研究
- 考察数据集大小对结果的影响
- 考察网络设计对结果的影响
- 进行消融研究:探究不同的保留响应损失函数、扩展网络结构以及使用较低学习率进行微调等方法对保持原有任务性能的有效性
5 代码
https://github.com/ngailapdi/LWF/blob/master/model.py
6 思考
LwF可以看作是蒸馏网络和微调的结合。LwF的整个训练过程和联合训练(Joint Training)有点类似,但不同的是LwF 不需要旧任务的数据和标签,而是用KD蒸馏损失去平衡旧任务的性能,完成了不需要访问任何旧任务数据的增量训练。

![[unity]多脚本情况下update函数的执行顺序](https://img-blog.csdnimg.cn/92ff06b432f945e7812bdca850ffa916.png)