本文全面探讨了自然语言处理(NLP)中句法分析的理论与实践。从句法和语法的定义,到各类句法理论和方法,文章细致入微地解析了句法分析的多个维度。最后,通过PyTorch的实战演示,我们展示了如何将这些理论应用到具体任务中。本文旨在为读者提供一份全面、深入且实用的句法分析指南。

一、引言
句法分析(Syntactic Parsing)是自然语言处理(NLP)中一个关键且不可或缺的任务。如果我们把自然语言看作一个庞大的建筑,那么句法分析就好比这座建筑的蓝图。正是因为有了这份蓝图,人们才能理解语言的结构,从而更准确地进行语义分析、情感分析或者机器翻译等高级任务。
句法分析不仅在学术研究中占有重要地位,也在商业应用、搜索引擎、机器人对话系统等多个领域中发挥着关键作用。例如,高级搜索算法会使用句法分析来更准确地理解查询语句,从而返回更为相关的搜索结果。
尽管句法分析的重要性众所周知,但其实现方式及应用却并不是一蹴而就的。它需要数学模型、算法、甚至对人类语言的深入理解。本文将对句法分析的理论基础进行全面而深入的介绍,并借助PyTorch框架进行实战演示。
我们将从句法与语法的定义出发,探讨其历史背景和理论分类,介绍成分和依存两大主流的句法分析方法,并最终提供PyTorch的实战代码演示。希望这篇文章能为您在理论学习和实践应用方面提供有力的支持。
二、句法与语法:定义和重要性
什么是句法?
句法(Syntax)关注的是语言结构和规则的研究,即词、短语、句子如何组合成有意义的表达方式。简单来说,句法就像是一个建造句子的“配方”,告诉我们如何将词汇(ingredients)合成为完整、有意义的句子(dish)。
例子
考虑一个简单的句子:“The cat sat on the mat。”(猫坐在垫子上。)在这个句子中,我们可以很清晰地看到主语(The cat)、谓语(sat)、宾语(on the mat)如何通过句法规则被组合成一个完整的句子。
什么是语法?
与句法不同,语法(Grammar)是一个更为宽泛的术语,它包括了句法、音位学(Phonology)、语义(Semantics)等多个方面。语法规定了语言如何正确、有效地使用,包括但不限于词汇的选择、词序、时态等。
例子
再次考虑刚才的句子:“The cat sat on the mat。”如果我们改变词序,如:“The mat sat on the cat”,意义就完全不同了。这就是语法的作用,确保句子不仅结构正确,而且意义明确。
句法与语法的重要性
句法和语法是语言理解和生成中不可或缺的组成部分。它们为高级NLP任务,如机器翻译、文本摘要、情感分析等提供了坚实的基础。
句法的重要性
-
可解释性:句法结构能帮助我们更好地理解句子的含义。
-
多样性:句法规则使语言更加丰富和多样,增加了表达能力。
-
自然语言处理应用:句法分析是信息检索、机器翻译、语音识别等多种NLP任务的基础。
语法的重要性
-
正确性:语法规则确保语言的标准和正确性。
-
复杂性和深度:良好的语法结构能表达更复杂、更深刻的观点和信息。
-
跨文化交流:了解语法规则有助于更准确地进行跨语言、跨文化的交流。
三、句法理论:历史与分类
句法研究历史悠久,不同的句法理论对我们如何理解和分析语言结构有着不同的影响。在这一部分,我们将深入探讨句法理论的历史背景和不同分类。
生成语法(Generative Grammar)
背景
生成语法是由诺姆·乔姆斯基(Noam Chomsky)于1950年代提出的,目的是通过一组有限的规则来生成(即产生)所有可能的合法句子。
例子
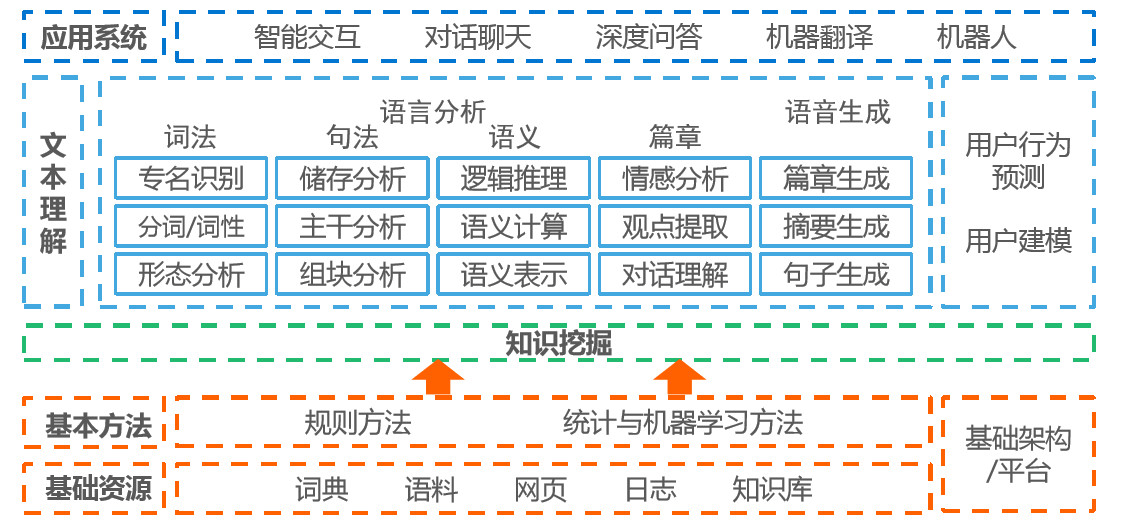
在生成语法中,一个句子如“John eats an apple”可以被视为从更高层次的“S”(句子)符号生成的,其中“S”可以被分解为主语(NP,名词短语)和谓语(VP,动词短语)。
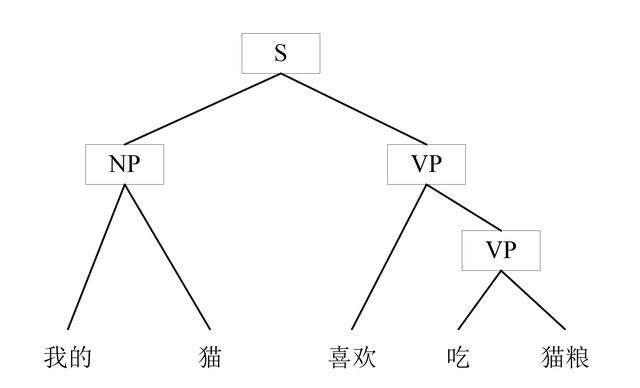
依存语法(Dependency Grammar)
背景
依存语法的核心思想是语言中的词相互依赖来传达意义。这一理论强调了单词之间的关系,而不仅仅是它们在句子中的位置。
例子
在句子“John eats an apple”中,“eats”依赖于“John”作为其执行者,而“an apple”则是“eats”的宾语。这些依赖关系帮助我们理解句子的结构和意义。
构式语法(Construction Grammar)
背景
构式语法关注的是特定语境下词汇或短语如何组合成更大的结构。这一理论强调了语言使用的动态性和灵活性。
例子
考虑短语“kick the bucket”,虽然字面意义是“踢桶”,但在特定文化和语境下,这个短语实际上意味着“去世”。构式语法能够解释这种特定语境下的语义复杂性。
Categorial Grammar(范畴语法)
背景
范畴语法是一种逻辑主导的语法体系,它使用数学逻辑来描述词汇项如何组合成更复杂的表达式。
例子
在范畴语法中,动词如“run”可以被视为一个从主语(名词)到谓语(动词)的函数。这一点用逻辑符号可以清晰地表示。
四、短语和句法范畴
理解短语和句法范畴是进行句法分析的关键步骤之一。在这一部分,我们将详细介绍这两个概念,以及它们在句法分析中的重要性。
短语(Phrase)
短语是一组单词,它们在句子中作为一个单元出现,并且通常具有特定的语法和语义功能。
名词短语(Noun Phrase, NP)
定义
名词短语通常由一个或多个名词以及与之相关的修饰词(如形容词或定语)组成。
例子
-
“The quick brown fox”(快速的棕色狐狸)是一个名词短语,其中“quick”和“brown”是修饰“fox”的形容词。
动词短语(Verb Phrase, VP)
定义
动词短语包含一个主动词以及可能出现的一系列宾语或补语。
例子
-
在句子“John is eating an apple”中,“is eating an apple”是一个动词短语。
句法范畴(Syntactic Categories)
句法范畴是对单词或短语在句子中功能的抽象表示。常见的句法范畴包括名词(N)、动词(V)、形容词(Adj)等。
基本范畴(Atomic Categories)
定义
这些是最基本的句法范畴,通常包括名词(N)、动词(V)、形容词(Adj)等。
例子
-
“Dog”(狗)是一个名词。
-
“Run”(跑)是一个动词。
-
“Happy”(快乐的)是一个形容词。
复合范畴(Complex Categories)
定义
复合范畴由两个或多个基本范畴通过特定的句法规则组合而成。
例子
-
名词短语(NP)是一个复合范畴,可能由名词(N)和形容词(Adj)组成,如“happy dog”。
五、短语结构规则与依存结构
理解句子的结构和组成通常涉及短语结构规则和依存结构两个主要方面。下面,我们将逐一介绍这两个概念。
短语结构规则(Phrase Structure Rules)
短语结构规则是一组规则,用于描述如何从单个单词生成句子或短语的结构。
句子(S)的生成
定义
一个常见的短语结构规则是将名词短语(NP)和动词短语(VP)组合以形成句子(S)。
例子
-
句子(S) = 名词短语(NP) + 动词短语(VP)"The cat" (NP) + "sat on the mat" (VP) = "The cat sat on the mat" (S)
动词短语的复杂性
定义
动词短语(VP)自身也可能包括其他名词短语(NP)或副词(Adv)作为其组成部分。
例子
-
动词短语(VP) = 动词(V) + 名词短语(NP)+ 副词(Adv)"eats" (V) + "an apple" (NP) + "quickly" (Adv) = "eats an apple quickly" (VP)
依存结构(Dependency Structure)
依存结构关注单词之间的依存关系,而不是它们如何组合成短语或句子。
核心与依赖元素
定义
在依存结构中,每个单词都有一个“头”(head),以及与这个头有依存关系的一系列“依赖”(dependents)。
例子
-
在句子"The quick brown fox jumps over the lazy dog"中,"jumps" 是动词,作为“头”元素。"The quick brown fox" 是这个动词的主语,因此是依赖元素。"over the lazy dog" 是这个动词的宾语,也是依赖元素。
两种结构都有各自的优点和应用场景。短语结构规则通常更容易与形式文法相匹配,便于生成句子。依存结构则强调单词之间的关系,更便于理解句子的语义。
六、句法分析方法
句法分析是NLP中一项至关重要的任务,用于解析句子结构,以便更好地理解句子的意义和组成。本节将介绍几种主流的句法分析方法。
自顶向下(Top-Down)分析
定义
从句子的最高层次(通常是句子(S)本身)开始,逐步将其分解为更小的组成部分(如名词短语、动词短语等)。
例子
在句子 "The cat sat on the mat" 中,自顶向下分析首先识别出整个句子,然后将其分解为名词短语 "The cat" 和动词短语 "sat on the mat"。
自底向上(Bottom-Up)分析
定义
从句子的单词开始,逐步合并它们以形成更高层次的短语或结构。
例子
对于同样的句子 "The cat sat on the mat",自底向上分析会先识别 "The", "cat", "sat", "on", "the", "mat" 这些单词,然后将它们组合成名词短语和动词短语,最终形成整个句子。
耳朵算法(Earley Algorithm)
定义
一种更高效的句法分析方法,适用于更复杂的文法系统。
例子
如果一个句子有多重可能的解析方式(即存在歧义),耳朵算法可以有效地识别出所有可能的解析结构,而不是仅找到其中一个。
基于统计的句法分析(Probabilistic Parsing)
定义
利用机器学习或统计方法来预测最可能的句子结构。
例子
在面对歧义句子时,基于统计的方法可以使用预先训练好的模型来预测最可能的句子结构,而不仅仅是依赖规则。
转换基础的分析(Transition-Based Parsing)
定义
通过一系列操作(如推入、弹出、左移、右移等)来逐步构建句子的依存关系。
例子
在处理 "She eats an apple" 这个句子时,转换基础的分析会从 "She" 开始,通过一系列的操作,逐步添加 "eats" 和 "an apple",并建立它们之间的依存关系。
PyTorch实战演示
在这一节中,我们将使用PyTorch来实现上述几种句法分析方法。以下代码段是使用Python和PyTorch编写的,并注释详尽,以便理解。
自顶向下(Top-Down)分析
示例代码
下面的代码展示了如何用PyTorch实现一个简单的自顶向下句法分析模型。
import torch
import torch.nn as nn# 定义模型
class TopDownParser(nn.Module):def __init__(self, vocab_size, hidden_size):super(TopDownParser, self).__init__()self.embedding = nn.Embedding(vocab_size, hidden_size)self.rnn = nn.LSTM(hidden_size, hidden_size)self.classifier = nn.Linear(hidden_size, 3) # 假设有3种不同的短语类型:NP, VP, PPdef forward(self, x):x = self.embedding(x)x, _ = self.rnn(x)x = self.classifier(x)return x# 示例输入:5个词的句子(用整数表示)
input_sentence = torch.tensor([1, 2, 3, 4, 5])# 初始化模型
model = TopDownParser(vocab_size=10, hidden_size=16)
output = model(input_sentence)print("输出:", output)输入和输出
-
输入:一个用整数表示的句子(每个整数是词汇表中一个词的索引)。
-
输出:句子中每个词可能属于的短语类型(如名词短语、动词短语等)。
自底向上(Bottom-Up)分析
示例代码
# 同样使用上面定义的 TopDownParser 类,但训练和应用方式不同# 示例输入:5个词的句子(用整数表示)
input_sentence = torch.tensor([6, 7, 8, 9, 10])# 使用相同的模型
output = model(input_sentence)print("输出:", output)输入和输出
-
输入:一个用整数表示的句子。
-
输出:句子中每个词可能属于的短语类型。
这只是一个简单的实现示例,实际应用中可能需要更多的细节和优化。
七、总结
句法分析作为自然语言处理(NLP)的关键组成部分,扮演着理解和解析人类语言结构的重要角色。从历史背景到理论分类,再到短语与依存结构的理解,我们逐一探究了句法分析的多个维度。实际操作层面,PyTorch的应用进一步揭示了如何在现实任务中实施这些理论。通过整合理论和实践,我们不仅能更深刻地理解语言结构,也能更有效地处理各种NLP问题。这种跨学科的融合为未来更多创新性应用和研究提供了坚实的基础。
文章转载自:techlead_krischang
原文链接:https://www.cnblogs.com/xfuture/p/17816617.html