文章目录
- 为什么要学习Scala语言
- 什么是Scala
- 如何快速掌握Scala语言
- Scala环境安装配置
- Scala命令行
- Scala的基本使用
- 变量
- 数据类型
- 操作符
- if 表达式
- 语句终结符
- 循环
- 高级for循环
- Scala的集合体系
- 集合
- Set
- List
- Map
- Array
- ArrayBuffer
- 数组常见操作
- Tuple
- 总结
- Scala中函数的使用
- 函数的定义
- 函数的参数
- 特殊的函数-过程
- lazy
- Scala面向对象编程
- 类-class
- constructor
- 主constructor
- 对象-object
- 伴生对象
- apply
- main方法
- 接口-trait
- Scala函数式编程
- 什么是函数式编程
- 函数赋值给变量
- 匿名函数
- 高阶函数
- 常用高阶函数
- map的使用:
- flatMap
- foreach
- filter
- reduceLeft
- 案例:函数式编程
- Scala高级特性
- 模式匹配
- 对变量的值进行模式匹配
- 变量类型的模式匹配
- case class与模式匹配
- Option与模式匹配
- 隐式转换
- 案例:狗也能抓老鼠
为什么要学习Scala语言
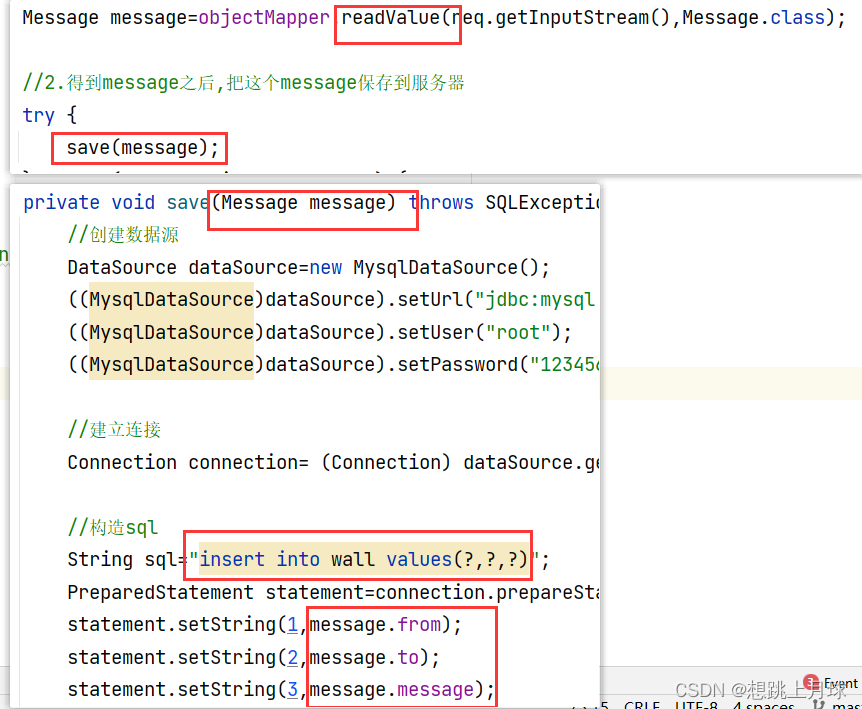
最直接的一点就是因为我们后面要学的Spark框架需要用到Scala这门语言。但是Spark其实是同时支持Scala语言和Java语言的,为什么非要学Scala呢,使用java它难道不香吗?
这就要说第二点了:看下面的代码,使用Spark统计文件内单词出现的次数这个需求,使用java代码和scala代码的区别是有多么的明显,在代码量上来说,scala是完胜java的,所以在实际工作中开发spark代码,我们都是需要使用scala的,使用java实现函数式编程太别扭了,代码量太大,这个就是我们学习scala的最直接的原因。

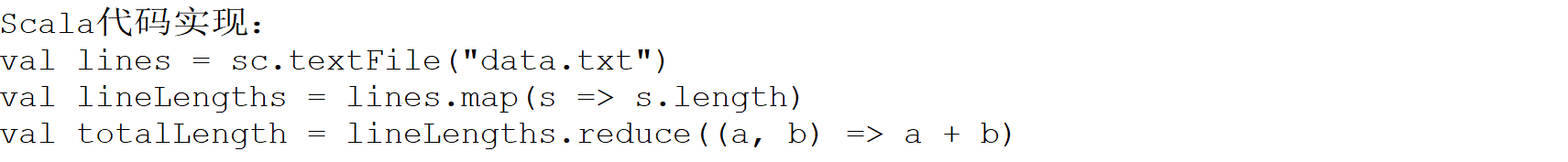
什么是Scala
Scala是一门多范式的编程语言,它是一种类似Java的编程语言,它设计的初衷是为了实现可伸缩的语言、并集成面向对象编程和函数式编程的各种特性。Scala基于Java虚拟机,也就是基于JVM的一门编程语言。所有Scala代码,都需要编译为字节码,然后交由Java虚拟机来运行。
Scala和Java可以无缝相互操作,Scala可以任意调用Java代码,这个特性是非常好的
如何快速掌握Scala语言
scala语言本身是很反人类的,特别是你熟悉了例如java之类的编程语言之后再来学scala,会感觉到既爱又恨
那我们如何快速掌握Scala语言的使用呢?
首先大家在学习的过程中需要对比分析Java和Scala在使用上的区别,这样可以加深我们的理解。然后没事的时候可以尝试着用Scala代码改写你之前的Java代码。
最后的最后,交给大家一个绝招,一个终极方案,那就是多练!多练!多练。因为针对编程语言,其实就是需要掌握它的一些基本语法,大家都是有其它语言编程基础的,在这学习Scala语言,其实主要就是掌握这门语言和其它语言的一些不同之处,只要把这些东西捋顺了,那上手也是很容易的。
Scala环境安装配置
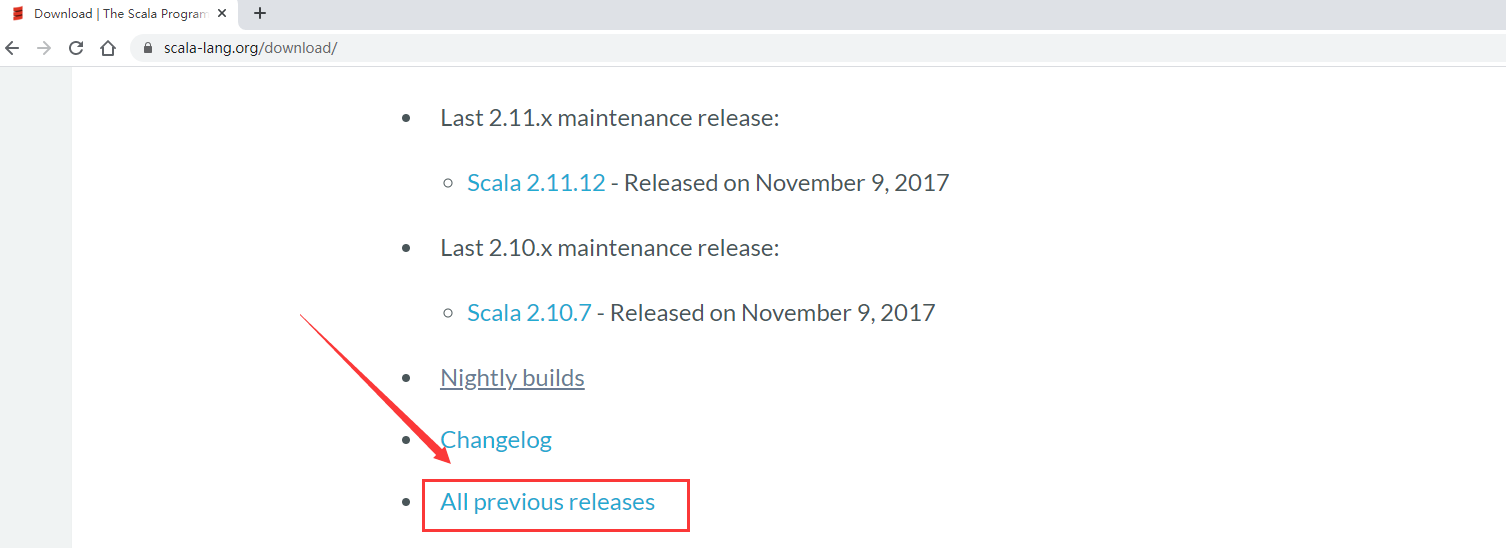
注意:由于Scala是基于Java虚拟机的,所以使用 Scala 之前必须先安装 Java,Java我们已经安装过了。那在这里我们先到官网下载Scala安装包
Scala现在有三个主要在使用的版本, 2.11,2.12,2.13。目前的话2.12使用的比较多,所以我们就使用这个版本
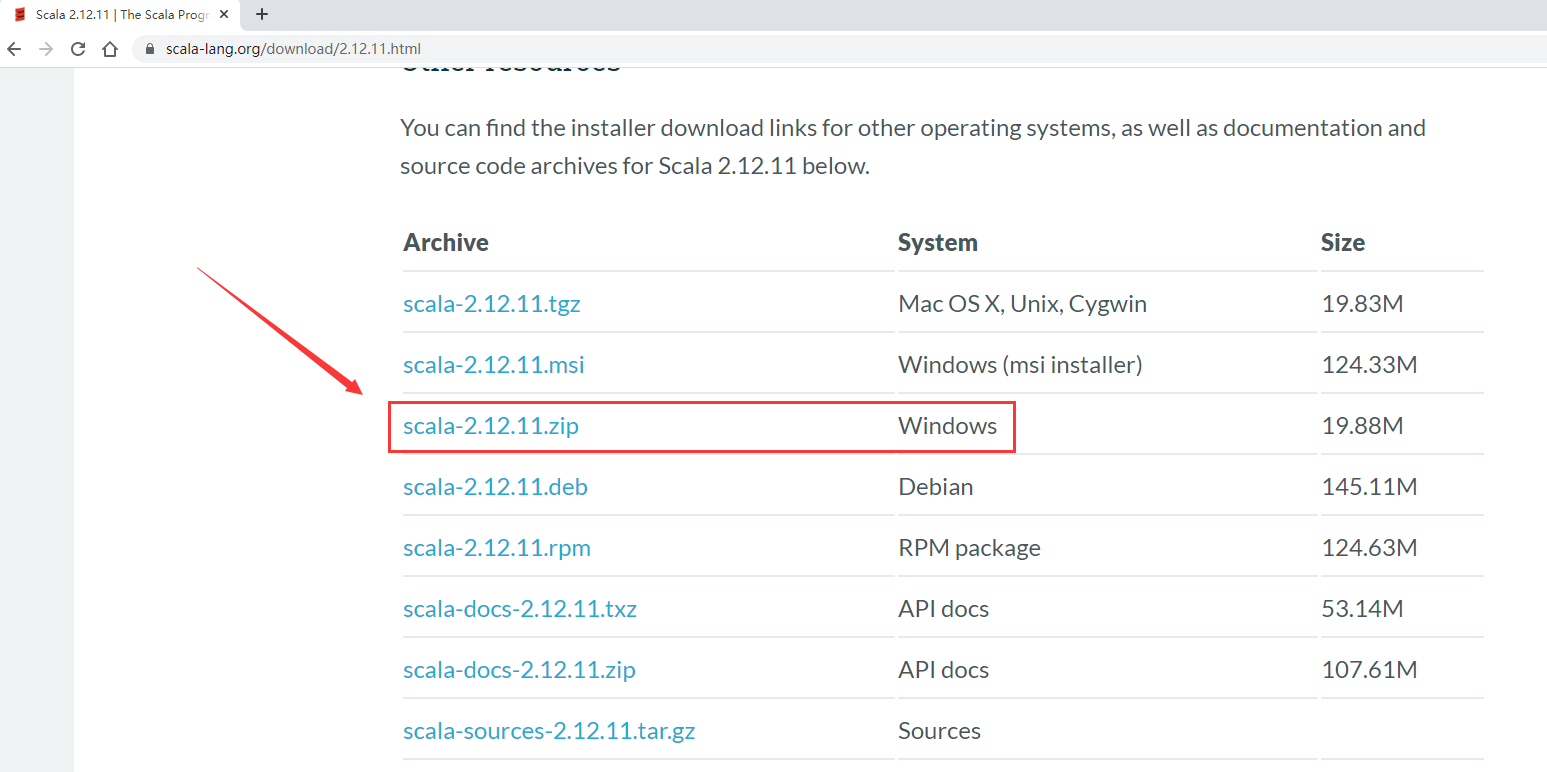
下载好了之后就需要安装了
安装很简单,直接解压就可以了,在这里我们把scala的安装包解压到了D盘下面的scala目录下
D:\scala\scala-2.12.11
接下来就该配置SCALA_HOME和PATH环境变量了,和Java的操作是一样的
SCALA_HOME=D:\scala\scala-2.12.11
PATH=...%SCALA_HOME%\bin...
进入cmd命令行,验证一下,输入scala命令,可以看到下面界面就说明安装配置成功了。
C:\Users\yehua>scala
Welcome to Scala version 2.10.6 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Scala命令行
Scala命令行也称为Scala解释器(REPL),它会快速编译Scala代码为字节码,然后交给JVM来执行
这里的REPL表示:Read(取值)-> Evaluation(求值)-> Print(打印)-> Loop(循环)
在Scala命令行内,输入Scala代码,解释器会直接返回结果
如果你没有指定变量来存放计算的值,那么值默认的名称会显示为res开头的变量,而且会显示结果的数据类型
scala> 1+1
res0: Int = 2
在后面可以继续使用res0这个变量,以及它里面存放的值
例如:
scala> 5 * res0
res1: Int = 10
scala的命令行也有自动补全功能,使用起来还是比较方便的
输入res,按键盘上的tab键,下面就会列出目前以res开头的变量名称
Scala的基本使用
变量
Scala中的变量分为两种:可变 var 和 不可变 val
- 可变var:可以随时修改var声明的变量的值
- 不可变val:val声明的变量,值不能被修改,否则会报错: error: reassignment to val
scala> var a = 1
a: Int = 1
scala> a = 2
a: Int = 2
scala> val b = 1
b: Int = 1
scala> b = 2
<console>:8: error: reassignment to val
b = 2
注意:在实际工作中,针对一些不需要改变值的变量,通常建议使用val,这样可以不用担心值被错误的修改(等于java中的final类型)。这样可以提高系统的稳定性和健壮性!
无论声明val变量,还是声明var变量,都可以手动指定变量的类型
如果不指定,Scala会自动根据值,进行类型推断 val c = 1 等价于 val c: Int = 1
scala> val c = 1
c: Int = 1
scala> val c: Int = 1
c: Int = 1
数据类型
Scala中的数据类型可以分为两种,基本数据类型和增强版数据类型
基本数据类型有: Byte、Char、Short、Int、Long、Float、Double、Boolean
增强版数据类型有: StringOps、RichInt、RichDouble、RichChar 等。scala使用这些增强版数据类给基本数据类型增加了上百种增强的功能
例如:RichInt提供的有一个to函数, 1.to(10) ,此处Int会先隐式转换为RichInt,然后再调用其to函数
scala> 1.to(10)
res2: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7,8,9,10)
注意,to函数还可以这样写
scala> 1 to 10
res3: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7,8,9,10)
使用基本数据类型,直接就可以调用RichInt中对应的函数
scala> 1.toString()
res4: String = 1
操作符
Scala的算术操作符与Java的算术操作符没有什么区别
比如 +、-、*、/、% 等,以及 &、|、^、>>、<< 等
注意:Scala中没有提供++、–操作符
我们只能使用+和- ,比如count = 1,count++是错误的,必须写做count += 1
scala> var count = 1
count: Int = 1
scala> count++
<console>:9: error: value ++ is not a member of Int
count++
^
scala> count += 1
scala> count
res8: Int = 2
if 表达式
在Scala中,if表达式是有返回值的,就是if或者else中最后一行语句返回的值,这一点和java中的if是不一样的,java中的if表达式是没有返回值的
例如: val age = 20; if (age > 18) 1 else 0
scala> val age = 20
age: Int = 20
scala> if(age > 18) 1 else 0
res9: Int = 1
在这因为if表达式是有返回值的,所以可以将if表达式赋予一个变量
scala> val res = if(age > 18) 1 else 0
res: Int = 1
由于if表达式是有值的,而if和else子句的值的类型可能还不一样,此时if表达式的值是什么类型呢?
注意:Scala会自动进行推断,取两个类型的公共父类型
例如,if(age > 18) 1 else 0,表达式的类型是Int,因为1和0都是Int
例如,if(age > 18) “old” else 0,此时if和else的值分别是String和Int,则表达式的值是Any类型,Any是String和Int的公共父类型
scala> if(age > 18) 1 else 0
res12: Int = 1
scala> if(age > 18) "old" else 0
res13: Any = old如果if后面没有跟else,则默认else的值是Unit,也可以用()表示,类似于java中的void或者null
例如,val age = 12; if(age > 18) “old”。此时就相当于if(age > 18) “old” else ()。
此时表达式的值是Any
scala> if(age > 18) "old" else ()
res17: Any = ()
如果想在scala REPL中执行多行代码,该如何操作?
使用 :paste 和 ctrl+D 的方式
:paste 表示代码块的开始
ctrl+D 表示代码块的结束
语句终结符
Scala默认不需要语句终结符,它将每一行作为一个语句
如果一行要放多条语句,则前面的语句必须使用语句终结符
语句终结符和Java中的一样,就是我们平时使用的分号
scala> val age = 20; if(age > 18) 1 else 0
age: Int = 20
res0: Int = 1
循环
- print和println
在讲循环之前,先来看一下打印命令print和println
print打印时不会加换行符,而println打印时会加一个换行符,这个特性和Java中的打印语句的特性是一样的 - for循环
for循环本身的特性就没什么好说的了,直接上案例,主要注意一下scala中的for和java中的for在语法层面的区别
scala> :paste
// Entering paste mode (ctrl-D to finish)
val n = 10
for(i <- 1 to n)
println(i)
// Exiting paste mode, now interpreting.
1
2
3
4
5
6
7
8
9
10
n: Int = 10
这里面的to可以换成until
scala> :paste
// Entering paste mode (ctrl-D to finish)
val n = 10
for(i <- 1 until 10)
println(i)
// Exiting paste mode, now interpreting.
1
2
3
4
5
6
7
8
对比两次执行的结果发现
1 to 10 可以获取1~10之间的所有数字
1 until 10可以获取1~9之间的所有数字
所以在这需要注意了,to 和 until 其实都是函数,一个是闭区间,一个是开区间,具体用哪个就要看你的需求了
for循环针对字符串还可以用
scala> for(c <- "hello scala") println(c)
h
e
l
l
o
s
c
a
l
a
注意:在这里我在for循环后面没有使用花括号,都省略了,主要是因为for循环的循环体代码就只有一行,如果有多行,就需要使用花括号了,否则,最终执行的结果就不是我们想要的
- while循环
while循环,它的用法和java中的while也是很像的,主要看一下语法层面的区别
scala> :paste
// Entering paste mode (ctrl-D to finish)
var n = 10
while(n>0){
println(n)
n -= 1
}
// Exiting paste mode, now interpreting.
10
9
8
7
6
5
4
3
2
1
n: Int = 0
高级for循环
最后来看一下高级for循环的用法
if守卫
if守卫模式,假设我们想要获取1~10之间的所有偶数,使用普通的for循环,需要把每一个数字都循环出来,然后判断是否是偶数。
如果在for循环里面使用if守卫,可以在循环的时候就执行一定的逻辑,判断数值是否是偶数。
scala> for(i <- 1 to 10 if i % 2 == 0) println(i)
2
4
6
8
10
这是if守卫模式的用法
for推导式
for推导式,一个典型例子是构造集合
我们在使用for循环迭代数字的时候,可以使用yield指定一个规则,对迭代出来的数字进行处理,并且创建一个新的集合。
scala> for(i <- 1 to 10) yield i *2
res16: scala.collection.immutable.IndexedSeq[Int] = Vector(2, 4, 6, 8, 10, 12,14,16,18,20)
Scala的集合体系
Scala中的集合体系,集合在工作中属于经常使用的数据结构
首先看一下整个集合体系结构,这个结构与Java的集合体系非常相似
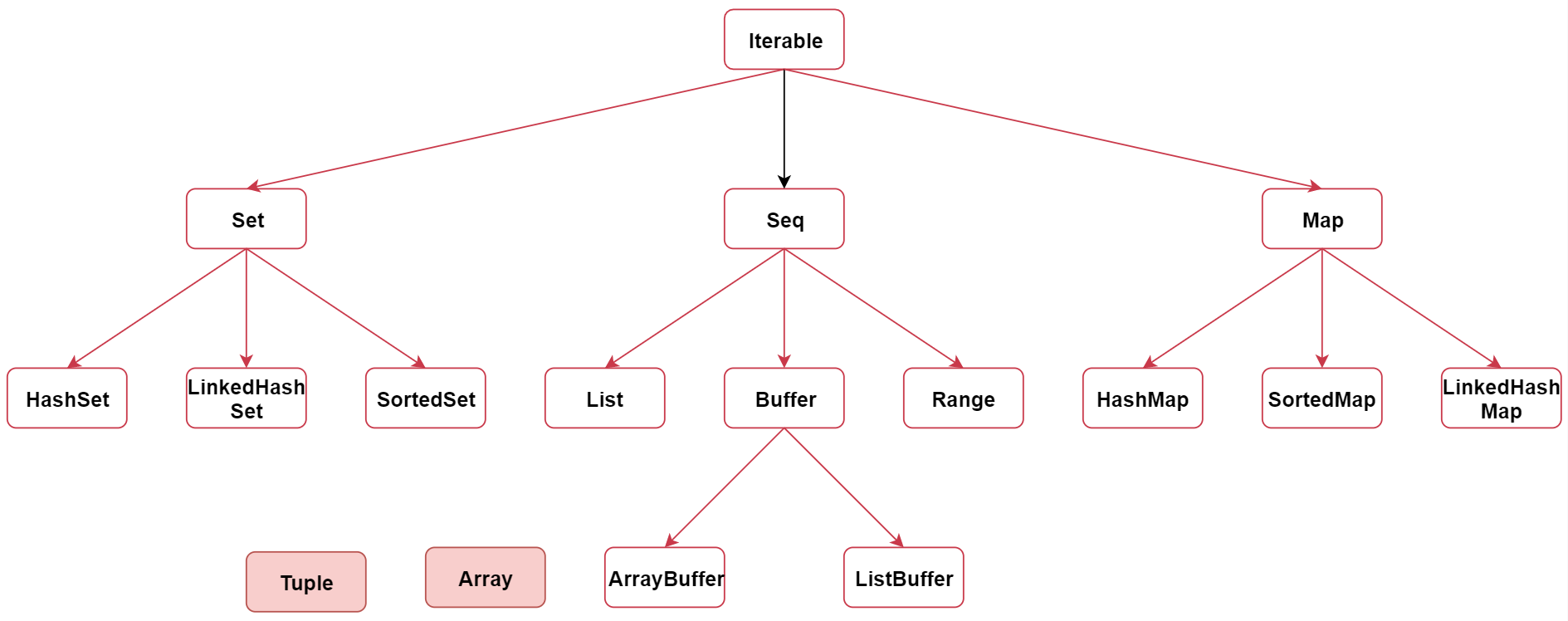
集合的顶层接口是Iterable,Iterable接口下面还有一些子接口, Set、Seq、Map
这几个子接口下面有具体的实现类
- set下面有HashSet、LinkedHashSet、SortedSet等等
- seq下面有List、Buffer、Range等等
- Map下面有HashMap、SortedMap、LinkedHashMap等等
- 其中Buffer下面还有两个常用的,ArrayBuffer、ListBuffer
这个集合体系的时候,还会关联讲到 Array和Tuple 这两个数据结构
集合
Scala中的集合是分成可变和不可变两类集合的
- 其中可变集合就是说,集合的元素可以动态修改
- 而不可变集合就是说,集合的元素在初始化之后,就无法修改了
可变集合:在 scala.collection.mutable 这个包下面
不可变集合:在 scala.collection.immutable 这个包下面
我们在创建集合的时候,如果不指定具体的包名,默认会使用不可变集合
Set
Set代表一个没有重复元素的集合
这个集合的特性和Java中Set集合的特性基本一样
Set集合分为可变的和不可变的集合,默认情况下使用的是不可变集合
Set可以直接使用,并且不需要使用new关键字,来看一下
scala> val s = Set(1,2,3)
s: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
本来Set是一个接口,但是却可以创建对象,更神奇的是竟然还不需要使用new关键字,这就有点颠覆我们的认知了
注意了,在学习Scala的时候,可以拿Java来进行对比,加深理解,但是不要全部拿Java里面的知识点来硬套,因为它们两个有些地方还是不一样的。
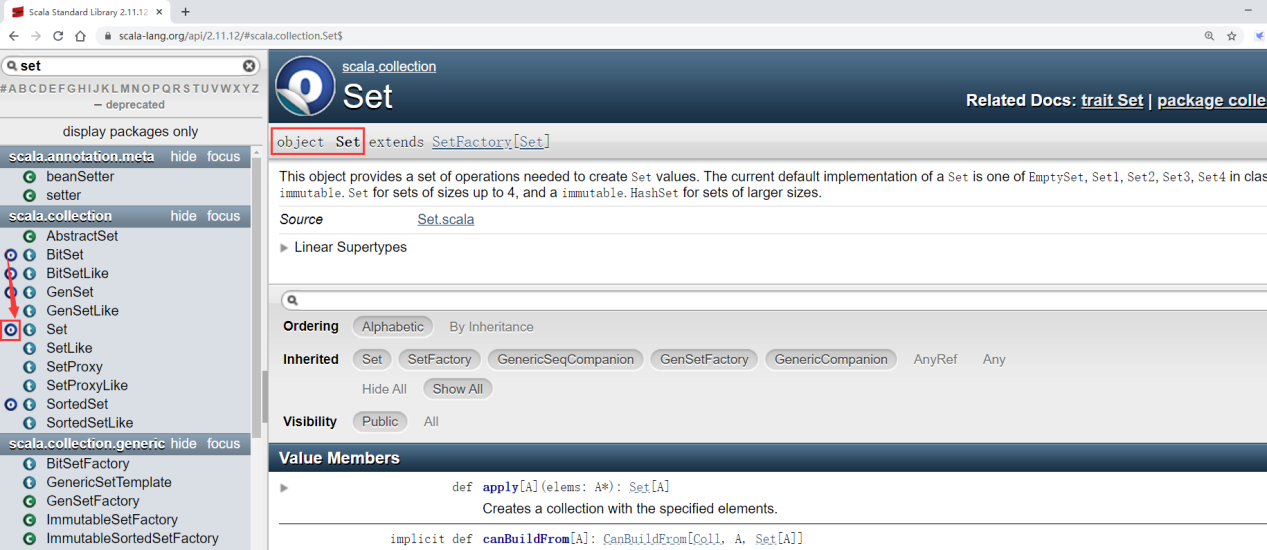
只要前面带有object的,可以直接创建对象,并且不需要使用new关键字所以set可以直接使用。
注意:默认情况下直接创建的set集合是一个不可变集合,在这可以看到是在immutable包里面
的,不可变集合中的元素一经初始化,就不能改变了,所以初始化后再向里面添加元素就报错了。
scala> val s = Set(1,2,3)
s: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
scala> s += 4
<console>:9: error: value += is not a member of scala.collection.immutable.Set
s += 4
但是注意,我使用s + 4 这种操作是可以的, 因为 s + 4 返回的是一个新的集合了,相当于在之前的集合的基础上,创建一个新的集合,新的集合包含之前集合的元素和我们新增的4这个元素这个大家需要能够区分开。如果想要创建一个可变的set集合,可以使用mutable包下面的set集合,显式指定包名
scala> val s = scala.collection.mutable.Set(1,2,3)
s: scala.collection.mutable.Set[Int] = Set(1, 2, 3)
scala> s += 4
res34: s.type = Set(1, 2, 3, 4)
Set常用子类有: HashSet、LinkedHashSet、SortedSet
- HashSet:这个集合的特点是:集合中的元素不重复、无序
- LinkedHashSet:这个集合的特点是:集合中的元素不重复、有序,它会用一个链表维护插入顺序,可以保证集合中元素是有序的
- SortedSet:这个集合的特点是:集合中的元素不重复、有序,它会自动根据元素来进行排序
先看HashSet
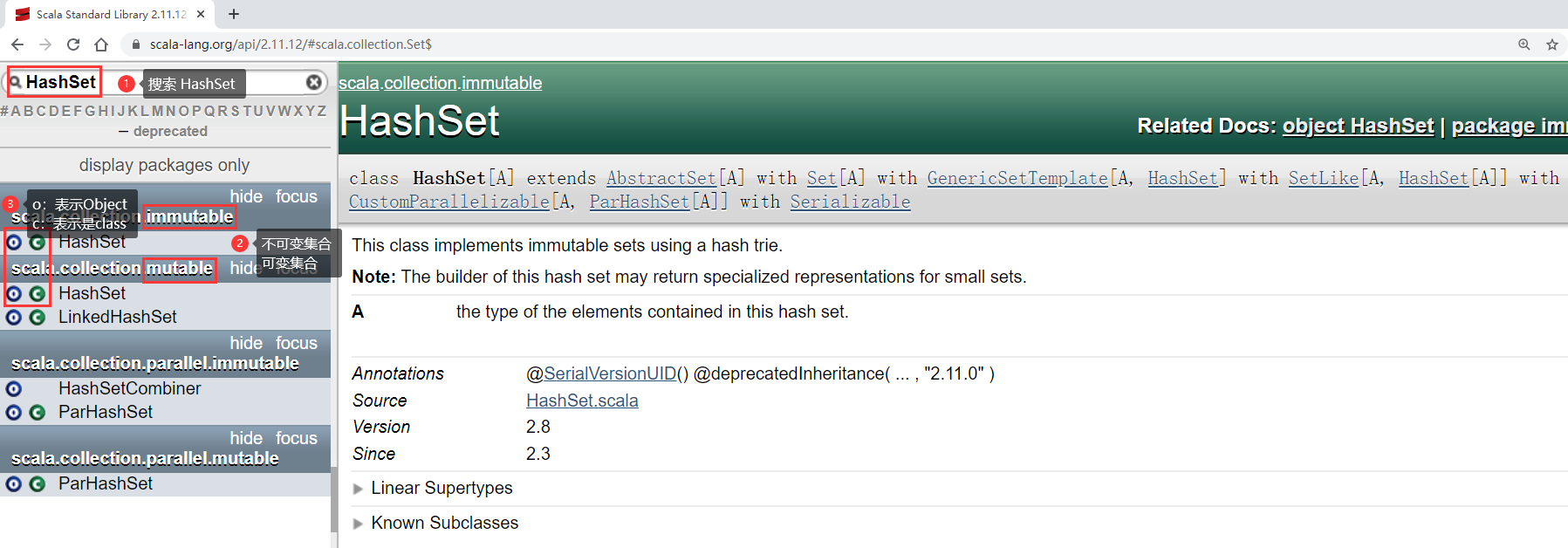
HashSet集合分为可变和不可变之分, immutable 包下面的是不可变的,后期无法新增元素。
在这里可以使用new关键字,也可以不使用,因为HashSet既是class,又是object,但是包名需要指定,否则无法识别
scala> val s = new scala.collection.mutable.HashSet[Int]()
s: scala.collection.mutable.HashSet[Int] = Set()
scala> s +=1
res35: s.type = Set(1)
scala> s +=2
res36: s.type = Set(1, 2)
scala> s +=5
res38: s.type = Set(1, 5, 2)
List
List属于Seq接口的子接口,List代表一个不可变的列表
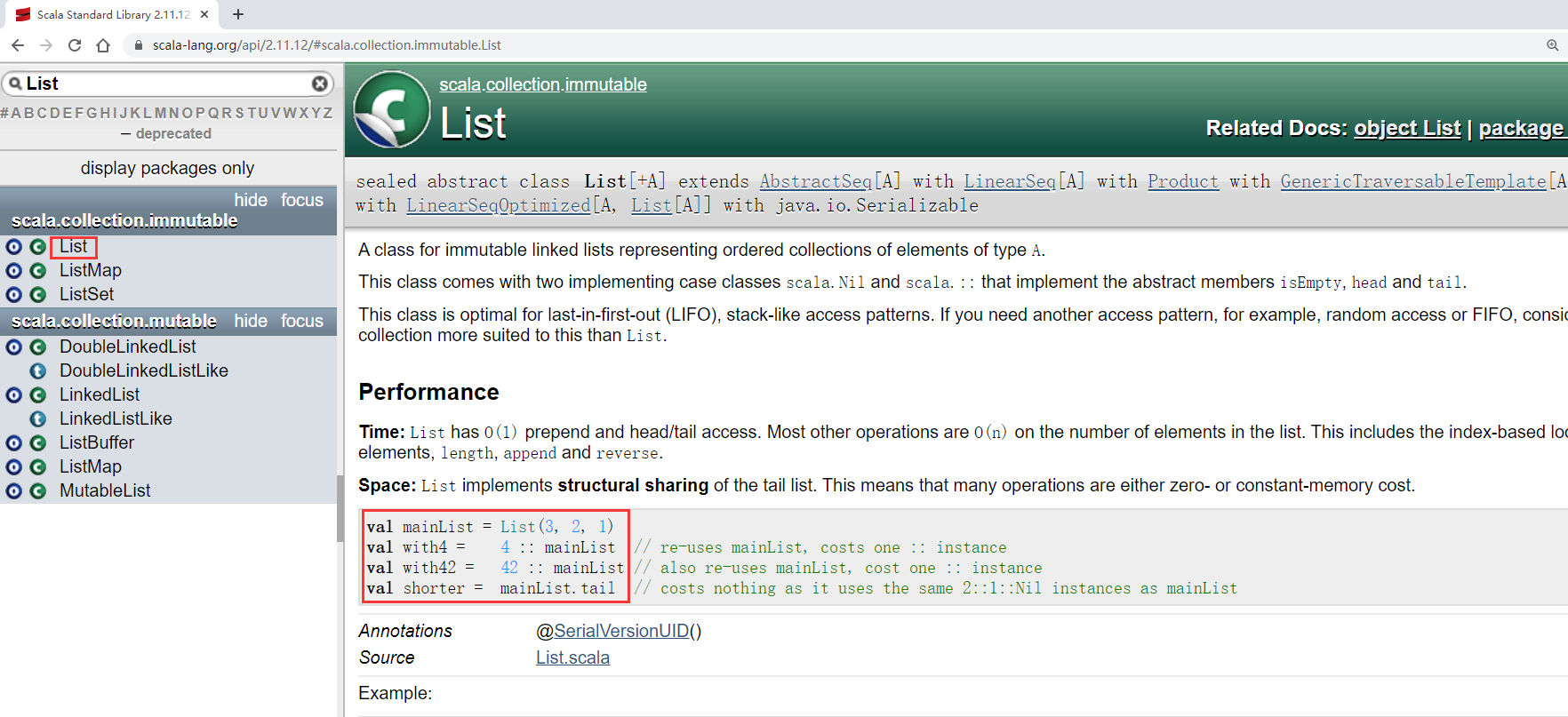
创建一个list
scala> val l = List(1, 2, 3, 4)
l: List[Int] = List(1, 2, 3, 4)
注意:为什么有的地方需要写类的全路径,而有的不需要呢?
由于immutable包是默认导入的,所以不需要导包,但是也会有个别虽然在immutable包下面的,但是不写全路径还是报错,原谅它把,反正你都带全路径肯定是没有问题的,后期我们会使用idea来开发,也不需要考虑包名的问题,不过在这为了演示起来更加清晰,就使用scala的命令行了。
针对List有 head 、 tail 以及 :: 这几个操作
先演示一下 head、tail 操作
scala> l.head
res49: Int = 1
scala> l.tail
res51: List[Int] = List(2, 3, 4)
- head:表示获取List中的第一个元素
- tail:表示获取List中第一个元素之后的所有元素
那其实head和tail就可以获取list中的所有元素了
通过 :: 操作符,可以将head和tail的结果合并成一个List
scala> l.head :: l.tail
res52: List[Int] = List(1, 2, 3, 4)
针对List中的元素进行迭代和前面讲的Set集合的迭代是一样的
scala> val l = List(1, 2, 3, 4)
l: List[Int] = List(1, 2, 3, 4)
scala> for(i <- l) println(i)
1
2
3
4
在这里List是不可变的列表,在实际工作中使用的时候会很不方便,因为我们很多场景下都是需要向列表中动态添加元素,这个时候该怎么办呢?
Scala还提供的有一个ListBuffer
ListBuffer:可以支持动态增加或者移除元素
scala> val lb = scala.collection.mutable.ListBuffer[Int]()
lb: scala.collection.mutable.ListBuffer[Int] = ListBuffer()
scala> lb +=1
res56: lb.type = ListBuffer(1)
scala> lb +=2
res57: lb.type = ListBuffer(1, 2)
scala> lb +=5
res58: lb.type = ListBuffer(1, 2, 5)
scala> lb -=5
res59: lb.type = ListBuffer(1, 2)
ListBuffer也可以直接使用for循环迭代
scala> for(i <- lb) println(i)
1
2
Map
Map是一种可迭代的键值对(key/value)结构
创建一个不可变的Map
scala> val ages = Map("jack"->30,"tom"->25,"jessic"->23)
ages: scala.collection.immutable.Map[String,Int] = Map(jack -> 30, tom -> 25,
scala> ages("jack")
res100: Int = 30
创建一个可变的Map
scala> val ages = scala.collection.mutable.Map("jack"->30,"tom"->25,"jessic"-
ages: scala.collection.mutable.Map[String,Int] = Map(jessic -> 23, jack -> 30
scala> ages("jack")
res101: Int = 30
还有一种创建Map的简易方式,这种方式创建的是不可变Map
scala> val ages = Map(("jack",30),("tom",25),("jessic"->23))
ages: scala.collection.immutable.Map[String,Int] = Map(jack -> 30, tom -> 25,
更新map中的元素
scala> ages("jack") = 31
scala> ages
res104: scala.collection.mutable.Map[String,Int] = Map(jessic -> 23, jack ->
增加多个元素
scala> ages += ("hehe" -> 35, "haha" -> 40)
res105: ages.type = Map(hehe -> 35, jessic -> 23, jack -> 31, tom -> 25
移除元素
scala> ages -= "hehe"
res106: ages.type = Map(jessic -> 23, jack -> 31, tom -> 25, haha -> 40)
遍历
遍历map的entrySet
scala> for ((key, value) <- ages) println(key + " " + value)
jessic 23
jack 31
tom 25
haha 40
最后看一下Map的几个子类
HashMap、SortedMap和LinkedHashMap
- HashMap:是一个按照key的hash值进行排列存储的map
- SortedMap:可以自动对Map中的key进行排序【有序的map】
- LinkedHashMap:可以记住插入的key-value的顺序
HashMap分为可变和不可变的,没有什么特殊之处
在这主要演示一下SortedMap和LinkedHashMap
Array
Scala中Array的含义与Java中的数组类似,长度不可变
由于Scala和Java都是运行在JVM中,双方可以互相调用,因此Scala数组的底层实际上就是Java数组。数组初始化后,长度就固定下来了,而且元素全部根据其类型进行初始化
scala> val a = new Array[Int](10)
a: Array[Int] = Array(0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
scala> a(0)
res65: Int = 0
scala> a(0)=1
scala> a(0)
res67: Int = 1
也可以直接使用Array()创建数组,元素类型自动推断
scala> val a = Array("hello", "world")
scala> a(0)
res68: String = hello
scala> val a1 = Array("hello", 30)
a1: Array[Any] = Array(hello, 30)
如果想使用一个长度可变的数组,就需要使用到ArrayBuffer了
ArrayBuffer
Scala中ArrayBuffer与Java中的ArrayList类似,长度可变
ArrayBuffer:添加元素、移除元素
如果不想每次都使用全限定名,则可以预先导入ArrayBuffer类
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
- 初始化
使用ArrayBuffer()的方式可以创建一个空的ArrayBuffer
注意:也支持直接创建并且初始化ArrayBuffer(1,2,3,4)
scala> val b = new ArrayBuffer[Int]()
b: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer()
- 添加元素
使用+=操作符,可以添加一个元素,或者多个元素
b += 1 或者 b += (2, 3, 4, 5)
scala> b += 1
res69: b.type = ArrayBuffer(1)
scala> b += (2, 3, 4, 5)
res70: b.type = ArrayBuffer(1, 2, 3, 4, 5)
使用insert()函数可以在指定位置插入元素,但是这种操作效率很低,因为需要移动指定位置后的所有元素向3号角标的位置添加一个元素 30
scala> b.insert(3,30)
scala> b
res72: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 30, 4
- 移除元素
使用 remove() 函数可以移除指定位置的元素
注意:Array与ArrayBuffer可以互相进行转换
- b.toArray:ArrayBuffer转Array
- a.toBuffer:Array转ArrayBuffer
数组常见操作
- 遍历Array和ArrayBuffer的两种方式
由于Array和ArrayBuffer都是有角标的,所以在迭代数组中元素的时候除了可以使用前面迭代集合的
方式还可以使用角标迭代
scala> val b=ArrayBuffer(1, 2, 3, 4, 5)
b: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 4, 5)
scala> for(i <- b) println(i)
1
2
3
4
5
scala> for(i <- 0 until b.length ) println(b(i))
1
2
3
4
5
- 求和、求最大值
scala> val a = Array(3, 2, 1, 4, 5)
a: Array[Int] = Array(3, 2, 1, 4, 5)
scala> val sum = a.sum
sum: Int = 15
scala> val max = a.max
max: Int = 5
- 数组排序
scala> scala.util.Sorting.quickSort(a)
scala> a
res99: Array[Int] = Array(1, 2, 3, 4, 5)
Tuple
Tuple:称之为元组,它与Array类似,都是不可变的,但与数组不同的是元组可以包含不同类型的元素Tuple中的元素角标从 1 开始
注意:目前 Scala 支持的元组最大长度为 22 ,对于更大长度可以使用集合或数组
scala> val t = (1, 3.14, "hehe")
t: (Int, Double, String) = (1,3.14,hehe)
scala> t._1
res117: Int = 1
scala> t._3
res118: String = hehe
总结
前面讲了很多集合体系中的数据结构,有的是可变的,有的是不可变的,有的是既是可变的又是不可变的,听起来有点乱,在这里我们总结一下
可变集合: LinkedHashSet、ListBuffer、ArrayBuffer、LinkedHashMap
不可变集合: List、SortedMap
可变+不可变集合: Set、HashSet、SortedSet、Map、HashMap
还有两个编外人员:
Array、Tuple
Array:长度不可变,里面的元素可变
Tuple:长度不可变,里面的元素也不可变
Scala中函数的使用
函数的定义
在Scala中定义函数需要使用 def 关键字,函数包括函数名、参数、函数体。Scala要求必须给出函数所有参数的类型,但是函数返回值的类型不是必须的,因为Scala可以自己根据函数体中的表达式推断出返回值类型。函数中最后一行代码的返回值就是整个函数的返回值,不需要使用return,这一点与Java不同,java中函数的返回值是必须要使用return的
下面来实现一个单行函数和多行函数
- 单行函数
scala> def sayHello(name: String) = print("Hello, " + name)
sayHello: (name: String)Unit
scala> sayHello("Scala")
Hello, Scala
- 多行函数
scala> :paste
// Entering paste mode (ctrl-D to finish)
def sayHello(name: String, age: Int) = {println("My name is "+name+",age is "+age)age
}
// Exiting paste mode, now interpreting.
sayHello: (name: String, age: Int)Int
scala> sayHello("Scala",18)
My name is Scala,age is 18
res120: Int = 18
函数的参数
- 默认参数
在Scala中,有时候我们调用某些函数时,不希望给出参数的具体值,而是希望使用参数自身默认的值,此时就需要在定义函数时使用默认参数。如果给出的参数不够,则会从左往右依次应用参数。
scala> def sayHello(fName: String, mName: String = "mid", lName: String = "last")
sayHello: (fName: String, mName: String, lName: String)String
scala> sayHello("zhang","san")
res122: String = zhang san last
- 带名参数
在调用函数时,也可以不按照函数定义的参数顺序来传递参数,而是使用带名参数的方式来传递。
scala> def sayHello(fName: String, mName: String = "mid", lName: String = "last")
sayHello: (fName: String, mName: String, lName: String)String
scala> sayHello(fName = "Mick", lName = "Tom", mName = "Jack")
res127: String = Mick Jack Tom
- 可变参数
在Scala中,有时我们需要将函数定义为参数个数可变的形式,则此时可以使用变长参数来定义函数。
scala> :paste
// Entering paste mode (ctrl-D to finish)
def sum(nums: Int*) = {var res = 0for (num <- nums) res += numres
}
// Exiting paste mode, now interpreting.
sum: (nums: Int*)Int
scala> sum(1,2,3,4,5)
res129: Int = 15
特殊的函数-过程
在Scala中,定义函数时,如果函数体直接在花括号里面而没有使用=连接,则函数的返回值类型就是Unit,这样的函数称之为过程
过程通常用于不需要返回值的函数
过程还有一种写法,就是将函数的返回值类型显式定义为Unit
比较一下这四种写法的区别
def sayHello(name: String) = "Hello, " + name
def sayHello(name: String): String = "Hello, " + name
def sayHello(name: String) { "Hello, " + name }
def sayHello(name: String): Unit = "Hello, " + name
前面两种写法的效果是一样的,都是函数
后面两种写法的效果是一样的,都是过程
lazy
Scala提供了lazy特性,如果将一个变量声明为lazy,则只有在第一次使用该变量时,变量对应的表达式才会发生计算
什么场景下需要使用lazy特性呢?
这种特性对于特别耗时的操作特别有用,比如打开文件这个操作。
scala> import scala.io.Source._
import scala.io.Source._
scala> lazy val lines = fromFile("D://test.txt").mkString
lines: String = <lazy>
即使D://test.txt文件不存在,代码也不会报错,只有变量使用时才会报错,这就是lazy这个特性。
Scala面向对象编程
在这里我们主要学习Scala中的类、对象和接口
注意:
Scala中类和java中的类基本是类似的
Scala中的对象时需要定义的,而java中的对象是通过class new出来的
Scala中的接口是trait,java中的接口是interface
类-class
首先看一下类
Scala中定义类和Java一样,都是使用 class 关键字
和Java一样,使用new关键字创建对象
那下面来看一个具体案例
定义Person类,
class Person{
var name = "scala"
def sayHello(){println("Hello,"+name)
}
def getName= name
}
注意:如果在定义方法的时候指定了(),那么在调用的时候()可写可不写,如果在定义方法的时候没指定(),则调用方法时肯定不能带()
scala> val p = new Person()
p: Person = Person@23b8d9f3
scala> p.sayHello()
Hello,scala
scala> p.sayHello
Hello,scala
scala> println(p.getName)
scala
scala> println(p.getName())
constructor
类创建好了,下面我们来看一下类中的构造函数,
Scala类中的构造函数可以分为主构造函数和辅助构造函数
这两种构造函数有什么区别呢?
主constructor:类似Java的默认构造函数 this()
辅助constructor:类似Java的重载构造函数 this(name,age)
主constructor
那先来看一下主构造函数
Scala的主constructor是与类名放在一起的,与Java不同,Java中的构造函数是写在类内部的
注意:在类中,没有定义在任何方法或者是代码块之中的代码就是主constructor的代码
先定义一个Student类
class Student(val name:String,val age:Int){
println("your name is " + name + ", your age is " + age)
}
创建对象
scala> new Student("zs",19)
your name is zs, your age is 19
res8: Student = Student@3134153d
在创建对象的时候,类中的println语句执行了,说明这个语句属于主构造函数中的代码,主constructor中还可以通过使用默认参数,来给参数设置默认值
class Student(val name:String = "jack",val age:Int = 20){
println("your name is " + name + ", your age is " + age)
}
创建对象
scala> new Student()
your name is jack, your age is 20
res10: Student = Student@7ddd84b5
scala> new Student("tom",18)
your name is tom, your age is 18
res11: Student = Student@a09303
Scala中,可以给类定义多个辅助constructor,类似于java中的构造函数重载。辅助constructor之间可以互相调用,但是第一行必须调用主constructor
来看一个案例:
给学生指定姓名和年龄信息
class Student {
var name = "jack"
var age = 10
def this(name: String) {
this()
this.name = name
}
def this(name: String, age: Int) {
this(name)
this.age = age
}
}
执行
scala> val s = new Student("tom")
s: Student = Student@1a538ed8
scala> val s = new Student("mick",30)
s: Student = Student@319642db
对象-object
我们学习的scala中的class和java中的class是类似的,下面来看一个java中没有的内容,叫Object
那大家可能有疑问了,Java中也有object,通过class就可以创建object
但是注意了,在scala中,我们可以直接定义一个object,就像定义class一样。
object:相当于class的单个实例,通常在里面放一些静态的field或者method
object不能定义带参数的constructor,只有空参的constructor
第一次调用object的方法时,会执行object的constructor,也就是执行object内部不在任何方法中的代码,因为它只有空参的构造函数。但是注意,object的constructor的代码只会在他第一次被调用时执行一次,以后再次调用就不会再执行了object通常用于作为单例模式的实现,或者放class的一些静态成员,比如工具方法。object可以直接使用,不能new创建一个object,使用object关键字
object Person {var age = 1println("this Person object!")def getAge = age
}
执行,直接通过Object的名称调用属性或者方法即可,类似于Java中的静态类
伴生对象
前面学习了class和object,那下面再来看一个特殊的概念,伴生对象
如果有一个class,还有一个与class同名的object,那么就称这个object是class的 伴生对象 ,class是object的 伴生类
注意:伴生类和伴生对象必须存放在一个.scala文件之中
伴生类和伴生对象最大特点在于可以互相访问private field
创建一个Person object和Person class
object Person {
private val fdNum= 1def getFdNum = fdNum
}class Person(val name: String, val age: Int) {def sayHello = println("Hi, " + name + ",you are " + age + " years old!" +
}
执行
scala> new Person("tom",20).sayHello
Hi, tom,you are 20 years old!, and you have 1 friend.
scala> Person.fdNum
<console>:9: error: value fdNum is not a member of object Person
Person.fdNum
^
scala> Person.getFdNum
res26: Int = 1
apply
apply是object中非常重要的一个特殊方法,通常在伴生对象中实现apply方法,并在其中实现构造伴生类对象的功能
在创建对象的时候,就不需要使用new Class的方式,而是使用Class()的方式,隐式调用伴生对象的
apply方法,这样会让对象创建更加简洁
例如:Array的伴生对象的apply方法就实现了接收可变数量的参数,以及会创建一个Array对象
val a = Array(1, 2, 3, 4, 5)
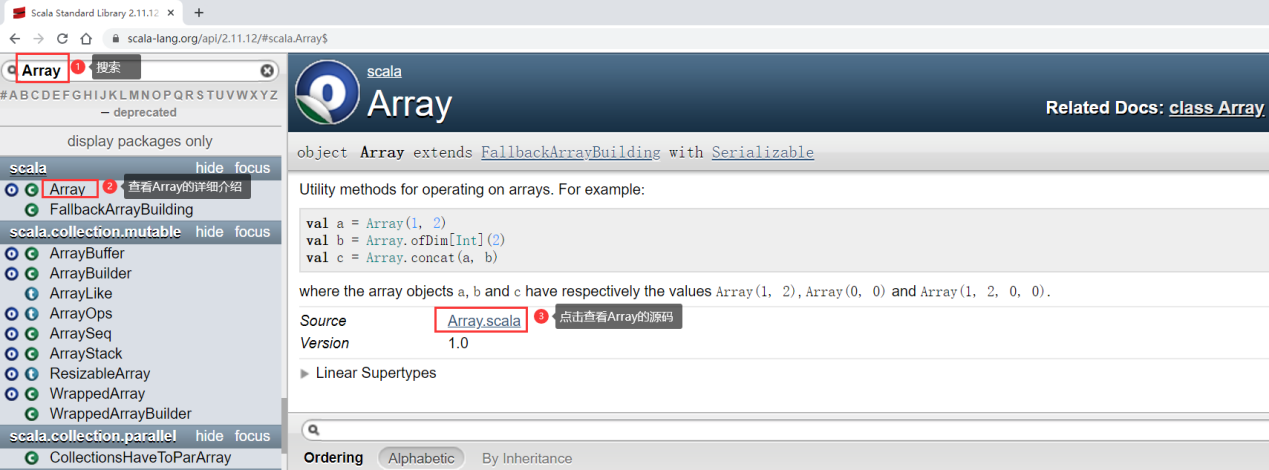
从Array object的源码中可以看出来,它里面就是在apply方法内部使用new Array创建的对象。下面我们来自己定义一个伴生类和伴生对象
class Person(val name: String){println("my name is,"+name)
}
object Person {def apply(name: String) = {println("apply exec...")new Person(name)}
}
执行
scala> new Person("tom")
my name is,tom
res29: Person = Person@63917fe1
scala> Person("tom")
apply exec...
my name is,tom
res30: Person = Person@35e74e08
注意:在这里new Person(“zhang”) 等于 Person(“zhang”),都是获取Person的对象
只不过Person(“zhang”)是用的object中apply方法, 而new Person(“zhang”)是直接基于class创建的。这两种方式肯定Person(“zhang”)这种方式使用起来更加方便简洁
main方法
接下来看一下scala中的main方法和Java一样,在Scala中如果要运行一个应用程序,必须有一个main方法,作为入口
Scala中的main方法必须定义在object中,格式为 def main(args: Array[String])
这就需要在编辑器中操作了,我们可以使用eclipse或者idea,但是eclipse对scala的支持不太好,所以建议使用idea。
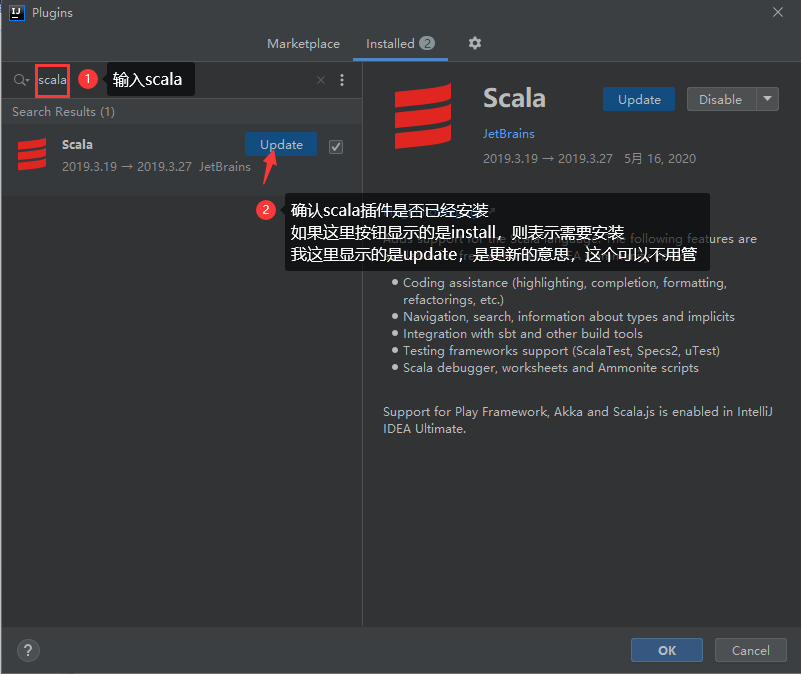
首先确认一下idea中是否集成了scala语言插件
打开idea,点击 configure–>plugins

确认scala的插件是否已经安装
接着创建maven项目
点击开启自动引入依赖
到这还没完,因为此时我们是无法创建scala代码的,这个项目中也没有集成scala的sdk,只有java的
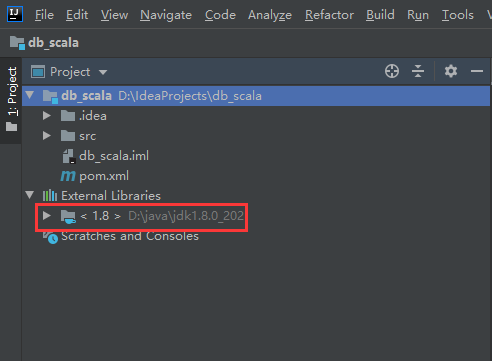
接下来就需要给这个项目添加scala的sdk了
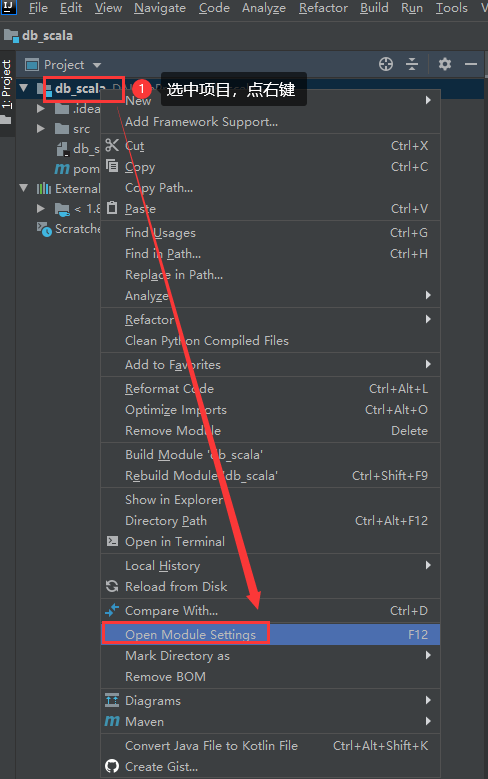
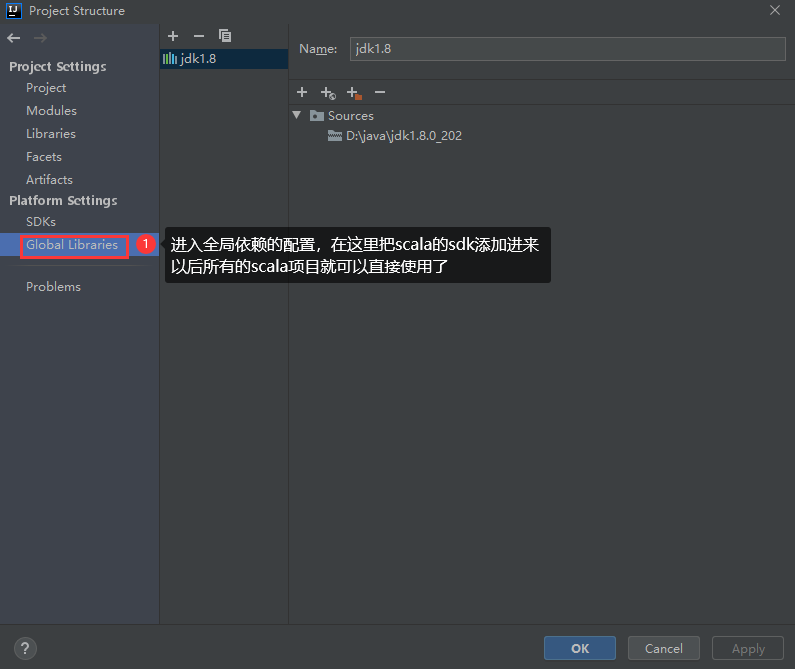
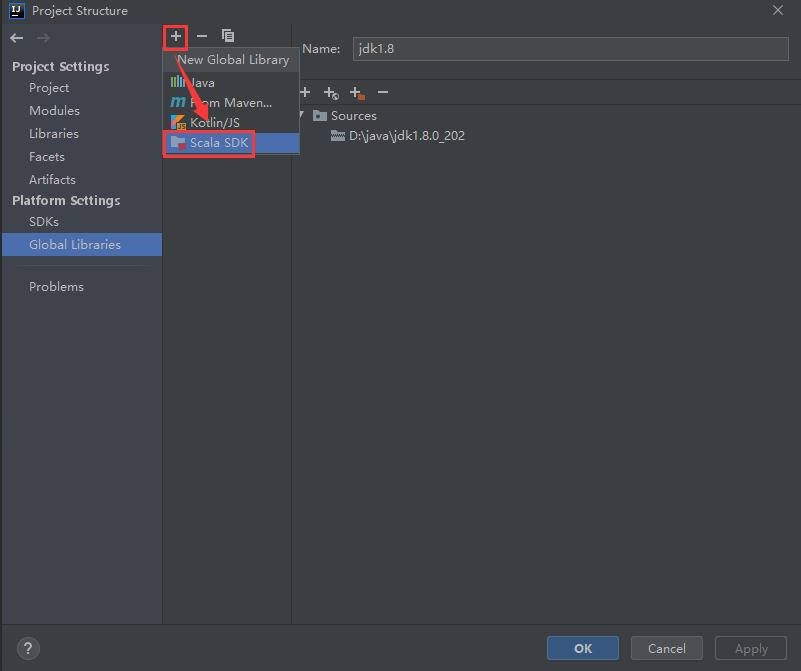
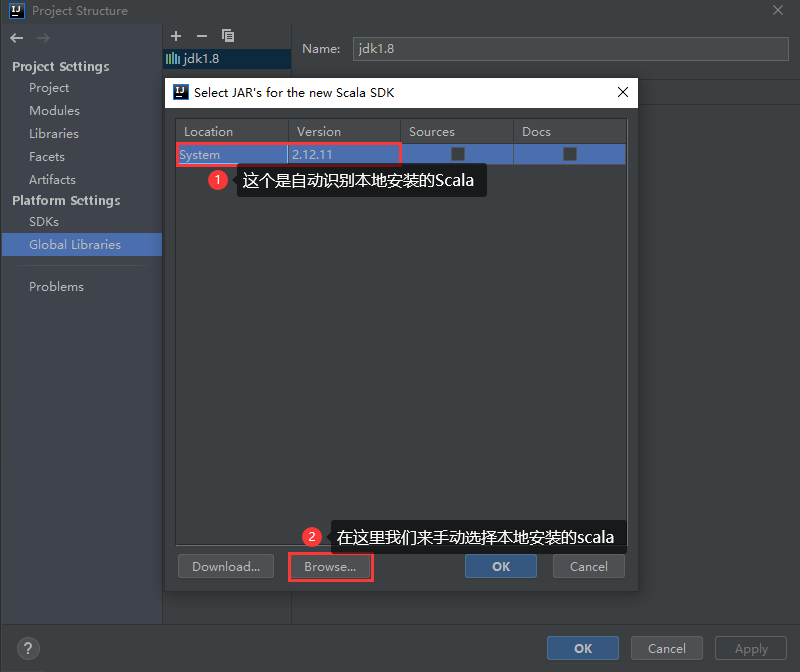
添加成功以后是这样的
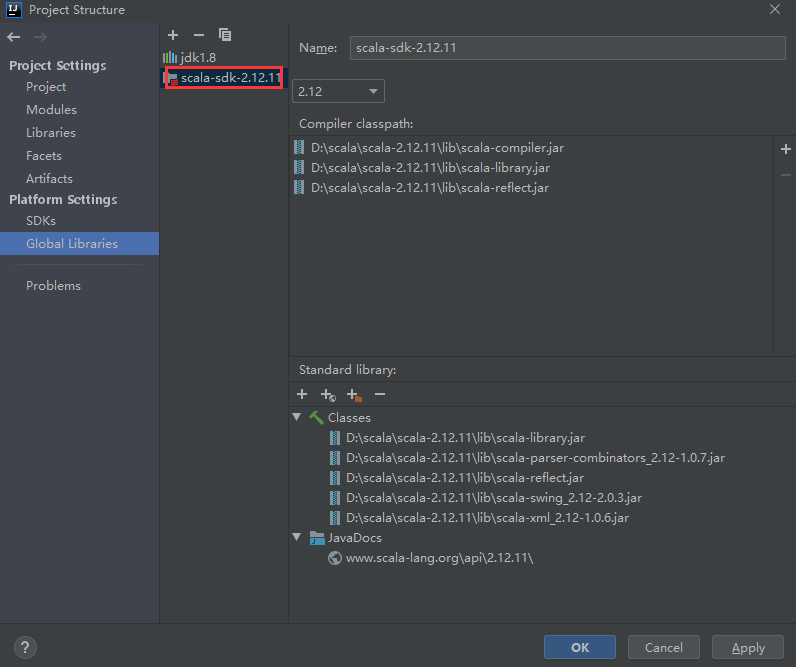
此时查看项目的依赖,发现scala的sdk已经添加进来了。
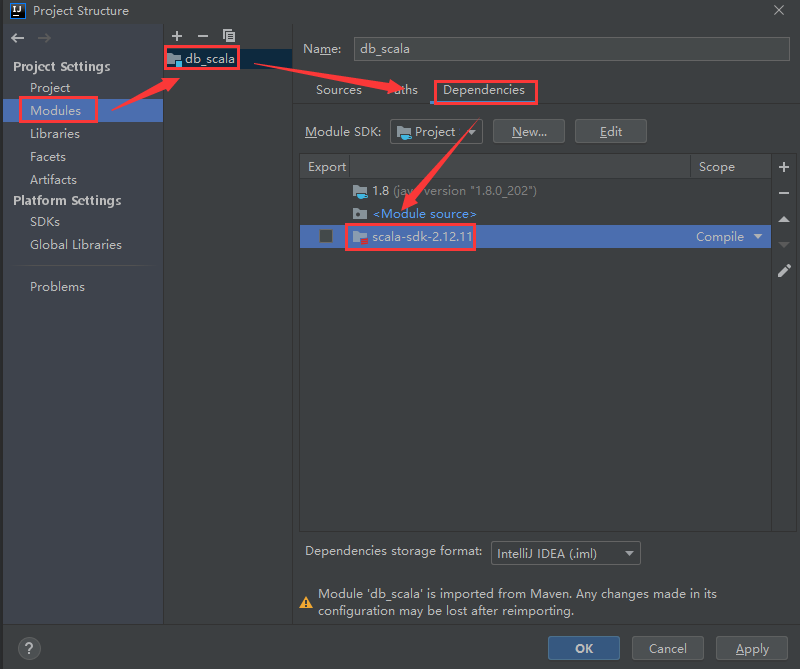
最终点击ok即可
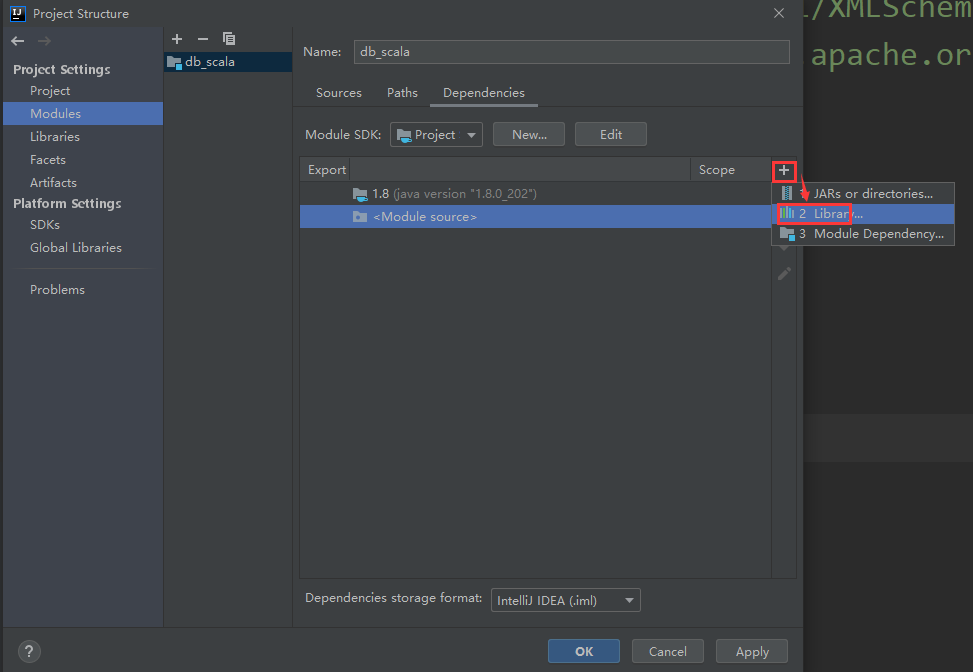
以后再创建想要创建scala的maven项目,只需要进入到这个界面确认项目中是否有scala的依赖,没有的话直接点击右边的加号按钮添加即可
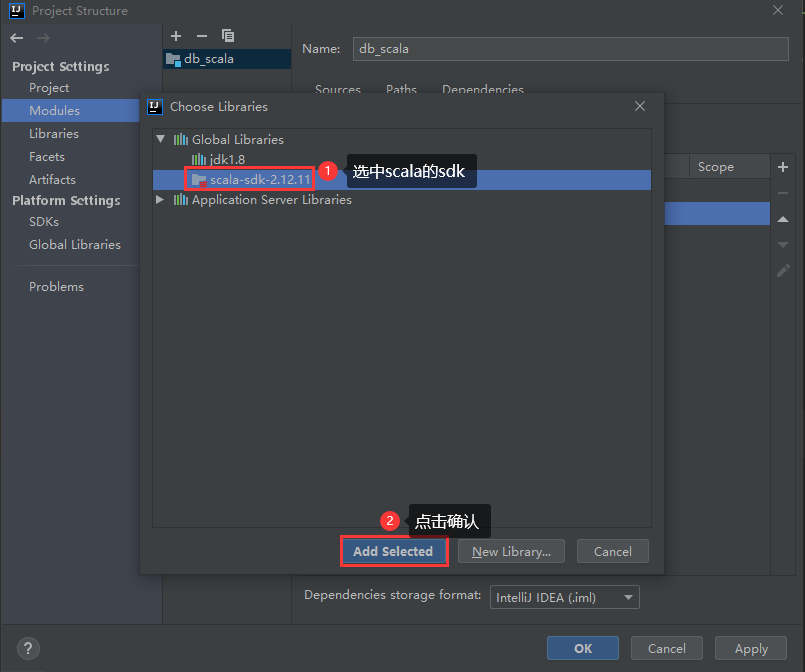
idea的scala开发环境配置好了,但是我一般还是喜欢再增加一些配置
目前项目的src目录下有一个java目录,这个目录表示是放java代码的,当然了你在里面写scala代码肯定是没有问题的。只是针对我这种稍微有点强迫症的用起来就有点别扭了。
在实际工作中可能我们一个项目既需要使用到java代码,也需要使用到scala代码,所以最好还是建议把java代码和scala代码分开存放,这样比较清晰
这样创建的scala目录是有问题的,你有没有发现这个目录的颜色和java目录的颜色都不一样因为你在这直接创建的scala目录是一个普通的目录,而java那个目录是一个source根目录。
所以我们也需要把scala目录变为source根目录。这样操作
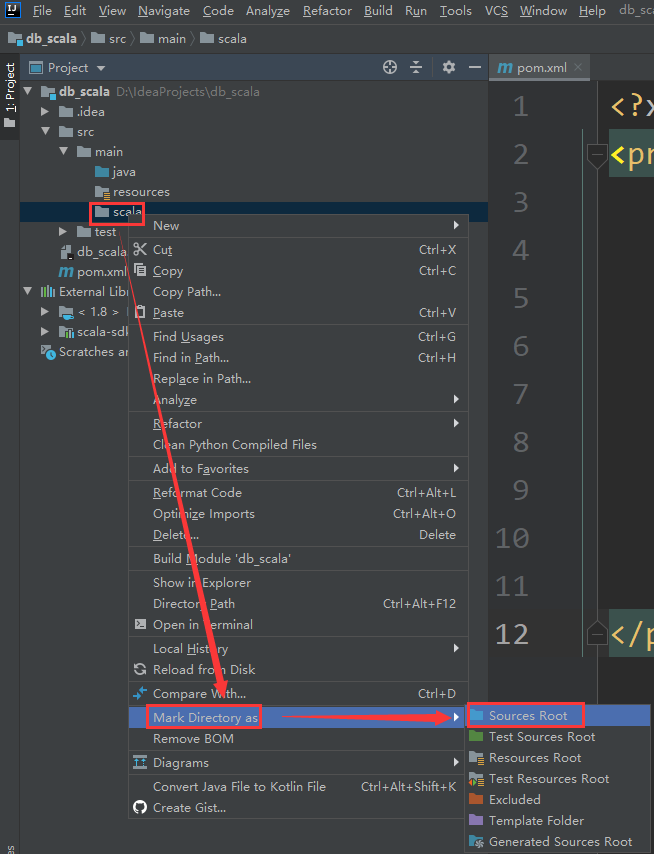
这样操作之后,就发现scala的目录颜色就正常了
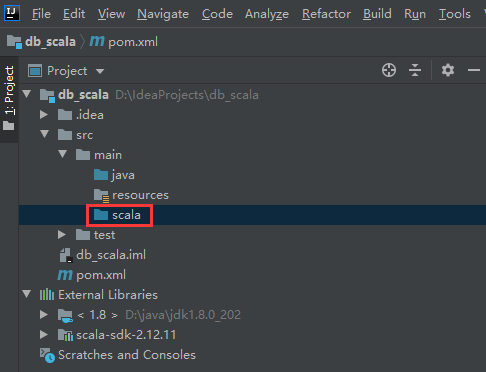
下面就可以正式开始写代码了,scala相关的代码就放到scala目录中
现在scala目录下创建包: com.imooc.demo
然后创建一个scala的object
先选中Scala Class
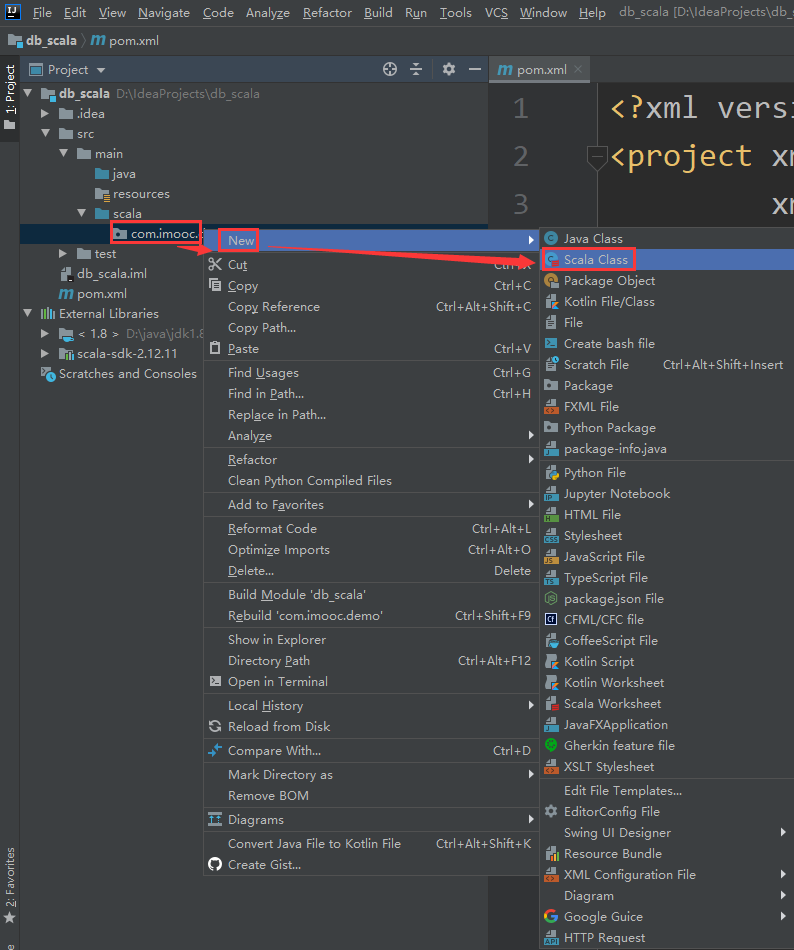
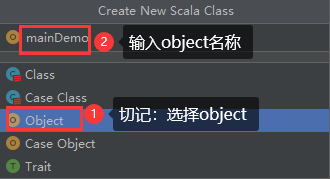
Scala 开发HelloWorld程序
package com.imooc.demo
/**
* Created by xuwei
*/
object mainDemo {
def main(args: Array[String]): Unit = {
println("hello scala!")}
}
执行代码,右键run即可
这就是Scala中main方法的用法,注意:main方法只能定义在object中,不能定义在class中
接口-trait
scala中的接口,这个接口也是比较特殊的
Scala中的接口称为trait,trait类似于Java中的interface
在triat中可以定义抽象方法
类可以使用 extends 关键字继承trait,无论继承类还是trait统一都是使用 extends 这个关键字。
类继承trait后,必须实现trait中的抽象方法,实现时不需要使用 override 关键字。
scala不支持对类进行多继承,但是支持对trait进行多重继承,使用 with 关键字即可
下面我们就来看一个接口多继承的案例
object PersonDemo {
def main(args: Array[String]): Unit = {
val p1 = new Person("tom")
val p2 = new Person("jack")
p1.sayHello(p2.name)
p1.makeFriends(p2)
}
}
trait HelloTrait { def sayHello(name: String)}
trait MakeFriendsTrait { def makeFriends(p: Person)}
class Person(val name: String) extends HelloTrait with MakeFriendsTrait {
def sayHello(name: String) = println("Hello, " + name)
def makeFriends(p: Person) = println("Hello, my name is " + name + ", your
}
Scala函数式编程
什么是函数式编程
Scala是一门既面向对象,又面向过程的语言。因此在Scala中有非常好的面向对象的特性,可以使用Scala来基于面向对象的思想开发大型复杂的系统和工程;而且Scala也面向过程,因此Scala中有函数的概念。在Scala中,函数与类、对象一样,都是一等公民,所以说scala的面向过程其实就重在针对函数的编程了,所以称之为函数式编程
函数赋值给变量
Scala中的函数是一等公民,可以独立定义,独立存在,而且可以直接将函数作为值赋值给变量。
Scala的语法规定,将函数赋值给变量时,必须在函数后面加上空格和下划线。
来看一个案例:将函数赋值给变量
scala> def sayHello(name: String) { println("Hello, " + name) }
sayHello: (name: String)Unit
scala> val sayHelloFunc = sayHello _
sayHelloFunc: String => Unit = <function1>
scala> sayHelloFunc("scala")
Hello, scala
匿名函数
Scala中的函数也可以不需要命名,这种函数称为匿名函数
匿名函数的语法格式:(参数名: 参数类型) => 函数体
(参数名: 参数类型) :是函数的参数列表
可以将匿名函数直接赋值给某个变量
看一个例子
scala> val sayHelloFunc = (name: String) => println("Hello, " + name)
sayHelloFunc: String => Unit = <function1>
scala> val sayHelloFunc = (name: String) => {println("Hello, " + name)}
sayHelloFunc: String => Unit = <function1>
注意:如果函数体有多行代码,则需要添加{}
高阶函数
由于函数是一等公民,所以说我们可以直接将某个函数作为参数传入其它函数。
这个功能是极其强大的,也是Java这种面向对象的编程语言所不具备的
这个功能在实际工作中是经常需要用到的。
接收其它函数作为当前函数的参数,当前这个函数也被称作高阶函数 (higher-order function)
看一个例子:
先定义一个匿名函数,赋值给变量sayHelloFunc
val sayHelloFunc = (name: String) => println("Hello, " + name)
再定义一个高阶函数,这个高阶函数的参数会接收一个函数
参数: (String) => Unit 表示这个函数接收一个字符串,没有返回值
def greeting(func: (String) => Unit, name: String) { func(name) }
使用:
scala> greeting(sayHelloFunc, "scala")
Hello, scala
或者还可以这样用,直接把匿名函数的定义传过来也是可以
scala> greeting((name: String) => println("Hello, " + name),"scala")
Hello, scala
高阶函数可以自动推断出它里面函数的参数类型,对于只有一个参数的函数,还可以省去小括号
# 先定义一个高阶函数
def greeting(func: (String) => Unit, name: String) { func(name) }
# 使用高阶函数:完整写法
greeting((name: String) => println("Hello, " + name), "scala")
# 使用高阶函数:高阶函数可以自动推断出参数类型,而不需要写明类型
greeting((name) => println("Hello, " + name), "scala")
# 使用高阶函数:对于只有一个参数的函数,还可以省去其小括号
greeting(name => println("Hello, " + name), "scala")
常用高阶函数
刚才是我们自己实现的高阶函数,其实我们在工作中自己定义高阶函数的场景不多,大部分场景都是去使用已有的高阶函数。下面我们来看几个常见的高阶函数
- map:对传入的每个元素都进行处理,返回一个元素
- flatMap:对传入的每个元素都进行处理,返回一个或者多个元素
- foreach:对传入的每个元素都进行处理,但是没有返回值
- filter:对传入的每个元素都进行条件判断,如果返回true,则保留该元素,否则过滤掉该元素
- reduceLeft:从左侧元素开始,进行reduce操作
map
map的使用:
scala> Array(1, 2, 3, 4, 5).map(num=>{num * 2})
res38: Array[Int] = Array(2, 4, 6, 8, 10)
可以简写为:
scala> Array(1, 2, 3, 4, 5).map(_ * 2)
res40: Array[Int] = Array(2, 4, 6, 8, 10)
flatMap
flagMap的使用
scala> Array("hello you","hello me").flatMap(line=>line.split(" "))
res53: Array[String] = Array(hello, you, hello, me)
可以简写为:
scala> Array("hello you","hello me").flatMap(_.split(" "))
res54: Array[String] = Array(hello, you, hello, me)
foreach
foreach的使用
scala> Array(1, 2, 3, 4, 5).map(_ * 2).foreach(num=>println(num))
2
4
6
8
10
可以简写为:
scala> Array(1, 2, 3, 4, 5).map(_ * 2).foreach(println(_))
2
4
6
8
10
filter
filter的使用
scala> Array(1, 2, 3, 4, 5).filter(num=>num % 2 == 0)
res46: Array[Int] = Array(2, 4)
可以简写为:
scala> Array(1, 2, 3, 4, 5).filter(_ % 2 == 0)
res47: Array[Int] = Array(2, 4)
reduceLeft
reduceLeft的使用
表示先对元素1和元素2进行处理,然后将结果与元素3处理,再将结果与元素4处理,依次类推
spark中有一个reduce函数,和这个函数的效果一致
scala> Array(1, 2, 3, 4, 5).reduceLeft((t1,t2)=>t1+t2)
res50: Int = 15
这个操作操作就相当于 1 + 2 + 3 + 4 + 5
可以简写为:
scala> Array(1, 2, 3, 4, 5).reduceLeft( _ + _)
res49: Int = 15
案例:函数式编程
统计多个文本内的单词总数
使用scala的io包读取文本文件内的数据
val lines01 = scala.io.Source.fromFile("D://a.txt").mkString
val lines02 = scala.io.Source.fromFile("D://b.txt").mkString
注意:下面这一行是核心代码,使用了链式调用的函数式编程
lines.flatMap(_.split( " ")).map((_, 1)).map(_._2).reduceLeft(_ + _)
lines.flatMap(.split( " ")) :表示对每一行数据使用空格进行切割,返回每一个单词
.map((, 1)) :针对每一个单词,都转成tuple类型,tuple中的第1个元素是这个单词,第2个元素表示单词出现的次数1
.map(_.2) :迭代每一个tuple,获取tuple中的第2个元素
.reduceLeft( + _) :对前面获取到的元素进行累加求和
Scala高级特性
模式匹配
模式匹配是Scala中非常有特色,非常强大的一种功能。
模式匹配,其实类似于Java中的 switch case 语法,即对一个值进行条件判断,然后针对不同的条件,进行不同的处理
不过Scala没有Java中的 switch case 语法,但是,Scala提供了更加强大的 match case 语法,就是这个模式匹配
Java的 switch case 仅能匹配变量的值,而Scala的 match case 可以匹配各种情况,比如:变量的类型、集合的元素,有值没值
对变量的值进行模式匹配
match case语法格式:变量 match { case 值 => 代码 }
如果值为下划线,则代表了不满足以上所有情况下的默认处理
def demo1(day: Int) {
day match {
case 1 => println("Monday")
case 2 => println("Tuesday")
case 3 => println("Wednesday")
case _ => println("none")
}
}
执行
scala> demo1(1)
Monday
scala> demo1(4)
none
注意:match case中,只要一个case分支满足并处理了,就不会继续判断下一个case分支了,这一点与Java不同,java的switch case需要用break停止向下执行
变量类型的模式匹配
Scala的模式匹配一个强大之处就在于,可以直接匹配类型,而不是值!!!这点是java的switch case绝对做不到的
语法格式:变量 match { case 变量: 类型 => 代码 }
典型的一个应用场景就是针对异常的处理
import java.io._
def processException(e: Exception) {
e match {
case e1: IllegalArgumentException => println("IllegalArgumentException "
case e2: FileNotFoundException => println("FileNotFoundException " + e2)
case e3: IOException => println("IOException " + e3)
case _: Exception => println("Exception " )
}
}
执行
scala> processException(new Exception())
Exception
在try-catch异常中的应用
try {
val lines02 = scala.io.Source.fromFile("D://test02.txt").mkString
} catch {
case ex: FileNotFoundException => println("no file")
case ex: IOException => println("io exception")
case ex: Exception => println("exception")
}
case class与模式匹配
Scala中提供了一种特殊的类,用 case class 进行声明,中文可以称为样例类
case class 其实有点类似于Java中的JavaBean的概念。即只定义field,会由Scala在编译时自动提供get和set方法,但是没有其它的method
case class 的主构造函数接收的参数通常不需要使用var或val修饰,Scala自动就会使用val修饰(但是如果你自己使用var修饰,那么还是会按照var来,在这用哪个区别都不大)
Scala自动为 case class 定义了伴生对象,也就是object,并且定义了apply()方法,该方法接收主构造函数中相同的参数,并返回 case class 对象
下面来看一个案例:,先定义三个class
class Person
case class Teacher(name: String, sub: String) extends Person
case class Student(name: String, cla: String) extends Person
再创建一个函数
def check(p: Person) {
p match {
case Teacher(name, sub) => println("Teacher, name is " + name + ", sub is
case Student(name, cla) => println("Student, name is " + name + ", cla is
case _ => println("none")
}
}
执行
scala> check(new Student("tom","class1"))
Student, name is tom, cla is class1
scala> check(new Person())
none
Option与模式匹配
Scala有一种特殊的数据类型,叫做Option。
Option有两种值,一种是Some,表示有值,一种是None,表示没有值
Option通常会用于模式匹配中,用于判断某个变量是有值还是没有值,这比null来的更加简洁明了
看这个案例
val ages = Map("jack" -> 18, "tom" -> 30, "jessic" -> 27)
def getAge(name: String) {
val age = ages.get(name)
age match {
case Some(age) => println("your age is " + age)
case None => println("none")
}
}
执行
scala> getAge("jack")
your age is 18
scala> getAge("hehe")
none
隐式转换
Scala的隐式转换,允许手动指定将某种类型的对象转换成其它类型的对象。
Scala的隐式转换,最核心的就是定义隐式转换函数,即implicit conversion function 。
隐式转换函数与普通函数唯一的语法区别是要以implicit开头而且最好要定义函数返回类型。
隐式转换非常强大的一个功能,就是可以在不知不觉中加强现有类型的功能。也就是说,我们可以为某个普通类定义一个加强类,并定义对应的隐式转换函数,这样我们在使用加强类里面的方法的时候,Scala会自动进行隐式转换,把普通类转换为加强类,然后再调用加强类中的方法
Scala默认会自动使用两种隐式转换
1:源类型,或者目标类型的伴生对象里面的隐式转换函数
2:当前程序作用域内可以用唯一标识符表示的隐式转换函数
def check(p: Person) {p match {case Teacher(name, sub) => println("Teacher, name is " + name + ", sub iscase Student(name, cla) => println("Student, name is " + name + ", cla iscase _ => println("none")
}scala> check(new Student("tom","class1"))
Student, name is tom, cla is class1
scala> check(new Person())val ages = Map("jack" -> 18, "tom" -> 30, "jessic" -> 27)
def getAge(name: String) {val age = ages.get(name)age match {case Some(age) => println("your age is " + age)case None => println("none")}
}scala> getAge("jack")
your age is 18
scala> getAge("hehe")
none
如果隐式转换函数不在上述两种情况下的话,那么就必须手动使用import引入对应的隐式转换函数。
通常建议,仅仅在需要进行隐式转换的地方,比如某个函数内,用import导入隐式转换函数,这样可以缩小隐式转换函数的作用域,避免不需要的隐式转换。
案例:狗也能抓老鼠
通过隐式转换实现,狗也具备猫抓老鼠的功能
class cat(val name: String){def catchMouse(){println(name+" catch mouse")}
}
class dog(val name: String)implicit def object2Cat (obj: Object): cat = {if (obj.getClass == classOf[dog]) {val dog = obj.asInstanceOf[dog]new cat(dog.name)}else Nil
}
执行
scala> val d = new dog("d1")
d: dog = dog@7f0e0db3
scala> d.catchMouse()
d1 catch mouse
大部分的场景是我们只需要使用import。导入对应的隐式转换函数就可以了,在这个案例中我们是自己手工实现了一个隐私转换函数,因为他们都在一个作用域内,所以就不需要import了。






![[LeetCode]-225. 用队列实现栈](https://img-blog.csdnimg.cn/de34221d0eb844148091245e07e4b19b.png)