在YOLOv6 初版出来不久,YOLOv7就立马横空出世了。与YOLOv5、YOLOv6不同,YOLOv7是由YOLOv4团队的原班人马提出的(官方出品)。从论文的表上来看,目前YOLOv7无论是在实时性还是准确率上都已经超过了当时已知的所有目标检测算法。并且它在COCO数据集上达到了56.8%的AP。
文章目录
- 1、YOLOv7介绍
- 1.1、创新点
- 1.2、详细设计
- 1.2.1、聚合网络设计
- 1.2.2、卷积重参化
- 1.2.3、基于concatenate的模型缩放
- 1.2.4、标签分配
- 1.2.5、训练时的其它策略
- 1.3、实验结果
- 2、测试
- 2.1、官方脚本测试
- 2.2、opencv dnn测试
- 2.3、测试统计
- 3、Opencv dnn 批量推理
1、YOLOv7介绍
1.1、创新点
模型结构重参化和动态标签分配已经成为了目标检测领域中的主要优化方向。针对于结构重参化,作者
通过分析梯度的传播路径来为网络中的不同层进行结构重参化优化,并且提出了不同规划的模型结构重参化。在动态标签分配上,因为模型有多个输出层,所以在训练时就难以为不同的分支分配更好地动态目标。所以作者提出了一个新的动态标签分配办法:coarse-to-fine,即由粗到细引导标签分配的策略。
还提出了扩展和复合缩放的方式,通过这种方式可以更高效利用参数量和计算量。这样不仅可以减少大量参数,还可以提高推理速度以及检测精度。
并且设计了几个可以训练的bag-of-freebies。这样使得模型在不更改本身结构时,大大提高检测精度。
1.2、详细设计
1.2.1、聚合网络设计
为了增强网络的实时性检测,YOLOv7里使使用VoVNet的变体CSPVOVNet。不仅考虑模型的参数量、计算量、内存访问次数、输入输出的通道比、element-wise操作等方面分析参数的数量、计算量和计算密度,还分析了梯度的在模型中流动路径,通过这个来使得不同层的权重能够学习到更加多样化的特征。
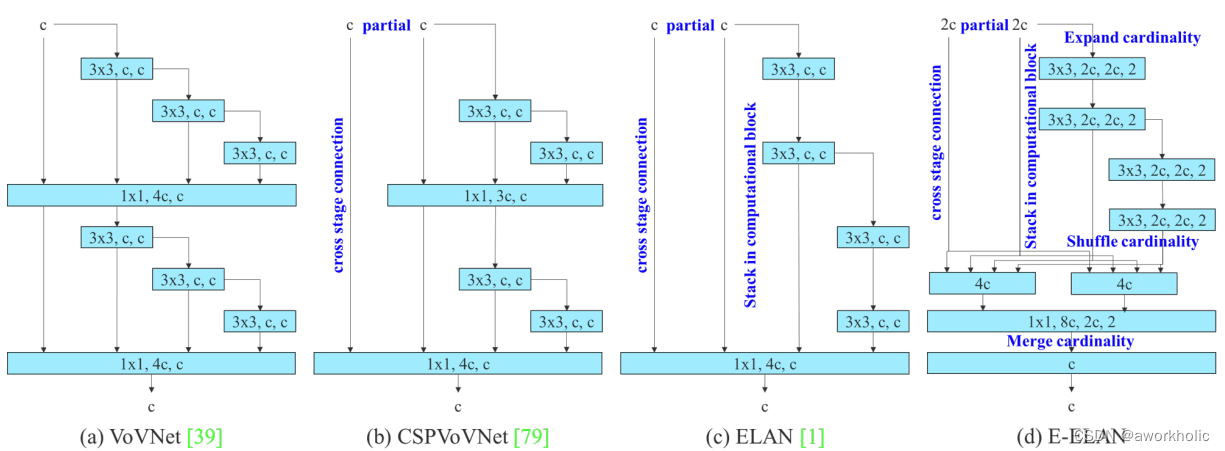
还提出了基于ELAN的Extended-ELAN,也就是E-ELAN方法。通过高效长程注意力网络来控制梯度的最短最长路径,让更深的网络可以更加高效地学习和收敛。作者提出的E-ELAN使用expand、shuffle、merge cardinality来实现在不破坏原有梯度路径的情况下,提升网络的学习能力。无论梯度路径长度和大规模ELAN中计算块的堆叠数量如何,网络都能够达到稳定状态,但是倘若继续这样一直地堆叠这一些计算块下去,反而可能会破坏这种稳定的状态,从而导致降低参数的利用率。
在结构方面,E-ELAN只改变块本身的架构,对于过渡层的架构则没有改变,这边的调整策略是使用组卷积来扩展计算块的通道和基数,将对计算层的所有计算块应用相同的组参数和通道数,然后,对于每个计算块输出的特征图会根据设置的组参数g被随即打乱成g个组,之后再将它们连接在一起。注意到这个时候,每组特征图的通道数和原来架构中的通道数是一样的,最后,添加g组的特征图来执行合并基数。E-ELAN除了保持原有的ELAN设计架构外,还可以帮助其它组的计算块学习到更加多样化的特征。
1.2.2、卷积重参化
重参化技术是模型在推理时将多个模块合并成一个模块的方法,其实就是一种集成技术。常见的重参化技术有:
- 一种是用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重进行平均。
- 一种是对不同迭代次数下模型权重进行加权平均。
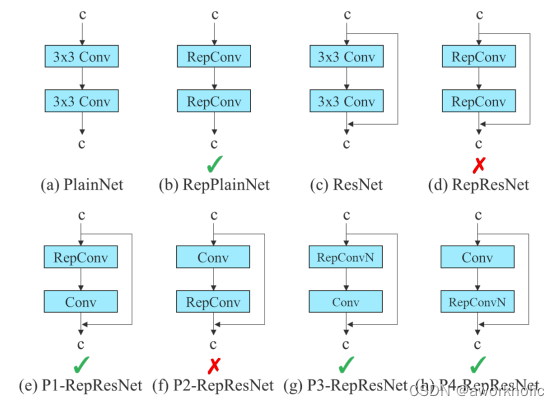
然RepConv在VGG上取得了很不错的效果,但将它直接应用于ResNet和DenseNet或其他骨干网络时,它的精度却下降得很厉害。作者就是用梯度传播路径的方法来分析,因为RepConv结合了3×3卷积,1×1卷积,和在一个卷积层中的identity连接,可是这个identity破坏力ResNet的残差连接以及DenseNet的跨层连接,为不同的特征图提供了更多的梯度多样性。
因此,作者认为,在同时使用重参化卷积和残差连接或者跨层连接时,不应该存在identity连接,而且作者还分析重参数化的卷积应该如何与不同的网络结构相结合以及设计了不同的重参数化的卷积。
1.2.3、基于concatenate的模型缩放
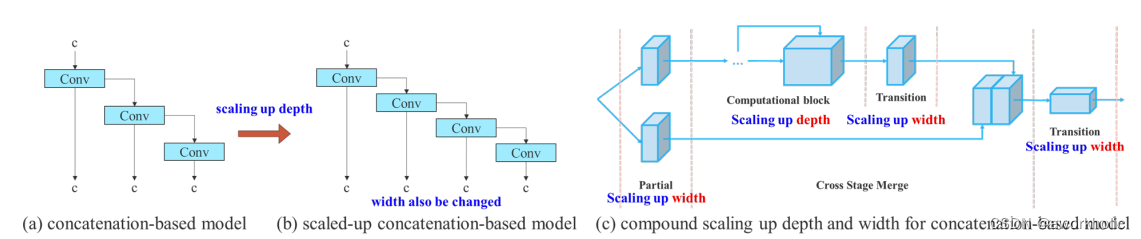
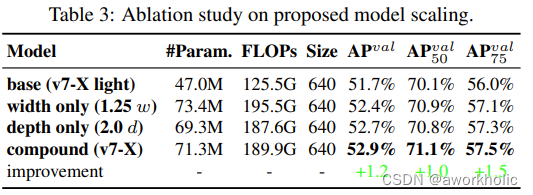
模型缩放是调整模型的大小来生成不同尺度的模型,用于满足不同场景下的推理需求。如今的网络中,主要的缩放因子有input size、depth、width、stage,通过控制这些参数,模型的参数量、计算量、推理速度和精度都有一个很好的平衡。同时,网络架构搜索NAS技术也经常使用到。
作者还发现使用concatenate模型时,不能单独地分析缩放因子的影响,还必须结合通道数的变化一起分析,因为在这过程中会导致输入通道和输出通道的比例会发生变化,从而导致模型的硬件使用率降低。还提出了一种复合缩放方法,这样不仅可以保持模型在初始设计时的特性还可以保持性能最佳时的结构。
1.2.4、标签分配
但近年来,需要研究者会利用网络的推理结果来结合GT,去生成一些软标签,如IOU。在YOLOv7中,有辅助头也有引导头,在训练时,它们二者都需要得到监督。因此,需要考虑如何为辅助头和引导头进行标签分配。因此在这里,作者提出了一种新的标签分配方法,是以引导头为主,通过引导头的推理来指引辅助头和自身的学习。
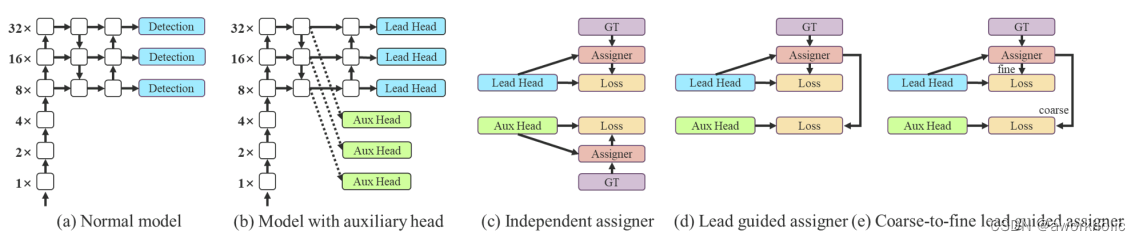
使用引导头的推理结果作为指导,生成从粗到细的层次标签,分别用于辅助头和引导头的学习。为了使那些超粗的正网格影响更小,会在解码器中设置限制,来使超粗的正网格无法完美地产生软标签。通过以上的机制,允许在学习过程中动态调整细标签和粗标签的重要性,使细标签的始终优于粗标签。

1.2.5、训练时的其它策略
-
Batch Normalization:
即将Batch Normalization层直接连接到卷积层中。这样可以在推理时将Batch Normalization的均值和方差直接融合到卷积层的偏差和权重中。 -
YOLOR中结合隐性知识和卷积特征图的加法和乘法方法
在YOLOR中,它认为隐式知识可以在推理时通过预计算步骤被简化为向量。然后再把这个向量和前一个或后一个卷积层的偏差和权重融合在一起。 -
EMA:
EMA是一种在mean teacher中使用的技术,在系统中使用EMA模型纯粹作为最终的推理模型。EMA可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关,这里可以取得平滑的作用。如果取n步的平均,就能使得模型更加得鲁棒。
1.3、实验结果
作者为边缘GPU、普通GPU、高性能云GPU三种不同场景设计了三种模型,分别是YOLOv7-Tiny、YOLOv7和YOLOv7-W6。并且通过论文中的复合缩放方法,对整个模型的深度、宽度进行缩放,得到了YOLOv7-X、YOLOv7-E6和YOLOv7-D6。以及在YOLOv7-E6基础上使用了E-ELAN技术来获得YOLOv7-E6E。
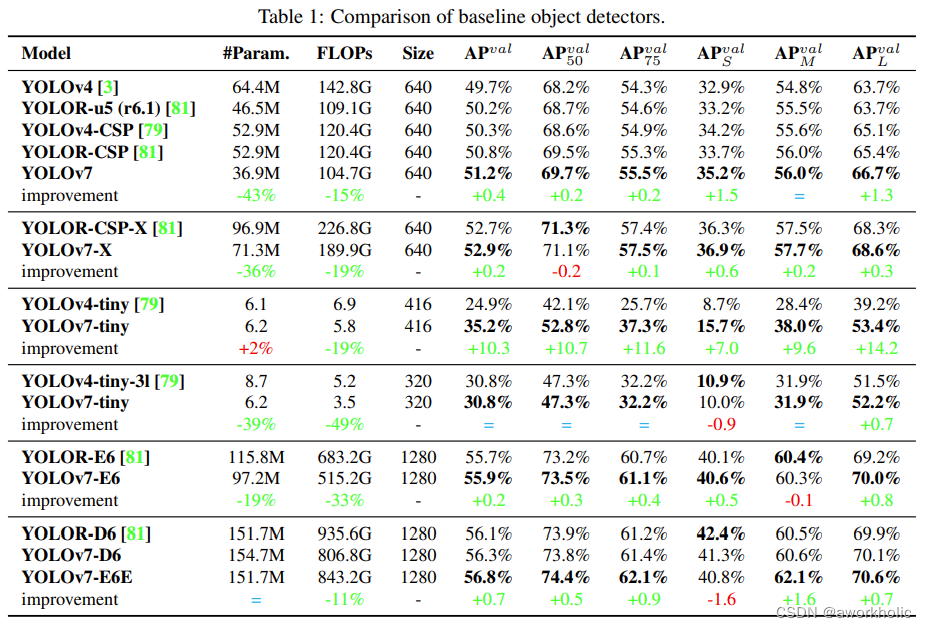
可以看到以下和其他目标检测器的速度、精度对比结果。
2、测试
以模型 YOLOv7.pt 为例进行测试 下载链接
2.1、官方脚本测试
使用默认脚本参数,设置--device 0使用GPU加速对目录中的所有图片进行推理。代码中当使用GPU加速时,提前进行了warmup。
(yolo_pytorch) E:\DeepLearning\yolov7>python detect.py --weights yolov7.pt --source inference/images --device 0
Namespace(weights=['yolov7.pt'], source='inference/images', img_size=640, conf_thres=0.25, iou_thres=0.45, device='0', view_img=False, save_txt=False, save_conf=False, nosave=False, classes=None, agnostic_nms=False, augment=False, update=False, project='runs/detect', name='exp', exist_ok=False, no_trace=False)
YOLOR v0.1-122-g3b41c2c torch 1.13.1+cu117 CUDA:0 (NVIDIA GeForce GTX 1080 Ti, 11263.75MB)Fusing layers...
RepConv.fuse_repvgg_block
RepConv.fuse_repvgg_block
RepConv.fuse_repvgg_block
Model Summary: 306 layers, 36905341 parameters, 6652669 gradientsConvert model to Traced-model...traced_script_module saved!model is traced!D:\Python\anaconda3\envs\yolo_pytorch\lib\site-packages\torch\functional.py:504: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\TensorShape.cpp:3191.)return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
4 persons, 1 bus, 1 tie, Done. (28.0ms) Inference, (4.0ms) NMSThe image with the result is saved in: runs\detect\exp19\bus.jpg
1 bicycle, 1 car, 1 truck, 1 dog, Done. (22.0ms) Inference, (1.0ms) NMSThe image with the result is saved in: runs\detect\exp19\dog.jpg
5 horses, Done. (20.0ms) Inference, (1.0ms) NMSThe image with the result is saved in: runs\detect\exp19\horses.jpg
2 persons, 1 tie, 1 cake, Done. (21.0ms) Inference, (2.0ms) NMSThe image with the result is saved in: runs\detect\exp19\image1.jpg
2 persons, 1 sports ball, Done. (19.0ms) Inference, (1.0ms) NMSThe image with the result is saved in: runs\detect\exp19\image2.jpg
1 dog, 1 horse, Done. (18.0ms) Inference, (2.0ms) NMSThe image with the result is saved in: runs\detect\exp19\image3.jpg
3 persons, 1 tie, Done. (17.0ms) Inference, (1.0ms) NMSThe image with the result is saved in: runs\detect\exp19\zidane.jpg
Done. (0.759s)
对于图片bus.jpg 的推理耗时为28ms。切换为CPU时,耗时增大到 770ms。
2.2、opencv dnn测试
导出 onnx 模型:
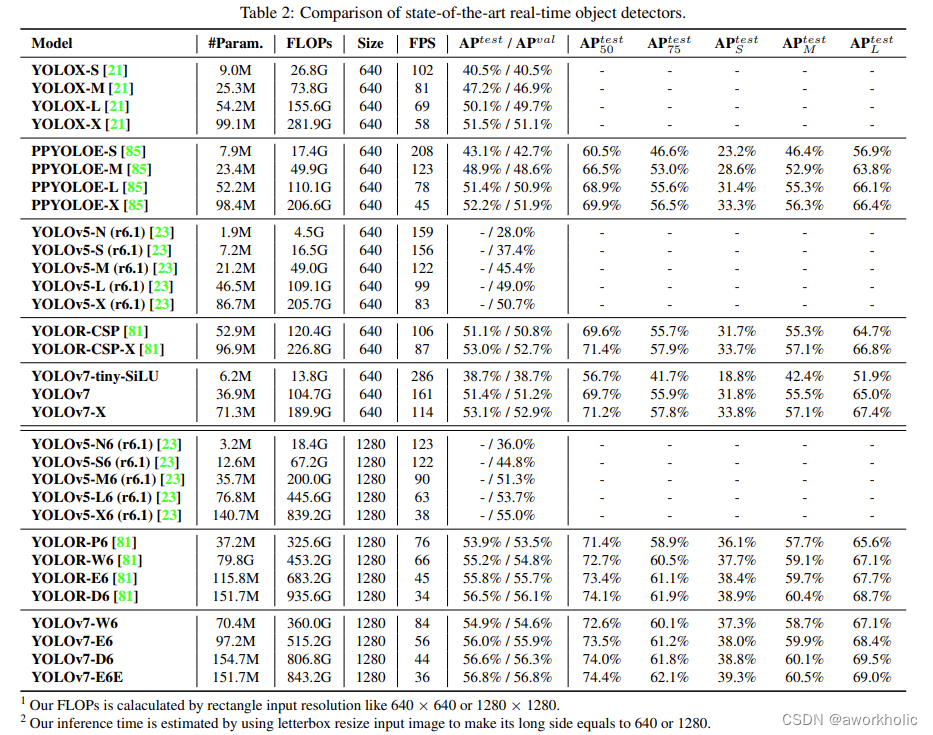
- 类似yolov4,三个尺度输出
三个尺度输出分别为 [1,3,80,80,85]、 [1,3,40,40,85]、 [1,3,20,20,85]python export.py --weights yolov7.pt --simplify --img-size 640 640 --max-wh 640 - grid导出,三个尺度输出进行合并
合并输出结果 [38080 + 34040 + 32020, 85] = [25200, 85]python export.py --weights yolov7.pt --grid --simplify --img-size 640 640 --max-wh 640 - end2end
根据指定参数,添加NMS输出的结果python export.py --weights yolov7.pt --grid --end2end --simplify --topk-all 100 --iou-thres 0.65 --conf-thres 0.35 --img-size 640 640 --max-wh 640
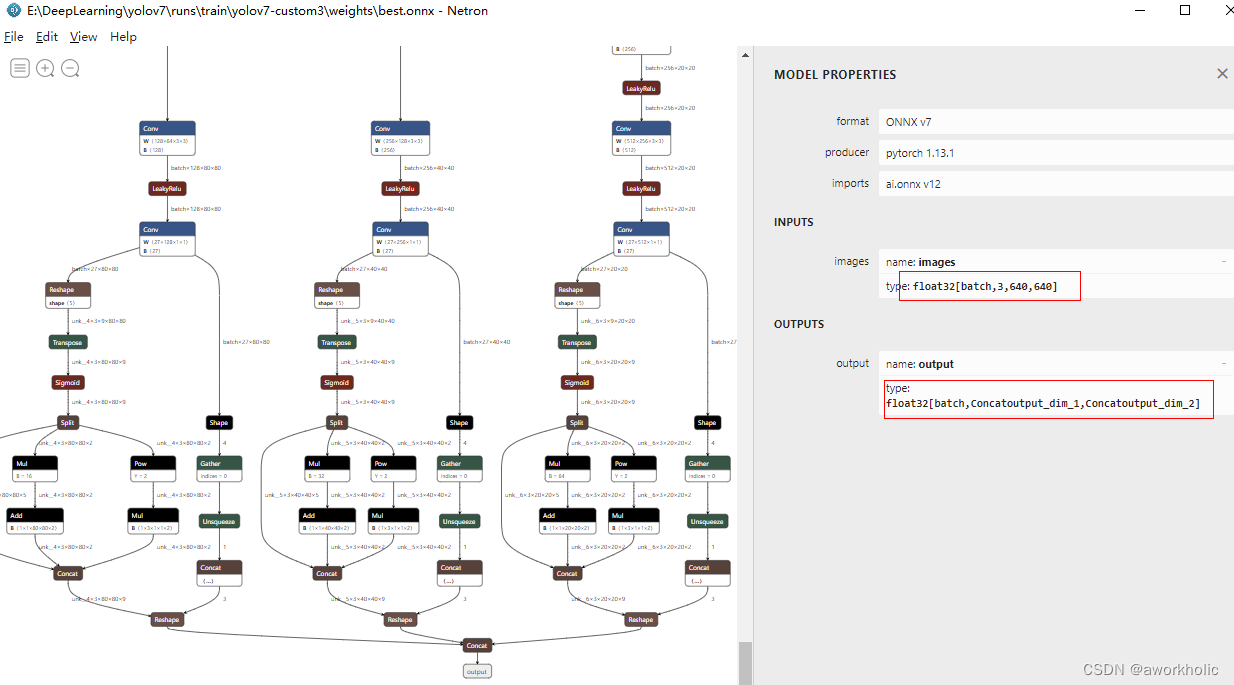
使用Netron上看上述三个脚本生成的onnx文件模型结构
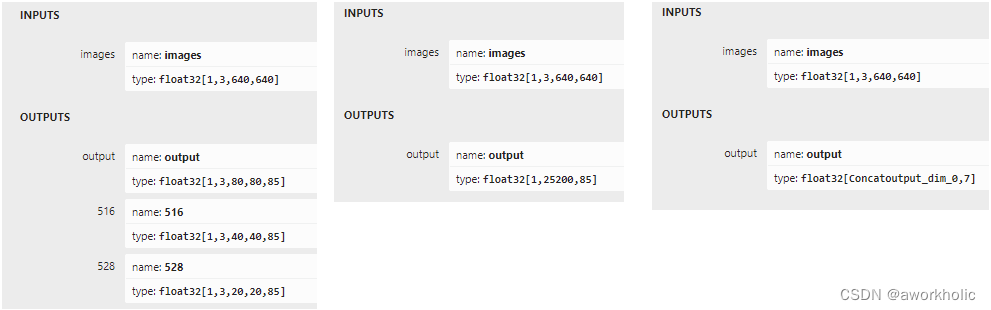
这里为了方便,使用 --grid 导出的模型,直接复用前面 yolov5、yolor、yolov6的代码,识别置信度比yolov6低一些。

另外,官方在yolov5he yolov6的基础上,提供了 anchor free 的模型文件 yolov7-u6.pt。
2.3、测试统计
python(CPU):797ms
python(GPU):28ms
opencv dnn(CPU):890ms
opencv dnn(GPU):28ms
后面测试包含 预处理+推理+后处理
openvino(CPU):409ms
onnxruntime(GPU):31ms
TensorRT:21ms
end2end模型的测试:
onnxruntime(CPU):460ms
onnxruntime(GPU):32ms
TensorRT:14ms
3、Opencv dnn 批量推理
当使用如下代码进行简单的批量推理时
auto inputImgs = std::vector<cv::Mat>{modelInput, modelInput, modelInput};
blobFromImages(inputImgs, blob, scale, cv::Size2f(inpWidth, inpHeight), mean, swapRB, false);
net.setInput(blob);
net.forward(outs, outNames);
报错如下:
[ERROR:0@4.559] global net_impl.cpp:1172 cv::dnn::dnn4_v20230620::Net::Impl::getLayerShapesRecursively input[0] = [ 3 1 3 9 80 80 ]
[ERROR:0@4.560] global net_impl.cpp:1182 cv::dnn::dnn4_v20230620::Net::Impl::getLayerShapesRecursively Exception message: OpenCV(4.8.0) D:\opencv\opencv4.8.0\sources\modules\dnn\src\layers\permute_layer.cpp:162: error: (-215:Assertion failed) (int)_numAxes == inputs[0].size() in function 'cv::dnn::PermuteLayerImpl::getMemoryShapes'
yolov7要是实现批量推理,需要增加参数 --dynamic-batch,完成命令为
python export.py --weights runs\train\yolov7-custom3\weights\best.pt --grid --simplify --img-size 640 640 --max-wh 640 --dynamic-batch
这里使用训练模型的类别数为4,因此常规一张图一推理的维度为 [1,25200, 9],按照常识,输入为[1x3,640,640]时,输出应该为[1x3,25200,9],但是实际为 [1, 25200x3, 9] = [1, 75600, 9],查看 转换都后onnx模型,