本文介绍
本篇博客为大家讲解的是通过组堆叠CNN、GRU、LSTM个数,建立多元预测和单元预测的时间序列预测模型,其效果要比单用GRU、LSTM效果好的多,其结合了CNN的特征提取功能、GRU和LSTM用于处理数据中的时间依赖关系的功能。通过将它们组合在一起,模型可以同时考虑输入数据的空间和时间特征,以更好地进行预测。本篇实战案例中包括->详细的参数讲解、数据集介绍、模型框架原理、训练你个人数据集的教程、以及结果分析。本篇文章的讲解流程为->

预测类型->多元预测、单元预测
开源代码->文末有完整代码块复制粘贴即可运行
适用人群->时间序列建模的初学者、时间序列建模的工作者
模型框架原理
首先我们来简单介绍一下本模型所用的框架原理,是为什么能够根据输入来预测出未来的值的,也就是数据的输入到数据的输出在我们的模型内部到底经过了一个什么样的处理这样一个过程的讲解。首先我们要知道三个概念,也就是本文所用到的CNN、GRU、LSTM三个主要处理结构,下面我们来简单的进行分别介绍。
CNN
CNN我相信大家都已经非常了解了这里只是简单介绍一下其在时间序列预测也就是在数据是一维(1-D)时候的作用机制。
CNN:在时间序列预测中,CNN可以用于提取时间序列数据中的局部模式或特征。通过卷积操作,CNN可以捕捉时间序列数据中的局部相关性,并通过激活函数的非线性变换,提取出高层次的特征表示。
可以看到其和2-D、3-D时候的作用是一样的主要做到的是一个特征提取的工作,唯一的区别可能就是我们的输入数据是一维的所以他会沿着时间序列顺序执行,下面我们来看一个图片来理解其工作原理。
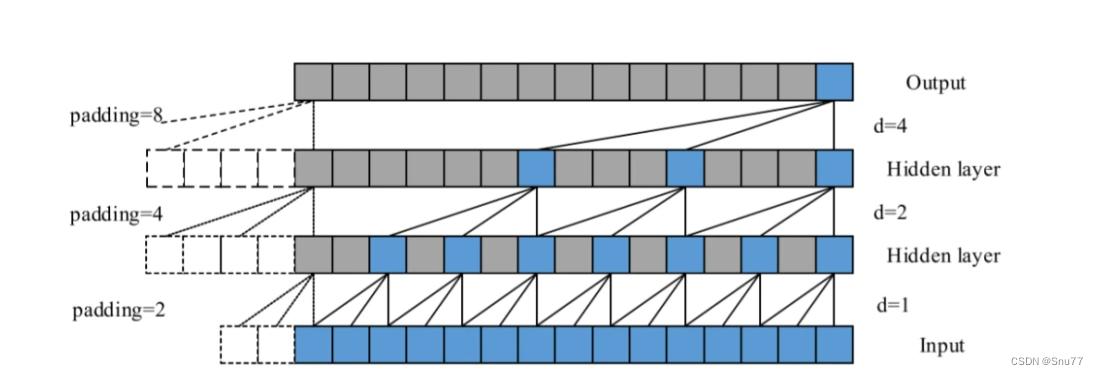
总结->这个图片代表着一个stride分别为1、2、4和卷积核=3的1维度卷积处理结果,可以看到其是顺序执行不想2-D、3-D卷积哪样需要换行的操作。
GRU
门控循环单元(GRU)是一种循环神经网络(RNN)单元,用于处理序列数据。GRU相对于传统的RNN单元具有改进的结构,旨在更好地处理长期依赖关系和消除梯度消失问题。
GRU的结构由以下几个关键单元组成:
更新门(Update Gate):更新门控制着前一时刻的隐藏状态(或记忆)保留多少信息传递到当前时刻的隐藏状态中。它通过观察当前输入和前一时刻的隐藏状态,决定更新的程度。更新门具有一个范围从0到1的值,其中0表示完全忘记先前的隐藏状态,1表示完全保留先前的隐藏状态。
重置门(Reset Gate):重置门决定如何使用前一时刻的隐藏状态来刷新当前时刻的隐藏状态。它通过控制前一时刻的隐藏状态在当前时刻的作用程度来帮助模型忘记不重要的信息。通过观察当前输入和前一时刻的隐藏状态,重置门输出一个范围从0到1的值,用于调整隐藏状态的刷新程度。
候选隐藏状态:候选隐藏状态(Candidate Hidden State)是一个候选的更新后的隐藏状态。它是根据当前输入和重置门的输出计算得到的。候选隐藏状态捕捉了当前输入和过去隐藏状态的相关性,并在一定程度上更新了隐藏状态。
新的隐藏状态(Updated Hidden State):新的隐藏状态由更新门、候选隐藏状态和前一时刻的隐藏状态组合而成。它被用作当前时刻的隐藏状态,并在下一个时刻传递下去。
总结->GRU的关键点是,它通过更新门控制了有关隐藏状态的信息流动,可以决定保留多少过去的信息。而重置门有助于捕捉当前输入和过去隐藏状态之间的相关性,并在一定程度上刷新隐藏状态。这种门控机制允许GRU更好地处理长期依赖关系,并减轻了梯度消失问题,使其能够更有效地处理序列数据。
下面的图片是一个完整的GRU的结构图片。

LSTM
LSTM在我之前的博客中以及详细的讲过,如果有需要的可以看我之前的博客,这里只做一个间的回顾和概念介绍。
时间序列预测模型实战案例(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
LSTM(长短期记忆,Long Short-Term Memory)是一种用于处理序列数据的深度学习模型,属于循环神经网络(RNN)的一种变体,其使用一种类似于搭桥术结构的RNN单元。相对于普通的RNN,LSTM引入了门控机制,能够更有效地处理长期依赖和短期记忆问题,是RNN网络中最常使用的Cell之一,其网络结构如下图。

模型执行流程
上面以及经过了三个主要结构的基本原理和结构,这里主要讲一下在模型中其它的结构如何搭配三个主要的结构(CNN、GRU、LSTM)实现回归问题的解决(时间序列预测就是一个回归问题)
- 模型的数据输入首先是经过卷积神经网络(CNN)。它从输入数据开始,进行卷积操作,并使用 ReLU 激活函数进行非线性变换。然后对卷积输出进行一个 reshape 操作,将维度重新排列。所有输出被添加到输出列表中,最后使用 `Concat` 操作将它们在维度 2 上连接起来。连接后的结果经过一个 dropout 操作,生成最终的特征输出。
- 接下来经过GRU层。首先将堆叠的所有循环单元按顺序连接在一起,并在每个循环单元之后添加一个 dropout 操作,将结果进行输出。
- 再下面是LSTM层。同样将循环单元按顺序连接在一起,并在每个循环单元之后添加 dropout 操作。这一部分与之前的GRU 类似。
- 接着是自回归(Autoregressive)组件。它对输入数据 `X` 的每个特征维度分别进行全连接操作,将维度减小到 1。
- 最后定义了预测组件的代码。通过一个全连接层将输入的维度变换为与输入特征向量的维度相同。然后将该输出与自回归组件的输出进行相加,得到最终的模型输出。使用线性回归损失函数计算模型输出与标签的损失。
- 最终,函数返回损失值,输入数据的名称列表以及标签数据的名称列表。
模型的结构图下->
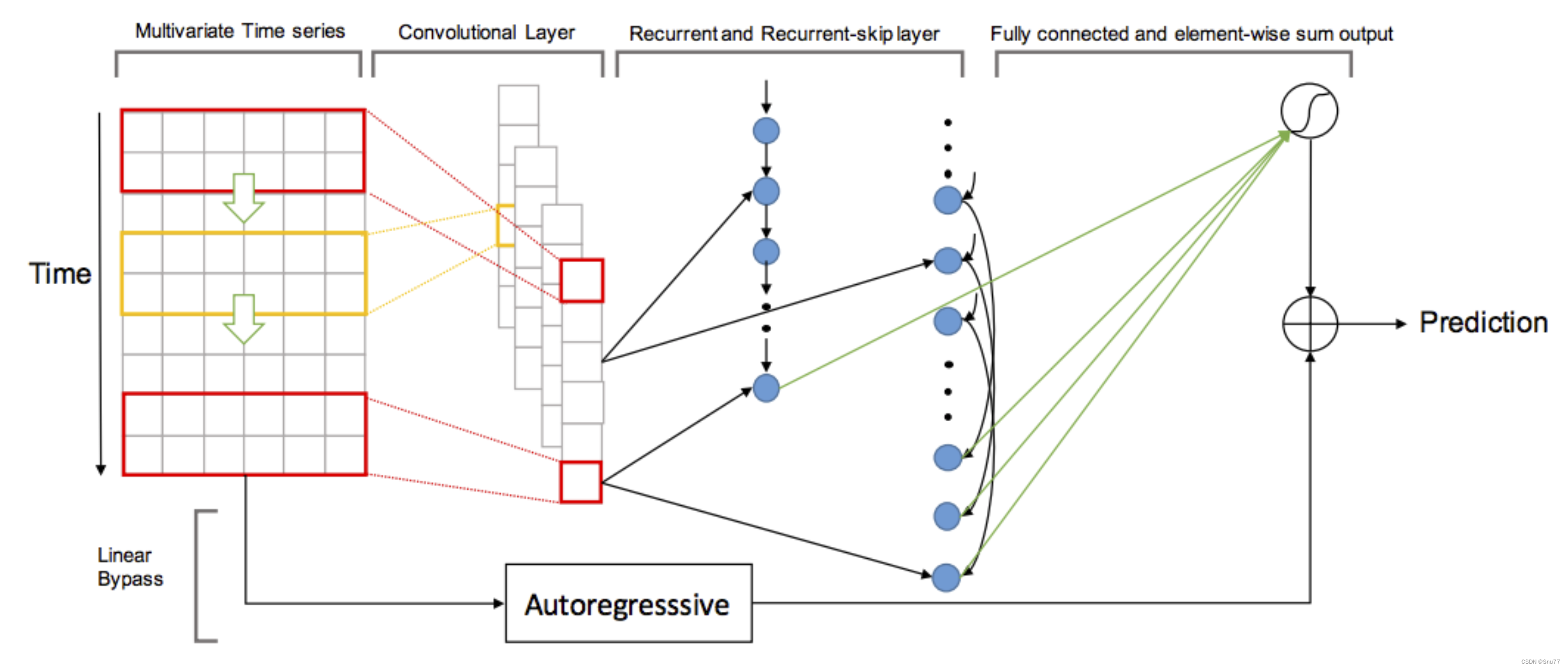
上述的过程讲述的就是模型中如下的代码流程可以参考着讲解和代码进行阅读。
def sym_gen(train_iter, q, filter_list, num_filter, dropout, rcells, skiprcells, seasonal_period, time_interval):input_feature_shape = train_iter.provide_data[0][1]X = mx.symbol.Variable(train_iter.provide_data[0].name)Y = mx.sym.Variable(train_iter.provide_label[0].name)# reshape data before applying convolutional layer (takes 4D shape incase you ever work with images)conv_input = mx.sym.reshape(data=X, shape=(0, 1, q, -1))################ CNN Component###############outputs = []for i, filter_size in enumerate(filter_list):# pad input array to ensure number output rows = number input rows after applying kernelpadi = mx.sym.pad(data=conv_input, mode="constant", constant_value=0,pad_width=(0, 0, 0, 0, filter_size - 1, 0, 0, 0))convi = mx.sym.Convolution(data=padi, kernel=(filter_size, input_feature_shape[2]), num_filter=num_filter)acti = mx.sym.Activation(data=convi, act_type='relu')trans = mx.sym.reshape(mx.sym.transpose(data=acti, axes=(0, 2, 1, 3)), shape=(0, 0, 0))outputs.append(trans)cnn_features = mx.sym.Concat(*outputs, dim=2)cnn_reg_features = mx.sym.Dropout(cnn_features, p=dropout)################ GRU Component###############stacked_rnn_cells = mx.rnn.SequentialRNNCell()for i, recurrent_cell in enumerate(rcells):stacked_rnn_cells.add(recurrent_cell)stacked_rnn_cells.add(mx.rnn.DropoutCell(dropout))outputs, states = stacked_rnn_cells.unroll(length=q, inputs=cnn_reg_features, merge_outputs=False)rnn_features = outputs[-1] #only take value from final unrolled cell for use later##################### LSTM Component####################stacked_rnn_cells = mx.rnn.SequentialRNNCell()for i, recurrent_cell in enumerate(skiprcells):stacked_rnn_cells.add(recurrent_cell)stacked_rnn_cells.add(mx.rnn.DropoutCell(dropout))outputs, states = stacked_rnn_cells.unroll(length=q, inputs=cnn_reg_features, merge_outputs=False)# Take output from cells p steps apartp = int(seasonal_period / time_interval)output_indices = list(range(0, q, p))outputs.reverse()skip_outputs = [outputs[i] for i in output_indices]skip_rnn_features = mx.sym.concat(*skip_outputs, dim=1)########################### Autoregressive Component##########################auto_list = []for i in list(range(input_feature_shape[2])):time_series = mx.sym.slice_axis(data=X, axis=2, begin=i, end=i+1)fc_ts = mx.sym.FullyConnected(data=time_series, num_hidden=1)auto_list.append(fc_ts)ar_output = mx.sym.concat(*auto_list, dim=1)####################### Prediction Component######################neural_components = mx.sym.concat(*[rnn_features, skip_rnn_features], dim=1)neural_output = mx.sym.FullyConnected(data=neural_components, num_hidden=input_feature_shape[2])model_output = neural_output + ar_outputloss_grad = mx.sym.LinearRegressionOutput(data=model_output, label=Y)return loss_grad, [v.name for v in train_iter.provide_data], [v.name for v in train_iter.provide_label]数据集介绍
上面简单的介绍了模型的原理,下面的部分就是开始正式的实战讲解了,首先介绍的是我本次实战中举例用到的数据集部分截图如下,其主要预测列为OT列代表的含义是油温。

参数讲解
下面我来介绍模型的主要参数,如果你想要使用自己的数据集进行预测,那么这个过程需要自信的看其中一些参数的讲解会涉及到如何替换个人数据集的介绍。
首先先列出所有参数后进行讲解,参数如下->
parser = argparse.ArgumentParser(description="CNN-GRU-LSTM for multivariate time series forecasting",formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--data-dir', type=str, default='./', help='relative path to input data')
parser.add_argument('--data_name',type=str, default='ETTh1-Test.csv', help='Input Model File Name')
parser.add_argument('--max-records', type=int, default=None, help='total records before data split')
parser.add_argument('--q', type=int, default=24*7, help='number of historical measurements included in each training example')
parser.add_argument('--horizon', type=int, default=4, help='number of measurements ahead to predict')
parser.add_argument('--splits', type=str, default="0.6,0.2", help='fraction of data to use for train & validation. remainder used for test.')
parser.add_argument('--batch-size', type=int, default=128, help='the batch size.')
parser.add_argument('--filter-list', type=str, default="6,12,18", help='unique filter sizes')
parser.add_argument('--num-filters', type=int, default=100, help='number of each filter size')
parser.add_argument('--recurrent-state-size', type=int, default=100, help='number of hidden units in each unrolled recurrent cell')
parser.add_argument('--seasonal-period', type=int, default=24, help='time between seasonal measurements')
parser.add_argument('--time-interval', type=int, default=1, help='time between each measurement')
parser.add_argument('--gpus', type=str, default='', help='list of gpus to run, e.g. 0 or 0,2,5. empty means using cpu. ')
parser.add_argument('--optimizer', type=str, default='adam', help='the optimizer type')
parser.add_argument('--lr', type=float, default=0.001, help='initial learning rate')
parser.add_argument('--dropout', type=float, default=0.2, help='dropout rate for network')
parser.add_argument('--num-epochs', type=int, default=100, help='max num of epochs')
parser.add_argument('--save-period', type=int, default=20, help='save checkpoint for every n epochs')
parser.add_argument('--model_prefix', type=str, default='electricity_model', help='prefix for saving model params')上面的就是本模型用到的所有参数,下面来分别进行讲解。
| 参数名称 | 参数类型 | 参数讲解 | |
|---|---|---|---|
| 1 | data-dir | str | 数据数据集的目录,注意不要到具体的文件要都文件的目录名称! |
| 2 | data-name | str | 文件的具体名称。 |
| 3 | max-records | int | 数据分割之前的总记录数,可以选择仅使用部分数据进行训练和评估,默认为None表示使用全部数据。 |
| 4 | q | int | 每个训练样本中包含的历史测量值的数量 |
| 5 | horizon | int | 预测的未来测量值的数量,默认为4,这个就是你预测未来多少个点的数据 |
| 6 | splits | str | 数据集划分的比例,用于训练、验证和测试集的分割,默认为"0.6,0.2",表示60%的数据用于训练,20%用于验证,剩余部分用于测试。 |
| 7 | batch-size | int | 一次往模型里输入多少个数据 |
| 8 | filter-list | str | 这个是CNN的卷积核大小,默认为"6,12,18",表示使用6、12和18的卷积核大小,这个可以根据你数据集的间隔来,如果你觉得你数据集的数据比较平缓可以设置大一点如果比较极端那么设置就小一点,如果你不知道也可以看我末尾推荐的文章里面有详细讲解。 |
| 9 | num-filters | int | 每个过滤器大小的滤波器数量,默认为100。 |
| 10 | recurrent-state-size | int | 每个未滚动展开循环单元中隐藏单位的数量,默认为100。 |
| 11 | seasonal-period | int | 季节性测量之间的时间间隔,默认为24,表示每24小时进行一次季节性测量。这个数据也很重要就是你数据具有的季节性。这个参数不同的数据集都不一样,如果你想知道如何测量你数据中的季节性、周期性等因素可以看我的其它博客文章的末尾会分享里面有详细的讲解。 |
| 12 | time-interval | int | 每个测量之间的时间间隔,默认为1。 |
| 13 | gpus | str | 要使用的GPU列表,例如"0"或"0,2,5",为空表示使用CPU。 |
| 14 | optimizer | str | 优化器的类型,默认为"adam"。 |
| 15 | lr | float | 初始学习率,默认为0.001。 |
| 16 | dropout | float | 网络的dropout率,默认为0.2。 |
| 17 | num-epochs | int | 最大的训练轮数,默认为100。 |
| 18 | svae-period | int | 每隔n个训练轮保存一次模型检查点,默认为20。 |
| 19 | model-prefix | str | 保存模型参数的前缀,默认为"electricity_model"。 |
模型训练
到此为止模型的准备工作以及全部做好了,经过参数的讲解和数据集的准备,可以开始训练模型了。
环境介绍
在正式开始训练之前介绍一下本模型用到的模块版本如下->
python=3.6
mxnet
numpy
pandas
tqdm
训练代码讲解
我们的程序入口代码汇总如下->
if __name__ == '__main__':# parse argsargs = parser.parse_args()args.splits = list(map(float, args.splits.split(',')))args.filter_list = list(map(int, args.filter_list.split(',')))# Check valid argsif not max(args.filter_list) <= args.q:raise AssertionError("no filter can be larger than q")if not args.q >= math.ceil(args.seasonal_period / args.time_interval):raise AssertionError("size of skip connections cannot exceed q")# Build data iteratorstrain_iter, val_iter, test_iter = build_iters(args.data_dir, args.max_records, args.q, args.horizon, args.splits, args.batch_size)# Choose cells for recurrent layers: each cell will take the output of the previous cell in the listrcells = [mx.rnn.GRUCell(num_hidden=args.recurrent_state_size)]skiprcells = [mx.rnn.LSTMCell(num_hidden=args.recurrent_state_size)]# Define network symbolsymbol, data_names, label_names = sym_gen(train_iter, args.q, args.filter_list, args.num_filters,args.dropout, rcells, skiprcells, args.seasonal_period, args.time_interval)Train = True# train cnn modelif Train:module = train(symbol, train_iter, val_iter, data_names, label_names)predict(symbol, train_iter, val_iter, test_iter, data_names, label_names)下面对其中的代码分别进行讲解!!!
args = parser.parse_args()args.splits = list(map(float, args.splits.split(',')))args.filter_list = list(map(int, args.filter_list.split(',')))# Check valid argsif not max(args.filter_list) <= args.q:raise AssertionError("no filter can be larger than q")if not args.q >= math.ceil(args.seasonal_period / args.time_interval):raise AssertionError("size of skip connections cannot exceed q")这一部分就是一些参数的解析部分了,检测参数是否有一些不符合规定的输入,不涉及到代码的流程,没什么好讲的给大家。
# Build data iteratorstrain_iter, val_iter, test_iter = build_iters(args.data_dir, args.max_records, args.q, args.horizon, args.splits, args.batch_size)这是构建训练集、验证集、测试集的数据加载器,需要注意的是时间序列是以滚动的形式构建数据加载器的。
# Choose cells for recurrent layers: each cell will take the output of the previous cell in the listrcells = [mx.rnn.GRUCell(num_hidden=args.recurrent_state_size)]skiprcells = [mx.rnn.LSTMCell(num_hidden=args.recurrent_state_size)]这里是定义GRU和LSTM的地方如果你想要修改其它的RNN单元就可以在这里修改进行其它尝试,毕竟GRU和LSTM以及存在许多年了现在有许多更高效效果更好的RNN单元存在。
# Define network symbolsymbol, data_names, label_names = sym_gen(train_iter, args.q, args.filter_list, args.num_filters,args.dropout, rcells, skiprcells, args.seasonal_period, args.time_interval)这一步就是构建网络结构了,其中sym_gen是我们定义的方法。
Train = True# train cnn modelif Train:module = train(symbol, train_iter, val_iter, data_names, label_names)predict(symbol, train_iter, val_iter, test_iter, data_names, label_names)进行训练和预测,Train=True时进行训练和预测,Train=False时候只进行预测不训练模型。
训练模型
下面我们开始正式的训练,运行程序文件,控制台进行输出如下。
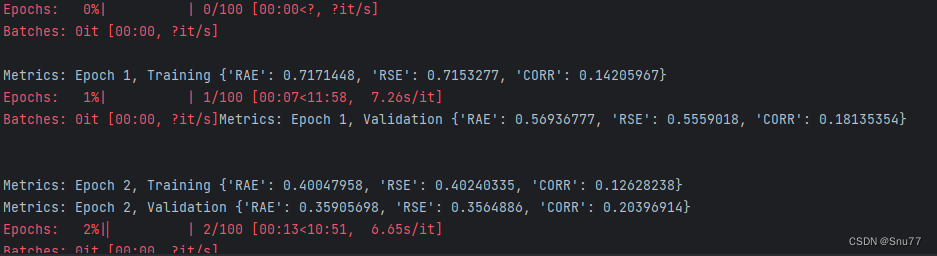
训练完成后,模型会自动保存在该目录下->

模型预测
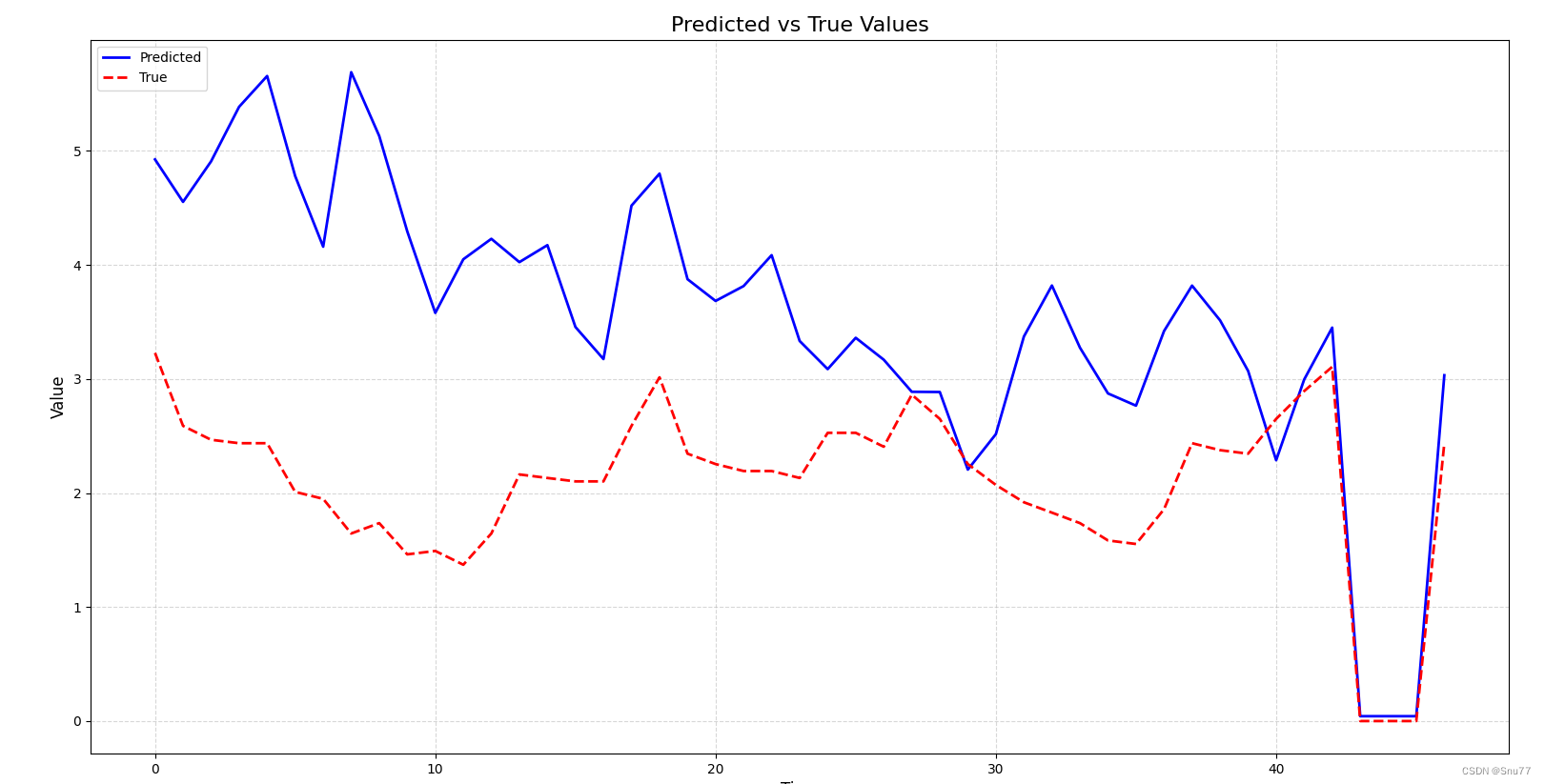
我们进行模型的预测主要观察我们想看的特征列"OT"列预测结果如下。

同时会将所有的结果和真实值输出到控制台并生成csv文件。
 保存到同级目录下的输出结果和折线图如下->
保存到同级目录下的输出结果和折线图如下->
结果分析
可以说结果还可以接受,这个模型的设计还是算成功的,当然精度还有待提升,后续的话可以更改一些结构,或者添加一些其它的网络层,这里我们再来展示一下其它几列的预测结果。
PS->需要注意的是我的训练数据只用了三百多条能达到这个精度我还是比较满意的。
LULL特征预测结果如下图->

LUFL特征预测结果如下->
训练个人数据集所需修改
下面来讲一下训练你个人数据集需要什么修改,其实主要修改的主要是参数部分,大部分的代码Bug我以及修复好了,所以下面来讲一下。
parser.add_argument('--data-dir', type=str, default='./', help='relative path to input data')
parser.add_argument('--data_name',type=str, default='ETTh1-Test.csv', help='Input Model File Name')
parser.add_argument('--q', type=int, default=24*7, help='number of histrical measurements included in each training example')
parser.add_argument('--filter-list', type=str, default="6,12,18", help='unique filter sizes')
parser.add_argument('--seasonal-period', type=int, default=24, help='time between seasonal measurements')
parser.add_argument('--time-interval', type=int, default=1, help='time between each measurement')这个是模型中需要你修改的参数部分,具体的修改和修改意见我在参数讲解部分以及提到了,大家可以回去参照这修改之后就可以运行该模型训练自己的数据集了。
项目完整代码分析
项目的完整代码如下->大家可以进行复制运行即可。
import argparse
import logging
import math
import os
import matplotlib.pyplot as plt
import mxnet as mx
import numpy as np
import pandas as pd
from tqdm import tqdm# 将matplotlib的日志级别设置为警告级别
mpl_logger = logging.getLogger('matplotlib')
mpl_logger.setLevel(logging.WARNING)
logging.basicConfig(level=logging.DEBUG)# 参数设置部分
parser = argparse.ArgumentParser(description="CNN-GRU-LSTM for multivariate time series forecasting",formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--data-dir', type=str, default='./', help='relative path to input data')
parser.add_argument('--data_name', type=str, default='ETTh1-Test.csv', help='Input Model File Name')
parser.add_argument('--max-records', type=int, default=None, help='total records before data split')
parser.add_argument('--q', type=int, default=24 * 7,help='number of histrical measurements included in each training example')
parser.add_argument('--horizon', type=int, default=4, help='number of measurements ahead to predict')
parser.add_argument('--splits', type=str, default="0.6,0.2",help='fraction of data to use for train & validation. remainder used for test.')
parser.add_argument('--batch-size', type=int, default=128, help='the batch size.')
parser.add_argument('--filter-list', type=str, default="6,12,18", help='unique filter sizes')
parser.add_argument('--num-filters', type=int, default=100, help='number of each filter size')
parser.add_argument('--recurrent-state-size', type=int, default=100,help='number of hidden units in each unrolled recurrent cell')
parser.add_argument('--seasonal-period', type=int, default=24, help='time between seasonal measurements')
parser.add_argument('--time-interval', type=int, default=1, help='time between each measurement')
parser.add_argument('--gpus', type=str, default='',help='list of gpus to run, e.g. 0 or 0,2,5. empty means using cpu. ')
parser.add_argument('--optimizer', type=str, default='adam', help='the optimizer type')
parser.add_argument('--lr', type=float, default=0.001, help='initial learning rate')
parser.add_argument('--dropout', type=float, default=0.2, help='dropout rate for network')
parser.add_argument('--num-epochs', type=int, default=100, help='max num of epochs')
parser.add_argument('--save-period', type=int, default=20, help='save checkpoint for every n epochs')
parser.add_argument('--model_prefix', type=str, default='electricity_model', help='prefix for saving model params')def rse(label, pred):"""computes the root relative squared error (condensed using standard deviation formula)"""numerator = np.sqrt(np.mean(np.square(label - pred), axis=None))denominator = np.std(label, axis=None)return numerator / denominatordef rae(label, pred):"""computes the relative absolute error (condensed using standard deviation formula)"""numerator = np.mean(np.abs(label - pred), axis=None)denominator = np.mean(np.abs(label - np.mean(label, axis=None)), axis=None)return numerator / denominatordef corr(label, pred):"""computes the empirical correlation coefficient"""numerator1 = label - np.mean(label, axis=0)numerator2 = pred - np.mean(pred, axis=0)numerator = np.mean(numerator1 * numerator2, axis=0)denominator = np.std(label, axis=0) * np.std(pred, axis=0)return np.mean(numerator / denominator)def get_custom_metrics():""":return: mxnet metric object"""_rse = mx.metric.create(rse)_rae = mx.metric.create(rae)_corr = mx.metric.create(corr)return mx.metric.create([_rae, _rse, _corr])def evaluate(pred, label):return {"RAE": rae(label, pred), "RSE": rse(label, pred), "CORR": corr(label, pred)}def build_iters(data_dir, max_records, q, horizon, splits, batch_size):"""Load & generate training examples from multivariate time series data:return: data iters & variables required to define network architecture"""# Read in data as numpy arraydf = pd.read_csv(os.path.join(data_dir, "ETTh1-Test.csv"), sep=",", )feature_df = df.iloc[:, 1:].fillna(0).astype(float)x = feature_df.valuesx = x[:max_records] if max_records else x# Construct training examples based on horizon and windowx_ts = np.zeros((x.shape[0] - q, q, x.shape[1]))y_ts = np.zeros((x.shape[0] - q, x.shape[1]))for n in range(x.shape[0]):if n + 1 < q:continueelif n + 1 + horizon > x.shape[0]:continueelse:y_n = x[n + horizon, :]x_n = x[n + 1 - q:n + 1, :]x_ts[n - q] = x_ny_ts[n - q] = y_n# Split into training and testing datatraining_examples = int(x_ts.shape[0] * splits[0])valid_examples = int(x_ts.shape[0] * splits[1])x_train, y_train = x_ts[:training_examples], \y_ts[:training_examples]x_valid, y_valid = x_ts[training_examples:training_examples + valid_examples], \y_ts[training_examples:training_examples + valid_examples]x_test, y_test = x_ts[training_examples + valid_examples:], \y_ts[training_examples + valid_examples:]# build iterators to feed batches to networktrain_iter = mx.io.NDArrayIter(data=x_train,label=y_train,batch_size=batch_size)val_iter = mx.io.NDArrayIter(data=x_valid,label=y_valid,batch_size=batch_size)test_iter = mx.io.NDArrayIter(data=x_test,label=y_test,batch_size=batch_size)return train_iter, val_iter, test_iterdef sym_gen(train_iter, q, filter_list, num_filter, dropout, rcells, skiprcells, seasonal_period, time_interval):input_feature_shape = train_iter.provide_data[0][1]X = mx.symbol.Variable(train_iter.provide_data[0].name)Y = mx.sym.Variable(train_iter.provide_label[0].name)# reshape data before applying convolutional layer (takes 4D shape incase you ever work with images)conv_input = mx.sym.reshape(data=X, shape=(0, 1, q, -1))################ CNN Component###############outputs = []for i, filter_size in enumerate(filter_list):# pad input array to ensure number output rows = number input rows after applying kernelpadi = mx.sym.pad(data=conv_input, mode="constant", constant_value=0,pad_width=(0, 0, 0, 0, filter_size - 1, 0, 0, 0))convi = mx.sym.Convolution(data=padi, kernel=(filter_size, input_feature_shape[2]), num_filter=num_filter)acti = mx.sym.Activation(data=convi, act_type='relu')trans = mx.sym.reshape(mx.sym.transpose(data=acti, axes=(0, 2, 1, 3)), shape=(0, 0, 0))outputs.append(trans)cnn_features = mx.sym.Concat(*outputs, dim=2)cnn_reg_features = mx.sym.Dropout(cnn_features, p=dropout)################ GRU Component###############stacked_rnn_cells = mx.rnn.SequentialRNNCell()for i, recurrent_cell in enumerate(rcells):stacked_rnn_cells.add(recurrent_cell)stacked_rnn_cells.add(mx.rnn.DropoutCell(dropout))outputs, states = stacked_rnn_cells.unroll(length=q, inputs=cnn_reg_features, merge_outputs=False)rnn_features = outputs[-1] # only take value from final unrolled cell for use later##################### LSTM Component####################stacked_rnn_cells = mx.rnn.SequentialRNNCell()for i, recurrent_cell in enumerate(skiprcells):stacked_rnn_cells.add(recurrent_cell)stacked_rnn_cells.add(mx.rnn.DropoutCell(dropout))outputs, states = stacked_rnn_cells.unroll(length=q, inputs=cnn_reg_features, merge_outputs=False)# Take output from cells p steps apartp = int(seasonal_period / time_interval)output_indices = list(range(0, q, p))outputs.reverse()skip_outputs = [outputs[i] for i in output_indices]skip_rnn_features = mx.sym.concat(*skip_outputs, dim=1)########################### Autoregressive Component##########################auto_list = []for i in list(range(input_feature_shape[2])):time_series = mx.sym.slice_axis(data=X, axis=2, begin=i, end=i + 1)fc_ts = mx.sym.FullyConnected(data=time_series, num_hidden=1)auto_list.append(fc_ts)ar_output = mx.sym.concat(*auto_list, dim=1)####################### Prediction Component######################neural_components = mx.sym.concat(*[rnn_features, skip_rnn_features], dim=1)neural_output = mx.sym.FullyConnected(data=neural_components, num_hidden=input_feature_shape[2])model_output = neural_output + ar_outputloss_grad = mx.sym.LinearRegressionOutput(data=model_output, label=Y)return loss_grad, [v.name for v in train_iter.provide_data], [v.name for v in train_iter.provide_label]def train(symbol, train_iter, val_iter, data_names, label_names):devs = mx.cpu() if args.gpus is None or args.gpus is '' else [mx.gpu(int(i)) for i in args.gpus.split(',')]module = mx.mod.Module(symbol, data_names=data_names, label_names=label_names, context=devs)module.bind(data_shapes=train_iter.provide_data, label_shapes=train_iter.provide_label)module.init_params(mx.initializer.Uniform(0.1))module.init_optimizer(optimizer=args.optimizer, optimizer_params={'learning_rate': args.lr})for epoch in tqdm(range(1, args.num_epochs + 1), desc="Epochs"):train_iter.reset()val_iter.reset()for batch in tqdm(train_iter, desc="Batches", leave=False):module.forward(batch, is_train=True) # compute predictionsmodule.backward() # compute gradientsmodule.update() # update parameterstrain_pred = module.predict(train_iter).asnumpy()train_label = train_iter.label[0][1].asnumpy()print('\nMetrics: Epoch %d, Training %s' % (epoch, evaluate(train_pred, train_label)))val_pred = module.predict(val_iter).asnumpy()val_label = val_iter.label[0][1].asnumpy()print('Metrics: Epoch %d, Validation %s' % (epoch, evaluate(val_pred, val_label)))if epoch % args.save_period == 0 and epoch > 1:module.save_checkpoint(prefix=os.path.join("../models/", args.model_prefix), epoch=epoch,save_optimizer_states=False)if epoch == args.num_epochs:module.save_checkpoint(prefix=os.path.join("../models/", args.model_prefix), epoch=epoch,save_optimizer_states=False)return moduledef predict(symbol, train_iter, val_iter, test_iter, data_names, label_names):devs = mx.cpu() if args.gpus is None or args.gpus is '' else [mx.gpu(int(i)) for i in args.gpus.split(',')]module = mx.mod.Module(symbol, data_names=data_names, label_names=label_names, context=devs)module.bind(data_shapes=train_iter.provide_data, label_shapes=train_iter.provide_label)module.init_params(mx.initializer.Uniform(0.1))module.init_optimizer(optimizer=args.optimizer, optimizer_params={'learning_rate': args.lr})# 加载模型参数params_file = "../models/electricity_model-0100.params" # 参数文件的路径module.load_params(params_file)# 将模型转换为评估模式test_iter.reset()test_pred = module.predict(test_iter).asnumpy()test_label = test_iter.label[0][1].asnumpy()pre_results = []real_results = []for i in range(len(test_pred)):# 这里你想看那个列的图形就画出那个列的即可pre_results.append(test_pred[i][4])real_results.append(test_label[i][4])print("预测值:", pre_results)print("真实值:", real_results)df = pd.DataFrame({'real': real_results, 'forecast': pre_results})df.to_csv('results.csv', index=False)# 创建一个新的图形plt.figure(figsize=(10, 6))# 绘制预测值曲线,使用蓝色实线plt.plot(pre_results, color='blue', linestyle='-', linewidth=2, label='Predicted')# 绘制真实值曲线,使用红色虚线plt.plot(real_results, color='red', linestyle='--', linewidth=2, label='True')# 添加标题和轴标签plt.title('Predicted vs True Values', fontsize=16)plt.xlabel('Time', fontsize=12)plt.ylabel('Value', fontsize=12)# 添加图例plt.legend(loc='upper left')# 显示网格线plt.grid(True, linestyle='--', alpha=0.5)# 保存图形plt.savefig('line_plot.png')# 显示图形plt.show()print(test_label, test_pred)if __name__ == '__main__':# parse argsargs = parser.parse_args()args.splits = list(map(float, args.splits.split(',')))args.filter_list = list(map(int, args.filter_list.split(',')))# Check valid argsif not max(args.filter_list) <= args.q:raise AssertionError("no filter can be larger than q")if not args.q >= math.ceil(args.seasonal_period / args.time_interval):raise AssertionError("size of skip connections cannot exceed q")# Build data iteratorstrain_iter, val_iter, test_iter = build_iters(args.data_dir, args.max_records, args.q, args.horizon, args.splits,args.batch_size)# Choose cells for recurrent layers: each cell will take the output of the previous cell in the listrcells = [mx.rnn.GRUCell(num_hidden=args.recurrent_state_size)]skiprcells = [mx.rnn.LSTMCell(num_hidden=args.recurrent_state_size)]# Define network symbolsymbol, data_names, label_names = sym_gen(train_iter, args.q, args.filter_list, args.num_filters,args.dropout, rcells, skiprcells, args.seasonal_period,args.time_interval)Train = True# train cnn modelif Train:module = train(symbol, train_iter, val_iter, data_names, label_names)predict(symbol, train_iter, val_iter, test_iter, data_names, label_names)
项目的目录结构如下->
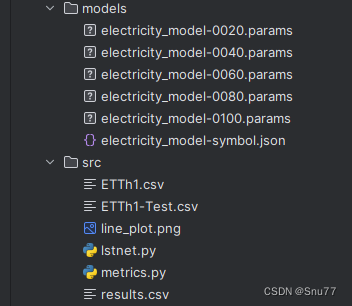
全文总结
到此本文已经全部讲解完成了,希望能够帮助到大家,在这里也给大家推荐一些我其它的博客的时间序列实战案例讲解,其中有数据分析的讲解就是我前面提到的如何设置参数的分析博客,最后希望大家订阅我的专栏,本专栏均分文章均分98。
时间序列预测中的数据分析->周期性、相关性、滞后性、趋势性、离群值等特性的分析方法
时间序列预测模型实战案例(八)(Informer)个人数据集、详细参数、代码实战讲解
时间序列预测模型实战案例(七)(TPA-LSTM)结合TPA注意力机制的LSTM实现多元预测
时间序列预测模型实战案例(六)深入理解机器学习ARIMA包括差分和相关性分析
时间序列预测模型实战案例(五)基于双向LSTM横向搭配单向LSTM进行回归问题解决
时间序列预测模型实战案例(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
时间序列预测模型实战案例(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
【全网首发】(MTS-Mixers)(Python)(Pytorch)最新由华为发布的时间序列预测模型实战案例(一)(包括代码讲解)实现企业级预测精度包括官方代码BUG修复Transform模型
时间序列预测模型实战案例(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
如果大家有不懂的也可以评论区留言一些报错什么的大家可以讨论讨论看到我也会给大家解答如何解决!
最后希望大家工作顺利学业有成!




![【PWN · ret2csu】[HNCTF 2022 WEEK2]ret2csu](https://img-blog.csdnimg.cn/317b1d0e7a05460c80715e3292025b90.png)

![[C/C++]数据结构 链表OJ题:环形链表(如何判断链表是否有环)](https://img-blog.csdnimg.cn/53d9b510d2b8465ebb55d4c7218d99ec.jpeg)